線形蒸気回帰エクセルを造る。 Excelの非線形回帰
線形回帰の構築、そのパラメータの評価およびそれらの意義は、パッケージを使用するときよりも迅速に実行することができる excel分析 (回帰)。 一般的なケースで得られた結果の解釈を考慮してください( k 実施例3.6に従って変数を説明する)。
テーブル 回帰統計 値は次のとおりです。
複数 r - 多重相関係数
r- 平方 - 決定係数 r 2 ;
norm r - 平方 - 調整しました r 2、自由度の数によって修正されました。
標準誤差- 標準回帰誤差 s;
観察 -観察数 n.
テーブル 分散解析利用可能:
1.列に dF。 - 自由度数は等しい
文字列の場合 回帰 dF。 = k;
文字列の場合 残基dF。 = n – k – 1;
文字列の場合 合計dF。 = n– 1.
列に SS -偏差の正方形の合計は
文字列の場合 回帰 ;
文字列の場合 残基 ;
文字列の場合 合計 .
列に MS。式で定義された分散 MS。 = ss。/dF。:
文字列の場合 回帰 - 要因分散
文字列の場合 残基- 残留分散
4.列に f - 計算値 f式によって計算された基準
f = MS。(回帰)/ MS。(残基)。
5.列に 意義 f - 計算に対応する有意性の照会レベル f- 統計 .
意義 f \u003d frasp( f統計、 dF。(回帰)、 dF。(残基))。
重要なら f < стандартного уровня значимости, то r 2統計的に重要です。
| コケフィセント | 標準誤差 | t-Tyati Tisty | P値 | 95%低い | トップ95% | |
| y。 | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| バツ。 | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
この表は次のものを示しています。
1. 要因- 係数の値 a., b.
標準誤差- 回帰係数の標準誤差 SのA., S B..
3. t統計 - 計算値 t 式によって計算された手法:
t統計\u003d係数/標準誤差。
4.r- 結論(重要性) t) - これは計算に対応する重要度の値です。 t統計。
r- otior \u003d 土曜日の(t-統計、 dF。(残基))。
もし r-値< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5。 95%、上位95%- 線形回帰の理論式の係数のための95%信頼区間の底と上限。
| 結論残差 | ||
| 観察 | yを予測しました。 | 残留物E. |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
テーブル 結論残差指定:
列の中で 観察- 観測数
列の中で 予知された y。 - 依存変数の計算値。
列の中で 残留物 e. - 依存変数の観測値と計算値の差。
例3.6。これらのデータは食料支出で入手できます y。 そしてシャワー収入 バツ。家族の9家族のために:
| バツ。 | |||||||||
| y。 |
Excel分析パッケージの結果(回帰)を使用して、シャワー収入の大きさからの食品のコストの依存性を分析します。
回帰分析の結果は、以下の形で受け入れられます。
![]()
ブラケットが回帰係数の標準誤差を示す場合。
不況係数 だが = 65,92 そしてB. \u003d 0.107。 間の通信方向 y。 そして バツ。係数市場の符号を決定します b \u003d 0.107、すなわち コミュニケーションは直接的で前向きです。 係数 b \u003d 0.107は、1つの状態ごとにシャワー収入が増加したことを示しています。 単位。 電力費用は0.107 SLで増加します。 単位。
得られたモデルの係数の重要性を推定しています。 係数の重要性 a、B。) によって確認されました t-テスト:
p値( a.) = 0,00080 < 0,01 < 0,05
p値( b) = 0,00016 < 0,01 < 0,05,
その結果、係数( a、B。)1%レベル、さらには有意差の5%でさらに高い。 したがって、回帰係数は重要であり、モデルは初期データに適しています。
回帰推定結果は、回帰係数の得られた値だけでなく、それらの多く(信頼区間)とも互換性がある。 係数の95%の信頼区間がある可能性がある(38,16 - 93.68) a. そして(0.0728 - 0.142) b。
モデルの品質は決定係数によって推定されます r 2 .
値 r 2 \u003d 0.884は、シャワー収入の要因が栄養費の変動(散布)の88.4%を説明できることを意味します。
意義 r 2をチェックしました fテスト:重要性 f = 0,00016 < 0,01 < 0,05, следовательно, r 2それは1%レベルで、5%の有意水準でさらに大きくなっています。
一対の線形回帰の場合、相関係数は次のように定義することができる。 ![]() 。 結果として生じる相関係数の値は、食料費とシャワー収入の関係が非常に近いことを示しています。
。 結果として生じる相関係数の値は、食料費とシャワー収入の関係が非常に近いことを示しています。
28 oct
こんにちは、親愛なるブログの読者! 今日は非線形回帰について話します。 決定 線形回帰 リンクを見ることができます。
この方法 それは主に経済的モデリングと予測に使われています。 彼の目標は、2つの指標の間の依存関係を非難して特定することです。
基本タイプ 非線形回帰 :
- 多項式(二次、立方体);
- 双曲線
- パワー;
- 気持ちいい。
- 対数
様々な組み合わせも使用することができる。 例えば、銀行部門における一時的なシリーズの分析のために、保険、人口統計学的研究はGompezer曲線によって使用され、それは一種の対数回帰である。
非線形回帰を使用した予測では、相関係数を見つけるための主なものが、2つのパラメータを持つ蜂蜜の密接な相互接続があるかどうかを示すための主なものです。 原則として、相関係数が1に近い場合は、接続があることを意味し、予測は非常に正確になります。 非線形回帰のもう1つの重要な要素は平均相対誤差です( だが )間隔にある場合<8…10%, значит модель достаточно точна.
これで、おそらく理論的なブロックは終了し、実際の計算に進みます。
15年間の車の販売テーブルがあります(それを表す)、測定ステップの数は議論の数になります。これらの期間の収益もあります(yを表します)将来の収益 次の表を作成します。
勉強するためには、式(Xからの依存性Y)を解く必要があります.Y \u003d AX 2 + BX + C + E。 これは一対の二次回帰です。 この場合、この場合の最小二乗法は、未知引数を決定するために、A、B、C。 フォームの代数式のシステムにつながります。

このシステムを解決するために、例えば駆動方法によって使用する。 システムに含まれる量が未知の係数であることがわかります。 それらを計算するには、テーブル(D、E、F、G、H)に数列を追加します。計算の意味 - 列D、Xの正方形へのX、INの場合、中の列に、 4度、g、xおよびy、x内のx(x)中、xからyの変数へのx

式を解くのに必要な形式の表で埋められることが判明します。


マトリックスを形成します A. 方程式の左側の部分には、未知の係数からなるシステム。 A22セルに配置して電話しましょう a \u003d。"。 私たちは回帰を解決することに選出した方程式のシステムに従います。

すなわち、B21セルでは、4次元F17のXインジケータが正立された列の量を配置しなければならない。 細胞に落ちたところ - "\u003d F17"。 次に、キューブE17のXが必要な列の量が必要です。その後、システムに厳密に進みます。 したがって、マトリックス全体を埋める必要があります。
クレアマアルゴリズムに従って、マトリックスA1が、最初の列の要素の代わりに、システム方程式の右側部分の要素を配置する必要があるAと同様に行列A1を有する。 すなわち、正方形のX列の合計にy、xy列の合計とy列の合計が乗算されます。

また、2つのマトリックスを必要とします - 2番目と3番目の列が方程式の右側の部分の係数からなるA2とA3と呼びます。 写真は次のとおりです。

選択されたアルゴリズムに続いて、結果の行列の決定要因(決定要因D)の値を計算する必要があります。 私達はモップされた式を使います。 結果はセルJ21:K24に配置されます。

RIN方程式の係数の計算は、以下の式によって、対応する決定基の反対側のセルで生成されます。 a. (セルM22) - "\u003d K22 / K21"; b (セルM23) - "\u003d K23 / K21"; から(M24セル) - "\u003d K24 / K21"。
私達は私達の望ましいペア二次回帰方程式を得る:
y \u003d -0.074x 2 + 2,151x + 6,523
相関インデックスによる線形通信を推定しましょう。

計算するには、追加の列jをテーブルに追加します(y *を呼び出しましょう)。 計算は次のとおりです(米国で取得した回帰式によると) - "\u003d $ m $ 22 * b2 * b2 + $ m $ 23 * b2 + $ m $ 24"。セルJ2に位置付けます。 オートコッシルマーカーをJ16セルに延伸したままになります。

金額(Y-Y平均化)2を計算するには、対応する式で表kおよびlに列を追加します。 列Yの平均はSRVNOW関数を使用して考慮されます。

K25セルでは、相関インデックス計算式 - "\u003d root(1-(k17 / L17))"を配置します。

0.959の値が1に非常に近いことがわかりました、そして、売上と年の間には密接な非線形接続があります。
結果として得られる二次回帰式(決定指数)を適合させることの品質を評価することは残っています。 相関指数の正方形の式を使用して計算されます。 すなわち、K26細胞の式は非常に単純であろう - 「\u003d K25 * K25」であろう。

0.920の係数は1に近い。これは高品質のフィットを示します。
最後のアクションは相対エラーの計算になります。 列を追加して式:「\u003d ABS((C2-J2)/ C2)、ABS - モジュール、絶対値を入力します。 マーカーを下にシフトさせることによって、M18セルで、平均値(SRVNA)を引き出し、フォーマットセルパーセントを割り当てます。 得られた結果 - 7.79%は許容エラー値内です<8…10%. Значит вычисления достаточно точны.
得られた値が必要な場合は、スケジュールを構築できます。
例のファイルが添付されています - リンク!
カテゴリー: / / 2017/10/28から回帰線は現象との関係のグラフィック反映です。 Excelでは明らかに回帰ラインを作成することができます。
これのために必要なので:
1. Excelプログラムを抽出します
2.データを含む列を作成します。 私たちの例では、積極的な攻撃と不確実性の間に、積極的な攻撃と不確実性の間に、積極的な回線または相互関係を構築します。 実験では、30人の子供が参加し、データは特別な表に表示されます。
1列 - テスト番号
2つのコルマド - 積極的 バラートで
3コレンシド - diff diff バラートで

3.次に、両方の列をハイライトする必要があります(列の名前なし)、タブをクリックします。 インサート , 選ぶ p 最初のものを選ぶために提案されたレイアウトから マーカーで熟練しています .

4.それでは、回帰回線のための空白を得ました - いわゆる - 散乱図。 回帰回線に移動するには、結果の描画をクリックしてタブをクリックする必要があります。 コンストラクタ、 パネルを見つけてください レイアウト図 そして選ぶ m だがket9。 それはまだそれに書かれています f(x)

5.そして我々は回帰ラインを持っています。 グラフはまた、その式と相関係数の二乗を示しています

6.チャート名、軸の名前があります。 また、凡例を削除することもでき、水平メッシュライン数を減らすこともできます(タブ レイアウト その後、 グリッド )。 メインの変更と設定はタブで行われます。 レイアウト

回帰回線はMS Excelで構築されています。 今すぐ作業のテキストに追加することができます。
私の意見では、学生として、経済学は私が私の大学の壁に知り合いになることができたすべてのものから最も適用されている科学の1つです。 これを使用すると、実際には、企業全体で適用されたタスクを解決できます。 これらのソリューションの効果的な効果的な問題は、3番目の質問です。 一番下の線は、ほとんどの知識が理論のままであるということですが、経済学や回帰分析は依然として特別な注意を払って勉強する価値があります。
回帰を説明しますか?
MS Excel関数を検討する前に、あなたがこれらのタスクを解決できるようにする前に、本質的に回帰分析を意味するというあなたの指であなたに説明したいと思います。 だからあなたが試験を受けることはあなたが試験を受けることが簡単になり、最も重要なことに、それは主題を研究するのが興味深いです。
数学の関数の概念に精通していることを願っていましょう。 関数は2つの変数の関係です。 1つの変数を変更するときは、もう一方のものが起こります。 xを変更し、それぞれyを変更します。 機能はさまざまな法律を説明しています。 機能を知ることで、xの任意の値を代用してyを見てもらえます。
回帰は、非体系的かつカオス的なプロセスで一目で一目で特定の機能の助けを借りて説明しようとする試みであるため、非常に重要です。 それで、例えば、あなたはロシアのドルと失業の関係を特定することができます。
このパターンが検出された場合は、計算中に受信した機能に従って、ルーブルに関連してN-OHMドル率での失業レベルとなる予測を行うことができます。
この関係は相関と呼ばれます。 回帰分析は相関係数の計算を含み、それは検討中の変数(ドルコースとジョブ数)間の関係の厳しさを説明する。
この係数は正と負にすることができます。 その値は-1から1の範囲にあります。したがって、私たちは高い否定的または正の相関を観察することができます。 それが肯定的であれば、ドルの増加は続き、新しい仕事の出現が続きます。 それが否定的であれば、コースを増やすための仕事の減少があるでしょう。
回帰はいくつかの種です。 それは線形、放物線状、電力、指数関数などです。 どの回帰が私たちの場合に特に満たされるかに応じてモデルの選択をします。このモデルは私たちの相関にできるだけ近くになります。 タスクの例としてこれを考慮し、MS Excelで解決してください。
MS Excelの線形回帰
線形回帰の問題を解決するには、「データ分析」機能が必要になります。 それはあなたに含まれないかもしれないのでそれを有効にする必要があります。
- 「ファイル」ボタンをクリックしてください。
- 項目「パラメータ」を選択してください。
- 左側の「超構造」の最後のタブをクリックしてください。
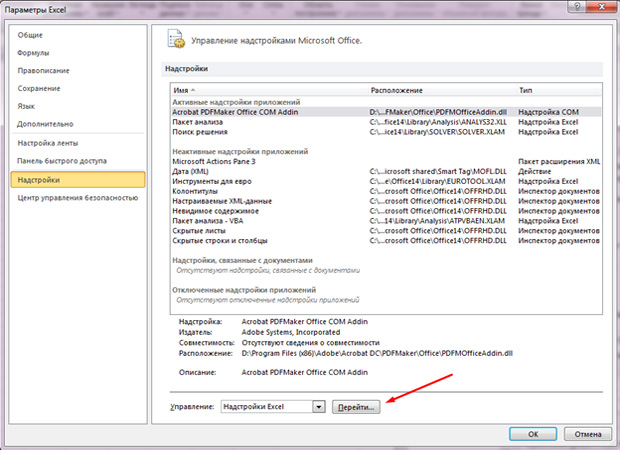
- 下から碑文「管理」と「GO」ボタンが表示されます。 クリックして;
- 「分析パッケージ」にチェックを入れてください。
- 「OK」をクリックしてください。

タスクの例
バッチ分析機能が有効になります。 以下のタスクを使用します。 企業内のPEの数と雇用された労働者数について数年間データのサンプルがあります。 これら2つの変数間の関係を特定する必要があります。 説明変数Xがあります - これは労働者の数であり、説明可能な変数 - yは緊急事態の数です。 送信元データを2列に配布します。

「データ」タブに行き、「データ分析」を選択しましょう。
表示されるリストで、「回帰」を選択してください。 入力間隔YとXでは、対応する値を選択します。
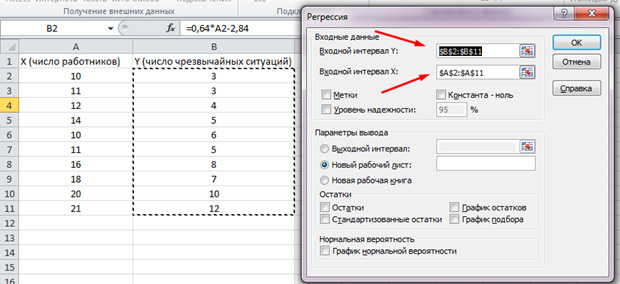
「OK」をクリックしてください。 解析が生成され、新しいシートでは結果がわかります。
私たちにとって最も重要な値は下図のマークされています。

複数のRは判定係数である。 複雑な計算式があり、相関係数を信頼する方法を示します。 したがって、この値が多いほど、信頼できるほど、私たちのモデルは全体として強くなります。
y交差点と交差点X1は私たちの回帰の係数です。 既に述べたように、回帰は関数であり、彼女は特定の係数を持っています。 したがって、私たちの関数は次のように見えます:y \u003d 0.64 * x-2.84。
私たちにそれを与えるのは何ですか? これは私達に予測をする機会を与えます。 私たちは企業上で25の労働者を雇いたいと思うとします、そして、私たちは緊急事態の数がどのようになるかをおおよそ想像する必要があります。 この価値を当社の機能に置き換え、結果Y \u003d 0.64 * 25 - 2.84を取得します。 約13 ppが発生します。
それがどのように機能するか見てみましょう。 下の図面を見てください。 関係する従業員の事実上の値では、事実値が置き換えられます。 本物の娯楽をどのように重要であるかを見てください。

「挿入」タブをクリックしてポイント図を選択して、IPSとICS領域を選択して相関フィールドを構築することもできます。

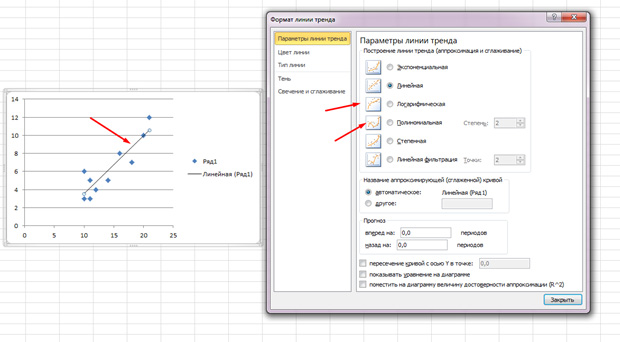
ポイントは角に移動しますが、一般に、ラインが真ん中にあるかのように動きます。 また、MS Excelの[レイアウト]タブをクリックしてトレンドライン項目を選択することで、この行を追加することもできます。
表示された行に沿って2回クリックし、以前に述べられたものを見てください。 相関フィールドのように見える方法に応じて、回帰の種類を変更できます。
おそらく、ポイントがパラボラを描画し、直接回線ではなく、別のタイプの回帰を選択するのに適しているようです。
結論
この記事があなたに回帰分析が必要なのか、そしてそれが必要なものについての理解を深めることを願っていました。 これすべてが大きな適用価値があります。
MS Excelパッケージは、線形回帰方程式の構造を非常に迅速に作動させることを可能にします。 得られた結果をどのように解釈するかを理解することが重要です。
働ければならない 分析パッケージメニュー項目で有効にしたいです サービス\\ add-in.

分析パッケージを有効にするには、Excel 2007では、ブロックをクリックする必要があります。 エクセル設定左上隅のボタンを押してからボタンを押すことによって エクセル設定»ウィンドウ下部にある:

![]()

![]()


回帰モデルを構築するには、項目を選択する必要があります サービス\\ Data Analysis \\ Regression。 (Excel 2007では、このモードはブロック内にあります データ/データ解析/回帰)。 ダイアログボックスが入力されているように見えます。

1) 入力間隔Y ➤パフォーマンスの値を含むセルへのリンクが含まれています y。。 値は列に配置する必要があります。
2) 入力間隔X ④係数の値を含むセルへのリンクを含みます。 値は列に配置する必要があります。
3)符号 タグ 最初のセルに説明テキスト(データシグネチャ)が含まれている場合は発生します。
4) 信頼性レベル ❖これはデフォルトで95%と見なされる信頼確率です。 この値が適していない場合は、この機能を含めて希望の値を入力する必要があります。
5)符号 コンスタンツーゼロ 空き変数が必要な方程式を構成する必要がある場合はオンになります。
6) 出力パラメータ 結果を配置する場所を決定します。 デフォルトのモードはです 新しい作業シート;
7)ブロック 残留物 残余の出力とそれらのグラフの構築を有効にすることができます。
その結果、必要な情報をすべて含み、3つのブロックにグループ化されている情報が表示されます。 回帰統計, 分散解析, 結論残差。 それらをより詳細に考えます。
1. 回帰統計:
複数 r 式によって決定される( ピアソン相関係数);
r  (決定係数);
(決定係数);
norm r-kvadratは式によって計算されます  (複数回帰に使用されます)。
(複数回帰に使用されます)。
標準誤差 s 式によって計算された  ;
;
観測×これはデータ量です n.
2. 分散解析、ライン 回帰:
パラメータ dF。 カラス m (要因のセット数 バツ。);
パラメータ ss。 式によって決定される。
パラメータ MS。 式によって決定される。
統計 f 式によって決定される。
意義 f。 得られた数が超えると仮説が取られ(線形的な関係はない)、そうでなければ仮説が取られる(線形関係がある)。
3. 分散解析、ライン 残基:
パラメータ dF。 等しい;
パラメータ ss。 式が決定されます  ;
;
パラメータ MS。 式によって決定されます。
4. 分散解析、ライン 合計 最初の2列の合計を含みます。
5. 分散解析、ライン y断面 係数、標準エラーの値が含まれています t-統計。
p-notion†は計算に対応する有意性のレベルの値です。 t-統計。 Stouturaspの機能によって決定されます( t-統計; )。 もし p-notionは、対応する変数が統計的に重要ではなく、モデルから除外することができます。
95%低い そして トップ95% ◦これは、線形回帰理論式の係数に対する95パーセント信頼区間の下限および上限です。 データ入力ブロックでは、信頼確率値がデフォルトで残された場合、最後の2列は前のものを複製します。 ユーザーが信頼確率を入力した場合、最後の2列には、指定された信頼確率の場合は下限と上限の値が含まれています。
6. 分散解析、文字列には係数の値、標準エラーの値が含まれています。 t- スタティシスト p- 関連する近似と信頼区間。
7.ブロック 結論残差 予測値が含まれています y。 (私たちの指定で)そして残骸。