Install, configure and use PostgreSQL on Ubuntu.
PostgreSQL directly out of the box can not be used for use with 1C. What is needed is an adapted version from 1C that turns PostgreSQL into a blocker, and you need to understand that locks will be applied to the entire table at once. If you need locks at the level of records, turn on the mode of controlled locks in 1C and prescribe them in the configuration with handles. Conclusion: it is necessary to download a special distribution kit from the 1C website or take an ITS disk.
You can find intuitive programming home pages. Things are so small that they do not need to change. You should always try to ensure that your test configuration is as close as possible to the conditions that were performed on the “hot” server, in order to avoid problems with sending test pages.
With such things, there are more things, perhaps to ask friends who have experience. Also remember that this site may be outdated and something is wrong. This window no longer works. Document baskets are one address book. The document bin should contain all published files and scripts.
Installation
The installation itself does not cause any special difficulties, you need to pay attention to the correct initialization of the database, namely setting the locale, then you can only change it by re-initial initialization. For example, the base 1C with the Ukrainian regional settings in the DBMS with the Russian locale installed will not load. Yes, and problems with sorting then not needed. Therefore, we do init according to the desired language.
You can specify which address will be the root of the documents. What this directive means can be understood from the comments and notifications. Will be completed. In any case, this is a study of long winter evenings beyond the scope of this text. But at the first moment you do not need to install anything. A minor problem can be met by those who connect to the modem by phone. When he detects it, he no longer wants to look at the local host.
If you know where it will be installed, try to find it. The importance of individual directives is evident from the comments. Dynamic libraries are the most interesting settings - if you want to use some other databases or program libraries, you have to decrypt the line that starts. That's enough, but for a newbie it's too hard.
For Russian language
initdb --locale = en_RU.UTF-8 --lc-collate = en_RU.UTF-8 --lc-ctype = en_RU.UTF-8 --encoding = UTF8 -D / db / postgresql
For Ukrainian language
initdb --locale = uk_UA.UTF-8 --lc-collate = uk_UA.UTF-8 --lc-ctype = uk_UA.UTF-8 --encoding = UTF8 -D / db / postgresql
where / db / postgresql is your PostgreSQL data directory. The coding is, of course, UTF-8.
Detailed option to re-create the cluster
1. It is necessary to give full rights to the folder in which we installed PostgreSQL, usually C: \\ Program Files \\ PostgreSQL
If you work with databases more often, you will very quickly understand the interface principle. There are links to other interesting sources. Most of them - only such insidious moments, like text in the dark. You can back up your database using metadata.
In Date and Time, you will learn how to set the default time format. You may be ready for all the data in the database, so first you need to perform a backup. In addition to the package installation method and the location of the configuration file, this instruction is valid for any distribution. The tutorial will help you step by step. Of course, not exhaustive, please read the documentation.
2. From under the admin rights run cmd. If you do this in win7, then run from the Administrator.
3. Create a folder where the cluster will be stored. For example, d: \\ postgredata.
md d: \\ postgredata
4. We perform the initialization of the cluster manually, indicating the path where it will be located.
“C: \\ Program Files \\ PostgreSQL \\ 9.1.2-1.1C \\ bin \\ initdb.exe” -D d: \\ postgredata --locale = Russian_Russia --encoding = UTF8 -U postgres
And then reload the settings with the command. If you do not use any parameters when it starts, it will try to connect to the local database as the user you are logged in to. Operations on specific databases. If you want to use this tool to perform management tasks, it does not need to leave it or allow access only from some computers. You will see that the parameters that the database administrator needs to know and be able to configure are not many.
For manufacturing operations, it is very low, and you need to allocate a bit more resources to the database. The size of the allocated memory affects the following five parameters. The specific values of these parameters can be determined by the formula. It will be connected to no more than sixteen clients, which can cause complex queries with excellent results and require large working memory.
5. Remove the PostgreSQL service that was installed during the installation.
sc delete pgsql-9.1.2-1.1C-x64
Where pgsql-9.1.2-1.1C-x64 is the name of the service. If you don’t know the name exactly, you can view the properties of the “PostgreSQL Database Server ...” service (Start - Control Panel - Administrative Tools - Services)
6. We create a new service with our cluster
“C: \\ Program Files \\ PostgreSQL \\ 9.1.2-1.1C \\ bin \\ pg_ctl” register -N pgsql -U postgresql -P password -D d: / postgredata
The appropriate size of working memory depends on the type of requests. For a common web server with fast and simple requests, we want to set up working memory to lower values, and the number of clients will be much higher. Only five parameters with values approximated by a simple formula. There is no need to set anything else, the other parameters are well tuned to protect the default data, and there is no need to change them in any way.
In the future, we can rely on the automatic configuration of these parameters, as modern commercial databases do. Very often, the administrator increases the number of connections, regardless of the size of the working memory. It should be remembered that in practice it may happen that a configured server after several days of trouble-free operation without an obvious reason “falls”. The database server has simply exhausted all the memory, and the allocation for the next client will not work anymore. The solution is to add additional memory to the server or change the configuration to meaningful values.
7.Now we go to the service. Start - Control Panel - Administration - Services and start our service.
DBMS Error: ERROR: new encoding (UTF8) is incompatible with the template database (WIN1251).
HINT: Use the same encoding as the database template, or use the template 0 as template.
You chose the wrong locale when installing the DBMS (WIN1251) for the server and the client, you need to change to UTF-8 in the configuration or reinstall the DBMS with the following parameters:
For each performance test, we need to think about what we really want to test, and what we want to achieve with this setting. In practice, however, we will not encounter such workloads; reading prevails there. Thus, this test may not always make sense, and database performance may vary significantly during practical deployment. Ideal to check them directly using the application, which will then run in production mode.
Default database server settings
The first requirement is now somewhat out of date, so a small database will fit into memory today, but this does not correspond to the intention to test disk performance.
Optimized database server settings
The testing database remained the same, the server parameters are the same as the above samples. The database should be in memory, which is ideal in practice.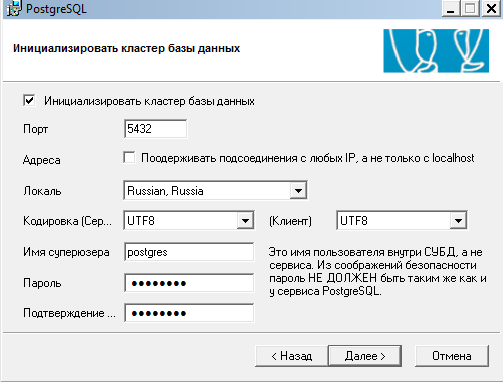
Attentionwhen installing, do NOT select the locale OS settings, select from the list Russian, Russia
PostgreSQL setup
It is necessary to remember the recommendation 1C not to use the FULL EXTERNAL CONNECTION in requests for the construction and to replace it using, for example, a combination of several left connections. There is also a known problem with performance loss in queries, where a connection with a virtual table is used. SliceLast, it is recommended to make separate queries for it and save the results in temporary tables.
Optimized server setup, read verification
This is eleven times larger than the default. What sometimes corresponds to practice, the database often fits into memory. But this is also not true. Thus, we return to the beginning when the database does not fit into the memory, and the disk system must cope with the current reading and writing.
Adjust settings to suit your needs.
We showed more or less significant performance tests and the impact of the settings on it. From the results, you can determine the limits within which you can expect improvements in database performance simply by changing the server settings. The comparison determined the installation scenario in accordance with the active localization settings. The data store format should not be changed in the main version, so if you upgrade to one main version, just upgrade the package and it will be executed. However, if you upgrade from one major version to another, for example, from 4 to 0, you should proceed as follows.
Configuration is done by editing the postgresql.conf file.
The most important parameters
effective_cache_size = 0.5 of RAM capacity
fsync = off disable reset to disk after each transfer (Warning! Use only when using a reliable UPS, there is a risk of data loss if an unexpected shutdown occurs)
synchronous_commit = off disable synchronous logging (risks are the same as in fsync)
Creating users and databases
You can start by creating a user who will own the database that was created later. You will be prompted to enter a password, and then you will be asked about three important things: should the new role created have administrative rights, should it have the right to create databases, and finally, should it have the right to create new roles.
Now there is a database that will belong to the user you just created. Suppose this database will be called “invoice”. A template is basically a database with some basic content that is copied to your newly created database. The point of several templates is that you still have a “clean” template for creating a database without editing after editing one template. In this series, we will look at most of the configuration options to explain what they mean and how to set them for high performance throughout the database.
wal_buffers = 0.25 of RAM capacity
After setup, do not forget to restart the service:
service postgresql restart
Network configuration
To connect 1C clients to the server from the outside and the operation of the database server, on the firewall, the following ports must be open:
Server agent (ragent) & tcp: 1540 Main cluster manager (rmngr) & tcp: 1541 A range of network ports for dynamically distributing workflows & tcp: 1560 & 1591, tcp: 5432 & Postgresql. Create a rule through a standard interface, or with the command:
But do not expect to optimize the database schema, we will search for a clean database on the server. Event and error logs are very important for the system administrator, and even if they do not fit into the performance tuning, a well-chosen log can help find flaws in the configuration and detect long-standing queries.
Log Line Prefix
By default, the line in the log does not have a prefix, which is impractical. For a start, it’s good to set up, for example. Additional information for entering the journal line is provided in the documentation. A typical database reads much more than a write, so these commands will be minimal.
netsh advfirewall firewall add rule name = "1Cv8-Server" dir = in action = allow protocol = TCP localport = 1540,1541,5432,1560-1590 enable = yes profile = ANY remoteip = ANY interfacetype = LAN
Now, from another computer, we quietly start the 1C: Enterprise client, add the existing information database newdb. Do not forget about the license, software / hardware protection.
Backup
Create a database dump command
Long queries
In search of problem queries, their logging is an excellent tool, especially in combination with the next option for recording only long queries. This option is the perfect tool for finding slow queries. Requests longer than 200 ms are considered long requests. With this option, you can turn on the logging of all requests; in the case of an optimized database and application, the log will always be empty.
This may be radically different from a later launch after recalculating statistics, etc. Therefore, data lines never change, a new line is always created, and the old one is only marked as invalid. These old lines should be removed regularly. To select the optimal implementation plan, you also need to update the statistics of the data columns.
su postgres -c "pg_dump -U postgres -Fc -Z9 -f baza1.sql baza1"
Recovery from dump
su postgres -c "pg_restore -U postgres -c -d baza1 -v baza1.sql"
Periodic service
su postgres -c "/ usr / bin / vacuumdb --dbname = $ i --analyze --full --quiet"
View PostgreSQL activity
Sometimes it is useful to see what the server is doing now. This design will help:
watch -n 1 "ps auxww | grep ^ postgres"
Practical example: the client database server worked in a basic configuration. This is very economical, so the database has a disproportionate load on the disk, but also without an active auto-vacuum process. It also significantly slowed down the entire database, and also significantly reduced the free disk space.
However, this process has been disabled until 3 in the default settings. Starting with version 3, it is enabled by default. In addition, it is unlikely that such operations will be performed more simultaneously, so you can allocate more memory than for a standard client. It is good to remember that this memory will also be used by auto-vacuum processes.
A little about configuring PostgreSQL
* Is there an alternative to MSSQL?
* PostgreSQL - a brake or an excellent DBMS?
* How to make PostgreSQL work at full speed?
This article does not pretend to the full description of all the PostgreSQL configuration options, and in comparative testing I do not cover all the modes of the database operation. Interested advise to study the book on the link
To install, run the command. After issuing the above command, the database server will be installed. Of course, these locations may be changed, but the server may have problems starting. To manage all users, we write everything.
When adding a user, we will be prompted to enter a password and repeat it. The switch used when adding a user. The system is stable and very effective, especially when working with large databases or data warehouses. Maximum database size is unlimited.
Introduction
I have worked a lot with PostgreSQL and consider it an excellent DBMS. I have a multi-gigabyte working database (not 1C) that processes huge data files instantly. PostgreSQL makes excellent use of indexes, copes well with parallel workloads, the functionality of stored procedures is at a height, there are good administration tools and improved performance out of the box, and the community has created useful utilities. But I was surprised to find out that many 1C administrators have an opinion that PostgreSQL is not up to par, that it is slow and barely overtakes the file version of the database, and only MSSQL can save the day.
Having studied the question, I found many articles on installing PostgreSQL step-by-step for dummies, both on Linux and under Windows. But the overwhelming majority of articles describe the installation before "it was established - let's create a base", and do not at all touch the issue of configuration. In the remaining configuration, it is mentioned only at the level “prescribe such values”, practically without explaining why.
And if the “one-button setup” approach is applicable to MSSQL and in general many products under Windows, then unfortunately it does not apply to PostgreSQL. The default settings greatly limit its use of memory so that it can be installed even on a calculator and it does not interfere with the work of the rest of the software. PostgreSQL must be configured for a specific system, and only then can it show itself at a height. In severe cases, you can tune the PostgreSQL settings, the base and the file system for each other, but this applies to a greater degree of Linux-systems, where there are more opportunities to configure everything and everyone.
It should be recalled that PostgreSQL from the developers of the DBMS, only compiled from the patched source code, is not suitable for 1C. Ready compatible builds are offered by 1C (via ITS disks and an office for those who have a subscription to support) and EterSoft
Testing was conducted in the Windows environment, but all the recommendations for customization are not platform-specific and are applicable to any OS.
Testing and Comparison
When testing, I did not set the task to conduct tests in all modes and scenarios of work, only a rough check of a successful configuration.
For testing, I used the following configuration:
Host machine: Win7, Core i5-760 2.8MHz, 4 cores, 12GB of RAM, VMWare 10
Virtual: Win7 x64, 2 cores, 4GB of RAM, a separate physical hard disk to accommodate the database (not SSD)
MSSQL Express 2014
PostgreSQL EtherSoft 9.2.1
1C 8.3.5 1383
DB was used, dt-unload 780MB.
After restoring the database:
file size 1CD in the file version - 10GB,
postgreSQL database size is 8GB
mSSQL database size - 6.7GB.
For the test, I used a request to sample contracts of counterparties (21k) with a sample of additional details from different registers; for each contract, a separate sample was actually made from registers. I took the configuration that was at hand - heavily modified on the basis of Accounting 3.0.
When testing, I performed a query with one and two clients several times until stable results were obtained. I ignored the first runs.
Testing by one client:
Sampling on the host from the file version with the base on the SSD - 31s
Sampling from file variant in virtual machine (from hard disk) - 46s
Sampling from the MSSQL database - first pass - 25s or 9s (apparently depending on the relevance of the DBMS cache) (the memory consumption of the DBMS process was approximately 1.3GB)
Sampling from PostgreSQL with default settings - 43s (memory consumption did not exceed 80MB per connection)
Sample of optimized PostgreSQL - 21s (memory consumption was 120MB per connection)
Testing by two clients:
Sample on the host from the file version with the base on the SSD - 34c
Sampling from file variant in virtual machine (from hard disk) - 56c each
Sampling from MSSQL-database - by 50s or 20s (apparently, depending on the relevance of the DBMS cache)
PostgreSQL sample with default settings - 60s each
Sampling from optimized PostgreSQL - by 40s
Testing Notes:
- After adding the third core, PostgreSQL and MSSQL variants began to work in the "two clients" test with practically the performance of the "one client" test, i.e. successfully parallelized. What prevented them from parallelizing work on two cores remains a mystery to me.
- MSSQL captures a lot of memory at once, PostgreSQL demanded significantly less in all modes, and immediately after the completion of the query almost all of it was released.
- MSSQL works as a single process. PostgreSQL runs on a separate process for connecting + service processes. This allows even the 32-bit version to effectively use memory when processing requests from several clients.
- The increase in memory for PostgreSQL in settings over the following values did not lead to a noticeable increase in performance.
- The first tests in all cases took longer than in subsequent measurements, did not specifically measure, but subjectively MSSQL started faster.
Configuring PostgreSQL
There is an excellent book in Russian about configuring and optimizing PostgreSQL: It makes sense for each elephant builder to bookmark this link. The book describes many techniques optimize the database, the creation of fault-tolerant and distributed systems. But now we will look at what's useful to everyone - configuring memory usage. PostgreSQL will not use more memory than allowed by the settings, and with the default settings, PostgreSQL uses minimum memory. In this case, it is not necessary to specify the memory more than is available to use - the system will begin to use the paging file with all the ensuing sad consequences for the server's performance. A number of tips for configuring PostgreSQL are provided on the ITS disk.
On Windows, PostgreSQL configuration files are located in the installation directory in the Data directory:
- postgresql.conf - main file with DBMS settings
- pg_hba.conf - file with access settings for clients. In particular, here you can specify which users from which IP addresses you can connect to certain databases, and whether you need to check the user's password, and if so, by what method.
- pg_ident.conf - a file with the conversion of user names from system to internal (it is unlikely that most users will need it)
Text files, you can edit the notepad. Lines starting with # are considered comments and ignored.
Parameters related to the amount of memory can be supplemented by suffixes kB, MB, GB - kilobytes, megabytes, gigabytes, for example, 128MB. Parameters describing time intervals can be supplemented with the suffixes ms, s, min, h, d - milliseconds, seconds, minutes, hours, days, for example, 5min
If you have forgotten the password to post-regress - it does not matter, you can write in pg_hba.conf line:
Host all all 127.0.0.1/32 trust
And connect by any user (for example, postgres) to the DBMS on the local machine at 127.0.0.1 without checking the password.
Optimization memory usage
Memory settings are located in postgresql.conf
The optimal values of the parameters depend on the amount of free RAM, the size of the database and the individual elements of the database (tables and indexes), the complexity of the queries (in principle, it is worth relying that the queries will be quite complicated - multiple connections in queries are a typical scenario) and the number of simultaneous active clients. By the way, PostgreSQL stores tables and database indices in separate files (<каталог установки PG><идентификатор БД>\\), and the size of objects can be estimated. You can also use the supplied utility pgAdmin to connect to the database, open the "Schemes" - "public", and generate a statistics report for the "Tables" element.
Further I will give approximate values with which it is possible to begin setup. After the initial setup, it is recommended to drive the server in operating modes and monitor memory consumption. Depending on the results obtained, it may be necessary to correct the parameter values.
When setting up the server for testing, I relied on the following calculations:
Only 4GB of RAM. Consumers - Windows OS, 1C server, PostgreSQL and system disk cache. I proceeded from the fact that for a DBMS you can allocate up to 2.5GB of RAM
Values can be specified with kB, MB, GB suffixes (values in kilobytes, megabytes or gigabytes). After changing the values, you must restart the PostgreSQL service.
shared_buffers - Server shared buffer
The size of the PostgreSQL read and write cache, common to all connections. If the data is not in the cache, it reads from the disk (the OS may be cached)
If the buffer is not enough to store frequently used working data, then they will be constantly written and read from the OS cache or from disk, which will have an extremely negative impact on performance.
But this is not all the memory required for the work, you should not specify too much value, otherwise there will be no memory for the actual execution of customer requests (and the greater the memory consumption), and for the OS and other applications, for example, the server process 1C. The server also relies on the OS cache and tries not to keep in its buffer what is most likely cached by the system.
Used in the test
shared_buffers = 512MB
work_mem - memory for sorting, data aggregation, etc.
It is allocated for each request, perhaps several times for complex requests. If there is not enough memory, PostgreSQL will use temporary files. If the value is too large, there may be an overrun of RAM and the OS will start using the paging file with a corresponding drop in performance.
There is a recommendation in the calculations to take the amount of available memory minus shared_buffersand divide by the number of simultaneously executed queries. In the case of complex queries, the divider should be increased, i.e. reduce the result. For the case in question, at the rate of 5 active users (2.5GB-0.5GB (shared_buffers)) / 5 = 400Mb. If the DBMS considers the queries to be quite complex, or additional users appear, the value will need to be reduced.
For simple queries, small values are enough - up to a couple of megabytes, but for complex queries (and this is a typical scenario for 1C), more will be required. Recommendation - for memory 1-4GB, you can use the values of 32-128Mb. In the test used
work_mem = 128MB
maintenance_work_mem - memory for commands for collecting garbage, statistics, creating indexes.
It is recommended to set the value to 50-75% of the size of the largest table or index, but in order to have enough memory for the system and applications. It is recommended that values be greater than work_mem. In the test used
maintenance_work_mem = 192MB
temp_buffers - buffer for temporary objects, mainly for temporary tables.
You can set the order of 16 MB. In the test used
temp_buffers = 32MB
effective_cache_size - approximate volume of file system disk cache.
The optimizer uses this value when building a query plan to estimate the probability of finding data in the cache (with fast random access) or on a slow disk. In Windows, the current amount of memory allocated for the cache can be viewed in the task manager.
Autovacuum - "garbage collection"
PostgreSQL as a typical representative of "versioned" DBMS (as opposed to blocking) does not independently block when changing data in the table and writing from reading transactions (in the case of 1C, the 1C server itself does this). Instead, a copy of the modified record is created, which becomes visible to subsequent transactions, while the active ones continue to see data that is relevant at the beginning of their transaction. As a result, the tables accumulate obsolete data - previous versions of modified records. In order for the DBMS to use the freed up space, it is necessary to perform a "garbage collection" - to determine which records are no longer used. This can be done explicitly with the SQL command. VACUUM, or wait until the automatic garbage collector processes the table - AUTOVACUUM. Just before a certain version, garbage collection was associated with collecting statistics (the scheduler uses data on the number of records in the tables and the distribution of the values of the indexed fields to build the optimal query plan). On the one hand, it is necessary to collect garbage so that the tables do not grow and efficiently use disk space. On the other hand, the suddenly started garbage collection imposes additional load on the disk and tables, which leads to an increase in the query execution time. A similar effect is created by automatic statistics collection (it can be explicitly launched by ANALYZE or with garbage collection VACUUM ANALYZE). And although from version to version PostgreSQL improves these mechanisms to minimize the negative impact on performance (for example, in earlier versions garbage collection completely blocked access to the table, since version 9.0, VACUUM accelerated), there is something to configure.
You can completely disable autovacuum by setting:
autovacuum = off
Also, Autovacuum requires the parameter track_counts = on, otherwise it will not work.
By default, both options are enabled. In fact, the autovacuum cannot be completely disabled - even with autovacuum = off, sometimes (after a large number of transactions) the autovacuum will start.
Comment: VACUUM usually does not reduce the file size of the table, only marks the free, reusable areas. If you need to physically free up excess space and minimize the space occupied on the disk, you will need the command VACUUM FULL. This option blocks access to the table at run time, and is usually not required to use it. More information about using the VACUUM command can be found in the documentation (in English).
If Autovacuum is not completely disabled, you can configure its effect on query execution by the following parameters:
autovacuum_max_workers - The maximum number of parallel running cleaning processes.
autovacuum_naptime - the minimum interval, less often which the autovacuum will not start. The default is 1 minute. You can increase, then with frequent changes in data analysis will be performed less frequently.
autovacuum_vacuum_threshold, - the number of changed or deleted entries in the table required to start the garbage collection process VACUUM or collecting statistics ANALYZE. The default is 50.
autovacuum_vacuum_scale_factor , autovacuum_analyze_scale_factor - coefficient of the size of the table in the records added to autovacuum_vacuum_threshold and autovacuum_analyze_threshold respectively. The default values are 0.2 (ie, 20% of the number of entries) and 0.1 (10%), respectively.
Consider an example with a table for 10,000 entries. Then with the default settings, after 50 + 10000 * 0.1 = 1050 changed or deleted records, statistics collection will be started ANALYZE, and after 2050 changes - garbage collection VACUUM.
If you increase the threshold and scale_factor, the maintenance processes will be performed less frequently, but small tables can grow significantly. If the database consists mainly of small tables, the total increase in disk space occupied can be significant, thus it is possible to increase these values, but with the mind.
Thus, it may make sense to increase the autovacuum_naptime interval, and slightly increase the threshold and scale_factor. In loaded bases, it can be an alternative to significantly raising scale_factor (a value of 1 will allow the tables to “swell” twice) and to put in the scheduler daily execution VACUUM ANALYZE in the period of minimum load of the database.
default_statistics_target - assigns the amount of statistics collected by the command ANALYZE. The default value is 100. Larger values increase the execution time of the ANALYZE command, but allow the scheduler to build more efficient query execution plans. There are recommendations to increase to 300.
Can manage performance AUTOVACUUM, making it more durable but less loading system.
vacuum_cost_page_hit - the size of the "fine" for processing a block located in shared_buffers. Associated with the need to block access to the buffer. The default value is 1
vacuum_cost_page_miss - the size of the "fine" for processing the block on the disk. It is associated with locking the buffer, searching data in the buffer, reading data from the disk. The default value is 10
vacuum_cost_page_dirty - The size of the "fine" for modifying the block. Associated with the need to reset the modified data to disk. The default value is 20
vacuum_cost_limit - The maximum size of "fines", after which the assembly process can be "frozen" for the time vacuum_cost_delay. The default is 200
vacuum_cost_delay - time of "freezing" of the garbage collection process to achieve vacuum_cost_limit. The default value is 0ms
autovacuum_vacuum_cost_delay - time of "freezing" the process of garbage collection for autovacuum. The default is 20ms. If set to -1, the vacuum_cost_delay value will be used.
autovacuum_vacuum_cost_limit - The maximum size of the "fine" for autovacuum. The default value is -1 - the vacuum_cost_limit value is used.
Reported use vacuum_cost_page_hit = 6, vacuum_cost_limit = 100, autovacuum_vacuum_cost_delay = 200ms reduces the effect of AUTOVACUUM by up to 80%, but triples its execution time.
Setting up writing to disk
When a transaction is completed, PostgreSQL starts writing data to a special WAL (Write-ahead log) transaction log, and then to the database after the log data is written to the disk. The default mechanism is fsyncwhen PostgreSQL forcibly flushes data (log) from the OS disk cache to disk, and only after a successful write (log) the client is informed about the successful completion of the transaction. Using the transaction log allows you to complete a transaction or restore the database if data fails during data recording.
In loaded systems with large write volumes, it may make sense to transfer the transaction log to a separate physical disk (but not to another partition of the same disk!). To do this, stop the DBMS, move the pg_xlog directory to another location, and create a symbolic link in the old place, for example, with the junction utility. The same links can create Far Manager (Alt-F6). At the same time, you need to make sure that the new site has access rights for the user from which PostgreSQL is started (usually postgres).
With a large number of data modification operations, it may be necessary to increase the value of checkpoint_segments, which regulates the amount of data that can be expected to be transferred from the log to the database itself. The default value is 3. At the same time, it should be taken into account that the space allocated by the formula (checkpoint_segments * 2 + 1) * 16 MB is allocated for the log, which, with a value of 32, will already require more than 1 GB of disk space.
PostgreSQL resets data from the OS file cache to disk after each completion of a writing transaction. On the one hand, this ensures that the data on the disk is always up to date, on the other hand, with a large number of transactions, performance drops. Disable completely fsync can, specifying
fsync = off
full_page_writes = off
This can be done only if you completely trust the equipment and the UPS (uninterruptible power supply). Otherwise, in the event of a system crash there is a risk of getting a damaged database. And in any case, the RAID controller with a battery for powering the memory of the underwritten data will not hurt either.
A certain alternative could be the use of the parameter
synchronous_commit = off
In this case, after a successful response to the completion of the transaction, it may take some time to write to the disk safely. In case of a sudden shutdown, the database will not collapse, but the data of the last transactions may be lost.
If you do not disable fsync at all, you can specify the synchronization method in the parameter. An article from the ITS disk refers to the pg_test_fsync utility, but it was not in my PostgreSQL build. According to 1C, in their case in Windows, the method open_datasync (apparently, this method is used by default).
If there are a lot of small writing transactions (in case of 1C this can be a massive update of the directory outside the transaction), a combination of commit_delay parameters (delay time of completion of the transaction in microseconds, default 0) and commit_siblings (default 5) can help When options are enabled, the completion of a transaction may be delayed for the time of commit_delay, if at least the commit_siblings of the transaction are currently executing. In this case, the result of all completed transactions will be recorded together to optimize writing to disk.
Other parameters affecting performance
wal_buffers - amount of memory in shared_buffers for keeping transaction logs. Recommendation - with 1-4GB of available memory use 256KB-1MB values. The documentation claims that using the value "-1" automatically matches the value depending on the value of shared_buffers.
random_page_cost - "Cost" of random reading, used when searching data by index. The default is 4.0. The unit takes the time of sequential data access. For fast disk arrays, especially SSD, it makes sense to lower the value, in this case PostgreSQL will use indexes more actively.
In the book on the link there are some other parameters that can be configured. It is also strongly recommended that you familiarize yourself with the PostgreSQL documentation on the purpose of specific parameters.
The parameters from the QUERY TUNING section, especially regarding the ban on the scheduler using specific search methods, are recommended to be changed only if you have a full understanding of what you are doing. It is very easy to optimize one type of query and collapse the performance of all others. The effectiveness of changing most of the parameters in this section depends on the data in the database, requests for this data (that is, on the version of 1C used, including) and the version of the DBMS.
Conclusion
PostgreSQL is a powerful database management system in the right hands, but requiring careful configuration. It can be used together with 1C and get a decent speed, and its free will be a very nice bonus.
Criticism and additions to this article are welcome.
useful links
http://postgresql.leopard.in.ua/ - book site " Working with PostgreSQL tuning and scaling ", the most complete and understandable guide in my opinion on the configuration and administration of PostgreSQL
http://etersoft.ru/products/postgre - here you can download the 1C-compatible PostgreSQL build for Windows and various distributions and versions of Linux. For those who do not have an ETS subscription or need a version for the Linux version, which is not represented on v8.1c.ru.
http://www.postgresql.org/docs/9.2/static/ - official PostgreSQL documentation (in English)
Articles from ITS disk for PostgreSQL configuration
Article edit history
- 01/29/2015 - the original version is published
- 01/31/2015 - The article is supplemented with a section on AUTOVACUUM, a link to the original documentation has been added.
In the future, I intend to test the work of the DBMS in the mode of adding and modifying data.