Karar vermeyi desteklemek için analitik veri işleme yöntemleri. Operasyonel Analitik Veri İşleme (OLAP)
3.4 Analitik Veri İşleme Yöntemleri
Mevcut veri depolarının yönetim kararlarının benimsenmesine katkıda bulunmaları için, bilgiler doğru biçimde analitiklerle temsil edilmelidir, yani depo verilerine ve işlemlerine erişim için araçlar geliştirmiş olmalıdır.
Çok sık, karar vermelerinin doğrudan kullanımı konusunda yaratılan bilgi ve analitik sistemler kullanımda son derece basittir, ancak işlevsellikte sağlam bir şekilde sınırlıdır. Bu tür statik sistemler, başın (IPR) veya İcra Bilgi Sistemlerinin (EIS) bilgi sistemleri olarak adlandırılır. Birçok istek içerirler ve günlük inceleme için yeterli, karar verirken ortaya çıkabilecek tüm sorulara cevap veremiyorlar. Bu tür bir sistemin kuralı olarak, analistin yeni bir dizi soruya sahip olduğu kapsamlı bir çalışmadan sonra çok sayfalı raporlardır. Bununla birlikte, böyle bir sistemi tasarlarken öngörülemeyen her yeni istek, resmen bir programcı tarafından kodlanmış ve daha sonra yürütülmesi gerekir. Bu durumda bekleme süresi, her zaman kabul edilebilir olmayan saatler ve günler yapabilir.
Operasyonel Analitik İşleme. Veya çevrimiçi analitik işlem, OLAP, veri depolarının organizasyonunun kilit bileşenidir. OLAP konsepti 1993 yılında Edgar Coddo tarafından tarif edilmiştir ve çok boyutlu analiz uygulamaları için aşağıdaki şartlara sahiptir:
- Hiyerarşiler ve çoklu hiyerarşiler için tam destek dahil, verilerin çok boyutlu kavramsal sunumu (anahtar OLAP gereksinimi);
- Kullanıcının, fiyatın ayrıntılı analizden daha az olsa bile, kabul edilebilir bir süre (genellikle en fazla 5 saniye) için analiz sonuçlarına vermek;
- Bu uygulamanın herhangi bir mantıklı ve istatistiksel analiz özelliğini uygulayabilme ve kullanımı kolay bir biçimde korunması;
- İlgili engelleme mekanizmalarının desteğiyle ve yetkili erişim araçlarıyla verilere çok oyunculu erişim;
- Hacim ve depolama konumundan bağımsız olarak gerekli tüm bilgilere başvurma yeteneği.
OLAP sistemi çeşitli bileşenlerden oluşur. En yüksek görünüm seviyesinde, sistem, OLAP teknolojisine, OLAP sunucusuna ve istemciye dayanan raporlama mekanizmasını uygulama yeteneğini sağlayan çok boyutlu bir veritabanı (MBD), bir veri kaynağı içerir. Sistem istemci-sunucu prensibi üzerine kuruludur ve MBD sunucusuna uzak ve çok oyunculu erişim sağlar.
OLAP sisteminin kompozit kısımlarını düşünün.
Kaynaklar.OLAP sistemlerdeki kaynak, analiz için veri sağlayan bir sunucudur. OLAP ürününün kullanım alanına bağlı olarak, kaynak bir veri ambarı, genel verileri içeren kalıtsal veritabanı olarak hizmet verebilir, ayarlanabilir
finansal verileri veya listelenen herhangi bir kombinasyonu birleştiren tablolar.
Bilgi deposu. İlk veriler, veri depolarının bina ilkelerine uygun olarak tasarlanan depoya toplanır ve yerleştirilir. HD bir ilişkisel veritabanıdır (RBD). HD'nin ana tablosu (gerçek tablosu) içerir sayısal değerler İstatistiksel bilgilerin toplandığı göstergeler.
Çok boyutlu veritabanı. Veri depolama, bir nesne kümesi olan çok boyutlu bir veritabanı için bir servis sağlayıcı görevi görür. Bu nesnelerin ana sınıfları ölçümler ve göstergelerdir. Ölçümler, zaman, bölgeler, kurum tipi, vb. Gibi veri endekslemesinin meydana geldiği birden fazla değer (parametre) içerir. Her ölçüm, karşılık gelen veri depolama ölçüm tablolarından değerlerle doldurulur. Ölçümlerin toplamı, sürecin çalışma alanını belirler. Göstergeler çok boyutlu veri küpleri (hipercubs) ile anlaşılmaktadır. Hypercube, verilerin yanı sıra, göstergenin bir parçası olan ölçümlerin toplam miktarını içerir. Göstergeler MBD'nin ana içeriğini oluşturur ve gerçek tabloya göre doldurulur. Her eksen hypercube boyunca, detaylarının farklı seviyelerini temsil eden bir hiyerarşi şeklinde veriler düzenlenebilir. Bu, daha sonraki analiz, toplama veya detaylandırma verilerinin gerçekleştirileceği hiyerarşik ölçümler oluşturmanıza olanak sağlar. Tipik bir hiyerarşik boyut örneği, ilçeler, bölgeler, ilçeler tarafından gruplandırılmış bölge nesnelerinin bir listesidir.
Sunucu.OLAP sisteminin aplikatör kısmı bir OLAP sunucusudur. Bu bileşen tüm işleri gerçekleştirir (sistem modeline bağlı olarak) ve aktif erişimin sağlandığı tüm bilgileri saklar. Sunucu mimarisi, çeşitli kavramları yönetir. Özellikle, OLAP ürünlerinin ana fonksiyonel özelliği, veri depolama için MBD veya RBD'nin kullanımıdır.
Müşteri uygulamasıMüşteri uygulamasını kullanarak analiz için uygun şekilde yapılandırılmış ve MBD'de depolanan veriler mevcuttur. Kullanıcı, verilere uzaktan erişim, karmaşık sorguları formüle ederek, Raporlar oluşturarak, keyfi veri alt kümeleri edinir. Raporun alınması, belirli ölçüm değerlerinin seçimine ve hipercube'nin enine kesitinin yapısına düşürülür. Bölüm, seçilen ölçüm değerleri ile belirlenir. Diğer boyutlar için veriler toplanmıştır.
Olap. İstemcide ve sunucuda.Birden fazla veri analizi, istemciye ve sunucu olaplarına ayrılabilecek çeşitli araçlar kullanılarak gerçekleştirilebilir.
Müşteri olaps (örneğin, Excel 2000'deki Pivot Tabloları, Microsoft veya Proclarity Firms firmalarındaki Pivot Tabloları), toplam verileri hesaplayan ve bunları görüntüleyen uygulamalardır. Bu durumda, toplam verilerin kendisi, böyle bir OLAP'nin adres alanındaki önbellekte bulunur.
İlk veriler masaüstü DBMS'de bulunursa, toplam verilerin hesaplanması OLAP'in kendisi tarafından gerçekleştirilir. Kaynak veri kaynağı bir sunucu DBMS'si ise, istemci OLAP fonlarının çoğu SQL istek sunucusuna gönderilir ve sonuç olarak, sunucuda hesaplanan toplam veriler elde edilir.
Kural olarak, OLAP işlevselliği istatistiksel veri işleme ve bazı elektronik tablolarda uygulanır.
Birçok geliştirme aracı, en basit olap işlevselliğini uygulayan (örneğin Borland Delphi ve Borland C ++ Builder'daki karar küp bileşenleri gibi) en basit OLAP işlevselliğini uygulayan uygulamaları oluşturmanıza olanak tanıyan sınıf kütüphaneleri veya bileşenler içerir. Buna ek olarak, birçok şirket, ActiveX kontrolleri ve bu işlevselliği uygulayan diğer kütüphaneler sunar.
Müşteri olaps, bir kural olarak, az sayıda ölçüm (genellikle altıdan fazla) ve bu parametrelerin az miktarda çeşitli değerleri ile kullanılır - çünkü elde edilen toplam veriler benzer bir yolun adres alanında sıkıştırılmalıdır. ve sayıları, ölçüm sayısındaki artışla katlanarak artmaktadır.
Birçok müşteri olası, önbelleğin içeriğini, yeniden hesaplamalarını yapmamak için bir dosya şeklinde toplam verilerle kaydetmenizi sağlar. Bununla birlikte, bu olasılık, bunları diğer kuruluşlara aktarmak veya yayınlamak için agrega verileri yabancılaştırmak için kullanılır.
Bir önbelleğe agrega verilerle bir önbellek kaydetme fikri, agrega verilerinin tasarrufu ve değiştirilmesi ve depolama için destek verdiği Sunucu OLAP (örneğin, Oracle Express sunucu veya Microsoft OLAP hizmetleri) Bunları içeren, OLAP Server adlı ayrı bir uygulama veya işlem ile gerçekleştirilir. İstemci uygulamaları, benzer bir çok boyutlu depolama talebinde bulunabilir ve belirli verileri almak için yanıt olarak. Bazı istemci uygulamaları, böylece değiştirilen kaynak verilerine göre bunları böyle bir mağaza oluşturabilir veya güncelleyebilir.
Sunucu olaplarını uygulama avantajlarının Avantajları OLAP araçlarıyla karşılaştırıldığında, masaüstlerine kıyasla sunucu DBMS'lerin uygulanmasının avantajlarına benzerdir: Sunucu Araçları kullanılıyorsa, agrega verilerinin hesaplanması ve depolanması sunucuda gerçekleşir ve istemci uygulaması yalnızca sonuçlarını alır. Genel davada izin veren, ağ trafiğini, sorgu zamanını ve müşteri uygulaması tarafından tüketilen kaynak gereksinimlerini azaltın.
3.5 Çok boyutlu depolamanın teknik yönleri
OLAP uygulamalarında çok boyutluluk üç seviyeye ayrılabilir:
1. Çok boyutlu veri gösterimi - Çok boyutlu görselleştirme ve veri manipülasyonu sağlayan son kullanıcı araçları; Çok boyutlu gösterim katmanı, fiziksel veri yapısından kurtuldu ve verileri çok boyutlu olarak algılıyor.
Çok boyutlu tedavi - Çok boyutlu sorguları formüle etme (Geleneksel ilişkisel dil SQL'si uygun olmayan) ve böyle bir talebi işleyebilecek ve yürütebilen işlemci anlamına gelir.
Çok boyutlu depolama - Çok boyutlu taleplerin etkili bir şekilde uygulanmasını sağlayan fiziksel veri kuruluşunun araçları.
İlk iki seviye mutlaka tüm OLAP araçlarında bulunur. Üçüncü seviye, yaygın olmasına rağmen, çok boyutlu gösterim için veriler normal ilişkisel yapılardan çıkarılabildiğinden gerekli değildir. Çok boyutlu sorgu işlemcisi, bu durumda, çok boyutlu istek taleplerini ilişkisel DBMS tarafından yürütülen SQL sorgularına çevirir.
Hem her zamanki gibi hem de çok boyutlu bir veri ambarında - operasyonel sistemlerden elde edilen ayrıntılı verilerle birlikte, her iki toplu gösterge, her iki toplu gösterge, satış hacimleri gibi, mal kategorileri, vb. açıkça tek amaçlı - isteklerin yürütülmesini hızlandırmak için. Sonuçta, bir yandan, depolama, bir kural olarak, çok fazla miktarda veri, diğer taraftan, çoğu durumda detaylı değil, ancak genelleştirilmiş göstergelerle ilgilenmektedir. Ve eğer her zaman satış miktarını hesaplamak için yılın milyonlarca bireysel satışını özetlemesi gerektiğinde, hız büyük olasılıkla kabul edilemezdi. Bu nedenle, çok boyutlu veritabanlarına veri yüklerken, tüm toplam göstergeler veya kısımları hesaplanır ve kaydedilir.
Bununla birlikte, toplu verilerin kullanımı dezavantajları ile doludur. Ana dezavantajları, depolanan bilgilerin hacminde bir artışdır (yeni ölçümler eklendiğinde, küpün veri bileşenlerinin miktarı üstel olarak büyüyor) ve indirmeleri için zaman. Ayrıca, bilgi miktarı düzinelerce ve hatta yüzlerce kez artar olabilir. Örneğin, yayınlanan standart testlerden birinde, toplam 10 MB kaynak verisi için agregaların tam olarak değerlendirilmesi 2,4 GB, yani veriler 240 kez arttı!
Birimlerin hesaplanmasında veri miktarını artırma derecesi, küpün ölçümlerinin sayısına ve bu ölçümlerin yapısı, yani "ebeveynler" ve "torunlar" sayısının farklı ölçüm seviyelerinde oranı. Toplamların depolanması problemini çözmek için, karmaşık şemalar, olası tüm birimlerden uzak hesaplandığında, sorguların performansında önemli bir artış elde etmek için geçerlidir.
Hem kaynak hem de toplu veriler de depolanabilir
ilişkisel veya çok boyutlu yapılarda. Bu bağlamda, çok boyutlu verilerin depolanması yöntemi şu anda uygulanır:
Molap. (Çok boyutlu OLAP) - Kaynak ve toplu veriler çok boyutlu bir veritabanında saklanır. Çok boyutlu yapılardaki verilerin depolanması, toplam değerlerin hesaplanmasının herhangi bir ölçüm için hesaplama oranının aynı olduğu için, çok boyutlu bir dizi olarak verilerin manipüle edilmesini sağlar. Bununla birlikte, bu durumda, çok boyutlu veritabanı yedekli, çünkü çok boyutlu veriler tamamen kaynak ilişkisel verileri içeriyor.
Bu sistemler eksiksiz bir OLAP işlemcisi sağlar. Ayrıca, sunucu bileşenine ek olarak, kendi entegre istemci arabirimi, e-tablolarla kullanıcı harici çalışma programlarıyla iletişim kurmak için kullanılır.
Rulap. (İlişkisel OLAP) - İlk veri, başlangıçta oldukları ve olduğu gibi aynı ilişkisel veritabanında kalır. Toplam veriler, aynı veritabanındaki depolamaları için özel olarak oluşturulan servis tablolarına yerleştirilir.
Holap (Hibrit OLAP) - İlk veriler, aslında tutuldukları aynı ilişkisel veritabanında kalır ve toplam veriler çok boyutlu bir veritabanında saklanır.
Bazı OLAPS, yalnızca ilişkisel yapılarda veri depolamasını destekleyin, bazıları sadece çok boyutludur. Ancak, çoğu modern sunucu OLAP fonları, üç depolama yönteminin tümünü desteklemektedir. Depolama yönteminin seçimi, kaynak verilerin boyutuna ve yapısına, isteklerin yürütülmesi hızı ve OLAP küplerinin güncelleme sıklığına bağlıdır.
3.6 Akıllı Veri Analizi (Veri.Madencilik.)
Veri madenciliği terimi, çeşitli matematiksel ve istatistiksel algoritmalarla korelasyon, trendler ve ilişkiler bulma sürecini belirtir: karar alma sistemleri için kümelenme, regresyon ve korelasyon analizi vb. Aynı zamanda, birikmiş bilgiler otomatik olarak bilgi olarak tanımlanabilecek bilgilere özetlenir.
Modern teknoloji veri madenciliğinin temeli, veri aboneliğinde doğal olan kalıpları yansıtan şablonların kavramına ve gizli bilginin bileşenlerinin bileşenlerine dayanmaktadır.
Şablonlar arayışı, bu alt topraklar hakkında herhangi bir önyargı varsayımını kullanmayan yöntemlerle yapılır. Veri madenciliğinin önemli bir özelliği, standart olmayan ve aranan şablonların görünmezliğidir. Başka bir deyişle, veri madenciliği araçları, önceden belirlenmiş ara bağlantı kullanıcılarının kontrolü yerine, veri istatistiksel araçlarından ve OLAP araçlarından farklıdır.
veriler arasında, mevcut verilerin temelinde, bu tür ilişkileri bağımsız olarak bulabilmek ve bunları hakkında hipotezler inşa edebilecekleridir.
Genel durumda, verilerin entelektüel analizinin (veri madenciliği) verileri üç aşamadan oluşur.
belirleme kalıpları (ücretsiz arama);
bilinmeyen değerlerin (prognostik modelleme) tahmin etmek için tanımlanmış kalıpların kullanımı;
yürütme analizi, bulunan düzenliliklerde anomalileri belirlemek ve yorumlamak için tasarlanmıştır.
Bazen, bulguları ve kullanımları arasında bulunan düzenliliklerin güvenilirliğinin doğrulanmasının bir ara aşamasını açıkça ayırt eder (doğrulama aşaması).
Veri madenciliği yöntemleriyle algılanan ciddi beş standart desen türü:
1.Asociationarada dolaylı olarak verilen bağlantıların olduğu, istikrarlı nesne gruplarını seçmenize olanak sağlar. Bir yüzde olarak ifade edilen ayrı bir konunun veya nesne grubunun görünümünün sıklığı, prevalans denir. Düşük prevalans (binde birden az), böyle bir derneğin önemli olmadığını göstermektedir. Dernekler kurallar şeklinde kaydedilir: A.=> B.nerede FAKAT -parsel İÇİNDE -corollary. Her bir ilişkisel kuralın önemini belirlemek için, güven olarak adlandırılan değeri hesaplamak gerekir. FAKATiçin İÇİNDE(veya ara bağlantı A ve B).Güven ne sıklıkta ne sıklıkta gösterir. FAKATgörünür İÇİNDE.Örneğin, eğer d (A / B)\u003d% 20, o zaman bu, bir ürün satın alırken FAKATher beşinci durumda, mallar da satın alınır İÇİNDE.
Birliğin uygulanmasının tipik bir örneği, satın alma yapısının analizidir. Örneğin, bir süpermarkette bir çalışma yaparken, patates cipolarının% 65'inin "Coca-Cola" nı yaptığını ve böyle bir kit için bir indirim varsa, Kola% 85'inde satın alındığını belirlemek mümkündür. davaların. Benzer sonuçlar, pazarlama stratejilerinin oluşumunda değerlidir.
2. Resepsiyon - bu, zaman içinde dernekleri tanımlama yöntemidir. Bu durumda, belirli olay gruplarının tutarlı görünümünü tanımlayan kurallar belirlenir. Bu tür kurallar, senaryoları inşa etmek için gereklidir. Ek olarak, örneğin, belirli bir ürünün satışını gerektiren tipik bir önceki satış setini oluşturmak için kullanılabilirler.
3. Sınıflandırma - genelleme aracı. Tek nesnelerin bazı nesneleri karakterize eden genelleştirilmiş kavramlara dikkat edilmesini sağlar ve bu Colts (Sınıflar) ait nesneleri tanımak için yeterlidir. Kavramların oluşumu kavramının özü, sınıflarda doğal kalıpları bulmaktır. Nesneleri tanımlamak için, birçok farklı özellik (nitelik) kullanılır. Karakteristik açıklamalar hakkında kavramların oluşumunun sorunu, M.M. ile formüle edildi. BONGART. Çözümü, iki ana prosedürün kullanımına dayanmaktadır: öğrenme ve kontrol. Çalışma prosedürleri, bir öğrenme nesnesinin işlenmesini temel alan bir sınıflandırma kuralı tarafından inşa edilmiştir. Doğrulama Prosedürü (Sınav), yeni (sınav) örneğinden nesneleri tanımak için elde edilen sınıflandırma kuralını kullanmaktır. Test sonuçları tatmin edici olarak kabul edilirse, öğrenme işlemi sona erer, aksi takdirde sınıflandırma kuralı yeniden öğrenme sürecinde belirtilmiştir.
4. claileveration - Bu, bu grupların eşzamanlı olarak tanımı olan gruplar için (kümeler) veya segmentler için bilgi (kayıtların) dağıtımıdır. Sınıflandırmanın aksine, analiz için sınıfların ön işini gerektirmez.
5. Prognozan Zaman Serisi zaman içinde dikkate alınan nesnelerin nitelikteki eğilimlerin belirlenmesi için bir araçtır. Zaman serisinin davranışının analizi, incelenen özelliklerin değerlerini tahmin etmenizi sağlar.
Bu tür görevleri çözmek için çeşitli yöntemler ve veri madenciliği algoritmaları kullanılır. Veri madenciliğinin istatistikler, bilgi teorisi, makine öğrenmesi, veritabanı teorisi gibi disiplinlerin birleştiğinde geliştiği ve geliştiği gerçeğinden dolayı, çoğu algoritmanın ve veri madenciliği yönteminin çeşitli yöntemler temelinde geliştirilmesi oldukça doğaldır. bu disiplinler.
Mevcut veri araştırma yöntemlerinin manifoldundan aşağıdakileri seçebilirsiniz:
regresyon, Dispersiyon ve Korelasyon Analizi(özellikle de şirketlerin SAS Enstitüsü, StatSoft, vb.) Şirketler ürünlerinde uygulanan (özellikle de modern istatistiksel paketlerde uygulanır);
analiz Yöntemleriampirik modellere dayanan belirli bir konu alanında (genellikle, örneğin, finansal analizin düşük maliyetli fonlarında kullanılır);
sinir Ağı Algoritmaları- Kompleks bağımlılıklarının çoğaltılmasına izin veren işlemlerin ve fenomenlerin taklit yöntemi. Yöntem, biyolojik beynin basitleştirilmiş bir modelinin kullanımına dayanır ve başlangıç \u200b\u200bparametrelerinin "nöronlar" arasındaki bağlantılara ve analiz sonucu olan bir cevap olarak dönüştürüldüğü sinyaller olarak değerlendirilir. tüm ağın kaynak verilerine cevabıyla kabul edilir. Bu durumda iletişim, hem kaynak verilerini hem de doğru cevapları içeren büyük bir hacmi örnekleyerek sözde ağ eğitimi kullanılarak oluşturulur. Sinir ağları, sınıflandırma görevlerini çözmek için yaygın olarak kullanılır;
bulanık mantıkÇeşitli dilsel değişkenlerle temsil edilebilecek bulanık gerçeği değerleriyle veri işleme için kullanılır. Bilginin bulanık sunumu, örneğin XperTrule Miner Sisteminde (Attar Software Ltd., Birleşik Krallık), AIS, Neufuz, vb. Sınıflandırma ve Tahmin görevlerini çözmek için yaygın olarak kullanılır.
endüktif sonuçlarveritabanında depolanan gerçeklerin genelleştirilmesine izin verin. Endüktif eğitim sürecinde, bir uzmanlık sağlama hipotezleri katılabilir. Bu yöntemin öğretmenle öğrenme denir. Genelleme kuralları arayışı, otomatik olarak hipotez üreterek öğretmen olmadan gerçekleştirilebilir. Modern yazılımda, kural olarak, her iki yöntem de birleştirilir ve hipotezleri test etmek için istatistiksel yöntemler kullanılır. Endüktif sonuçların kullanımı ile bir sistemin örneği, Attar Software Ltd. tarafından geliştirilen XperTrule Miner'dır. (Büyük Britanya);
muhakeme dayalı benzer durumlar("En yakın komşu" yöntemi) (vaka tabanlı muhakeme - CBR), açıklamaları, belirli bir duruma sahip bir dizi özelliğe benzer olan durumlar için arayışa dayanmaktadır. Analojinin prensibi, benzer durumların sonuçlarının da birbirlerine yakın olacağını göstermektedir. Bu yaklaşımın dezavantajı, önceki deneyimi genelleştiren hiçbir model veya kural olmadığı gerçeğinde yatmaktadır. Ek olarak, çıkış sonuçlarının güvenilirliği, endüktif çıkış işlemlerinde olduğu gibi durumların açıklamasının eksiksizliğine bağlıdır. CBR kullanarak sistem örnekleri: Kate Tools (Acknosoft, Fransa), Desen Tanıma Tezgahı (Unica, ABD);
ağaç Çözümleri- Verileri verileri sınıflandırmak veya kararların etkilerini analiz eden bir ağaç grafiği şeklinde bir görevi yapılandırma yöntemi. Bu yöntem, çoğu kişi yoksa, sınıflandırma kuralları sistemi hakkında görsel bir fikir verir. Basit görevler, bu yöntemle sinir ağlarını kullanmaktan çok daha hızlı çözülür. Karmaşık problemler için ve bazı veri türleri için, çözümlerin ağaçları kabul edilemez olabilir. Ek olarak, bu yöntem önem sorunu ile karakterizedir. Hiyerarşik veri kümelerinin sonuçlarından biri, birçok özel durum için çok sayıda eğitim örneğinin olmamasıdır ve bu nedenle sınıflandırma güvenilir olarak kabul edilemez. Karar alma yöntemleri Ağaçlar, yani birçok yazılımda, yani: C5.0 (Kuraycu, Avustralya), Clementine (Integral Solutions, Birleşik Krallık), Sipina (Lyon Üniversitesi, Fransa), IDIS (Bilgi Keşif, ABD);
evrimsel Programlama- Arama işlemi sırasında değiştirilmiş başlangıçta belirtilen algoritma temelinde verilerin birbirine bağlılığını ifade eden bir algoritmanın aranması ve oluşturulması; Bazen birbirine bağımlılıkların aranması, belirli herhangi bir fonksiyon türü arasında gerçekleştirilir (örneğin, polinomlar);
sınırlı bütünlük algoritmalarıVeri alt gruplarındaki basit mantıksal olayların hesaplama kombinasyonları.
3.7 EntegrasyonOlap. veVeri.Madencilik.
Operasyonel Analitik İşleme (OLAP) ve Akıllı Veri Analizi (Veri Madenciliği) - Karar verme sürecinin iki bileşeni. Bununla birlikte, bugün, OLAP sistemlerinin çoğunluğu sadece çok boyutlu verilere erişim sağlamaya odaklanır ve kalıp alanında çalışan çoğu veri madenciliği aleti tek boyutlu veri beklentileri ile uğraşıyor. Karar destek sistemleri için veri işleme verimliliğini artırmak için, bu iki analiz türü birleştirilmelidir.
Şu anda, bileşik terim "OLAP veri madenciliği" (çok boyutlu akıllı analiz) böyle bir sendikayı belirliyor gibi görünüyor.
"OLAP veri madenciliği" oluşturmanın üç ana yolu vardır:
- Öğretim El Kitabı
... konferanslar. Hazırlık konferanslar matematik. yazı Özkonferanslar konferanslar. Kullanma bilgiteknoloji ...
Ve Lebedev'de KondAurov'a, gelecekteki matematik öğretmeni öğretmeninin ilköğretim matematikleri ve öğretme yöntemi ile
Öğretim El Kitabı... konferanslar. Hazırlık konferanslar matematik. yazı Özkonferanslar. Görsel faydaların hazırlanması. Okuma tekniği konferanslar. Kullanma bilgiteknoloji ...
M Medya Mesleki Eğitim Modernizasyonu ONERG MARK - Ağustos 2011
Özet... 11 .08.2011 RNIM'de "Ölü Souls-2" onlara ... 3,11 -3,44 . ... halka açık konferanslar Liderler ... Cheboksary ... ve vuruş Öz seyirci - ... bilgisistemler ve teknolojiler. ... sistem Eğitim - diyor doçent ... derleyiciler ... parçalar Gerçek geliştirmek İçerik ...
"Küp takma sonra." Akıllı analiz yapabilme yeteneği, bir talebin herhangi bir sonucu, bu, hipercube göstergelerinin herhangi bir projeksiyonunun herhangi bir parçası üzerindeki herhangi birinin herhangi birinin herhangi bir sonucu üzerinde sağlanmalıdır.
"Madencilik sonra küp." Depodan çıkan veriler gibi, entelektüel analizin sonuçları, daha sonra çok boyutlu analiz için hipercubik formda sunulmalıdır.
"Madencilik sırasında küp." Entegre etmenin bu esnek yolu, genelleme düzeyleri arasında, yeni bir hipercube fragmanı, vb.
11. Sınıf [Metin ... onlara gibi bölüm herşey sistemler ... doçent ... Cheboksary, 2009. 10. S. 44 -49 ... Yazarlar- derleyiciler: N. ... Özkonferanslar, ...
İş Süreçlerinin Analitik Teknolojileri
İş zekası iş zekası (BI), çeşitli araçları ve teknoloji analizini ve işletmenin veri işlenmesini birleştirir. Bi-sistemler, bu fonlara dayanarak, bunun amacı, yönetim kararlarını vermek için bilgi kalitesini artırmaktır.
BI, aşağıdaki sınıfların yazılım ürünlerini içerir:
· Operasyonel Analitik İşleme Sistemleri (OLAP);
· Akıllı veri analizi araçları (DM);
Her sınıfın yazılım ürünleri özel teknolojiler kullanarak belirli bir fonksiyon veya işlem seti gerçekleştirir.
OLAP (çevrimiçi analitik işleme) - Operasyonel analitik işlem, belirli bir ürünün adıdır, ancak bir teknolojidir. OLAP konseptinin temeli, çok boyutlu bir veri sunumu yatmaktadır.
1993 yılında, Ortaklar (Edgar Codd, Matematics ve Scholant IBM) Edgar CODD veritabanlarını (Edgar Codd, Matematics ve Scholant IBM) veritabanlarını oluşturmaya yönelik olarak kurucusu, şirket tarafından başlatılan ve "Analist kullanıcıları için OLAP sağlama (operasyonel analitik işleme)" başlıklı bir makale yayınladı. Hangi 12, OLAP teknolojisi kriterleri formüle edildi, daha sonra yeni ve çok umut verici teknolojinin ana içeriği haline geldi.
Daha sonra, OLAP ürünlerinin gerekliliklerini tanımlayan FASMI testinde elden geçirildiler:
· Hızlı. OLAP uygulaması, analitik verilere minimum bir erişim süresi sağlamalıdır - ortalama 5 saniye;
· Analiz (analiz). OLAP uygulaması, kullanıcıya sayısal ve istatistiksel analiz yapabilme yeteneğini vermelidir;
· Paylaşılan (paylaşılan erişim). OLAP uygulaması, aynı anda birçok kullanıcıya bilgi ile çalışma yeteneğini sağlamalıdır;
· Çok boyutlu (çok boyutlu);
· Bilgi (bilgi). OLAP uygulaması, kullanıcıya elektronik veri ambarının olmadığı gerekli bilgileri alma fırsatı vermelidir.
FASMI'ye dayanarak, aşağıdaki tanım verebilirsiniz: OLAP uygulamaları - Bunlar, sayısal ve istatistiksel analiz yetenekleriyle çok boyutlu analitik bilgilere hızlı çok oyunculu erişim sistemidir.
Olap'ın temel fikri, kullanıcı istekleri için uygun olacak çok boyutlu küpler oluşturmaktır. Çok boyutlu küpler (Şek. 5.3), hem ilişkisel hem de çok boyutlu veritabanlarında depolanabilecek kaynak ve toplanmış veriler temelinde inşa edilmiştir. Bu nedenle, üç veri depolama yöntemi şu anda uygulanır: Molap. (Çok boyutlu OLAP) Rulap. (İlişkisel OLAP) ve Holap (Hibrit olap).
Buna göre, saklama yöntemine göre OLAP ürünleri üçe bölünmüştür:
1. Molap durumunda, ilk ve çok boyutlu veriler çok boyutlu bir veritabanında veya çok boyutlu bir yerel Küba'da depolanır. Bu depolama yöntemi sağlar yüksek hız OLAP işlemlerini gerçekleştirin. Ancak bu durumda çok boyutlu taban çoğu zaman yedek olacaktır. Buna dayanarak küp, ölçüm sayısına bağlı olacaktır. Ölçüm sayısında bir artışla, küpün hacmi katlanarak büyüyecektir. Bazen veri hacminin "patlayıcı büyümesine" neden olabilir.
2. ROLAP ürünlerinde, ilk veriler ilişkisel veritabanlarında veya dosya sunucusundaki düz yerel tablolarda saklanır. Toplam veri aynı veritabanındaki servis tablolarına yerleştirilebilir. Verileri ilişkisel veritabanından çok boyutlu küplere dönüştürme, OLAP'in talebinde oluşur. Bu durumda, bir küp oluşturma hızı, veri kaynağının türüne göre oldukça bağlı olacaktır.
3. Hibrit bir mimari kullanma durumunda, ilk veri ilişkisel bazda kalır ve üniteler çok boyutlu olarak yerleştirilir. OLAP Küpünün yapımı, ilişkisel ve çok boyutlu verilere dayanan OLAP-Aletlerin talebi üzerine yapılır. Bu yaklaşım, veri patlayan büyümesini önler. Aynı zamanda, müşteri isteklerinin optimum yürütme süresini elde etmek mümkündür.
OLAP teknolojilerini kullanarak, kullanıcı esnek bilgi izlemeyi, farklı veri bölümlerini elde edebilir, farklı veri bölümleri elde edebilir, detayların analitik işlemlerini gerçekleştirebilir, dağıtım, zaman karşılaştırmaları, yani. Raporlar ve belgeleri oluşturun ve dinamik olarak yayınlayın.
Depolama veritabanının yapısı genellikle bilgilerin analizini en üst düzeye çıkarmak için geliştirilir. Veriler farklı yönlerde (ölçümler denilen) rahatça "uzanmalıdır). Örneğin, bugün kullanıcı teslimatlarını faaliyetlerini karşılaştırmak için tedarikçilerin teslimat özetini görmek istiyor. Yarın aynı kullanıcı, malzemelerin dinamiklerini izlemek için aylara göre ayrıntıların teslimat hacmindeki değişikliklere ihtiyaç duyacaktır. Veritabanı yapısı, bu tür analiz türlerini sağlamalı, belirtilen ölçüm setine karşılık gelen verileri tahsis etmenizi sağlar.
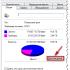
Operasyonel analitik veri işleme temeli, bir hipercubik modelde bilgi organize etme ilkesidir. Daha önce düşünülen test veritabanının ayrıntıları için en basit üç boyutlu küp, Şekil 2'de gösterilmiştir. 3.11. Her hücre "gerçeğe" karşılık gelir - örneğin, parçanın teslim hacmi. Küpün bir yüzü boyunca (bir ölçüm) yansıyan teslimat küpünün yapıldığı aylar vardır. İkinci boyut, ayrıntıların türleridir ve üçüncüsü tedarikçilere karşılık gelir. Her hücre, her üç boyut için karşılık gelen değerlerin kombinasyonu için teslimat miktarını içerir. Küpü doldururken, test veritabanından her ayın temini için değerlerin bir toplanması yapıldığı belirtilmelidir.
3.11. Parça malzemelerinin analizi için basitleştirilmiş bir hipercube varyantı
OLAP sınıfı sistemleri veri temsil yöntemi ile farklılık gösterir.
Çok boyutlu olap (molap) - Bu sistemlerin temeli, dinamik dizilere dayanarak çok boyutludur. Uygun erişim yöntemleriyle veri yapısı. Molap, çok boyutlu DBMS düzenlemek için patentli teknolojiler üzerine uygulanır. Bu yaklaşımın avantajı, hipercube hücrelerinin üzerinde hesaplama yapmanın kolaylığıdır, çünkü Tüm ölçümlerin kombinasyonları altında, ilgili hücreler (hem elektronik tabloda hem de) şarj edilir. Bu tür sistemlerin klasik temsilcileri, Oracle Express, SAS Enstitüsü MDDB'yi içerir.
Olap ilişkisi (ROLAP) - İlişkisel veritabanları üzerinden çok boyutlu analitik modelleri destekler. Bu sistem sınıfı, meta küpü Informix, Microsoft OLAP hizmetleri, Hyperion çözümleri, SAS Enstitüsü ilişkisel OLAP içerir.
Masaüstü OLAP (Masaüstü OLAP)- Yerel bilgi sistemleri (elektronik tablolar, düz dosyalar) için çok boyutlu istek ve raporlar oluşturmak içindir. Aşağıdaki sistemleri seçebilirsiniz - iş nesneleri, Cognos Power Play.
E.f. Kod, verilerin, şeffaflık, kullanılabilirlik, sürdürülebilir performans, istemci-sunucu mimarisinin, ölçüm eşitliği, çok oyunculu mimarların dinamik işlenmesi, çok oyunculu modun, sınırsız desteği destekleyen çok sayıda Çapraz boyutlu işlemler, sezgisel veri manipülasyonu, esnek rapor üretimi mekanizması, sınırsız ölçüm ve toplanma seviyeleri.
 |
ROLAP sınıfının en yaygın sistemleri. Organize etmenize izin verirler bilgi modeli Herhangi bir yapının ilişkisel ve eksiksiz depolanması üzerinde veya özel bir vitrin üzerinde.
İncir. 3.12. "Yıldız" tipinin şeması, parça temini için analitik vitrin
Çoğu veri deposu için, bir N boyutlu küpü modellemenin en etkili yolu bir yıldızdır. İncirde. 3.11 Bilginin dört boyutta (tedarikçi, detay, ay, yıl) konsolide edildiği parçaların arzını analiz etmek için hipercube modeli. "Star" şeması, gerçek tabloya dayanmaktadır. Gerçek tablosu, teslimat miktarının belirtildiği bir sütun, yanı sıra tüm ölçüm tabloları için harici tuşları gösteren sütunlar içerir. Küpün her bir ölçümü, gerçeklerin fabrikasına referans olan bir değer tablosu ile sunulur. Ölçüm referans kitapları hakkında bilgi genelleme düzeylerini organize etmek için, katlian girişler düzenlenir (örneğin, materyal-detay "," şehir tedarikçisi ").
Şekil 2'deki şemanın nedeni. 3.12 "Star" adında oldukça açık. "Yıldızların" uçları, ölçüm tabloları tarafından oluşturulur ve orta form ışınlarında bulunan gerçekler tablosu ile bağlantıları oluşturulur. Bu veritabanı yapısıyla, iş analizi alanından gelen çoğu talep, merkezi gerçeklerin bir veya birkaç ölçüm tablosu ile birleştirilmesi. Örneğin, 2004 yılında aylara göre tüm parçaların teslimatlarının bir hacimlerini, tedarikçiler tarafından bir arıza ile birlikte, şöyle görünür:
SUM SUM (Value), SUCUTY.SUPPLIER_NAME, FACT.MONTH_ID
Gerçekten, Tedarikçiden
Gerçek.year_id \u003d 2004
Ve fact.supplier_code \u003d supplier.supplier_code
Group_by SuppereT_code, ay_id
Sipariş_by suppere_code, ay_id.
İncirde. 3.13 Belirtilen bir istek sonucu oluşan raporun bir parçası gösterilir.
Terim operasyonel Analitik İşleme(Çevrimiçi analitik işlem - OLAP) ilk önce Arbor Software Corp için hazırlanan raporda belirtildi. 1993 yılında, bu terimin tanımı, veri depolama durumunda olduğu gibi, çok daha sonra formüle edilmiştir. Bu terimle belirtilen konsept "," Verileri oluşturma, sürdürme, verileri analiz etme ve rapor yayınlama işlemi "olarak tanımlanabilir. Ek olarak, genellikle dikkate alınan verilerin alınması ve işlenmesi gerektiği gibi algılanması ve işlenmesi gerektiğini eklerler. Çok boyutlu dizi.Ancak, çok boyutlu bir sunumun kendisinin tartışılmasıyla devam etmeden önce, geleneksel SQL tabloları açısından uygun fikirleri göz önünde bulundurun.
İlk özellik, analitik işlemlerde kesinlikle bazı toplama gerektirmesidir. veri,genellikle birkaç ile derhal yürütülür farklı yollar veya başka bir deyişle, birçok farklı gruplama kriterine uygun olarak. Özünde, analitik işlemlerin temel sorunlarından biri, her türlü gruplama yönteminin sayısının olmasıdır.
Çok yakında çok büyük olur. Bununla birlikte, kullanıcıların tümünü ya da hemen hemen tüm yollarını göz önünde bulundurmaları gerekir. Tabii ki, şimdi SQL standardında, bu tür bir toplama desteklenir, ancak herhangi bir özel sQL isteği Sonuç olarak sadece bir tablo olarak gelişir ve bu sonuçta bu tablodaki tüm çizgiler aynı formda ve aynı yorumlamaya sahiptir (en azından böylece)
9 Biz kitaptan veri ambarları tarafından tavsiye veriyoruz: "[Reddet] Normalizasyondan ... işkenceden, yalnızca disk diski tasarrufu için [tıpkı böyle!] - boşuna zamanında Zamanın ... Boyut Tabloları normalize edilmemelidir ... normalize boyut tabloları görüntüleme yeteneğini dışlar. "
10 Keşke bu sonuç tablosu, tanımsız bir değerleri veya boş değerleri içermezse (bkz. Bölüm 19, Bölüm 19.3, Yürüyüşler "hakkında daha fazla bilgi için"). Aslında, bu bölümde tarif edilmesi gereken SQL: 1999'un tasarımı, "kullanımına dayanarak" istenmeyen SQL (?); Eylemde, çeşitli belirtilerinde, belirsiz değerlerin farklı anlamları olabileceğini ve bu nedenle çubukların bir tabloda bir tabloda (aşağıda gösterileceği gibi) birçok farklı tahmini sunmanıza olanak tanıyan gerçeğini vurgularlar.
sQL: 1999 standart görünümünden önce oldu). Uygulamak için pgrubun çeşitli yolları, gerçekleştirmeniz gerekir payrı sorgular ve bireysel tabloların bir sonucu olarak oluşturun. Örneğin, Tedarikçi ve Parçalar Veritabanında gerçekleştirilen aşağıdaki istek sıralarını göz önünde bulundurun.
1. Toplam teslimat miktarını belirleyin.
2. Tedarikçilere toplam tedarikçi sayısını belirleyin.
3. Toplam teslimat miktarını ayrıntılı olarak belirleyin.
4. Tedarikçilere ve detaylara toplam teslimat miktarını belirleyin.
(Kesinlikle, bu sağlayıcı için "toplam" numarası ve bu kısım için bu tedarikçi ve bu bölüm için gerçek bir miktardır. Bir örnek, kurucu veritabanı, detaylar ve projeler kullanılmışsa daha gerçekçi olacaktır. Ancak bu örneği zorlamak için , Hala her zamanki tedarikçilerinin ve detayların temelinde durduk.)
Şimdi, P1 ve P2 numaralarına sahip olan sadece iki ayrıntı olduğunu ve tedarik tablosu olduğunu varsayalım.
Çok boyutlu veritabanları
OLAP verilerinin SQL dili kullanılarak geleneksel bir veritabanında depolandığı (bazen terminoloji ve kavramlar söz konusu olduğumuzu saymamak) varsayılıyordu. Çok boyutlu veritabanları).Aslında, net bir şekilde işaret etmeden, sözde sistemi tanımladık. Rulap.İlişkisel Olapilişkisel Olap).Ancak, birçok sistemin kullanımına inanıyor Molap.(Çok boyutlu Olap.- Çok boyutlu OLAP) - daha fazla umut verici yol. Bu alt bölümde, molap sistemleri oluşturma ilkeleri daha fazla düşünülecektir.
Molap sistemi bakım sağlar Çok boyutlu veritabanlarıverilerin, çok boyutlu dizinin hücrelerinde kavramsal olarak depolandığı.
Not. Yukarıda olmasına rağmen veÖ. kavramsaldepolama, gerçekte, veri fiziksel organizasyonu düzenleme yöntemi Molap.mantıksal organizasyonlarına çok benzer.
DBMS'nin desteklenmesi denir çok boyutlu.Basit bir örnek olarak, sırasıyla, mal, müşterileri ve zaman dilimlerini temsil eden üç boyutlu bir dizi verilebilir. Her bir hücrenin değeri, belirli bir süre içerisinde müşteri tarafından satılan belirtilen ürünün toplam miktarını temsil edebilir. Yukarıda belirtildiği gibi, önceki alt bölümdeki çapraz tablolar da bu tür diziler olarak kabul edilebilir.
Verilerin yapısının yeterince net bir şekilde anlaşılması durumunda, veriler arasındaki tüm bağlantılar bilinmektedir. Dahası, değişkenlerböyle bir bütünlük (geleneksel programlama dilleri anlamında değil), kabaca konuşma, ayrılabilir bağımlıve bağımsız. İÇİNDEÖnceki örnek mallar, müşterive zaman aralığıbağımsız değişkenler olarak kabul edilebilir ve miktar -tek bağımlı değişken. Genel olarak, bağımsız değişkenler, değerleri birlikte bağımlı değişkenlerin değerlerini belirleyen değişkenlerdir (ilişkisel terminolojiyi kullanırsanız, potansiyel anahtar bir settir.
değerleri kalan sütunların değerlerini belirleyen sütunlar). Bu nedenle, bağımsız değişkenler, verilerin düzenlendiği dizinin boyutunu belirler ve ayrıca scheme11 adreslemebu dizi için. Gerçek verileri temsil eden bağımlı değişkenlerin değerleri, dizinin hücrelerinde depolanır.
Not. Bağımsız değerler arasında ayrım veya boyutludeğişkenler
ve bağımlı değerler veya istila etmedeğişkenler bazen arasındaki fark olarak karakterize eder. yerve içerik.
"Dolayısıyla, dizi hücreleri sembolik olarak ele alınır ve genellikle dizilerle çalışmak için kullanılan sayısal endeksleri kullanmamak.
Ne yazık ki, çok boyutlu veritabanlarının yukarıdaki özelliği çok basittir, çünkü veri kümelerinin çoğu başlangıçta kalır. değiltamamen okudu. Bu nedenle, genellikle her şeyden önce, onları daha iyi anlamak için verileri analiz ediyoruz. Genellikle yetersiz bir anlayış, önceden değişkenlerin bağımsız olduğu ve hangi değişkenlerin bağımsız olduğunu belirlemenin imkansız olmasıdır. Daha sonra bağımsız değişkenler, bunların mevcut temsiline göre seçilir (yani bazı hipotezler temelinde), bundan sonra, bağımsız değişkenlerin ne kadar iyi seçildiğini belirlemek için ortaya çıkan dizi kontrol edilir (bkz. Bölüm 22.7). Böyle bir yaklaşım, örneklerin ve hatalar ilkesi üzerine birçok yineleme yapıldığına yol açar. Bu nedenle, sistem genellikle boyutsal ve farklı olmayan değişkenlerin değiştirilmesine izin verir ve bu işlem denir koordinatların Vardiyası Eksenleri(Döndürme). Desteklenen diğer işlemler arasında massiva'nın Transpozisyonuve boyutları yeniden düzenleme.Boyutlar eklemenin bir yolu da olmalıdır.
Bu arada, önceki açıklamadan, dizinin hücrelerinin genellikle boş olduğu açık olmalıdır (ve daha fazla boyutta, bu kadar sıklıkla böyle bir fenomen gözlenir). Başka bir deyişle, diziler genellikle yeniden yazdı.Örneğin, R ürününün tüm süre boyunca müşteriye satılmadığını varsayalım. t.Sonra hücre [C, p, t]boş olacak (veya sıfır içermek için en iyi şekilde). Çok boyutlu DBMSS, daha verimli, sıkıştırılmış gösterimdeki seyrek dizilerin çeşitli depolama yöntemlerini destekler12. Bu, boş hücrelerin karşılık geldiğini eklemelidir. eksik bilgibu nedenle, sistemlerin boş hücreler için bazı bilgi işlem desteği sağlamaları gerekir. Bu tür bir destek gerçekten genellikle mevcuttur, ancak ne yazık ki, SQL'de kabul edilen bir stile benziyor. Bu hücrenin boş olması durumunda, daha sonra bilgi, diğer nedenlerden dolayı tanıtılmamış veya uygulanmamış veya bulunmadığı gerçeğine dikkat edin.
(Bkz. Bölüm 19).
Bağımsız değişkenler genellikle ilişkilidir. hiyerarşibağımlı verilerin toplamının oluşabileceği yolları tanımlama. Örneğin, geçici var
birkaç dakika ile birkaç dakika, birkaç dakika, bir saat, bir gün, bir gün, haftalar, haftalar, yıllar, aylar boyunca, aylardır. Veya başka bir örnek: hiyerarşi mümkündür
kompozisyonlar Parçaları bir parçadan oluşan parçalar, düğümlü parça seti, modüllü düğümler, bir ürünle modüller. Genellikle aynı veriler birçok farklı yolla toplanabilir, yani. Aynı bağımsız değişken birçok farklı hiyerarşiye ait olabilir. Sistem için operatörler sağlar geçmek(Delme) ve peşin geçmek(Delik açın) böyle bir hiyerarşi için. Üsttopaklık seviyesinden üste kadar hareket etmek ve aşağı doğru -
ters yönde geçiş. Hiyerarşilerle çalışmak için, hiyerarşinin seviyelerini yeniden düzenlemek için bir işlem gibi başka işlemler de vardır.
Not.Operasyonlar arasında geçmek(Delme) ve sonuç Birikimi(Rulo
yukarı) Bir ince fark var: Operasyon Çıktıların Birikimi -bu bir operasyon işlemidir
12 İlişkisel sistemlerin aksine dikkat edin. Bu örneğin dizede bu örneğin ilişkisel analogunda IC, P,t) Satırın olduğu gerçeğinden dolayı boş bir "hücre" miktarı olmazdı. (s, r,t) ağırlık sadece eksik olacaktır. Bu nedenle, ilişkisel bir model kullanırken, aksine Çok boyutlu diziler"RareFied Dizileri" veya daha doğrusu "seyrek tabloları" korumaya gerek yok, bu da bu tür tablolarla çalışmak için yetenekli sıkıştırma yöntemlerinin gerekli olmadığı anlamına gelir.
gerekli gruplama ve toplama yöntemleri ve operasyon yöntemleri geçmekbu bir işlemdir girişbu yöntemlerin uygulanmasının sonuçlarına. Ve operasyon örneği peşin geçmekböyle bir istek var: "Son teslimat miktarı biliniyor; her bireysel tedarikçi için nihai verileri elde etmek için." Tabii ki, bu talebe verilen cevap için daha ayrıntılı seviyelerde mevcut (veya hesaplanabilir) verileri bulunmalıdır.
Bir dizi istatistiksel ve diğer matematiksel fonksiyonlar, hipotezleri formüle etmeye ve kontrol etmenize yardımcı olan çok boyutlu veritabanlarının ürünlerinde de sağlanır (yani, önerilen bağlantılara ilişkin hipotezler). Ek olarak, görselleştirme araçları ve rapor oluşturma araçları bu tür görevleri çözmek için sağlanmıştır. Ancak, ne yazık ki, çok boyutlu veritabanları için standart bir sorgu dili yoktur, ancak bu standartların dayanabileceği hesaplamaların geliştirilmesi için araştırmalar devam etmektedir. Ancak, çok boyutlu veritabanlarının tasarımı için bilimsel olarak hizmet edebilecek olan ilişkiselleştirme teorisi gibi hiçbir şey, maalesef, hayır.
Bu bölümü tamamlayan bazı yaklaşımların bazı ürünlerde - Rolap ve Molap'ta birleştirildiğini not ediyoruz. Böyle oLAP Hibrit Sistemiaramak Holap.Bu üç yaklaşımdan hangisinin daha iyi olduğunu bulmak amacıyla geniş görüşmeler yapılır, bu nedenle bu konuda birkaç kelime söylemeye çalışmaya değer. Genel durumda, Molap sistemi daha hızlı hesaplamalar sağlar, ancak Rolap sistemlerine kıyasla daha küçük veri hacimlerini destekler, yani. Veri arttıkça daha az etkili olur. Ve ROLAP sistemleri, molap sistemlerinin benzer özelliklerine kıyasla daha gelişmiş ölçeklenebilirlik, paralellik ve kontrol sağlar. Ek olarak, SQL standardı son zamanlarda takviye edildi ve birçok istatistiksel ve analitik fonksiyon içine dahil edildi (bkz. Bölüm 22.8). Bundan, şu anda Rolap ürünlerinin genişletilmiş işlevsellik sağlayabilmesi için takip eder.
OLAP (çevrimiçi analitik işleme - operasyonel analitik işleme) bilgi SüreciKullanıcıya sisteme, davranış analizini vb. talep etmesini sağlar. Operasyonel mod (çevrimiçi). Sonuçlar saniyeler içinde üretilir.
OLAP sistemleri son kullanıcılar için yürütülürken OLTP Sistemleri IP profesyonel kullanıcıları için yapılmıştır. OLAP, sorgu üretimi, geçersiz raporlar, istatistiksel analiz ve bina multimedya uygulamaları gibi eylemler sunar.
OLAP'yi sağlamak için, veri depolama (veya çok boyutlu depolama) ile birlikte, genellikle çok boyutlu yeteneklerle birlikte bir dizi araçla çalışmak gerekir. Bu fonlar sorgu araç seti, elektronik tablolar, veri madenciliği araçları, veri görselleştirme araçları vb. Olabilir.
OLAP kavramının temeli, çok boyutlu veri sunumunun ilkesidir. E. CODD, her şeyden önce ilişkisel modelin eksikliklerini gözden geçirdi, verileri çok sayıda ölçümlerin bakış açısıyla birleştirmenin, görüntülemenin ve analiz etmenin imkansızlığını belirtir, yani kurumsal analistler için en anlaşılır yöntemdir ve belirlemiştir. İlişkili DBM'lerin işlevselliğini genişleten OLAP sistemleri için genel şartlar, özelliklerinden biri olarak çok boyutlu analiz içerir.
Yazılım ürün sınıfı OLAP'u karşılayan 12 kural. Bu kurallar:
1. Verilerin çok boyutlu kavramsal gösterimi.
2. Şeffaflık.
3. Erişilebilirlik.
4. Sürdürülebilir performans.
5. Müşteri - Sunucu Mimarisi.
6. Ölçüm Eşitliği.
7. Rarefied matrislerin dinamik işlenmesi.
8. Çok oyunculu mod için destek.
9. Çapraz boyutlu işlemler için sınırsız destek.
10. Sezgisel veri manipülasyonu.
11. Esnek Rapor Üretim Mekanizması.
12. Sınırsız ölçüm ve toplanma seviyeleri.
OLAP'nin gerçek tanımı olarak görev yapan bu gerekliliklerin kümesi, tavsiye edici bir ürün olarak kabul edilmeli ve spesifik ürün, tüm gereksinimlere tam olarak tam olarak tam olarak tam olarak tamamlamak için yaklaşım derecesi ile değerlendirilir.
Akıllı veri analizi (veri madenciliği) ve bilgi (bilgi madenciliği). Çok miktarda veri yönetimi ve analizi (büyük veri). İş Analytics Sistemleri (İş Zekası, Bi).
Akıllı Veri Analizi (IAD) - Aktif kullanımla veri analizini belirtmek için ortak bir terim matematiksel Yöntemler ve yöntem kullanımının sonuçlarını kullanarak algoritmalar (optimizasyon yöntemleri, genetik algoritmalar, görüntü tanıma, istatistiksel yöntemler, veri madenciliği vb.) görsel sunum veri.
Genel durumda, jiad süreci üç aşamadan oluşur:
1) Desenleri tanımlama (ücretsiz arama);
2) Bilinmeyen değerlerin (tahmin) tahmin etmek için tanımlanmış kalıpların kullanılması;
3) Bulunan düzenliliklerde anomalileri belirlemek ve yorumlamak için istisnaların analizi.
Bazen, buldukları ve kullanımı arasındaki düzenliliklerin güvenilirliğinin (doğrulama aşaması) güvenilirliğinin doğrulanmasının bir ara aşımını ayırt eder.
Jiad'ın tüm yöntemleri, kaynak verilerle çalışma prensibi üzerine iki gruba ayrılmıştır:
Ödentiklerin analizine dayanarak akıl yürütme yöntemleri - İlk veriler açıkça ayrıntılı bir biçimde depolanabilir ve doğrudan istisnaları tahmin etmek ve / veya analiz etmek için doğrudan kullanılır. Bu yöntem grubunun dezavantajı, büyük miktarda veri üzerinde kullanımlarının karmaşıklığıdır.
Birincil verilerden bilgi gerektiren ve bunları belirli bir yönteme bağlı olan bazı resmi yapılara dönüştüren resmileştirilmiş desenleri tanımlama ve kullanma yöntemleri.
Veri Madenciliği (DM), daha önce bilinmeyen olmayan, pratik olarak faydalı ve uygun fiyatlı insan faaliyet alanlarında karar vermek için gerekli olan bilginin "ham" verilerinde bir algılama teknolojisidir. Veri madenciliğinde kullanılan algoritmalar, daha önce bu yöntemlerin geniş pratik uygulamasına caydırıcı olan çok sayıda hesaplama gerektirir, ancak modern işlemcilerin performansındaki büyüme bu sorunun netliğini aldı.
İş zekası piyasası 5 sektörden oluşur:
1. OLAP ürünleri;
2. Veri madenciliği araçları;
3. Depolama ve veri showcases (veri ambarı) için araçlar;
4. Yönetim bilgi sistemi ve uygulamalar;
5. Sorgu yürütme ve raporlama için kullanıcı araçlarını sonlandırın.
Şu anda, kurumsal bi-platformların liderleri arasında, mikrosektratji, iş nesneleri, Cognos, Hyperion çözümleri, Microsoft, Oracle, SAP, SAS Enstitüsü ve diğerlerini vurgulayabilirsiniz (Ek B'de, bazılarının karşılaştırmalı bir analizi) fonksiyonellik Bi sistemleri).