Пустой файл robots txt. Поисковые роботы Google. Что означает User-agent
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Директива Host – это команда или правило, сообщающее поисковой машине о том, какое (с www или без) считать основным. Находится директива Host в файле и предназначена исключительно для Яндекса.
Часто возникает необходимость, чтобы поисковая система не индексировала некоторые страницы сайта или его зеркала. Например, ресурс находится на одном сервере, однако в интернете есть идентичное доменное имя, по которому осуществляется индексация и отображение в результатах поисковой выдачи.
Поисковые роботы Яндекса обходят страницы сайтов и добавляют собранную информацию в базу данных по собственному графику. В процессе индексации они самостоятельно решают, какую страницу необходимо обработать. К примеру, роботы обходят стороной различные форумы, доски объявлений, каталоги и прочие ресурсы, где индексация бессмысленна. Также они могут определять главный сайт и зеркала. Первые подлежат индексации, вторые – нет. В процессе часто возникают ошибки. Повлиять на это можно посредством использования директивы Host в файл Robots.txt.
Зачем нужен файл Robots.txt
Robots – это обычный текстовый файл. Его можно создать через блокнот, однако работать с ним (открывать и редактировать информацию) рекомендуется в текстовом редакторе Notepad++ . Необходимость данного файла при оптимизации веб-ресурсов обуславливается несколькими факторами:
- Если файл Robots.txt отсутствует, сайт будет постоянно перегружен из-за работы поисковых машин.
- Существует риск, что индексироваться будут лишние страницы или сайты зеркала.
Индексация будет проходить гораздо медленнее, а при неправильно установленных настройках он вовсе может исчезнуть из результатов поисковой выдачи Google и Яндекс.
Как оформить директиву Host в файле Robots.txt
Файл Robots включает в себя директиву Host – инструкцию для поисковой машины о том, где главный сайт, а где его зеркала.
Директива имеет следующую форму написания: Host: [необязательный пробел] [значение] [необязательный пробел]. Правила написания директивы требуют соблюдения следующих пунктов:
- Наличие в директиве Host протокола HTTPS для поддержки шифрования. Его необходимо использовать, если доступ к зеркалу осуществляется только по защищенному каналу.
- Доменное имя, не являющееся IP-адресом, а также номер порта веб-ресурса.
Корректно составленная директива позволит веб-мастеру обозначить для поисковых машин, где главное зеркало. Остальные будут считаться второстепенными и, следовательно, индексироваться не будут. Как правило, зеркала можно отличить по наличию или отсутствию аббревиатуры www. Если пользователь не укажет главное зеркало веб-ресурса посредством Host, поисковая система Яндекс пришлет соответствующее уведомление в Вебмастер. Также уведомление будет выслано, если в файле Роботс задана противоречивая директива Host.
Определить, где главное зеркало сайта можно через поисковик. Необходимо вбить в поисковую строку адрес ресурса и посмотреть на результаты выдачи: сайт, где перед доменом в адресной строке стоит www, является главным доменом.
В случае, если ресурс не отображается на странице выдачи, пользователь может самостоятельно назначить его главным зеркалом, перейдя в соответствующий раздел в Яндекс.Вебмастере. Если веб-мастеру необходимо, чтобы доменное имя сайта не содержало www, следует не указывать его в Хосте.
Многие веб-мастера используют кириллические домены в качестве дополнительных зеркал для своих сайтов. Однако в директиве Host кириллица не поддерживается. Для этого необходимо дублировать слова на латинице, с условием, что их можно будет легко узнать, скопировав адрес сайта из адресной строки.
Хост в файле Роботс
Главное предназначение данной директивы состоит в решении проблем с дублирующими страницами. Использовать Host необходимо в случае, если работа веб-ресурса ориентирована на русскоязычную аудиторию и, соответственно, сортировка сайта должна проходить в системе Яндекса.
Не все поисковики поддерживают работу директивы Хост. Функция доступна только в Яндексе. При этом даже здесь нет гарантий, что домен будет назначен в качестве главного зеркала, но по заверениям самого Яндекса, приоритет всегда остается за именем, которое указано в хосте.
Чтобы поисковые машины правильно считывали информацию при обработке файла robots.txt, необходимо прописывать директиву Host в соответствующую группу, начинающуюся после слов User-Agent. Однако, роботы смогут использовать Host независимо от того, будет директива прописана по правилам или нет, поскольку она является межсекционной.
Здравствуйте, уважаемые читатели блога «Мир Вебмастера»!
Файл robots.txt – это очень важный файл, напрямую влияющий на качество индексации вашего сайта, а значит и на его поисковое продвижение.
Именно поэтому вы должны уметь правильно оформлять роботс.тхт, чтобы случайно не запретить к индексу какие-нибудь важные документы интернет-проекта.
О том, как оформить файл robots.txt, какой синтаксис нужно использовать при этом, как разрешать и запрещать к индексу документы, и пойдет речь в этой статье.
О файле robots.txt
Сначала давайте подробнее узнаем, что же это за файл такой.
Файл роботс – это файл, который показывает поисковым системам, какие страницы и документы сайта можно добавлять в индекс, а какие – нельзя. Он необходим из-за того, что изначально поисковые системы стараются проиндексировать весь сайт, а это не всегда правильно. Например, если вы создаете сайт на движке (WordPress, Joomla и т.д.), то у вас будут присутствовать папки, организующие работу административной панели. Понятно, что информацию в этих папках индексировать нельзя, как раз в этом случае и используется файл robots.txt, который ограничивает доступ поисковикам.
Также в файле роботс.тхт указывается адрес карты сайта (она улучшает индексацию поисковыми системами), а также главный домен сайта (главное зеркало).
Зеркало – это абсолютная копия сайта, т.е. когда один сайт , то говорят, что один из них – это главный домен, а другой – его зеркало.
Таким образом, у файла достаточно много функций, причем немаловажных!
Синтаксис файла robots.txt
Файл роботс содержит блоки правил, которые говорят той или иной поисковой системе, что можно индексировать, а что нет. Блок правил может быть и один (для всех поисковиков), но также их может быть несколько – для каких-то конкретных поисковиков отдельно.

Каждый такой блок начинается с оператора «User-Agent», который указывает, к какой поисковой системе применимы данные правила.
User-
Agent:
A
{правила для робота «А»}
User-
Agent:
B
{правила для робота «В»}
В примере выше показано, что оператор «User-Agent» имеет параметр – имя робота поисковой системы, к которой применяются правила. Основные из них я укажу ниже:
После «User-Agent» идут другие операторы. Вот их описание:
Для всех операторов справедлив один синтаксис. Т.е. операторы нужно использовать следующим образом:
Оператор1: параметр1
Оператор2: параметр2
…
Таким образом, сначала мы пишем название оператора (неважно, большими или маленькими буквами), затем ставим двоеточие и через пробел указываем параметр данного оператора. Затем с новой строки таким же образом описываем оператор два.
Важно!!! Пустая строка будет означать, что блок правил для данного поисковика закончен, поэтому не разделяйте операторы пустой строкой.
Пример файла robots.txt
Рассмотрим простенький пример файла robots.txt, чтобы лучше разобраться в особенностях его синтаксиса:
User-agent: Yandex
Allow: /folder1/
Disallow: /file1.html
Host: www.site.ru
User-agent: *
Disallow: /document.php
Disallow: /folderxxx/
Disallow: /folderyyy/folderzzz
Disallow: /feed/
Sitemap: http://www.site.ru/sitemap.xml
Теперь разберем описанный пример.
Файл состоит из трех блоков: первый для Яндекса, второй для всех поисковых систем, а в третьем указан адрес карты сайта (применяется автоматически для всех поисковиков, поэтому указывать «User-Agent» не нужно). Яндексу мы разрешили индексировать папку «folder1» и все ее содержимое, но запретили индексировать документ «file1.html», находящийся в корневом каталоге на хостинге. Также мы указали главный домен сайта яндексу. Второй блок – для всех поисковиков. Там мы запретили документ «document.php», а также папки «folderxxx», «folderyyy/folderzzz» и «feed».
Обратите внимание, что мы запретили в втором блоке команд к индексу не всю папку «folderyyy», а лишь папку внутри этой папки – «folderzzz». Т.е. мы указали полный путь для «folderzzz». Так всегда нужно делать, если мы запрещаем документ, находящийся не в корневом каталоге сайта, а где-то внутри других папок.
Создание займет меньше двух минут:
Созданный файл роботс можно проверить на работоспособность в панели вебмастеров Яндекса . Если в файле вдруг обнаружатся ошибки, то яндекс это покажет.

Обязательно создайте файл robots.txt для вашего сайта, если его у вас до сих пор нету. Это поможет развиваться вашему сайту в поисковых системах. Также можете почитать еще одну нашу статью про методом мета-тегов и.htaccess.
Время чтения: 7 минут(ы)
Почти каждый проект, который приходит к нам на аудит либо продвижение, имеет некорректный файл robots.txt, а часто он вовсе отсутствует. Так происходит, потому что при создании файла все руководствуются своей фантазией, а не правилами. Давайте разберем, как правильно составить этот файл, чтобы поисковые роботы эффективно с ним работали.
Зачем нужна настройка robots.txt?
Robots.txt - это файл, размещенный в корневом каталоге сайта, который сообщает роботам поисковых систем, к каким разделам и страницам сайта они могут получить доступ, а к каким нет.
Настройка robots.txt - важная часть в выдаче поисковых систем, правильно настроенный robots также увеличивает производительность сайта. Отсутствие Robots.txt не остановит поисковые системы сканировать и индексировать сайт, но если этого файла у вас нет, у вас могут появиться две проблемы:
Поисковый робот будет считывать весь сайт, что «подорвет» краулинговый бюджет. Краулинговый бюджет - это число страниц, которые поисковый робот способен обойти за определенный промежуток времени.
Без файла robots, поисковик получит доступ к черновым и скрытым страницам, к сотням страниц, используемых для администрирования CMS. Он их проиндексирует, а когда дело дойдет до нужных страниц, на которых представлен непосредственный контент для посетителей, «закончится» краулинговый бюджет.
В индекс может попасть страница входа на сайт, другие ресурсы администратора, поэтому злоумышленник сможет легко их отследить и провести ddos атаку или взломать сайт.
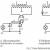
Как поисковые роботы видят сайт с robots.txt и без него:

Синтаксис robots.txt
Прежде чем начать разбирать синтаксис и настраивать robots.txt, посмотрим на то, как должен выглядеть «идеальный файл»:

Но не стоит сразу же его применять. Для каждого сайта чаще всего необходимы свои настройки, так как у всех у нас разная структура сайта, разные CMS. Разберем каждую директиву по порядку.
User-agent
User-agent - определяет поискового робота, который обязан следовать описанным в файле инструкциям. Если необходимо обратиться сразу ко всем, то используется значок *. Также можно обратиться к определенному поисковому роботу. Например, Яндекс и Google:

С помощью этой директивы, робот понимает какие файлы и папки индексировать запрещено. Если вы хотите, чтобы весь ваш сайт был открыт для индексации оставьте значение Disallow пустым. Чтобы скрыть весь контент на сайте после Disallow поставьте “/”.
Мы можем запретить доступ к определенной папке, файлу или расширению файла. В нашем примере, мы обращаемся ко всем поисковым роботам, закрываем доступ к папке bitrix, search и расширению pdf.

Allow
Allow принудительно открывает для индексирования страницы и разделы сайта. На примере выше мы обращаемся к поисковому роботу Google, закрываем доступ к папке bitrix, search и расширению pdf. Но в папке bitrix мы принудительно открываем 3 папки для индексирования: components, js, tools.

Host - зеркало сайта
Зеркало сайта - это дубликат основного сайта. Зеркала используются для самых разных целей: смена адреса, безопасность, снижение нагрузки на сервер и т. д.
Host - одно из самых важных правил. Если прописано данное правило, то робот поймет, какое из зеркал сайта стоит учитывать для индексации. Данная директива необходима для роботов Яндекса и Mail.ru. Другие роботы это правило будут игнорировать. Host прописывается только один раз!
Для протоколов «https://» и «http://», синтаксис в файле robots.txt будет разный.
Sitemap - карта сайта
Карта сайта - это форма навигации по сайту, которая используется для информирования поисковых систем о новых страницах. С помощью директивы sitemap, мы «насильно» показываем роботу, где расположена карта.

Символы в robots.txt
Символы, применяемые в файле: «/, *, $, #».

Проверка работоспособности после настройки robots.txt
После того как вы разместили Robots.txt на своем сайте, вам необходимо добавить и проверить его в вебмастере Яндекса и Google.
Проверка Яндекса:
- Перейдите по ссылке https://webmaster.yandex.ru/tools/robotstxt/ .
- Выберите: Настройка индексирования - Анализ robots.txt.
Проверка Google:
- Перейдите по ссылке https://support.google.com/webmasters/answer/6062598 .
- Выберите: Сканирование - Инструмент проверки файла robots.txt.
Таким образом вы сможете проверить свой robots.txt на ошибки и внести необходимые настройки, если потребуется.
- Содержимое файла необходимо писать прописными буквами.
- В директиве Disallow нужно указывать только один файл или директорию.
- Строка «User-agent» не должна быть пустой.
- User-agent всегда должна идти перед Disallow.
- Не стоит забывать прописывать слэш, если нужно запретить индексацию директории.
- Перед загрузкой файла на сервер, обязательно нужно проверить его на наличие синтаксических и орфографических ошибок.
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Robots.txt - это текстовый файл, содержащий сведения для поисковых роботов, которые помогают проиндексировать страницы портала.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
Представьте, что вы отправились за сокровищами на остров. У вас есть карта. Там указан маршрут: “Подойти к большому пню. От него сделать 10 шагов на восток, затем дойти до обрыва. Повернуть вправо, найти пещеру”.
Это - указания. Следуя им, вы идете по маршруту и находите клад. Примерно также работает и поисковой бот, когда начинает индексировать сайт или страницу. Он находит файл robots.txt. В нем считывает, какие страницы нужно проиндексировать, а какие - нет. И, следуя этим командам, он обходит портал и добавляет его страницы в индекс.
Для чего нужен robots.txt
Начинают ходить по сайтам и индексировать страницы после того, как сайт загружен на хостинг и прописаны dns. Они делают свою работу вне зависимости от того, есть у вас какие-то технические файлы или нет. Роботс указывает поисковикам, что при обходе веб-сайта нужно учитывать параметры, которые в нем находится.
Отсутствие файла robots.txt может привести к проблемам со скоростью обхода сайта и присутствия мусора в индексе. Некорректная настройка файла чревата исключением из индекса важных частей ресурса и присутствием в выдаче ненужных страниц.
Все это, как результат, ведет к проблемам с продвижением.
Рассмотрим подробнее, какие инструкции содержатся в этом файле, как они влияют на поведение бота у вас на сайте.
Как сделать robots.txt
Для начала проверьте, есть ли у вас этот файл.
Введите в адресной строке браузера адрес сайта и через слэш имя файла, например, https://www.xxxxx.ru/robots.txt
Если файл присутствует, то на экране появится список его параметров.

Если файла нет:
- Файл создается в обычном текстом редакторе типо блокнота или Notepad++.
- Нужно задать имя robots, расширение.txt. Внести данные с учетом принятых стандартов оформления.
- Можно проверить на предмет ошибок с помощью сервисов типа вебмастера Яндекса.Там нужно выбрать пункт «Анализ robots.txt» в разделе «Инструменты» и следовать подсказкам.
- Когда файл готов, залейте его в корневой каталог сайта.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые - только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Сейчас есть две ключевых поисковых системы: Яндекс и Google, соответственно, важно при составлении сайта учитывать требования обеих.
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки.

Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.
Такой вариант, наоборот, означает полный запрет индексации для всех.
Запрет на просмотр всего содержимого определенной папки-каталога
Для блокировки одного файла нужно указать его абсолютный путь
Директивы Sitemap, Host
Для Яндекса в принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.
Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.
Директива Crawl-delay
С помощью можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.
Ошибки robots.txt
- Файл не находится в корневом каталоге. Глубже робот его искать не будет и не учтет.
- Буквы в названии должны быть маленькие латинские.
Ошибка в названии, иногда упускают букву S на конце и пишут robot. - Нельзя использовать кириллические символы в файле robots.txt. Если нужно указать домен на русском языке, используйте формат в специальной кодировке Punycode.
- Это метод преобразования доменных имен в последовательность ASCII-символов. Для этого можно воспользоваться специальными конвертерами.
Выглядит такая кодировка следующим образом:
сайт.рф = xn--80aswg.xn--p1ai
Дополнительную информацию, что закрывать в robots txt и по настройкам в соответствии с требованиями поисковиков Гугл и Яндекс можно найти в справочных документах. Для различных cms также могут быть свои особенности, это следует учесть.
Файл robots.txt находится в корневом каталоге вашего сайта. Например, на сайте www.example.com адрес файла robots.txt будет выглядеть как www.example.com/robots.txt. Он представляет собой обычный текстовый файл, который соответствует стандарту исключений для роботов , и включает одно или несколько правил, каждое из которых запрещает или разрешает тому или иному поисковому роботу доступ к определенному пути на сайте.
Ниже приведен пример простого файла robots.txt, содержащего два правила, и его интерпретация.
# Rule 1 User-agent: Googlebot Disallow: /nogooglebot/ # Rule 2 User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Интерпретация
- Агент пользователя с названием Googlebot не должен сканировать каталог http://example.com/nogooglebot/ и его подкаталоги.
- У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Ниже представлено несколько советов по работе с файлами robots.txt. Мы рекомендуем вам изучить полный синтаксис файлов robots.txt , так как используемые при создании файлов robots.txt синтаксические правила являются неочевидными и вы должны разбираться в них.
Формат и расположение
Создать файл robots.txt можно почти в любом текстовом редакторе (он должен поддерживать кодировку ASCII или UTF-8). Не используйте текстовые процессоры: зачастую они сохраняют файлы в проприетарном формате и добавляют в них недопустимые символы, например фигурные кавычки, которые не распознаются поисковыми роботами.
Применяйте инструмент проверки файлов robots.txt при создании и тестировании таких файлов. Он позволяет проанализировать синтаксис файла и узнать, как он будет функционировать на вашем сайте.
Правила в отношении формата и расположения файла
- Файл должен носить название robots.txt.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать сканирование всех страниц сайта http://www.example.com/ , файл robots.txt следует разместить по адресу http://www.example.com/robots.txt . Он не должен находиться в подкаталоге (например, по адресу http://example.com/pages/robots.txt ). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги .
- Файл robots.txt можно добавлять по адресам с субдоменами (например, http://website .example.com/robots.txt) или нестандартными портами (например, http://example.com:8181 /robots.txt).
- Комментариями являются любые строки, начинающиеся с символа решетки (#).
Синтаксис
- Файл robots.txt должен являться текстовым файлом в кодировке ASCII или UTF-8. Использовать другие символы не разрешается.
- Файл robots.txt может состоять из одного или нескольких правил .
- Правило должно содержать несколько директив (инструкций), каждую из которых следует указывать на отдельной строке.
- Правило содержит следующую информацию:
- К какому агенту пользователя относится правило.
- есть доступ .
- К каким каталогам или файлам у этого агента нет доступа .
- Правила обрабатываются сверху вниз. Агент пользователя может следовать только одному подходящему для него правилу, которое будет обработано первым.
- По умолчанию предполагается , что если доступ к странице или каталогу не заблокирован правилом Disallow: , агент пользователя может их обрабатывать.
- Правила чувствительны к регистру . Так, правило Disallow: /file.asp применимо к URL http://www.example.com/file.asp , но не к http://www.example.com/File.asp .
Директивы, которые используются в файлах robots.txt
- User-agent: Обязательно к использованию, в одном правиле может быть одно или несколько таких правил. Определяет робота поисковой системы, к которому относится правило. Эта строка является первой в любом правиле. Большинство из них перечислены в базе данных роботов Интернета или в списке поисковых роботов Google . Поддерживается подстановочный знак * для обозначения префикса или суффикса пути или всего пути. Используйте такой знак (*), как указано в примере ниже, чтобы заблокировать все поисковые роботы (кроме роботов AdsBot , которых нужно задавать отдельно). Рекомендуем ознакомиться со списком роботов Google . Примеры: # Example 1: Block only Googlebot User-agent: Googlebot Disallow: / # Example 2: Block Googlebot and Adsbot User-agent: Googlebot User-agent: AdsBot-Google Disallow: / # Example 3: Block all but AdsBot crawlers User-agent: * Disallow: /
- Disallow: . Указывает на каталог или страницу в корневом домене, которые нельзя сканировать агенту пользователя, определенному выше. Если это страница, должен быть указан полный путь к ней, как в адресной строке браузера. Если это каталог, путь к нему должен заканчиваться косой чертой (/). Поддерживается подстановочный знак * для обозначения префикса или суффикса пути или всего пути.
- Allow: В каждом правиле должна быть по крайней мере одна директива Disallow: или Allow: . Указывает на каталог или страницу в корневом домене, которые нельзя сканировать агенту пользователя, определенному выше. Используется для того, чтобы отменить правило Disallow и разрешить сканирование подкаталога или страницы в закрытом для сканирования каталоге. Если это страница, должен быть указан полный путь к ней, как в адресной строке браузера. Если это каталог, путь к нему должен заканчиваться косой чертой (/). Поддерживается подстановочный знак * для обозначения префикса или суффикса пути или всего пути.
- Sitemap: Необязательно, таких директив может быть несколько или совсем не быть. Указывает на расположение файла Sitemap, используемого на этом сайте. URL должен быть полным. Google не обрабатывает и не проверяет варианты URL с префиксами http и https или с элементом www и без него. Файлы Sitemap сообщают Google, какой контент нужно сканировать и как отличить его от контента, который можно или нельзя сканировать. Ознакомьтесь с дополнительными сведениями о файлах Sitemap. Пример: Sitemap: https://example.com/sitemap.xml Sitemap: http://www.example.com/sitemap.xml
Неизвестные ключевые слова игнорируются.
Ещё один пример
Файл robots.txt состоит из одного или нескольких наборов правил. Каждый набор начинается с строки User-agent , которая определяет робота, подчиняющегося правилам в наборе. Вот пример файла с двумя правилами; они объяснены встроенными комментариями:
# Блокировать доступ робота Googlebot к каталогам example.com/directory1/... и example.com/directory2/... # но разрешить доступ к каталогу directory2/subdirectory1/... # Доступ ко всем остальным каталогам разрешен по умолчанию. User-agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ # Блокировать доступ ко всему сайту другой поисковой системе. User-agent: anothercrawler Disallow: /
Полный синтаксис файла robots.txt
Полный синтаксис описан в этой статье . Рекомендуем вам ознакомиться с ней, так как в синтаксисе файла robots.txt есть некоторые важные нюансы.
Полезные правила
Вот несколько распространенных правил для файла robots.txt:
| Правило | Пример |
|---|---|
| Запрет сканирования всего сайта. Следует учесть, что в некоторых случаях URL сайта могут присутствовать в индексе, даже если они не были просканированы. Обратите внимание, что это правило не относится к роботам AdsBot , которых нужно указывать отдельно. | User-agent: * Disallow: / |
| Чтобы запретить сканирование каталога и все его содержание , поставьте после названия каталога косую черту. Не используйте файл robots.txt для защиты конфиденциальной информации! Для этих целей следует применять аутентификацию. URL, сканирование которых запрещено файлом robots.txt, могут быть проиндексированы, а содержание файла robots.txt может просмотреть любой пользователь, и таким образом узнать местоположение файлов с конфиденциальной информацией. | User-agent: * Disallow: /calendar/ Disallow: /junk/ |
| Разрешение сканирования только для одного поискового робота | User-agent: Googlebot-news Allow: / User-agent: * Disallow: / |
| Разрешение сканирования для всех поисковых роботов, за исключением одного | User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / |
|
Чтобы запретить сканирование отдельной страницы , укажите эту страницу после косой черты. |
Disallow: /private_file.html |
|
Чтобы скрыть определенное изображение от робота Google Картинок |
User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
|
Чтобы скрыть все изображения с вашего сайта от робота Google Картинок |
User-agent: Googlebot-Image Disallow: / |
|
Чтобы запретить сканирование всех файлов определенного типа (в данном случае GIF) |
User-agent: Googlebot Disallow: /*.gif$ |
|
Чтобы заблокировать определенные страницы сайта, но продолжать на них показ объявлений AdSense , используйте правило Disallow для всех роботов, за исключением Mediapartners-Google. В результате этот робот сможет получить доступ к удаленным из результатов поиска страницам, чтобы подобрать объявления для показа тому или иному пользователю. |
User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
| Чтобы указать URL, заканчивающиеся на определенные символы, применяйте символ $ . Например, для URL, заканчивающихся на.xls , используйте следующий код: | User-agent: Googlebot Disallow: /*.xls$ |
Была ли эта статья полезна?
Как можно улучшить эту статью?