一次元配列のバブルソート法c。 バブルソート(パスカル)。 そのような変わった名前はどこから来たのですか?
交換の種類のクラスからの最速の方法がいわゆるであるということを誰もが完全によく知っています クイックソート..。 彼らはそれについての論文を書き、ハブレに関する多くの記事がそれに専念し、複雑なハイブリッドアルゴリズムがそれに基づいて発明されています。 しかし、今日は話していません クイックソート、しかし別の交換方法について-古き良き バブルソート そしてその改善、修正、突然変異および多様性。
これらの方法による実際の消耗はそれほど熱くはなく、多くのhabrapユーザーはファーストクラスでこれらすべてを経験しました。 したがって、この記事は、アルゴリズムの理論に興味を持ち、この方向への第一歩を踏み出している人々を対象としています。
画像:泡
今日は最も単純なものについて話します ソーティングエクスチェンジ.
誰かが興味を持っているなら、私は他のクラスがあると言います- 選択ソート, インサートで並べ替え, マージソート, 配布ソート, ハイブリッドソート そして 並列ソート..。 ちなみにもっとあります 難解な分類..。 これらはさまざまな偽の、根本的に実現不可能な、コミックやその他の疑似アルゴリズムであり、ITユーモアハブでいくつかの記事を書く予定です。
しかし、これは今日の講義とは何の関係もありません。今では、交換による単純な並べ替えにのみ関心があります。 交換仕分け自体もたくさんあるので(私は十数以上知っています)、いわゆるを検討します バブルソート そしてそれに密接に関連する他のいくつか。
上記の方法のほとんどすべてが非常に遅く、時間の複雑さの詳細な分析がないことを事前に警告します。 速いものもあれば遅いものもありますが、大まかに言えば、平均して O(n 2)。 また、プログラミング言語での実装で記事を乱雑にする理由はありません。 興味のある人は、Rosetta、Wikipedia、またはその他の場所でコード例を簡単に見つけることができます。
しかし、交換ソートに戻ります。 順序付けは、アレイ上で複数の連続した反復を行い、要素のペアを相互に比較した結果として発生します。 比較された要素が相互に関連してソートされていない場合は、それらを交換します。 唯一の問題は、アレイをどのように正確にバイパスするか、そしてどの原則によって比較のためにペアを選択するかです。
参照バブルソートではなく、...というアルゴリズムから始めましょう。
愚かな仕分け
並べ替えは本当にばかげています。 アレイを左から右にトラバースし、途中で隣接するものを比較します。 相互にソートされていない要素のペアに遭遇した場合、それらを交換して、正方形の1つ、つまり最初に戻ります。 もう一度調べて配列を確認し、隣接する要素の「間違った」ペアに再び遭遇した場合は、場所を変更して最初からやり直します。 配列が徐々に整理されるまで続けます。「だから、どんな愚か者も分類する方法を知っている」-あなたは言う、そしてあなたは絶対に正しいだろう。 そのため、並べ替えは「バカ」と呼ばれます。 この講義では、この方法を一貫して改善および変更します。 今、彼は一時的な困難を抱えています O(n 3)、1つの修正を行った後、すでに O(n 2)、それから私たちはもう少しスピードアップし、そしてもっとスピードアップし、そして最終的に私たちは得るでしょう O(n ログ n)-そしてそれは「クイックソート」ではありません!
ばかげた種類に1つの改善を加えましょう。 ウォーク中に2つの隣接するソートされていない要素を見つけて交換したので、アレイの最初にロールバックせず、静かに最後まで歩き続けます。
この場合、私たちの前にはよく知られている...
バブルソート
または 簡単な交換による並べ替え..。 このジャンルの不滅の名作。 アクションの原則は単純です。最初から最後まで配列を調べ、同時にソートされていない隣接要素を交換します。 最初のパスの結果として、最大要素が最後の場所に「ポップアップ」します。 ここで、配列のソートされていない部分(最初の要素から最後から2番目の要素まで)を再度調べ、途中でソートされていないネイバーを変更します。 2番目に大きい要素は最後から2番目の場所にあります。 同じ精神で続けて、配列の絶えず減少するソートされていない部分をバイパスし、見つかった最大値を最後までプッシュします。高値を最後まで押すだけでなく、低値を最初に移動すると、...
シェーカーソーティング
彼女はいる シャッフルソート、 彼女 カクテルソーティング..。 プロセスは「バブル」のように始まります。私たちは最大限を裏庭に押し出します。 その後、180 0を回って反対方向に進みますが、すでに最初に転がっています。最大ではなく、最小です。 配列の最初と最後の要素を並べ替えたら、もう一度いくつかの攻撃を行います。 何度か行ったり来たりした後、私たちはリストの真ん中に行き着きます。ハイとローの両方がアレイに沿って必要な方向に交互に移動するため、シェーカーソートはバブルソートよりも少し速く動作します。 彼らが言うように、改善は明らかです。
ご覧のとおり、列挙プロセスで創造性を発揮すると、重い(軽い)要素を配列の最後に押し出す方が速くなります。 したがって、職人はリストをバイパスするためにもう1つの非標準の「ロードマップ」を提案しました。
奇数-偶数ソート
今回は、アレイを前後に移動するのではなく、左から右への体系的なトラバースのアイデアに戻りますが、より広いステップを踏むだけです。 最初のパスで、奇数のキーを持つ要素が偶数の場所にある隣接要素と比較されます(1番目と2番目、3番目と4番目、5番目と6番目などを比較します)。 次に、逆に、「偶数」要素と「奇数」要素を比較/変更します。 次に、再び「奇数-偶数」、次に「偶数-奇数」。 アレイを2回連続して通過した後(「奇数-偶数」および「偶数-奇数」)、交換が発生しなかった場合、プロセスは停止します。 それで彼らはそれを整理しました。通常の「バブル」では、各パス中に、現在の最大値をアレイの最後まで体系的に絞り出します。 偶数と奇数のインデックスに沿ってスキップすると、多かれ少なかれすべての大きな配列要素が1回の実行で同時に右の1つの位置にプッシュされます。 それはより速くなります。
後者を分析してみましょう 減少* にとって Sortuvannya Bulbashkoy** - Sortuvannyaコンビネーション***。 この方法は非常に迅速に注文します。 O(n 2)その最悪の複雑さです。 平均して、 O(n ログ n)、そして最高でも、あなたは信じられないでしょう O(n)。 つまり、「クイックソート」に対して非常に価値のある競合相手であり、これは、再帰を使用せずに注意してください。 しかし、今日は巡航速度については深く掘り下げないことを約束しました。話をやめて、直接アルゴリズムに進みます。

亀はすべてのせいです
少し背景。 1980年、Wlodzimierz Dobosiewiczは、バブルソーティングとその派生物の動作が非常に遅い理由を説明しました。 それはすべてカメのせいです..。 タートルはリストの最後にある小さなアイテムです。 お気づきかもしれませんが、バブルの並べ替えは「ウサギ」(バブシュキンの「ウサギ」と混同しないでください)、つまりリストの一番上にある大きなアイテムを対象としています。 彼らは非常に活発にフィニッシュラインに移動します。 しかし、遅い爬虫類はしぶしぶ最初まで這う。 を使用して「トルティーヤ」をカスタマイズできます ヘアブラシ.画像:有罪のカメ
櫛で並べ替え
「バブル」、「シェーカー」、「偶数奇数」では、アレイを反復処理するときに、隣接する要素が比較されます。 「コーミング」の主なアイデアは、最初に比較対象の要素間で十分に大きな距離を取り、配列が順序付けられているときに、この距離を最小に狭めることです。 したがって、アレイをコーミングして、徐々に滑らかにして、よりきちんとしたストランドにします。とにかく比較された要素間の最初のギャップを考慮するのが良いですが、と呼ばれる特別な値を考慮に入れます 削減係数、その最適値は約1.247です。 まず、要素間の距離は、配列のサイズをで割った値に等しくなります。 削減係数 (結果は自然に最も近い整数に丸められます)。 次に、このステップで配列を調べた後、ステップを次のように分割します。 削減係数 リストをもう一度確認します。 これは、インデックス間の差が1に達するまで続きます。 この場合、配列は通常のバブルでソートされます。
最適値は実験的および理論的に確立されています 削減係数:

この方法が発明されたとき、70年代と80年代の変わり目にそれに注意を払う人はほとんどいませんでした。 10年後、プログラミングがIBMの多くの科学者やエンジニアでなくなり、すでに雪崩のように大衆的な性格を獲得していたとき、この方法は1991年にStephenLaceyとRichardBoxによって再発見され、研究され、普及しました。
実は、バブルソートなどについてお話ししたかったのはそれだけです。
- ノート
* 減少 ( ukr。)-改善
** Sortuvannyabulbashkoy( ukr。) - バブルソート
*** Sortuvannyaコンバイナー( ukr。)-コームで並べ替え
要素0から最後の要素まで、配列を上から下に配置します。
この方法の背後にある考え方:ソートステップは、配列を下から上に移動することで構成されます。 隣接する要素のペアが途中で見られます。 いくつかのペアの要素が間違った順序である場合、それらを交換します。

ゼロがアレイを通過した後、「トップ」は「最も軽い」要素になります。したがって、バブルとの類似性があります。 次のパスは上から2番目の要素に対して行われるため、2番目に大きい要素が正しい位置に持ち上げられます...
要素が1つだけ残るまで、配列の減少し続ける下部に沿ってパスを作成します。 シーケンスは昇順であるため、これでソートは終了します。

テンプレート
比較と交換の平均数には、2次の成長順序があります。シータ(n 2)から、バブルアルゴリズムは非常に遅く、効果がないと結論付けることができます。
それにもかかわらず、それは大きなプラスを持っています:それはシンプルで、どんな方法でも改善することができます。 私たちが今やろうとしていること。
まず、どの通路でも交換が行われなかった場合の状況を考えてみましょう。 どういう意味ですか?
これは、すべてのペアが正しい順序になっているため、配列がすでにソートされていることを意味します。 また、プロセスを続行することは意味がありません(特に、配列が最初からソートされている場合)。
したがって、アルゴリズムの最初の改善点は、特定のパスで交換が実行されたかどうかを記憶することです。 そうでない場合、アルゴリズムは終了します。
交換自体の事実だけでなく、最後の交換のインデックスkも覚えていれば、改善プロセスを継続できます。 実際、インデックスがk未満の隣接する要素のすべてのペアは、すでに必要な順序になっています。 それ以上のパスは、所定の上限iに移動する代わりに、インデックスkで終了できます。
アルゴリズムの質的に異なる改善は、以下の観察から得ることができます。 下からの軽い泡は1回のパスで上に上昇しますが、重い泡は最小速度で下降します。つまり、反復ごとに1ステップです。 したがって、配列2 3 4 5 6 1は1パスでソートされ、シーケンス6 1 2 3 45をソートするには5パスかかります。
この影響を回避するために、連続するパスの方向を変更できます。 結果として得られるアルゴリズムは、「 シェーカーソーティング".
テンプレート
説明されている変更は、メソッドの有効性にどのように影響しましたか? 比較の平均数は減少しましたが、O(n 2)のままですが、交換の数はまったく変化していません。 操作の平均(最悪)数は2次のままです。
追加のメモリは明らかに必要ありません。 改善された(ただし初期ではない)メソッドの動作は非常に自然であり、ほぼソートされた配列はランダムな配列よりもはるかに高速にソートされます。 バブルソートは安定していますが、ソートシェーカーはこの品質を失います。
実際には、バブル方式は、改善されたとしても、残念ながら遅すぎます。 したがって、ほとんど使用されません。
詳細カテゴリ:並べ替えと検索バブルソート(Exchangeソート)は、実装が簡単で非効率的なソートアルゴリズムです。 この方法は、アルゴリズム理論の過程で最初に研究されたものの1つですが、実際にはほとんど使用されていません。
アルゴリズムは、ソートされる配列を繰り返し通過することで構成されます。 パスごとに、要素がペアで順番に比較され、ペアの順序が正しくない場合、要素が交換されます。 アレイを通過するパスは1回繰り返されるか、次のパスで交換が不要になるまで繰り返されます。つまり、アレイがソートされます。 アルゴリズムが内側のループを通過するたびに、配列の次に大きい要素が前の「最大の要素」の隣の配列の最後に配置され、最小の要素が1つの位置を配列の先頭に移動します(「フロート」は水中の泡のように目的の位置に移動します。 およびアルゴリズムの名前)。
| 最悪の時間 | |
|---|---|
| ベストタイム | |
| 平均時間 | |
| メモリコスト |
アルゴリズムの仕組みの例
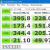
数字の配列「51 4 2 8」を取得し、バブルソートを使用して値を昇順でソートします。 この段階で比較される要素が強調表示されます。
最初のパス:
(5 1 4 2 8) (1 5 4 2 8)、ここでアルゴリズムは最初の2つの要素を比較し、それらを交換します。 (1 5 4 2 8) (1 4 5 2 8)、以来場所を交換します (1 4 5 2 8) (1 4 2 5 8)、以来場所を交換します (1 4 2 5 8 ) (1 4 2 5 8 )、ここで、要素はそれらの場所()にあるため、アルゴリズムはそれらを交換しません。2番目のパス:
(1 4 2 5 8) (1 4 2 5 8) (1 4 2 5 8) (1 2 4 5 8)、場所を入れ替える理由 (1 2 4 5 8) (1 2 4 5 8) (1 2 4 5 8 ) (1 2 4 5 8 )配列は完全にソートされましたが、アルゴリズムはこれが当てはまるかどうかを認識していません。 したがって、彼はフルパスを作成し、要素の順列がなかったことを確認する必要があります。
3番目のパス:
(1 2 4 5 8) (1 2 4 5 8) (1 2 4 5 8) (1 2 4 5 8) (1 2 4 5 8) (1 2 4 5 8) (1 2 4 5 8 ) (1 2 4 5 8 )これで配列がソートされ、アルゴリズムを完了できます。
さまざまなプログラミング言語でのアルゴリズムの実装:
Intel構文
Mov bx、オフセット配列mov cx、n for_i:dec cx xor dx、dx for_j:cmp dx、cx jae exit_for_j jbe no_swap mov ah、byte ptr bx mov byte ptr bx、al mov byte ptr bx、ah no_swap:inc dx jmp for_j exit_for_j:ループfor_i
AT&T構文(GNU)
テキスト#voidbubble_sort(unsigned * array、unsigned length); .globlbubble_sort .typebubble_sort、@ functionbubble_sort:mov 8(%esp)、%ecx#unsigned length cmp $ 1、%ecx jbe exit mov 4(%esp)、%eax#unsigned * array dec%ecx for_ecx:xor% edi、%edi for_edi:mov(%eax、%edi、4)、%ebx cmp%ebx、4(%eax、%edi、4)jae no_xchng mov 4(%eax、%edi、4)、%edx mov %edx、(%eax、%edi、4)mov%ebx、4(%eax、%edi、4)no_xchng:inc%edi cmp%edi、%ecx jne for_edi loop for_ecx exit:ret
C
#define SWAP(A、B)(int t \u003d A; A \u003d B; B \u003d t;)voidbubblesort(int * a、int n)(int i、j; for(i \u003d n-1; i\u003e 0 ; i-)(for(j \u003d 0; j< i; j++) { if (a[j] > a)SWAP(a [j]、a); ))))
C ++
テンプレートの使用
#include
テンプレートを使用せずに
ボイドバブル(int * a、int n)(for(int i \u003d n-1; i\u003e \u003d 0; i-)(for(int j \u003d 0; j< i; j++) { if (a[j] > a)(int tmp \u003d a [j]; a [j] \u003d a; a \u003d tmp;))))
C#
Void BubbleSort(int A)(for(int i \u003d 0; i< A.Length; i++) { for (int j = i+1; j < A.Length; j++) { if (A[j] < A[i]) { var temp = A[i]; A[i] = A[j]; A[j] = temp; } } } }
デルファイ
1次元動的整数配列の並べ替え:
タイプTIntVec \u003d整数の配列; ...プロシージャBubbleSort(var a:TIntVec); var i、p、n:整数; b:ブール; 開始n:\u003d長さ(a); nの場合< 2 then exit; repeat b:= false; Dec(n); if n > 0 then for i:\u003d 0 to n-1 do if a [i]\u003e a then begin p:\u003d a [i]; a [i]:\u003d a; a:\u003d p; b:\u003d true; 終わり; bでないまで; 終わり;
D
ボイドbubbleSort(エイリアスop、T)(T inArray)(foreach(i、ref a; inArray)(foreach(ref b; inArray)(if(mixin(op))(auto tmp \u003d a; a \u003d b; b \u003d tmp;))))
Fortran
Do i \u003d n-1,1、-1 do j \u003d 1、i if(a(j).gt.a(j + 1))then t \u003d a(j)a(j)\u003d a(j + 1 )a(j + 1)\u003d t endif enddo enddo
Java
ボイドバブルソート(int arr)(for(int i \u003d 0; i< arr.length-1; i++){ for (int j = i+1; j < arr.length; j++){ if (arr[i] < arr[j]) { int t = arr[i]; arr[i] = arr[j]; arr[j] = t; } } } }
パスカル
i:\u003d n-1から1do(nは配列Mのサイズ)for j:\u003d 1 to i do if M [j]\u003e M then begin tmp:\u003d M [j]; M [j]:\u003d M; M:\u003d tmp; 終わり; 書き込み( "出力値M:"); for i:\u003d 1 to n do write(M [i]:4); writeln;
改善されたバブルソートアルゴリズム:
P:\u003d True; (順列はありますか?)K:\u003d 1; (ビュー番号)P Do Begin P:\u003d false; For i:\u003d 1 To n-k Do If X [i]\u003e X Then Begin A:\u003d X [i]; X [i]:\u003d X; X:\u003d A; P:\u003d true; 終わり; k:\u003d k + 1; 終わり;
Perl
For(@out)(for(0 .. $ N-1)(if($ out [$ _] gt $ out [$ _ + 1])(($ out [$ _]、$ out [$ _ + 1])\u003d($ out [$ _ + 1]、$ out [$ _]);)))
ルビー
Arr \u003d swap \u003d true size \u003d arr.length-1 while swap swap \u003d false for i in 0 ... size swap | \u003d arr [i]\u003e arr arr [i]、arr \u003d arr、arr [i] if arr [ i]\u003e arr end size- \u003d 1 end puts arr.join( "")#output \u003d\u003e 1 3 3 5 8 10 11 12 17 20
Python
Def swap(arr、i、j):arr [i]、arr [j] \u003d arr [j]、arr [i] defbubble_sort(arr):i \u003d len(arr)while i\u003e 1:for j in xrange (i-1):arr [j]\u003e arrの場合:スワップ(arr、j、j + 1)i- \u003d 1
VBA
Sub Sort(Mus()As Long)Dim i As Long、tmp As Long、t As Boolean t \u003d True Do While tt \u003d False For i \u003d 0 To UBound(Mus())-1 If Mus(i)\u003e Mus( i + 1)次に、tmp \u003d Mus(i)Mus(i)\u003d Mus(i + 1)Mus(i + 1)\u003d tmp t \u003d True End If Next Loop End Sub
PHP
$ size \u003d sizeof($ arr)-1; for($ i \u003d $ size; $ i\u003e \u003d 0; $ i-)(for($ j \u003d 0; $ j<=($i-1); $j++) if ($arr[$j]>$ arr [$ j + 1])($ k \u003d $ arr [$ j]; $ arr [$ j] \u003d $ arr [$ j + 1]; $ arr [$ j + 1] \u003d $ k;))
JavaScript
関数sortBubble(data)(var tmp; for(var i \u003d data.length-1; i\u003e 0; i-)(for(var j \u003d 0; j< i; j++) { if (data[j] > data)(tmp \u003d data [j]; data [j] \u003d data; data \u003d tmp;)))return data; )
JavaFX
関数bubbleSort(seq:Number):Number(var sort \u003d seq; var elem:Number; for(n in reverse)(for(i in)(if(sort< sort[i]){ elem = sort[i]; sort[i] = sort; sort = elem; } } } return sort; }
ネメルル
System.Consoleの使用; Nemerle.Collectionsを使用する; def arr \u003d配列; foreach(i in)foreach(j in)when(arr [j]\u003e arr)(arr [j]、arr)\u003d(arr、arr [j]); WriteLine($ "ソートされたリストは$(arr.ToList())");
TurboBasic 1.1
CLS RANDOMIZE TIMER DEFINT X、Y、N、I、J、DN \u003d 10 "32 766-62.7 SEC DIM Y [N]、Y1 [N]、Y2 [N]、Y3 [N]、Y4 [N]" FRE (-1)\u003d 21440-21456 PRINT "ZAPOLNENIE MASSIVA ELEMENTAMI" FOR X \u003d 1 TO NY [X] \u003d X PRINT Y [X]; 次のX:PRINT PRINT "PEREMESHIVANIJE ELEMENTOV MASSIVA" PRINT "SLUCHAINYE CHISLA" FOR X \u003d 1 TO N YD \u003d Y [X] XS \u003d INT(RND * N)+1 PRINT XS; Y [X] \u003d Y Y \u003d YD NEXT X:PRINT PRINT "PEREMESHANNYJ MASSIV" FOR X \u003d 1 TO N PRINT Y [X]; 次のX:「ALGORITM」SORTIROVKA PROSTYM OBMENOM "O(N ^ 2)MTIMER FOR J \u003d 1 TO N-1 STEP 1 F \u003d 0 FOR I \u003d 1 TO NJ STEP 1" IF Y [I]\u003e Y THEN D \u003d Y [I]:Y [I] \u003d Y:Y \u003d D:F \u003d 1 IF Y [I]\u003e Y THEN SWAP Y [I]、Y:F \u003d 1 LOCATE 8,1 REM PRINT "ANYMACIJA SORTIROVKI" REM FOR X1 \u003d 1からNのREMアニメーションブロック印刷Y; REM NEXT X1:PRINT REM DELAY .5 REM NEXT I IF F \u003d 0 THEN EXIT FOR NEXT J T1 \u003d MTIMER PRINT "OTSORTIROVANNYJ MASSIV" FOR X \u003d 1 TO N PRINT Y [X]; 次のX:PRINT PRINT "ELAPSED TIME \u003d"; T1
前述のように、このアルゴリズムはパフォーマンスが低いため、実際にはほとんど使用されません。 バブルソートには、せいぜいO(n)時間かかり、平均して最悪の場合O(n2)かかります。
記事を書くとき、インターネットのオープンソースが使用されました:
かなりの数のソートアルゴリズムがあり、それらの多くは非常に特殊であり、狭い範囲の問題を解決し、特定のデータタイプで動作するように開発されました。 しかし、これらすべての種類の中で、最も単純なアルゴリズムは当然のことながらバブルソートであり、任意のプログラミング言語で実装できます。 その単純さにもかかわらず、それは多くのかなり複雑なアルゴリズムの根底にあります。 もう1つの同様に重要な利点は、その単純さです。したがって、目の前に追加の文献がなくても、すぐに覚えて実現することができます。
前書き
現代のインターネット全体は、データベースに収集された膨大な数の異なるタイプのデータ構造です。 ユーザーの個人データから高度にインテリジェントな自動システムのセマンティックコアに至るまで、あらゆる種類の情報を保存します。 言うまでもなく、データの並べ替えは、この膨大な量の構造化された情報において非常に重要な役割を果たします。 並べ替えは、データベース内の情報を探す前に必須の手順である可能性があり、並べ替えアルゴリズムの知識はプログラミングにおいて非常に重要です。 かなりの数のソートアルゴリズムがあり、それらの多くは非常に特殊であり、狭い範囲の問題を解決し、特定のデータタイプで動作するように開発されました。 しかし、これらすべての種類の中で、最も単純なアルゴリズムは当然です バブルソートこれは、任意のプログラミング言語で実装できます。 その単純さにもかかわらず、それは多くのかなり複雑なアルゴリズムの根底にあります。 もう1つの同様に重要な利点は、その単純さです。したがって、目の前に追加の文献がなくても、すぐに覚えて実現することができます。機械の目と人間の目で分類
高さの異なる5つの列を昇順で並べ替えるとします。 これらの列は、あらゆる種類の情報(株価、通信チャネルの帯域幅など)を意味する可能性があります。この問題のいくつかのバージョンを想像して、より明確にすることができます。 例として、復讐者を高さで並べ替えます。
コンピュータプログラムとは異なり、全体像を見ることができ、高さによる並べ替えを成功させるためにどのヒーローに移動する必要があるかをすぐに判断できるため、並べ替えは難しくありません。 このデータ構造を昇順で並べ替えるには、ハルクとアイアンマンの場所を入れ替えるだけで十分だとすでに推測しているでしょう。

完了しました。
これで、並べ替えが正常に完了します。 ただし、コンピューティングマシンは、あなたとは異なり、やや鈍く、データ構造全体を全体として見ることはできません。 その制御プログラムは、一度に2つの値しか比較できません。 この問題を解決するには、2つの数値をメモリに渡して比較操作を実行してから、別の数値のペアに移動し、すべてのデータが分析されるまで続けます。 したがって、ソートアルゴリズムは、次の3つのステップで非常に簡略化できます。- 2つの項目を比較します。
- それらの1つを交換またはコピーします。
- 次の項目に移動します。
バブルソートアルゴリズム
バブルソートは最も単純であると考えられていますが、このアルゴリズムを説明する前に、マシンのように一度に2人のヒーローだけを比較できる場合、アベンジャーを高さでソートする方法を想像してみましょう。 ほとんどの場合、(最も最適な)次のようにします。- アレイのゼロ要素(ブラックウィドウ)に移動します。
- 要素ゼロ(ブラックウィドウ)を最初の要素(ハルク)と比較します。
- ゼロ位置の要素が高い場合は、それらを交換します。
- それ以外の場合、要素がゼロ位置にある場合は、それらをその場所に残します。
- 右の位置に移動して比較を繰り返します(ハルクとキャプテンを比較してください)

このアルゴリズムを使用してリスト全体を1回のパスで確認すると、並べ替えは完全には実行されません。 ただし、その一方で、リストの最大のアイテムは右端の位置に移動されます。 最大の要素を見つけるとすぐに、最後に移動するまで常に交換するため、これは常に発生します。 つまり、プログラムが配列内のハルクを「見つける」とすぐに、それをリストの最後に移動します。

そのため、このアルゴリズムはバブルソートと呼ばれます。これは、その操作の結果、リスト内の最大の要素が配列の最上部にあり、小さい要素はすべて1つ左にシフトされるためです。

並べ替えを完了するには、配列の先頭に戻り、上記の5つの手順をもう一度繰り返し、必要に応じて要素を比較して移動し、左から右に移動する必要があります。 ただし、今回は、配列の終わりの1要素前にアルゴリズムを停止する必要があります。これは、最大の要素(Hulk)が正確に右端の位置にあることがすでにわかっているためです。

したがって、プログラムには2つのループが必要です。 わかりやすくするために、プログラムコードの確認に進む前に、次のリンクをたどって、バブルソートの操作の視覚化を確認してください。バブルソートの操作の視覚化
Javaでのバブルソートの実装
Javaで並べ替えがどのように機能するかを示すために、次のプログラムコードを示します。- 5つの要素を持つ配列を作成します。
- アベンジャーズを彼にロードします。
- 配列の内容を表示します。
- バブルソートを実装します。
- ソートされた配列を再表示します。
- into-要素を配列に挿入するためのメソッド。
- プリンター-配列の内容を1行ずつ表示します。
bubbleSorter-主な作業を行い、配列に格納されているデータを並べ替えます。これを再度個別に表示します。
public voidbubbleSorter()( //バブルの並べ替え方法 for(int out \u003d elems-1; out\u003e \u003d 1; out-)(//外部ループfor(int in \u003d 0; in out ; ++で)( //内部ループ if(a [in]\u003e a [in + 1]) //要素の順序が狂っている場合 toSwap(in、in + 1); //スワップするメソッドを呼び出す } } }
toSwap-必要に応じてアイテムを交換します。 このために、一時変数ダミーが使用され、最初の数値の値が書き込まれ、最初の数値の代わりに2番目の数値の値が書き込まれます。 その後、一時変数の内容が2番目の番号に書き込まれます。 これは、2つの要素を交換するための標準的な手法です。
そして最後に主な方法:
結論
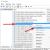
バブルソートアルゴリズムは、最も遅いものの1つです。 配列がN個の要素で構成されている場合、最初のパスでN-1の比較が実行され、2番目のパスでN-2、次にN-3などが実行されます。 つまり、パスの総数は次のようになります。 (N-1)+(N-2)+(N-3)+…+ 1 \u003d N x(N-1)/ 2 したがって、ソート時に、アルゴリズムは約0.5x(N ^ 2)の比較を実行します。 N \u003d 5の場合、比較の数は約10になり、N \u003d 10の場合、比較の数は45に増えます。したがって、要素の数が増えると、並べ替えの複雑さが大幅に増します。
アルゴリズムの速度は、パスの数だけでなく、実行する必要のある順列の数にも影響されます。 ランダムデータの場合、平均での順列の数は(N ^ 2)/ 4であり、パス数の約半分です。 ただし、最悪の場合、順列の数もN ^ 2/2になる可能性があります。これは、データが最初に逆の順序でソートされている場合です。 これはかなり遅いソートアルゴリズムであるという事実にもかかわらず、それがどのように機能するかを知り、理解することは非常に重要です。さらに、前述のように、これはより複雑なアルゴリズムの基礎です。 Jgd!
みなさん、こんにちは!
今日はバブルソートを見ていきます。 このアルゴリズムは学校や大学でよく使用されるため、Pascal言語を使用します。 では、並べ替えとは何ですか? 並べ替えとは、アイテムを最小から最大(昇順で並べ替え)または最大から最小(降順で並べ替え)に並べ替えることです。 配列は通常ソートされます。
さまざまな並べ替えアルゴリズムがあります。 多数のアイテムを並べ替えるのが得意なものもあれば、非常に少ないアイテムでより効率的なものもあります。 私たちのバブル法の特徴は次のとおりです。
長所:
- アルゴリズム実装のシンプルさ
- 美しい名前
- 最も遅いソート方法の1つ(実行時間はアレイの長さn 2に二次的に依存します)
- 実生活ではほとんど使用されていません(主に教育目的で使用されます)
アルゴリズム: 配列の要素を取得し、それを次の要素と比較します。要素が次の要素よりも大きい場合は、それらを交換します。 配列全体を調べた後、最大要素が「押し出され」、最後になることを確認できます。 したがって、その場所にはすでに1つの要素があります。 なぜなら それらをすべてそれらの場所に配置する必要があるため、配列の要素から1を引いた回数だけ、この操作を繰り返す必要があります。残りがそれらの場所にある場合、最後の要素は自動的に上昇します。
配列に戻りましょう:3 1 4 2
最初の要素「3」を取り、次の「1」と比較します。 なぜなら 「3」\u003e「1」の場合、場所を入れ替えます。
1 3 4 2
ここで、「3」と「4」を比較します。3つは4つ以下なので、何もしません。 次に、「4」と「2」を比較します。 4つは2つ以上なので、場所を入れ替えます:1 3 24。 サイクルは終わりました。 これは、最大の要素がすでにその場所にあるはずであることを意味します!! これがここで起こったことであることがわかります。 「4」(最大の要素)が配置されている場合は常に、ループが配列全体を通過した後も最後になります。 アナロジー-気泡が水に浮くように-私たちの要素は配列に浮かんでいます。 したがって、このアルゴリズムは「バブルソート」と呼ばれます。 次の要素を配置するには、ループを最初からやり直す必要がありますが、最後の要素はその場所にあるため、考慮できなくなります。
「1」と「3」を比較してください。何も変更しないでください。
「3」と「2」を比較してください-3つは2つ以上なので、場所を入れ替えます。 結局のところ:1 2 34。 2番目のサイクルを終了しました。 すでに2つのサイクルを実行しました。つまり、最後の2つの要素はすでにソートされていると自信を持って言えます。 3番目の要素を並べ替えるのは私たちの責任であり、4番目の要素は自動的に適切な場所に配置されます。 もう一度、最初の要素と2番目の要素を比較します。すべてが整っていることがわかります。つまり、配列は要素の昇順で並べ替えられていると見なすことができます。
現在、このアルゴリズムをPascalでプログラムする必要があります。 const n \u003d 4; (定数を設定します。これは配列の長さになります)var i、j、k:整数; (ネストされたループ用に2つの変数、要素を交換するために1つ)m:整数の配列。 (配列を開始します)begin(キーボードから配列を要求します:) Writeln( "配列を入力してください:"); for i:\u003d 1 to n do begin Writeln(i、 "element:"); Readln(m [i]); 終わり; (外側のループは、配列要素から1を引いた回数だけ内側のループを繰り返さなければならないという事実に責任があります。)for i:\u003d 1 to n-1 do begin(内側のループはすでに要素を繰り返し処理して相互に比較しています。)For j :\u003d 1 to ni do begin(要素が次の要素よりも大きい場合は、場所を入れ替えます。)m [j]\u003e mの場合、kを開始します:\u003d m [j]; m [j]:\u003d m; m:\u003d k; 終わり; 終わり; 終わり; (結果を出力します:) for i:\u003d 1 to n do Write(m [i]、 ""); 終わり。
結果は次のとおりです。