Erstellen Sie lineare dampfige Regressionsregressions-Excel. Nichtlineare Regression in Excel
Aufbau der linearen Regression, die Bewertung seiner Parameter und ihrer Bedeutung kann bei Verwendung des Pakets schneller durchgeführt werden excel-Analyse. (Regression). Betrachten Sie die Interpretation der in der allgemeinen Falle erhaltenen Ergebnisse ( k. Erklären von Variablen) gemäß Beispiel 3.6.
Tabelle regressionsstatistik. Die Werte sind:
Mehrere R. - Mehrfacher Korrelationskoeffizient;
R.- quadrat - Bestimmtheitsmaß R. 2 ;
Normiert R. - quadrat - angepasst R. 2, geändert durch die Anzahl der Freiheitsgrade;
Standart Fehler- Standard-Regressionsfehler S.;
Beobachtungen -anzahl der Beobachtungen. n..
Tabelle Dispersionsanalyseverfügbar:
1. Spalte dF. - die Anzahl der Freiheitsgrade gleich
für string. Regression. dF. = k.;
für string. RückstanddF. = n. – k. – 1;
für string. GESAMTdF. = n.– 1.
2. Säule Ss -die Summe der Quadrate der Abweichungen entspricht
für string. Regression. ;
für string. Rückstand ;
für string. GESAMT .
3. Spalte FRAU.dispersionen, die durch die Formel definiert sind FRAU. = Ss./dF.:
für string. Regression. - Faktordispersion;
für string. Rückstand- Restdispersion.
4. Spalte F. - Berechnungswert. F.-Kriterien, berechnet von der Formel
F. = FRAU.(Regression) / FRAU.(Rückstand).
5. Spalte Bedeutung F. -Notion-Niveau der Signifikanz, die dem berechnen entspricht F.- Statistiken .
Bedeutung F. \u003d Frasig ( F-statistiken, dF.(Regression), dF.(Rückstand)).
Wenn signifikant F. < стандартного уровня значимости, то R. 2 statistisch signifikant.
| Coeffizi-Cents. | Standart Fehler | t-tyati tisty | P-Wert | Niedriger 95% | Top 95% | |
| Y. | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X. | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Diese Tabelle zeigt an:
1. Faktoren- die Werte der Koeffizienten eIN., b..
2. Standardfehler- Standardfehler von Regressionskoeffizienten S A., S B..
3. t-statistiken - berechnete Werte t. -Kriterien, berechnet von der Formel:
t-Statistiken \u003d Koeffizienten / Standardfehler.
4.R.-Notion (Bedeutung t.) - Dies ist der Wert des Signifikanzniveaus, der dem berechnen t-statistiken.
R.-Notion \u003d. SACIERSAG.(t.-Statistiken, dF.(Rückstand)).
Wenn ein R.-Wert< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. Niedriger 95% und obere 95%- Bottom und obere Grenzen von 95% Konfidenzintervallen für Koeffizienten der theoretischen Gleichung der linearen Regression.
| Fazit Rückstand | ||
| Überwachung | Vorausgesagt y. | Rückstände E. |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
Tabelle Fazit Rückstandspezifizierten:
in der Spalte Überwachung- Beobachtungsnummer;
in der Spalte Vorhergesagt y. - berechnete Werte der abhängigen Variablen;
in der Spalte Rückstände e. - der Unterschied zwischen den beobachteten und berechneten Werten der abhängigen Variablen.
Beispiel 3.6.Diese Daten sind auf Lebensmittelaufwendungen erhältlich y. und Duscheinkommen x.für neun Familien von Familien:
| X. | |||||||||
| y. |
Analysieren Sie die Ergebnisse des Excel-Analysepakets (Regression), analysiert die Abhängigkeit der Kosten von Nahrungsmitteln aus der Größe des Duschwassereinkommens.
Die Ergebnisse der Regressionsanalyse werden in Form von:
![]()
wo die Klammern die Standardfehler von Regressionskoeffizienten angeben.
Rezessionskoeffizienten aber = 65,92 und B. \u003d 0,107. Die Richtung der Kommunikation zwischen y. und x.bestimmt das Zeichen des Koeffizientenmarktes b. \u003d 0,107, d. H. Die Kommunikation ist direkt und positiv. Koeffizient b. \u003d 0,107 zeigt, dass mit zunehmender Erhöhung des Duscheinkommens pro 1 Zustand. Einheiten. Leistungskosten steigen um 0,107 SL. Einheiten.
Wir schätzen die Bedeutung der Koeffizienten des erhaltenen Modells. Die Bedeutung der Koeffizienten ( a, B.) Geprüft von t.-Prüfung:
P-Wert ( eIN.) = 0,00080 < 0,01 < 0,05
P-Wert ( b.) = 0,00016 < 0,01 < 0,05,
folglich die Koeffizienten ( a, B.) Signifikant bei 1% auf 1% und sogar mehr mit 5% der Bedeutung. Somit sind die Regressionskoeffizienten signifikant und das Modell ist für die anfänglichen Daten ausreichend.
Die Ergebnisse der Regressionsschätzung sind nicht nur mit den erhaltenen Werten von Regressionskoeffizienten kompatibel, sondern auch mit einigen ihrer vielen (Vertrauensintervalle). Mit einer Wahrscheinlichkeit von 95% Konfidenzintervallen für Koeffizienten (38,16 - 93,68) für eIN. und (0,0728 - 0,142) für b.
Die Qualität des Modells wird durch den Bestimmungskoeffizienten geschätzt R. 2 .
Wert R. 2 \u003d 0.884 bedeutet, dass der Faktor der Duscheinnahmen 88,4% der Variationen (Scatter) der Ernährungskosten erklären kann.
Bedeutung R. 2 checkte von F-test: Bedeutung F. = 0,00016 < 0,01 < 0,05, следовательно, R. 2 Es ist erheblich auf 1% -Anzweige, und sogar noch dabei bei 5% der Signifikanzniveau.
Bei der gekoppelten linearen Regression kann der Korrelationskoeffizient als definiert werden ![]() . Der resultierende Wert des Korrelationskoeffizienten weist darauf hin, dass die Beziehung zwischen den Lebensmittelkosten und der Duscheinnahmen sehr nahe ist.
. Der resultierende Wert des Korrelationskoeffizienten weist darauf hin, dass die Beziehung zwischen den Lebensmittelkosten und der Duscheinnahmen sehr nahe ist.
28 Okt.
Guten Tag, liebe Blog-Leser! Heute werden wir über eine nichtlineare Regression sprechen. Entscheidung lineare Regressionen Sie können den Link sehen.
Diese Methode Es wird hauptsächlich in der wirtschaftlichen Modellierung und der Prognose verwendet. Sein Ziel ist es, die Abhängigkeiten zwischen den beiden Indikatoren zu beschuldigen und zu identifizieren.
Grundtypen nichtlineare Regressionen sind:
- polynom (quadratisch, kubisch);
- hyperbolisch;
- leistung;
- indikativ;
- logarithmisch.
Es können auch verschiedene Kombinationen verwendet werden. Beispielsweise werden für Analysen der temporären Serien im Bankensektor, Versicherungen, demografische Studien von einer Gompezer-Kurve verwendet, die eine Art logarithmischer Regression ist.
In der Vorhersage mit nichtlinearen Regressionen, die Hauptsache, um den Korrelationskoeffizienten herauszufinden, der uns zeigt, ob es eine enge Verbindung von Honig mit zwei Parametern gibt oder nicht. Wenn der Korrelationskoeffizient nahe an 1 liegt, bedeutet dies in der Regel eine Verbindung, und die Prognose ist ziemlich genau. Ein weiteres wichtiges Element nichtlinearer Regressionen ist der durchschnittliche relative Fehler ( ABER ) Wenn es sich im Intervall befindet<8…10%, значит модель достаточно точна.
Daraufhin werden wir vielleicht den theoretischen Block beenden und auf praktische Berechnungen eingehen.
Wir verfügen über einen Autovertreibung über das Intervall von 15 Jahren (bezeichnen Sie IT X), die Anzahl der Messschritte ist ein Argument n, es gibt auch ein Umsatz für diese Zeiträume (wir bezeichnen es y), wir müssen vorhersagen, was sein wird Umsatz in der Zukunft. Bauen Sie die folgende Tabelle auf:
Um zu studieren, müssen wir die Gleichung lösen (Abhängigkeiten y von x): y \u003d AX 2 + BX + C + E. Dies ist eine gepaarte quadratische Regression. In diesem Fall wird in diesem Fall das kleinste Quadrate in diesem Fall zur Bestimmung unbekannter Argumente - A, B, c. Es wird zum System von algebraischen Gleichungen des Formulars führen:

Um dieses System zu lösen, verwenden wir zum Beispiel beispielsweise durch die Antriebsmethode. Wir sehen, dass der im System enthaltene Betrag bei unbekanntem Koeffizienten ist. Fügen Sie zum Berechnen ein paar Säulen an den Tisch (D, E, F, G, H) bzw. Schild, der Bedeutung von Berechnungen - in der Säule D ein, errichten Sie X in das Quadrat in E in den Würfel, in f in 4 grad, in g, x und y, in h auf a errect x in ein quadratisches und variablen von y.

Es stellt sich heraus, dass es mit dem Tisch der Form gefüllt ist, um die Gleichung zu lösen.


Wir bilden eine Matrix EIN. Systeme, bestehend aus Koeffizienten, die in den linken Teilen von Gleichungen unbekannt sind. Positionieren Sie es in der A22-Zelle und lass uns anrufen A \u003d.". Wir folgen dem System der Gleichungen, die wir zur Lösung der Regression gewählt haben.

Das heißt, in der B21-Zelle müssen wir die Menge der Säule aufsetzen, in der der X-Indikator im vierten Grad - F17 errichtet wurde. Ich bin gerade auf die Zelle gefallen - "\u003d F17". Als nächstes benötigen wir die Menge der Spalte, in der X im Cube - E17, dann streng auf das System gehen. Somit müssen wir die gesamte Matrix füllen.
In Übereinstimmung mit dem Cramer-Algorithmus mit einer Matrix A1, ähnlich einem, in dem anstelle der Elemente der ersten Säule Elemente der rechten Teile der Systemgleichungen platziert werden sollten. Das heißt, die Summe der X-Säule im Quadrat wird mit y, der Summe der XY-Säule und der Summe der Y-Säule multipliziert.

Wir benötigen auch zwei weitere Matrizen - wir nennen sie A2 und A3, in der die zweite und dritte Säule aus den Koeffizienten der richtigen Teile der Gleichungen bestehen. Das Bild wird wie folgt sein.

Nach dem gewählten Algorithmus müssen wir die Werte der Determinanten (Determinanten, d) der resultierenden Matrizen berechnen. Wir verwenden die multurierte Formel. Die Ergebnisse werden in den Zellen J21: K24 platziert.

Die Berechnung der Koeffizienten der Rin-Gleichung wird in Zellen entgegengesetzt, die den entsprechenden Determinanten durch die Formel entgegengesetzt sind: eIN. (in der Zelle M22) - "\u003d k22 / k21"; b. (in der Zelle M23) - "\u003d k23 / k21"; von(In der M24-Zelle) - "\u003d k24 / k21".
Wir erhalten unsere gewünschte Paare quadratische Regressionsgleichung:
y \u003d -0,074x 2 + 2,151x + 6,523
Lassen Sie uns die lineare Kommunikation durch den Korrelationsindex abschätzen.

Fügen Sie zum Berechnen einer zusätzlichen Spalte J zur Tabelle hinzu (nennen Sie es y *). Die Berechnung ist der folgende (entsprechend der von uns erhaltenen Regressionsgleichung) - "\u003d $ M $ 22 * \u200b\u200bB2 * B2 + $ M $ 23 * B2 + $ M $ 24".Positionieren Sie es in der Zelle J2. Es bleibt den AutoCill-Marker in die J16-Zelle.

Um die Beträge (Y-Y-Durchschnitt) 2 zu berechnen, fügen Sie die Spalten der Tabelle K und L mit den entsprechenden Formeln mit den entsprechenden Formeln hinzu. Der Durchschnitt der Spalte y wird mit der SRVNow-Funktion betrachtet.

Platzieren Sie in der K25-Zelle den Korrelationsindex-Berechnungsformel - "\u003d root (1- (k17 / l17))".

Wir sehen, dass der Wert von 0,959 sehr nahe an 1 ist, dann gibt es eine enge nichtlineare Verbindung zwischen Vertrieb und Jahren.
Es bleibt, die Qualität der Anpassung der resultierenden quadratischen Regressionsgleichung (Bestimmungsindex) zu bewerten. Es wird mit der quadratischen Formel Korrelationsindex berechnet. Das heißt, die Formel in der K26-Zelle ist sehr einfach - "\u003d k25 * k25".

Der Koeffizient von 0,920 ist nahe an 1, was auf eine hohe Qualität anzeigt.
Die letzte Aktion ist die Berechnung des relativen Fehlers. Fügen Sie eine Spalte hinzu und geben Sie die Formel ein: "\u003d ABS (((C2-J2 / C2), ABS-Modul, absoluter Wert. Wenn Sie den Marker nach unten und in der M18-Zelle verschieben, ziehen Sie den Durchschnittswert (SRVNA) ab, zuordnen Sie Prozentformatzellen. Das erhaltene Ergebnis - 7,79% erfolgt innerhalb der zulässigen Fehlerwerte<8…10%. Значит вычисления достаточно точны.
Wenn ein Bedarf an erhaltenen Werten erforderlich ist, können wir einen Zeitplan aufbauen.
Die Datei mit dem Beispiel ist beigefügt - Link!
Kategorien: / / ab 10/28/2017Die Regressionslinie ist eine grafische Reflexion der Beziehung zwischen Phänomenen. Sehr deutlich kann eine Regressionslinie in Excel gebaut werden.
Dafür brauchen Sie:
1. Extrahieren Excel-Programm
2. Erstellen Sie Spalten mit Daten. In unserem Beispiel werden wir eine Regressionslinie oder Wechselbeziehungen zwischen Aggressivität und Unsicherheit in ihren Erstklässern aufbauen. Im Experiment haben 30 Kinder teilgenommen, die Daten werden in der speziellen Tabelle dargestellt:
1 Spalte - Testnummer
2 columid - aggressivität in ballaten
3 columid - schüchternheit in ballaten

3. Dann müssen Sie beide Säulen (ohne den Namen der Spalte) hervorheben, klicken Sie auf die Registerkarte einfügen , wählen pagle und aus den vorgeschlagenen Layouts, um das erste zu wählen Wählerisch mit markierern. .

4. Also haben wir ein Leerzeichen für die Regressionslinie - die sogenannten - streuungsdiagramm. Um in die Regressionszeile zu gelangen, müssen Sie auf die resultierende Zeichnung klicken, klicken Sie auf die Registerkarte konstrukteur, finden Sie auf dem Panel Layouts-Diagramme und wähle M. aberket9. Es ist immer noch darauf geschrieben F (x)

5. Und wir haben eine Regressionslinie. Die Grafik zeigt auch seine Gleichung und das Quadrat des Korrelationskoeffizienten an

6. Es gibt einen Diagrammnamen, den Namen der Achsen. Sie können auch die Legende entfernen, die Anzahl der horizontalen Mesh-Linien reduzieren (Registerkarte layout , dann gitter ). Hauptänderungen und Einstellungen werden auf der Registerkarte vorgenommen. Layout

Die Regressionslinie ist in MS Excel gebaut. Jetzt kann es dem Text der Arbeit hinzugefügt werden.
Meiner Meinung nach ist Econometric als Student eine der angelegten Wissenschaften von allem, was ich in den Mauern meiner Universität kennengelernt habe. Damit ist es in der Tat, Sie können angewandte Aufgaben im gesamten Unternehmen lösen. Wie effektiv diese Lösungen sind - die dritte Frage. Die unterste Linie ist, dass der größte Teil des Wissens Theorie bleiben wird, aber Ökonometrie und Regressionsanalyse lohnt sich immer noch, mit besonderer Aufmerksamkeit zu studieren.
Was erklärt die Regression?
Bevor wir mit MS Excel-Funktionen fortfahren, so dass Sie diese Aufgaben lösen können, möchte ich Ihnen auf Ihren Fingern erklären, dass im Wesentlichen die Regressionsanalyse impliziert. Es ist also einfacher für Sie, die Prüfung zu ergreifen, und vor allem ist es interessanter, das Thema zu studieren.
Hoffen wir, dass Sie mit dem Konzept einer Funktion der Mathematik vertraut sind. Die Funktion ist die Beziehung von zwei Variablen. Wenn Sie eine Variable ändern, geschieht etwas auf der anderen Seite. Ändern Sie X, Änderungen y. Funktionen beschreiben verschiedene Gesetze. Wir können eine Funktion kennen, wir können beliebige Werte von X ersetzen und ansehen, wie y.
Es ist von großer Bedeutung, da Regression ein Versuch ist, mit Hilfe einer bestimmten Funktion auf den ersten Blick auf unsystematische und chaotische Prozesse zu erklären. So können Sie beispielsweise die Beziehung des Dollars und der Arbeitslosigkeit in Russland identifizieren.
Wenn dieses Muster erkannt wird, werden wir gemäß der Funktion, die wir während der Berechnungen erhalten haben, eine Prognose erstellen, die auf der N-Ohm-Dollarrate in Bezug auf den Rubel das Niveau der Arbeitslosigkeit sein wird.
Diese Beziehung wird als Korrelation bezeichnet. Die Regressionsanalyse beinhaltet die Berechnung des Korrelationskoeffizienten, der die Dichtheit der Beziehung zwischen den unter Berücksichtigung der Variablen (Dollarkurs und der Anzahl der Jobs) erklärt.
Dieser Koeffizient kann positiv und negativ sein. Seine Werte liegen im Bereich von -1 bis 1. Dementsprechend können wir eine hohe negative oder positive Korrelation beobachten. Wenn es positiv ist, folgt der Anstieg des Dollars und der Entstehung neuer Arbeitsplätze. Wenn es negativ ist, wird es einen Rückgang der Arbeitsplätze, um den Kurs zu steigern.
Regression ist mehrere Arten. Es kann linear, parabolisch, macht, exponentiell usw. sein Wir treffen die Wahl des Modells, je nachdem, welche Regression das speziell auf unseren Fall erfüllt, welches Modell so nahe wie möglich an unserem Korrelation ist. Betrachten Sie dies im Beispiel der Aufgabe und lösen Sie es in MS Excel.
Lineare Regression in MS Excel
Um lineare Regressionsprobleme zu lösen, benötigen Sie eine Funktion "Datenanalyse". Es kann nicht mit Ihnen enthalten sein, damit Sie es aktivieren müssen.
- Klicken Sie auf die Schaltfläche "Datei".
- Wählen Sie den Artikel "Parameter" aus.
- Klicken Sie auf die vorletzte Registerkarte des "Superstructure" auf der linken Seite.
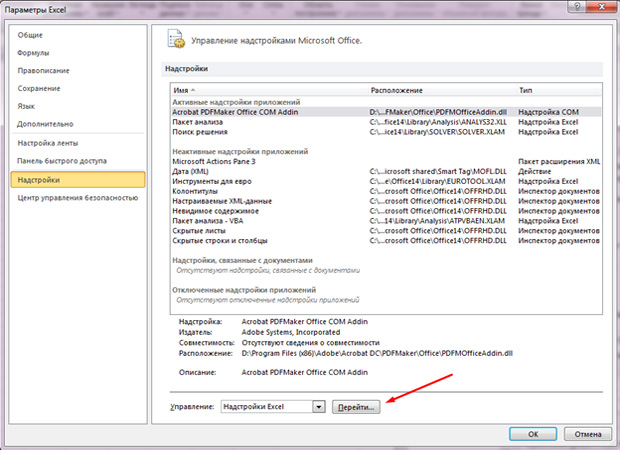
- Von unten sehen Sie die Inschrift "Management" und "GO" -Taste. Klick es an;
- Zecke ein Tick auf das "Analysepaket";
- OK klicken".

Beispiel für die Aufgabe
Die Batch-Analyse-Funktion ist aktiviert. Lassen Sie die folgende Aufgabe. Wir haben ein Beispiel für mehrere Jahre über die Anzahl der PE im Unternehmen und die Anzahl der Beschäftigten. Wir müssen die Beziehung zwischen diesen beiden Variablen erkennen. Es gibt eine erläuternde Variable X - Dies ist die Anzahl der Arbeiter und die erläuternde Variable - y ist die Anzahl der Notfälle. Ich verteile die Quelldaten in zwei Säulen.

Gehen wir auf die Registerkarte "Daten" und wählen Sie "Datenanalyse".
Wählen Sie in der angegebenen Liste "Regression" aus. Wählen Sie in den Eingangsintervallen Y und X die entsprechenden Werte aus.
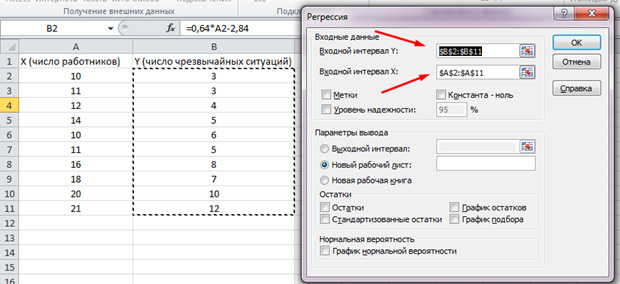
OK klicken". Die Analyse wird hergestellt, und in einem neuen Blatt sehen wir die Ergebnisse.
Die wichtigsten Werte für uns sind in der folgenden Abbildung markiert.

Mehrere R ist der Bestimmungskoeffizient. Es verfügt über eine komplexe Berechnungsformel und zeigt, wie er unseren Korrelationskoeffizienten vertrauen kann. Denin mehr, desto mehr dieser Wert, desto mehr Vertrauen, desto stärker ist unser Modell als Ganzes.
Y-Kreuzung und Kreuzung X1 sind die Koeffizienten unserer Regression. Wie bereits erwähnt, ist Regression eine Funktion, und sie hat bestimmte Koeffizienten. Somit wird unsere Funktion ansehen: y \u003d 0,64 * x-2.84.
Was gibt uns das? Dies gibt uns die Möglichkeit, eine Prognose zu erstellen. Angenommen, wir möchten 25 Arbeiter auf dem Unternehmen einstellen, und wir müssen uns annähernd vorstellen, wie die Anzahl der Notfälle sein wird. Wir ersetzen diesen Wert auf unsere Funktion und wir erhalten das Ergebnis y \u003d 0,64 * 25 - 2.84. Etwa 13 PP werden wir auftreten.
Mal sehen, wie es funktioniert. Schauen Sie sich die untenstehende Zeichnung an. In den tatsächlichen Werten der beteiligten Mitarbeiter werden die sachlichen Werte ersetzt. Sehen, wie nah an echten Akteuren an Bedeutung ist.

Sie können das Korrelationsfeld auch aufbauen, indem Sie den IPVENTION- und ICS-Bereich auswählen, indem Sie auf die Registerkarte "Einfügen" klicken und ein Punktdiagramm auswählen.

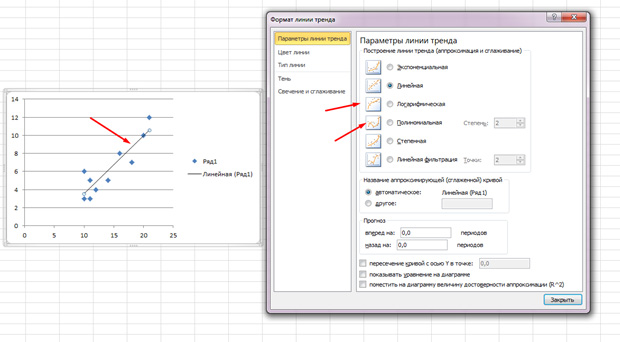
Die Punkte gehen in die Ecke, steigen aber im Allgemeinen auf, als ob die Linie in der Mitte liegt. Sie können diese Zeile auch hinzufügen, indem Sie in MS Excel auf die Registerkarte "Layout" klicken und die Trendzeilenelemente auswählen
Klicken Sie zweimal auf der angegebenen Linie, die erscheint, und sehen Sie, was zuvor angegeben wurde. Sie können die Art der Regression ändern, je nachdem, wie Ihr Korrelationsfeld aussieht.
Vielleicht scheint es Ihnen, dass die Punkte einen Parabola ziehen, und keine direkte Linie und Sie angemessen, um eine andere Art von Regression zu wählen.
Fazit
Hoffen wir, dass dieser Artikel Ihnen ein größeres Verständnis dafür hat, welche Regressionsanalyse ist und für das, was es benötigt wird. All dies hat einen großen Anwendungswert.
Das MS Excel-Paket ermöglicht den Bau einer linearen Regressionsgleichung der meisten der Arbeit sehr schnell. Es ist wichtig zu verstehen, wie Sie die erzielten Ergebnisse interpretieren können.
Muss arbeiten Analysepaket.was Sie im Menüpunkt aktivieren möchten Service \\ Add-In

In Excel 2007, um das Analysepaket zu aktivieren, müssen Sie auf den Block klicken Excel-EinstellungenDurch Drücken der Taste in der oberen linken Ecke und dann die Taste " Excel-Einstellungen»Am unteren Rand des Fensters:

![]()

![]()


Um ein Regressionsmodell aufzubauen, müssen Sie Element auswählen Service \\ Data Analysis \\ Regression. (In Excel 2007 befindet sich dieser Modus im Block Daten- / Datenanalyse / Regression). Ein Dialogfeld scheint auszufüllen:

1) Eingabeintervall y. ¾ Enthält einen Link zu Zellen, die Werte der Leistung enthalten y.. Werte müssen sich in der Spalte befinden.
2) Eingabeintervall X. ¾ Enthält einen Link zu Zellen, die die Werte der Faktoren enthalten. Werte müssen sich in Spalten befinden.
3) Zeichen Stichworte Es wird angehoben, wenn die ersten Zellen erläuterndes Text enthalten (Datensignaturen);
4) Zuverlässigkeitsstufe ¾ Dies ist eine Vertrauenswahrscheinlichkeit, die standardmäßig als 95% betrachtet wird. Wenn dieser Wert nicht angeht, müssen Sie diese Funktion aufnehmen und den gewünschten Wert eingeben.
5) Zeichen Constanta null. Es schaltet ein, wenn es notwendig ist, eine Gleichung aufzubauen, in der eine freie Variable ist;
6) Ausgangsparameter Bestimmen Sie, wo die Ergebnisse platziert werden müssen. Der Standardmodus ist Neues Arbeitsblatt;
7) Block Rückstände Ermöglicht das Einschalten der Ausgabe der Rückstände und der Konstruktion ihrer Grafiken.
Infolgedessen werden Informationen angezeigt, die alle erforderlichen Informationen enthalten, und in drei Blöcke gruppiert: Regressionsstatistik., Dispersionsanalyse, Fazit Rückstand. Betrachten Sie sie näher.
1. Regressionsstatistik.:
mehrere R. bestimmt von der Formel ( pearson-Korrelationskoeffizient);
R.  (bestimmtheitsmaß);
(bestimmtheitsmaß);
Normiert R.-KVadrat wird von der Formel berechnet  (für mehrere Regression verwendet);
(für mehrere Regression verwendet);
Standart Fehler S. Berechnet durch Formel.  ;
;
Beobachtungen ¾ Dies ist die Datenmenge n..
2. Dispersionsanalyse, Linie Regression.:
Parameter dF. Rabe m. (Anzahl der Faktorengruppen x.);
Parameter Ss. bestimmt durch die Formel;
Parameter FRAU. bestimmt durch die Formel;
Statistiken F. bestimmt durch die Formel;
Bedeutung F.. Wenn die erhaltene Zahl übersteigt, wird die Hypothese aufgenommen (es gibt keine lineare Beziehung), da sonst die Hypothese entnommen wird (eine lineare Beziehung).
3. Dispersionsanalyse, Linie Rückstand:
Parameter dF. gleich;
Parameter Ss. Formel ist bestimmt  ;
;
Parameter FRAU. Von der Formel bestimmt.
4. Dispersionsanalyse, Linie GESAMT Enthält die Summe der ersten beiden Spalten.
5. Dispersionsanalyse, Linie Y-crossing. Enthält den Wert des Koeffizienten, des Standardfehlers und t.-Statistiken.
P.-NOTION ¾ ist der Wert der Signifikanzgrade, die dem berechnen t.-Statistiken. Bestimmt durch die Funktion von stouturasp ( t.-Statistiken; ). Wenn ein P.-NOTION überschreitet, die entsprechende Variable ist statistisch unbedeutend und es kann vom Modell ausgeschlossen werden.
Niedriger 95% und Top 95% ¾ Dies ist die untere und obere Grenze von 95 Prozent Konfidenzintervallen für die Koeffizienten der linearen Regression theoretischen Gleichung. Wenn in dem Dateneingabeblock der Konfidenzwahrscheinlichkeit standardmäßig standardmäßig hinterlassen wurde, werden die letzten beiden Spalten die vorherigen duplizieren. Wenn der Benutzer seine Vertrauenswahrscheinlichkeit eingegeben hat, enthalten die letzten beiden Spalten die Werte der unteren und oberen Grenze für die angegebene Vertrauenswahrscheinlichkeit.
6. DispersionsanalyseSaiten enthalten die Werte der Koeffizienten, Standardfehler, t.-Statistiker, P.- Annäherungen und Vertrauensintervalle für relevante.
7. Block Fazit Rückstand Enthält vorhergesagte Werte y. (In unseren Bezeichnungen es) und den Resten.