Примеры решения регрессии в excel. Математические методы в психологии
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.


Теперь, когда мы перейдем во вкладку «Данные» , на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных» .

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.


Разбор результатов анализа
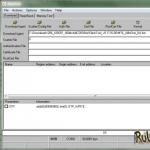
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат . В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты» . Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Построение линейной регрессии, оценивание ее параметров и их значимости можно выполнить значительнее быстрей при использовании пакета анализа Excel (Регрессия). Рассмотрим интерпретацию полученных результатов в общем случае (k объясняющих переменных) по данным примера 3.6.
В таблице регрессионной статистики приводятся значения:
Множественный R – коэффициент множественной корреляции ;
R - квадрат – коэффициент детерминации R 2 ;
Нормированный R - квадрат – скорректированный R 2 с поправкой на число степеней свободы;
Стандартная ошибка – стандартная ошибка регрессии S ;
Наблюдения – число наблюдений n .
В таблице Дисперсионный анализ приведены:
1. Столбец df - число степеней свободы, равное
для строки Регрессия df = k ;
для строкиОстаток df = n – k – 1;
для строкиИтого df = n – 1.
2. Столбец SS – сумма квадратов отклонений, равная
для строки Регрессия ;
для строкиОстаток ;
для строкиИтого .
3. Столбец MS дисперсии, определяемые по формуле MS = SS /df :
для строки Регрессия – факторная дисперсия;
для строкиОстаток – остаточная дисперсия.
4. Столбец F – расчетное значение F -критерия, вычисляемое по формуле
F = MS (регрессия)/MS (остаток).
5. Столбец Значимость F –значение уровня значимости, соответствующее вычисленной F -статистике.
Значимость F = FРАСП(F- статистика, df (регрессия), df (остаток)).
Если значимость F < стандартного уровня значимости, то R 2 статистически значим.
| Коэффи-циенты | Стандартная ошибка | t-cта-тистика | P-значение | Нижние 95% | Верхние 95% | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
В этой таблице указаны:
1. Коэффициенты – значения коэффициентов a , b .
2. Стандартная ошибка –стандартные ошибки коэффициентов регрессии S a , S b .
3. t- статистика – расчетные значения t -критерия, вычисляемые по формуле:
t-статистика = Коэффициенты / Стандартная ошибка.
4.Р -значение (значимость t ) – это значение уровня значимости, соответствующее вычисленной t- статистике.
Р -значение = СТЬЮДРАСП (t -статистика, df (остаток)).
Если Р -значение < стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. Нижние 95% и Верхние 95% – нижние и верхние границы 95 %-ных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии.
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное y | Остатки e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
В таблице ВЫВОД ОСТАТКА указаны:
в столбце Наблюдение – номер наблюдения;
в столбце Предсказанное y – расчетные значения зависимой переменной;
в столбце Остатки e – разница между наблюдаемыми и расчетными значениями зависимой переменной.
Пример 3.6. Имеются данные (усл. ед.) о расходах на питание y и душевого дохода x для девяти групп семей:
| x | |||||||||
| y |
Используя результаты работы пакета анализа Excel (Регрессия), проанализируем зависимость расходов на питание от величины душевого дохода.
Результаты регрессионного анализа принято записывать в виде:
![]()
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Коэффициенты регрессии а = 65,92 и b = 0,107. Направление связи между y и x определяет знак коэффициентарегрессии b = 0,107, т.е. связь является прямой и положительной. Коэффициент b = 0,107 показывает, что при увеличении душевого дохода на 1 усл. ед. расходы на питание увеличиваются на 0,107 усл. ед.
Оценим значимость коэффициентов полученной модели. Значимость коэффициентов (a, b ) проверяется по t -тесту:
Р-значение (a ) = 0,00080 < 0,01 < 0,05
Р-значение (b ) = 0,00016 < 0,01 < 0,05,
следовательно, коэффициенты (a, b ) значимы при 1 %-ном уровне, а тем более при 5 %-ном уровне значимости. Таким образом, коэффициенты регрессии значимы и модель адекватна исходным данным.
Результаты оценивания регрессии совместимы не только с полученными значениями коэффициентов регрессии, но и с некоторым их множеством (доверительным интервалом). С вероятностью 95 % доверительные интервалы для коэффициентов есть (38,16 – 93,68) для a и (0,0728 – 0,142) для b.
Качество модели оценивается коэффициентом детерминации R 2 .
Величина R 2 = 0,884 означает, что фактором душевого дохода можно объяснить 88,4 % вариации (разброса) расходов на питание.
Значимость R 2 проверяется по F- тесту: значимость F = 0,00016 < 0,01 < 0,05, следовательно, R 2 значим при 1 %-ном уровне, а тем более при 5 %-ном уровне значимости.
В случае парной линейной регрессии коэффициент корреляции можно определить как ![]() . Полученное значение коэффициента корреляции свидетельствует, что связь между расходами на питание и душевым доходом очень тесная.
. Полученное значение коэффициента корреляции свидетельствует, что связь между расходами на питание и душевым доходом очень тесная.
R 2 = r xy 2 , где r xy - коэффициент корреляции.
Например, значение R 2 = 0.83, означает, что в 83% случаев изменения х приводят к изменению y . Другими словами, точность подбора уравнения регрессии - высокая.
Рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть больше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
В случае нелинейной регрессии
коэффициент детерминации рассчитывается через этот калькулятор . При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
В общем случае, коэффициент детерминации находится по формуле: или
Правило сложения дисперсий:
,
где - общая сумма квадратов отклонений;
- сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
- остаточная сумма квадратов отклонений.
С помощью данного онлайн-калькулятора рассчитывается коэффициент детерминации и проверяется его значимость (Пример решения).
Инструкция . Укажите количество исходных данных. Полученное решение сохраняется в файле Word . Также автоматически создается шаблон для проверки решения в Excel .
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением

На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по .
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.

Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.

Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.

Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:

Щелкните ОК. На рисунке ниже показаны полученные результаты:

Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .
Известна тем, что она полезна в разных областях деятельности, включая и такую дисциплину, как эконометрика, где в работе используется данная программная утилита. В основном все действия практических и лабораторных занятий выполняют в Excel, которая существенно облегчает работу, давая подробные объяснения тех или иных действий. Так, один из инструментов анализа «Регрессия» применяется с целью подбора графика для набора наблюдений за счет метода наименьших квадратов. Рассмотрим, что представляет собой данный инструмент программы и в чем заключается его польза для пользователей. Ниже также предоставлена краткая, но понятная инструкция построения регрессионной модели.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных. К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.