Cursors in MySQL stored procedures. Cursors in Mysql Modifying and deleting rows through cursors
An explicit cursor is a SELECT command explicitly defined in the declaration section of a program. When you declare an explicit cursor, it is given a name. Explicit cursors cannot be defined for INSERT, UPDATE, MERGE, and DELETE commands.
By defining the SELECT command as an explicit cursor, the programmer has control over the major stages of retrieving information from the Oracle database. It determines when to open the cursor (OPEN), when to select rows from it (FETCH), how many rows to select, and when to close the cursor using the CLOSE command. Information about the current state of the cursor is available through its attributes. It is this high granularity of control that makes explicit cursors an invaluable tool for the programmer.
Let's look at an example:
1 FUNCTION jealousy_level (2 NAME_IN IN friends.NAME%TYPE) RETURN NUMBER 3 AS 4 CURSOR jealousy_cur 5 IS 6 SELECT location FROM friends 7 WHERE NAME = UPPER (NAME_IN); 8 8 jealousy_rec jealousy_cur%ROWTYPE; 9 retval NUMBER; 10 BEGIN 11 OPEN jealousy_cur; 13 12 FETCH jealousy_cur INTO jealousy_rec; 15 13 IF jealousy_cur%FOUND 14 THEN 15 IF jealousy_rec.location = "PUERTO RICO" 16 THEN retval:= 10; 17 ELSIF jealousy_rec.location = "CHICAGO" 18 THEN retval:= 1; 19 END IF; 20 END IF; 24 21 CLOSE jealousy_cur; 26 22 RETURN retval; 23 EXCEPTION 24 WHEN OTHERS THEN 25 IF jealousy_cur%ISOPEN THEN 26 CLOSE jealousy_cur; 27 END IF; 28 END;

The next few sections discuss each of these operations in detail. The term "cursor" in them refers to explicit cursors, unless the text explicitly states otherwise.
Declaring an Explicit Cursor
To be able to use an explicit cursor, it must be declared in the declaration section of the PL/SQL block or package:
CURSOR cursor_name [ ([ parameter [, parameter...]) ] [ RETURN specification_reEirn ] IS SELECT_command ];
Here the cursor name is the name of the declared cursor; spiifiction_te?it - optional RETURN section; KOMaHdaSELECT - any valid SQL SELECT command. Parameters can also be passed to the cursor (see the “Cursor Parameters” section below). Finally, after the SELECT...FOR UPDATE command, you can specify a list of columns to update (also see below). After the declaration, the cursor is opened with the OPEN command, and rows are retrieved from it with the FETCH command.
Some examples of explicit cursor declarations.
- Cursor without parameters. The resulting set of rows from this cursor is the set of company IDs selected from all the rows in the table:
- Cursor with parameters. The resulting rowset of this cursor contains a single row with the company name corresponding to the value of the passed parameter:
- Cursor with RETURN clause. The resulting rowset of this cursor contains all the data in the employee table for department ID 10:
Cursor name
An explicit cursor name must be up to 30 characters long and follow the same rules as other PL/SQL identifiers. The cursor name is not a variable - it is the identifier of the pointer to the request. The cursor name is not assigned a value and cannot be used in expressions. The cursor is used only in the OPEN, CLOSE and FETCH commands, and to qualify the cursor attribute.
Declaring a cursor in a package
Explicit cursors are declared in the declaration section of a PL/SQL block. A cursor can be declared at the package level, but not within a specific package procedure or function. An example of declaring two cursors in a package:
PACKAGE book_info IS CURSOR titles_cur IS SELECT title FROM books; CURSOR books_cur (title_filter_in IN books.title%TYPE) RETURN books%ROWTYPE IS SELECT * FROM books WHERE title LIKE title_filter_in; END;
The first titles_cur cursor returns only book titles. The second, books_cur , returns all rows of the books table in which the book names match the pattern specified as the cursor parameter (for example, "All books containing the string 'PL/SQL'"). Note that the second cursor uses a RETURN section, which declares the data structure returned by the FETCH command.
The RETURN section can contain any of the following data structures:
- A record defined from a data table row using the %ROWTYPE attribute.
- An entry defined from another, previously declared cursor, also using the %rowtype attribute.
- A programmer-defined entry.
The number of expressions in the cursor selection list must match the number of columns in the table_name%ROWTYPE, Kypcop%ROWTYPE, or record type record. The data types of the elements must also be compatible. For example, if the second element of the select list is of type NUMBER, then the second column of the entry in the RETURN section cannot be of type VARCHAR2 or BOOLEAN.
Before moving on to a detailed examination of the RETURN section and its advantages, let's first understand why it might be necessary to declare cursors in a package? Why not declare an explicit cursor in the program in which it is used - in a procedure, function or anonymous block?
The answer is simple and convincing. By defining a cursor in a package, you can reuse the query defined in it without repeating the same code in different places in the application. Implementing the query in one place simplifies its modification and code maintenance. Some time savings are achieved by reducing the number of requests processed.
It's also worth considering creating a function that returns a cursor variable based on REF CURSOR . The calling program fetches rows through a cursor variable. For more information, see the "Cursor Variables and REF CURSOR" section.
When declaring cursors in reusable packages, there is one important thing to consider. All data structures, including cursors, declared at the “package level” (not inside a specific function or procedure), retain their values throughout the session. This means that the batch cursor will remain open until you explicitly close it, or until the session ends. Cursors declared in local blocks are automatically closed when those blocks complete.
Now let's look at the RETURN section. One interesting thing about declaring a cursor in a package is that the header of the cursor can be separated from its body. This header, more reminiscent of a function header, contains information that the programmer needs to work: the name of the cursor, its parameters and the type of data returned. The body of the cursor is the SELECT command. This technique is demonstrated in the new version of the books_cur cursor declaration in the book_info package:
PACKAGE book_info IS CURSOR books_cur (title_filter_in IN books.title%TYPE) RETURN books%ROWTYPE; END; PACKAGE BODY book_info IS CURSOR books_cur (title_filter_in IN books.title%TYPE) RETURN books%ROWTYPE IS SELECT * FROM books WHERE title LIKE title_filter_in; END;
All characters before the IS keyword form a specification, and after IS comes the cursor body. Splitting the cursor declaration can serve two purposes.
- Hiding information. The cursor in the package is a “black box”. This is convenient for programmers because they don't have to write or even see the SELECT command. It is enough to know what records this cursor returns, in what order and what columns they contain. A programmer working with the package uses the cursor like any other ready-made element.
- Minimum recompilation. By hiding the query definition in the body of the package, changes to the SELECT command can be made without changing the cursor header in the package specification. This allows code to be improved, corrected, and recompiled without recompiling the package specification, so that programs that depend on that package will not be marked as invalid and will not need to be recompiled.
Opening an Explicit Cursor
Using a cursor starts with defining it in the declarations section. Next, the declared cursor must be opened. The syntax for the OPEN statement is very simple:
OPEN cursor_name [ (argument [, argument...]) ];
Here, cursorname is the name of the previously declared cursor, and argument is the value passed to the cursor if it is declared with a list of parameters.
Oracle also supports FOR syntax when opening a cursor, which is used for both cursor variables (see "Cursor Variables and REF CURSOR" section) and embedded dynamic SQL.
When PL/SQL opens a cursor, it executes the query it contains. In addition, it identifies the active data set - the rows of all tables participating in the query that match the WHERE criterion and the join condition. The OPEN command does not retrieve data - that is the job of the FETCH command.
Regardless of when the first data fetch occurs, Oracle's data integrity model ensures that all fetch operations return data in the state at which the cursor was opened. In other words, from opening to closing the cursor, when retrieving data from it, the insert, update, and delete operations performed during this time are completely ignored.
Moreover, if the SELECT command contains a FOR UPDATE section, all rows identified by the cursor are locked when the cursor is opened.
If you try to open a cursor that is already open, PL/SQL will throw the following error message:
ORA-06511: PL/SQL: cursor already open
Therefore, before opening the cursor, you should check its state using the attribute value %isopen:
IF NOT company_cur%ISOPEN THEN OPEN company_cur; ENDIF;
The attributes of explicit cursors are described below in the section dedicated to them.
If a program executes a FOR loop using a cursor, the cursor does not need to be opened (fetched, closed) explicitly. The PL/SQL engine does this automatically.
Fetching data from an explicit cursor
The SELECT command creates a virtual table - a set of rows defined by a WHERE clause with columns defined by a list of SELECT columns. Thus, the cursor represents this table in the PL/SQL program. The primary purpose of a cursor in PL/SQL programs is to select rows for processing. Fetching cursor rows is done with the FETCH command:
FETCH cursor_name INTO record_or_variable_list;
Here, cursor name is the name of the cursor from which the record is selected, and the record or variable list is the PL/SQL data structures into which the next row of the active recordset is copied. Data can be placed in a PL/SQL record (declared with the %ROWTYPE attribute or TYPE declaration) or in variables (PL/SQL variables or bind variables - such as in Oracle Forms elements).
Examples of explicit cursors
The following examples demonstrate different ways to sample data.
- Fetching data from a cursor into a PL/SQL record:
- Fetching data from a cursor into a variable:
- Fetching data from a cursor into a PL/SQL table row, variable, and Oracle Forms bind variable:
Data fetched from a cursor should always be placed in a record declared under the same cursor with the %ROWTYPE attribute; Avoid selecting lists of variables. Fetching into a record makes the code more compact and flexible, allowing you to change the fetch list without changing the FETCH command.
Sampling after processing the last row
Once you open the cursor, you select lines from it one by one until they are all exhausted. However, you can still issue the FETCH command after this.
Oddly enough, PL/SQL does not throw an exception in this case. He just doesn't do anything. Since there is nothing else to select, the values of the variables in the INTO section of the FETCH command are not changed. In other words, the FETCH command does not set these variables to NULL.
Explicit cursor column aliases
The SELECT statement in the cursor declaration specifies the list of columns it returns. Along with table column names, this list can contain expressions called calculated or virtual columns.
A column alias is an alternative name specified in the SELECT command for a column or expression. By defining appropriate aliases in SQL*Plus, you can display the results of an arbitrary query in human-readable form. In these situations, aliases are not necessary. On the other hand, when using explicit cursors, calculated column aliases are needed in the following cases:
- when retrieving data from a cursor into a record declared with the %ROWTYPE attribute based on the same cursor;
- when a program contains a reference to a calculated column.
Consider the following query. The SELECT command selects the names of all companies that ordered goods during 2001, as well as the total amount of orders (assuming the default formatting mask for the current database instance is DD-MON-YYYY):
SELECT company_name, SUM (inv_amt) FROM company c, invoice i WHERE c.company_id = i.company_id AND i.invoice_date BETWEEN "01-JAN-2001" AND "31-DEC-2001";
Running this command in SQL*Plus will produce the following output:
| COMPANY_NAME | SUM (INV_AMT) |
| ACME TURBO INC. | 1000 |
| WASHINGTON HAIR CO. | 25.20 |
As you can see, the column header SUM (INV_AMT) is not well suited for a report, but it is fine for simply viewing data. Now let's run the same query in a PL/SQL program using an explicit cursor and add a column alias:
DECLARE CURSOR comp_cur IS SELECT c.name, SUM (inv_amt) total_sales FROM company C, invoice I WHERE C.company_id = I.company_id AND I.invoice_date BETWEEN "01-JAN-2001" AND "31-DEC-2001"; comp_rec comp_cur%ROWTYPE; BEGIN OPEN comp_cur; FETCH comp_cur INTO comp_rec; END;
Without the alias, I won't be able to reference the column in the comp_rec record structure. If you have an alias, you can work with a calculated column just like you would with any other query column:
IF comp_rec.total_sales > 5000 THEN DBMS_OUTPUT.PUT_LINE (" You have exceeded your credit limit of $5000 by " || TO_CHAR (comp_rec.total_sales - 5000, "$9999")); ENDIF;
When selecting a row into a record declared with the %ROWTYPE attribute, the calculated column can only be accessed by name - because the structure of the record is determined by the structure of the cursor itself.
Closing an explicit cursor
Once upon a time in childhood we were taught to clean up after ourselves, and this habit remained with us (although not everyone) for the rest of our lives. It turns out that this rule plays an extremely important role in programming, and especially when it comes to managing cursors. Never forget to close your cursor when you no longer need it!
CLOSE command syntax:
CLOSE cursor_name;
Below are some important tips and considerations related to closing explicit cursors.
- If a cursor is declared and opened in a procedure, be sure to close it when you are done with it; otherwise your code will leak memory. In theory, a cursor (like any data structure) should be automatically closed and destroyed when it goes out of scope. Typically, when exiting a procedure, function, or anonymous block, PL/SQL actually closes all open cursors within it. But this process is resource-intensive, so for efficiency reasons, PL/SQL sometimes delays identifying and closing open cursors. Cursors of type REF CURSOR, by definition, cannot be closed implicitly. The only thing you can be sure of is that when the "outermost" PL/SQL block completes and control is returned to SQL or another calling program, PL/SQL will implicitly close all cursors opened by that block or nested blocks. except REF CURSOR . The article "Cursor reuse in PL/SQL static SQL" from the Oracle Technology Network provides a detailed analysis of how and when PL/SQL closes cursors. Nested anonymous blocks are an example of a situation in which PL/SQL does not implicitly close cursors. For some interesting information on this topic, see Jonathan Gennick's article “Does PL/SQL Implicitly Close Cursors?”
- If a cursor is declared in a package at the package level and is open in some block or program, it will remain open until you explicitly close it or until the session ends. Therefore, after finishing working with a batch level cursor, you should immediately close it with the CLOSE command (and by the way, the same should be done in the exceptions section):
- The cursor can only be closed if it was previously open; otherwise, an INVALID_CURS0R exception will be thrown. The cursor state is checked using the %ISOPEN attribute:
- If there are too many open cursors left in the program, the number of cursors may exceed the value of the OPEN_CURSORS database parameter. If you receive an error message, first make sure that the cursors declared in the packages are closed when they are no longer needed.
Explicit Cursor Attributes
Oracle supports four attributes (%FOUND, %NOTFOUND, %ISOPEN, %ROWCOUNTM) to obtain information about the state of an explicit cursor. An attribute reference has the following syntax: cursor%attribute
Here cursor is the name of the declared cursor.
The values returned by explicit cursor attributes are shown in Table. 1.
Table 1. Explicit Cursor Attributes
The values of cursor attributes before and after performing various operations with them are shown in Table. 2.
When working with explicit cursor attributes, consider the following:
- If you attempt to access the %FOUND, %NOTFOUND, or %ROWCOUNT attribute before the cursor is opened or after it is closed, Oracle throws an INVALID CURSOR exception (ORA-01001).
- If the first time the FETCH command is executed, the resulting rowset is empty, the cursor attributes return the following values: %FOUND = FALSE , %NOTFOUND = TRUE , and %ROWCOUNT = 0 .
- When using BULK COLLECT, the %ROWCOUNT attribute returns the number of rows retrieved into the given collections.
|
|
Table 2. Cursor Attribute Values
| Operation | %FOUND | %NOTFOUND | %ISOPEN | %ROWCOUNT |
| Before OPEN | Exception ORA-01001 |
Exception ORA-01001 |
FALSE | Exception ORA-01001 |
| After OPEN | NULL | NULL | TRUE | 0 |
| Before the first FETCH sample | NULL | NULL | TRUE | 0 |
| After the first sample FETCH |
TRUE | FALSE | TRUE | 1 |
| Before subsequent FETCH |
TRUE | FALSE | TRUE | 1 |
| After subsequent FETCH | TRUE | FALSE | TRUE | Depends on data |
| Before the last FETCH sample | TRUE | FALSE | TRUE | Depends on data |
| After the last FETCH sample | TRUE | FALSE | TRUE | Depends on data |
| Before CLOSE | FALSE | TRUE | TRUE | Depends on data |
| After CLOSE | Exception | Exception | FALSE | Exception |
The use of all these attributes is demonstrated in the following example:
Previous blogs have repeatedly provided examples of using procedure and function parameters. Parameters are a means of passing information to and from a program module. When used correctly, they make modules more useful and flexible.
PL/SQL allows you to pass parameters to cursors. They perform the same functions as the parameters of the software modules, as well as several additional ones.
- Expanding cursor reuse capabilities. Instead of hard-coding the values that define the data selection conditions into the WHERE clause, you can use parameters to pass new values into the WHERE clause each time the cursor is opened.
- Troubleshooting Cursor Scope Issues. If the query uses parameters instead of hard-coded values, the resulting set of cursor rows is not tied to a specific program or block variable. If your program has nested blocks, you can define a cursor at the top level and use it in nested blocks with variables declared in them.
The number of cursor parameters is unlimited. When OPEN is called, all parameters (except those that have default values) must be specified for the cursor.
When does a cursor require parameters? The general rule here is the same as for procedures and functions: if the cursor is expected to be used in different places and with different values in the WHERE section, a parameter should be defined for it. Let's compare cursors with and without the parameter. Example of a cursor without parameters:
CURSOR joke_cur IS SELECT name, category, last_used_date FROM Jokes;
The cursor's result set includes all entries in the joke table. If we only need a certain subset of rows, the WHERE section is included in the query:
CURSOR joke_cur IS SELECT name, category, last_used_date FROM jokes WHERE category = "HUSBAND";
To perform this task, we did not use parameters, and they are not needed. In this case, the cursor returns all rows that belong to a specific category. But what if the category changes every time you access this cursor?
Cursors with parameters
Of course, we wouldn't define a separate cursor for each category—that would be completely inconsistent with how data-driven application development works. We only need one cursor, but one for which we could change the category - and it would still return the required information. And the best (although not the only) solution to this problem is to define a parameterized cursor:
PROCEDURE explain_joke (main_category_in IN joke_category.category_id%TYPE) IS /* || Cursor with a list of parameters consisting of || from a single string parameter. */ CURSOR joke_cur (category_in IN VARCHAR2) IS SELECT name, category, last_used_date FROM Joke WHERE category = UPPER (category_in); joke_rec joke_cur%ROWTYPE; BEGIN /* Now, when opening a cursor, an argument is passed to it */ OPEN joke_cur (main_category_in); FETCH joke_cur INTO joke_rec;
Between the cursor name and the IS keyword there is now a list of parameters. The hard-coded HUSBAND value in the WHERE clause has been replaced by a reference to the UPPER parameter (category_in). When you open the cursor, you can set the value to HUSBAND , husband or HuSbAnD - the cursor will still work. The name of the category for which the cursor should return joke table rows is specified in the OPEN statement (in parentheses) as a literal, constant, or expression. When the cursor is opened, the SELECT command is parsed and the parameter is associated with the value. The resulting set of rows is then determined and the cursor is ready for fetching.
Opening a cursor with options
A new cursor can be opened indicating any category:
OPEN joke_cur(Jokes_pkg.category); OPEN joke_cur("husband"); OPEN joke_cur("politician"); OPEN joke_cur (Jokes_pkg.relation || "-IN-LAW");
Cursor parameters are most often used in the WHERE clause, but they can be referenced elsewhere in the SELECT statement:
DECLARE CURSOR joke_cur (category_in IN ARCHAR2) IS SELECT name, category_in, last_used_date FROM joke WHERE category = UPPER (category_in);
Instead of reading the category from the table, we simply substitute the category_in parameter into the select list. The result remains the same because the WHERE clause restricts the sample category to the parameter value.
Cursor parameter scope
The scope of a cursor parameter is limited to that cursor. A cursor parameter cannot be referenced outside of the SELECT command associated with the cursor. The following PL/SQL snippet does not compile because program_name is not a local variable in the block. This is a formal cursor parameter that is defined only inside the cursor:
DECLARE CURSOR scariness_cur (program_name VARCHAR2) IS SELECT SUM (scary_level) total_scary_level FROM tales_from_the_crypt WHERE prog_name = program_name; BEGIN program_name:= "THE BREATHING MUMMY"; /* Invalid link */ OPEN scariness_cur (program_name); .... CLOSE scariness_cur; END;
Cursor Parameter Modes
The syntax for cursor parameters is very similar to that of procedures and functions - except that cursor parameters can only be IN parameters. Cursor parameters cannot be set to OUT or IN OUT modes. These modes allow values to be passed and returned from procedures, which makes no sense for a cursor. There is only one way to get information from the cursor: fetching a record and copying the values from the list of columns in the INTO section
Default Parameter Values
Cursor parameters can be assigned default values. An example of a cursor with a default parameter value:
CURSOR emp_cur (emp_id_in NUMBER:= 0) IS SELECT employee_id, emp_name FROM employee WHERE employee_id = emp_id_in;
Because the emp_id_in parameter has a default value, it can be omitted in the FETCH command. In this case, the cursor will return information about the employee with code 0.
Today we will look at a lot of interesting things, for example, how to launch an already created procedure that accepts parameters in bulk, i.e. not only with static parameters, but with parameters that will change, for example, based on some table, like a regular function, and this is exactly what they will help us with cursors and loops, and now we’ll look at how to implement all this.
As you understand, we will consider cursors and loops as they apply to a specific task. I’ll tell you what the task is now.
There is a procedure that does some things that a normal SQL function cannot do, such as calculations and insert based on those calculations. And you launch it, for example like this:
EXEC test_PROCEDURE par1, par2
In other words, you run it only with the parameters that were specified, but if you need to run this procedure, say, 100, 200 or even more times, then you will agree that this is not very convenient, i.e. for a long time. It would be much easier if we ran the procedure like a regular function in a select query, like this:
SELECT my_fun(id) FROM test_table
In other words, the function will work for each record of the test_table table, but as you know, the procedure cannot be used this way. But there is a way that will help us achieve our plan, or rather, even two ways: the first is using a cursor and a loop, and the second is simply using a loop, but without a cursor. Both options imply that we will create an additional procedure, which we will launch later.
Note! We will write all examples in the MSSql 2008 DBMS using Management Studio. Also, all of the actions listed below require the necessary knowledge in SQL, or more precisely in programming in Transact-SQL. I can recommend starting with reading the following material:
And so let's get started, and before writing the procedure, let's look at the source data of our example.
Let's say there is a table test_table
CREATE TABLE .( (18, 0) NULL, (50) NULL, (50) NULL) ON GOIt is necessary to insert data into it, based on some calculations that the procedure will perform my_proc_test, in this case it simply inserts data, but in practice you can use your own procedure, which can perform many calculations, so in our case this particular procedure is not important, it is just an example. Well, let's create it:
CREATE PROCEDURE. (@number numeric, @pole1 varchar(50), @pole2 varchar(50)) AS BEGIN INSERT INTO dbo.test_table (number, pole1, pole2) VALUES (@number, @pole1, @pole2) END GO
It simply takes three parameters and inserts them into the table.
And let’s say this procedure, we need to run it as many times as there are rows in some table or view (VIEWS), in other words, run it en masse for each source row.
And for example, let's create such a source, we will have a simple table test_table_time, but for you it may be, as I already said my source, for example a temporary table or view:
CREATE TABLE .( (18, 0) NULL, (50) NULL, (50) NULL) ON GO
Let's fill it with test data:
And now our procedure needs to be run for each row, i.e. three times with different parameters. As you understand, the values of these fields are our parameters, in other words, if we ran our procedure manually, it would look like this:
exec my_proc_test 1, 'pole1_str1', 'pole2_str1'
And so on three more times, with the appropriate parameters.
But we don’t want to do that, so we’ll write another additional procedure, which will run our main procedure as many times as we need.
First option.
Using a cursor and a loop in a procedure
Let's get straight to the point and write the procedure ( my_proc_test_all), I commented the code as always:
CREATE PROCEDURE. AS --declare variables DECLARE @number bigint DECLARE @pole1 varchar(50) DECLARE @pole2 varchar(50) --declare a cursor DECLARE my_cur CURSOR FOR SELECT number, pole1, pole2 FROM test_table_vrem --open the cursor OPEN my_cur --read the data of the first lines into our variables FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2 --if there is data in the cursor, then go into a loop --and spin there until there are no more lines in the cursor WHILE @@FETCH_STATUS = 0 BEGIN --for each iteration of the loop, we launch our main procedure with the necessary parameters exec dbo.my_proc_test @number, @pole1, @pole2 --read the next line of the cursor FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2 END --close the cursor CLOSE my_cur DEALLOCATE my_cur GO
And now all we have to do is call it and check the result:

Before the SELECT * FROM test_table procedure is executed --call the EXEC procedure dbo.my_proc_test_all --after the SELECT * FROM test_table procedure is executed
As you can see, everything worked as it should, in other words, the my_proc_test procedure worked all three times, and we only ran the additional procedure once.
Second option.
We use only a loop in the procedure
I’ll say right away that this requires row numbering in the temporary table, i.e. Each line must be numbered, for example 1, 2, 3; in our temporary table this field is number.
Writing a procedure my_proc_test_all_v2
CREATE PROCEDURE. AS --declare variables DECLARE @number bigint DECLARE @pole1 varchar(50) DECLARE @pole2 varchar(50) DECLARE @cnt int DECLARE @i int --find out the number of rows in the temporary table SELECT @cnt=count(*) FROM test_table_vrem - -set the initial value of the identifier SET @i=1 WHILE @cnt >= @i BEGIN --assign values to our parameters SELECT @number=number, @pole1= pole1, @pole2=pole2 FROM test_table_vrem WHERE number = @I --for each iteration of the loop, we launch our main procedure with the necessary parameters EXEC dbo.my_proc_test @number, @pole1, @pole2 --increase the step set @i= @i+1 END GO
And we check the result, but first we’ll clear our table, since we’ve just filled it out using the my_proc_test_all procedure:

Clear the table DELETE test_table --before executing the SELECT * FROM test_table procedure --calling the EXEC procedure dbo.my_proc_test_all_v2 --after executing the SELECT * FROM test_table procedure
As expected, the result is the same, but without using cursors. It’s up to you to decide which option to use, the first option is good because, in principle, numbering is not needed, but as you know, cursors work for quite a long time if there are a lot of lines in the cursor, and the second option is good because it seems to me that it will work faster, again, if there are a lot of lines, but numbering is needed, I personally like the option with a cursor, but in general it’s up to you, you can come up with something more convenient, I just showed the basics of how you can implement the task. Good luck!
I received a number of comments. In one of them, a reader asked me to pay more attention to cursors, one of the important elements of stored procedures.
Since cursors are part of a stored procedure, in this article we will look at HP in more detail. In particular, how to extract a data set from HP.
What is a cursor?
A cursor cannot be used by itself in MySQL. It is an important component of stored procedures. I would compare a cursor to a "pointer" in C/C++ or an iterator in a PHP foreach statement.
Using a cursor, we can iterate through a data set and process each record according to specific tasks.
This record processing operation can also be done at the PHP layer, which significantly reduces the amount of data passed to the PHP layer since we can simply return the processed summary/statistical result back (thus eliminating the select - foreach processing on the client side) .
Since the cursor is implemented in a stored procedure, it has all the advantages (and disadvantages) inherent in HP (access control, pre-compilation, difficulty debugging, etc.)
You can find the official documentation on cursors here. It describes four commands related to cursor declaration, opening, closing, and retrieving. As mentioned, we will also cover some other stored procedure statements. Let's get started.
Practical application example
My personal website has a page with game results for my favorite NBA team: the Lakers.
The table structure of this page is quite simple:
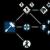
Fig 1. Structure of the Lakers game results table
I have been filling out this table since 2008. Some of the latest Lakers game results from the 2013-14 season are below:
Rice. 2. Table of results of Lakers games (partial) in the 2013-2014 season
(I am using MySQL Workbench as a GUI tool to manage MySQL database. You can use another tool of your choice).
Well, I have to admit that the Lakers basketball players haven't been playing very well lately. 6 defeats in a row as of January 15th. I defined these " 6 defeats in a row", by manually counting how many matches in a row, starting from the current date (and down to earlier games) have a winlose value of "L" (loss).
This is certainly not an impossible task, but if the conditions become more complex and the data table is much larger, then it will take longer and the likelihood of error will also increase.
Can we do the same with a single SQL statement? I'm not a SQL expert, so I couldn't figure out how to achieve the desired result (" 6 defeats in a row") through a single SQL statement. The guru's opinions will be very valuable to me - leave them in the comments below.
Can we do this via PHP? Yes, sure. We can get the game data (specifically, the winlos column) for that season and iterate through the records to calculate the length of the current win/loss streak.
But to do that, we'd have to cover all of the data for that year, and most of the data would be useless to us (it's not very likely that any team would have a streak longer than 20+ games in a row in an 82-game regular season ).
However, we don't know for sure how many records must be retrieved in PHP to determine a series. So we cannot do without needlessly extracting unnecessary data. And finally, if the current number of wins/losses in a row is the only thing we want to know from this table, why would we need to extract all the rows of data?
Can we do this another way? Yes it is possible. For example, we can create a backup table specifically designed to store the current value of the number of wins/losses in a row.
Adding each new record will automatically update this table. But this is too cumbersome and error-prone.
So how can we do this better?
Using a cursor in a stored procedure
As you might have guessed from the title of this article, the best alternative (in my opinion) to solve this problem is to use a cursor in a stored procedure.
Let's create the first HP in MySQL Workbench:
DELIMITER $$ CREATE DEFINER=`root`@`localhost` PROCEDURE `streak`(in cur_year int, out longeststreak int, out status char(1)) BEGIN declare current_win char(1); declare current_streak int; declare current_status char(1); declare cur cursor for select winlose from lakers where year=cur_year and winlose<>"" order by id desc; set current_streak=0; open cur; fetch cur into current_win; set current_streak = current_streak +1; start_loop: loop fetch cur into current_status; if current_status<>current_win then leave start_loop; else set current_streak=current_streak+1; end if; end loop; close cur; select current_streak into longeststreak; select current_win into `status`; END
In this HP we have one incoming parameter and two outgoing ones. This defines the HP signature.
In the body of the HP we also declared several local variables for the series of results (wins or losses, current_win), the current series and the current win/loss status of a particular match:
This line is the declaration of the cursor. We have declared a cursor named cur and a set of data associated with this cursor, which is the win/lose status for those matches (the value of the winlose column can be either "W" or "L", but not empty) in a particular year that are ordered by id (last played games will have a higher ID) in descending order.
Although it is not visible, we can imagine that this data set will contain a sequence of values "L" and "W". Based on the data shown in Figure 2, it should be as follows: “LLLLLLWLL...” (6 values “L", 1 “W”, etc.)
To calculate the number of wins/losses in a row, we start with the last (and first in the given data set) match. When a cursor is opened, it always starts with the first record in the corresponding data set.
After the first data is loaded, the cursor moves to the next record. Thus, the behavior of the cursor is similar to a queue that iterates through a set of data using the FIFO (First In First Out) system. This is exactly what we need.
After receiving the current win/loss status and the number of consecutive identical elements in the set, we continue to loop through the rest of the data set. In each iteration of the loop, the cursor will “jump” to the next record until we break the loop or until all records are iterated.
If the status of the next record is the same as the current consecutive set of wins/losses, it means the streak continues, then we increase the number of consecutive wins (or losses) by another 1 and continue to loop through the data.
If the status is different, it means the streak is broken and we can stop the cycle. Finally, we close the cursor and leave the original data. After this, the result is displayed.
To test the operation of this HP, we can write a short PHP script:
exec("call streak(2013, @longeststreak, @status)"); $res=$cn->query("select @longeststreak, @status")->fetchAll(); var_dump($res); //Dump the output here to get a raw view of the output $win=$res["@status"]="L"?"Loss":"Win"; $streak=$res["@longeststreak"]; echo "Lakers is now $streak consecutive $win.n";
The processing result should look something like the following figure:
Outputting a data set from a stored procedure
Several times during the course of this article, the conversation concerned how to derive a set of data from a HP, which constitutes a set of data from the results of processing several successive calls to another HP.
The user may want to obtain more information using the HP we previously created than just a continuous series of wins/losses for the year; for example, we can create a table that will display series of wins/losses for different years:
| YEAR | Win/Lose | Streak |
| 2013 | L | 6 |
| 2012 | L | 4 |
| 2011 | L | 2 |
(In principle, more useful information would be the duration of the longest winning or losing streak in a particular season. To solve this problem, you can easily expand the described HP, so I will leave this task to those readers who are interested. In the framework of the current article, we will continue processing the current win/loss streak).
MySQL stored procedures can only return scalar values (integer, string, etc.), unlike select ... from ... statements (the results are converted to a data set). The problem is that the table in which we want to get the results does not exist in the existing database structure; it is compiled from the results of processing the stored procedure.
To solve this problem, we need a temporary table or, if possible and necessary, a backup table. Let's see how we can solve the problem at hand using a temporary table.
First we will create a second HP, the code for which is shown below:
DELIMITER $$ CREATE DEFINER=`root`@`%` PROCEDURE `yearly_streak`() begin declare cur_year, max_year, min_year int; select max(year), min(year) from lakers into max_year, min_year; DROP TEMPORARY TABLE IF EXISTS yearly_streak; CREATE TEMPORARY TABLE yearly_streak (season int, streak int, win char(1)); set cur_year=max_year; year_loop: loop if cur_year A few significant notes on the above code: To get the results, we create another small PHP script, the code of which is shown below: query("call yearly_streak")->fetchAll(); foreach ($res as $r) ( echo sprintf("In year %d, the longest W/L streaks is %d %sn", $r["season"], $r["streak"], $r[ "win"]); ) The displayed results will look something like this: A query against a relational database typically returns multiple rows (records) of data, but the application only processes one record at a time. Even if it deals with several rows at the same time (for example, displaying data in the form of spreadsheets), their number is still limited. In addition, when modifying, deleting, or adding data, the work unit is the series. In this situation, the concept of a cursor comes to the fore, and in this context, the cursor is a pointer to a row. A cursor in SQL is an area in database memory that is designed to hold the last SQL statement. If the current statement is a database query, a row of query data called the current value, or current cursor line, is also stored in memory. The specified area in memory is named and accessible to application programs. Typically, cursors are used to select from a database a subset of the information stored in it. At any given time, one cursor line can be checked by the application program. Cursors are often used in SQL statements embedded in application programs written in procedural languages. Some of them are implicitly created by the database server, while others are defined by programmers. In accordance with the SQL standard, when working with cursors, the following main actions can be distinguished: The definition of a cursor may vary slightly across implementations. For example, sometimes a developer must explicitly free the memory allocated for a cursor. After release the cursor its associated memory is also freed. This makes it possible to reuse his name. In other implementations when closing the cursor freeing memory occurs implicitly. Immediately after recovery, it becomes available for other operations: opening another cursor etc. In some cases, using a cursor is unavoidable. However, if possible, this should be avoided and work with standard data processing commands: SELECT, UPDATE, INSERT, DELETE. In addition to the fact that cursors do not allow modification operations on the entire volume of data, the speed of performing data processing operations using a cursor is noticeably lower than that of standard SQL tools. SQL Server supports three types of cursors: Different types of multi-user applications require different types of parallel access to data. Some applications require immediate access to information about changes to the database. This is typical for ticket reservation systems. In other cases, such as statistical reporting systems, data stability is important because if it is constantly being modified, programs will not be able to display information effectively. Different applications need different implementations of cursors. In SQL Server, cursor types vary in the capabilities they provide. The cursor type is determined at the stage of its creation and cannot be changed. Some types of cursors can detect changes made by other users to rows included in the result set. However, SQL Server only tracks changes to such rows while the row is being accessed and does not allow changes to be modified once the row has already been read. Cursors are divided into two categories: sequential and scrollable. Consecutive allow you to select data in only one direction - from beginning to end. Scrollable cursors provide greater freedom of action - it is possible to move in both directions and jump to an arbitrary row of the cursor's result set. If the program is able to modify the data that the cursor points to, it is called scrollable and modifiable. Speaking of cursors, we should not forget about transaction isolation. When one user modifies a record, another reads it using their own cursor, and moreover, he can modify the same record, which makes it necessary to maintain data integrity. SQL Server supports static, dynamic, sequential and controlled by a set of keys. In the scheme with static cursor information is read from the database once and stored as a snapshot (as of some point in time), so changes made to the database by another user are not visible. For a while opening the cursor the server sets a lock on all rows included in its full result set. Static cursor does not change after creation and always displays the data set that existed at the time of its opening. If other users change the data included in the cursor in the source table, this will not affect the static cursor. IN static cursor It is not possible to make changes, so it always opens in read-only mode. Dynamic cursor maintains data in a “live” state, but this requires network and software resources. Using dynamic cursors a complete copy of the source data is not created, but a dynamic selection is performed from the source tables only when the user accesses certain data. During the fetch, the server locks the rows, and any changes the user makes to the full result set of the cursor will be visible in the cursor. However, if another user has made changes after the cursor has fetched the data, they will not be reflected in the cursor. Cursor controlled by a set of keys, is in the middle between these extremes. Records are identified at the time of sampling, and thus changes are tracked. This type of cursor is useful when implementing scrolling back - then additions and deletions of rows are not visible until the information is updated, and the driver selects a new version of the record if changes have been made to it. Sequential cursors are not allowed to fetch data in the reverse direction. The user can only select rows from the beginning to the end of the cursor. Serial cursor does not store a set of all rows. They are read from the database as soon as they are selected in the cursor, which allows all changes made by users to the database to be dynamically reflected using INSERT, UPDATE, DELETE commands. The cursor shows the most recent state of the data. Static cursors provide a stable view of the data. They are good for information "warehousing" systems: applications for reporting systems or for statistical and analytical purposes. Besides, static cursor copes better than others with sampling large amounts of data. In contrast, electronic purchasing or ticket reservation systems require dynamic perception of updated information as changes are made. In such cases it is used dynamic cursor. In these applications, the amount of data transferred is typically small and accessed at the row (individual record) level. Group access is very rare. Cursor control implemented by executing the following commands: The SQL standard provides the following command to create a cursor: Using the INSENSITIVE keyword will create static cursor. Data changes are not allowed, in addition, changes made by other users are not displayed. If the INSENSITIVE keyword is missing, a dynamic cursor. When you specify the SCROLL keyword, the created cursor can be scrolled in any direction, allowing you to use any selection commands. If this argument is omitted, the cursor will be consistent, i.e. its viewing will be possible only in one direction - from beginning to end. The SELECT statement specifies the body of the SELECT request, which determines the resulting set of rows for the cursor. Specifying FOR READ_ONLY creates a read-only cursor and does not allow any modifications to the data. It differs from static, although the latter also does not allow data to be changed. Can be declared as a read-only cursor dynamic cursor, which will allow changes made by another user to be displayed. Creating a cursor with a FOR UPDATE argument allows you to execute in the cursor data change either in the specified columns or, in the absence of the OF column_name argument, in all columns. In the MS SQL Server environment, the following syntax for the cursor creation command is accepted: <создание_курсора>::= DECLARE cursor_name CURSOR FOR SELECT_statement ]] Using the LOCAL keyword will create a local cursor that is visible only within the scope of the package, trigger, stored procedure, or user-defined function that created it. When a package, trigger, procedure, or function terminates, the cursor is implicitly destroyed. To pass the contents of the cursor outside the construct that created it, you must assign an OUTPUT argument to its parameter. If the GLOBAL keyword is specified, a global cursor is created; it exists until the current connection is closed. Specifying FORWARD_ONLY creates serial cursor; Data can only be sampled in the direction from the first row to the last. Specifying SCROLL creates scrollable cursor; Data can be accessed in any order and in any direction. Specifying STATIC creates static cursor. Specifying KEYSET creates a key cursor. Specifying DYNAMIC creates dynamic cursor. If you specify the FAST_FORWARD argument for a READ_ONLY cursor, the created cursor will be optimized for fast data access. This argument cannot be used in conjunction with the FORWARD_ONLY or OPTIMISTIC arguments. A cursor created with the OPTIMISTIC argument prevents modification or deletion of rows that were modified after opening the cursor. By specifying the TYPE_WARNING argument, the server will inform the user of an implicit change to the cursor type if it is incompatible with the SELECT query. For opening the cursor and filling it with data from the SELECT query specified when creating the cursor, use the following command: After opening the cursor The associated SELECT statement is executed, the output of which is stored in multi-level memory. Right after opening the cursor you can select its contents (the result of executing the corresponding query) using the following command: Specifying FIRST will return the very first row of the cursor's complete result set, which becomes the current row. Specifying LAST returns the most recent row of the cursor. It also becomes the current line. Specifying NEXT returns the row immediately after the current one in the full result set. Now it becomes current. By default, the FETCH command uses this method for fetching rows. The PRIOR keyword returns the row before the current one. It becomes current. Argument ABSOLUTE (line_number | @line_number_variable) returns a row by its absolute ordinal number in the cursor's complete result set. The line number can be specified using a constant or as the name of a variable in which the line number is stored. The variable must be an integer data type. Both positive and negative values are indicated. When specifying a positive value, the string is counted from the beginning of the set, while a negative value is counted from the end. The selected line becomes the current line. If a null value is specified, no row is returned. Argument RELATIVE (number of rows | @variable number of rows) returns the line that is the specified number of lines after the current one. If you specify a negative number of rows, the row that is the specified number of rows before the current one will be returned. Specifying a null value will return the current row. The returned row becomes the current row. To open global cursor, you must specify the GLOBAL keyword before its name. The cursor name can also be specified using a variable. In design INTO @variable_name [,...n] a list of variables is specified in which the corresponding column values of the returned row will be stored. The order of specifying variables must match the order of the columns in the cursor, and the data type of the variable must match the data type in the cursor column. If the INTO construct is not specified, then the behavior of the FETCH command will resemble the behavior of the SELECT command - the data is displayed on the screen. To make changes using a cursor, you must issue an UPDATE command in the following format: Several columns of the current cursor row can be changed in one operation, but they all must belong to the same table. To delete data using a cursor, use the DELETE command in the following format: As a result, the line set current in the cursor will be deleted. After closing, the cursor becomes inaccessible to program users. When closing, all locks installed during its operation are removed. Closure can only be applied to open cursors. Closed but not freed cursor may be reopened. It is not allowed to close an unopened cursor. Closing the cursor does not necessarily free the memory associated with it. Some implementations must explicitly deallocate it using the DEALLOCATE statement. After release the cursor Memory is also freed, making it possible to reuse the cursor name. To control whether the end of the cursor has been reached, it is recommended to use the function: @@FETCH_STATUS The @@FETCH_STATUS function returns: 0 if the fetch was successful; 1 if the fetch failed due to an attempt to fetch a line outside the cursor; 2 if the fetch failed due to an attempt to access a deleted or modified row. DECLARE @id_kl INT, @firm VARCHAR(50), @fam VARCHAR(50), @message VARCHAR(80), @nam VARCHAR(50), @d DATETIME, @p INT, @s INT SET @s=0 PRINT "Shopping list" DECLARE klient_cursor CURSOR LOCAL FOR SELECT Client Code, Company, Last Name FROM Client WHERE City="Moscow" ORDER BY Company, Last Name OPEN klient_cursor FETCH NEXT FROM klient_cursor INTO @id_kl, @firm, @fam WHILE @@FETCH_STATUS=0 BEGIN SELECT @message="Client "+@fam+ "Company "+ @firm PRINT @message SELECT @message="Product name Purchase date Cost" PRINT @message DECLARE tovar_cursor CURSOR FOR SELECT Product.Name, Transaction.Date, Product.Price* Transaction.Quantity AS Cost FROM Product INNER JOIN Transaction ON Product. Product Code=Transaction.Product Code WHERE Transaction.Customer Code=@id_kl OPEN tovar_cursor FETCH NEXT FROM tovar_cursor INTO @nam, @d, @p IF @@FETCH_STATUS<>0 PRINT "No purchases" WHILE @@FETCH_STATUS=0 BEGIN SELECT @message=" "+@nam+" "+ CAST(@d AS CHAR(12))+" "+ CAST(@p AS CHAR(6)) PRINT @message SET @s=@s+@p FETCH NEXT FROM tovar_cursor INTO @nam, @d, @p END CLOSE tovar_cursor DEALLOCATE tovar_cursor SELECT @message="Total cost "+ CAST(@s AS CHAR(6)) PRINT @message -- move to next client-- FETCH NEXT FROM klient_cursor INTO @id_kl, @firm, @fam END CLOSE klient_cursor DEALLOCATE klient_cursor Example 13.6. Cursor for displaying a list of goods purchased by clients from Moscow and their total cost. Example 13.7. Develop a scrollable cursor for clients from Moscow. If the phone number starts with 1, delete the client with that number and in the first cursor entry replace the first digit in the phone number with 4. DECLARE @firm VARCHAR(50), @fam VARCHAR(50), @tel VARCHAR(8), @message VARCHAR(80) PRINT "List of clients" DECLARE klient_cursor CURSOR GLOBAL SCROLL KEYSET FOR SELECT Firm, Last name, Phone FROM Client WHERE City ="Moscow" ORDER BY Company, Last name FOR UPDATE OPEN klient_cursor FETCH NEXT FROM klient_cursor INTO @firm, @fam, @tel WHILE @@FETCH_STATUS=0 BEGIN SELECT @message="Client "+@fam+ " Company "+@firm " Phone "+ @tel PRINT @message -- if the phone number starts with 1, -- delete the client with that number IF @tel LIKE '1%' DELETE Client WHERE CURRENT OF klient_cursor ELSE -- move to the next client FETCH NEXT FROM klient_cursor INTO @firm, @fam, @tel END FETCH ABSOLUTE 1 FROM klient_cursor INTO @firm, @fam, @tel -- in the first entry, replace the first digit in the phone number with 4 UPDATE Client SET Phone='4' + RIGHT(@ tel,LEN(@tel)-1)) WHERE CURRENT OF klient_cursor SELECT @message="Client "+@fam+" Firm "+ @firm "Phone "+ @tel PRINT @message CLOSE klient_cursor DEALLOCATE klient_cursor Example 13.7. Scrollable cursor for clients from Moscow. Example 13.8. Usage cursor as an output parameter of the procedure. The procedure returns a data set - a list of products. Calling the procedure and printing data from the output cursor is carried out as follows: DECLARE @my_cur CURSOR DECLARE @n VARCHAR(20) EXEC my_proc @cur=@my_cur OUTPUT FETCH NEXT FROM @my_cur INTO @n SELECT @n WHILE (@@FETCH_STATUS=0) BEGIN FETCH NEXT FROM @my_cur INTO @n SELECT @n END CLOSE @my_cur DEALLOCATE @my_cur Cursor in SQL, an area in database memory that is dedicated to storing the last SQL statement. If the current statement is a database query, a string of query data called the current value, or current row, is also stored in memory. cursor. The specified area in memory is named and accessible to application programs. According to the SQL standard when working with cursors the following main ones can be identified actions: SQL Server supports three type of cursors: Cursor management in MS SQL Server environment Cursor control implemented by executing the following commands: Cursor Declaration In the SQL standard for creating cursor The following command is provided:
<создание_курсора>::= DECLARE cursor_name CURSOR FOR SELECT_statement ])] Using the INSENSITIVE keyword will create static cursor. Data changes are not allowed, in addition, are not displayed changes, made by other users. If the INSENSITIVE keyword is missing, a dynamic cursor. When you specify the SCROLL keyword, the created cursor can be scrolled in any direction, allowing you to apply any commands samples. If this argument is omitted, then cursor it turns out consistent, i.e. its viewing will be possible only in one direction - from beginning to end. The SELECT statement specifies the body of the SELECT query, which determines the result set of rows cursor. Specifying the FOR READ_ONLY argument creates cursor"read-only" and no modification of the data is allowed. It is different from static, although the latter also does not allow you to change data. Can be declared as a read-only cursor dynamic cursor, which will allow you to display changes, made by another user. Creation cursor with the FOR UPDATE argument allows you to execute in cursor data change either in the specified columns or, in the absence of the OF column_name argument, in all columns. In the MS SQL Server environment, the following syntax for the creation command is accepted cursor:
<создание_курсора>::= DECLARE cursor_name CURSOR FOR SELECT_statement ]] Using the LOCAL keyword will create a local cursor, which is visible only within the scope of the package, trigger, stored procedure, or user-defined function that created it. When a package, trigger, procedure, or function completes cursor is implicitly destroyed. To transfer content cursor outside the construct that created it, you must assign its parameter an OUTPUT argument. If the GLOBAL keyword is specified, a global cursor; it exists until the current connection is closed. Specifying FORWARD_ONLY creates serial cursor ; sample data can only be processed in the direction from the first line to the last. Specifying SCROLL creates scrollable cursor; Data can be accessed in any order and in any direction. Specifying STATIC creates static cursor. Specifying KEYSET creates a key cursor. Specifying DYNAMIC creates dynamic cursor. If for cursor READ_ONLY specify the FAST_FORWARD argument then created cursor will be optimized for fast data access. This argument cannot be used in conjunction with the FORWARD_ONLY or OPTIMISTIC arguments. IN cursor, created with the OPTIMISTIC argument, is prohibited change And deleting rows that were changed after opening the cursor. When specifying the TYPE_WARNING argument, the server will inform the user of the implicit type change cursor if it is incompatible with the SELECT query. Opening the cursor For opening the cursor and filling it with data from the one specified during creation cursor The SELECT query uses the following command: OPEN ((cursor_name) |@cursor_variable_name) After opening the cursor The associated SELECT statement is executed, the output of which is stored in multi-level memory. Retrieving data from a cursor Right after opening the cursor you can select its contents (the result of executing the corresponding query) using the following command: FETCH [ FROM ]((cursor_name)| @cursor_variable_name) ] Specifying FIRST will return the very first row of the complete result set cursor, which becomes the current line. Specifying LAST returns the most recent row cursor. It also becomes the current line. Specifying NEXT returns the row immediately after the current one in the full result set. Now it becomes current. By default, the FETCH command uses this method. samples lines. The PRIOR keyword returns the row before the current one. It becomes current. ABSOLUTE (row_number | @row_number_variable) returns the row by its absolute index number in the complete result set cursor. The line number can be specified using a constant or as the name of a variable in which the line number is stored. The variable must be an integer data type. Both positive and negative values are indicated. When specifying a positive value, the string is counted from the beginning of the set, while a negative value is counted from the end. The selected line becomes the current line. If a null value is specified, no row is returned. The RELATIVE argument (number of rows | @variable number of rows) returns the row that is the specified number of rows after the current one. If you specify a negative number of rows, the row that is the specified number of rows before the current one will be returned. Specifying a null value will return the current row. The returned row becomes the current row. To open global cursor, you must specify the GLOBAL keyword before its name. Name cursor can also be specified using a variable. The INTO @variable_name [,...n] construction specifies a list of variables in which the corresponding column values of the returned string will be stored. The order of the variables must match the order of the columns in cursor, and the data type of the variable is the data type in the column cursor. If the INTO construct is not specified, then the behavior of the FETCH command will resemble the behavior of the SELECT command - the data is displayed on the screen.Cursor concept
Implementation of cursors in MS SQL Server environment
Cursor management in MS SQL Server environment
Cursor Declaration
Opening the cursor
Retrieving data from a cursor
Changing and deleting data
Closing the cursor
Release the cursor