Cursor in gespeicherten MySQL-Prozeduren. Cursor in MySQL Ändern und Löschen von Zeilen über Cursor
Ein expliziter Cursor ist ein SELECT-Befehl, der explizit im Deklarationsabschnitt eines Programms definiert ist. Wenn Sie einen expliziten Cursor deklarieren, wird ihm ein Name zugewiesen. Für die Befehle INSERT, UPDATE, MERGE und DELETE können keine expliziten Cursor definiert werden.
Durch die Definition des SELECT-Befehls als expliziter Cursor hat der Programmierer die Kontrolle über die wichtigsten Phasen des Abrufens von Informationen aus der Oracle-Datenbank. Es bestimmt, wann der Cursor geöffnet werden soll (OPEN), wann Zeilen daraus ausgewählt werden sollen (FETCH), wie viele Zeilen ausgewählt werden sollen und wann der Cursor mit dem CLOSE-Befehl geschlossen werden soll. Informationen über den aktuellen Status des Cursors sind über seine Attribute verfügbar. Es ist diese hohe Granularität der Steuerung, die explizite Cursor zu einem unschätzbar wertvollen Werkzeug für den Programmierer macht.
Schauen wir uns ein Beispiel an:
1 FUNKTION eifersüchtigy_level (2 NAME_IN IN friends.NAME%TYPE) RETURN NUMBER 3 AS 4 CURSOR eifersüchtigy_cur 5 IS 6 SELECT location FROM friends 7 WHERE NAME = UPPER (NAME_IN); 8 8 eifersüchtigy_rec eifersüchtigy_cur%ROWTYPE; 9 Retval-Nummer; 10 BEGIN 11 OPEN eifersüchtigy_cur; 13 12 FETCH eifersüchtigy_cur INTO eifersüchtigy_rec; 15 13 WENN eifersüchtigy_cur%FOUND 14 DANN 15 WENN eifersüchtigy_rec.location = "PUERTO RICO" 16 DANN retval:= 10; 17 ELSIF eifersüchtigy_rec.location = "CHICAGO" 18 THEN retval:= 1; 19 ENDE WENN; 20 ENDE WENN; 24 21 SCHLIEßEN eifersüchtigy_cur; 26 22 RÜCKKEHR; 23 Exception 24 WENN ANDERE DANN 25 WENN eifersüchtigy_cur%ISOPEN DANN 26 SCHLIEßEN eifersüchtigy_cur; 27 ENDE WENN; 28 ENDE;

In den nächsten Abschnitten wird jeder dieser Vorgänge im Detail besprochen. Der Begriff „Cursor“ bezieht sich darin auf explizite Cursor, sofern im Text nicht ausdrücklich etwas anderes angegeben ist.
Deklarieren eines expliziten Cursors
Um einen expliziten Cursor verwenden zu können, muss er im Deklarationsabschnitt des PL/SQL-Blocks oder -Pakets deklariert werden:
CURSOR Cursorname [ ([ Parameter [, Parameter...]) ] [ RETURN Specification_reEirn ] IS SELECT_command ];
Hier ist der Cursorname der Name des deklarierten Cursors; spiiction_te?it – optionaler RETURN-Abschnitt; KOMaHdaSELECT – jeder gültige SQL SELECT-Befehl. Es können auch Parameter an den Cursor übergeben werden (siehe Abschnitt „Cursorparameter“ weiter unten). Schließlich können Sie nach dem Befehl SELECT...FOR UPDATE eine Liste der zu aktualisierenden Spalten angeben (siehe auch unten). Nach der Deklaration wird der Cursor mit dem OPEN-Befehl geöffnet und mit dem FETCH-Befehl werden Zeilen daraus abgerufen.
Einige Beispiele für explizite Cursor-Deklarationen.
- Cursor ohne Parameter. Der resultierende Satz von Zeilen aus diesem Cursor ist der Satz von Firmen-IDs, die aus allen Zeilen in der Tabelle ausgewählt wurden:
- Cursor mit Parametern. Der resultierende Zeilensatz dieses Cursors enthält eine einzelne Zeile mit dem Firmennamen, der dem Wert des übergebenen Parameters entspricht:
- Cursor mit RETURN-Klausel. Das resultierende Rowset dieses Cursors enthält alle Daten in der Mitarbeitertabelle für die Abteilungs-ID 10:
Cursorname
Ein expliziter Cursorname muss bis zu 30 Zeichen lang sein und denselben Regeln folgen wie andere PL/SQL-Bezeichner. Der Cursorname ist keine Variable – er ist die Kennung des Zeigers auf die Anfrage. Dem Cursornamen wird kein Wert zugewiesen und er kann nicht in Ausdrücken verwendet werden. Der Cursor wird nur in den Befehlen OPEN, CLOSE und FETCH und zur Qualifizierung des Cursorattributs verwendet.
Deklarieren eines Cursors in einem Paket
Explizite Cursor werden im Deklarationsabschnitt eines PL/SQL-Blocks deklariert. Ein Cursor kann auf Paketebene deklariert werden, jedoch nicht innerhalb einer bestimmten Paketprozedur oder -funktion. Ein Beispiel für die Deklaration von zwei Cursorn in einem Paket:
PACKAGE book_info IS CURSOR titles_cur IS SELECT title FROM Books; CURSOR Books_cur (title_filter_in IN Books.title%TYPE) RETURN Books%ROWTYPE IS SELECT * FROM Books WHERE title LIKE title_filter_in; ENDE;
Der erste titles_cur-Cursor gibt nur Buchtitel zurück. Der zweite Befehl, „books_cur“, gibt alle Zeilen der Büchertabelle zurück, in denen die Buchnamen mit dem als Cursorparameter angegebenen Muster übereinstimmen (z. B. „Alle Bücher, die die Zeichenfolge ‚PL/SQL‘ enthalten“). Beachten Sie, dass der zweite Cursor einen RETURN-Abschnitt verwendet, der die vom FETCH-Befehl zurückgegebene Datenstruktur deklariert.
Der RETURN-Abschnitt kann eine der folgenden Datenstrukturen enthalten:
- Ein Datensatz, der mithilfe des %ROWTYPE-Attributs aus einer Datentabellenzeile definiert wird.
- Ein Eintrag, der von einem anderen, zuvor deklarierten Cursor definiert wurde und ebenfalls das %rowtype-Attribut verwendet.
- Ein vom Programmierer definierter Eintrag.
Die Anzahl der Ausdrücke in der Cursor-Auswahlliste muss mit der Anzahl der Spalten im Tabellenname%ROWTYPE, Kypcop%ROWTYPE oder Datensatztyp-Datensatz übereinstimmen. Auch die Datentypen der Elemente müssen kompatibel sein. Wenn beispielsweise das zweite Element der Auswahlliste vom Typ NUMBER ist, kann die zweite Spalte des Eintrags im Abschnitt RETURN nicht vom Typ VARCHAR2 oder BOOLEAN sein.
Bevor wir zu einer detaillierten Untersuchung des RETURN-Abschnitts und seiner Vorteile übergehen, wollen wir zunächst verstehen, warum es notwendig sein könnte, Cursor in einem Paket zu deklarieren. Warum deklarieren Sie nicht einen expliziten Cursor in dem Programm, in dem er verwendet wird – in einer Prozedur, Funktion oder einem anonymen Block?
Die Antwort ist einfach und überzeugend. Durch die Definition eines Cursors in einem Paket können Sie die darin definierte Abfrage wiederverwenden, ohne denselben Code an verschiedenen Stellen in der Anwendung zu wiederholen. Die Implementierung der Abfrage an einem Ort vereinfacht deren Änderung und Codepflege. Eine gewisse Zeitersparnis wird durch die Reduzierung der Anzahl der bearbeiteten Anfragen erzielt.
Es lohnt sich auch, darüber nachzudenken, eine Funktion zu erstellen, die eine Cursorvariable basierend auf REF CURSOR zurückgibt. Das aufrufende Programm ruft Zeilen über eine Cursorvariable ab. Weitere Informationen finden Sie im Abschnitt „Cursorvariablen und REF CURSOR“.
Bei der Deklaration von Cursorn in wiederverwendbaren Paketen ist eine wichtige Sache zu beachten. Alle Datenstrukturen, einschließlich Cursor, die auf „Paketebene“ (nicht innerhalb einer bestimmten Funktion oder Prozedur) deklariert werden, behalten ihre Werte während der gesamten Sitzung. Das bedeutet, dass der Stapelcursor geöffnet bleibt, bis Sie ihn explizit schließen oder bis die Sitzung endet. In lokalen Blöcken deklarierte Cursor werden automatisch geschlossen, wenn diese Blöcke abgeschlossen sind.
Schauen wir uns nun den RETURN-Bereich an. Eine interessante Sache bei der Deklaration eines Cursors in einem Paket ist, dass der Header des Cursors von seinem Körper getrennt werden kann. Dieser Header, der eher an einen Funktionsheader erinnert, enthält Informationen, die der Programmierer zum Arbeiten benötigt: den Namen des Cursors, seine Parameter und den Typ der zurückgegebenen Daten. Der Körper des Cursors ist der SELECT-Befehl. Diese Technik wird in der neuen Version der Cursor-Deklaration „books_cur“ im Paket „book_info“ demonstriert:
PACKAGE book_info IS CURSOR Books_cur (title_filter_in IN Books.title%TYPE) RETURN Books%ROWTYPE; ENDE; PACKAGE BODY book_info IS CURSOR Books_cur (title_filter_in IN Books.title%TYPE) RETURN Books%ROWTYPE IS SELECT * FROM Books WHERE title LIKE title_filter_in; ENDE;
Alle Zeichen vor dem IS-Schlüsselwort bilden eine Spezifikation, und nach IS kommt der Cursorkörper. Das Aufteilen der Cursordeklaration kann zwei Zwecken dienen.
- Informationen verbergen. Der Cursor im Paket ist eine „Black Box“. Dies ist praktisch für Programmierer, da sie den SELECT-Befehl nicht schreiben oder sehen müssen. Es genügt zu wissen, welche Datensätze dieser Cursor zurückgibt, in welcher Reihenfolge und welche Spalten sie enthalten. Ein Programmierer, der mit dem Paket arbeitet, verwendet den Cursor wie jedes andere vorgefertigte Element.
- Minimale Neukompilierung. Durch Ausblenden der Abfragedefinition im Hauptteil des Pakets können Änderungen am SELECT-Befehl vorgenommen werden, ohne den Cursor-Header in der Paketspezifikation zu ändern. Dadurch kann Code verbessert, korrigiert und neu kompiliert werden, ohne die Paketspezifikation neu zu kompilieren, sodass Programme, die von diesem Paket abhängen, nicht als ungültig markiert werden und nicht neu kompiliert werden müssen.
Öffnen eines expliziten Cursors
Die Verwendung eines Cursors beginnt mit der Definition im Deklarationsabschnitt. Als nächstes muss der deklarierte Cursor geöffnet werden. Die Syntax für die OPEN-Anweisung ist sehr einfach:
OPEN Cursorname [ (Argument [, Argument...]) ];
Hier ist Cursorname der Name des zuvor deklarierten Cursors und Argument der an den Cursor übergebene Wert, wenn er mit einer Liste von Parametern deklariert wird.
Oracle unterstützt auch die FOR-Syntax beim Öffnen eines Cursors, die sowohl für Cursorvariablen (siehe Abschnitt „Cursorvariablen und REF CURSOR“) als auch für eingebettetes dynamisches SQL verwendet wird.
Wenn PL/SQL einen Cursor öffnet, führt es die darin enthaltene Abfrage aus. Darüber hinaus identifiziert es den aktiven Datensatz – die Zeilen aller an der Abfrage beteiligten Tabellen, die dem WHERE-Kriterium und der Join-Bedingung entsprechen. Der OPEN-Befehl ruft keine Daten ab – das ist die Aufgabe des FETCH-Befehls.
Unabhängig davon, wann der erste Datenabruf erfolgt, stellt das Datenintegritätsmodell von Oracle sicher, dass alle Abrufvorgänge Daten in dem Zustand zurückgeben, in dem der Cursor geöffnet wurde. Mit anderen Worten: Vom Öffnen bis zum Schließen des Cursors werden beim Abrufen von Daten die während dieser Zeit ausgeführten Einfüge-, Aktualisierungs- und Löschvorgänge vollständig ignoriert.
Wenn der SELECT-Befehl außerdem einen FOR UPDATE-Abschnitt enthält, werden alle durch den Cursor identifizierten Zeilen gesperrt, wenn der Cursor geöffnet wird.
Wenn Sie versuchen, einen bereits geöffneten Cursor zu öffnen, gibt PL/SQL die folgende Fehlermeldung aus:
ORA-06511: PL/SQL: Cursor bereits geöffnet
Daher sollten Sie vor dem Öffnen des Cursors seinen Zustand anhand des Attributwerts überprüfen %ist offen:
WENN NICHT company_cur%ISOPEN, DANN OPEN company_cur; ENDIF;
Die Attribute expliziter Cursor werden weiter unten in dem ihnen gewidmeten Abschnitt beschrieben.
Wenn ein Programm eine FOR-Schleife mit einem Cursor ausführt, muss der Cursor nicht explizit geöffnet (abgerufen, geschlossen) werden. Die PL/SQL-Engine erledigt dies automatisch.
Daten von einem expliziten Cursor abrufen
Der SELECT-Befehl erstellt eine virtuelle Tabelle – eine Reihe von Zeilen, die durch eine WHERE-Klausel definiert werden, mit Spalten, die durch eine Liste von SELECT-Spalten definiert werden. Somit repräsentiert der Cursor diese Tabelle im PL/SQL-Programm. Der Hauptzweck eines Cursors in PL/SQL-Programmen besteht darin, Zeilen zur Verarbeitung auszuwählen. Das Abrufen von Cursorzeilen erfolgt mit dem FETCH-Befehl:
FETCH Cursorname INTO Record_or_Variable_list;
Hier ist Cursorname der Name des Cursors, aus dem der Datensatz ausgewählt wird, und der Datensatz oder die Variablenliste sind die PL/SQL-Datenstrukturen, in die die nächste Zeile des aktiven Recordsets kopiert wird. Daten können in einem PL/SQL-Datensatz (deklariert mit dem %ROWTYPE-Attribut oder der TYPE-Deklaration) oder in Variablen (PL/SQL-Variablen oder Bind-Variablen – z. B. in Oracle Forms-Elementen) platziert werden.
Beispiele für explizite Cursor
Die folgenden Beispiele veranschaulichen verschiedene Möglichkeiten zum Abtasten von Daten.
- Daten von einem Cursor in einen PL/SQL-Datensatz abrufen:
- Daten von einem Cursor in eine Variable abrufen:
- Abrufen von Daten von einem Cursor in eine PL/SQL-Tabellenzeile, eine Variable und eine Oracle Forms-Bindungsvariable:
Von einem Cursor abgerufene Daten sollten immer in einem Datensatz platziert werden, der unter demselben Cursor mit dem Attribut %ROWTYPE deklariert wurde. Vermeiden Sie die Auswahl von Variablenlisten. Durch das Abrufen in einen Datensatz wird der Code kompakter und flexibler, sodass Sie die Abrufliste ändern können, ohne den FETCH-Befehl zu ändern.
Probenahme nach Bearbeitung der letzten Reihe
Sobald Sie den Cursor öffnen, wählen Sie eine nach der anderen Zeilen aus, bis alle erschöpft sind. Sie können danach jedoch immer noch den FETCH-Befehl ausgeben.
Seltsamerweise löst PL/SQL in diesem Fall keine Ausnahme aus. Er macht einfach nichts. Da nichts anderes auszuwählen ist, werden die Werte der Variablen im INTO-Abschnitt des FETCH-Befehls nicht geändert. Mit anderen Worten: Der FETCH-Befehl setzt diese Variablen nicht auf NULL.
Explizite Cursorspaltenaliase
Die SELECT-Anweisung in der Cursordeklaration gibt die Liste der zurückgegebenen Spalten an. Neben Tabellenspaltennamen kann diese Liste Ausdrücke enthalten, die als berechnete oder virtuelle Spalten bezeichnet werden.
Ein Spaltenalias ist ein alternativer Name, der im SELECT-Befehl für eine Spalte oder einen Ausdruck angegeben wird. Durch die Definition geeigneter Aliase in SQL*Plus können Sie die Ergebnisse einer beliebigen Abfrage in für Menschen lesbarer Form anzeigen. In diesen Situationen sind Aliase nicht erforderlich. Andererseits werden bei der Verwendung expliziter Cursor in den folgenden Fällen berechnete Spaltenaliase benötigt:
- beim Abrufen von Daten von einem Cursor in einen Datensatz, der mit dem %ROWTYPE-Attribut basierend auf demselben Cursor deklariert wurde;
- wenn ein Programm einen Verweis auf eine berechnete Spalte enthält.
Betrachten Sie die folgende Abfrage. Der Befehl SELECT wählt die Namen aller Unternehmen aus, die im Jahr 2001 Waren bestellt haben, sowie die Gesamtzahl der Bestellungen (vorausgesetzt, die Standardformatierungsmaske für die aktuelle Datenbankinstanz ist TT-MON-JJJJ):
SELECT Firmenname, Summe (Inv_amt) von Firma c, Rechnung i WHERE c.company_id = i.company_id AND i.invoice_date BETWEEN „01-JAN-2001“ AND „31-DEC-2001“;
Das Ausführen dieses Befehls in SQL*Plus erzeugt die folgende Ausgabe:
| NAME DER FIRMA | SUMME (INV_AMT) |
| ACME TURBO INC. | 1000 |
| WASHINGTON HAIR CO. | 25.20 |
Wie Sie sehen, eignet sich die Spaltenüberschrift SUM (INV_AMT) nicht gut für einen Bericht, ist aber zum einfachen Anzeigen der Daten in Ordnung. Lassen Sie uns nun dieselbe Abfrage in einem PL/SQL-Programm mit einem expliziten Cursor ausführen und einen Spaltenalias hinzufügen:
DECLARE CURSOR comp_cur IS SELECT c.name, SUM (inv_amt) total_sales FROM Firma C, Rechnung I WHERE C.company_id = I.company_id AND I.invoice_date BETWEEN „01-JAN-2001“ AND „31-DEC-2001“; comp_rec comp_cur%ROWTYPE; BEGIN OPEN comp_cur; FETCH comp_cur INTO comp_rec; ENDE;
Ohne den Alias kann ich nicht auf die Spalte in der Datensatzstruktur „comp_rec“ verweisen. Wenn Sie einen Alias haben, können Sie mit einer berechneten Spalte genauso arbeiten wie mit jeder anderen Abfragespalte:
IF comp_rec.total_sales > 5000 THEN DBMS_OUTPUT.PUT_LINE ("Sie haben Ihr Kreditlimit von 5000 $ um" || TO_CHAR (comp_rec.total_sales - 5000, "9999 $") überschritten); ENDIF;
Beim Auswählen einer Zeile in einem Datensatz, der mit dem Attribut %ROWTYPE deklariert wurde, kann auf die berechnete Spalte nur über den Namen zugegriffen werden, da die Struktur des Datensatzes durch die Struktur des Cursors selbst bestimmt wird.
Schließen eines expliziten Cursors
Es gab einmal eine Zeit in der Kindheit, in der uns beigebracht wurde, hinter uns selbst aufzuräumen, und diese Angewohnheit blieb für den Rest unseres Lebens bei uns (wenn auch nicht bei jedem). Es stellt sich heraus, dass diese Regel bei der Programmierung und insbesondere bei der Verwaltung von Cursorn eine äußerst wichtige Rolle spielt. Vergessen Sie nie, den Cursor zu schließen, wenn Sie ihn nicht mehr benötigen!
CLOSE-Befehlssyntax:
CLOSE Cursorname;
Nachfolgend finden Sie einige wichtige Tipps und Überlegungen zum Schließen expliziter Cursor.
- Wenn ein Cursor in einer Prozedur deklariert und geöffnet wird, schließen Sie ihn unbedingt, wenn Sie damit fertig sind. Andernfalls verliert Ihr Code Speicher. Theoretisch sollte ein Cursor (wie jede Datenstruktur) automatisch geschlossen und zerstört werden, wenn er den Gültigkeitsbereich verlässt. Normalerweise schließt PL/SQL beim Beenden einer Prozedur, Funktion oder eines anonymen Blocks tatsächlich alle darin enthaltenen offenen Cursor. Da dieser Prozess jedoch ressourcenintensiv ist, verzögert PL/SQL aus Effizienzgründen manchmal das Identifizieren und Schließen offener Cursor. Cursor vom Typ REF CURSOR können per Definition nicht implizit geschlossen werden. Sie können sich nur sicher sein, dass PL/SQL implizit alle von diesem Block oder verschachtelten Blöcken geöffneten Cursor schließt, wenn der „äußerste“ PL/SQL-Block abgeschlossen ist und die Kontrolle an SQL oder ein anderes aufrufendes Programm zurückgegeben wird. außer REF CURSOR . Der Artikel „Cursor reuse in PL/SQL static SQL“ vom Oracle Technology Network bietet eine detaillierte Analyse, wie und wann PL/SQL Cursor schließt. Verschachtelte anonyme Blöcke sind ein Beispiel für eine Situation, in der PL/SQL Cursor nicht implizit schließt. Einige interessante Informationen zu diesem Thema finden Sie in Jonathan Gennicks Artikel „Does PL/SQL Implicitly Close Cursors?“
- Wenn ein Cursor in einem Paket auf Paketebene deklariert ist und in einem Block oder Programm geöffnet ist, bleibt er geöffnet, bis Sie ihn explizit schließen oder bis die Sitzung endet. Daher sollten Sie nach Abschluss der Arbeit mit einem Batch-Level-Cursor diesen sofort mit dem CLOSE-Befehl schließen (und das Gleiche sollte übrigens auch im Abschnitt „Ausnahmen“ erfolgen):
- Der Cursor kann nur geschlossen werden, wenn er zuvor geöffnet war; Andernfalls wird eine INVALID_CURS0R-Ausnahme ausgelöst. Der Cursorstatus wird mithilfe des %ISOPEN-Attributs überprüft:
- Wenn zu viele offene Cursor im Programm übrig sind, kann die Anzahl der Cursor den Wert des Datenbankparameters OPEN_CURSORS überschreiten. Wenn Sie eine Fehlermeldung erhalten, stellen Sie zunächst sicher, dass die in den Paketen deklarierten Cursor geschlossen werden, wenn sie nicht mehr benötigt werden.
Explizite Cursor-Attribute
Oracle unterstützt vier Attribute (%FOUND, %NOTFOUND, %ISOPEN, %ROWCOUNTM), um Informationen über den Status eines expliziten Cursors zu erhalten. Eine Attributreferenz hat die folgende Syntax: Cursor%Attribut
Hier ist Cursor der Name des deklarierten Cursors.
Die von expliziten Cursorattributen zurückgegebenen Werte werden in der Tabelle angezeigt. 1.
Tabelle 1. Explizite Cursor-Attribute
Die Werte der Cursorattribute vor und nach der Ausführung verschiedener Operationen mit ihnen sind in der Tabelle aufgeführt. 2.
Beachten Sie beim Arbeiten mit expliziten Cursorattributen Folgendes:
- Wenn Sie versuchen, auf das Attribut %FOUND, %NOTFOUND oder %ROWCOUNT zuzugreifen, bevor der Cursor geöffnet oder nachdem er geschlossen wird, löst Oracle eine INVALID CURSOR-Ausnahme (ORA-01001) aus.
- Wenn der FETCH-Befehl zum ersten Mal ausgeführt wird und das resultierende Rowset leer ist, geben die Cursorattribute die folgenden Werte zurück: %FOUND = FALSE , %NOTFOUND = TRUE und %ROWCOUNT = 0 .
- Bei Verwendung von BULK COLLECT gibt das Attribut %ROWCOUNT die Anzahl der Zeilen zurück, die in die angegebenen Sammlungen abgerufen wurden.
|
|
Tabelle 2. Cursor-Attributwerte
| Betrieb | %GEFUNDEN | %NICHT GEFUNDEN | %IST OFFEN | %REIHENANZAHL |
| Vor dem ÖFFNEN | Ausnahme ORA-01001 |
Ausnahme ORA-01001 |
FALSCH | Ausnahme ORA-01001 |
| Nach OFFEN | NULL | NULL | WAHR | 0 |
| Vor dem ersten FETCH-Beispiel | NULL | NULL | WAHR | 0 |
| Nach der ersten Probe BRINGEN |
WAHR | FALSCH | WAHR | 1 |
| Vorher nachfolgend BRINGEN |
WAHR | FALSCH | WAHR | 1 |
| Nach anschließendem FETCH | WAHR | FALSCH | WAHR | Hängt von den Daten ab |
| Vor dem letzten FETCH-Beispiel | WAHR | FALSCH | WAHR | Hängt von den Daten ab |
| Nach dem letzten FETCH-Beispiel | WAHR | FALSCH | WAHR | Hängt von den Daten ab |
| Vor SCHLIESSEN | FALSCH | WAHR | WAHR | Hängt von den Daten ab |
| Nach SCHLIESSEN | Ausnahme | Ausnahme | FALSCH | Ausnahme |
Die Verwendung all dieser Attribute wird im folgenden Beispiel demonstriert:
In früheren Blogs wurden wiederholt Beispiele für die Verwendung von Prozedur- und Funktionsparametern bereitgestellt. Parameter sind ein Mittel zur Weitergabe von Informationen an und von einem Programmmodul. Bei richtiger Anwendung machen sie Module nützlicher und flexibler.
PL/SQL ermöglicht die Übergabe von Parametern an Cursor. Sie erfüllen die gleichen Funktionen wie die Parameter der Softwaremodule sowie mehrere zusätzliche Funktionen.
- Erweiterung der Möglichkeiten zur Cursor-Wiederverwendung. Anstatt die Werte, die die Datenauswahlbedingungen definieren, fest in die WHERE-Klausel zu codieren, können Sie Parameter verwenden, um bei jedem Öffnen des Cursors neue Werte an die WHERE-Klausel zu übergeben.
- Fehlerbehebung bei Cursor-Scope-Problemen. Wenn die Abfrage Parameter anstelle von hartcodierten Werten verwendet, ist der resultierende Satz von Cursorzeilen nicht an ein bestimmtes Programm oder eine bestimmte Blockvariable gebunden. Wenn Ihr Programm über verschachtelte Blöcke verfügt, können Sie auf der obersten Ebene einen Cursor definieren und ihn in verschachtelten Blöcken mit darin deklarierten Variablen verwenden.
Die Anzahl der Cursorparameter ist unbegrenzt. Beim Aufruf von OPEN müssen alle Parameter (außer denen, die Standardwerte haben) für den Cursor angegeben werden.
Wann benötigt ein Cursor Parameter? Die allgemeine Regel ist hier dieselbe wie bei Prozeduren und Funktionen: Wenn erwartet wird, dass der Cursor an verschiedenen Stellen und mit unterschiedlichen Werten im WHERE-Abschnitt verwendet wird, sollte ein Parameter dafür definiert werden. Vergleichen wir Cursor mit und ohne Parameter. Beispiel eines Cursors ohne Parameter:
CURSOR joke_cur IS SELECT Name, Kategorie, letztes_verwendetes_Datum FROM Witze;
Die Ergebnismenge des Cursors umfasst alle Einträge in der Witztabelle. Wenn wir nur eine bestimmte Teilmenge von Zeilen benötigen, ist der WHERE-Abschnitt in der Abfrage enthalten:
CURSOR joke_cur IS SELECT Name, Kategorie, letztes_verwendetes_Datum FROM jokes WHERE Category = "EHEMANN";
Um diese Aufgabe auszuführen, haben wir keine Parameter verwendet und sie werden auch nicht benötigt. In diesem Fall gibt der Cursor alle Zeilen zurück, die zu einer bestimmten Kategorie gehören. Was aber, wenn sich die Kategorie jedes Mal ändert, wenn Sie auf diesen Cursor zugreifen?
Cursor mit Parametern
Natürlich würden wir nicht für jede Kategorie einen eigenen Cursor definieren – das wäre völlig unvereinbar mit der Funktionsweise der datengesteuerten Anwendungsentwicklung. Wir brauchen nur einen Cursor, aber einen, dessen Kategorie wir ändern könnten – und der trotzdem die erforderlichen Informationen zurückgibt. Und die beste (wenn auch nicht die einzige) Lösung für dieses Problem besteht darin, einen parametrisierten Cursor zu definieren:
VERFAHREN EXPLAIN_JOKE (main_category_in IN joke_category.category_id%TYPE) IS /* || Cursor mit einer Parameterliste bestehend aus || aus einem einzelnen String-Parameter. */ CURSOR joke_cur (category_in IN VARCHAR2) IS SELECT Name, Kategorie, letztes_verwendetes_Datum FROM Joke WHERE Category = UPPER (category_in); joke_rec joke_cur%ROWTYPE; BEGIN /* Wenn nun ein Cursor geöffnet wird, wird ihm ein Argument übergeben */ OPEN joke_cur (main_category_in); FETCH joke_cur INTO joke_rec;
Zwischen dem Cursornamen und dem IS-Schlüsselwort befindet sich nun eine Liste von Parametern. Der hartcodierte HUSBAND-Wert in der WHERE-Klausel wurde durch einen Verweis auf den UPPER-Parameter (category_in) ersetzt. Wenn Sie den Cursor öffnen, können Sie den Wert auf HUSBAND, Ehemann oder HuSbAnD setzen – der Cursor funktioniert weiterhin. Der Name der Kategorie, für die der Cursor Scherztabellenzeilen zurückgeben soll, wird in der OPEN-Anweisung (in Klammern) als Literal, Konstante oder Ausdruck angegeben. Wenn der Cursor geöffnet wird, wird der SELECT-Befehl analysiert und der Parameter wird dem Wert zugeordnet. Der resultierende Zeilensatz wird dann bestimmt und der Cursor ist zum Abruf bereit.
Öffnen eines Cursors mit Optionen
Es kann ein neuer Cursor geöffnet werden, der eine beliebige Kategorie anzeigt:
OPEN joke_cur(Jokes_pkg.category); OPEN joke_cur("husband"); OPEN joke_cur("politician"); OPEN joke_cur (Jokes_pkg.relation || "-IN-LAW");
Cursorparameter werden am häufigsten in der WHERE-Klausel verwendet, können aber auch an anderer Stelle in der SELECT-Anweisung referenziert werden:
DECLARE CURSOR joke_cur (category_in IN ARCHAR2) IS SELECT name, Category_in, last_used_date FROM joke WHERE Category = UPPER (category_in);
Anstatt die Kategorie aus der Tabelle zu lesen, ersetzen wir einfach den Parameter „category_in“ in der Auswahlliste. Das Ergebnis bleibt dasselbe, da die WHERE-Klausel die Probenkategorie auf den Parameterwert beschränkt.
Gültigkeitsbereich des Cursorparameters
Der Gültigkeitsbereich eines Cursorparameters ist auf diesen Cursor beschränkt. Auf einen Cursorparameter kann nicht außerhalb des mit dem Cursor verknüpften SELECT-Befehls verwiesen werden. Das folgende PL/SQL-Snippet lässt sich nicht kompilieren, da program_name keine lokale Variable im Block ist. Dies ist ein formaler Cursorparameter, der nur innerhalb des Cursors definiert wird:
DECLARE CURSOR scariness_cur (program_name VARCHAR2) IS SELECT SUM (scary_level) total_scary_level FROM tales_from_the_crypt WHERE prog_name = program_name; BEGIN program_name:= „DIE ATMENDE MUMIE“; /* Ungültiger Link */ OPEN scariness_cur (program_name); .... SCHLIESSEN scariness_cur; ENDE;
Cursor-Parametermodi
Die Syntax für Cursorparameter ist der von Prozeduren und Funktionen sehr ähnlich – mit der Ausnahme, dass Cursorparameter nur IN-Parameter sein können. Cursorparameter können nicht auf die Modi OUT oder IN OUT eingestellt werden. Diese Modi ermöglichen die Übergabe und Rückgabe von Werten von Prozeduren, was für einen Cursor keinen Sinn ergibt. Es gibt nur eine Möglichkeit, Informationen vom Cursor abzurufen: einen Datensatz abzurufen und die Werte aus der Spaltenliste im Abschnitt INTO zu kopieren
Standardparameterwerte
Cursorparametern können Standardwerte zugewiesen werden. Ein Beispiel für einen Cursor mit einem Standardparameterwert:
CURSOR emp_cur (emp_id_in NUMBER:= 0) IS SELECT Employee_id, Emp_Name FROM Employee WHERE Employee_id = emp_id_in;
Da der Parameter emp_id_in einen Standardwert hat, kann er im FETCH-Befehl weggelassen werden. In diesem Fall gibt der Cursor Informationen über den Mitarbeiter mit Code 0 zurück.
Heute werden wir uns viele interessante Dinge ansehen, zum Beispiel, wie man eine bereits erstellte Prozedur startet, die Parameter in großen Mengen akzeptiert, d. h. nicht nur mit statischen Parametern, sondern auch mit Parametern, die sich beispielsweise basierend auf einer Tabelle ändern, wie bei einer regulären Funktion, und genau dabei werden sie uns helfen Cursor und Schleifen, und jetzt schauen wir uns an, wie wir das alles umsetzen können.
Wie Sie wissen, betrachten wir Cursor und Schleifen in ihrer Anwendung auf eine bestimmte Aufgabe. Ich verrate dir jetzt, was die Aufgabe ist.
Es gibt eine Prozedur, die einige Dinge ausführt, die eine normale SQL-Funktion nicht ausführen kann, beispielsweise Berechnungen und auf diesen Berechnungen basierende Einfügungen. Und Sie starten es beispielsweise so:
EXEC test_PROCEDURE par1, par2
Mit anderen Worten: Sie führen es nur mit den angegebenen Parametern aus. Wenn Sie diese Prozedur jedoch beispielsweise 100, 200 oder noch öfter ausführen müssen, werden Sie zustimmen, dass dies nicht sehr praktisch ist, d. h. für eine lange Zeit. Es wäre viel einfacher, wenn wir die Prozedur wie eine reguläre Funktion in einer Auswahlabfrage ausführen würden, etwa so:
SELECT my_fun(id) FROM test_table
Mit anderen Worten: Die Funktion funktioniert für jeden Datensatz der Tabelle test_table, aber wie Sie wissen, kann die Prozedur nicht auf diese Weise verwendet werden. Aber es gibt einen Weg, der uns hilft, unseren Plan zu verwirklichen, oder besser gesagt, sogar zwei Wege: Der erste ist die Verwendung eines Cursors und einer Schleife, und der zweite ist einfach die Verwendung einer Schleife, aber ohne Cursor. Beide Optionen implizieren, dass wir ein zusätzliches Verfahren erstellen, das wir später starten.
Notiz! Wir werden alle Beispiele im MSSql 2008 DBMS mit Management Studio schreiben. Außerdem erfordern alle unten aufgeführten Aktionen die notwendigen Kenntnisse in SQL, genauer gesagt in der Programmierung in Transact-SQL. Ich kann empfehlen, mit der Lektüre des folgenden Materials zu beginnen:
Also fangen wir an und schauen uns vor dem Schreiben der Prozedur die Quelldaten unseres Beispiels an.
Nehmen wir an, es gibt eine Tabelle test_table
TABELLE ERSTELLEN .( (18, 0) NULL, (50) NULL, (50) NULL) ON GOEs ist notwendig, Daten einzufügen, die auf einigen Berechnungen basieren, die das Verfahren durchführen wird my_proc_test, in diesem Fall werden einfach Daten eingefügt, aber in der Praxis können Sie Ihre eigene Prozedur verwenden, die viele Berechnungen durchführen kann, daher ist diese spezielle Prozedur in unserem Fall nicht wichtig, sie ist nur ein Beispiel. Nun, lass es uns erstellen:
VERFAHREN ERSTELLEN. (@number numeric, @pole1 varchar(50), @pole2 varchar(50)) AS BEGIN INSERT INTO dbo.test_table (number, pole1, pole2) VALUES (@number, @pole1, @pole2) END GO
Es nimmt einfach drei Parameter und fügt sie in die Tabelle ein.
Nehmen wir an, wir müssen diese Prozedur so oft ausführen, wie Zeilen in einer Tabelle oder Ansicht (VIEWS) vorhanden sind, mit anderen Worten, wir müssen sie massenhaft für jede Quellzeile ausführen.
Und wenn wir zum Beispiel eine solche Quelle erstellen, erhalten wir eine einfache Tabelle test_table_time, aber für Sie kann es, wie meine Quelle bereits sagte, zum Beispiel eine temporäre Tabelle oder Ansicht sein:
TABELLE ERSTELLEN .( (18, 0) NULL, (50) NULL, (50) NULL) ON GO
Füllen wir es mit Testdaten:
Und jetzt muss unsere Prozedur für jede Zeile ausgeführt werden, d. h. dreimal mit unterschiedlichen Parametern. Wie Sie verstehen, sind die Werte dieser Felder unsere Parameter. Mit anderen Worten: Wenn wir unsere Prozedur manuell ausführen würden, würde sie so aussehen:
exec my_proc_test 1, 'pole1_str1', 'pole2_str1'
Und so weiter dreimal mit den entsprechenden Parametern.
Da wir das aber nicht wollen, schreiben wir eine weitere zusätzliche Prozedur, die unsere Hauptprozedur so oft ausführt, wie wir brauchen.
Erste Wahl.
Verwenden eines Cursors und einer Schleife in einer Prozedur
Kommen wir gleich zur Sache und schreiben die Prozedur ( my_proc_test_all), habe ich den Code wie immer kommentiert:
VERFAHREN ERSTELLEN. AS --Variablen deklarieren DECLARE @number bigint DECLARE @pole1 varchar(50) DECLARE @pole2 varchar(50) --einen Cursor deklarieren DECLARE my_cur CURSOR FOR SELECT number, pole1, pole2 FROM test_table_vrem --den Cursor öffnen OPEN my_cur --read die Daten der ersten Zeilen in unsere Variablen FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2 – wenn sich Daten im Cursor befinden, gehen Sie in eine Schleife – und drehen Sie dort, bis keine Zeilen mehr im Cursor sind Cursor WHILE @@FETCH_STATUS = 0 BEGIN – für jede Iteration der Schleife starten wir unsere Hauptprozedur mit den notwendigen Parametern exec dbo.my_proc_test @number, @pole1, @pole2 – lesen Sie die nächste Zeile des Cursors FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2 END --Cursor schließen CLOSE my_cur DEALLOCATE my_cur GO
Und jetzt müssen wir es nur noch aufrufen und das Ergebnis überprüfen:

Bevor die Prozedur SELECT * FROM test_table ausgeführt wird, rufen Sie die EXEC-Prozedur dbo.my_proc_test_all auf, nachdem die Prozedur SELECT * FROM test_table ausgeführt wird
Wie Sie sehen, funktionierte alles wie es sollte, mit anderen Worten, die Prozedur my_proc_test funktionierte alle drei Male und wir haben die zusätzliche Prozedur nur einmal ausgeführt.
Zweite Option.
Wir verwenden in der Prozedur nur eine Schleife
Ich sage gleich, dass dies eine Zeilennummerierung in der temporären Tabelle erfordert, d.h. Jede Zeile muss nummeriert sein, zum Beispiel 1, 2, 3; in unserer temporären Tabelle ist dieses Feld Nummer.
Eine Prozedur schreiben my_proc_test_all_v2
VERFAHREN ERSTELLEN. AS – Variablen deklarieren DECLARE @number bigint DECLARE @pole1 varchar(50) DECLARE @pole2 varchar(50) DECLARE @cnt int DECLARE @i int – Anzahl der Zeilen in der temporären Tabelle ermitteln SELECT @cnt=count(* ) FROM test_table_vrem - -Setzen Sie den Anfangswert des Bezeichners SET @i=1 WHILE @cnt >= @i BEGIN --weisen Sie unseren Parametern Werte zu SELECT @number=number, @pole1= pole1, @pole2=pole2 FROM test_table_vrem WHERE number = @I – für jede Iteration der Schleife starten wir unsere Hauptprozedur mit den notwendigen Parametern EXEC dbo.my_proc_test @number, @pole1, @pole2 – erhöhen Sie den Schrittsatz @i= @i+1 END GEHEN
Und wir überprüfen das Ergebnis, aber zuerst leeren wir unsere Tabelle, da wir sie gerade mit der Prozedur my_proc_test_all ausgefüllt haben:

Löschen Sie die Tabelle. DELETE test_table – bevor Sie die Prozedur SELECT * FROM test_table ausführen – indem Sie die EXEC-Prozedur dbo.my_proc_test_all_v2 aufrufen – nach der Ausführung der Prozedur SELECT * FROM test_table
Wie erwartet ist das Ergebnis dasselbe, jedoch ohne Verwendung von Cursorn. Es liegt an Ihnen, zu entscheiden, welche Option Sie verwenden. Die erste Option ist gut, da im Prinzip keine Nummerierung erforderlich ist, aber wie Sie wissen, funktionieren Cursor ziemlich lange, wenn sich viele Zeilen im Cursor befinden, und Die zweite Option ist gut, weil sie meiner Meinung nach schneller funktioniert. Wenn viele Zeilen vorhanden sind, aber eine Nummerierung erforderlich ist, gefällt mir persönlich die Option mit einem Cursor, aber im Allgemeinen liegt es an Ihnen, Sie können Wenn Sie sich etwas Bequemeres einfallen lassen, habe ich nur die Grundlagen gezeigt, wie Sie die Aufgabe umsetzen können. Viel Glück!
Ich habe eine Reihe von Kommentaren erhalten. In einem davon bat mich ein Leser, den Cursorn, einem der wichtigen Elemente gespeicherter Prozeduren, mehr Aufmerksamkeit zu schenken.
Da Cursor Teil einer gespeicherten Prozedur sind, werden wir uns in diesem Artikel genauer mit HP befassen. Insbesondere, wie man einen Datensatz von HP extrahiert.
Was ist ein Cursor?
Ein Cursor kann in MySQL nicht alleine verwendet werden. Es ist ein wichtiger Bestandteil gespeicherter Prozeduren. Ich würde einen Cursor mit einem „Zeiger“ in C/C++ oder einem Iterator in einer PHP-foreach-Anweisung vergleichen.
Mithilfe eines Cursors können wir einen Datensatz durchlaufen und jeden Datensatz gemäß bestimmten Aufgaben verarbeiten.
Dieser Datensatzverarbeitungsvorgang kann auch auf der PHP-Ebene durchgeführt werden, wodurch die an die PHP-Ebene übergebene Datenmenge erheblich reduziert wird, da wir einfach die verarbeitete Zusammenfassung/das statistische Ergebnis zurückgeben können (wodurch die Select-foreach-Verarbeitung auf der Clientseite entfällt). .
Da der Cursor in einer gespeicherten Prozedur implementiert ist, verfügt er über alle Vor- und Nachteile von HP (Zugriffskontrolle, Vorkompilierung, Fehlerbehebung bei Schwierigkeiten usw.).
Die offizielle Dokumentation zu Cursorn finden Sie hier. Es beschreibt vier Befehle im Zusammenhang mit der Cursordeklaration, dem Öffnen, Schließen und Abrufen. Wie bereits erwähnt, werden wir auch einige andere gespeicherte Prozeduranweisungen behandeln. Lass uns anfangen.
Praktisches Anwendungsbeispiel
Auf meiner persönlichen Website gibt es eine Seite mit Spielergebnissen für mein Lieblings-NBA-Team: die Lakers.
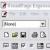
Der Tabellenaufbau dieser Seite ist recht einfach:
Abb. 1. Struktur der Lakers-Spielergebnistabelle
Ich fülle diese Tabelle seit 2008 aus. Nachfolgend finden Sie einige der neuesten Spielergebnisse der Lakers aus der Saison 2013–14:
Reis. 2. Ergebnistabelle der Lakers-Spiele (teilweise) in der Saison 2013–2014
(Ich verwende MySQL Workbench als GUI-Tool zum Verwalten der MySQL-Datenbank. Sie können ein anderes Tool Ihrer Wahl verwenden.)
Nun, ich muss zugeben, dass die Basketballspieler der Lakers in letzter Zeit nicht besonders gut gespielt haben. 6 Niederlagen in Folge, Stand 15. Januar. Ich habe diese definiert „ 6 Niederlagen in Folge„, indem manuell gezählt wird, wie viele Spiele in Folge, beginnend mit dem aktuellen Datum (und bis hin zu früheren Spielen), einen Win-Loss-Wert von „L“ (Niederlage) haben.
Dies ist sicherlich keine unmögliche Aufgabe, aber wenn die Bedingungen komplexer werden und die Datentabelle viel größer ist, dann wird es länger dauern und auch die Fehlerwahrscheinlichkeit steigt.
Können wir dasselbe mit einer einzigen SQL-Anweisung tun? Ich bin kein SQL-Experte und konnte daher nicht herausfinden, wie ich das gewünschte Ergebnis erzielen kann (" 6 Niederlagen in Folge") durch eine einzige SQL-Anweisung. Die Meinungen des Gurus werden für mich sehr wertvoll sein – hinterlassen Sie sie unten in den Kommentaren.
Können wir das über PHP machen? Ja natürlich. Wir können die Spieldaten (insbesondere die Win/Los-Spalte) für diese Saison abrufen und die Aufzeichnungen durchlaufen, um die Länge der aktuellen Sieges-/Niederlagesträhne zu berechnen.
Aber dazu müssten wir alle Daten für dieses Jahr abdecken, und die meisten Daten wären für uns nutzlos (es ist nicht sehr wahrscheinlich, dass ein Team eine Serie von mehr als 20 oder mehr aufeinanderfolgenden Spielen in Folge haben würde). eine reguläre Saison mit 82 Spielen).
Allerdings wissen wir nicht genau, wie viele Datensätze in PHP abgerufen werden müssen, um eine Reihe zu bestimmen. Wir können also nicht darauf verzichten, unnötige Daten unnötig zu extrahieren. Und schließlich: Wenn die aktuelle Anzahl der Siege/Niederlagen in Folge das Einzige ist, was wir aus dieser Tabelle wissen wollen, warum sollten wir dann alle Datenzeilen extrahieren müssen?
Können wir das anders machen? Ja, es ist möglich. Beispielsweise können wir eine Sicherungstabelle erstellen, die speziell darauf ausgelegt ist, den aktuellen Wert der Anzahl der Siege/Niederlagen in Folge zu speichern.
Durch das Hinzufügen jedes neuen Datensatzes wird diese Tabelle automatisch aktualisiert. Das ist aber zu umständlich und fehleranfällig.
Wie können wir das also besser machen?
Verwenden eines Cursors in einer gespeicherten Prozedur
Wie Sie vielleicht anhand des Titels dieses Artikels erraten haben, ist die (meiner Meinung nach) beste Alternative zur Lösung dieses Problems die Verwendung eines Cursors in einer gespeicherten Prozedur.
Lassen Sie uns den ersten HP in MySQL Workbench erstellen:
DELIMITER $$ CREATE DEFINER=`root`@`localhost` PROCEDURE `streak`(in cur_year int, out longeststreak int, out status char(1)) BEGIN deklarieren current_win char(1); deklariere current_streak int; deklarieren Sie current_status char(1); Deklarieren Sie den aktuellen Cursor für die Auswahl von Winlose von Lakers, wobei Jahr = Cur_Jahr und Winlose ist<>"" order by id desc; setze current_streak=0; offener Cur; fetch cur in current_win; set current_streak = current_streak +1; start_loop: Schleife fetch cur in current_status; wenn aktueller_Status<>current_win dann verlassen start_loop; sonst setze current_streak=current_streak+1; Ende, wenn; Endschleife; schließen cur; wähle current_streak in longeststreak aus; wähle current_win in „status“ aus; ENDE
In diesem HP haben wir einen eingehenden Parameter und zwei ausgehende. Dies definiert die HP-Signatur.
Im Hauptteil des HP haben wir außerdem mehrere lokale Variablen für die Ergebnisreihe (Siege oder Niederlagen, current_win), die aktuelle Serie und den aktuellen Sieg-/Niederlagestatus eines bestimmten Spiels deklariert:
Diese Zeile ist die Deklaration des Cursors. Wir haben einen Cursor namens cur und einen mit diesem Cursor verknüpften Datensatz deklariert, der den Gewinn-/Verluststatus für diese Übereinstimmungen darstellt (der Wert der Winlose-Spalte kann entweder „W“ oder „L“ sein, ist aber nicht leer). ein bestimmtes Jahr, die nach ID (die zuletzt gespielten Spiele haben eine höhere ID) in absteigender Reihenfolge sortiert sind.
Obwohl es nicht sichtbar ist, können wir uns vorstellen, dass dieser Datensatz eine Folge der Werte „L“ und „W“ enthält. Basierend auf den in Abbildung 2 gezeigten Daten sollte es wie folgt lauten: „LLLLLLWLL...“ (6 Werte „L“, 1 „W“ usw.)
Um die Anzahl der Siege/Niederlagen in Folge zu berechnen, beginnen wir mit dem letzten (und ersten im angegebenen Datensatz) Spiel. Wenn ein Cursor geöffnet wird, beginnt er immer mit dem ersten Datensatz im entsprechenden Datensatz.
Nachdem die ersten Daten geladen wurden, bewegt sich der Cursor zum nächsten Datensatz. Daher ähnelt das Verhalten des Cursors einer Warteschlange, die mithilfe des FIFO-Systems (First In First Out) einen Datensatz durchläuft. Das ist genau das, was wir brauchen.
Nachdem wir den aktuellen Gewinn-/Verluststatus und die Anzahl aufeinanderfolgender identischer Elemente im Satz erhalten haben, durchlaufen wir weiterhin den Rest des Datensatzes. Bei jeder Iteration der Schleife „springt“ der Cursor zum nächsten Datensatz, bis wir die Schleife unterbrechen oder bis alle Datensätze iteriert sind.
Wenn der Status des nächsten Datensatzes mit dem aktuellen aufeinanderfolgenden Sieges-/Verlustsatz übereinstimmt, bedeutet dies, dass die Serie weitergeht. Dann erhöhen wir die Anzahl der aufeinanderfolgenden Siege (oder Niederlagen) um eine weitere 1 und durchlaufen die Daten weiter.
Wenn der Status unterschiedlich ist, bedeutet das, dass der Streak unterbrochen ist und wir den Zyklus stoppen können. Zum Schluss schließen wir den Cursor und belassen die Originaldaten. Anschließend wird das Ergebnis angezeigt.
Um die Funktionsweise dieses HP zu testen, können wir ein kurzes PHP-Skript schreiben:
exec("call streak(2013, @longeststreak, @status)"); $res=$cn->query("select @longeststreak, @status")->fetchAll(); var_dump($res); //Ausgabe hier ausgeben, um eine Rohansicht der Ausgabe zu erhalten $win=$res["@status"]="L"?"Loss":"Win"; $streak=$res["@longeststreak"]; echo „Lakers ist jetzt $streak in Folge $win.n“;
Das Verarbeitungsergebnis sollte etwa wie in der folgenden Abbildung aussehen:
Ausgeben eines Datensatzes aus einer gespeicherten Prozedur
Im Laufe dieses Artikels ging es mehrmals um die Frage, wie man einen Datensatz von einem HP ableiten kann, der einen Datensatz aus den Ergebnissen der Verarbeitung mehrerer aufeinanderfolgender Aufrufe an einen anderen HP darstellt.
Der Benutzer möchte möglicherweise mehr Informationen mithilfe der zuvor erstellten HP erhalten als nur eine kontinuierliche Reihe von Gewinnen/Verlusten für das Jahr. Beispielsweise können wir eine Tabelle erstellen, die eine Reihe von Gewinnen/Verlusten für verschiedene Jahre anzeigt:
| JAHR | Gewinnen/Verlieren | Strähne |
| 2013 | L | 6 |
| 2012 | L | 4 |
| 2011 | L | 2 |
(Grundsätzlich wäre eine nützlichere Information die Dauer der längsten Sieges- oder Niederlagenserie in einer bestimmten Saison. Um dieses Problem zu lösen, kann man die beschriebene HP leicht erweitern, daher überlasse ich diese Aufgabe den interessierten Lesern. In Im Rahmen des aktuellen Artikels werden wir die aktuelle Siegesserie weiter bearbeiten.
Gespeicherte MySQL-Prozeduren können im Gegensatz zu select ... from ... -Anweisungen nur Skalarwerte (Ganzzahl, Zeichenfolge usw.) zurückgeben (die Ergebnisse werden in einen Datensatz konvertiert). Das Problem besteht darin, dass die Tabelle, in der wir die Ergebnisse abrufen möchten, in der vorhandenen Datenbankstruktur nicht vorhanden ist; sie wird aus den Ergebnissen der Verarbeitung der gespeicherten Prozedur zusammengestellt.
Um dieses Problem zu lösen, benötigen wir eine temporäre Tabelle oder, wenn möglich und notwendig, eine Backup-Tabelle. Sehen wir uns an, wie wir das vorliegende Problem mithilfe einer temporären Tabelle lösen können.
Zuerst erstellen wir ein zweites HP, dessen Code unten gezeigt wird:
DELIMITER $$ CREATE DEFINER=`root`@`%` PROCEDURE `yearly_streak`() begin destroy cur_year, max_year, min_year int; wähle max(year), min(year) von Lakers in max_year, min_year; DROP TEMPORARY TABLE IF EXISTS yearly_streak; TEMPORÄRE TABELLE ERSTELLEN yearly_streak (season int, streak int, win char(1)); set cur_year=max_year; year_loop: Schleife, wenn cur_year Einige wichtige Hinweise zum obigen Code: Um die Ergebnisse zu erhalten, erstellen wir ein weiteres kleines PHP-Skript, dessen Code unten dargestellt ist: query("call yearly_streak")->fetchAll(); foreach ($res as $r) ( echo sprintf("Im Jahr %d sind die längsten W/L Streaks %d %sn", $r["season"], $r["streak"], $r[ "gewinnen"]); ) Die angezeigten Ergebnisse sehen etwa so aus: Eine Abfrage einer relationalen Datenbank gibt normalerweise mehrere Datenzeilen (Datensätze) zurück, die Anwendung verarbeitet jedoch jeweils nur einen Datensatz. Auch wenn es sich um mehrere Zeilen gleichzeitig handelt (z. B. die Anzeige von Daten in Form von Tabellenkalkulationen), ist deren Anzahl dennoch begrenzt. Darüber hinaus ist die Arbeitseinheit beim Ändern, Löschen oder Hinzufügen von Daten die Serie. In dieser Situation tritt das Konzept eines Cursors in den Vordergrund, und in diesem Zusammenhang ist der Cursor ein Zeiger auf eine Zeile. Ein Cursor in SQL ist ein Bereich im Datenbankspeicher, der die letzte SQL-Anweisung enthalten soll. Wenn es sich bei der aktuellen Anweisung um eine Datenbankabfrage handelt, wird auch eine Zeile mit Abfragedaten, die als aktueller Wert oder aktuelle Cursorzeile bezeichnet wird, im Speicher gespeichert. Der angegebene Bereich im Speicher wird benannt und ist für Anwendungsprogramme zugänglich. Typischerweise werden Cursor verwendet, um aus einer Datenbank eine Teilmenge der darin gespeicherten Informationen auszuwählen. Zu jedem Zeitpunkt kann eine Cursorzeile vom Anwendungsprogramm überprüft werden. Cursor werden häufig in SQL-Anweisungen verwendet, die in in prozeduralen Sprachen geschriebenen Anwendungsprogrammen eingebettet sind. Einige davon werden implizit vom Datenbankserver erstellt, während andere von Programmierern definiert werden. Gemäß dem SQL-Standard lassen sich beim Arbeiten mit Cursorn folgende Hauptaktionen unterscheiden: Die Definition eines Cursors kann je nach Implementierung leicht variieren. Beispielsweise muss ein Entwickler manchmal explizit den für einen Cursor zugewiesenen Speicher freigeben. Nach Lassen Sie den Cursor los Der zugehörige Speicher wird ebenfalls freigegeben. Dies ermöglicht die Wiederverwendung seines Namens. In anderen Implementierungen when Schließen des Cursors Das Freigeben von Speicher erfolgt implizit. Unmittelbar nach der Wiederherstellung steht es für andere Vorgänge zur Verfügung: einen weiteren Cursor öffnen usw. In manchen Fällen ist die Verwendung eines Cursors unvermeidlich. Dies sollte jedoch nach Möglichkeit vermieden werden und mit Standard-Datenverarbeitungsbefehlen arbeiten: SELECT, UPDATE, INSERT, DELETE. Abgesehen davon, dass Cursor keine Änderungsvorgänge am gesamten Datenvolumen zulassen, ist die Geschwindigkeit der Datenverarbeitungsvorgänge mit einem Cursor deutlich geringer als bei Standard-SQL-Tools. SQL Server unterstützt drei Arten von Cursorn: Verschiedene Arten von Mehrbenutzeranwendungen erfordern unterschiedliche Arten des parallelen Zugriffs auf Daten. Einige Anwendungen erfordern sofortigen Zugriff auf Informationen über Änderungen an der Datenbank. Dies ist typisch für Ticketreservierungssysteme. In anderen Fällen, beispielsweise bei statistischen Berichtssystemen, ist die Datenstabilität wichtig, da Programme bei ständiger Änderung nicht in der Lage sind, Informationen effektiv anzuzeigen. Unterschiedliche Anwendungen erfordern unterschiedliche Implementierungen von Cursorn. In SQL Server variieren die Cursortypen hinsichtlich der von ihnen bereitgestellten Funktionen. Der Cursortyp wird bei seiner Erstellung festgelegt und kann nicht geändert werden. Einige Cursortypen können Änderungen erkennen, die andere Benutzer an im Ergebnissatz enthaltenen Zeilen vorgenommen haben. Allerdings verfolgt SQL Server Änderungen an solchen Zeilen nur, während auf die Zeile zugegriffen wird, und lässt keine Änderungen zu, wenn die Zeile bereits gelesen wurde. Cursor sind in zwei Kategorien unterteilt: sequentiell und scrollbar. Aufeinanderfolgenden ermöglichen es Ihnen, Daten nur in einer Richtung auszuwählen – vom Anfang bis zum Ende. Scrollbare Cursor bieten größere Handlungsfreiheit – es ist möglich, sich in beide Richtungen zu bewegen und zu einer beliebigen Zeile der Ergebnismenge des Cursors zu springen. Wenn das Programm in der Lage ist, die Daten zu ändern, auf die der Cursor zeigt, werden sie als scrollbar und modifizierbar bezeichnet. Wenn wir von Cursorn sprechen, sollten wir die Transaktionsisolation nicht vergessen. Wenn ein Benutzer einen Datensatz ändert, liest ein anderer ihn mit seinem eigenen Cursor und kann darüber hinaus denselben Datensatz ändern, was die Wahrung der Datenintegrität erforderlich macht. SQL Server unterstützt statische, dynamische, sequentiell und über einen Tastensatz gesteuert. Im Schema mit statischer Cursor Informationen werden einmal aus der Datenbank gelesen und als Snapshot (ab einem bestimmten Zeitpunkt) gespeichert, sodass von einem anderen Benutzer an der Datenbank vorgenommene Änderungen nicht sichtbar sind. Auf Zeit den Cursor öffnen Der Server setzt eine Sperre für alle Zeilen, die in seinem vollständigen Ergebnissatz enthalten sind. Statischer Cursorändert sich nach der Erstellung nicht und zeigt immer den Datensatz an, der zum Zeitpunkt des Öffnens vorhanden war. Wenn andere Benutzer die im Cursor in der Quelltabelle enthaltenen Daten ändern, hat dies keine Auswirkungen auf die statischer Cursor. IN statischer Cursor Es ist nicht möglich, Änderungen vorzunehmen, daher wird es immer im schreibgeschützten Modus geöffnet. Dynamischer Cursor Hält Daten in einem „Live“-Zustand, dies erfordert jedoch Netzwerk- und Softwareressourcen. Benutzen dynamische Cursor Es wird keine vollständige Kopie der Quelldaten erstellt, sondern eine dynamische Auswahl aus den Quelltabellen wird nur dann durchgeführt, wenn der Benutzer auf bestimmte Daten zugreift. Während des Abrufs sperrt der Server die Zeilen und alle Änderungen, die der Benutzer an der vollständigen Ergebnismenge des Cursors vornimmt, werden im Cursor sichtbar. Wenn jedoch ein anderer Benutzer Änderungen vorgenommen hat, nachdem der Cursor die Daten abgerufen hat, werden diese nicht im Cursor widergespiegelt. Cursor gesteuert durch eine Reihe von Tasten, liegt in der Mitte zwischen diesen Extremen. Datensätze werden zum Zeitpunkt der Probenahme identifiziert und so Änderungen nachverfolgt. Dieser Cursortyp ist nützlich, wenn ein Zurückscrollen implementiert wird. Dann sind Hinzufügungen und Löschungen von Zeilen erst sichtbar, wenn die Informationen aktualisiert werden, und der Treiber wählt eine neue Version des Datensatzes aus, wenn daran Änderungen vorgenommen wurden. Sequentielle Cursor dürfen keine Daten in umgekehrter Richtung abrufen. Der Benutzer kann nur Zeilen vom Anfang bis zum Ende des Cursors auswählen. Serieller Cursor speichert nicht einen Satz aller Zeilen. Sie werden aus der Datenbank gelesen, sobald sie im Cursor ausgewählt werden, wodurch alle von Benutzern an der Datenbank vorgenommenen Änderungen mithilfe der Befehle INSERT, UPDATE und DELETE dynamisch widergespiegelt werden. Der Cursor zeigt den aktuellsten Stand der Daten an. Statische Cursor sorgen für eine stabile Sicht auf die Daten. Sie eignen sich gut für Informationslagersysteme: Anwendungen für Berichtssysteme oder für statistische und analytische Zwecke. Außerdem, statischer Cursor kommt mit der Erfassung großer Datenmengen besser zurecht als andere. Im Gegensatz dazu erfordern elektronische Kauf- oder Ticketreservierungssysteme eine dynamische Wahrnehmung aktualisierter Informationen, wenn Änderungen vorgenommen werden. In solchen Fällen wird es verwendet dynamischer Cursor. Bei diesen Anwendungen ist die übertragene Datenmenge typischerweise gering und der Zugriff erfolgt auf Zeilenebene (einzelner Datensatz). Gruppenzugänge sind sehr selten. Cursorsteuerung implementiert durch die Ausführung der folgenden Befehle: Der SQL-Standard stellt den folgenden Befehl zum Erstellen eines Cursors bereit: Durch die Verwendung des Schlüsselworts INSENSITIVE wird erstellt statischer Cursor. Datenänderungen sind nicht erlaubt, außerdem werden von anderen Benutzern vorgenommene Änderungen nicht angezeigt. Wenn das Schlüsselwort INSENSITIVE fehlt, a dynamischer Cursor. Wenn Sie das Schlüsselwort SCROLL angeben, kann der erstellte Cursor in jede Richtung gescrollt werden, sodass Sie beliebige Auswahlbefehle verwenden können. Wenn dieses Argument weggelassen wird, wird der Cursor angezeigt konsistent, d.h. seine Betrachtung wird nur in einer Richtung möglich sein – vom Anfang bis zum Ende. Die SELECT-Anweisung gibt den Hauptteil der SELECT-Anforderung an, der den resultierenden Zeilensatz für den Cursor bestimmt. Die Angabe von FOR READ_ONLY erstellt einen schreibgeschützten Cursor und lässt keine Änderungen an den Daten zu. Es unterscheidet sich von statisch, obwohl letzteres auch keine Änderung von Daten zulässt. Kann als schreibgeschützter Cursor deklariert werden dynamischer Cursor, wodurch die von einem anderen Benutzer vorgenommenen Änderungen angezeigt werden können. Wenn Sie einen Cursor mit einem FOR UPDATE-Argument erstellen, können Sie die Ausführung im Cursor durchführen Datenänderung entweder in den angegebenen Spalten oder, wenn das Argument OF Spaltenname fehlt, in allen Spalten. In der MS SQL Server-Umgebung wird die folgende Syntax für den Befehl zur Cursorerstellung akzeptiert: <создание_курсора>::= DECLARE Cursorname CURSOR FÜR SELECT_Anweisung ]] Durch die Verwendung des Schlüsselworts LOCAL wird ein lokaler Cursor erstellt, der nur im Bereich des Pakets, Triggers, der gespeicherten Prozedur oder der benutzerdefinierten Funktion sichtbar ist, die ihn erstellt hat. Wenn ein Paket, ein Trigger, eine Prozedur oder eine Funktion beendet wird, wird der Cursor implizit zerstört. Um den Inhalt des Cursors außerhalb des Konstrukts zu übergeben, das ihn erstellt hat, müssen Sie seinem Parameter ein OUTPUT-Argument zuweisen. Wenn das Schlüsselwort GLOBAL angegeben ist, wird ein globaler Cursor erstellt; Es existiert, bis die aktuelle Verbindung geschlossen wird. Durch die Angabe von FORWARD_ONLY wird erstellt serieller Cursor; Daten können nur in der Richtung von der ersten bis zur letzten Zeile abgetastet werden. Durch Angabe von SCROLL wird erstellt scrollbarer Cursor; Auf Daten kann in beliebiger Reihenfolge und in jeder Richtung zugegriffen werden. Durch die Angabe von STATIC wird erstellt statischer Cursor. Durch die Angabe von KEYSET wird ein Tastencursor erstellt. Durch die Angabe von DYNAMIC wird erstellt dynamischer Cursor. Wenn Sie das Argument FAST_FORWARD für einen READ_ONLY-Cursor angeben, wird der erstellte Cursor für schnellen Datenzugriff optimiert. Dieses Argument kann nicht in Verbindung mit den Argumenten FORWARD_ONLY oder OPTIMISTIC verwendet werden. Ein mit dem Argument OPTIMISTIC erstellter Cursor verhindert das Ändern oder Löschen von Zeilen, die danach geändert wurden den Cursor öffnen. Durch Angabe des Arguments TYPE_WARNING informiert der Server den Benutzer über eine implizite Änderung des Cursortyps, wenn dieser mit der SELECT-Abfrage nicht kompatibel ist. Für den Cursor öffnen und füllen Sie es mit Daten aus der SELECT-Abfrage, die beim Erstellen des Cursors angegeben wurde, verwenden Sie den folgenden Befehl: Nach den Cursor öffnen Die zugehörige SELECT-Anweisung wird ausgeführt, deren Ausgabe im mehrstufigen Speicher abgelegt wird. Sofort nach den Cursor öffnen Sie können seinen Inhalt (das Ergebnis der Ausführung der entsprechenden Abfrage) mit dem folgenden Befehl auswählen: Durch die Angabe von FIRST wird die allererste Zeile des vollständigen Ergebnissatzes des Cursors zurückgegeben, die zur aktuellen Zeile wird. Wenn Sie LAST angeben, wird die aktuellste Zeile des Cursors zurückgegeben. Es wird auch zur aktuellen Zeile. Durch die Angabe von NEXT wird die Zeile unmittelbar nach der aktuellen im vollständigen Ergebnissatz zurückgegeben. Jetzt wird es aktuell. Standardmäßig verwendet der FETCH-Befehl diese Methode zum Abrufen von Zeilen. Das Schlüsselwort PRIOR gibt die Zeile vor der aktuellen zurück. Es wird aktuell. Streit ABSOLUT (Zeilennummer | @Zeilennummer_Variable) gibt eine Zeile mit ihrer absoluten Ordnungszahl im vollständigen Ergebnissatz des Cursors zurück. Die Angabe der Zeilennummer kann über eine Konstante oder als Name einer Variablen erfolgen, in der die Zeilennummer gespeichert wird. Die Variable muss ein ganzzahliger Datentyp sein. Es werden sowohl positive als auch negative Werte angezeigt. Bei der Angabe eines positiven Werts wird die Zeichenfolge vom Anfang des Satzes an gezählt, während ein negativer Wert vom Ende an gezählt wird. Die ausgewählte Zeile wird zur aktuellen Zeile. Wenn ein Nullwert angegeben wird, wird keine Zeile zurückgegeben. Streit RELATIVE (Anzahl der Zeilen | @variable Anzahl der Zeilen) gibt die Zeile zurück, die der angegebenen Anzahl an Zeilen nach der aktuellen Zeile entspricht. Wenn Sie eine negative Anzahl von Zeilen angeben, wird die Zeile zurückgegeben, die der angegebenen Anzahl von Zeilen vor der aktuellen entspricht. Durch Angabe eines Nullwerts wird die aktuelle Zeile zurückgegeben. Die zurückgegebene Zeile wird zur aktuellen Zeile. Zu globalen Cursor öffnen, müssen Sie das Schlüsselwort GLOBAL vor seinem Namen angeben. Der Cursorname kann auch über eine Variable angegeben werden. Im Design INTO @variable_name [,...n] Es wird eine Liste von Variablen angegeben, in der die entsprechenden Spaltenwerte der zurückgegebenen Zeile gespeichert werden. Die Reihenfolge der Variablenangabe muss mit der Reihenfolge der Spalten im Cursor übereinstimmen und der Datentyp der Variablen muss mit dem Datentyp in der Cursorspalte übereinstimmen. Wenn das INTO-Konstrukt nicht angegeben ist, ähnelt das Verhalten des FETCH-Befehls dem Verhalten des SELECT-Befehls – die Daten werden auf dem Bildschirm angezeigt. Um Änderungen mit einem Cursor vorzunehmen, müssen Sie einen UPDATE-Befehl im folgenden Format ausgeben: Mehrere Spalten der aktuellen Cursorzeile können in einem Vorgang geändert werden, sie müssen jedoch alle zur selben Tabelle gehören. Um Daten mit einem Cursor zu löschen, verwenden Sie den DELETE-Befehl im folgenden Format: Dadurch wird der aktuelle Zeilensatz im Cursor gelöscht. Nach dem Schließen ist der Cursor für Programmbenutzer nicht mehr zugänglich. Beim Schließen werden alle während des Betriebs installierten Schlösser entfernt. Der Abschluss kann nur auf offene Cursor angewendet werden. Geschlossen, aber nicht Cursor freigegeben kann wiedereröffnet werden. Es ist nicht erlaubt, einen ungeöffneten Cursor zu schließen. Schließen des Cursors gibt nicht unbedingt den damit verbundenen Speicher frei. Bei einigen Implementierungen muss die Zuordnung mithilfe der DEALLOCATE-Anweisung explizit aufgehoben werden. Nach Lassen Sie den Cursor los Außerdem wird Speicher freigegeben, sodass der Cursorname wiederverwendet werden kann. Um zu kontrollieren, ob das Ende des Cursors erreicht wurde, empfiehlt sich die Verwendung der Funktion: @@FETCH_STATUS Die Funktion @@FETCH_STATUS gibt Folgendes zurück: 0, wenn der Abruf erfolgreich war; 1, wenn der Abruf aufgrund eines Versuchs, eine Zeile außerhalb des Cursors abzurufen, fehlgeschlagen ist; 2, wenn der Abruf aufgrund eines Zugriffsversuchs auf eine gelöschte oder geänderte Zeile fehlgeschlagen ist. DECLARE @id_kl INT, @firm VARCHAR(50), @fam VARCHAR(50), @message VARCHAR(80), @nam VARCHAR(50), @d DATETIME, @p INT, @s INT SET @s=0 PRINT „Einkaufsliste“ DECLARE klient_cursor CURSOR LOCAL FOR SELECT Kundencode, Firma, Nachname FROM Kunde WHERE City="Moskau" ORDER BY Company, Nachname OPEN klient_cursor FETCH NEXT FROM klient_cursor INTO @id_kl, @firm, @fam WHILE @@FETCH_STATUS =0 BEGIN SELECT @message="Kunde "+@fam+ "Firma "+ @firm PRINT @message SELECT @message="Produktname Kaufdatum Kosten" PRINT @message DECLARE tovar_cursor CURSOR FOR SELECT Product.Name, Transaction.Date, Product .Preis* Transaktion.Menge AS Kosten AUS Produkt INNER JOIN Transaktion ON Produkt. Product Code=Transaction.Product Code WHERE Transaction.Customer Code=@id_kl OPEN tovar_cursor FETCH NEXT FROM tovar_cursor INTO @nam, @d, @p IF @@FETCH_STATUS<>0 PRINT „Keine Käufe“ WHILE @@FETCH_STATUS=0 BEGIN SELECT @message=" "+@nam+" "+ CAST(@d AS CHAR(12))+" "+ CAST(@p AS CHAR(6)) PRINT @message SET @s=@s+@p FETCH NEXT FROM tovar_cursor INTO @nam, @d, @p END CLOSE tovar_cursor DEALLOCATE tovar_cursor SELECT @message="Gesamtkosten "+ CAST(@s AS CHAR(6)) PRINT @message -- zum nächsten Kunden wechseln-- FETCH NEXT FROM klient_cursor INTO @id_kl, @firm, @fam END CLOSE klient_cursor DEALLOCATE klient_cursor Beispiel 13.6. Ein Cursor zur Anzeige einer Liste der von Kunden aus Moskau gekauften Waren und ihrer Gesamtkosten. Beispiel 13.7. Entwickeln Sie einen scrollbaren Cursor für Kunden aus Moskau. Wenn die Telefonnummer mit 1 beginnt, löschen Sie den Kunden mit dieser Nummer und ersetzen Sie im ersten Cursoreintrag die erste Ziffer der Telefonnummer durch 4. DECLARE @firm VARCHAR(50), @fam VARCHAR(50), @tel VARCHAR(8), @message VARCHAR(80) PRINT „Liste der Kunden“ DECLARE klient_cursor CURSOR GLOBAL SCROLL KEYSET FOR SELECT Firma, Nachname, Telefon FROM Client WHERE Stadt ="Moskau" ORDER NACH Firma, Nachname FOR UPDATE OPEN klient_cursor FETCH NEXT FROM klient_cursor INTO @firm, @fam, @tel WHILE @@FETCH_STATUS=0 BEGIN SELECT @message="Client "+@fam+ " Company "+ @firm „Phone“ + @tel PRINT @message – wenn die Telefonnummer mit 1 beginnt, – den Client mit dieser Nummer löschen. IF @tel LIKE „1%“ DELETE Client WHERE CURRENT OF klient_cursor ELSE – zum nächsten wechseln client FETCH NEXT FROM klient_cursor INTO @firm, @fam, @tel END FETCH ABSOLUTE 1 FROM klient_cursor INTO @firm, @fam, @tel – Ersetzen Sie im ersten Eintrag die erste Ziffer der Telefonnummer durch 4 UPDATE Client SET Phone ='4' + RIGHT(@ tel,LEN(@tel)-1)) WHERE CURRENT OF klient_cursor SELECT @message="Client "+@fam+" Firm "+ @firm "Phone "+ @tel PRINT @message CLOSE klient_cursor DEALLOCATE klient_cursor Beispiel 13.7. Scrollbarer Cursor für Kunden aus Moskau. Beispiel 13.8. Verwendung Cursor als Ausgabeparameter der Prozedur. Die Prozedur gibt einen Datensatz zurück – eine Liste von Produkten. Der Aufruf der Prozedur und das Drucken der Daten aus dem Ausgabecursor erfolgt wie folgt: DECLARE @my_cur CURSOR DECLARE @n VARCHAR(20) EXEC my_proc @cur=@my_cur OUTPUT FETCH NEXT FROM @my_cur INTO @n SELECT @n WHILE (@@FETCH_STATUS=0) BEGIN FETCH NEXT FROM @my_cur INTO @n SELECT @n ENDE SCHLIESSEN @my_cur DEALLOCATE @my_cur Mauszeiger in SQL ein Bereich im Datenbankspeicher, der der Speicherung der letzten SQL-Anweisung gewidmet ist. Wenn es sich bei der aktuellen Anweisung um eine Datenbankabfrage handelt, wird auch eine Zeichenfolge mit Abfragedaten namens aktueller Wert oder aktuelle Zeile im Speicher gespeichert. Mauszeiger. Der angegebene Bereich im Speicher wird benannt und ist für Anwendungsprogramme zugänglich. Gemäß dem SQL-Standard beim Arbeiten mit Cursor Die folgenden Hauptmerkmale können identifiziert werden Aktionen: SQL Server unterstützt drei Art der Cursor: Cursorverwaltung in der MS SQL Server-Umgebung Cursorsteuerung implementiert durch die Ausführung der folgenden Befehle: Cursor-Deklaration Im SQL-Standard zum Erstellen Mauszeiger Der folgende Befehl wird bereitgestellt:
<создание_курсора>::= DECLARE Cursorname CURSOR FÜR SELECT_Anweisung ])] Durch die Verwendung des Schlüsselworts INSENSITIVE wird erstellt statischer Cursor. Datenänderungen sind nicht erlaubt, außerdem werden sie nicht angezeigt Änderungen, erstellt von anderen Benutzern. Wenn das Schlüsselwort INSENSITIVE fehlt, a dynamischer Cursor. Wenn Sie das Schlüsselwort SCROLL angeben, wird die erstellte Datei erstellt Mauszeiger kann in jede Richtung gescrollt werden, sodass Sie beliebige Befehle anwenden können Proben. Wenn dieses Argument weggelassen wird, dann Mauszeiger es stellt sich heraus konsistent, d.h. seine Betrachtung wird nur in einer Richtung möglich sein – vom Anfang bis zum Ende. Die SELECT-Anweisung gibt den Hauptteil der SELECT-Abfrage an, der die Ergebnismenge der Zeilen bestimmt Mauszeiger. Durch Angabe des Arguments FOR READ_ONLY wird erstellt Mauszeiger„schreibgeschützt“ und es ist keine Änderung der Daten zulässig. Es ist anders als statisch, obwohl letzteres auch keine Datenänderung zulässt. Kann als schreibgeschützter Cursor deklariert werden dynamischer Cursor, mit dem Sie anzeigen können Änderungen, erstellt von einem anderen Benutzer. Schaffung Mauszeiger mit dem Argument FOR UPDATE ermöglicht die Ausführung in Cursordatenänderung entweder in den angegebenen Spalten oder, wenn das Argument OF Spaltenname fehlt, in allen Spalten. In der MS SQL Server-Umgebung wird die folgende Syntax für den Erstellungsbefehl akzeptiert Mauszeiger:
<создание_курсора>::= DECLARE Cursorname CURSOR FÜR SELECT_Anweisung ]] Durch die Verwendung des Schlüsselworts LOCAL wird ein Local erstellt Mauszeiger, die nur im Bereich des Pakets, Triggers, der gespeicherten Prozedur oder der benutzerdefinierten Funktion sichtbar ist, die sie erstellt hat. Wenn ein Paket, ein Trigger, eine Prozedur oder eine Funktion abgeschlossen wird Mauszeiger wird implizit zerstört. Inhalte übertragen Mauszeiger Außerhalb des Konstrukts, das es erstellt hat, müssen Sie seinem Parameter ein OUTPUT-Argument zuweisen. Wenn das Schlüsselwort GLOBAL angegeben ist, handelt es sich um ein globales Schlüsselwort Mauszeiger; Es existiert, bis die aktuelle Verbindung geschlossen wird. Durch die Angabe von FORWARD_ONLY wird erstellt serieller Cursor ; Probe Daten können nur in der Richtung von der ersten zur letzten Zeile verarbeitet werden. Durch Angabe von SCROLL wird erstellt scrollbarer Cursor; Auf Daten kann in beliebiger Reihenfolge und in jeder Richtung zugegriffen werden. Durch die Angabe von STATIC wird erstellt statischer Cursor. Durch die Angabe von KEYSET wird ein Schlüsselcursor erstellt. Durch die Angabe von DYNAMIC wird erstellt dynamischer Cursor. Wenn wegen Mauszeiger READ_ONLY geben Sie das dann erstellte FAST_FORWARD-Argument an Mauszeiger wird für einen schnellen Datenzugriff optimiert. Dieses Argument kann nicht in Verbindung mit den Argumenten FORWARD_ONLY oder OPTIMISTIC verwendet werden. IN Mauszeiger, erstellt mit dem Argument OPTIMISTIC, ist verboten ändern Und Zeilen löschen die danach geändert wurden den Cursor öffnen. Bei Angabe des Arguments TYPE_WARNING informiert der Server den Benutzer über die implizite Typänderung Mauszeiger wenn es mit der SELECT-Abfrage nicht kompatibel ist. Öffnen des Cursors Für den Cursor öffnen und Füllen Sie es mit Daten aus dem bei der Erstellung angegebenen Mauszeiger Die SELECT-Abfrage verwendet den folgenden Befehl: OPEN ((cursor_name) |@cursor_variable_name) Nach den Cursor öffnen Die zugehörige SELECT-Anweisung wird ausgeführt, deren Ausgabe im mehrstufigen Speicher abgelegt wird. Abrufen von Daten von einem Cursor Sofort nach den Cursor öffnen Sie können seinen Inhalt (das Ergebnis der Ausführung der entsprechenden Abfrage) mit dem folgenden Befehl auswählen: FETCH [ FROM ]((cursor_name)| @cursor_variable_name) ] Durch die Angabe von FIRST wird die allererste Zeile des vollständigen Ergebnissatzes zurückgegeben Mauszeiger, die zur aktuellen Zeile wird. Wenn Sie LAST angeben, wird die aktuellste Zeile zurückgegeben Mauszeiger. Es wird auch zur aktuellen Zeile. Durch die Angabe von NEXT wird die Zeile unmittelbar nach der aktuellen im vollständigen Ergebnissatz zurückgegeben. Jetzt wird es aktuell. Standardmäßig verwendet der FETCH-Befehl diese Methode. Proben Linien. Das Schlüsselwort PRIOR gibt die Zeile vor der aktuellen zurück. Es wird aktuell. ABSOLUTE (row_number | @row_number_variable) gibt die Zeile mit ihrer absoluten Indexnummer im vollständigen Ergebnissatz zurück Mauszeiger. Die Angabe der Zeilennummer kann über eine Konstante oder als Name einer Variablen erfolgen, in der die Zeilennummer gespeichert wird. Die Variable muss ein ganzzahliger Datentyp sein. Es werden sowohl positive als auch negative Werte angezeigt. Bei der Angabe eines positiven Werts wird die Zeichenfolge vom Anfang des Satzes an gezählt, während ein negativer Wert vom Ende an gezählt wird. Die ausgewählte Zeile wird zur aktuellen Zeile. Wenn ein Nullwert angegeben wird, wird keine Zeile zurückgegeben. Das RELATIVE-Argument (Anzahl der Zeilen | @variable Anzahl der Zeilen) gibt die Zeile zurück, die um die angegebene Anzahl an Zeilen nach der aktuellen Zeile liegt. Wenn Sie eine negative Anzahl von Zeilen angeben, wird die Zeile zurückgegeben, die der angegebenen Anzahl von Zeilen vor der aktuellen entspricht. Durch Angabe eines Nullwerts wird die aktuelle Zeile zurückgegeben. Die zurückgegebene Zeile wird zur aktuellen Zeile. Zu globalen Cursor öffnen, müssen Sie das Schlüsselwort GLOBAL vor seinem Namen angeben. Name Mauszeiger kann auch über eine Variable angegeben werden. Die INTO @variable_name [,...n]-Konstruktion gibt eine Liste von Variablen an, in denen die entsprechenden Spaltenwerte der zurückgegebenen Zeichenfolge gespeichert werden. Die Reihenfolge der Variablen muss mit der Reihenfolge der Spalten in übereinstimmen Mauszeiger, und der Datentyp der Variablen ist der Datentyp in der Spalte Mauszeiger. Wenn das INTO-Konstrukt nicht angegeben ist, ähnelt das Verhalten des FETCH-Befehls dem Verhalten des SELECT-Befehls – die Daten werden auf dem Bildschirm angezeigt.Cursor-Konzept
Implementierung von Cursorn in der MS SQL Server-Umgebung
Cursorverwaltung in der MS SQL Server-Umgebung
Cursor-Deklaration
Öffnen des Cursors
Abrufen von Daten von einem Cursor
Daten ändern und löschen
Schließen des Cursors
Lassen Sie den Cursor los