How to copy in 1c accounting. Uploading a copy of the database to a file. method: using unloading information database.
To protect yourself from partial or complete data loss, before you take any actions with your infobase, it becomes necessary to back up data to 1C. With the help of a backup, you can return the database to the state in which it was at the time of copying.
Create a backup copy of 1C manually
Run 1C and select the configurator mode for your information database:
Delete previous backups to avoid overloading? How can I recover my database? Backing up your information database 1C is necessary to protect your data. This section discusses the above issues and presents the different types of backup work, developing a maintenance plan, and how to use it in your backup strategy.
The simplest type of backup is a full backup of a database — a complete copy of a database that provides a single point in time by which a database can be restored. Although the backup process can take many hours, you can restore a backup at one point only.
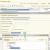
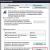
After logging into the configurator, go to the Administration menu and select the item “Unload information database”
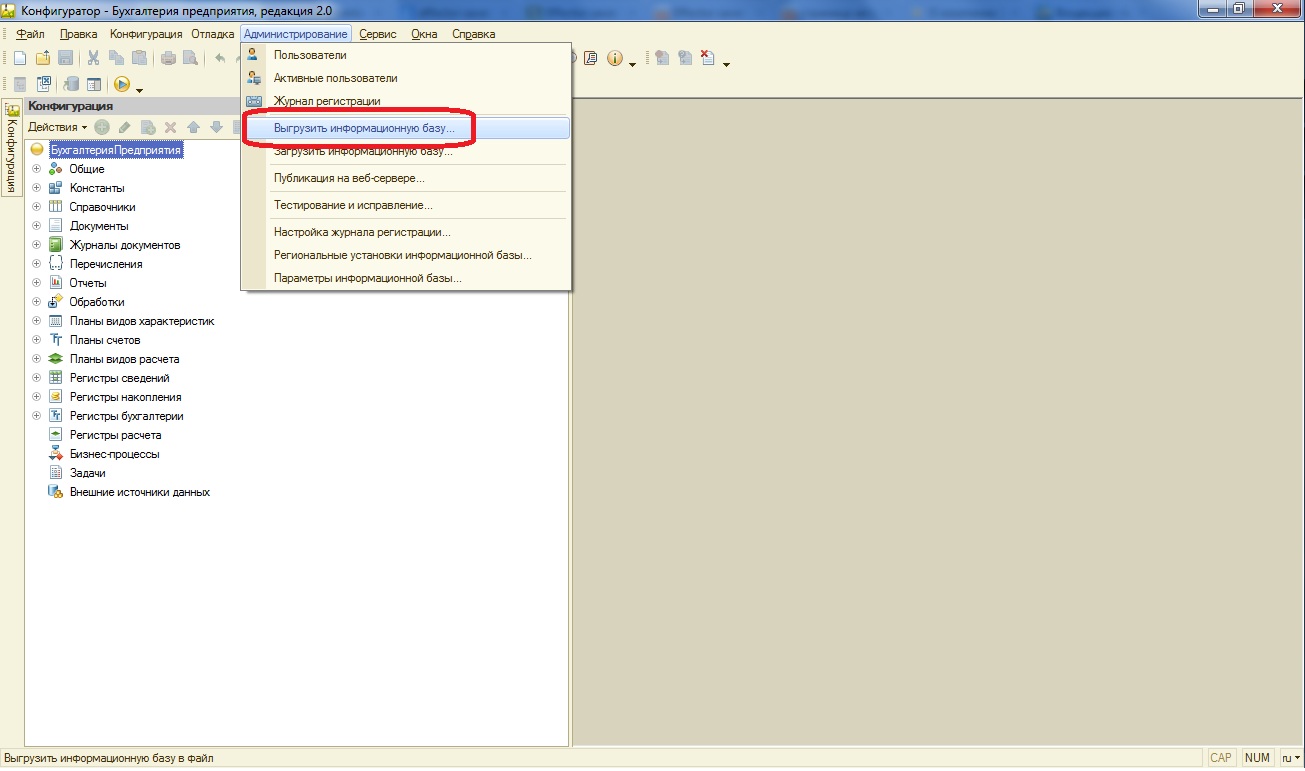
A window appears in which you need to specify a folder for saving backups (in my case it is called 1C Archive copies, you can name it as you please), the name of the backup file (in my case BP20082012, the first two letters are the designation of the name of the information base, hereinafter save date, ie August 20, 2012) and click save.
Another type of data backup is differential backup. A differential backup performs the same operations as a full backup, but contains only all the data that has been changed or added since the previous full backup. Differential backups are cumulative and consecutive backups after a full backup and will increase in size as you change or add more data. So why do we need differential backups?
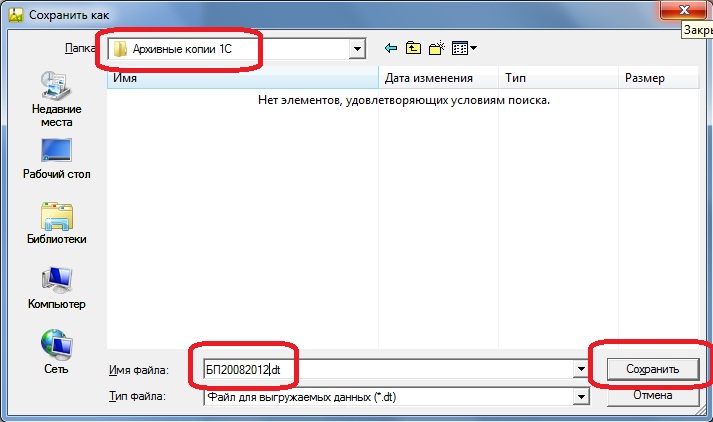
We are waiting for the program to perform the file saving. This operation can be observed in the lower left corner of the configurator window:
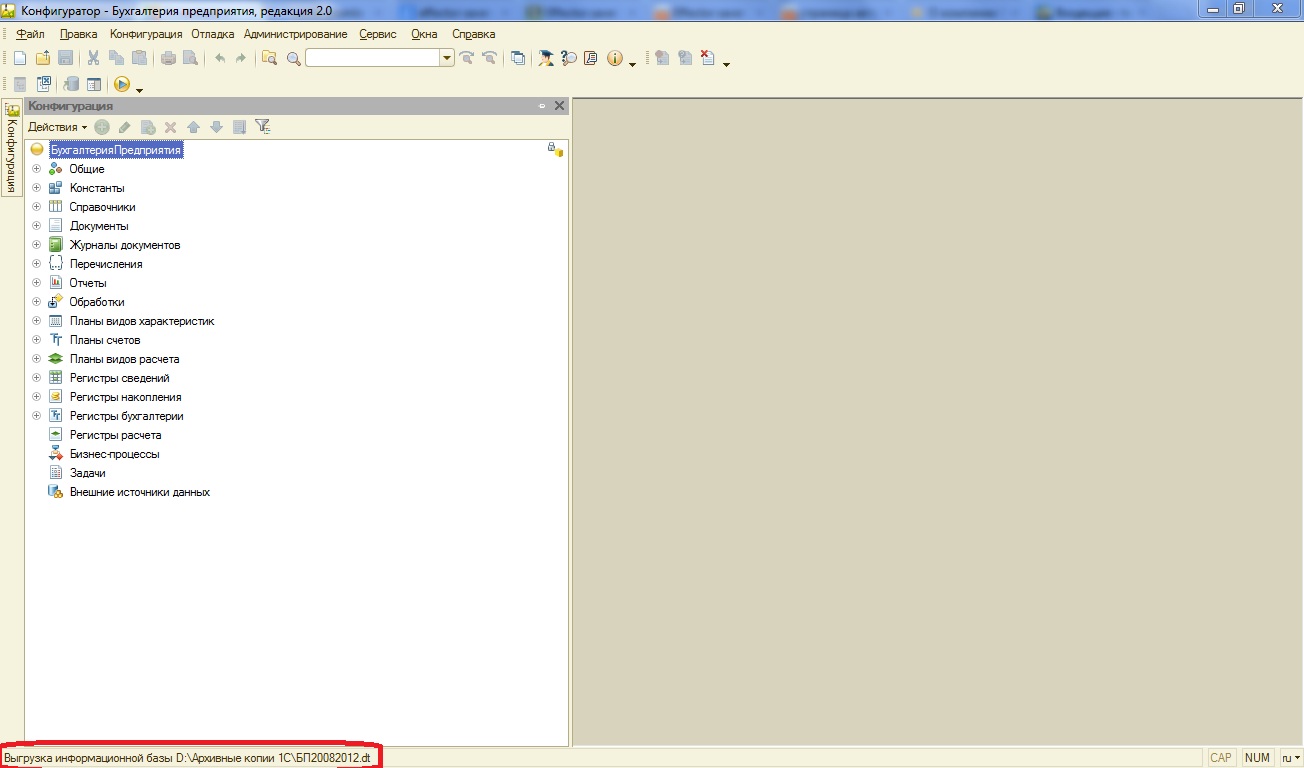
Upon completion, the program will display a message:
This will be discussed in the backup strategy section; differential backups can really speed up recovery operations, allowing you to skip many transaction log backups during the recovery process. It is much faster to speed up significantly using a differential backup than to rewrite multiple transaction log entries to get to the same point in time.
Unloading information database
A transaction log backup contains all the transaction log entries created since the last log backup, and is used to restore the database at a specific point in time. This means that they are incremental, unlike differential backups, which are cumulative. Because they are incremental, if you want to restore the database to a specific point in time, you need to have all the transaction log entries necessary to re-modify the database before that point in time.
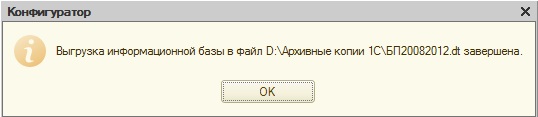
Backup created.
How to restore the database from a backup is described in.
Setting up automatic backup in 1C on schedule
This instruction will help you set up backups in automatic mode. It is suitable only for the file mode of operation in the 1C database. For setting in client-server mode, 1C recommends making backups using DBMS tools - MS SQL, Postgre, etc.
Method: using unloading information database
They are contained in the log backup chain. Although the backup chain of logs extends to a full backup, you do not need to restore all backup logs during recovery. If you made a full backup, say, on Sunday evening and on Wednesday evening with log backups every half hour Starting from Sunday, and then restoring the database after a disaster on Friday can use a full backup of the medium and all backup copies of the journal from Wednesday to Wednesday , instead of fully returning to full backup on Sunday evening.
To configure, follow the tab "Administration", the item "Support and Maintenance":
You can store copies of databases on your computer or on an external hard disk, and you can also use the 1C Cloud Archive service.
A log backup chain is a continuous series of log backups that contains all the transaction log entries needed to restore a database to a certain point. The chain begins with a full backup of the database and continues until something breaks the chain, thereby preventing more backups of the log until another full backup is taken. To manage the size of the transaction log, you need to back up the logs.
To prevent a log file from failing log, you must make regular log backups. Log backups can only be used in the full recovery model described in the next section. Each of these models represents a different approach to balancing the trade-off between saving disk space and ensuring the granularity of disaster recovery.
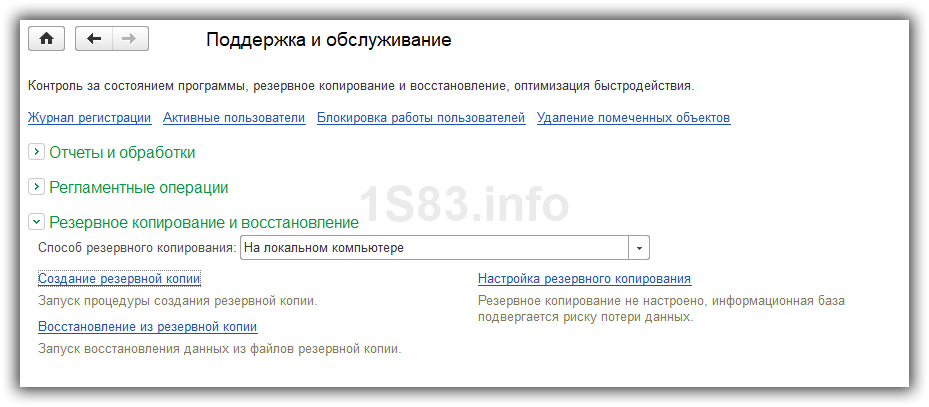
There is also a function available to manually start the backup and restore, but we are interested in the item "Setting Backup":
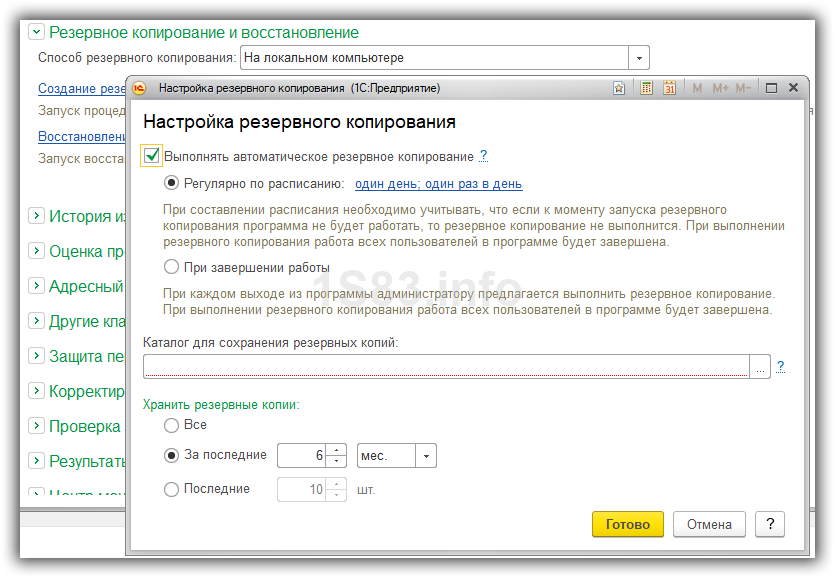
Possible customization options are scheduled and upon completion of work with the program. Best of all, especially if you are working in the database is not one, choose the option "Regularly scheduled." It is very easy to configure. In the screenshot, I set up the daily procedure:
A simple recovery model is simple: simple. In databases using a simple recovery model, you can restore only full or differential backups. It is impossible to restore such a database at a given time; you can restore it only at the time when a full or differential backup has occurred.
Backup temporary file external processing
The full recovery model also has a self-descriptive name. This allows you to develop a disaster recovery plan that includes a combination of full and differential database backups combined with transaction log backups.
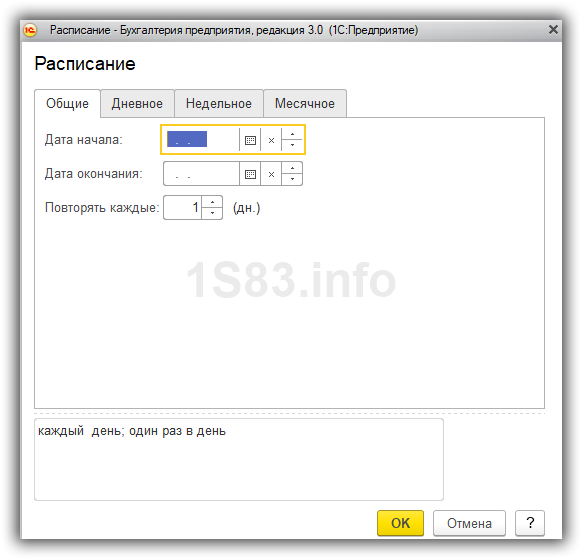
In addition to these settings, you must also specify the directory for storing copies (it is best to use Google Drive or Yandex Disk) and how many backups to store:
Backup tools of the operating system and third-party programs
In the event of a database failure, you get maximum flexibility when restoring databases using the full recovery model. In addition to saving changes to data stored in the transaction log, the complete recovery model allows you to restore the database at a specific point in time.
Method: copying the configuration file
Disaster recovery is a process that you can use to restore information systems and data if a disaster occurs. Some examples of natural disasters include a natural or man-made disaster, such as a fire or a technical disaster. Disaster recovery planning is a job that is dedicated to preparing all the actions that must occur in response to a disaster. Planning includes choosing a strategy to help recover valuable data.
Quite a lot has been said and written about the need to periodically save the results of our activities when working with a personal computer, so we will not repeat these common truths. The information base, in its essence, is the fruit of a large group of people, which is why it is important to know how to properly configure backup in 1C.
To be more secure in such cases, we recommend storing already recovered data for no more than 30 minutes. Intervals on a separate server, preferably located at a remote distance from your production server. While this may be an expensive backup strategy, it will work for at least two purposes.
Connect your users to the already restored database and restore it from scratch. Keep your data away from a potential disaster area. . A strategy that includes only full backups is somewhat limited by what you can restore. In principle, you can restore only the full backup time, as shown in the figure. For this reason, if you need to avoid data loss and the Data cannot be recreated, log backups are also included, as shown in the figure.
Backup tools of the operating system and third-party programs
When 1C is in file mode, database tables are stored in a single file. Its location can be seen at the bottom of the program launch window (Fig. 1).
The address bar indicated after the “File =” inscription is the place where we need to look for a file with the 1CD extension (Fig.2).
Uploading a copy of the database to a file
Backup strategy with full backup. Backup strategy with full and backup logs. Imagine log backups being taken every 30 minutes. As long as all the backups are available, this means that when you back up the transaction log every half hour, you can guarantee that you will never lose your job for half an hour. However, this may not be the best strategy. The first thing to do would be to backup the tail and start the recovery.
 Fig.2
Fig.2
List of further possible actions:
- Copy this file to another folder or to another physical medium;
- Using the archiver program to archive the file and place it in the repository.
Naturally, these actions must be performed periodically and preferably in those moments when the minimum number of changes is made to the database. For small-volume databases with a small document flow, the period can range from one backup per month to a couple of times a week. Large companies, it is desirable to make backups every day.
A tail-log backup is a transaction log backup that includes a portion of a log that has not previously been copied. Tail backup does not truncate the log and is usually used when the data files for the database become inaccessible, but the log file is not damaged.
To restore the database to a point of distress would mean restoring a full backup last Sunday, and then backing up to 336 logs. Depending on how much data was in the database per week, this could be a huge transaction log, which will be very long to answer. This is clearly not an optimal recovery strategy.
Some programs allow you to customize an arbitrary archiving schedule by setting the date of the copy creation in the name of the saved file.
Backup technology implemented in 1C
The 1C platform itself implements the following backup mechanism:
- Making sure that there are no users in the database, open it in the configurator mode;
- Select the menu item Administration;
- Click "Unload information database";
- In the directory selection window that opens, select the location for storing the backup;
- Set the name for the file with dt extension, in which the database tables will be saved;
- We wait.
If there is at least one user in the database, the saving will be interrupted and the message “Error of exclusive blocking” will appear on the screen (Fig.3).
To mitigate this problem, some strategies use more frequent full backups, but they can be prohibitively large, for example, every day. The alternative is to use differential backups that contain only data that has been modified since the previous full backup. Continuing our example, this strategy is illustrated in the figure.
Application of backup strategy for 1C information base
Backup strategy with full, log and differential backups. It was a fairly simple and contrived example, but it clearly shows the advantages of each type of backup. The frequency is set to “Weekly” weekly every week on Sunday.
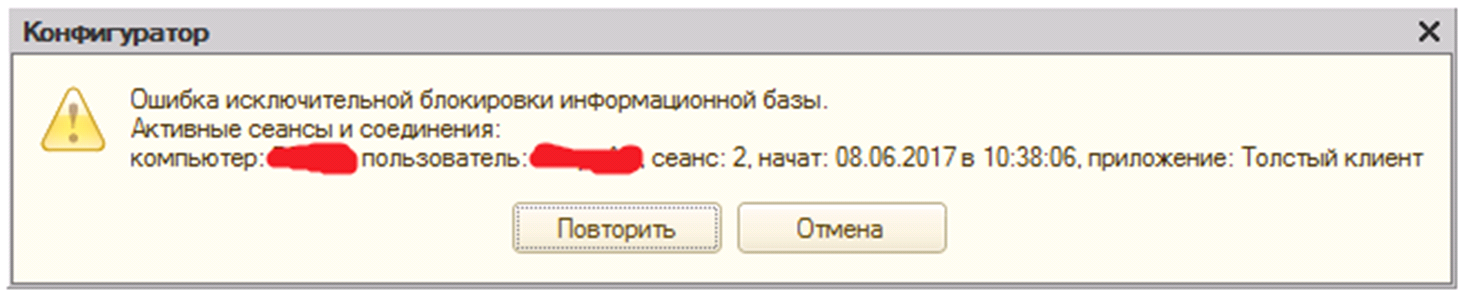 Pic.3
Pic.3
Depending on the volume of the database, the unloading process can take from several minutes to several tens of minutes. Very large databases in this mode cannot be saved, as restrictions on the part of the file system begin to apply.
It is important to select “Overwrite” in “If Backup Files Exist” to avoid overlapping full backup files up. It is also recommended to select “Check backup integrity”. Although not required, validating backups is a good practice.
Backup Verification verifies the physical integrity of the backup so that all the files in the backup are readable and can be restored, and that you can restore the backup if you need to use it. The next step for an effective backup plan is to create daily differential backups. Each daily differential backup will contain information from the moment of creating a full backup to the moment of creating a differential backup, in other words, each subsequent differential backup will accumulate data from previous differential backups, and it would be safe to overwrite previous backups with a new one.
Despite some restrictions on the size of the receiver file, this method is perfect for both file and client-server operation.
Backup 1C server
Depending on which DBMS serves as the storage medium for the 1C database tables, the backup technology also differs significantly.
Make sure that you select “Transaction Log” and “Overwrite” in the “If there are backup files” section. This will make sure that with each new differential backup we launch a new set of transaction log backups. All the following transaction log files will be executed hourly and must be added to the previous transaction log.
It is very important to select “Add” when creating an hour backup. Now it's time to check that all backups are working and saved to the specified destination. Now let's verify that the backup is created and saved in the specified location.
In our country, the most common were:
- Microsoft SQL server, the free version of which contains several cropped functionality;
- PostgreSQL is an absolutely free database server with a fairly user-friendly interface.
More than one scientific article can be devoted to a detailed description of backup data saving in sql mode. Here I would also like to note that all actions are intuitively simple and come down to calling the context menu of the database in the database management console (Fig.4).
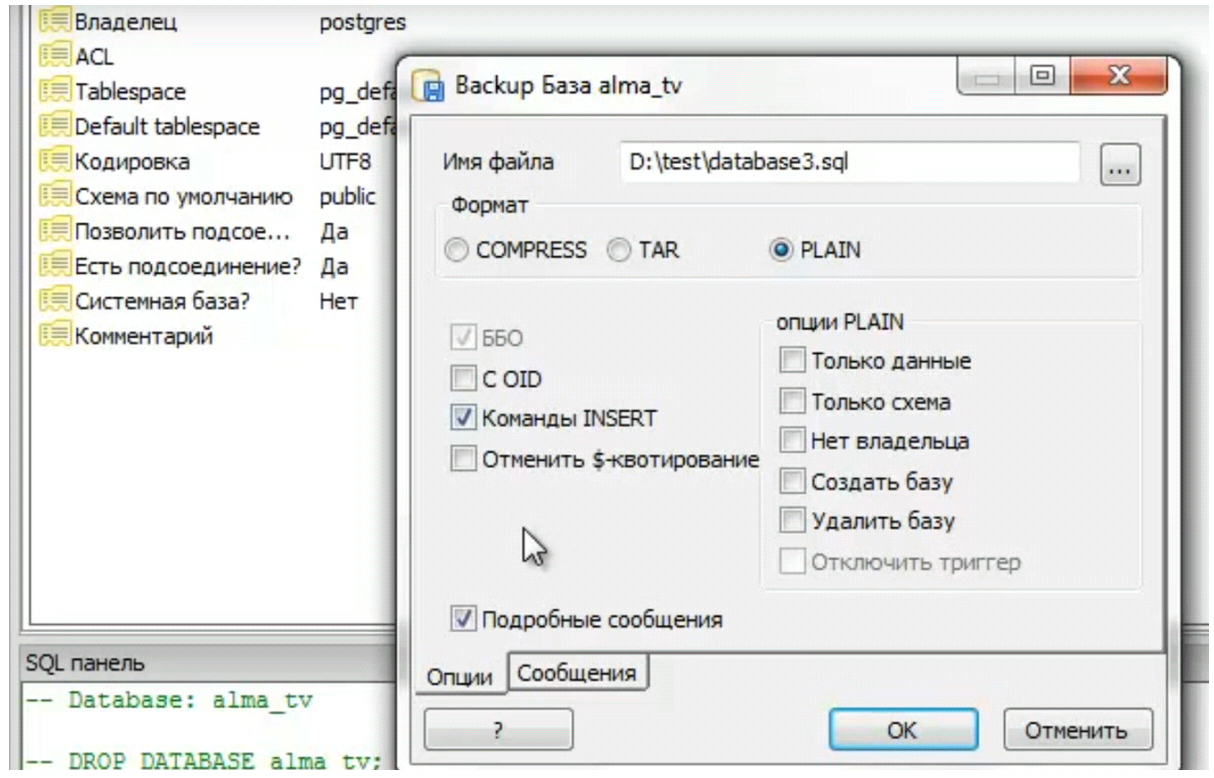 Pic.4
Pic.4
Backup temporary file external processing
Of course, we can say that external processing is not part of the database, but sometimes there are times when they have to be restored.
Consider this problem: when developing an external processing module, there was a power surge. In some cases, this is not a problem, and in some cases, re-opening the processing gives an error (Figure 5):
 Fig. five
Fig. five
A detailed description of the error reports "Invalid data storage format." So more than a week's work can be lost.
What to do? First of all do not panic! And in no case do not run 1C !!!
- In the user’s folder there is a TEMP directory (for Windows 7 it is located at C: \\ Users \\ UserName \\ AppData \\ Local), where 1C saves user data;
- The mask of similar files v8_ * and the extension tmp;
- Before starting the program, it is necessary to pick up all files in the name of which there is a specified mask in another place;
- On the copies of these files, change their extension to epf;
- Try to open them in the configurator.
If you run the program before this algorithm, the files will be overwritten, and it is unlikely to restore processing.