Bestimmungskoeffizient in Excel (Excel). Berechnung des Bestimmungskoeffizienten in Microsoft Excel
Für statistische Modelle ist es in vielen Fällen notwendig, die Genauigkeit der Prognose zu bestimmen. Dies erfolgt mit der Hilfe speziellen Berechnungen in Microsoft Excel.Und der Entschlossenheitskoeffizient wird verwendet. Es ist als R ^ 2 bezeichnet.
Statistische Modelle können je nach Koeffizient in hochwertige Anwendungen unterteilt werden. Von 0,8 bis 1 umfassen Modelle gute Qualität, ausreichend Qualitätsmodelle verfügen über einen Niveau von 0,5 bis 0,8 und minderer Qualität Es hat einen Bereich von 0 bis 0,5.
Methode zur Bestimmung der Genauigkeit mit der FIRSON-Funktion
IM lineare Funktion Der Bestimmungskoeffizient ist gleich dem Quadrat des Korrelationskoeffizienten. Sie können es mit der Verwendung berechnen spezialfunktion. Um mit dem Anfang zu beginnen, erstellen Sie eine Tabelle mit Daten.
Dann müssen Sie einen Ort auswählen, an dem das Ergebnis der Berechnung angezeigt wird, und klicken Sie auf die Schaltfläche Einfügen der Funktion.

Danach wird ein spezielles Fenster geöffnet. Die Kategorie muss "statistisch" wählen und CVGirson auswählen. Mit dieser Funktion können Sie den Korrelationskoeffizienten in Bezug auf die Pearson-Funktion des quadratischen Werts des Korrelationskoeffizienten \u003d Bestimmungskoeffizienten bestimmen.

Nach der Bestätigung der Aktion erscheint ein Fenster, in dem Sie "bekannte X-Werte" und "bekannte Werte y" in den Feldern einstellen müssen. Drücken Sie die "bekannten Werte y" mit der Maus mit der Maus und im Bedienfenster die Daten der Spalte Y zuordnen. Eine ähnliche Aktion erfolgt und mit einem anderen Feld, das Daten von der Tabelle H. auswählt.

Als Ergebnis dieser Aktionen ist der Wert des Bestimmungskoeffizienten in der Zelle, der zuvor ausgewählt wurde, um das Ergebnis anzuzeigen.

Bestimmung der Bestimmungskoeffizienten, wenn die Funktion nicht linear ist.
Wenn die Funktion nicht linear ist, können Sie auch das Excel Toolkit auch den Koeffizienten mit dem "Regression" -Oinma berechnen. Es ist im Datenanalysepaket zu finden. Aber zuerst müssen Sie dieses Paket aktivieren, indem Sie in den Abschnitt "Datei" und in der Liste "Open Options" teilnehmen.

Danach können Sie ein neues Fenster sehen, in dem Sie im Menü "Add-In" auswählen müssen, und in dem speziellen Feld zur Kontrolle von Superstrukturen, wählen Sie das "Excel-Add-In" und gehen Sie zu ihnen.

Nach Übergang zum Excel-Add-In wird ein neues Fenster angezeigt. Es ist für den Superstructure des Benutzers zu sehen. Wir legen ein Takt in die Nähe des "Analysepakets" und bestätigen die Aktion.

Sie finden es im Abschnitt "Daten", nachdem Sie das Wechseln auf die "Datenanalyse" auf der rechten Seite des Bildschirms klicken.

Nach dem Öffnen wird die Liste "Regression" gewählt und bestätigt die Aktion.

Danach erscheint ein neues Fenster, in dem Sie einrichten können. Mit den Eingabedaten können Sie den Wert der X- und Y-Intervalle anpassen, sondern es genügt, die entsprechenden Zellen der Argumente eines anderen Arguments hervorzuheben. Im Feld Zuverlässigkeitsstufe können Sie den gewünschten Indikator einstellen. Ausgangsparameter ermöglichen es Ihnen, anzugeben, wo das Ergebnis angezeigt wird. Wenn Sie beispielsweise das Display auf dem aktuellen Blatt auswählen, müssen Sie zunächst das Element "Ausgabeintervall" auswählen - und klicken Sie auf den Hauptfensterbereich, in dem das Ergebnis angezeigt wird, und die Zellkoordinaten werden das entsprechende Feld angezeigt. Am Ende bestätigen Sie die Aktion.

Das Ergebnis erscheint im Arbeitsfenster. Da wir den Bestimmungskoeffizienten berechnen, benötigen wir in den Ergebnissen einen R-Koeffizienten. Wenn Sie den Wert ansehen, können Sie sehen, was es auf die beste Qualität bezieht.

Das Verfahren zur Bestimmung des Bestimmungskoeffizienten für die Trendlinie
Mit einer Tabelle mit dem entsprechenden Wert erstellen, erstellen Sie einen Zeitplan. Um die Trendlinie darauf auszugeben, müssen Sie auf den Zeitplan klicken, nämlich der Bereich, in dem die Zeile erstellt wurde. Wählen Sie von oben in der Symbolleiste den Abschnitt "Layout" aus und wählen Sie "Trendlinie" aus. Danach im Kontext dieses Beispiel Die Liste wird "exponentielle Annäherung" ausgewählt.

Die Trendlinie wird in der Grafik als Kurve mit Schwarz angezeigt.

Um den Entschlossenheitskoeffizienten anzuzeigen, müssen Sie auf eine schwarze Kurve drücken rechtsklick Maus und wählen Sie in der Liste "Trend Line Format".

Danach erscheint ein neues Fenster. Darin müssen Sie das Kontrollkästchen markieren und die gewünschte Aktion auswählen (im Screenshot angezeigt). Aufgrund dessen wird der Koeffizient in der Grafik angezeigt. Schließen Sie das Fenster, nachdem es fertig war.

Nach dem Schließen des Trendline-Formatfensters im Arbeitsfenster können Sie den Wert des Bestimmungskoeffizienten sehen.

Wenn der Benutzer einen anderen Trendzeilentyp benötigt, können Sie im Fenster Trend Line-Format auswählen, das Sie auswählen. Ohne zu vergessen, es früher zu fragen, wenn Sie eine Trendlinie im Abschnitt "Layout" oder in erstellen kontextmenü. Wir vergessen auch nicht, das Flag für die Funktion R ^ 2 zu überprüfen.

Infolgedessen können Sie die Änderung der Trendlinie und der Anzahl der Genauigkeit sehen.

Nachdem Sie verschiedene Variationen der Trendlinien angesehen haben, kann der Benutzer das am besten geeignete für sich selbst geeignete Euro ermitteln, da ein Vertrauensanzeiger je nach Auswahl der Zeile variieren kann. Der maximale Koeffizient ist eine Einheit, was eine maximale Genauigkeit bedeutet, es ist jedoch nicht immer möglich, diesen Wert zu erreichen.
Somit wurden mehrere Möglichkeiten, den Bestimmungskoeffizienten zu finden, berücksichtigt. Der Benutzer kann für seine Zwecke optimal optimal wählen.
28 Okt.
Guten Tag, liebe Blog-Leser! Heute werden wir über eine nichtlineare Regression sprechen. Entscheidung lineare Regressionen Sie können den Link sehen.
Diese Methode Es wird hauptsächlich in der wirtschaftlichen Modellierung und der Prognose verwendet. Sein Ziel ist es, die Abhängigkeiten zwischen den beiden Indikatoren zu beschuldigen und zu identifizieren.
Grundtypen nichtlineare Regressionen sind:
- polynom (quadratisch, kubisch);
- hyperbolisch;
- leistung;
- indikativ;
- logarithmisch.
Es können auch verschiedene Kombinationen verwendet werden. Beispielsweise werden für Analysen der temporären Serien im Bankensektor, Versicherungen, demografische Studien von einer Gompezer-Kurve verwendet, die eine Art logarithmischer Regression ist.
In der Vorhersage mit nichtlinearen Regressionen, die Hauptsache, um den Korrelationskoeffizienten herauszufinden, der uns zeigt, ob es eine enge Verbindung von Honig mit zwei Parametern gibt oder nicht. Wenn der Korrelationskoeffizient nahe an 1 liegt, bedeutet dies in der Regel eine Verbindung, und die Prognose ist ziemlich genau. Ein weiteres wichtiges Element nichtlinearer Regressionen ist der durchschnittliche relative Fehler ( ABER ) Wenn es sich im Intervall befindet<8…10%, значит модель достаточно точна.
Daraufhin werden wir vielleicht den theoretischen Block beenden und auf praktische Berechnungen eingehen.
Wir verfügen über einen Autovertreibung über das Intervall von 15 Jahren (bezeichnen Sie IT X), die Anzahl der Messschritte ist ein Argument n, es gibt auch ein Umsatz für diese Zeiträume (wir bezeichnen es y), wir müssen vorhersagen, was sein wird Umsatz in der Zukunft. Bauen Sie die folgende Tabelle auf:
Um zu studieren, müssen wir die Gleichung lösen (Abhängigkeiten y von x): y \u003d AX 2 + BX + C + E. Dies ist eine gepaarte quadratische Regression. In diesem Fall wird in diesem Fall das kleinste Quadrate in diesem Fall zur Bestimmung unbekannter Argumente - A, B, c. Es wird zum System von algebraischen Gleichungen des Formulars führen:

Um dieses System zu lösen, verwenden wir zum Beispiel beispielsweise durch die Antriebsmethode. Wir sehen, dass der im System enthaltene Betrag bei unbekanntem Koeffizienten ist. Fügen Sie zum Berechnen ein paar Säulen an den Tisch (D, E, F, G, H) bzw. Schild, der Bedeutung von Berechnungen - in der Säule D ein, errichten Sie X in das Quadrat in E in den Würfel, in f in 4 grad, in g, x und y, in h auf a errect x in ein quadratisches und variablen von y.

Es stellt sich heraus, dass es mit dem Tisch der Form gefüllt ist, um die Gleichung zu lösen.


Wir bilden eine Matrix EIN. Systeme, bestehend aus Koeffizienten, die in den linken Teilen von Gleichungen unbekannt sind. Positionieren Sie es in der A22-Zelle und lass uns anrufen A \u003d.". Wir folgen dem System der Gleichungen, die wir zur Lösung der Regression gewählt haben.

Das heißt, in der B21-Zelle müssen wir die Menge der Säule aufsetzen, in der der X-Indikator im vierten Grad - F17 errichtet wurde. Ich bin gerade auf die Zelle gefallen - "\u003d F17". Als nächstes benötigen wir die Menge der Spalte, in der X im Cube - E17, dann streng auf das System gehen. Somit müssen wir die gesamte Matrix füllen.
In Übereinstimmung mit dem Cramer-Algorithmus mit einer Matrix A1, ähnlich einem, in dem anstelle der Elemente der ersten Säule Elemente der rechten Teile der Systemgleichungen platziert werden sollten. Das heißt, die Summe der X-Säule im Quadrat wird mit y, der Summe der XY-Säule und der Summe der Y-Säule multipliziert.

Wir benötigen auch zwei weitere Matrizen - wir nennen sie A2 und A3, in der die zweite und dritte Säule aus den Koeffizienten der richtigen Teile der Gleichungen bestehen. Das Bild wird wie folgt sein.

Nach dem gewählten Algorithmus müssen wir die Werte der Determinanten (Determinanten, d) der resultierenden Matrizen berechnen. Wir verwenden die multurierte Formel. Die Ergebnisse werden in den Zellen J21: K24 platziert.

Die Berechnung der Koeffizienten der Rin-Gleichung wird in Zellen entgegengesetzt, die den entsprechenden Determinanten durch die Formel entgegengesetzt sind: eIN. (in der Zelle M22) - "\u003d k22 / k21"; b. (in der Zelle M23) - "\u003d k23 / k21"; von(In der M24-Zelle) - "\u003d k24 / k21".
Wir erhalten unsere gewünschte Paare quadratische Regressionsgleichung:
y \u003d -0,074x 2 + 2,151x + 6,523
Lassen Sie uns die lineare Kommunikation durch den Korrelationsindex abschätzen.

Fügen Sie zum Berechnen einer zusätzlichen Spalte J zur Tabelle hinzu (nennen Sie es y *). Die Berechnung ist der folgende (entsprechend der von uns erhaltenen Regressionsgleichung) - "\u003d $ M $ 22 * \u200b\u200bB2 * B2 + $ M $ 23 * B2 + $ M $ 24".Positionieren Sie es in der Zelle J2. Es bleibt den AutoCill-Marker in die J16-Zelle.

Um die Beträge (Y-Y-Durchschnitt) 2 zu berechnen, fügen Sie die Spalten der Tabelle K und L mit den entsprechenden Formeln mit den entsprechenden Formeln hinzu. Der Durchschnitt der Spalte y wird mit der SRVNow-Funktion betrachtet.

Platzieren Sie in der K25-Zelle den Korrelationsindex-Berechnungsformel - "\u003d root (1- (k17 / l17))".

Wir sehen, dass der Wert von 0,959 sehr nahe an 1 ist, dann gibt es eine enge nichtlineare Verbindung zwischen Vertrieb und Jahren.
Es bleibt, die Qualität der Anpassung der resultierenden quadratischen Regressionsgleichung (Bestimmungsindex) zu bewerten. Es wird mit der quadratischen Formel Korrelationsindex berechnet. Das heißt, die Formel in der K26-Zelle ist sehr einfach - "\u003d k25 * k25".

Der Koeffizient von 0,920 ist nahe an 1, was auf eine hohe Qualität anzeigt.
Die letzte Aktion ist die Berechnung des relativen Fehlers. Fügen Sie eine Spalte hinzu und geben Sie die Formel ein: "\u003d ABS (((C2-J2 / C2), ABS-Modul, absoluter Wert. Wenn Sie den Marker nach unten und in der M18-Zelle verschieben, ziehen Sie den Durchschnittswert (SRVNA) ab, zuordnen Sie Prozentformatzellen. Das erhaltene Ergebnis - 7,79% erfolgt innerhalb der zulässigen Fehlerwerte<8…10%. Значит вычисления достаточно точны.
Wenn ein Bedarf an erhaltenen Werten erforderlich ist, können wir einen Zeitplan aufbauen.
Die Datei mit dem Beispiel ist beigefügt - Link!
Kategorien: / / ab 10/28/2017Eine der Indikatoren, die die Qualität des aufgebauten Modells in der Statistik beschreibt, ist der Bestimmungskoeffizient (R ^ 2), der auch als Wert der Genauigkeit der Annäherung bezeichnet wird. Damit können Sie den Niveau der Präzisionsvorhersage bestimmen. Lernen Sie, wie Sie diesen Indikator mit verschiedenen Excel-Tools berechnen können.
Abhängig von der Ebene des Bestimmungskoeffizienten ist es üblich, Modelle in drei Gruppen zu teilen:
- 0,8 - 1 - ein Modell von guter Qualität;
- 0,5 - 0.8 - Modell der akzeptablen Qualität;
- 0 - 0,5 - ein Modell von schlechter Qualität.
Im letzteren Fall weist die Qualität des Modells auf die Unmöglichkeit der Verwendung für die Prognose hin.
Die Wahl eines Verfahrens zur Berechnung des angegebenen Werts in Excel hängt davon ab, ob die Regression linear ist oder nicht. Im ersten Fall können Sie die Funktion verwenden Kvawson.Und in der zweiten müssen Sie ein spezielles Werkzeug aus dem Analysepaket verwenden.
Verfahren 1: Berechnung des Bestimmungskoeffizienten mit einer linearen Funktion
Finden Sie zunächst heraus, wie Sie den Bestimmungskoeffizienten mit einer linearen Funktion finden. In diesem Fall ist dieser Indikator gleich dem Quadrat des Korrelationskoeffizienten. Wir werden es mit der eingebetteten Excel-Funktion im Beispiel einer bestimmten Tabelle berechnet, die unten gezeigt ist.



Verfahren 2: Berechnung des Bestimmungskoeffizienten in nichtlinearen Funktionen
Die obige Option zum Berechnen des gewünschten Werts kann jedoch nur für lineare Funktionen verwendet werden. Was tun, um seine Berechnung in einer nichtlinearen Funktion zu berechnen? In Excel gibt es eine Gelegenheit. Es kann mit dem Werkzeug erfolgen "Regression"Welches ist ein integraler Bestandteil des Pakets "Datenanalyse".
- Bevor Sie jedoch das angegebene Werkzeug verwenden, sollten Sie sich selbst aktivieren "Analysepaket"was standardmäßig in Excel deaktiviert ist. In die Registerkarte gehen "Datei"und dann durch den Artikel gehen "Parameter".
- In dem Fenster, das eröffnet, machen Sie sich in den Abschnitt "Add-In" Verwenden der Navigation in das linke vertikale Menü. Am unteren Rand des rechten Fensters befindet sich das Feld "Steuerung". Aus der verfügbaren Liste gibt es Unterabschnitte den Namen "Excel Add-In ..."Klicken Sie dann auf die Schaltfläche "Gehen ..."Befindet sich rechts neben dem Feld.
- Das Fenster wird gestartet. In seinem zentralen Teil gibt es eine Liste der verfügbaren Add-Ons. Installieren Sie das Kontrollkästchen in der Nähe der Position "Analysepaket". Danach müssen Sie auf die Schaltfläche klicken. OK Auf der rechten Seite der Fensterschnittstelle.
- Werkzeugpaket. "Datenanalyse" In der aktuellen Instanz wird Excel aktiviert. Zugriff auf sie befindet sich auf dem Band auf der Registerkarte "Daten". Wechseln Sie in die angegebene Registerkarte und Ton auf der Schaltfläche "Datenanalyse" In der Einstellungsgruppe "Analyse".
- Aktiviertes Fenster "Datenanalyse" mit einer Liste der spezialisierten Informationsverarbeitungswerkzeuge. Wir weisen aus diesem Listenelement zuordnen "Regression" und Ton auf der Taste OK.
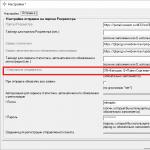
- Dann öffnet das Werkzeugfenster "Regression". Erster Einstellungsblock - "Eingabedaten". Hier in zwei Feldern müssen Sie die Adresse der Bereiche angeben, in denen sich die Werte des Arguments und der Funktion befinden. Setzen Sie den Cursor auf das Feld "Input Intervall y" und markieren Sie den Inhalt der Spalte auf dem Blatt "Y". Nachdem die Adresse des Arrays im Fenster angezeigt wird "Regression"Setzen Sie den Cursor in das Feld "Input Intervall y" und genau die gleiche Weise, wie Zellenspalten zuweisen "X".
In der Nähe der Parameter "Etikett" und "Constanta null" Flaggen geben nicht. Das Kontrollkästchen kann in der Nähe des Parameters installiert werden "Zuverlässigkeitsstufe" Geben Sie im entgegengesetzten Feld den gewünschten Wert des entsprechenden Indikators an (standardmäßig 95%) an.
In einer Gruppe "Ausgabeparameter" Sie müssen angeben, in welchem \u200b\u200bBereich das Ergebnis der Berechnung angezeigt wird. Es gibt drei Möglichkeiten:
- Bereich auf dem aktuellen Blatt;
- Ein anderes Blatt;
- Ein anderes Buch (neue Datei).
Stellen Sie Ihre Wahl in der ersten Ausführungsform fest, damit die Quelldaten und das Ergebnis auf einem Arbeitsblatt angeordnet sind. Setzen Sie den Schalter in der Nähe des Parameters "Ausgangsintervall". Auf dem Feld gegenüber diesem Artikel legen wir den Cursor ein. Klicken Sie auf die linke Maustaste auf dem leeren Element auf dem Blatt, das zur linken oberen Zelle der Ausgabentabelle der Berechnung ist. Die Adresse dieses Elements sollte im Fensterbereich hervorgehoben werden. "Regression".
Gruppenparameter "Überreste" und "Normale Wahrscheinlichkeit" Ich ignoriere, da die Aufgabe, die Aufgabe zu lösen, nicht wichtig ist. Danach sind wir Ton auf der Schaltfläche OKdas befindet sich in der oberen rechten Ecke des Fensters "Regression".
- Das Programm ergibt eine Berechnung basierend auf zuvor eingegebenen Daten und zeigt das Ergebnis an den angegebenen Bereich an. Wie Sie sehen, zeigt dieses Tool eine ziemlich große Anzahl von Ergebnissen auf verschiedenen Parametern an. Im Rahmen der aktuellen Lektion interessieren wir uns jedoch an dem Indikator "R Quadrat". In diesem Fall ist es gleich 0,947664, was das ausgewählte Modell als ein Modell von guter Qualität kennzeichnet.







Methode 3: Bestimmungskoeffizient für die Trendlinie
Zusätzlich zu den obigen Optionen kann der Bestimmungskoeffizient direkt für die Trendlinie in dem auf der Excel-Folie aufgebauten Grafik angezeigt werden. Finden Sie heraus, wie dies in einem bestimmten Beispiel erfolgen kann.
- Wir haben einen Zeitplan, der auf der Grundlage der Argumentabelle und der Funktionen der Funktion, die für das vorherige Beispiel verwendet wurde, aufgebaut. Wir werden eine Trendlinie dazu bauen. Klicken Sie auf eine beliebige Stelle des Bauraums, auf dem sich der Zeitplan linksklick befindet. In diesem Fall erscheint ein zusätzlicher Satz von Tabs auf dem Farbband - "Arbeiten mit Diagrammen". Auf die Registerkarte gehen "Layout". Ton auf der Schaltfläche "Trendlinie"das in dem Werkzeugblock veröffentlicht ist "Analyse". Ein Menü erscheint mit der Wahl der Art der Trendlinie. Starten Sie die Wahl auf dem Typ, der der spezifischen Aufgabe entspricht. Lassen Sie uns die Option für unser Beispiel auswählen. "Exponentielle Annäherung".
- Excel baut direkt in der Ebene des Erstellens einer Trendlinie in Form einer zusätzlichen schwarzen Kurve auf.
- Nun ist unsere Aufgabe, den tatsächlichen Bestimmungskoeffizienten anzuzeigen. Klicken Sie mit der rechten Maustaste auf die Trendlinie. Das Kontextmenü ist aktiviert. Stoppen Sie die Wahl an der Stelle "Trendlinienformat ...".

Um einen Übergang zum Fenster zum Trendlinienformat auszuführen, können Sie eine alternative Aktion vornehmen. Wir markieren die Trendlinie mit der linken Maustaste darauf. In die Registerkarte gehen "Layout". Ton auf der Schaltfläche "Trendlinie" Im Block "Analyse". In der Liste der Tonliste zum besten Punkt der Aktionsliste - "Zusätzliche Trendlinie Parameter ...".
- Nach einem der beiden obigen Aktionen wird das Formatfenster gestartet, in dem Sie zusätzliche Einstellungen erstellen können. Um unsere Aufgabe zu erfüllen, müssen Sie das Kontrollkästchen gegenüber dem Artikel überprüft werden "Platzieren Sie den Wert der Genauigkeit der Annäherung (R ^ 2) im Diagramm (R ^ 2). Es befindet sich am unteren Rand des Fensters. Das heißt, also beinhalten wir die Anzeige des Bestimmungskoeffizienten auf den Baubereich. Vergessen Sie nicht, auf die Schaltfläche zu klicken "Schließen" Am unteren Rand des aktuellen Fensters.
- Der Wert der Genauigkeit der Annäherung, dh der Wert des Bestimmungskoeffizienten wird auf einem Blatt im Baubereich angezeigt. In diesem Fall ist dieser Wert sichtbar, gleich 0,9242, der Annäherung als Modell von guter Qualität charakterisiert.
- Absolut auf diese Weise können Sie eine Bestimmungskoeffizient-Show für jede andere Art von Trendlinie einrichten. Sie können den Trendzeilentyp ändern, indem Sie einen Übergang durch die Schaltfläche in dem Band oder im Kontextmenü im Fenster seiner Parameter erstellen, wie oben gezeigt. Dann im Fenster selbst in der Gruppe "Trendlinie bauen" Sie können zu einem anderen Typ wechseln. Vergessen Sie nicht, die Kontrolle zu kontrollieren, um über Artikel zu sein "Platzieren Sie den Wert der Genauigkeit der Annäherung in das Diagramm" Das Kontrollkästchen wurde ausgewählt. Klicken Sie nach Abschluss der obigen Aktionen auf die Schaltfläche "Schließen" In der rechten unteren Ecke des Fensters.
- Mit einem linearen Typ hat die Trendlinie bereits den Wert der Genauigkeit der Annäherung in Höhe von 0,9477, was dieses Modell charakterisiert, sogar noch zuverlässiger als die von uns in Betracht gezogene Trends des Exponentialtyps.
- Durch das Umschalten zwischen verschiedenen Arten von Trendlinien und dem Vergleich der Annäherungssicherheitswerte (Bestimmungskoeffizient) können Sie die Option finden, die Option, dass das Modell den eingereichten Zeitplan am genauesten beschreibt. Eine Option mit der höchsten Bestimmungsrate ist das zuverlässigste. Auf der Basis können Sie die genaueste Prognose aufbauen.
Beispielsweise konnte für unseren Fall festgestellt werden, dass das höchste Zuverlässigkeitsniveau eine Polynomentyp eines zweiten Grad-Trends hat. Der Bestimmungskoeffizient in diesem Fall ist 1. Dies deutet darauf hin, dass das angegebene Modell absolut zuverlässig ist, was die vollständige Ausnahme von Fehlern bedeutet.

Gleichzeitig bedeutet dies jedoch nicht, dass diese Art der Trendlinie für eine andere Grafik auch der zuverlässigste sein wird. Die optimale Wahl der Art der Trendlinie hängt von der Art der Funktion ab, auf deren Grundlage der Zeitplan erstellt wurde. Wenn der Benutzer nicht ausreichend Wissen auf "auf dem Auge" hat, um die Option höchste Qualität zu schätzen, ist die einzige Leistung der Bestimmung der besten Prognose nur ein Vergleich der Bestimmungskoeffizienten, wie in dem obigen Beispiel gezeigt.







Das MS Excel-Paket ermöglicht den Bau einer linearen Regressionsgleichung der meisten der Arbeit sehr schnell. Es ist wichtig zu verstehen, wie Sie die erzielten Ergebnisse interpretieren können.
Muss arbeiten Analysepaket.was Sie im Menüpunkt aktivieren möchten Service \\ Add-In

In Excel 2007, um das Analysepaket zu aktivieren, müssen Sie auf den Block klicken Excel-EinstellungenDurch Drücken der Taste in der oberen linken Ecke und dann die Taste " Excel-Einstellungen»Am unteren Rand des Fensters:

![]()

![]()


Um ein Regressionsmodell aufzubauen, müssen Sie Element auswählen Service \\ Data Analysis \\ Regression. (In Excel 2007 befindet sich dieser Modus im Block Daten- / Datenanalyse / Regression). Ein Dialogfeld scheint auszufüllen:

1) Eingabeintervall y. ¾ Enthält einen Link zu Zellen, die Werte der Leistung enthalten y.. Werte müssen sich in der Spalte befinden.
2) Eingabeintervall X. ¾ Enthält einen Link zu Zellen, die die Werte der Faktoren enthalten. Werte müssen sich in Spalten befinden.
3) Zeichen Stichworte Es wird angehoben, wenn die ersten Zellen erläuterndes Text enthalten (Datensignaturen);
4) Zuverlässigkeitsstufe ¾ Dies ist eine Vertrauenswahrscheinlichkeit, die standardmäßig als 95% betrachtet wird. Wenn dieser Wert nicht angeht, müssen Sie diese Funktion aufnehmen und den gewünschten Wert eingeben.
5) Zeichen Constanta null. Es schaltet ein, wenn es notwendig ist, eine Gleichung aufzubauen, in der eine freie Variable ist;
6) Ausgangsparameter Bestimmen Sie, wo die Ergebnisse platziert werden müssen. Der Standardmodus ist Neues Arbeitsblatt;
7) Block Rückstände Ermöglicht das Einschalten der Ausgabe der Rückstände und der Konstruktion ihrer Grafiken.
Infolgedessen werden Informationen angezeigt, die alle erforderlichen Informationen enthalten, und in drei Blöcke gruppiert: Regressionsstatistik., Dispersionsanalyse, Fazit Rückstand. Betrachten Sie sie näher.
1. Regressionsstatistik.:
mehrere R. bestimmt von der Formel ( pearson-Korrelationskoeffizient);
R.  (bestimmtheitsmaß);
(bestimmtheitsmaß);
Normiert R.-KVadrat wird von der Formel berechnet  (für mehrere Regression verwendet);
(für mehrere Regression verwendet);
Standart Fehler S. Berechnet durch Formel.  ;
;
Beobachtungen ¾ Dies ist die Datenmenge n..
2. Dispersionsanalyse, Linie Regression.:
Parameter dF. Rabe m. (Anzahl der Faktorengruppen x.);
Parameter Ss. bestimmt durch die Formel;
Parameter FRAU. bestimmt durch die Formel;
Statistiken F. bestimmt durch die Formel;
Bedeutung F.. Wenn die erhaltene Zahl übersteigt, wird die Hypothese aufgenommen (es gibt keine lineare Beziehung), da sonst die Hypothese entnommen wird (eine lineare Beziehung).
3. Dispersionsanalyse, Linie Rückstand:
Parameter dF. gleich;
Parameter Ss. Formel ist bestimmt  ;
;
Parameter FRAU. Von der Formel bestimmt.
4. Dispersionsanalyse, Linie GESAMT Enthält die Summe der ersten beiden Spalten.
5. Dispersionsanalyse, Linie Y-crossing. Enthält den Wert des Koeffizienten, des Standardfehlers und t.-Statistiken.
P.-NOTION ¾ ist der Wert der Signifikanzgrade, die dem berechnen t.-Statistiken. Bestimmt durch die Funktion von stouturasp ( t.-Statistiken; ). Wenn ein P.-NOTION überschreitet, die entsprechende Variable ist statistisch unbedeutend und es kann vom Modell ausgeschlossen werden.
Niedriger 95% und Top 95% ¾ Dies ist die untere und obere Grenze von 95 Prozent Konfidenzintervallen für die Koeffizienten der linearen Regression theoretischen Gleichung. Wenn in dem Dateneingabeblock der Konfidenzwahrscheinlichkeit standardmäßig standardmäßig hinterlassen wurde, werden die letzten beiden Spalten die vorherigen duplizieren. Wenn der Benutzer seine Vertrauenswahrscheinlichkeit eingegeben hat, enthalten die letzten beiden Spalten die Werte der unteren und oberen Grenze für die angegebene Vertrauenswahrscheinlichkeit.
6. DispersionsanalyseSaiten enthalten die Werte der Koeffizienten, Standardfehler, t.-Statistiker, P.- Annäherungen und Vertrauensintervalle für relevante.
7. Block Fazit Rückstand Enthält vorhergesagte Werte y. (In unseren Bezeichnungen es) und den Resten.
Die Regressionslinie ist eine grafische Reflexion der Beziehung zwischen Phänomenen. Sehr deutlich kann eine Regressionslinie in Excel gebaut werden.
Dafür brauchen Sie:
1. Extrahieren Excel-Programm
2. Erstellen Sie Spalten mit Daten. In unserem Beispiel werden wir eine Regressionslinie oder Wechselbeziehungen zwischen Aggressivität und Unsicherheit in ihren Erstklässern aufbauen. Im Experiment haben 30 Kinder teilgenommen, die Daten werden in der speziellen Tabelle dargestellt:
1 Spalte - Testnummer
2 columid - aggressivität in ballaten
3 columid - schüchternheit in ballaten

3. Dann müssen Sie beide Säulen (ohne den Namen der Spalte) hervorheben, klicken Sie auf die Registerkarte einfügen , wählen pagle und aus den vorgeschlagenen Layouts, um das erste zu wählen Wählerisch mit markierern. .

4. Also haben wir ein Leerzeichen für die Regressionslinie - die sogenannten - streuungsdiagramm. Um in die Regressionszeile zu gelangen, müssen Sie auf die resultierende Zeichnung klicken, klicken Sie auf die Registerkarte konstrukteur, finden Sie auf dem Panel Layouts-Diagramme und wähle M. aberkET9. Es ist immer noch darauf geschrieben f (x)

5. Und wir haben eine Regressionslinie. Die Grafik zeigt auch seine Gleichung und das Quadrat des Korrelationskoeffizienten an

6. Es gibt einen Diagrammnamen, den Namen der Achsen. Sie können auch die Legende entfernen, die Anzahl der horizontalen Mesh-Linien reduzieren (Registerkarte layout , dann gitter ). Hauptänderungen und Einstellungen werden auf der Registerkarte vorgenommen. Layout

Die Regressionslinie ist in MS Excel gebaut. Jetzt kann es dem Text der Arbeit hinzugefügt werden.