Hyper threading paralel hesaplama teknolojisi. Hyper Threading Nedir? BIOS'ta destek nasıl etkinleştirilir? Teknolojinin teknik açıklaması
"...Ve biz gururluyuz, düşmanımız da gururlu
Hand, tembelliği unut. Görelim,
sonunda kimin botları var
sonunda diz çökecek..."
© filmi "D"Artagnan ve Üç Silahşörler"
Bir süre önce yazar, Intel Hyper Threading'in yeni paradigması hakkında "biraz homurdanmasına" izin verdi. Intel'in takdirine göre yazarın şaşkınlığı gözden kaçmadı. Bu nedenle, yazara bunu bulma konusunda yardım teklif edildi ( şirketin yöneticilerinin nasıl hassas bir şekilde değerlendirdiği) Hyper Threading teknolojisiyle "gerçek" durum. Gerçeği bulma arzusu ancak övülebilir. Öyle değil mi sevgili okuyucu? En azından gerçeklerden biri şöyle: doğru bu iyi. Peki biz de bu tabire uygun hareket etmeye çalışacağız. Üstelik gerçekten de bir miktar yeni bilgi ortaya çıktı.
Öncelikle Hyper Threading teknolojisi hakkında tam olarak bildiklerimizi formüle edelim:
1. Bu teknoloji işlemcinin verimliliğini artırmak için tasarlanmıştır. Gerçek şu ki, Intel'in tahminlerine göre çoğu zaman yalnızca %30'u çalışıyor ( Bu arada bu oldukça tartışmalı bir rakam; hesaplamasının detayları bilinmiyor.) işlemcideki tüm aktüatörlerin. Katılıyorum, bu oldukça saldırgan. Ve fikrin geri kalan% 70'i bir şekilde "toplamak" için ortaya çıkması oldukça mantıklı görünüyor ( Üstelik bu teknolojinin uygulanacağı Pentium 4 işlemcinin kendisi de megahertz başına aşırı performanstan muzdarip değil). Dolayısıyla yazar bu fikrin oldukça sağlam olduğunu kabul etmek zorunda kalıyor.
2. Hyper Threading teknolojisinin özü, bir programın bir "iş parçacığının" yürütülmesi sırasında, boşta kalan yürütme cihazlarının programın başka bir "iş parçacığını" yürütmeye başlayabilmesidir ( veya "iplikler" bir diğer programlar). Veya, örneğin, bir komut dizisini yürütürken, bellekteki verilerin başka bir diziyi yürütmesini bekleyin.
3. Doğal olarak, farklı "iş parçacıkları" yürütülürken, işlemci bir şekilde hangi komutların hangi "iş parçacığına" ait olduğunu ayırt etmelidir. Bu, bazı mekanizmalar olduğu anlamına gelir ( biraz işaret), işlemcinin komutların hangi "iş parçacığına" ait olduğunu ayırt etmesi sayesinde.
4. Ayrıca, x86 mimarisindeki az sayıdaki genel amaçlı kayıtlar göz önüne alındığında ( toplam 8), her iş parçacığının kendi kayıt kümesi vardır. Ancak bu artık yeni bir haber değil; bu mimari sınırlama, "kayıt yeniden adlandırma" kullanılarak uzun süredir aşılıyor. Başka bir deyişle, mantıksal kayıtlardan çok daha fazla fiziksel kayıt vardır. Pentium III işlemcide bunlardan 40 tane var. Elbette Pentium 4 için bu sayı daha fazla, yazarın hiçbir gerekçesi yok; "simetri" hususları hariç:-) görüş şu ki bunlardan yüzlerce var. Sayıları hakkında güvenilir bilgi bulunamadı. Henüz doğrulanmamış verilere göre 256 tane var. Diğer kaynaklara göre başka bir sayı. Genel olarak tam bir belirsizlik... Bu arada, Intel'in konumu Bu nedeni tamamen anlaşılmaz :-( Yazar bu tür gizliliğe neyin sebep olduğunu anlamıyor.
5. Ayrıca, birkaç "iş parçacığının" aynı kaynakları talep ettiği veya "iş parçacıklarından" birinin veri beklediği durumlarda, performansta bir düşüşü önlemek için programcının özel bir "duraklatma" eklemesi gerektiği de bilinmektedir. emretmek. Doğal olarak bu, programların yeniden derlenmesini gerektirecektir.
6. Aynı anda birkaç "iş parçacığını" yürütme girişimlerinin performansta düşüşe yol açabileceği durumların olabileceği de açıktır. Örneğin, L2 önbelleğinin boyutunun sonsuz olmaması ve aktif "iş parçacıklarının" önbelleği yüklemeye çalışacağı nedeniyle, böyle bir "önbellek mücadelesinin" sürekli olarak temizlenmesine ve yeniden yüklenmesine yol açması mümkündür. ikinci düzey önbellekteki veriler.
7. Intel, programları bu teknolojiye göre optimize ederken kazancın %30'a kadar çıkacağını iddia ediyor. ( Daha doğrusu Intel, günümüzün sunucu uygulamalarında ve günümüz sistemlerinde %30'a kadar) Hım... Bu, optimizasyon için fazlasıyla yeterli bir teşviktir.
Bazı özellikleri formüle ettik. Şimdi bazı çıkarımlar üzerinde düşünmeye çalışalım ( Mümkün olduğunda, bildiğimiz bilgilere dayanarak). Ne söyleyebiliriz? Öncelikle bize tam olarak ne teklif edildiğine daha yakından bakmamız gerekiyor. Bu peynir gerçekten “bedava” mı? Öncelikle, birkaç "iş parçacığının" "eşzamanlı" işlenmesinin tam olarak nasıl gerçekleşeceğini bulalım. Bu arada Intel "iş parçacığı" kelimesiyle ne anlama geliyor?
Yazarın izlenimi var ( muhtemelen hatalı), bu durumda, çok görevli bir işletim sisteminin, çok işlemcili bir donanım sisteminin işlemcilerinden birine yürütülmek üzere atadığı bir program parçasını ifade eder. "Beklemek!" dikkatli okuyucu "tanımlardan biri bu!" diyecektir. Ve içinde hiçbir şey yok verildi Yazar bu soruda özgünlük iddiasında bulunmamaktadır. Intel'in neyin "orijinal" olduğunu öğrenmek isterim :-). Peki, bunu işe yarar bir hipotez olarak kabul edelim.
Daha sonra belirli bir iş parçacığı yürütülür. Bu arada, komut kod çözücü ( bu arada, tamamen eşzamansız ve Net Burst'un kötü şöhretli 20 aşamasına dahil değil) örnekleme ve şifre çözme işlemini gerçekleştirir ( tüm karşılıklı bağımlılıklarla)V mikro talimatlar. Burada yazarın "eşzamansız" kelimesiyle ne kastettiğini açıklığa kavuşturmak gerekir - gerçek şu ki, mikro talimatlardaki x86 komutlarının "çökmesinin" sonucu şifre çözme bloğunda meydana gelir. Her x86 komutunun kodu bir, iki veya daha fazla mikro talimata dönüştürülebilir. Aynı zamanda işleme aşamasında karşılıklı bağımlılıklar netleştirilir ve gerekli veriler sistem veri yolu aracılığıyla iletilir. Buna göre, bu bloğun çalışma hızı çoğu zaman bellekten veri erişim hızına bağlı olacaktır ve en kötü durumda bu hız tarafından belirlenir. Onu, aslında mikro işlemlerin gerçekleştirildiği boru hattından “çözmek” mantıklı olacaktır. Bu, bir şifre çözme bloğu yerleştirerek yapıldı önceönbelleği izle. Bununla neyi başarıyoruz? Ve bu "blokların yeniden düzenlenmesi" yardımıyla basit bir şeyi başarıyoruz: izleme önbelleğinde yürütme için mikro talimatlar varsa, işlemci daha verimli çalışır. Doğal olarak bu ünite Rapid Engine'den farklı olarak işlemci frekansında çalışıyor. Bu arada yazar, bu kod çözücünün 10-15 aşamaya kadar uzunlukta bir taşıma bandına benzer bir şey olduğu izlenimini edindi. Böylece önbellekten veri alınmasından sonucun elde edilmesine kadar görünüşe göre yaklaşık 30 35 aşama var ( Net Burst boru hattı dahil, bkz. Mikro Tasarım Kaynakları Ağustos 2000 Mikroişlemci raporu Cilt 14 Arşivi8, sayfa 12).
Sonuçta ortaya çıkan mikro talimatlar seti, tüm karşılıklı bağımlılıklarla birlikte, yaklaşık 12.000 mikro işlemi içeren aynı önbellekteki bir izleme önbelleğinde birikir. Kaba tahminlere göre böyle bir tahminin kaynağı P6 mikro talimatının yapısıdır; gerçek şu ki, talimatların uzunluğunun temelde dramatik bir şekilde değişmesi pek mümkün değildir ( Mikrokomutun uzunluğu servis alanları ile birlikte dikkate alındığında yaklaşık 100 bittir.) izleme önbellek boyutu şuradan elde edilir: 96 KB'ye 120 KB!!! Fakat! Bu arka plana karşı, boyutta bir veri önbelleği 8 KB bir şekilde asimetrik görünüyor :-)… ve soluk. Elbette boyut arttıkça erişim gecikmeleri de artıyor ( örneğin, 32 KB'ye artırıldığında iki saat döngüsü yerine gecikmeler 4 olacaktır). Ancak bu veri önbelleğine erişim hızı gerçekten o kadar önemli ki gecikmede 2 saat döngüsü artışı ( tüm konveyörün toplam uzunluğunun arka planına karşı) hacimdeki böyle bir artışı kârsız hale getirir mi? Yoksa bu sadece kristal boyutunu arttırma konusundaki isteksizlikten mi kaynaklanıyor? Ancak daha sonra 0,13 mikrona geçerken ilk adım bu özel önbelleği artırmak oldu ( ikinci düzey bir önbellek değil). Bu tezden şüphe duyanlar, birinci seviye önbellekteki artış sayesinde Pentium'dan Pentium MMX'e geçişi hatırlamalıdır. iki katına çıktı Neredeyse tüm programların performansında %10-15 artış elde edildi. Artış konusunda ne söyleyebiliriz? dörtlü (özellikle işlemci hızlarının 2 GHz'e çıktığı ve çarpma faktörünün 2,5'tan 20'ye çıktığı dikkate alındığında)? Doğrulanmamış raporlara göre, Pentium4 (Prescott) çekirdeğinin bir sonraki modifikasyonunda birinci düzey önbellek 16 veya 32 KB'ye yükseltilecek. İkinci seviye önbellek de artacaktır. Ancak şu anda tüm bunlar söylentiden öteye gidemiyor. Açıkçası bu biraz kafa karıştırıcı bir durum. Her ne kadar bir rezervasyon yapalım, yazar böyle bir fikrin belirli bir nedenden dolayı engellendiğini tamamen kabul ediyor. Örnek olarak, blokların düzeninin geometrisi için belirli gereksinimler veya konveyörün yakınında banal boş alan eksikliği ( veri önbelleğini ALU'ya daha yakın bir yere yerleştirmenin gerekli olduğu açıktır).
Dikkatimiz dağılmadan sürece daha detaylı bakalım. İşlem hattı çalışıyor, mevcut ekiplerin ALU'yu kullanmasına izin verin. FPU, SSE, SSE2 ve diğerlerinin boşta olduğu açıktır. Böyle bir şans yok Hyper Threading devreye giriyor. Yeni iş parçacığı için verilerle birlikte mikro talimatların da hazır olduğunu fark eden kayıt yeniden adlandırma birimi, fiziksel kayıtların bir kısmını yeni iş parçacığına tahsis eder. Bu arada, iki seçenek mümkündür: bir fiziksel kayıt bloğu tüm iş parçacıkları için ortaktır veya her biri için ayrıdır. Intel'in Hyper Threading sunumunda, kayıt yeniden adlandırma bloğunun değiştirilmesi gereken bloklar arasında listelenmediğine bakılırsa ilk seçenek seçilmiştir; İyi mi kötü mü? Teknoloji uzmanlarının bakış açısından bu açıkça iyidir çünkü transistörlerden tasarruf sağlar. Programcıların bakış açısından bu hala belirsiz. Eğer fiziksel kayıt sayısı gerçekten 128 ise, makul sayıda iş parçacığı ile "kayıt sıkıntısı" durumu ortaya çıkamaz. Sonra onlar ( mikro talimatlar) aslında onları yürütme cihazına gönderen zamanlayıcıya gönderilir ( eğer meşgul değilse) veya bu aktüatör şu anda mevcut değilse "sıraya alındı". Böylece ideal olarak mevcut aktüatörlerin daha verimli kullanılması sağlanır. Bu sırada kendimi İşlemci işletim sistemi açısından iki "mantıksal" işlemciye benziyor. Hm... Her şey gerçekten bu kadar bulutsuz mu? Duruma daha yakından bakalım: bir ekipman parçası ( önbellekler, Rapid Engine, geçiş tahmin modülü gibi) her iki işlemci için de ortaktır. Bu arada, geçiş tahmin doğruluğu bundan, büyük olasılıkla, biraz acı çekecek. Özellikle aynı anda yürütülen iş parçacıkları birbirine bağlı değilse. Ve kısım ( örneğin, MIS mikro komut dizisi planlayıcısı, önceden programlanmış bir dizi ortak işlem dizisini ve RAT kaydı yeniden adlandırma tablosunu içeren bir tür ROM'dur.) bloklar "farklı" işlemcilerde çalışan farklı iş parçacıklarıyla ayırt edilmelidir. Yol boyunca ( önbellek topluluğundan) iki iş parçacığının önbellek açgözlü olması durumunda ( yani önbelleği artırmanın büyük bir etkisi vardır), O Hyper Threading'i kullanmak hızı bile azaltabilir. Bunun nedeni şu anda önbellek için mücadele etmek için "rekabetçi" bir mekanizmanın uygulanmış olmasıdır: şu anda "aktif" iş parçacığı "etkin olmayan" iş parçacığının yerini alır. Ancak önbelleğe alma mekanizması görünüşe göre değişebilir. Ayrıca hızın da açık olduğu açıktır ( en azından şimdilik) dürüst SMP'nin azaldığı uygulamalarda azalacaktır. Örnek olarak SPEC ViewPerf genellikle tek işlemcili sistemlerde daha iyi sonuçlar verir. Bu nedenle, sonuçlar muhtemelen Hyper Threading'in olduğu bir sistemde, Hyper Threading'in olmadığı bir sisteme göre daha düşük olacaktır. Aslında Hyper Threading'in pratik testinin sonuçları şu adreste görülebilir:
Bu arada, internete sızan bilgiler Pentium 4 16-bit'te ALU. İlk başta yazar bu tür bilgiler konusunda çok şüpheciydi - kıskanç insanların ne düşündüğünü :-) söylüyorlar. Ve sonra bu tür bilgilerin Mikro Tasarım Raporu'nda yayınlanması beni düşündürdü: Ya doğruysa? Ve bununla ilgili bilgiler doğrudan makalenin konusuyla ilgili olmasa da direnmek zordur :-). Yazarın yeterince "anladığı" kadarıyla, mesele ALU'nun gerçekten 16 bit olduğudur. vurguluyorum Yalnızca ALU. Bunun işlemcinin bit kapasitesiyle hiçbir ilgisi yoktur. Böylece yarım vuruşta ( buna tik, tik denir) ALU ( hatırladığınız gibi çift frekans) yalnızca 16 bit hesaplar. İkinci 16, bir sonraki yarı vuruşu üzerinden hesaplanır. Bu nedenle, bu arada, ALU'yu iki kat daha hızlı hale getirme ihtiyacını anlamak kolaydır - bu, verilerin zamanında "öğütülmesi" için gereklidir. Böylece tam saat döngüsünde tam 32 bit hesaplanır. Aslında görünüşe göre parçaları "yapıştırmak" ve "çıkarmak" gerektiğinden 2 döngüye ihtiyaç duyuluyor, ancak bu konunun açıklığa kavuşturulması gerekiyor. Aslında kazılar (hakkında ayrı bir şiir yazabileceğiniz) şunu ortaya çıkardı: her ALU 2 adet 16 bitlik yarıya bölünmüştür. İlk yarım döngü 16 bit işler iki diğer yarılar için sayılar ve form taşıma bitleri. Diğer yarısı şu anda işlemeyi bitiriyor öncesi sayılar. ALU'nun ikinci işareti ilk yarısı 16 biti işler Sonraki sayı çiftleri ve transferlerini oluşturur. İkinci yarı üstteki 16 biti işler ilk çift sayılar ve hazır 32 bitlik bir sonuç alır. 1 sonucun alınmasındaki gecikme 1 saat döngüsüdür, ancak daha sonra her yarım saat döngüsünde 1 32 bitlik sonuç ortaya çıkar. Oldukça esprili ve etkili. Neden bu özel ALU modeli seçildi? Görünüşe göre Intel böyle bir organizasyonla bir taşla birkaç kuş vuruyor:
1. 16 bit genişliğindeki bir boru hattının hız aşırtma işleminin 32 bit genişliğindeki bir boru hattına göre daha kolay olduğu açıktır, bunun nedeni çapraz karışma ve ortak bağlantının varlığıdır.
2. Görünüşe göre Intel, tam sayı hesaplama işlemlerinin, örneğin FPU'yu değil, ALU'yu hızlandıracak kadar sık olduğunu düşünüyordu. Tamsayı işlemlerinin sonuçları hesaplanırken tablolar veya "taşıma-birikimli" şemaların kullanılması muhtemeldir. Karşılaştırma için, 32 bitlik bir tablo 2E32 adrestir, yani. 4 gigabayt. İki adet 16 bitlik tablo 2x64kb veya 128 kilobayttır, farkı hissedin! Ve iki adet 16 bitlik kısımdaki tirelerin birikmesi, bir adet 32 bitlik kısımdakinden daha hızlı gerçekleşir.
3. Transistörlerden ve ısıdan tasarruf sağlar. Sonuçta, tüm bu mimari hilelerin hararetli olduğu bir sır değil. Görünüşe göre oldukça büyüktü (ve belki de Ev) sorun, örneğin bir teknoloji olarak Termal Monitörün değerinin ne olduğudur! Sonuçta böyle bir teknolojiye pek ihtiyaç yok, yani elbette var olması güzel. Ancak dürüst olalım; yeterli güvenilirlik için basit bir engelleme yeterli olacaktır. Böylesine karmaşık bir teknoloji sağlandığı için, hareket halindeyken bu tür frekans değişiklikleri normal çalışma modlarından biri olduğunda, seçeneğin ciddi şekilde değerlendirildiği anlamına gelir. Ya da belki asıl olanı? Pentium 4'ün çok daha fazla sayıda aktüatörle planlandığına dair söylentiler boşuna değildi. O zaman ısı sorunu asıl sorun haline gelmeliydi. Daha doğrusu aynı söylentilere göre ısı salınımının şu kadar olması gerekirdi: 150W. O halde sadece normal soğutmanın sağlandığı sistemlerde işlemcinin “tam kapasitede” çalışmasını sağlayacak önlemlerin alınması oldukça mantıklıdır. Üstelik çoğu "Çin" menşeli kasa, soğutma açısından düşünceli tasarımla parlamıyor. Hm... Uzun bir yol kat ettik :-)
Ama bunların hepsi teorileştirme. Günümüzde bu teknolojiyi kullanan işlemciler var mı? Yemek yemek. Bu Xeon ( Prestonya) ve XeonMP. Üstelik XeonMP'nin 4 işlemciye kadar desteklemesi açısından Xeon'dan farklı olması ilginçtir ( IBM Summit gibi yonga setleri 16'ya kadar işlemciyi destekler, teknik ProFusion yonga seti ile yaklaşık olarak aynıdır) ve çekirdeğe entegre edilmiş 512 KB ve 1 MB'lık üçüncü düzey bir önbelleğin varlığı. Bu arada neden üçüncü seviye önbelleği entegre ettiler? Birinci düzey önbellek neden artırılmıyor?? Mantıklı bir nedeni olmalı... Neden ikinci seviye önbelleği artırmadılar? Belki de bunun nedeni Gelişmiş Aktarım Önbelleğinin nispeten düşük gecikmeye ihtiyaç duymasıdır. Önbellek boyutunun artırılması gecikmelerin artmasına neden olur. Bu nedenle, çekirdek için üçüncü düzey önbellek ve ikinci düzey önbellek genellikle bir veri yolu olarak "temsil edilir". Sadece bir lastik :-). Dolayısıyla ilerleme açıktır; verilerin çekirdeğe mümkün olan en hızlı şekilde beslenmesini sağlamak için her şey yapılmıştır ( ve aynı zamanda bellek veri yolu daha az yüklendi).
Peki, özellikle hiçbir darboğazın olmadığı ortaya çıktı? Yazar neden "homurdanamıyor"? Bir işlemci - ve işletim sistemi iki tane görüyor. İyi! İki işlemci ve işletim sistemi 4'ü görüyor! Güzellik! Durmak! Bu 4 işlemciyle ne tür bir işletim sistemi çalışıyor? İkiden fazla işlemcinin maliyetini anlayan Microsoft işletim sistemleri tamamen farklı para. Örneğin 2000 Professional, XP Professional, NT4.0 yalnızca iki işlemciyi anlıyor. Ve şimdilik bu teknolojinin iş istasyonu pazarına yönelik olduğu göz önüne alındığında ( ve sunucular) ve yalnızca ilgili işlemcilerde mevcut - bunun son derece rahatsız edici olduğu ortaya çıktı. Bugün bu teknolojiye sahip işlemcileri ancak çift işlemcili bir kart satın alıp takarak kullanabiliyoruz. birİŞLEMCİ. Alice Harikalar Diyarında'nın dediği gibi, ne kadar ileri gidersen, o kadar tuhaflaşır... Yani bu teknolojiyi kullanmak isteyen bir kişi, mevcut işletim sistemlerinin Sunucu ve Gelişmiş Sunucu versiyonlarını satın almak zorunda kalıyor. Ah, ve "ücretsiz" işlemci biraz pahalı... Belki de Intel'in şu anda Microsoft ile aktif olarak "iletişim kurduğunu" ve lisans politikasını Microsoft'a bağlamaya çalıştığını eklemekte fayda var. fiziksel işlemci. En azından belgeye göre Microsoft'un yeni işletim sistemleri fiziksel işlemciyle lisanslanacak. En azından WindowsXP, fiziksel işlemci sayısına göre lisanslanır.
Doğal olarak her zaman diğer üreticilerin işletim sistemlerine yönelebilirsiniz. Dürüst olalım; bu mevcut durumdan pek de iyi bir çıkış yolu değil... Dolayısıyla uzun süredir bu teknolojiyi kullanıp kullanmama konusunda düşünen Intel'in tereddütünü anlamak mümkün.
Peki, oldukça önemli bir sonucu unutmayalım: Hyper Threading'in kullanılması hem performans kazanımlarına hem de kayıplara yol açabilir. Kaybetmeyi daha önce tartıştığımıza göre, kazanmak için neyin gerekli olduğunu anlamaya çalışalım: Kazanmak için de bu teknolojiyi bilmeleri gerekiyor:
- Anakart BIOS'u
- İşletim sistemi (!!!)
- Aslında uygulamanın kendisi
Bu nokta üzerinde daha detaylı durayım; mesele BIOS değil. İşletim sisteminden biraz önce bahsetmiştik. Ancak örneğin bellekten veri bekleyen iş parçacıklarında özel bir komut girmeniz gerekecektir. Duraklat işlemciyi yavaşlatmamak için; Sonuçta, veri yokluğunda, iş parçacığı belirli aktüatörleri bloke etme yeteneğine sahiptir. Ve bu komutu eklemek için uygulamaların yeniden derlenmesi gerekecek - bu iyi değil, ancak Intel sayesinde herkes son zamanlarda buna alışmaya başladı :-). Böylece ana ( yazara göre) Hyper Threading teknolojisinin dezavantajı başka bir derlemeye ihtiyaç duymasıdır. Bu yaklaşımın ana avantajı yol boyunca bu tür yeniden derlemedir ( ve büyük olasılıkla daha dikkat çekici :-)"dürüst" çift işlemcili sistemlerde performansı artıracaktır ve bu yalnızca memnuniyetle karşılanabilir. Bu arada, bunu doğrulayan deneysel çalışmalar zaten var. çoğu durumda SMP için optimize edilmiş programlar, Hyper Threading'den %15'ten %18'e kadar yararlanın. Bu oldukça iyi. Bu arada Hyper Threading'in hangi durumlarda performansta düşüşe yol açtığını da görebilirsiniz.
Ve son olarak neyin değişebileceğini hayal etmeye çalışalım ( geliştirmek) bu fikrin daha da geliştirilmesinde. Bu teknolojinin gelişiminin Pentium 4 çekirdeğinin gelişimiyle doğrudan bağlantılı olacağı oldukça açık. Dolayısıyla çekirdekteki potansiyel değişiklikleri hayal edelim. Planımızda bundan sonra ne var? 0,09 mikron teknolojisi, daha çok 90nm olarak bilinir…. Yazar inanmaya meyillidir ( şu anda), bu işlemci ailesinin gelişiminin aynı anda birkaç yöne ilerleyeceği:
- Daha "ince" bir teknik süreç sayesinde işlemci frekansı daha da yükselecek.
- Veri önbelleğinin artacağını umalım. En az 32KB'a kadar.
- “Dürüst” bir 32 bit ALU yapacaklar. Bu verimliliği artırmalıdır.
- Sistem veri yolu hızını artırın ( ancak bu zaten yakın gelecekte).
- Çift kanallı DDR bellek yapacaklar ( yine, bekleme nispeten kısa).
- Belki bu teknoloji varsa, x86-64 teknolojisinin bir analogunu tanıtacaklar ( AMD'ye teşekkürler) kök salacaktır. Yazar aynı zamanda tüm gücüyle bu analogun x86-64 ile uyumlu olacağını umuyor. Birbiriyle uyumsuz uzantılar oluşturmaya son verin... Yine ilgimizi çeken Jerry Sanders olacak; kendisi geçen yıl AMD ve Intel'in Pentium4 sistem veri yolu dışında her şey için çapraz lisanslama konusunda anlaştığını belirtmişti. Bu, Intel'in bir sonraki Pentium4 (Prescott) çekirdeğinde x86-64 oluşturacağı ve AMD'nin işlemcilerinde Hyper Threading oluşturacağı anlamına mı geliyor? İlginç soru...
- Belki aktüatörlerin sayısı artırılacaktır. Doğru, önceki gibi, bu da oldukça tartışmalı bir nokta çünkü çekirdeğin neredeyse tamamen yeniden tasarlanmasını gerektiriyor - ve bu uzun ve emek yoğun bir süreç.
Acaba Hyper Threading fikri geliştirilecek mi? Gerçek şu ki, niceliksel olarak gelişebilecek hiçbir yer yok; iki fiziksel işlemcinin, üç mantıksal işlemciden daha iyi olduğu açıktır. Evet ve konumlandırma kolay olmayacak... İlginç bir şekilde Hyper Threading, iki ( yada daha fazla) çip başına işlemci sayısı. Yazar, niteliksel değişikliklerle, sıradan masaüstü bilgisayarlarda bu tür bir teknolojinin varlığının, aslında kullanıcıların çoğunluğunun [neredeyse] çift işlemcili makinelerde çalışacağı gerçeğine yol açacağını kastediyor ki bu da çok iyi. Bu iyi çünkü bu tür makineler, ağır yük altında bile çok daha sorunsuz çalışıyor ve kullanıcı eylemlerine daha duyarlı. Yazarın bakış açısından bu çok iyi.
Son söz yerine
Yazar, makale üzerinde çalışırken Hyper Threading'e karşı tutumunun birkaç kez değiştiğini itiraf etmelidir. Bilgi toplanıp işlendikçe tutum ya genel olarak olumlu hale geldi ya da tam tersi :-). Şu anda aşağıdakileri yazabiliriz:
Performansı artırmanın yalnızca iki yolu vardır: frekansı artırmak ve saat başına performansı artırmak. Ve eğer Pentium4 mimarisinin tamamı birinci yol için tasarlanmışsa, Hyper Threading yalnızca ikinci yol olacaktır. Bu açıdan bakıldığında ancak memnuniyetle karşılanabilir. Hyper Threading'in ayrıca programlama paradigmasını değiştirmek, çoklu işlemeyi geniş kitlelere ulaştırmak, işlemci performansını artırmak gibi ilginç sonuçları da vardır. Bununla birlikte, bu yolda "sıkışıp kalmamanın" önemli olduğu birkaç "büyük tümsek" vardır: işletim sistemlerinden normal desteğin olmaması ve en önemlisi yeniden derleme ihtiyacı ( ve bazı durumlarda algoritmayı değiştirmek) uygulamalarını kullanarak Hyper Threading'in avantajlarından tam olarak yararlanabilmelerini sağlayın. Buna ek olarak, Hyper Threading'in varlığı, işletim sistemini ve uygulamaları, şu anda olduğu gibi tek tek "parçalar" halinde değil, gerçekten paralel olarak çalıştırmayı mümkün kılacaktır. Tabii ki, yeterli sayıda serbest aktüatörün olması şartıyla.
Yazar minnettarlığını vurgulamak ister Maxim Lenya(aka C.A.R.C.A.S.S.) ve İlya Vaitsman(aka Stranger_NN) makalenin yazılmasında tekrarlanan ve paha biçilmez yardımları için.
Ayrıca değerli yorumlarını defalarca dile getiren tüm forum katılımcılarına da teşekkür etmek isterim.
BIOS Kurulumunun içeriğini dikkatlice incelediyseniz, orada CPU Hyper Threading Teknolojisi seçeneğini fark etmiş olabilirsiniz. Hyper Threading'in (veya hyperthreading'in, resmi adı Hyper Threading Technology, HTT'dir) ne olduğunu ve bu seçeneğin ne işe yaradığını merak etmiş olabilirsiniz.
Hyper Threading, Intel tarafından Pentium mimarili işlemciler için geliştirilen nispeten yeni bir teknolojidir. Uygulamanın gösterdiği gibi, Hyper Threading teknolojisinin kullanımı birçok durumda CPU performansının yaklaşık% 20-30 oranında artırılmasını mümkün kılmıştır.
Burada bir bilgisayarın merkezi işlemcisinin genel olarak nasıl çalıştığını hatırlamanız gerekir. Bilgisayarı açıp üzerinde bir program çalıştırdığınız anda, CPU, makine kodu olarak adlandırılan, içinde yer alan talimatları okumaya başlar. Her talimatı sırayla okur ve birbiri ardına yürütür.
Ancak birçok programda aynı anda çalışan birden fazla yazılım işlemi bulunur. Ayrıca modern işletim sistemleri kullanıcıya birden fazla programın aynı anda çalıştırılmasına olanak tanır. Ve buna izin vermiyorlar - aslında, işletim sisteminde tek bir işlemin çalıştığı bir durum bugün tamamen düşünülemez. Bu nedenle eski teknolojiler kullanılarak geliştirilen işlemciler, aynı anda birden fazla işlemin işlenmesinin gerekli olduğu durumlarda düşük performans gösteriyordu.
Elbette bu sorunu çözmek için sisteme birden fazla işlemci veya birkaç fiziksel hesaplama çekirdeği kullanan işlemciler dahil edebilirsiniz. Ancak böyle bir gelişme pahalıdır, teknik açıdan karmaşıktır ve pratik açıdan her zaman etkili değildir.
Geliştirme geçmişi
Bu nedenle birden fazla işlemin tek bir fiziksel çekirdek üzerinde işlenmesine olanak sağlayacak bir teknolojinin oluşturulmasına karar verildi. Bu durumda, programlar için dışarıdan bakıldığında sistemde aynı anda birden fazla işlemci çekirdeği varmış gibi görünecektir.
Hyper Threading teknolojisi desteği ilk olarak 2002 yılında işlemcilerde ortaya çıktı. Bunlar Pentium 4 ailesinin işlemcileri ve saat hızı 2 GHz'in üzerinde olan Xeon sunucu işlemcileriydi. Başlangıçta teknolojinin kod adı Jackson'dı, ancak daha sonra adı genel halk için daha anlaşılır olan Hyper Threading olarak değiştirildi - kabaca "süper iş parçacığı" olarak çevrilebilir.
Aynı zamanda Intel'e göre Hyper Threading'i destekleyen işlemci kristalinin yüzey alanı, onu desteklemeyen önceki modele göre yalnızca %5 arttı ve ortalama %20 performans artışı sağlandı.
Teknolojinin genel olarak kendini iyi bir şekilde kanıtlamış olmasına rağmen Intel, çeşitli nedenlerden dolayı Pentium 4'ün yerini alan Core 2 ailesi işlemcilerdeki Hyper Threading teknolojisini devre dışı bırakmaya karar verdi. Ancak Hyper Threading daha sonra işlemcilerde yeniden ortaya çıktı. Sandy Bridge ve Ivy mimarileri Bridge ve Haswell önemli ölçüde yeniden tasarlandı.
Teknolojinin özü
Hyper Threading Teknolojisini anlamak önemlidir çünkü Intel işlemcilerdeki temel özelliklerden biridir.
İşlemcilerin elde ettiği tüm başarıya rağmen, önemli bir dezavantajları var; aynı anda yalnızca bir talimatı yürütebiliyorlar. Diyelim ki metin editörü, tarayıcı ve Skype gibi uygulamaları aynı anda başlattınız. Kullanıcı açısından bakıldığında bu yazılım ortamı çoklu görev olarak adlandırılabilir, ancak işlemci açısından bu durumdan çok uzaktır. İşlemci çekirdeği yine de belirli bir zaman dilimi başına bir talimat yürütecektir. Bu durumda işlemcinin görevi, işlemci zamanı kaynaklarını bireysel uygulamalar arasında dağıtmaktır. Talimatların bu sıralı yürütülmesi son derece hızlı gerçekleştiğinden, bunu fark etmezsiniz. Ve size öyle geliyor ki hiçbir gecikme yok.
Ama hâlâ bir gecikme var. Gecikme, her programın işlemciye veri sağlama şekli nedeniyle oluşur. Her veri akışının belirli bir zamanda ulaşması ve işlemci tarafından ayrı ayrı işlenmesi gerekir. Hyper Threading teknolojisi, her işlemci çekirdeğinin veri işlemeyi planlamasını ve kaynakları iki iş parçacığı için aynı anda dağıtmasını mümkün kılar.

Modern işlemcilerin çekirdeğinde, her biri veriler üzerinde belirli bir işlemi gerçekleştirmek üzere tasarlanmış birkaç sözde yürütme cihazının bulunduğunu belirtmekte fayda var. Bu durumda, bu yürütme aygıtlarından bazıları, bir iş parçacığından gelen verileri işlerken boşta kalabilir.
Bu durumu anlamak için bir montaj atölyesinde konveyör üzerinde çalışan ve farklı türde parçaları işleyen işçilere benzetme yapabiliriz. Her çalışan, bir görevi gerçekleştirmek için tasarlanmış özel bir araçla donatılmıştır. Ancak parçaların yanlış sırayla gelmesi durumunda bazı çalışanların işe başlamak için kuyrukta beklemesi nedeniyle gecikmeler meydana geliyor. Hyper Threading, daha önce boşta olan çalışanların işlerini diğerlerinden bağımsız olarak yürütmeleri için atölyeye yerleştirilen ek bir taşıma bandına benzetilebilir. Atölye hala bir tanedir ancak parçalar daha hızlı ve verimli bir şekilde işlenir, bu da arıza süresinin azalmasına neden olur. Böylece Hyper Threading, bir iş parçacığından gelen talimatları yürütürken boşta kalan işlemci yürütme birimlerinin açılmasını mümkün kıldı.
Hyper Threading'i destekleyen çift çekirdekli işlemciye sahip bir bilgisayarı açtığınızda ve Performans sekmesi altında Windows Görev Yöneticisini açtığınızda, içinde dört grafik bulacaksınız. Ancak bu aslında 4 işlemci çekirdeğine sahip olduğunuz anlamına gelmez.

Bunun nedeni Windows'un her çekirdeğin iki mantıksal işlemciye sahip olduğunu düşünmesidir. "Mantıksal işlemci" terimi kulağa komik gelse de fiziksel olarak var olmayan bir işlemci anlamına gelir. Windows her mantıksal işlemciye veri akışı gönderebilir, ancak aslında işi yalnızca bir çekirdek yapar. Bu nedenle Hyper Threading teknolojisine sahip tek bir çekirdek, ayrı fiziksel çekirdeklerden önemli ölçüde farklıdır.
Hyper Threading teknolojisi aşağıdaki donanım ve yazılımlardan destek gerektirir:
- İşlemci
- Anakart yonga seti
- işletim sistemi
Teknolojinin faydaları
Şimdi şu soruyu ele alalım: Hyper Threading teknolojisi bilgisayar performansını ne kadar artırıyor? İnternette gezinmek ve yazmak gibi günlük görevlerde teknolojinin faydaları o kadar açık değildir. Ancak günümüzün işlemcilerinin o kadar güçlü olduğunu ve günlük görevlerin nadiren işlemciyi tam olarak kullandığını unutmayın. Ayrıca birçok şey yazılımın nasıl yazıldığına da bağlıdır. Aynı anda çalışan birden fazla programınız olabilir ancak yük grafiğine baktığınızda çekirdek başına yalnızca bir mantıksal işlemcinin kullanıldığını göreceksiniz. Bunun nedeni, yazılımın çekirdekler arasındaki süreçlerin dağıtımını desteklememesidir.
Ancak daha karmaşık görevler için Hyper Threading daha kullanışlı olabilir. 3B modelleme programları, 3B oyunlar, müzik veya video kodlama/kod çözme programları ve birçok bilimsel uygulama gibi uygulamalar, çoklu iş parçacığından tam olarak yararlanacak şekilde yazılmıştır. Böylece zorlu oyunlar oynarken, müzik dinlerken veya film izlerken Hyper Threading özellikli bir bilgisayarın performans avantajlarından yararlanabilirsiniz. Performans artışı %30'lara kadar çıkabiliyor ancak Hyper Threading'in hiç avantaj sağlamadığı durumlar da olabiliyor. Bazen her iki iş parçacığının tüm işlemci yürütme birimlerini aynı görevlerle yüklemesi durumunda performansta hafif bir düşüş bile gözlemlenebilir.
BIOS Kurulumunda Hyper Threading parametrelerini ayarlamanıza izin veren ilgili seçeneğin varlığına dönersek, çoğu durumda bu işlevin etkinleştirilmesi önerilir. Ancak bilgisayarınızın hatalarla çalıştığı veya beklediğinizden daha düşük bir performansa sahip olduğu ortaya çıkarsa her zaman devre dışı bırakabilirsiniz.
Çözüm
Hyper Threading kullanıldığında maksimum performans artışı %30 olduğundan teknolojinin işlemci çekirdek sayısını iki katına çıkarmaya eşdeğer olduğu söylenemez. Ancak Hyper Threading kullanışlı bir seçenektir ve bir bilgisayar sahibi olarak size zarar vermez. Faydası özellikle, örneğin multimedya dosyalarını düzenlediğinizde veya bilgisayarınızı Photoshop veya Maya gibi profesyonel programlar için bir iş istasyonu olarak kullandığınızda fark edilir.
Geçmişte Intel işlemcilerde kullanılan Simultane Multi-Threading (SMT) teknolojisinden bahsetmiştik. Başlangıçta olası bir seçenek olarak Jackson Teknolojisi kod adı verilmiş olsa da Intel, teknolojisini geçen sonbaharda IDF forumunda resmen duyurdu. Jackson kod adı daha uygun olan Hyper-Threading ile değiştirildi. Dolayısıyla yeni teknolojinin nasıl çalıştığını anlamak için bazı başlangıç bilgilerine ihtiyacımız var. Yani thread'in ne olduğunu, bu thread'lerin nasıl çalıştırıldığını bilmemiz gerekiyor. Uygulama neden çalışıyor? İşlemci hangi veriler üzerinde hangi işlemleri yapması gerektiğini nasıl biliyor? Tüm bu bilgiler çalışan uygulamanın derlenmiş kodunda bulunur. Uygulama, kullanıcıdan herhangi bir komut, herhangi bir veri alır almaz, iş parçacıkları derhal işlemciye gönderilir ve bunun sonucunda kullanıcının isteğine yanıt olarak yapması gerekeni gerçekleştirir. İşlemcinin bakış açısından bir iş parçacığı, yürütülmesi gereken bir dizi talimattır. Quake III Arena'da bir mermiyle vurulduğunuzda veya bir Microsoft Word belgesini açtığınızda, işlemciye yürütmesi gereken belirli bir dizi talimat gönderilir.
İşlemci bu talimatları tam olarak nereden alacağını biliyor. Program Sayacı (PC) adı verilen ve nadiren bahsedilen bir kayıt bu amaç için tasarlanmıştır. Bu kayıt, yürütülecek bir sonraki talimatın hafızada saklandığı yeri gösterir. İşlemciye bir iş parçacığı gönderildiğinde, iş parçacığının bellek adresi bu program sayacına yüklenir, böylece işlemci yürütmeye tam olarak nereden başlayacağını bilir. Her talimattan sonra bu kaydın değeri artırılır. Tüm bu süreç iş parçacığı sonlandırılıncaya kadar devam eder. İş parçacığının yürütülmesinin sonunda, yürütülecek bir sonraki komutun adresi program sayacına girilir. İş parçacıkları birbirini kesebilir ve işlemci, program sayacının değerini yığında saklar ve sayaca yeni bir değer yükler. Ancak bu süreçte hala bir sınırlama var; birim zaman başına yalnızca bir iş parçacığı yürütülebilir.
Bu sorunu çözmenin iyi bilinen bir yolu var. İki işlemcinin kullanılmasından oluşur - eğer bir işlemci aynı anda bir iş parçacığını yürütebiliyorsa, o zaman iki işlemci zaten aynı zaman biriminde iki iş parçacığını çalıştırabilir. Bu yöntemin ideal olmadığını unutmayın. Pek çok başka sorunu da beraberinde getiriyor. Bazılarına muhtemelen zaten aşinasınızdır. Birincisi, birden fazla işlemci her zaman tek işlemciden daha pahalıdır. İkincisi, iki işlemciyi yönetmek de o kadar kolay değil. Ayrıca kaynakların işlemciler arasındaki paylaşımını da unutmayın. Örneğin, AMD 760MP yonga setinin piyasaya sürülmesinden önce, çoklu işlem desteğine sahip tüm x86 platformları, tüm sistem veri yolu bant genişliğini mevcut tüm işlemciler arasında paylaşıyordu. Ancak asıl dezavantaj farklıdır - böyle bir iş için hem uygulamanın hem de işletim sisteminin kendisinin çoklu işlemeyi desteklemesi gerekir. Birden fazla iş parçacığının yürütülmesini bilgisayar kaynakları arasında dağıtma yeteneğine genellikle çoklu iş parçacığı adı verilir. Aynı zamanda işletim sisteminin çoklu iş parçacıklarını desteklemesi gerekir. Uygulamaların ayrıca bilgisayarınızın kaynaklarından en iyi şekilde yararlanmak için çoklu iş parçacığını desteklemesi gerekir. Çoklu iş parçacığı sorununu çözmeye yönelik başka bir yaklaşıma, Intel'in yeni Hyper-Threading teknolojisine bakarken bunu aklınızda bulundurun.
Verimlilik asla yeterli değildir
Verimlilik hakkında her zaman çok fazla konuşma vardır. Ve sadece kurumsal bir ortamda, bazı ciddi projelerde değil, aynı zamanda günlük yaşamda da. Homo sapiens'in beyin yeteneklerini yalnızca kısmen kullandığını söylüyorlar. Aynı şey modern bilgisayarların işlemcileri için de geçerlidir.
Örneğin Pentium 4'ü ele alalım. İşlemcide toplam yedi yürütme birimi bulunur ve bunlardan ikisi saat döngüsü başına iki işlemin (mikro işlemler) iki katı hızda çalışabilir. Ancak her durumda, tüm bu cihazları talimatlarla doldurabilecek bir program bulamazsınız. Geleneksel programlar basit tam sayı hesaplamaları ve birkaç veri yükleme ve depolama işlemiyle yetinirken, kayan nokta işlemleri bir kenara bırakılır. Diğer programlar (örneğin, Maya) öncelikle kayan nokta aygıtlarını işle yükler.
Durumu açıklamak için, üç yürütme birimine sahip bir işlemci hayal edelim: bir aritmetik mantık birimi (tamsayı ALU), bir kayan nokta birimi (FPU) ve bir yükleme/depolama birimi (bellekten veri yazmak ve okumak için). Ek olarak, işlemcimizin herhangi bir işlemi tek bir saat döngüsünde gerçekleştirebildiğini ve işlemleri aynı anda üç cihaza dağıtabildiğini varsayalım. Aşağıdaki talimatların bir dizisinin yürütülmek üzere bu işlemciye gönderildiğini hayal edelim:
Aşağıdaki şekilde aktüatörlerin yük seviyesi gösterilmektedir (gri, boşta olan bir cihazı, mavi ise çalışan bir cihazı gösterir):
Yani her saat döngüsünde tüm aktüatörlerin yalnızca %33'ünün kullanıldığını görüyorsunuz. Bu sefer FPU tamamen kullanılmadan kalır. Intel'e göre çoğu IA-32 x86 programı, Pentium 4 işlemcinin yürütme birimlerinin %35'inden fazlasını kullanmaz.
Başka bir iş parçacığı hayal edelim ve onu yürütülmek üzere işlemciye gönderelim. Bu sefer veri yükleme, veri ekleme ve saklama işlemlerinden oluşacaktır. Aşağıdaki sırayla yürütülecekler:

Ve yine aktüatörler üzerindeki yük yalnızca %33'tür.
Bu durumdan kurtulmanın iyi bir yolu Öğretim Düzeyinde Paralellik (ILP) olacaktır. Bu durumda, işlemci aynı anda birden fazla paralel yürütme birimini doldurabildiğinden, birkaç talimat aynı anda yürütülür. Ne yazık ki çoğu x86 programı ILP'ye yeterince uyarlanmamıştır. Bu nedenle verimliliği artırmanın başka yollarını bulmamız gerekiyor. Yani, örneğin sistem aynı anda iki işlemci kullanıyorsa, iki iş parçacığı aynı anda yürütülebilir. Bu çözüme iş parçacığı düzeyinde paralellik (TLP) adı verilir. Bu arada bu çözüm oldukça pahalıdır.
Modern x86 işlemcilerin yürütme gücünü artırmanın başka yolları nelerdir?
Hyper-Threading
Aktüatörlerin yetersiz kullanımı sorunu çeşitli nedenlerden kaynaklanmaktadır. Genel olarak konuşursak, eğer işlemci istenilen hızda veri alamıyorsa (bu, yetersiz sistem veri yolu ve bellek veri yolu bant genişliğinin bir sonucu olarak ortaya çıkar), aktüatörler o kadar verimli kullanılmayacaktır. Ek olarak, başka bir neden daha var - çoğu komut iş parçacığında talimat düzeyinde paralellik eksikliği.
Şu anda çoğu üretici saat hızını ve önbellek boyutlarını artırarak işlemcilerin hızını artırıyor. Elbette bu şekilde performansı artırabilirsiniz ancak yine de işlemcinin potansiyeli tam olarak kullanılmayacaktır. Eğer aynı anda birden fazla thread çalıştırabilseydik işlemciyi çok daha verimli kullanabilirdik. Hyper-Threading teknolojisinin özü tam olarak budur.
Hyper-Threading, daha önce x86 dünyası dışında var olan bir teknolojinin adıdır: Eşzamanlı Çoklu İş Parçacığı (SMT). Bu teknolojinin arkasındaki fikir basittir. Bir fiziksel işlemci, işletim sistemine iki mantıksal işlemci olarak görünür ve işletim sistemi, bir SMT işlemci veya iki normal işlemci arasındaki farkı görmez. Her iki durumda da işletim sistemi iş parçacıklarını çift işlemcili bir sistemmiş gibi yönlendirir. Ayrıca tüm sorunlar donanım düzeyinde çözülür.

Hyper-Threading'li bir işlemcide, her mantıksal işlemcinin kendi kayıt seti vardır (ayrı bir program sayacı dahil) ve teknolojiyi basit tutmak için, iki iş parçacığında getirme/kod çözme talimatlarının eşzamanlı yürütülmesini uygulamaz. Yani bu tür talimatlar birer birer yürütülür. Yalnızca sıradan komutlar paralel olarak yürütülür.
Teknoloji geçen sonbaharda Intel Geliştirici Forumunda resmi olarak duyuruldu. Teknoloji, işlemenin Maya kullanılarak gerçekleştirildiği bir Xeon işlemci üzerinde gösterildi. Bu testte Hyper-Threading özellikli Xeon, standart Xeon'dan %30 daha iyi performans gösterdi. Güzel bir performans artışı, ancak en ilginç olanı, teknolojinin Pentium 4 ve Xeon çekirdeklerinde zaten mevcut olması, ancak kapalı olmasıdır.
Teknoloji henüz piyasaya sürülmedi, ancak 0,13 mikron Xeon'u satın alıp bu işlemciyi güncellenmiş BIOS'a sahip anakartlara kuranlar, BIOS'ta Hyper-Threading'i etkinleştirme/devre dışı bırakma seçeneğini gördüklerinde muhtemelen şaşırmışlardır.
Bu arada Intel, Hyper-Threading seçeneğini varsayılan olarak devre dışı bırakacaktır. Ancak bunu etkinleştirmek için BIOS'u güncellemeniz yeterlidir. Tüm bunlar iş istasyonları ve sunucular için geçerli; kişisel bilgisayar pazarında ise şirketin bu teknolojiyle ilgili yakın gelecekte bir planı yok. Her ne kadar mümkün olsa da anakart üreticileri özel bir BIOS kullanarak Hyper-Threading'i etkinleştirme olanağı sağlayacaklar.
Geriye çok ilginç bir soru kalıyor: Intel neden bu seçeneği devre dışı bırakmak istiyor?
Teknolojinin derinliklerine inmek
Önceki örneklerdeki bu iki konuyu hatırlıyor musunuz? Bu sefer işlemcimizin Hyper-Threading ile donatıldığını varsayalım. Bu iki thread'i aynı anda çalıştırmayı denersek ne olacağını görelim:

Daha önce olduğu gibi, mavi dikdörtgenler ilk iş parçacığının talimatının yürütüldüğünü, yeşil dikdörtgenler ise ikinci iş parçacığının talimatının yürütüldüğünü gösterir. Gri dikdörtgenler kullanılmayan yürütme cihazlarını gösterirken, kırmızı dikdörtgenler farklı iş parçacıklarından iki farklı talimat aynı cihaza ulaştığında bir çakışmayı gösterir.
Peki ne görüyoruz? İş parçacığı düzeyinde paralellik başarısız oldu - yürütme cihazları daha da az verimli kullanılmaya başlandı. İşlemci, iş parçacıklarını paralel olarak yürütmek yerine, bunları Hyper-Threading olmadan yürütmeye kıyasla daha yavaş yürütür. Nedeni oldukça basit. Birbirine çok benzeyen iki thread'i aynı anda yürütmeye çalıştık. Sonuçta ikisi de yükleme/depolama işlemlerinden ve ekleme işlemlerinden oluşuyor. Eğer bir "tamsayı" uygulaması ile bir kayan nokta uygulamasını paralel olarak çalıştırsaydık çok daha iyi bir durumda olurduk. Gördüğünüz gibi Hyper-Threading'in etkinliği büyük ölçüde bilgisayardaki yükün türüne bağlıdır.
Şu anda çoğu PC kullanıcısı bilgisayarlarını yaklaşık olarak örneğimizde anlatıldığı gibi kullanıyor. İşlemci birbirine çok benzeyen birçok işlemi gerçekleştirir. Ne yazık ki benzer operasyonlar söz konusu olduğunda ilave yönetim zorlukları ortaya çıkıyor. Gerekli türde aktüatörün kalmadığı durumlar vardır ve şans eseri, normalden iki kat daha fazla talimat vardır. Çoğu durumda, ev bilgisayarı işlemcileri Hyper-Threading teknolojisini kullanıyorsa performans artmaz, hatta belki %0-10 oranında düşer.
Ancak iş istasyonlarında Hyper-Threading'in verimliliği artırmak için daha fazla fırsatı var. Ancak öte yandan, her şey bilgisayarın özel kullanımına bağlıdır. Bir iş istasyonu, 3D grafikleri işlemek için ileri teknolojiye sahip bir bilgisayar veya yalnızca ağır yüklü bir bilgisayar anlamına gelebilir.
Hyper-Threading kullanımından kaynaklanan performanstaki en büyük artış sunucu uygulamalarında gözlemlenir. Bunun temel nedeni işlemciye gönderilen işlemlerin çok çeşitli olmasıdır. İşlemleri kullanan bir veritabanı sunucusu, Hyper-Threading seçeneği etkinleştirildiğinde %20-30 daha hızlı çalışabilir. Web sunucularında ve diğer alanlarda biraz daha küçük performans artışları gözlemlendi.
Hyper-Threading'den maksimum verimlilik
Intel'in Hyper-Threading'i yalnızca kendi sunucu işlemcileri için mi geliştirdiğini düşünüyorsunuz? Tabii ki değil. Eğer durum böyle olsaydı, çip alanını diğer işlemcilerinde israf etmezlerdi. Aslında Pentium 4 ve Xeon'da kullanılan NetBurst mimarisi, eşzamanlı çoklu iş parçacığını destekleyen bir çekirdeğe mükemmel şekilde uygundur. Tekrar işlemciyi hayal edelim. Bu sefer bir aktüatöre daha sahip olacak; ikinci bir tamsayı cihazı. İş parçacıkları her iki cihaz tarafından da yürütülürse ne olacağını görelim:

İkinci tam sayı cihazını kullanırken tek çakışma son işlemde meydana geldi. Teorik işlemcimiz Pentium 4'e biraz benziyor. Üç adede kadar tam sayı aygıtına sahiptir (iki ALU ve dönüşümlü vardiyalar için bir yavaş tamsayı aygıtı). Daha da önemlisi, her iki Pentium 4 tam sayı cihazı da iki kat hızda çalışma kapasitesine sahiptir; saat döngüsü başına iki mikro işlem gerçekleştirebilir. Bu da, bu iki Pentium 4/Xeon tamsayı aygıtından herhangi birinin, bir saat döngüsünde farklı iş parçacıklarından bu iki toplama işlemini gerçekleştirebileceği anlamına gelir.
Ama bu sorunumuzu çözmüyor. Hyper-Threading'in performansını artırmak için işlemciye ek yürütme birimleri eklemek pek mantıklı olmayacaktır. Silikon alanı açısından bu son derece pahalı olacaktır. Bunun yerine Intel, geliştiricilerin programlarını Hyper-Threading için optimize etmelerini önerdi.
HALT komutunu kullanarak mantıksal işlemcilerden birini askıya alabilir, böylece Hyper-Threading'den faydalanmayan uygulamaların performansını artırabilirsiniz. Böylece uygulama daha yavaş çalışmayacak, bunun yerine mantıksal işlemcilerden biri durdurulacak ve sistem tek bir mantıksal işlemci üzerinde çalışacak - performans tek işlemcili bilgisayarlarla aynı olacaktır. Daha sonra uygulama performans açısından Hyper-Threading'den yararlanacağına karar verdiğinde ikinci mantıksal işlemci işine kaldığı yerden devam edecektir.
Intel web sitesinde Hyper-Threading'den en iyi şekilde yararlanmak için nasıl programlanacağını tam olarak açıklayan bir sunum var.
sonuçlar
Tüm modern Pentium 4/Xeon'ların çekirdeklerinde Hyper-Threading söylentilerini duyduğumuzda hepimiz son derece heyecanlanmış olsak da, bu hala tüm durumlar için ücretsiz performans olmayacak. Sebepler açık ve Hyper-Threading'in ev bilgisayarları dahil tüm platformlarda çalıştığını görmeden önce teknolojinin kat etmesi gereken uzun bir yol var. Ve geliştiricilerin desteğiyle bu teknoloji, Pentium 4, Xeon ve Intel'in gelecek nesil işlemcileri için kesinlikle iyi bir müttefik olabilir.
Mevcut sınırlamalar ve mevcut paketleme teknolojisi göz önüne alındığında, Hyper-Threading tüketici pazarı için örneğin AMD'nin SledgeHammer yaklaşımından daha akıllı bir seçim gibi görünüyor; bu işlemciler iki çekirdek kadar kullanıyor. Bumpless Build-Up Layer gibi paketleme teknolojileri olgunlaşana kadar çok çekirdekli işlemci geliştirmenin maliyeti fahiş olabilir.
AMD ve Intel'in son birkaç yılda ne kadar farklılaştığını görmek ilginç. Sonuçta AMD bir zamanlar Intel işlemcilerini pratikte kopyalamıştı. Artık şirketler, sunucular ve iş istasyonları için gelecekteki işlemcilere yönelik temelde farklı yaklaşımlar geliştirdiler. AMD aslında çok uzun bir yol kat etti. Ve eğer Sledge Hammer işlemcileri gerçekten iki çekirdek kullanıyorsa, o zaman böyle bir çözüm performans açısından Hyper-Threading'den daha verimli olacaktır. Nitekim bu durumda tüm aktüatörlerin sayısının iki katına çıkarılmasının yanı sıra yukarıda anlattığımız sorunlar da ortadan kalkıyor.
Hyper-Threading bir süreliğine ana bilgisayar pazarına girmeyecek, ancak iyi bir geliştirici desteğiyle sunucu seviyesinden ana bilgisayarlara doğru ilerleyen bir sonraki teknoloji olabilir.
Hyper-Threading teknolojisi (HT, hyperthreading) ilk olarak 15 yıl önce - 2002'de Pentium 4 ve Xeon işlemcilerde ortaya çıktı ve o zamandan beri Intel işlemcilerde (Core i serisinde, bazı Atomlarda ve yakın zamanda Pentium'da) ortaya çıktı. sonra ortadan kayboldu (desteği Core 2 Duo ve Quad hatlarında değildi). Ve bu süre zarfında efsanevi özellikler edindi - varlığının işlemci performansını neredeyse iki katına çıkardığını ve zayıf i3'leri güçlü i5'lere dönüştürdüğünü söylüyorlar. Aynı zamanda diğerleri HT'nin yaygın bir pazarlama taktiği olduğunu ve pek işe yaramadığını söylüyor. Gerçek şu ki, her zamanki gibi ortada - bazı yerlerde bunun bir anlamı var, ancak kesinlikle iki kat bir artış beklememelisiniz.
Teknolojinin teknik açıklaması
Intel web sitesinde verilen tanımla başlayalım:
Intel® Hyper-Threading Teknolojisi (Intel® HT), her çekirdekte birden fazla iş parçacığının çalışmasına izin vererek işlemci kaynaklarının daha verimli kullanılmasını sağlar. Performans açısından bu teknoloji, işlemcilerin verimini artırarak çok iş parçacıklı uygulamaların genel performansını artırır.
Genel olarak, hiçbir şeyin net olmadığı açıktır - sadece genel ifadeler, ancak teknolojiyi kısaca açıklarlar - HT, bir fiziksel çekirdeğin aynı anda birkaç (genellikle iki) mantıksal iş parçacığını işlemesine izin verir. Ama nasıl? Hyperthreading'i destekleyen işlemci:
- birden fazla çalışan iş parçacığı hakkındaki bilgileri aynı anda saklayabilir;
- bir dizi kayıt (yani işlemci içindeki hızlı bellek blokları) ve bir kesme denetleyicisi (yani, anında müdahale gerektiren herhangi bir olayın meydana gelmesi için istekleri sırayla işleme yeteneğinden sorumlu yerleşik bir işlemci birimi) içerir. her mantıksal CPU için farklı cihazlar).

Diyelim ki işlemcinin iki görevi var. İşlemcinin bir çekirdeği varsa, bunları sırayla, ikiyse iki çekirdekte paralel olarak yürütecek ve her iki görevin yürütme süresi, daha ağır görev için harcanan süreye eşit olacaktır. Peki ya işlemci tek çekirdekliyse ancak hiper iş parçacığını destekliyorsa? Yukarıdaki resimde görebileceğiniz gibi, bir görevi gerçekleştirirken işlemci %100 meşgul değildir - bu görevde bazı işlemci bloklarına gerek yoktur, bir yerlerde dal tahmin modülü bir hata yapmaktadır (bu, bir hatanın olup olmayacağını tahmin etmek için gereklidir). koşullu dallanma programda yürütülecektir), bir yerde önbellek erişim hatası vardır - genel olarak, bir görevi yürütürken işlemci nadiren% 70'ten fazla meşgul olur. Ve HT teknolojisi, boş işlemci bloklarına ikinci bir görevi "itiyor" ve iki görevin aynı anda tek bir çekirdekte işlendiği ortaya çıkıyor. Bununla birlikte, performansı iki katına çıkarmak bariz nedenlerden dolayı gerçekleşmez - çoğu zaman iki görevin işlemcide aynı bilgi işlem birimine ihtiyaç duyduğu ortaya çıkar ve sonra basit bir görev görürüz: bir görev işlenirken ikincisinin yürütülmesi basitçe şu anda durur (mavi kareler - ilk görev, yeşil - ikinci, kırmızı - işlemcide aynı bloğa erişen görevler):

Sonuç olarak, HT'li bir işlemcinin iki görev için harcadığı sürenin, en ağır görevi hesaplamak için gereken süreden fazla, ancak her iki görevi sırayla değerlendirmek için gereken süreden daha az olduğu ortaya çıkıyor.
Teknolojinin artıları ve eksileri
HT destekli işlemci kalıbının HT içermeyen işlemci kalıbından fiziksel olarak ortalama %5 daha büyük olduğu (bu, ek yazmaç bloklarının ve kesme denetleyicilerinin kapladığı miktardır) ve HT desteğinin, işlemciyi %90-95 oranında artırdıktan sonra, HT'siz %70 ile karşılaştırıldığında artışın en iyi ihtimalle %20-30 olacağını görüyoruz - rakam oldukça büyük.
Ancak her şey o kadar iyi değil: HT'den hiçbir performans artışı olmuyor ve hatta HT işlemcinin performansını kötüleştiriyor. Bu birçok nedenden dolayı olur:
- Önbellek eksikliği. Örneğin, modern dört çekirdekli i5'lerde 6 MB L3 önbellek bulunur (çekirdek başına 1,5 MB). HT'li dört çekirdekli i7'lerde önbellek zaten 8 MB'dir, ancak 8 mantıksal çekirdek olduğundan çekirdek başına yalnızca 1 MB alıyoruz - hesaplamalar sırasında bazı programlar bu hacimden yeterli olmayabilir, bu da düşüşe neden olur verim.
- Yazılım optimizasyonu eksikliği. En temel sorun, programların mantıksal çekirdekleri fiziksel olarak kabul etmesidir; bu nedenle, görevleri bir çekirdek üzerinde paralel olarak yürütürken, görevlerin aynı hesaplama birimine erişmesi nedeniyle sıklıkla gecikmeler meydana gelir ve bu da sonuçta HT'den elde edilen performans kazancını sıfıra indirir.
- Veri bağımlılığı. Önceki noktadan hareketle - bir görevi tamamlamak için diğerinin sonucu gereklidir, ancak henüz tamamlanmamıştır. Ve yine kesinti, CPU yükünde azalma ve HT'de küçük bir artışla karşılaşıyoruz.
Birçoğu var, çünkü HT hesaplamaları için bu cennetten gelen mannadır - ısı dağılımı pratikte artmaz, işlemci çok fazla büyümez ve uygun optimizasyonla% 30'a kadar bir artış elde edebilirsiniz. Bu nedenle, arşivleyicilerde (WinRar), 2D/3D modelleme programlarında (3ds Max, Maya), fotoğraf ve video işleme programlarında (Sony Vegas, Photoshop,) yükü paralelleştirmenin kolay olduğu programlarda desteği hızlı bir şekilde uygulandı. Corel çizgisi) .
Hyperthreading ile iyi çalışmayan programlar
Geleneksel olarak, bu oyunların çoğunluğudur - genellikle yetkin bir şekilde paralelleştirilmesi zordur, bu nedenle genellikle yüksek frekanslardaki dört fiziksel çekirdek (i5 K serisi) oyunlar için fazlasıyla yeterlidir, paralelleştirme i7'deki 8 mantıksal çekirdekle ortaya çıkar imkansız bir görev. Bununla birlikte, arka planda süreçlerin olduğunu da dikkate almakta fayda var ve eğer işlemci HT'yi desteklemiyorsa, bunların işlenmesi fiziksel çekirdeklere düşüyor ve bu da oyunu yavaşlatabilir. Burada HT'li i7 kazanıyor - tüm arka plan görevleri geleneksel olarak daha düşük önceliğe sahiptir, bu nedenle oyunun bir fiziksel çekirdeğinde ve bir arka plan görevinde aynı anda çalıştırıldığında, oyun artan öncelik alacaktır ve arka plan görevi çekirdeklerin "dikkatini dağıtmayacaktır" oyunla meşgul - bu yüzden oyunları yayınlamak veya kaydetmek için hiper iş parçacıklı bir i7 almak daha iyidir.
Sonuçlar
Belki de burada tek bir soru kalıyor: HT'li işlemcileri almak mantıklı mı değil mi? Beş programı aynı anda açık tutmayı ve aynı anda oyun oynamayı seviyorsanız veya fotoğraf işleme, video veya modelleme ile uğraşıyorsanız - evet, elbette almaya değer. Ağır bir programı başlatmadan önce diğerlerini kapatmaya alışkınsanız ve işleme veya modellemeyle ilgilenmiyorsanız, HT'li bir işlemcinin size hiçbir faydası yoktur.
Şubat 2002'de Intel'in tescilli teknolojisi Hyper-Threading piyasaya çıktı. Bu nedir ve neden bugün neredeyse evrensel hale geldi? Bu sorunun cevabı ve daha fazlası bu materyalde tartışılacaktır.
HT teknolojisinin ortaya çıkış tarihi
Mantıksal çoklu iş parçacığını destekleyen ilk masaüstü işlemci dördüncü nesil Pentium'du. Hyper-Threading, bu durumda iki veri akışının tek bir fiziksel çekirdekte aynı anda işlenmesini mümkün kılan bir teknolojidir. Üstelik bu çip PGA478 işlemci soketine takılıydı, 32 bit hesaplama modunda çalışıyordu ve saat frekansı 3,06 GHz idi. Bundan önce yalnızca XEON serisi sunucu işlemcili cihazlarda bulunabiliyordu.
Bu alanda başarılı sonuçlar elde ettikten sonra Intel, HT'yi masaüstü segmentine genişletmeye karar verdi. Daha sonra, PGA478'de bu tür işlemcilerden oluşan bir aile piyasaya sürüldü. LGA775 soketi piyasaya sürüldükten sonra NT geçici olarak unutuldu. Ancak LGA1156'nın satışlarının başlamasıyla 2009 yılında ikinci bir rüzgar daha aldı. O zamandan beri, hem ultra performans segmentinde hem de bütçe bilgisayar sistemlerinde Intel'in işlemci çözümlerinin zorunlu bir özelliği haline geldi.
Bu teknolojinin konsepti
Intel Hyper-Threading teknolojisinin özü, geliştiricilerin, mikroişlemci aygıtının düzeninde minimum değişiklik yaparak, sistem ve yazılım düzeylerinde kodun tek bir fiziksel çekirdekteki iki iş parçacığında işlenmesini sağlamasıdır. Bilgi işlem modülünün tüm öğeleri değişmeden kalır, yalnızca özel kayıtlar ve yeniden tasarlanmış bir kesme denetleyicisi eklenir.
Herhangi bir nedenle fiziksel bilgi işlem modülü boşta kalmaya başlarsa, ikinci program iş parçacığı onun üzerinde başlatılırken, birincisi gerekli veri veya bilgilerin alınmasını bekler. Yani, daha önce çiplerin bilgi işlem kısmındaki kesintiler oldukça sık görülüyorsa, Hyper-Threading bu olasılığı neredeyse tamamen ortadan kaldırıyor. Bu teknolojinin ne olduğuna aşağıda bakalım.

Donanım düzeyinde
Hyper-Threading kullanılırken donanıma yönelik gereksinimler artar. Anakart, BIOS ve işlemcinin bunu desteklemesi gerekir. En azından PGA478 işlemci soketi çerçevesinde bu uyumluluğa özellikle dikkat edilmesi gerekiyordu. Bu durumda tüm sistem mantık kümeleri, tıpkı işlemci aygıtları gibi NT kullanımına yönelik değildi. Ve anakartın isimlendirmesinde böylesine imrenilen bir kısaltma mevcut olsa bile, bu, BIOS'u güncellemenin gerekli olması nedeniyle yongaların doğru şekilde başlatıldığı anlamına gelmiyordu.
Bu durumda durum LGA1156'dan bu yana çarpıcı biçimde değişti. Bu bilgi işlem platformu başlangıçta Hyper-Threading'in kullanımı için tasarlandı. Bu nedenle kullanıcılar bu durumda ikincisinin kullanımıyla ilgili herhangi bir önemli sorunla karşılaşmadılar. Aynı durum LGA1155, LGA1151 ve LGA1150 gibi sonraki işlemci soketleri için de geçerlidir.
Yüksek performanslı soketler LGA1366, LGA2011 ve LGA2011-v3, HT kullanımında benzer sorun eksikliğine sahip olabilir. Üstüne üstlük, Intel'in doğrudan rakibi AMD, AM4 için son nesil işlemcilerinde çok benzer bir mantıksal çoklu görev teknolojisi olan SMT'yi uyguladı. Neredeyse aynı konsepti kullanıyor. Tek fark isminde.
Yazılım tarafındaki ana bileşenler
NT'nin donanım kaynakları tarafından tam olarak desteklense bile yazılım düzeyinde her zaman başarılı bir şekilde çalışmayacağını belirtmek gerekir. Başlangıç olarak işletim sisteminin birden fazla bilgi işlem çekirdeğiyle aynı anda çalışabilmesi gerekir. MS-DOS veya Windows 98 sistem yazılımlarının günümüzün eski sürümlerinde bu özellik bulunmamaktadır. Ancak Windows 10 durumunda herhangi bir sorun ortaya çıkmaz ve bu işletim sistemi başlangıçta kişisel bir bilgisayarın bu tür donanım kaynakları için tasarlanmıştır.
Şimdi Windows'ta Hyper-Threading'in nasıl etkinleştirileceğini bulalım. Bunu yapmak için gerekli tüm kontrol uygulama yazılımının bilgisayara yüklenmesi gerekir. Kural olarak, bu anakart CD'sindeki özel bir yardımcı programdır. BIOS'taki değerleri gerçek zamanlı olarak değiştirebileceğiniz özel bir sekmeye sahiptir. Bu da, içindeki Hyper-Threading seçeneğinin Etkin konuma gitmesine ve işletim sistemini yeniden başlatmadan bile ek mantıksal iş parçacıklarının etkinleştirilmesine yol açar.
Teknolojiyi Etkinleştirme
Pek çok acemi kullanıcı, yeni bir bilgisayar kullanmanın ilk aşamasında, Hyper-Threading ile ilgili önemli bir soruyu sıklıkla sorar: nasıl etkinleştirilir? Bu sorunu çözmenin iki olası yolu vardır. Bunlardan biri BIOS kullanıyor. Bu durumda aşağıdakileri yapmanız gerekir:
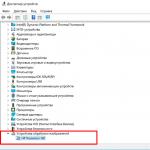
- Bilgisayarı açtığınızda, BIOS'a girme prosedürünü başlatıyoruz. Bunu yapmak için, test ekranı göründüğünde DEL düğmesini basılı tutmanız yeterlidir (bazı durumlarda F2 tuşunu basılı tutmanız gerekir).
- Mavi ekran göründükten sonra GELİŞMİŞ sekmesine gitmek için gezinme tuşlarını kullanın.
- Sonra üzerinde Hyper-Threading öğesini buluyoruz.
- Bunun karşısında değeri Etkin olarak ayarlamanız gerekir.
Bu yöntemin en önemli dezavantajı, bu işlemi gerçekleştirmek için kişisel bilgisayarın yeniden başlatılmasının gerekli olmasıdır. Gerçek bir alternatif anakart yapılandırma yardımcı programını kullanmaktır. Bu yöntem önceki bölümde ayrıntılı olarak anlatılmıştır. Ve bu durumda BIOS'a girmenize hiç gerek yok.

NT'yi devre dışı bırakma
NT'yi açma yöntemlerine benzer şekilde, bu işlevi devre dışı bırakmanın iki yolu vardır. Bunlardan biri yalnızca bilgisayar sisteminin başlatılması sırasında gerçekleştirilebilir. Bu da pratikte pek uygun değildir. Bu nedenle uzmanlar, anakartta bir bilgisayar yardımcı programının kullanılmasına dayanan ikinci yöntemi tercih ediyor. İlk durumda, aşağıdaki manipülasyonlar gerçekleştirilir:
- Elektronik bir bilgisayar yüklerken, daha önce açıklanan yönteme göre temel giriş-çıkış sistemine (ikinci adı BIOS'tur) giriyoruz.
- Gelişmiş menü öğesine gitmek için imleç tuşlarını kullanın.
- Daha sonra Hyper-Threading menü öğesini bulmanız gerekir (bazı anakart modellerinde HT olarak belirtilmiş olabilir). Karşısındaki PG DN ve PG UP düğmelerini kullanarak değeri Devre Dışı olarak ayarlayın.
- Yıkılan değişiklikleri F10 kullanarak kaydediyoruz.
- BIOS'tan çıkın ve kişisel bilgisayarı yeniden başlatın.
İkinci durumda, anakart tanılama yardımcı programını kullanırken bilgisayarı yeniden başlatmaya gerek yoktur. Bu onun temel avantajıdır. Bu durumda algoritma aynıdır. Aradaki fark, anakart üreticisinin önceden yüklenmiş özel bir yardımcı programını kullanmasıdır.
Daha önce Hyper-Threading'i devre dışı bırakmanın iki ana yolu açıklanmıştı. İkincisi nominal olarak daha karmaşık kabul edilse de, bilgisayarın yeniden başlatılmasını gerektirmemesi nedeniyle daha pratiktir.

NT'yi destekleyen işlemci modelleri
Başlangıçta, daha önce de belirtildiği gibi, Hyper-Threading desteği yalnızca Pentium 4 serisi işlemcili cihazlarda ve yalnızca PGA478 sürümünde uygulanıyordu. Ancak LGA1156 ve sonraki bilgi işlem platformları çerçevesinde, bu materyalde tartışılan teknoloji neredeyse tüm olası çip modellerinde kullanıldı. Onun yardımıyla Celeron işlemciler tek çekirdekten çift iş parçacıklı çözüme dönüştü. Buna karşılık Penrium ve i3, onun yardımıyla zaten 4 kod akışını işleyebiliyordu. i7 serisinin amiral gemisi çözümleri, 8 mantıksal işlemciyle aynı anda çalışabilme kapasitesine sahiptir.
Netlik sağlamak amacıyla, Intel - LGA1151'in mevcut bilgi işlem platformunda NT kullanımını sunuyoruz:
- Celeron serisi CPU'lar bu teknolojiyi desteklemez ve yalnızca 2 hesaplama birimine sahiptir.
- Pentium hattı çipleri 2 çekirdek ve dört iş parçacığıyla donatılmıştır. Sonuç olarak NT bu durumda tamamen desteklenmektedir.
- Core i3 model serisinin daha güçlü işlemcili cihazları benzer bir düzene sahiptir: 2 fiziksel modül 4 iş parçacığında çalışabilir.
- Çoğu bütçe Celeron yongası gibi Core i5 de HT desteğiyle donatılmamıştır.
- Amiral gemisi i7 çözümleri aynı zamanda HT'yi de destekler. Ancak bu durumda 2 gerçek çekirdek yerine zaten 4 kod işleme birimi vardır. Onlar da zaten 8 iş parçacığında çalışabilirler.
Hyper-Threading - bu teknoloji nedir ve temel amacı nedir? Bu, minimum donanım ayarlamaları yoluyla bir bütün olarak bilgisayar sisteminin performansını artırmaya olanak tanıyan mantıksal çoklu görevdir.

Bu teknoloji hangi durumlarda en iyi şekilde kullanılır?
Bazı durumlarda, daha önce de belirtildiği gibi NT, işlemcinin program kodunu işleme hızını artırır. Hyper-Threading yalnızca sıcak yazılımlarla etkili bir şekilde çalışabilir. Tipik örnekler video ve ses kodlayıcılar, profesyonel grafik paketleri ve arşivleyicilerdir. Ayrıca böyle bir teknolojinin varlığı, sunucu sisteminin performansını önemli ölçüde artırabilir. Ancak program kodunun tek iş parçacıklı uygulanmasıyla Hyper-Threading'in varlığı dengelenir, yani tek çekirdekte bir görevi çözen normal bir işlemci elde edersiniz.
Avantajlar ve dezavantajlar
Intel Hyper-Threading teknolojisinin bazı dezavantajları vardır. Bunlardan ilki CPU maliyetinin artmasıdır. Ancak daha yüksek hız ve geliştirilmiş silikon çip düzeni her durumda CPU'nun fiyatını artıracaktır. Ayrıca işlemci cihazının yarı iletken tabanının artan alanı, güç tüketiminin ve sıcaklığın artmasına neden olur. Bu durumda fark önemsizdir ve% 5'i geçmez, ancak hala mevcuttur. Bu durumda başka önemli bir eksiklik yoktur.
Şimdi faydaları hakkında. Intel'in tescilli NT teknolojisi performansı ve performansı etkilemez, yani böyle bir bilgisayar belirli bir eşiğin altına düşemeyecektir. Yazılım paralel hesaplamayı mükemmel bir şekilde destekliyorsa, hızda ve elbette üretkenlikte belirli bir artış olacaktır.
Testler bazı durumlarda artışın %20'ye ulaşabileceğini gösteriyor. Bu durumda en optimize edilmiş yazılım, çeşitli multimedya içerik kodlayıcıları, arşivleyicileri ve grafik paketleridir. Ancak oyunlarda her şey o kadar iyi değil. Bunlar da 4 iş parçacığında çalışabiliyorlar ve sonuç olarak amiral gemisi yongaları bu durumda orta seviye işlemci çözümlerinden daha iyi performans gösteremiyor.

AMD'den modern bir alternatif
Hyper-Threading teknolojisi günümüzde türünün tek örneği değil. Gerçek bir alternatifi var. AM4 platformunun piyasaya sürülmesiyle AMD, ona SMT şeklinde değerli bir rakip sundu. Donanım düzeyinde bunlar aynı çözümlerdir. Yalnızca Intel'in amiral gemisi 8 iş parçacığını işleyebilir ve önde gelen AMD çipi 16 iş parçacığını işleyebilir. Tek başına bu durum, ikinci çözümün daha umut verici olduğunu gösteriyor.
Bu nedenle Intel, ürün planlarını acilen ayarlamak ve AMD'nin yeni gelenleriyle rekabet edebilecek tamamen yeni işlemci çözümleri sunmak zorunda kalıyor. Ancak bugün henüz yeniden düzenlenmediler. Bu nedenle uygun fiyatlı bir bilgisayar platformuna ihtiyacınız varsa Intel'den LGA1151'i seçmek daha iyidir. Performans artışına ihtiyacınız varsa AMD'nin AM4'ü tercih edilebilir.