Excel'de doğrusal bağımlılık. Excel'deki regresyonun temel görevleri: bir model oluşturma örneği
Önceki notlarda, analizin analizi genellikle ayrı bir sayı değişkeni, örneğin, yatırım fonlarının verimi, bir web sayfasını yükleme süresi veya alkolsüz içecek tüketiminin hacmini oluşturur. Şimdiki zamanda ve aşağıdaki notlarda, bir veya daha fazla sayıda sayısal değişkenin değerlerine bağlı olarak sayısal değişken değerlerin tahmin yöntemlerine bakacağız.
Malzeme bir örnek ile gösterilecektir. Giyim mağazasında satış tahmini.Ayçiçeği 25 yıldır indirimli giyim mağazası sürekli genişletti. Ancak, şimdi şirketin yeni çıkışların seçimine sistematik bir yaklaşımı yoktur. Şirketin yeni bir mağaza açacak bir yer, öznel hususlar temelinde belirlenir. Seçim kriterleri uygun kiralama koşulları veya ideal konum yöneticisidir. Özel Projeler ve Planlama Bölümü'nün başı olduğunuzu hayal edin. Yeni mağazaları açmak için stratejik bir plan geliştirmemiz istendi. Bu plan, yeni açılan mağazalarda yıllık satışların tahminini içermelidir. Ticaret alanının doğrudan gelir hacmi ile ilgili olduğuna inanıyorsunuz ve bu gerçeği karar alma sürecinde dikkate almak istiyorsunuz. Yıllık satışları yeni bir mağazanın boyutuna göre tahmin etmenizi sağlayan istatistiksel bir model geliştirilir?
Kural olarak, değişken değerleri tahmin etmek için regresyon analizi kullanılır. Amacı, bağımlı değişkenin değerlerini veya yanıtı, en az bir, bağımsız veya açıklayıcı, değişken değerlerine göre, bağımlı değişkenin değerlerini tahmin etmenizi sağlayan istatistiksel bir model geliştirmektir. Bu notta, basit doğrusal regresyonu - bağımlı değişkenin değerlerini tahmin etmenizi sağlayan istatistiksel bir yöntem olduğunu düşünüyoruz. Y. bağımsız bir değişkenin değerleri ile X.. Sonraki notlarda, bağımsız bir değişkenin değerlerini tahmin etmek için tasarlanmış bir çoklu regresyon modeli açıklanacaktır. Y. birkaç bağımlı değişkenlerin değerleri ile ( X 1, x 2, ..., x k).
Not formatında veya formattaki örnekler indirin
Regresyon Modelleri Türleri
nerede ρ 1 - Otokorelasyon katsayısı; Eğer bir ρ 1 \u003d 0 (otokorelasyon yok), D. ≈ 2; Eğer bir ρ 1 ≈ 1 (pozitif otokorelasyon), D. ≈ 0; Eğer bir ρ 1 \u003d -1 (negatif otokorelasyon), D. ≈ 4.
Uygulamada, Durbin-Watson'ın kriterinin kullanımı karşılaştırmaya dayanmaktadır. D. kritik teorik değerlerle d L. ve d Belirli bir gözlem için n., bağımsız değişken modellerinin sayısı k. (Basit doğrusal regresyon için k. \u003d 1) ve anlamlılık seviyesi α. Eğer bir D.< d L , rastgele sapmaların bağımsızlığıyla ilgili hipotez reddedilir (bu nedenle, pozitif otokorelasyon mevcuttur); Eğer bir D\u003e d u, hipotez reddedilmez (yani, otokorelasyon yoktur); Eğer bir d L.< D < d U Bir karar vermek için yeterli bir gerekçesiniz yoktur. Hesaplanan değerde D. 2'yi aştı, sonra d L. ve d Katsayının kendisini yerine getirmedi D.ve ifadesi (4 - D.).
Excel'deki Durbina-Watson istatistiklerini hesaplamak için, ŞEKİL 2'deki alt tabloya dönüyoruz. on dört Sonuç kalıntısı. (10) ifadesindeki numseratör, fonksiyon \u003d toplayabilir (array1; dizi2) ve DENOUMINATOR \u003d Sumk (dizi) kullanılarak hesaplanır (Şekil 16).

İncir. 16. Durbin-Watson'ın istatistiklerini hesaplamak için formüller
Örneğimize D. \u003d 0.883. Asıl soru şu şekildedir - Durbin-Watson istatistiklerinin anlamı nedir, pozitif otokorelasyonun varlığını sonlandıracak kadar küçük olarak kabul edilmelidir? D değerini kritik değerlerle ilişkilendirmek için gereklidir ( d L.ve D) gözlem sayısına bağlı olarak n. ve anlamlılık seviyesi α (Şekil 17).

İncir. 17. Durbin-Watson İstatistiklerinin Kritik Değerleri (Tablo Fragmanı)
Böylece, mağazadaki satış görevinde, eve mal veren, bir bağımsız değişken vardır ( k. \u003d 1), 15 gözlem ( n. \u003d 15) ve anlamlılık seviyesi α \u003d 0.05. Dolayısıyla d L.\u003d 1.08 I. d. U \u003d 1.36. Gibi D. = 0,883 < d L.\u003d 1.08, artıklar arasında pozitif bir otokorelasyon var, en küçük kareler yöntemi uygulanamaz.
Eğim ve korelasyon katsayısı hakkında hipotezleri kontrol edin
Yukarıda regresyon sadece tahmin için kullanıldı. Regresyon katsayılarını ve değişkenin değerinin tahmini belirlemek Y. Belirli bir değişken değer için X. En az kare yöntemi kullanıldı. Ek olarak, tahminin ortalama kare hatasını ve karışık korelasyon katsayısının olduğunu düşündük. Kalıntıların analizi, en az kareler yönteminin uygulanabilirliği koşullarının ihlal edilmediğini ve basit doğrusal regresyon modelinin yeterli olduğunu doğrularsa, seçici veriler temelinde, değişkenler arasında doğrusal bir bağımlılık olduğu iddia edilebilir. genel popülasyonda.
Uygulamat. -eğim için kriter.Β 1 sıfırının genel kombinasyonunun eğilmesinin, değişkenler arasındaki istatistiksel olarak anlamlı bir ilişkinin olup olmadığını belirlemek mümkün olup olmadığını doğrulayın. X. ve Y.. Bu hipotez saptırırsa, değişkenler arasında olduğu söylenebilir. X. ve Y. Doğrusal bir bağımlılık var. Sıfır ve alternatif hipotezler aşağıdaki gibi formüle edilir: h 0: β 1 \u003d 0 (Doğrusal bağımlılık yok), H1: β 1 ≠ 0 (doğrusal bir bağımlılık var). A-priory t.-Station, seçici eğim ile genel popülasyonun eğiminin varsayımsal değeri arasındaki farkın, eğim tahmininin ortalama kare hatasına bölünmesinin varsayımsal değeridir:
(11) t. = (b. 1 – β 1 ) / S B. 1
nerede b. 1
- Seçici verilere göre doğrudan regresyonun eğimi, β1 doğrudan genel agreganın varsayımsal bir eğimidir, ![]() ve test istatistikleri t. Var t.- S.'nin dağıtılması n - 2. özgürlük derecesi.
ve test istatistikleri t. Var t.- S.'nin dağıtılması n - 2. özgürlük derecesi.
Mağazanın büyüklüğü ile α \u003d 0.05'te yıllık satış hacmi arasında istatistiksel olarak anlamlı bir ilişki olup olmadığını kontrol edin. t.-Criteri, kullanıldığında diğer parametrelerle birlikte görüntülenir. Paket Analizi (Seçenek Regresyon). Tam olarak analiz paketinin analizinin sonuçları, Şekil 2'de gösterilmiştir. Şekil 4, T-istatistiklerine ait bir fragman - Şekil 2'de. onsekiz.
İncir. 18. Başvuru Sonuçları t.
Dükkan sayısından beri n. \u003d 14 (bkz. Şekil 3), Kritik Değer t.- anlamlılık düzeyinde istatistikler α \u003d 0.05 formül tarafından bulunabilir: t l. \u003d Öğrenci. ÜRETİM (0.025; 12) \u003d -2,1788, burada 0.025 anlamlılık seviyesinin yarısıdır ve 12 \u003d n. – 2; t \u003d Öğrenci. Prof (0.975; 12) \u003d +2,1788.
Gibi t.-Station \u003d 10.64\u003e t \u003d 2,1788 (Şekil 19), sıfır hipotez H 0 sapmalar. Diğer yandan, rİçin H. \u003d 10,6411, formül \u003d 1-sade.SP (D3; 12; gerçek) ile hesaplanan, yaklaşık sıfır, böylece hipotez H 0 tekrar reddedildi. Bu gerçeği r- Bir fikir neredeyse sıfıra eşittir, bu, mağazaların büyüklüğü ile yıllık satış hacminin arasında gerçek bir doğrusal bağımlılık yoksa, doğrusal regresyon kullanılarak tespit etmek neredeyse imkansız olur. Sonuç olarak, mağazalardaki ortalama yıllık satış hacmi ile büyüklükleri arasında istatistiksel olarak anlamlı bir doğrusal bağımlılık vardır.

İncir. 19. Genel nüfusun eğilimi hakkındaki hipotezi, 0.05'e eşit, 12 dereceye eşit, 12 dereceye eşittir.
UygulamaF. -eğim için kriter.Basit bir doğrusal regresyonun eğimi ile ilgili hipotezleri kontrol etmek için alternatif bir yaklaşım kullanmaktır. F.-Criteria. Hatırlamak F.-Criteri, iki dispersiyon arasındaki ilişkiyi doğrulamak için kullanılır (daha fazla ayrıntı için, bakınız). Hipotezi eğimle ilgili hipotezi, rastgele hataların bir ölçüsü ile kontrol ederken hata dağılımıdır (serbestlik derecelerinin sayısına bölünmüş hataların karelerinin toplamı), bu nedenle F.-Criteria, regresyon nedeniyle dispersiyon oranını kullanır (yani değerler) SSR.Bağımsız değişken sayısına bölün k.), dispersiyon hatalarına ( Mse \u003d s y X. 2 ).
A-priory F.-Station, regresyonun (MSR) yol açtığı ortalama sapmaların ortalama kare karesine eşittir (MSR) hata dağılımına (MSE): F. = Msr./ MSE.nerede Msr \u003d.SSR. / k., MSE \u003d.Set/(n.- K - 1), K - Regresyon modelinde bağımsız değişkenlerin sayısı. Test istatistikleri F. Var F.- S.'nin dağıtılması k. ve n. - K - 1 özgürlük derecesi.
Belirli bir öneme sahip α düzeyinde, belirleyici kural aşağıdaki gibi formüle edilmiştir: F\u003e F. U, sıfır hipotez sapma; Aksi takdirde, sapmaz. Bir özet dispersiyon analizi tablosu şeklinde dekore edilmiş sonuçlar, Şekil 2'de gösterilmiştir. yirmi.

İncir. 20. Dispersiyon Tablosu Regresyon Katsayısının İstatistiksel Önemi Hakkında Hipotezi Test Etmek İçin
benzer şekilde t.-Criteri F.-Criteri, kullanıldığında tabloda görüntülenir. Paket Analizi (Seçenek Regresyon). Tamamen performans sonuçları Paket Analizi Şekil l'de gösterilmiştir. 4, Fragment ile ilgili F.-Statistik - Şekil 2'de. 21.

İncir. 21. Uygulama sonuçları F.Excel analiz paketi kullanılarak elde edilen kriterler
F-istatistikleri 113.23 ve r-Size sıfıra yakın (hücre) ÖnemF.). Eğer anlamlılık seviyesi α 0.05 ise, kritik değeri belirleyin F.Bir ve 12 derecelik özgürlük ile dağıtım formülü kullanıyor olabilir F u \u003d F. ÜRETİM (1-0.05; 1; 12) \u003d 4,7472 (Şekil 22). Gibi F. = 113,23 > F u \u003d 4,7472 ve r0 0'a yakın< 0,05, нулевая гипотеза H 0 sapmalar, yani. Mağazanın büyüklüğü yıllık satışlarıyla yakından ilgilidir.

İncir. 22. Genel nüfusun eğilimi ile ilgili hipotezi, bir ve 12 derecelik özgürlük ile 0,05'e eşit, 0.05'e eşittir.
Β 1'in eğimini içeren güven aralığı. Değişkenler arasındaki doğrusal bir ilişkinin varlığındaki hipotezi test etmek için, β 1'in eğimini içeren bir güven aralığı yapılabilir ve β 1 \u003d 0'un varsayımsal değerinin bu aralığa ait olduğundan emin olabilirsiniz. Β 1'in eğimini içeren güven aralığının merkezi seçici eğimdir b. 1 ve ve sınırları - değerler b1 ±t N. –2 S B. 1
Şekil l'de gösterildiği gibi. onsekiz, b. 1 = +1,670, n. = 14, S B. 1 = 0,157. t. 12 \u003d Öğrenci. PROF (0.975; 12) \u003d 2,1788. Dolayısıyla b1 ±t N. –2 S B. 1 \u003d +1,670 ± 2,1788 * 0.157 \u003d +1,670 ± 0.342 veya + 1,328 ≤ β 1 ≤ +2,012. Böylece, genel nüfusun 0.95 olasılıkla eğimi +1.328 ila +2.012 (yani 1.268.000 ila 2.012.000 $) arasında değişmektedir. Bu miktarlar sıfırdan daha büyük olduğundan, yıllık satış hacmi ve mağaza alanı arasında istatistiksel olarak anlamlı bir doğrusal bağımlılık var. Güven aralığı sıfır içeriyorsa, değişkenler arasında bir bağımlılık olmaz. Ek olarak, güven aralığı, mağaza alanındaki her artışın 1.000 metrekarelik olduğu anlamına gelir. Ayaklar, ortalama satışlarda 1.328.000 ila 2,012.000 ABD Doları arasında bir artışa yol açar.
Kullanmat. Korelasyon katsayısı için kriterler. Korelasyon katsayısı tanıtıldı r., iki sayısal değişken arasındaki ilişkinin bir ölçüsünü temsil eder. Bununla birlikte, iki değişken arasında istatistiksel olarak anlamlı bir bağlantı olup olmadığını yükleyebilirsiniz. Her iki değişkenin genel ayarları arasındaki korelasyon katsayısını ρ sembolü ile belirtir. Sıfır ve alternatif hipotezler aşağıdaki gibi formüle edilir: H 0: ρ \u003d 0 (korelasyon yok), H 1.: ρ ≠ 0 (bir korelasyon var). Korelasyonun varlığını kontrol etme:

nerede r. = + , Eğer bir b. 1 > 0, r. = – , Eğer bir b. 1 < 0. Тестовая статистика t. Var t.- S.'nin dağıtılması n - 2. özgürlük derecesi.
Ağın görevinde ayçiçeği r 2. \u003d 0.904 ve b 1.- +1,670 (bkz. Şekil 4). Gibi b 1. \u003e 0, yıllık satışlar arasındaki korelasyon katsayısı ve mağazanın büyüklüğü eşittir r. \u003d + √0.904 \u003d +0,951. Kullanarak bu değişkenler arasında korelasyon olmadığını savunan sıfır hipotezi kontrol edin. t.-İstatistik:

Anlamlılık düzeyinde α \u003d 0.05 sıfır hipotez reddedilmelidir çünkü t. \u003d 10.64\u003e 2,1788. Böylece, yıllık satış hacmi ile mağazanın büyüklüğü arasında istatistiksel olarak anlamlı bir bağlantı olduğu söylenebilir.
Genel nüfusun eğimiyle ilgili sonuçları tartışırken, hipotezleri test etmek için güven aralıkları ve kriterleri değiştirilebilir araçlardır. Bununla birlikte, korelasyon katsayısını içeren güven aralığının hesaplanması, seçici istatistik dağıtımının türünden bu yana daha karmaşıktır. r. Gerçek korelasyon katsayısına bağlıdır.
Matematiksel beklenti ve bireysel değerlerin tahmini değerlendirilmesi
Bu bölüm, cevabın matematiksel beklentisini değerlendirme yöntemlerini tartışmaktadır. Y. ve bireysel değerlerin tahminleri Y. değişkenin belirtilen değerlerinde X..
Gizli bir aralık oluşturmak.Örnek 2'de (Bkz. Bölümüne bakınız. En az kare yöntemi) Regresyon denklemi değişkenin değerini tahmin etmeyi mümkün kıldı Y. X.. Trafik noktası için bir yer seçme görevinde, 4000 metrekarelik bir dükkanda ortalama yıllık satışlar. Ayaklar 7.644 milyon dolara eşitti. Ancak, genel nüfusun matematiksel beklentisinin bu değerlendirmesi noktasıdır. Genel nüfusun matematiksel beklentisini değerlendirmek için, gizli bir aralık kavramı önerildi. Benzer şekilde, kavramı girebilirsiniz matematiksel yanıt beklentisi için güven aralığı Belirli bir değişken değeri ile X.:
nerede  , =
b. 0
+
b. 1
X I. - Tahmin edilen değer değişkeni Y. için X. = X I., S yx. - radan hatası, n. - örnekleme hacmi X. BEN. - Değişkenin belirtilen değeri X., µ
Y.| X. =
X. BEN. - Matematiksel Bekleme Değişkeni Y. için H. = X I., SSX \u003d.
, =
b. 0
+
b. 1
X I. - Tahmin edilen değer değişkeni Y. için X. = X I., S yx. - radan hatası, n. - örnekleme hacmi X. BEN. - Değişkenin belirtilen değeri X., µ
Y.| X. =
X. BEN. - Matematiksel Bekleme Değişkeni Y. için H. = X I., SSX \u003d. 
Formül (13) analizi, güven aralığının genişliğinin birkaç faktöre bağlı olduğunu göstermektedir. Belirli bir anlamlılık düzeyinde, standart hata kullanılarak ölçülen regresyon çizgisi çevresindeki salınımların genliğini arttırmak, aralığın genişliğinde bir artışa yol açar. Öte yandan, beklendiği gibi, örneğin boyutunda bir artış aralığın daralması ile birliktedir. Ek olarak, aralığın genişliği değerlere bağlı olarak değişir. X. BEN.. Değişkenin değeri ise Y. büyüklük için tahmin edildi X.Ortalama değere yakın Güven aralığı, ortalamadan uzak değerlerin tepkisini tahmin ederken zaten mevcuttur.
Diyelim ki, mağaza için bir yer seçerek, bölgedeki tüm mağazalardaki ortalama yıllık satışlar için% 95 güven aralığı oluşturmak istiyoruz. Ayak:

Sonuç olarak, alanı 4.000 metrekare olan tüm mağazalarda yıllık ortalama satışlar. Ayak,% 95 olasılıkla 6.971'den 8.317 milyon dolar arasında değişiyor.
Öngörülen değer için güven aralığını hesaplamak.Matematiksel yanıt için güven aralığına ek olarak, belirli bir değişken değeri ile X.Öngörülen değer için güven aralığını bilmek genellikle gereklidir. Böyle bir güven aralığını hesaplamak için formülün formül (13) 'e çok benzer olmasına rağmen, bu aralık öngörülen değer içerir ve parametrenin bir tahmini değildir. Tahmin edilen cevap için aralık Y. X. = Xi Belirli bir değişken değeri ile X. BEN. Formül tarafından belirlenir:

Diyelim ki, bir trafik noktası için bir yer seçtiğimizde, bölge, bölgedeki öngörülen yıllık satışlar için% 95 güven aralığı oluşturmak istiyoruz. Ayak:

Sonuç olarak, bölgede, bölgedeki yıllık satışların 4000 m2'dir. Ayak,% 95 olasılıkla 5.433 - 9.854 milyon dolar arasında değişiyor. Gördüğümüz gibi, öngörülen yanıt değerinin güven aralığı, matematiksel beklentisi için güven aralığından çok daha geniş. Bu, bireysel değerlerin öngörülmesinde değişkenliğin matematiksel beklentiyi değerlendirirken çok daha büyük olduğu açıklanmaktadır.
Sualtı taşları ve regresyonla ilgili etik problemler
Regresyon Analizi ile İlişkili Zorluklar:
- En az kareler yönteminin uygulanabilirliğinin koşullarını görmezden gelmek.
- En az kareler yönteminin uygulanabilirliğinin koşullarının hata değerlendirmesi.
- En az kareler yönteminin uygulanabilirliğinin koşullarını ihlal etmede alternatif yöntemlerin yanlış seçimi.
- Çalışmanın konusu hakkında derin bilgi olmadan regresyon analizinin uygulanması.
- Açıklayıcı değişkendeki değişikliklerin ötesinde regresyonun ekstrapolasyonu.
- İstatistiksel ve nedensel bağımlılıklar arasında karışıklık.
Elektronik tabloların ve yazılımın istatistiksel hesaplamalar için yaygın yayılımı, regresyon analizinin uygulanmasını engelleyen hesaplamalı problemleri ortadan kaldırdı. Bununla birlikte, bu, regresyon analizinin yeterli niteliklere ve bilgiye sahip olmayan kullanıcıları uygulamaya başlamasına yol açmıştır. Kullanıcılar, alternatif yöntemler hakkında ne biliyorsa, çoğu, en küçük kareler yönteminin uygulanabilirliğinin en ufak bir kavramına sahip değilse ve yürütmelerinin nasıl kontrol edileceğini bilmiyorlarsa?
Araştırmacı, sayıların öğütülmesi ile taşınmamalıdır - kayma, eğim ve karışık korelasyon katsayısının hesaplanması. Daha derin bilgiye ihtiyacı var. Bunu, ders kitaplarından alınan klasik bir örnekle gösteriyoruz. Ansky, Şekil 2'de gösterilen dört veri kümesinin tümünü gösterdi. 23, aynı regresyon parametrelerine sahiptir (Şekil 24).

İncir. 23. Dört yapay veri kümesi

İncir. 24. Dört yapay veri kümesinin regresyon analizi; Yardım ile yapılan Paket Analizi(Resmi büyütmek için resme tıklayın)
Bu nedenle, regresyon analizi açısından, tüm bu veri setleri tamamen aynıdır. Analiz tamamlandıysa, çok fazla yararlı bilgi kaybederiz. Bu, bu veri setleri için inşa edilen, dağılım diyagramları (Şekil 25) ve artık grafikler (Şekil 26) tarafından kanıtlanır.

İncir. 25. Dört veri seti için dağılım diyagramları
Saçılma diyagramları ve artıkların programları, bu verilerin birbirinden farklı olduğunu göstermektedir. Düz çizgi boyunca dağıtılan tek ayar, A SET A ile hesaplanan kalıntıların bir takvimi bir dizidir. Bu, B, B ve G setleri hakkında söylenemez. SET B, B, B, B, B üzerine kurulu olan Scatter programı, belirgin bir ikinci dereceden model gösterir. Bu sonuç, parabolik bir şekle sahip artıkların takvimi ile doğrulanır. Saçak diyagramı ve artık takvimi, veri setinin emisyonları içerdiğini göstermektedir. Bu durumda, emisyonu bir veri kümesinden dışlamak ve analizi tekrarlamak gerekir. Gözlemlerden kaynaklanan emisyonları tespit etmesine ve dışlamaya izin veren yöntem, etki analizi denir. Emisyon hariçten sonra, modelin yeniden değerlendirilmesinin sonucu tamamen farklı olabilir. Bir setten verilere göre inşa edilen dağılım diyagramı, ampirik modelin ayrı bir yanıtta önemli ölçüde bağlı olduğu sıradışı bir durumu göstermektedir ( X 8. = 19, Y. 8 \u003d 12.5). Bu tür regresyon modelleri özellikle dikkatlice hesaplanmalıdır. Bu nedenle, saçılma ve kalıntı programları, regresyon analizi için son derece gerekli bir araçtır ve ayrılmaz bir parça olmalıdır. Onlarsız, regresyon analizi güven duymaz.

İncir. 26. Dört veri kümesi için artıkların programları
Regresyon Analizi ile Sualtı Taşları Nasıl Kaçınılır:
- Değişkenler arasındaki olası ilişkinin analizi X. ve Y. Daima Scatter Diyagramının yapımıyla başlayın.
- Regresyon analiz sonuçlarını yorumlamadan önce, uygulanabilirliğinin koşullarını kontrol edin.
- Kalıntıların bağımsız bir değişkenden bağımlılığının bir grafiğini oluşturun. Bu, ampirik modelin gözlem sonuçlarını nasıl karşıladığını ve dispersiyon dağılımını tespit etmeyi belirler.
- Normal hata dağılımının varsayımını doğrulamak için, histogramları, "gövde ve yapraklar", blok diyagramları ve normal dağılım çizelgelerini kullanın.
- En küçük kareler yönteminin uygulanabilirlik koşulları gerçekleştirilmezse, alternatif yöntemler kullanın (örneğin, ikinci dereceden veya çoklu regresyon modeli).
- En küçük kareler yönteminin uygulanabilirlik koşulları yapılırsa, regresyon katsayılarının istatistiksel olarak önemi üzerindeki hipotezi test etmek ve matematiksel beklentiyi ve öngörülen yanıt değerini içeren güven aralıkları oluşturulması gerekir.
- Bağımsız değişkenin bağımsız bir değişkendeki değişikliklerin dışındaki değerlerini tahmin etmekten kaçının.
- İstatistiksel bağımlılıkların her zaman nedensel olmadığını unutmayın. Değişkenler arasındaki korelasyonun, aralarında herhangi bir nedensel bağımlılık anlamına gelmediğini unutmayın.
Özet.Yapısal şemada gösterildiği gibi (Şekil 27), bir not, basit bir doğrusal regresyon modelini, uygulanabilirliğinin koşullarını ve bu koşulları kontrol etme yöntemlerini açıklar. Düşünülen t.-Criteria Regresyon eğiliminin istatistiksel önemini doğrulamak için. Bağımlı değişkenin değerlerini tahmin etmek için bir regresyon modeli kullanılmıştır. Yıllık satış hacminin mağaza alanından bağımlılığını inceleyen ticaret noktası için yer seçimi ile ilişkili örnek incelenmiştir. Alınan bilgiler, mağaza için daha doğru bir yer seçmenize ve yıllık satışlarını tahmin etmenizi sağlar. Aşağıdaki notlar regresyon analizini tartışmaya devam edecek ve çoklu regresyon modelleri de dikkate alınacaktır.

İncir. 27. Yapısal şema notları
Kitabın Malzemeleri Levin ve ark. Yöneticiler için istatistikler. - M.: Williams, 2004. - ile. 792-872.
Bağımlı değişken kategorik ise, lojistik regresyon uygulamak gerekir.
Regresyon analizi, istatistiksel araştırmaların en çok aranan yöntemlerinden biridir. Bununla birlikte, bağımsız değerlerin bağımlı değişken üzerindeki etkisinin derecesini belirlemek mümkündür. Microsoft Excel işlevselliğinin benzer bir analiz türü için tasarlanmış araçlara sahiptir. Kendilerini temsil ettiklerini ve nasıl kullanılacağını analiz edelim.
Analiz paketini bağlamak
Ancak, bir regresyon analizi yapmanıza izin veren bir işlevi kullanmak için, her şeyden önce, analiz paketini etkinleştirmeniz gerekir. Ancak, bu prosedür için gereken araçlar sürgün bandında görünecektir.
- "Dosya" sekmesine gidin.
- "Parametreler" bölümüne gidin.
- Excel parametreleri penceresi açılır. "Addstahure" alt bölümüne gidin.
- Açılış penceresinin alt kısmında, başka bir konumdaysa, "kontrol" bloğundaki düğmeyi "Excel eklentisi" konumuna yeniden düzenleriz. "GO düğmesine" tıklayın.
- Excel'in üst yapısına erişilebilen pencereye açıldı. "Analiz Paketi" öğesi hakkında bir kene koyduk. "Tamam" düğmesine tıklayın.

Şimdi, "Veri" sekmesine geçtiğimizde, "Analiz" araç çubuğu, "Veri Analizi" düğmesinde yeni bir düğme göreceğiz.

Regresyon Analizi Türleri
Birkaç çeşit regresyon vardır:
- parabolik;
- güç;
- logaritmik;
- Üstel;
- gösterge;
- hiperbolik;
- doğrusal regresyon.
Excele'deki son regresyon analizinin uygulanması hakkında daha fazla konuşacağız.
Excel programında doğrusal regresyon
Örnek olarak, bir örnek olarak, sokaktaki ortalama günlük hava sıcaklığının ve uygun iş günü için dükkan alıcılarının sayısının belirtildiği bir tablo sunulmuştur. Regresyon analizi yardımıyla, hava sıcaklığı şeklindeki hava koşullarının ticari kurumun katılımını tam olarak nasıl etkileyebileceğini öğrenelim.
Doğrusal türlerin regresyonunun genel denklemi aşağıdaki gibidir: Y \u003d A0 + A1X1 + ... + AKK. Bu formülde Y, keşfetmeye çalıştığımız faktörlerin etkisi olan bir değişken anlamına gelir. Bizim durumumuzda, bu alıcı sayısıdır. X'in değeri değişkeni etkileyen çeşitli faktörlerdir. Parametreler A katsayılar regresyonudur. Yani, belirli bir faktörün önemini belirleyenlerdir. K endeksinin bu faktörlerin toplam sayısını belirtir.


Analiz sonuçlarının analizi
Regresyon analizinin sonuçları, ayarlarda belirtilen yerde bir tablo biçiminde görüntülenir.

Ana göstergelerden biri R-Meydanıdır. Modelin kalitesini gösterir. Bizim durumumuzda, bu katsayı 0.705 veya yaklaşık% 70.5'dir. Bu kabul edilebilir bir kalite seviyesidir. 0,5'ten az bağımlılık kötüdür.
Bir diğer önemli gösterge, "Y)" Y-Kavşağı "hattının ve" katsayılar "sütununun kesişiminde hücrede bulunur. Hangi değerin Y'de olacağını gösterir ve bizim durumumuzda, bu, tüm diğer faktörler sıfıra eşit olan alıcı sayısıdır. Bu tablo bu tabloda 58.04'tür.
Sayımın "değişkeni X1" ve "katsayılarının" kesişimindeki değeri, Y'dan y'nin bağımlılığı seviyesini göstermektedir. Bizim durumumuzda, Mağazanın Müşteri sayısının sıcaklıktaki sayısının bağımlılığı seviyesidir. 1.31 katsayısı oldukça yüksek bir etki göstergesi olarak kabul edilir.
Gördüğünüz gibi, Microsoft Excel programını kullanarak regresyon analizi tablosu yapmak oldukça kolaydır. Ancak, çıkışta elde edilen verilerle çalışmak ve özlerini anlamak için, yalnızca hazırlanmış bir insan yapabilecektir.
Sorunu çözmenize yardımcı olabileceğiniz için mutluyuz.
Sorununun özünü ayrıntılı olarak oynarken, sorunuzu yorumlarınızı sorunuz. Uzmanlarımız mümkün olduğunca çabuk cevap vermeye çalışacaktır.
Bu makale size yardımcı olacak mı?
Doğrusal regresyon yöntemi, doğrudan satırı, en uygun sayıda buhar (X, Y) tanımlamamızı sağlar. Doğrusal denklem olarak bilinen düz bir çizgi için denklem aşağıda sunulur:
ŷ - Belirli bir değerde beklenen değeri,
x bağımsız bir değişkendir,
a - Y ekseni üzerinde düz bir çizgi için kesilmiş,
b - düz çizgi eğim.
Aşağıdaki şekilde, bu kavram grafiksel olarak gösterilir:
Yukarıdaki şekil, ŷ \u003d 2 + 0.5x denklemi ile tarif edilen çizgiyi göstermektedir. Eksen ekseni üzerindeki segment, eksen ekseninin kesişme noktasıdır; Bizim durumumuzda, A \u003d 2. Çizginin eğimi, B, kaldırma hattının çizginin uzunluğuna oranı, 0.5'tir. Olumlu bir eğim, çizginin soldan sağa yükseldiği anlamına gelir. Eğer b \u003d 0 ise, yatay çizgi ise, bağımlı ve bağımsız değişkenler arasında bağlantı olmadığı anlamına gelir. Başka bir deyişle, X değerindeki değişiklik Y'nin değerini etkilemez.
Sık sık karıştı ŷ ve y. Grafik, bu denklem uyarınca 6 sipariş edilen nokta ve bir çizgi işaret etti.
Bu şekilde, sipariş edilen bir çifte x \u003d 2 ve y \u003d 4. bir noktaya karşılık gelen bir noktayı göstermektedir. Y'nin beklenen değerinin, hatta h. \u003d 2 ŷ. Bunu aşağıdaki denklemi kullanarak onaylayabiliriz:
ŷ \u003d 2 + 0.5x \u003d 2 +0.5 (2) \u003d 3.
Y'nin değeri gerçek nokta ve ŷ değeri, belirli bir değer x için lineer bir denklem kullanılarak beklenen y değeridir.
Bir sonraki adım, doğrusal denklemi belirlemek, sipariş edilen buhar kümesine karşılık gelen maksimum, önceki makalenin, en az kareler yöntemine göre denklemin formunun belirlendiği önceki makalede konuştuk.
Doğrusal regresyonu belirlemek için Excel'i kullanmak
Excel'e gömülü regresyon analizi aracını kullanmak için eklentiyi etkinleştirmeniz gerekir. Analiz Paketi. Sekmeyi tıklatarak bulabilirsiniz Dosya -\u003e Parametreler(2007+), diyalog görüntülenen iletişim kutusunda ParametrelerExcelsekmeye git Üst yapıAlanda Kontrolseç Üst yapıExcelve tıklayın GitGörünen pencerede, karşısında bir kene koyduk Analiz Paketizhmem. TAMAM MI.
Sekmede Verigrup içinde Analizyeni bir düğme belirir Veri analizi.
Eklentinin çalışmalarını göstermek için, verileri adamın ve kızın banyodaki bir masayı paylaşacağı önceki makaleden kullanıyoruz. Örneğimizin verilerini a ve temiz bir tabakada bir banyo ile girin.
Sekmeye git Veri,grup içinde Analiztıklayın Veri analizi.Görünen pencerede Veri analizi Seç Regresyon, Şekilde gösterildiği gibi ve Tamam'ı tıklatın.
Pencerede gerekli regresyon parametrelerini takın Regresyon, resimde gösterildiği gibi:
Tıklayın TAMAM MI.Aşağıdaki şekil, elde edilen sonuçları göstermektedir:
Bu sonuçlar, önceki makalede bağımsız hesaplama ile aldığımız kişilere karşılık gelir.
Regresyon analizi, bir parametrenin bir veya birkaç bağımsız değişkenden bağımlılığını gösteren istatistiksel bir araştırma yöntemidir. Uygulamanın, özellikle büyük miktarda veri ile ilgili olsaydı, bir Compuscript döneminde kullanmak zordu. Bugün, Excel'de regresyon yapmayı öğrenmek, karmaşık istatistiksel görevleri tam anlamıyla birkaç dakika içinde çözebilirsiniz. Aşağıda ekonomi alanından somut örneklerdir.
Regresyon Türleri
Bu konseptin kendisi 1886'da Matematik Francis Galton'a tanıtıldı. Regresyon olur:
- doğrusal;
- parabolik;
- güç;
- Üstel;
- hiperbolik;
- gösterge;
- logaritmik.
Örnek 1.
Ekibin üyelerini 6 sanayi işletmesinde ortalama maaştan söndürenlerin sayısının bağımlılığını belirleme görevini göz önünde bulundurun.
Bir görev. Altı işletmenin ortalama aylık ücretini ve kendi istekleriyle istifa eden çalışanların sayısını analiz etti. Tablo halinde biz var:
6 işletmedeki ortalama maaştan boğulmuş olan işçiler miktarının bağımlılığını belirleme görevi için, regresyon modeli, Y \u003d A0 + A1 × 1 + ... + AKXK, burada Xi Etkileyen Değişkenleri, AI - regresyon katsayıları, AK, faktörlerin sayısıdır.
Bu görev için Y, çalışanları kavga edenlerin ve etkilenen faktörün bir göstergesidir - X'in X tarafından belirtildiği maaş.
"Excel" masa işlemcisinin yeteneklerini kullanma
Excel'deki regresyon analizi, yerleşik fonksiyonların mevcut tablo verilerine başvurudan önce gelmelidir. Bununla birlikte, bu amaçlar için çok yararlı bir üst yapı "analiz paketi" kullanmak daha iyidir. Etkinleştirmek için, ihtiyacınız:
- dosya sekmesinden, "Parametreler" bölümüne gidin;
- açılan pencerede "Üst Yapı" dizesini seçin;
- aşağıdaki "Yönetim" sağındaki "GO Button" düğmesine tıklayın;
- "Analiz Paketi" adının yanındaki bir kene koyun ve Tamam'ı tıklatarak eylemlerinizi onaylayın.
Her şey doğru şekilde yapılırsa, "Verilerin" sekmesinin sağ tarafında, "Excel" iş istasyonunun üstünde bulunan, istediğiniz düğme görünecektir.
Excel'de doğrusal regresyon
Şimdi, ekonometrik hesaplamaların uygulanması için gerekli tüm sanal araçlara sahip olduğunuzda, görevimizi çözmeye devam edebiliriz. Bunun için:
- "Veri Analizi" düğmesine tıklayın;
- açılan pencerede, "Regresyon" düğmesine tıklayın;
- görünen sekmede, Y (kaldırılmış çalışanların sayısı) ve X (maaşları) için değer aralığını giriyoruz;
- "OK" düğmesine basarak eylemlerinizi onaylayın.
Sonuç olarak, program otomatik olarak yeni bir tablo işlemcisini regresyon analizi verileriyle doldurur. Not! Excel, bu amaç için tercih ettiğiniz yere bağımsız olarak sorma yeteneğine sahiptir. Örneğin, değerlerin Y ve X olduğu ve hatta bu tür verileri depolamak için özel olarak tasarlanmış yeni bir kitap olduğu aynı sayfa olabilir.
R-kare için regresyon sonuçlarının analizi
Excel'de, dikkate alınan verilerin işlenmesi sırasında elde edilen veriler şunlar gibi görünüyor:
Her şeyden önce, R-Meydanın değerine dikkat etmelisiniz. Bu belirleme katsayısıdır. Bu örnekte, R-kare \u003d 0.755 (% 75.5), yani modelin hesaplanan parametreleri, dikkate alınan parametreler arasındaki ilişkiyi% 75,5 oranında açıklamaktadır. Belirleme katsayısının değeri ne kadar yüksek olursa, seçilen model belirli bir görev için daha uygulanabilir. Gerçek durumu, 0.8'in üzerindeki R-Meydanın değeri ile doğru şekilde tanımladığına inanılmaktadır. Eğer R-kare TKR ise, lineer denklemin serbest elemanının önemsizliğinin hipotezi reddedilir.
Ücretsiz bir üye için dikkate alınan problemde, "Excel" araçlarını kullanarak, T \u003d 169,20903 ve p \u003d 2.89E-12'nin, yani ücretsiz bir önemsizliğin doğru hipotezinin, yani sıfır olasılığımızı sağladı. Üye reddedilecektir. Bilinmeyen bir t \u003d 5,79405 ve p \u003d 0.001158 katsayısı için. Başka bir deyişle, katsayının önemsizliğinin doğru hipotezinin bilinmeyen bir şekilde reddedilmesi olasılığı% 0.12'dir.
Böylece, doğrusal regresyonun ortaya çıkan denkleminin yeterince olduğuna dair tartışılabilir.
Bir paket paketi satın alma fizibilitesi üzerinde görev
Excel'de çoklu regresyon, tüm "veri analizi" aracı kullanılarak gerçekleştirilir. Belirli bir uygulamalı görevi düşünün.
Yönetim Şirketi "NNN", MMM JSC'de% 20 hisseye göre% 20 hisseyi almanın fizibilitesine karar vermelidir. Paketin (SP) maliyeti 70 milyon ABD dolarıdır. "NNN" uzmanları benzer işlemlerde verileri topladı. Milyonlarca Amerikan Doları cinsinden ifade edilen bu tür parametrelerde bir hisse maliyetini değerlendirmeye karar verildi:
- ödenecek hesaplar (VK);
- yıllık ciro (VO) hacmi;
- alacaklar (VD);
- sabit varlıkların maliyeti (SOF).
Buna ek olarak, ücret işletmesinin (V3 P) binlerce dolar cinsinden yerleşimi kullanılıyor.
Bir masa işlemcisi için çözüm araçları Excel
Her şeyden önce, kaynak veri tablosu yapmanız gerekir. Aşağıdaki forma sahiptir:
- "Veri Analizi" penceresini arayın;
- "Regresyon" bölümünü seçin;
- "Giriş Aralığı Y" penceresinde, G'nin sütundan bağımlı değişkenlerin bir dizi değeri tanıtılır;
- "Giriş Aralığı X" penceresinin sağındaki kırmızı bir okla simgeye tıklayın ve B, C, D, F sütunlarından tüm değerlerin aralığını tahsis edin.
"Yeni çalışma listesi" öğesi ve "Tamam" ı tıklayın.
Bu görev için analiz al.
Sonuçlar ve sonuçların incelenmesi
Yukarıda sunulan yuvarlatılmış verilerden "topla", bir masa işlemcisi Excel'in bir sayfasında, regresyon denklemi:
SP \u003d 0.103 * SOF + 0.541 * VO - 0.031 * VK + 0.405 * VD + 0.691 * VZP - 265,844.
Daha tanıdık bir matematiksel formda, şu şekilde yazılabilir:
y \u003d 0.103 * x1 + 0,541 * x2 - 0.031 * x3 + 0,405 * x4 + 0,691 * x5 - 265,844
MMM JSC'nin verileri tabloda sunulmuştur:
Regresyon denklemine yerleştirmek, 64.72 milyon ABD doları bir rakam alırlar. Bu, MMM JSC'nin paylarının satın alınmaması gerektiği anlamına gelir, çünkü 70 milyon ABD doları maliyetleri yeterince fazla tahmin edilmektedir.
Gördüğümüz gibi, "Excel" masa işlemcisinin kullanımı ve regresyon denklemleri, tamamen belirli bir işlemin fizibilitesine ilişkin makul bir kararın alınmasını mümkün kıldı.
Şimdi regresyonun ne olduğunu biliyorsun. Yukarıda tartışılan Excel örnekler, ekonometri alanından pratik görevleri çözmenize yardımcı olacaktır.
MS Excel paketi, işlerin çoğunu çok hızlı bir şekilde doğrusal bir regresyon denkleminin yapımına izin verir. Elde edilen sonuçları nasıl yorumlayacağınızı anlamak önemlidir. Bir regresyon modeli oluşturmak için, Service \\ Veri Analizi \\ Regresyon'u seçmelisiniz (Excel 2007'de bu mod veri / veri analizi birimi / regresyonunda). Daha sonra sonuçlar analiz birimine kopyalanır.

Bence, bir öğrenci olarak, ekonometrik, üniversitemdeki duvarlarında tanışmayı başardığım her şeyden en uygulanan bilimlerden biri. Bununla birlikte, aslında, uygulamalı görevleri işletme boyunca çözebilirsiniz. Bu çözümler ne kadar etkili olacaktır - üçüncü soru. Alt çizgi, bilginin çoğunun teori kalacağıdır, ancak ekonometri ve regresyon analizi hala özel dikkat ile çalışmaya değer.
Regresyonu açıklar?
MS Excel işlevlerini göz önünde bulundurmaya devam etmeden önce, bu görevleri çözmenize izin vererek, size, özünde, regresyon analizini ima eden parmaklarınızda açıklamak istiyorum. Bu yüzden sınava girmeniz daha kolay olacak ve en önemlisi, konuyu incelemek daha ilginçtir.
Umarım matematiğin bir fonksiyonu kavramına aşina olursunuz. İşlev, iki değişkenin ilişkisidir. Bir değişkeni değiştirirken, diğerinde bir şey olur. X değiştir, sırasıyla Y'yi değiştirir. İşlevler çeşitli yasaları tanımlar. Bir işlevi bilmek, x'in keyfi değerlerini değiştirebiliriz ve nasıl y'ye bakabiliriz.
Çok önemlidir, çünkü regresyon, sistematik olmayan ve kaotik süreçlerle ilk bakışta belirli bir fonksiyonun yardımıyla açıklama girişimidir. Bu nedenle, örneğin, Rusya'daki dolar ve işsizliğin ilişkisini tanımlayabilirsiniz.
Bu model tespit edilirse, hesaplamalar sırasında aldığımız işleve göre, Ruble ile ilgili olarak N-Ohm dolar oranındaki işsizlik düzeyi olacak bir tahmin yapabilecektir.
Bu ilişki korelasyon denir. Regresyon analizi, göz önünde bulundurulan değişkenler (dolar dersleri ve iş sayısı) arasındaki ilişkinin sıkılığını açıklayacak olan korelasyon katsayısının hesaplanmasını içerir.
Bu katsayı olumlu ve olumsuz olabilir. Değerleri -1 ile 1 arasında değişmektedir. Buna göre, yüksek bir negatif veya pozitif korelasyon gözlemleyebiliriz. Eğer pozitif ise, dolardaki artış takip edecek ve yeni işlerin ortaya çıkışı. Olumsuzsa, o zaman kursu artırmak için işlerde bir düşüş olacaktır.
Regresyon birkaç türdür. Doğrusal, parabolik, güç, üstel, vb. Hangi gerilemeye bağlı olarak hangi gerilemeyeceğine bağlı olarak model seçimi yapacağız, hangi modelin korelasyonumuza mümkün olduğu kadar yakın olacaktır. Bunu görevin örneğinde düşünün ve MS Excel'de çözün.
MS Excel'de Doğrusal Regresyon
Doğrusal regresyon problemlerini çözmek için, bir "veri analizi" işlevselliğine ihtiyacınız olacaktır. Size dahil olmayabilir, böylece etkinleştirmeniz gerekir.
- "Dosya" düğmesine tıklayın;
- "Parametreler" öğesini seçin;
- Sol taraftaki "Üst Yapı" nın son sekmesine tıklayın;
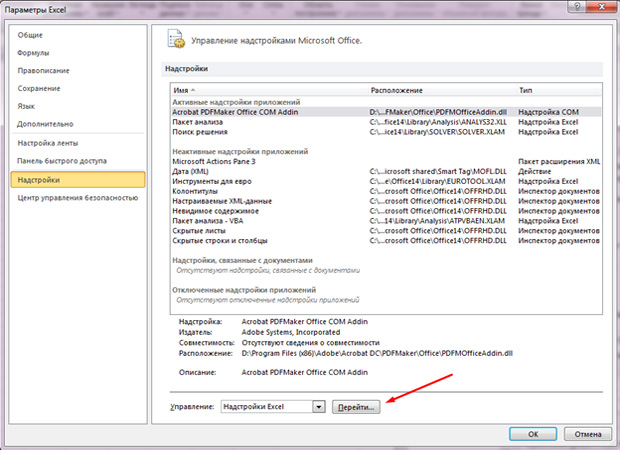
- Alttan "Yönetim" ve "GO" düğmesini görecektir. Üstüne tıkla;
- "Analiz Paketi" nde bir kene koyun;
- "Tamam" ı tıklayın.

Görev örneği
Toplu analiz fonksiyonu etkinleştirilir. Aşağıdaki göreve izin verin. Kurumdaki PE sayısı ve çalışan işçilerin sayısının sayısı hakkında birkaç yıldır bir veri örneği var. Bu iki değişken arasındaki ilişkiyi tanımlamamız gerekiyor. Açıklayıcı bir değişken X var - bu, işçi sayısıdır ve açıklanabilir değişken - Y acil durumların sayısıdır. Kaynak verileri iki sütundan dağıtıyorum.
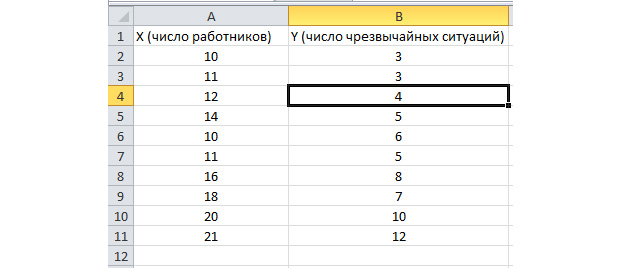
"Veri" sekmesine gidelim ve "Veri Analizi" yi seçin.
Görünen listede "Regresyon" seçeneğini seçin. Y ve X giriş aralıklarında, ilgili değerleri seçin.
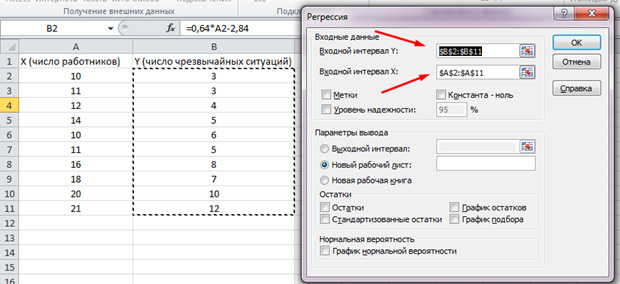
"Tamam" ı tıklayın. Analiz üretilir ve yeni bir sayfada sonuçları göreceğiz.
Bizim için en önemli değerler aşağıdaki şekilde işaretlenmiştir.
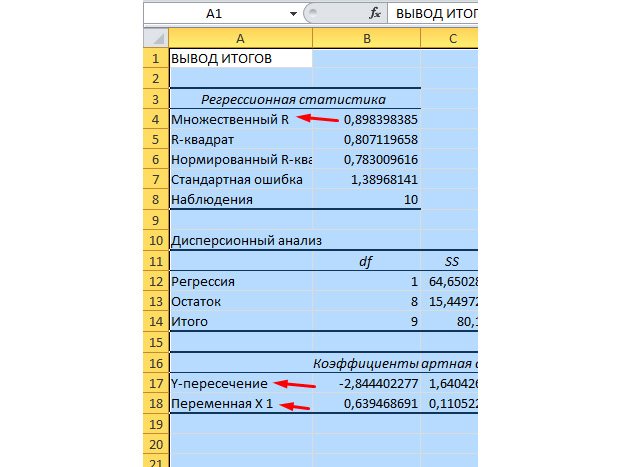
Çoklu R belirleme katsayısıdır. Karmaşık bir hesaplama formülü vardır ve korelasyon katsayısımıza nasıl güveneceğini gösterir. Buna göre, bu değer daha fazla, daha fazla güven, modelimizi bir bütün olarak güçlendirir.
Y-kavşak ve kavşak X1, regresyonun katsayılarıdır. Daha önce de belirtildiği gibi, regresyon bir fonksiyondur ve belirli katsayıları vardır. Böylece, işlevimiz aşağıdakilere bakacaktır: Y \u003d 0.64 * X-2.84.
Bize bu ne verir? Bu bize bir tahmin yapma fırsatı veriyor. Diyelim ki işletmede 25 işçi işe almak istiyoruz ve acil durumların ne olacağını yaklaşık olarak hayal etmeliyiz. Bu değeri fonksiyonumuza değiştiriyoruz ve Y \u003d 0.64 * 25 - 2.84 sonuçlarını elde ediyoruz. Yaklaşık 13 pp oluşacağız.
Nasıl çalıştığını görelim. Aşağıdaki çizime bir göz atın. Katılan çalışanların gerçek değerlerinde, gerçek değerler ikame edilir. Gerçek oyunculara ne kadar önemli olduğunu görün.

Ayrıca, "Ekle" sekmesini tıklatarak ve bir nokta şeması seçerek IPERSION ve ICS alanını seçerek korelasyon alanını da oluşturabilirsiniz.

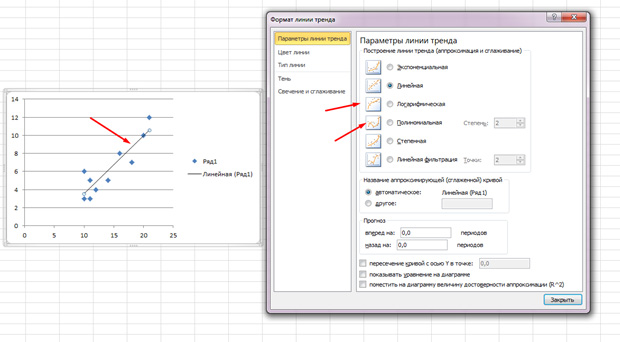
Noktalar köşeye gidiyor, ancak genel olarak, hattın ortasında olduğu sanki. Ayrıca, MS Excel'deki "Düzen" sekmesine tıklayarak ve trend satırı öğesini seçerek bu satırı da ekleyebilirsiniz.
Görünen hat boyunca iki kez tıklayın ve daha önce belirtilenleri görün. Korelasyon alanınızın nasıl göründüğüne bağlı olarak regresyon türünü değiştirebilirsiniz.
Belki de, puanların bir parabola çizdiği ve doğrudan bir çizgi değil ve başka bir regresyon türünü seçmek için uygun olduğunu söyleyecektir.
Sonuç
Bu makalenin size gerileme analizinin ne olduğu ve ihtiyaç duyduğu şeyin daha iyi bir şekilde anlaşılmasını sağlayalım. Bütün bunlar iyi bir uygulamalı değere sahiptir.
İÇİNDE Excel Doğrusal bir regresyon programı (ve hatta lineer olmayan regresyonların bile cm. Sonraki) inşa etmenin daha hızlı ve daha uygun bir yolu vardır. Bu şöyle yapılabilir:
1) Sütunları verilerle tahsis edin X. ve Y. (Bu sırayla yerleştirilmelidir!);
2) Çağrı Ana grafik ve bir grupta seçin Bir tür – Otlatmak Ve hemen basın hazır;
3) Seçimi diyagramdan düşürmeden, görünen ilk öğe öğesini seçin. DiyagramÖğeyi seçmelisiniz Trend Hattı Ekle;
4) iletişim kutusundaki iletişim kutusunda Trend çizgisi Sekmede Bir türseç Doğrusal;
5) sekmede Parametreleranahtarı etkinleştirebilirsiniz Grafikteki denklemi gösterBu, katsayıların (4.5) hesaplanacağı doğrusal regresyon denklemini (4.4) görmesine izin verecektir.
6) Aynı sekmesinde, anahtarı etkinleştirebilirsiniz Diyagramdaki yaklaşım (R ^ 2) doğruluğunun değerini yerleştirin (r ^ 2). Bu büyüklük, korelasyon katsayısının (4.3) karesidir ve hesaplanan denklemin deneysel bağımlılığı ne kadar iyi tanımladığını gösterir. Eğer bir R. 2 birime yakındır, daha sonra teorik regresyon denklemi iyi deneysel bir bağımlılığı tanımlar (teori, deney ile iyi anlaşılıyor) ve eğer R. Şekil 2, sıfıra yakındır, o zaman bu denklem deneysel bağımlılığı tanımlamak için uygun değildir (teori deney ile tutarlı değildir).
Açıklanan eylemlerin yürütülmesinin bir sonucu olarak, regresyon programına sahip bir diyagram ve denklemi elde edilecektir.
§4.3. Doğrusal olmayan regresyonun ana türleri
Parabolik ve polinom regresyonu.
Parabolik Büyüklüğün bağımlılığı Y. büyüklükten H. Bağımlılık, ikinci dereceden bir fonksiyon denir (2. sipariş parabol):
Bu denklem denir parabolik regresyon y denklemi Y üzerinde H.. Parametreler fakat, b., dan aranan parabolik Regresyon Katsayıları. Parabolik regresyon katsayılarının hesaplanması her zaman hantaldır, bu nedenle hesaplamalar için bir bilgisayar kullanmanız önerilir.
Parabolik regresyonun denklemi (4.8), polinom olarak adlandırılan daha genel bir regresyonun özel bir vakasıdır. Polinom Büyüklüğün bağımlılığı Y. büyüklükten H. polinom ile ifade edilen bağımlılık denir n.sipariş:
nerede sayılar bir I. (bEN.=0,1,…, n.) Aranan polinom Regresyon Katsayıları.
Güç regresyonu.
Güç Büyüklüğün bağımlılığı Y. büyüklükten H. Formun bağımlılığı denir:
Bu denklem denir güç regresyonunun denklemi Y üzerinde H.. Parametreler fakat ve b. aranan güç regresyon katsayıları.
ln \u003d ln. a.+b ·ln. x.. (4.11)
Bu denklem, düzlemin doğrudan LOGARitmik koordinat eksenleri ile doğrudan tanımlanmaktadır. x. ve ln. Bu nedenle, güç regresyonunun uygulanabilirliği için kriter, ampirik veri logaritmalarının puanlarının LN'nin x I. ve ln. bEN. Çizgiye en yakın (4.11).
Gösterge niteliğinde regresyon.
Gösterge niteliğinde(veya Üstel) Büyüklüğün bağımlılığı Y. büyüklükten H. Formun bağımlılığı denir:
(veya). (4.12)
Bu denklem denir denklem göstergesidir (veya Üstel) regresyon Y. üzerinde H.. Parametreler fakat (veya k.) BEN. b. aranan katsayılar Göstergesi (veya Üstel) regresyon.
Güç regresyon denkleminin her iki kısmı de prologa edildiyse, denklem olacaktır.
ln \u003d. x ·ln. a.+ Ln. b. (veya ln \u003d k · X.+ Ln. b.). (4.13)
Bu denklem, tek bir LN değerinin logaritmasının diğer bir değerden doğrusal bağımlılığını açıklar. x.. Bu nedenle, güç regresyonunun uygulanabilirliği için kriter, aynı büyüklükteki ampirik verilerin puanlarının gerekliliğidir. x I. Ve başka bir LN büyüklüğünün logaritmaları bEN. Doğrudan en yakınlardı (4.13).
Logaritmik regresyon.
Logaritmikbüyüklüğün bağımlılığı Y. büyüklükten H. Formun bağımlılığı denir:
=a.+b ·ln. x.. (4.14)
Bu denklem denir logaritmik regresyonun denklemi y üzerinde H.. Parametreler fakat ve b. aranan logaritmik regresyonun katsayıları.
Hiperbolik regresyon.
Hiperbolik Büyüklüğün bağımlılığı Y. büyüklükten H. Formun bağımlılığı denir:
Bu denklem denir hiperbolik regresyon y denklemi Y üzerinde H.. Parametreler fakat ve b. aranan hiperbolik regresyon katsayıları ve en küçük kareler yöntemi ile belirlenir. Bu yöntemin kullanımı formüllere yol açar:
Formüllerde (4.16-4.17) Toplam, Endeks ile gerçekleştirilir. bEN. birden gözlem sayısına kadar n..
Maalesef, Excel Hiperbolik regresyon katsayılarını hesaplayan hiçbir işlev yoktur. Ölçülen değerlerin ters orantılığıyla ilişkili olduğu bilinmemesi durumunda, güç regresyon denklemini aramak için hiperbolik regresyon denklemi yerine önerilir. Excel Konumu için bir prosedür var. Ölçülen değerler arasında hiperbolik bağımlılık varsayılırsa, regresyon katsayıları, yardımcı hesaplama tabloları ve formüllere göre toplama işlemleri kullanılarak hesaplanmalıdır (4.16-4.17).