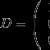Jakie są zasady von Neumanna? Zasady Johna von Neumanna. pokolenia komputerów Klasyfikacja współczesnych komputerów
Zasady von Neumanna (architektura von Neumanna)
Architektura komputerowa
W 1946 roku D. von Neumann, G. Goldstein i A. Berks we wspólnym artykule przedstawili nowe zasady budowy i działania komputerów. Następnie w oparciu o te zasady wyprodukowano pierwsze dwie generacje komputerów. W późniejszych pokoleniach nastąpiły pewne zmiany, chociaż zasady Neumanna są nadal aktualne.
W rzeczywistości Neumannowi udało się podsumować rozwój naukowy i odkrycia wielu innych naukowców i sformułować na ich podstawie coś zasadniczo nowego.
Zasady von Neumanna
Zastosowanie binarnego systemu liczbowego w komputerach. Przewaga nad systemem liczb dziesiętnych polega na tym, że urządzenia można tworzyć dość prosto, a operacje arytmetyczne i logiczne w systemie liczb binarnych są również wykonywane w prosty sposób.
Sterowanie oprogramowaniem komputerowym. Pracą komputera steruje program składający się z zestawu poleceń. Polecenia wykonywane są sekwencyjnie, jedno po drugim. Stworzenie maszyny z zapisanym programem było początkiem tego, co dzisiaj nazywamy programowaniem.
Pamięć komputera służy nie tylko do przechowywania danych, ale także programów.. W tym przypadku zarówno polecenia programu, jak i dane kodowane są w systemie liczb binarnych, tj. ich metoda nagrywania jest taka sama. Dlatego w niektórych sytuacjach możesz wykonywać te same czynności na poleceniach, co na danych.
Komórki pamięci komputera mają adresy, które są ponumerowane sekwencyjnie. W dowolnym momencie możesz uzyskać dostęp do dowolnej komórki pamięci po jej adresie. Zasada ta otworzyła możliwość wykorzystania zmiennych w programowaniu.
Możliwość skoku warunkowego podczas wykonywania programu. Pomimo tego, że polecenia są wykonywane sekwencyjnie, programy mogą implementować możliwość przeskakiwania do dowolnej sekcji kodu.
Najważniejszą konsekwencją tych zasad jest to, że teraz program nie jest już stałą częścią maszyny (jak na przykład kalkulator). Możliwość łatwej zmiany programu stała się możliwa. Ale sprzęt oczywiście pozostaje niezmieniony i bardzo prosty.
Dla porównania program komputera ENIAC (który nie miał zapisanego programu) ustalany był specjalnymi zworkami na panelu. Przeprogramowanie maszyny może zająć więcej niż jeden dzień (inne ustawienie zworek). I chociaż pisanie programów na nowoczesne komputery może zająć lata, działają one na milionach komputerów już po kilku minutach instalacji na dysku twardym.
Jak działa maszyna von Neumanna?
Maszyna von Neumanna składa się z urządzenia przechowującego (pamięci) - pamięci, jednostki arytmetyczno-logicznej - ALU, urządzenia sterującego - CU oraz urządzeń wejściowych i wyjściowych.
Programy i dane są wprowadzane do pamięci z urządzenia wejściowego za pośrednictwem jednostki arytmetyczno-logicznej. Wszystkie polecenia programu są zapisywane w sąsiednich komórkach pamięci, a dane do przetwarzania mogą być zawarte w dowolnych komórkach. W przypadku każdego programu ostatnie polecenie musi być poleceniem zamknięcia.
Polecenie składa się ze wskazania, jaką operację należy wykonać (z możliwych operacji na danym sprzęcie) oraz adresów komórek pamięci, na których przechowywane są dane, na których ma zostać wykonana określona operacja, a także adresu komórki gdzie należy zapisać wynik (jeśli ma zostać zapisany w pamięci).
Jednostka arytmetyczno-logiczna wykonuje operacje określone instrukcjami na określonych danych.
Z jednostki arytmetyczno-logicznej wyniki są przesyłane do pamięci lub urządzenia wyjściowego. Zasadnicza różnica między pamięcią a urządzeniem wyjściowym polega na tym, że w pamięci dane są przechowywane w formie dogodnej do przetwarzania przez komputer i przesyłane do urządzeń wyjściowych (drukarki, monitora itp.) w wygodny sposób dla osoby.
Jednostka sterująca steruje wszystkimi częściami komputera. Z urządzenia sterującego inne urządzenia otrzymują sygnały „co robić”, a z innych urządzeń jednostka sterująca otrzymuje informację o ich stanie.
Urządzenie sterujące zawiera specjalny rejestr (komórkę) zwany „licznikiem programu”. Po załadowaniu programu i danych do pamięci, do licznika programu zapisywany jest adres pierwszej instrukcji programu. Jednostka sterująca odczytuje z pamięci zawartość komórki pamięci, której adres znajduje się w liczniku programu, i umieszcza ją w specjalnym urządzeniu - „Rejestrze poleceń”. Jednostka sterująca określa wykonanie polecenia, „zaznacza” w pamięci dane, których adresy są podane w poleceniu, oraz kontroluje wykonanie polecenia. Operację wykonuje jednostka ALU lub sprzęt komputerowy.
W wyniku wykonania dowolnego polecenia licznik programu zmienia się o jeden i tym samym wskazuje kolejne polecenie programu. Gdy konieczne jest wykonanie polecenia, które nie jest następne po bieżącym, ale jest oddzielone od podanego określoną liczbą adresów, wówczas specjalne polecenie skoku zawiera adres komórki, do której należy przekazać sterowanie .
Zasady von Neumanna[edytuj | edytować tekst źródłowy]
Zasada jednorodności pamięci
Polecenia i dane są przechowywane w tej samej pamięci i są zewnętrznie nierozróżnialne w pamięci. Można je rozpoznać jedynie po sposobie użycia; oznacza to, że ta sama wartość w komórce pamięci może zostać użyta jako dane, jako polecenie i jako adres, w zależności tylko od sposobu dostępu do niej. Pozwala to wykonywać te same operacje na poleceniach, co na liczbach, i odpowiednio otwiera szereg możliwości. Tym samym zmieniając cyklicznie część adresową polecenia, możliwy jest dostęp do kolejnych elementów tablicy danych. Technika ta nazywana jest modyfikacją poleceń i nie jest zalecana z punktu widzenia współczesnego programowania. Bardziej użyteczna jest inna konsekwencja zasady jednorodności, gdy instrukcje z jednego programu można uzyskać w wyniku wykonania innego programu. Możliwość ta leży u podstaw tłumaczenia – tłumaczenia tekstu programu z języka wysokiego poziomu na język konkretnego komputera.
Zasada targetowania
Strukturalnie pamięć główna składa się z ponumerowanych komórek, a każda komórka jest dostępna dla procesora w dowolnym momencie. Kody binarne poleceń i danych są podzielone na jednostki informacji zwane słowami i przechowywane w komórkach pamięci, a do uzyskania dostępu do nich wykorzystywane są numery odpowiednich komórek - adresów.
Zasada sterowania programowego
Wszystkie obliczenia przewidziane przez algorytm rozwiązania problemu należy przedstawić w postaci programu składającego się z ciągu słów kontrolnych - poleceń. Każde polecenie zaleca jakąś operację z zestawu operacji realizowanych przez komputer. Polecenia programu przechowywane są w kolejnych komórkach pamięci komputera i wykonywane są w naturalnej kolejności, czyli według kolejności ich ułożenia w programie. W razie potrzeby za pomocą specjalnych poleceń można zmienić tę sekwencję. Decyzja o zmianie kolejności wykonywania poleceń programu podejmowana jest albo na podstawie analizy wyników poprzednich obliczeń, albo bezwarunkowo.
Zasada kodowania binarnego
Zgodnie z tą zasadą wszystkie informacje, zarówno dane, jak i polecenia, są kodowane cyframi binarnymi 0 i 1. Każdy rodzaj informacji jest reprezentowany przez ciąg binarny i ma swój własny format. Sekwencja bitów w formacie mającym określone znaczenie nazywana jest polem. W informacjach liczbowych zwykle występuje pole znaku i pole cyfr znaczących. W formacie polecenia można wyróżnić dwa pola: pole kodu operacji i pole adresów.
Kolejną prawdziwie rewolucyjną ideą, której znaczenie trudno przecenić, jest zaproponowana przez Neumanna zasada „programu zapisanego”. Początkowo program ustawiano instalując zworki na specjalnym panelu krosowym. Było to bardzo pracochłonne zadanie: np. zmiana programu maszyny ENIAC trwała kilka dni (podczas gdy same obliczenia nie mogły trwać dłużej niż kilka minut – zepsuły się lampy). Neumann jako pierwszy zdał sobie sprawę, że program można również przechowywać w postaci ciągu zer i jedynek w tej samej pamięci, w której znajdują się przetwarzane przez niego liczby. Brak zasadniczej różnicy między programem a danymi umożliwił komputerowi utworzenie dla siebie programu zgodnie z wynikami obliczeń.
Von Neumann nie tylko przedstawił podstawowe zasady logicznej struktury komputera, ale także zaproponował jego strukturę, która była powielana podczas pierwszych dwóch generacji komputerów. Główne bloki według Neumanna to jednostka sterująca (CU) i jednostka arytmetyczno-logiczna (ALU) (zwykle połączone w centralny procesor), pamięć, pamięć zewnętrzna, urządzenia wejściowe i wyjściowe. Schemat konstrukcyjny takiego komputera pokazano na ryc. 1. Należy zauważyć, że pamięć zewnętrzna różni się od urządzeń wejściowych i wyjściowych tym, że dane są do niej wprowadzane w formie dogodnej dla komputera, ale niedostępnej dla bezpośredniego postrzegania przez człowieka. Zatem napęd dysku magnetycznego odnosi się do pamięci zewnętrznej, a klawiatura jest urządzeniem wejściowym, wyświetlacz i drukowanie są urządzeniami wyjściowymi.

Ryż. 1. Architektura komputera zbudowana na zasadach von Neumanna. Linie ciągłe ze strzałkami wskazują kierunek przepływu informacji, linie przerywane wskazują sygnały sterujące z procesora do innych węzłów komputera
Urządzenie sterujące i jednostka arytmetyczno-logiczna we współczesnych komputerach są połączone w jedną jednostkę - procesor, który jest konwerterem informacji pochodzących z pamięci i urządzeń zewnętrznych (obejmuje to pobieranie instrukcji z pamięci, kodowanie i dekodowanie, wykonywanie różnych, w tym arytmetycznych , operacje, koordynacja pracy węzłów komputerowych). Funkcje procesora zostaną omówione bardziej szczegółowo poniżej.
Pamięć (pamięć) przechowuje informacje (dane) i programy. Urządzenie pamięci masowej we współczesnych komputerach jest „wielowarstwowe” i zawiera pamięć o dostępie swobodnym (RAM), w której przechowywane są informacje, z którymi komputer pracuje bezpośrednio w danym momencie (program wykonywalny, część niezbędnych do niego danych, część programy sterujące) i zewnętrzne urządzenia pamięci masowej (ESD).) o znacznie większej pojemności niż RAM. ale ze znacznie wolniejszym dostępem (i znacznie niższym kosztem w przeliczeniu na 1 bajt przechowywanej informacji). Klasyfikacja urządzeń pamięci nie kończy się na RAM i VRAM - pewne funkcje pełni zarówno SRAM (pamięć o dostępie superlosowym), ROM (pamięć tylko do odczytu), jak i inne podtypy pamięci komputerowej.
W komputerze zbudowanym według opisanego schematu instrukcje są sekwencyjnie odczytywane z pamięci i wykonywane. Numer (adres) następnej komórki pamięci. z którego zostanie pobrane kolejne polecenie programu, jest wskazywane przez specjalne urządzenie - licznik poleceń w centrali. Jej obecność jest także jedną z cech charakterystycznych omawianej architektury.
Podstawy architektury urządzeń obliczeniowych opracowane przez von Neumanna okazały się na tyle fundamentalne, że w literaturze otrzymały nazwę „architektura von Neumanna”. Zdecydowana większość współczesnych komputerów to maszyny von Neumanna. Jedynymi wyjątkami są niektóre typy systemów obliczeń równoległych, w których nie ma licznika programu, nie jest realizowana klasyczna koncepcja zmiennej i istnieją inne istotne zasadnicze różnice w stosunku do modelu klasycznego (przykładami są komputery strumieniowe i redukcyjne).
Najwyraźniej znaczne odejście od architektury von Neumanna nastąpi w wyniku rozwoju idei maszyn piątej generacji, w których przetwarzanie informacji opiera się nie na obliczeniach, ale na logicznych wnioskach
 .
.
Pierwszą maszyną dodającą zdolną do wykonywania czterech podstawowych operacji arytmetycznych była maszyna dodająca słynnego francuskiego naukowca i filozofa Blaise'a Pascala. Głównym jego elementem było koło zębate, którego wynalezienie samo w sobie stało się kluczowym wydarzeniem w historii technologii komputerowej. Chciałbym zauważyć, że ewolucja w dziedzinie technologii komputerowej jest nierówna, spazmatyczna: okresy gromadzenia sił ustępują przełomom rozwojowym, po których rozpoczyna się okres stabilizacji, podczas którego osiągnięte wyniki wykorzystywane są praktycznie i na w tym samym czasie gromadzona jest wiedza i siła, aby móc wykonać kolejny krok naprzód. Po każdej rewolucji proces ewolucji osiąga nowy, wyższy poziom.
W 1671 roku niemiecki filozof i matematyk Gustav Leibniz stworzył także maszynę sumującą opartą na kole zębatym o specjalnej konstrukcji - kole zębatym Leibniza. Maszyna dodająca Leibniza, podobnie jak maszyny dodające jego poprzedników, wykonywała cztery podstawowe operacje arytmetyczne. Okres ten dobiegł końca, a ludzkość przez prawie półtora wieku gromadziła siły i wiedzę niezbędną do następnej rundy ewolucji technologii komputerowej. Wiek XVIII i XIX to czas szybkiego rozwoju różnych nauk, w tym matematyki i astronomii. Często wiązały się z zadaniami wymagającymi czasochłonnych i pracochłonnych obliczeń.
Kolejną znaną osobą w historii informatyki był angielski matematyk Charles Babbage. W 1823 roku Babbage rozpoczął pracę nad maszyną do obliczania wielomianów, ale co ciekawsze, maszyna ta oprócz bezpośredniego wykonywania obliczeń miała generować wyniki - drukować je na kliszy negatywowej w celu drukowania fotograficznego. Planowano, że maszyna będzie napędzana silnikiem parowym. Z powodu problemów technicznych Babbage nie był w stanie ukończyć swojego projektu. Tutaj po raz pierwszy zrodził się pomysł wykorzystania zewnętrznego (peryferyjnego) urządzenia do wyprowadzania wyników obliczeń. Należy zauważyć, że inny naukowiec, Scheutz, mimo to wdrożył maszynę wymyśloną przez Babbage'a w 1853 roku (okazała się ona jeszcze mniejsza niż planowano). Babbage’owi chyba bardziej podobał się proces twórczy, poszukiwanie nowych pomysłów, niż przekładanie ich na coś materialnego. W 1834 roku nakreślił zasadę działania kolejnej maszyny, którą nazwał „analityczną”. Trudności techniczne ponownie uniemożliwiły mu pełną realizację swoich pomysłów. Babbage był w stanie jedynie doprowadzić maszynę do etapu eksperymentalnego. Ale to idea jest motorem postępu naukowego i technologicznego. Kolejna maszyna Charlesa Babbage'a była ucieleśnieniem następujących pomysłów:
Zarządzanie procesem produkcyjnym. Maszyna sterowała pracą krosna, zmieniając wzór tworzonej tkaniny w zależności od układu otworów na specjalnej taśmie papierowej. Taśma ta stała się poprzedniczką takich nośników informacji, które są nam wszystkim znane jako karty dziurkowane i taśmy dziurkowane.
Programowalność. Maszyną sterowano także za pomocą specjalnej papierowej taśmy z otworami. Kolejność znajdujących się na nim otworów determinowała polecenia i dane przetwarzane przez te polecenia. Maszyna posiadała urządzenie arytmetyczne i pamięć. Polecenia maszyny zawierały nawet polecenie skoku warunkowego, które zmieniało przebieg obliczeń w zależności od wyników pośrednich.
W rozwoju tej maszyny brała udział hrabina Ada Augusta Lovelace, uważana za pierwszą programistkę na świecie.
Pomysły Charlesa Babbage'a zostały rozwinięte i wykorzystane przez innych naukowców. I tak w 1890 roku, na przełomie XIX i XX wieku, Amerykanin Herman Hollerith opracował maszynę współpracującą z tabelami danych (pierwszy Excel?). Maszyna sterowana była programem na kartach perforowanych. Został użyty w spisie powszechnym Stanów Zjednoczonych w 1890 roku. W 1896 roku Hollerith założył firmę, która była poprzedniczką IBM Corporation. Wraz ze śmiercią Babbage'a nastąpił kolejny przełom w ewolucji technologii komputerowej aż do lat 30. XX wieku. Następnie cały rozwój ludzkości stał się nie do pomyślenia bez komputerów.
W 1938 roku centrum rozwoju na krótko przeniosło się z Ameryki do Niemiec, gdzie Konrad Zuse stworzył maszynę, która w odróżnieniu od swoich poprzedników operowała nie liczbami dziesiętnymi, a binarnymi. Maszyna ta również była nadal mechaniczna, jednak jej niewątpliwą zaletą było to, że realizowała ideę przetwarzania danych w kodzie binarnym. Kontynuując swoją pracę, Zuse w 1941 roku stworzył maszynę elektromechaniczną, której urządzenie arytmetyczne opierało się na przekaźniku. Maszyna może wykonywać operacje zmiennoprzecinkowe.
Za granicą, w Ameryce, w tym okresie trwały także prace nad stworzeniem podobnych maszyn elektromechanicznych. W 1944 roku Howard Aiken zaprojektował maszynę o nazwie Mark-1. Ona, podobnie jak maszyna Zuse, pracowała na przekaźniku. Ponieważ jednak maszyna ta najwyraźniej powstała pod wpływem pracy Babbage'a, operowała danymi w postaci dziesiętnej.
Naturalnie, ze względu na duży udział części mechanicznych, maszyny te były skazane na zagładę.
Cztery generacje komputerów
Pod koniec lat trzydziestych XX wieku znacznie wzrosła potrzeba automatyzacji złożonych procesów obliczeniowych. Umożliwił to szybki rozwój takich gałęzi przemysłu, jak produkcja samolotów, fizyka jądrowa i inne. Od 1945 roku do dnia dzisiejszego technologia komputerowa przeszła w swoim rozwoju 4 pokolenia:
Pierwsza generacja
Pierwsza generacja (1945-1954) - komputery lampowe. To czasy prehistoryczne, era pojawienia się technologii komputerowej. Większość maszyn pierwszej generacji była urządzeniami eksperymentalnymi i została zbudowana w celu przetestowania pewnych zasad teoretycznych. Waga i rozmiar tych komputerowych dinozaurów, które często wymagały dla siebie osobnych budynków, od dawna stały się legendą.
Począwszy od 1943 roku grupa specjalistów pod przewodnictwem Howarda Aitkena, J. Mauchly'ego i P. Eckerta w USA zaczęła projektować komputer oparty na lampach próżniowych, a nie na przekaźnikach elektromagnetycznych. Maszyna ta nazywała się ENIAC (Electronic Numeral Integrator And Computer) i działała tysiąc razy szybciej niż Mark-1. ENIAC zawierał 18 tysięcy lamp próżniowych, zajmował powierzchnię 9 x 15 metrów, ważył 30 ton i zużywał moc 150 kilowatów. ENIAC miał też istotną wadę – sterowano go za pomocą patch panelu, nie miał pamięci, a aby ustawić program, odpowiednie podłączenie przewodów zajmowało kilka godzin, a nawet dni. Najgorszą ze wszystkich wad była straszliwa zawodność komputera, ponieważ w ciągu jednego dnia pracy kilkanaście lamp próżniowych uległo awarii.
Aby uprościć proces ustawiania programów, Mauchly i Eckert zaczęli projektować nową maszynę, która mogłaby przechowywać program w swojej pamięci. W 1945 roku w prace zaangażował się słynny matematyk John von Neumann, który przygotował raport na temat tej maszyny. W raporcie tym von Neumann jasno i prosto sformułował ogólne zasady funkcjonowania uniwersalnych urządzeń obliczeniowych, tj. komputery. Była to pierwsza sprawna maszyna zbudowana na lampach próżniowych i została oficjalnie oddana do użytku 15 lutego 1946 roku. Próbowali wykorzystać tę maszynę do rozwiązania niektórych problemów przygotowanych przez von Neumanna i związanych z projektem bomby atomowej. Następnie przewieziono ją na poligon w Aberdeen, gdzie działała do 1955 roku.
ENIAC stał się pierwszym przedstawicielem komputerów I generacji. Każda klasyfikacja jest warunkowa, ale większość ekspertów zgodziła się, że pokolenia należy rozróżniać na podstawie elementarnej podstawy, na której zbudowane są maszyny. Zatem pierwsza generacja wydaje się być maszynami lampowymi.
Należy zwrócić uwagę na ogromną rolę amerykańskiego matematyka von Neumanna w rozwoju technologii pierwszej generacji. Konieczne było zrozumienie mocnych i słabych stron ENIAC i przedstawienie zaleceń dotyczących dalszego rozwoju. Raport von Neumanna i jego współpracowników G. Goldsteina i A. Burksa (czerwiec 1946) jasno sformułował wymagania dotyczące konstrukcji komputerów. Wiele postanowień tego raportu nazwano zasadami von Neumanna.
Pierwsze projekty komputerów domowych zaproponowała firma S.A. Lebiediew, B.I. Ramejew w 1948 r W latach 1949-51. według projektu S.A. Lebedev, MESM (mała elektroniczna maszyna licząca) została zbudowana. Pierwsze próbne uruchomienie prototypu maszyny odbyło się w listopadzie 1950 r., a maszynę wprowadzono do eksploatacji w 1951 r. MESM pracował w systemie binarnym, z trójadresowym systemem dowodzenia, a program obliczeniowy przechowywany był w operacyjnym urządzeniu pamięci masowej. Całkowicie nowym rozwiązaniem była maszyna Lebiediewa z równoległym przetwarzaniem tekstu. Był to jeden z pierwszych komputerów na świecie i pierwszy na kontynencie europejskim z zapisanym programem.
W skład komputera I generacji wchodzi także BESM-1 (duża elektroniczna maszyna licząca), którego rozwój pod kierownictwem S.A. Lebiediewa została ukończona w 1952 r., zawierała 5 tysięcy lamp, pracowała bezawaryjnie przez 10 godzin. Wydajność osiągnęła 10 tysięcy operacji na sekundę (Załącznik 1).
Niemal jednocześnie zaprojektowano komputer Strela (załącznik 2) pod kierownictwem Yu.Ya. Bazilewskiego w 1953 r. został wprowadzony do produkcji. Później pojawił się komputer Ural - 1 (załącznik 3), który zapoczątkował dużą serię maszyn Ural, opracowanych i wprowadzonych do produkcji pod kierownictwem B.I. Rameeva. W 1958 r Do produkcji seryjnej wprowadzono komputer pierwszej generacji M-20 (prędkość do 20 tys. operacji/s).
Komputery pierwszej generacji osiągały prędkość kilkudziesięciu tysięcy operacji na sekundę. Jako pamięć wewnętrzną zastosowano rdzenie ferrytowe, a jednostki ALU i jednostki sterujące zbudowano na lampach elektronicznych. Szybkość komputera była determinowana przez wolniejszy element – pamięć wewnętrzną – co zmniejszało ogólny efekt.
Komputery pierwszej generacji były nastawione na wykonywanie operacji arytmetycznych. Próbując dostosować je do zadań analitycznych, okazały się nieskuteczne.
Nie było jeszcze języków programowania jako takich, a programiści do kodowania swoich algorytmów używali instrukcji maszynowych lub asemblerów. To skomplikowało i opóźniło proces programowania.
Pod koniec lat 50. narzędzia programistyczne ulegały zasadniczym zmianom: dokonano przejścia na automatyzację programowania z wykorzystaniem uniwersalnych języków i bibliotek standardowych programów. Stosowanie języków uniwersalnych doprowadziło do pojawienia się tłumaczy.
Programy były realizowane zadanie po zadaniu, tj. operator musiał monitorować postęp zadania i po osiągnięciu jego końca inicjować kolejne zadanie.
Drugie pokolenie
W drugiej generacji komputerów (1955-1964) zamiast lamp próżniowych zaczęto stosować tranzystory, a jako urządzenia pamięci zaczęto stosować rdzenie magnetyczne i bębny magnetyczne, odległych przodków współczesnych dysków twardych. Wszystko to pozwoliło znacznie zmniejszyć rozmiar i koszt komputerów, które następnie zaczęto po raz pierwszy budować na sprzedaż.
Ale główne osiągnięcia tej epoki należą do dziedziny programów. W drugiej generacji komputerów po raz pierwszy pojawił się tak zwany system operacyjny. W tym samym czasie powstały pierwsze języki wysokiego poziomu - Fortran, Algol, Cobol. Te dwa ważne ulepszenia znacznie ułatwiły i przyspieszyły pisanie programów komputerowych; Programowanie, pozostając nauką, nabiera cech rzemiosła.
W związku z tym rozszerzył się zakres zastosowań komputerowych. Teraz na dostęp do technologii obliczeniowej mogli już liczyć nie tylko naukowcy; komputery były używane w planowaniu i zarządzaniu, a niektóre duże firmy nawet skomputeryzowały swoją księgowość, wyprzedzając modę o dwadzieścia lat.
Półprzewodniki stały się podstawą elementarną drugiej generacji. Bez wątpienia tranzystory można uznać za jeden z najbardziej imponujących cudów XX wieku.
Patent na odkrycie tranzystora został wydany w 1948 roku Amerykanom D. Bardeenowi i W. Brattainowi, a osiem lat później wraz z teoretykiem V. Shockleyem zostali laureatami Nagrody Nobla. Prędkości przełączania pierwszych elementów tranzystorowych okazały się setki razy wyższe niż elementy lampowe, a także niezawodność i wydajność. Po raz pierwszy zaczęto powszechnie stosować pamięć na rdzeniach ferrytowych i cienkich warstwach magnetycznych oraz testowano elementy indukcyjne – parametry.
Pierwszy komputer pokładowy do montażu na rakiecie międzykontynentalnej Atlas został oddany do użytku w Stanach Zjednoczonych w 1955 roku. Maszyna wykorzystywała 20 tysięcy tranzystorów i diod, zużywała 4 kW.W 1961 r. naziemne komputery rozciągające Barrows kontrolowały loty kosmiczne rakiet Atlas, a maszyny IBM kontrolowały lot astronauty Gordona Coopera. Komputer sterował lotami bezzałogowego statku kosmicznego typu Ranger na Księżyc w 1964 roku, a także statku kosmicznego Mariner na Marsa. Podobne funkcje spełniały komputery radzieckie.
W 1956 roku IBM opracował pływające głowice magnetyczne na poduszce powietrznej. Ich wynalazek umożliwił stworzenie nowego typu pamięci – dyskowych urządzeń magazynujących, których znaczenie zostało w pełni docenione w kolejnych dekadach rozwoju techniki komputerowej. Pierwsze urządzenia dyskowe pojawiły się w maszynach IBM-305 i RAMAC (załącznik 4). Ten ostatni miał pakiet składający się z 50 metalowych dysków powlekanych magnetycznie, które obracały się z prędkością 12 000 obr./min. Na powierzchni dysku znajdowało się 100 ścieżek do zapisu danych, każda zawierająca 10 000 znaków.
Pierwsze masowo produkowane komputery typu mainframe z tranzystorami zostały wypuszczone na rynek w 1958 roku jednocześnie w USA, Niemczech i Japonii.
Pojawiają się pierwsze minikomputery (na przykład PDP-8 (załącznik 5)).
W Związku Radzieckim pierwsze maszyny bezlampowe „Setun”, „Razdan” i „Razdan-2” powstały w latach 1959–1961. W latach 60. radzieccy projektanci opracowali około 30 modeli komputerów tranzystorowych, z których większość zaczęła być produkowana masowo. Najpotężniejszy z nich, Mińsk-32, wykonywał 65 tysięcy operacji na sekundę. Pojawiły się całe rodziny pojazdów: „Ural”, „Mińsk”, BESM.
Rekordzistą wśród komputerów drugiej generacji był BESM-6 (Załącznik 6), który osiągał prędkość około miliona operacji na sekundę - jedną z najbardziej produktywnych na świecie. Architektura i wiele rozwiązań technicznych w tym komputerze było na tyle postępowych i wyprzedzających swoje czasy, że był on z powodzeniem stosowany niemal do naszych czasów.
Specjalnie dla automatyzacji obliczeń inżynierskich w Instytucie Cybernetyki Akademii Nauk Ukraińskiej SRR pod kierownictwem akademika V.M. Głuszkow opracował komputery MIR (1966) i MIR-2 (1969). Istotną cechą maszyny MIR-2 było zastosowanie ekranu telewizyjnego do wizualnej kontroli informacji oraz pióra świetlnego, za pomocą którego można było korygować dane bezpośrednio na ekranie.
Budowa takich układów, składających się z około 100 tysięcy elementów łączeniowych, w oparciu o technologię lampową byłaby po prostu niemożliwa. W ten sposób drugie pokolenie narodziło się w głębi pierwszego, przejmując wiele jego cech. Jednak w połowie lat 60. boom w dziedzinie produkcji tranzystorów osiągnął swoje maksimum - nastąpiło nasycenie rynku. Faktem jest, że montaż sprzętu elektronicznego był procesem bardzo pracochłonnym i powolnym, który nie nadawał się dobrze do mechanizacji i automatyzacji. Stworzono zatem warunki do przejścia na nową technologię, która uwzględniałaby rosnącą złożoność obwodów poprzez eliminację tradycyjnych połączeń pomiędzy ich elementami.
Trzecia generacja
Wreszcie w trzeciej generacji komputerów (1965-1974) zaczęto po raz pierwszy stosować układy scalone - całe urządzenia i zespoły dziesiątek i setek tranzystorów, wykonane na pojedynczym krysztale półprzewodnikowym (co obecnie nazywa się mikroukładami). W tym samym czasie pojawiła się pamięć półprzewodnikowa, która do dziś jest używana w komputerach osobistych jako pamięć RAM przez cały dzień. Pierwszeństwo w wynalezieniu układów scalonych, które stały się podstawową podstawą komputerów trzeciej generacji, mają amerykańscy naukowcy D. Kilby i R. Noyce, którzy dokonali tego odkrycia niezależnie od siebie. Masową produkcję układów scalonych rozpoczęto w 1962 r., a w 1964 r. zaczęło szybko następować przejście od elementów dyskretnych do scalonych. Wspomniany ENIAK o wymiarach 9x15 metrów w 1971 roku mógł być zmontowany na płycie o powierzchni 1,5 centymetra kwadratowego. Rozpoczęła się transformacja elektroniki w mikroelektronikę.
W ciągu tych lat produkcja komputerów nabrała skali przemysłowej. IBM, który stał się liderem, jako pierwszy wdrożył rodzinę komputerów - serię komputerów w pełni ze sobą kompatybilnych, od najmniejszego, wielkości małej szafy (nigdy wcześniej nie robili niczego mniejszego), do najmocniejszych i najdroższych modeli. Najbardziej rozpowszechnioną w tamtych latach była rodzina System/360 firmy IBM, na bazie której w ZSRR opracowano serię komputerów ES. W 1973 roku wypuszczono pierwszy model komputera z serii ES, a od 1975 roku pojawiły się modele ES-1012, ES-1032, ES-1033, ES-1022, a później mocniejszy ES-1060.
W ramach trzeciej generacji zbudowano w USA unikalną maszynę „ILLIAK-4”, która w pierwotnej wersji planowała wykorzystywać 256 urządzeń do przetwarzania danych wykonanych na monolitycznych układach scalonych. Projekt został później zmieniony ze względu na dość wysoki koszt (ponad 16 milionów dolarów). Należało zmniejszyć liczbę procesorów do 64, a także przejść na układy scalone o niskim stopniu integracji. Skrócona wersja projektu została ukończona w 1972 roku; nominalna wydajność ILLIAC-4 wynosiła 200 milionów operacji na sekundę. Przez prawie rok komputer ten był rekordzistą pod względem szybkości obliczeń.
Już na początku lat 60. pojawiły się pierwsze minikomputery – małe komputery o niskim poborze mocy, dostępne dla małych firm lub laboratoriów. Minikomputery stanowiły pierwszy krok w kierunku komputerów osobistych, których prototypy wypuszczono dopiero w połowie lat 70-tych. Prototypem radzieckiej serii maszyn SM była znana rodzina minikomputerów PDP firmy Digital Equipment.
Tymczasem liczba elementów i połączeń między nimi mieszczących się w jednym mikroukładzie stale rosła, a w latach 70. układy scalone zawierały już tysiące tranzystorów. Umożliwiło to połączenie większości podzespołów komputera w jedną małą część - tak właśnie uczynił Intel w 1971 roku, wypuszczając pierwszy mikroprocesor, który był przeznaczony do dopiero co pojawiających się kalkulatorów stacjonarnych. Wynalazek ten miał w najbliższej dekadzie wywołać prawdziwą rewolucję – w końcu mikroprocesor jest sercem i duszą naszego komputera osobistego.
Ale to nie wszystko – przełom lat 60. i 70. to naprawdę fatalny czas. W 1969 roku narodziła się pierwsza globalna sieć komputerowa – zalążek tego, co obecnie nazywamy Internetem. W tym samym roku 1969 pojawił się jednocześnie system operacyjny Unix i język programowania C, co wywarło ogromny wpływ na świat oprogramowania i nadal utrzymuje wiodącą pozycję.
Czwarta generacja
Kolejna zmiana w bazie elementów doprowadziła do zmiany pokoleń. W latach 70. aktywnie trwały prace nad stworzeniem dużych i bardzo dużych układów scalonych (LSI i VLSI), które umożliwiały umieszczenie dziesiątek tysięcy elementów na jednym chipie. Spowodowało to dalsze znaczne zmniejszenie rozmiaru i kosztu komputerów. Praca z oprogramowaniem stała się bardziej przyjazna dla użytkownika, co przełożyło się na wzrost liczby użytkowników.
W zasadzie przy takim stopniu integracji elementów możliwa stała się próba stworzenia funkcjonalnie kompletnego komputera na jednym chipie. Podejmowano odpowiednie próby, choć przeważnie spotykały się one z niedowierzającym uśmiechem. Prawdopodobnie byłoby mniej tych uśmiechów, gdyby można było przewidzieć, że to właśnie ten pomysł spowoduje wyginięcie komputerów typu mainframe w ciągu zaledwie półtorej dekady.
Jednak na początku lat 70. Intel wypuścił mikroprocesor (MP) 4004. I jeśli wcześniej w świecie komputerów istniały tylko trzy kierunki (superkomputery, komputery typu mainframe i minikomputery), teraz dodano do nich kolejny - mikroprocesor. Ogólnie rzecz biorąc, przez procesor rozumie się jednostkę funkcjonalną komputera, przeznaczoną do logicznego i arytmetycznego przetwarzania informacji w oparciu o zasadę sterowania mikroprogramem. Ze względu na implementację sprzętową procesory można podzielić na mikroprocesory (wszystkie funkcje procesora są w pełni zintegrowane) oraz procesory o niskiej i średniej integracji. Strukturalnie wyraża się to tym, że mikroprocesory realizują wszystkie funkcje procesora w jednym chipie, podczas gdy inne typy procesorów realizują je poprzez połączenie dużej liczby chipów.
Tak więc pierwszy mikroprocesor 4004 został stworzony przez firmę Intel na przełomie lat 70-tych. Było to 4-bitowe urządzenie do obliczeń równoległych, a jego możliwości były poważnie ograniczone. Licznik 4004 mógł wykonywać cztery podstawowe operacje arytmetyczne i początkowo był używany tylko w kalkulatorach kieszonkowych. Później zakres jego zastosowania został rozszerzony o zastosowanie w różnych układach sterowania (np. do sterowania sygnalizacją świetlną). Intel, trafnie przewidział obietnicę mikroprocesorów, kontynuował intensywny rozwój, a jeden z jego projektów ostatecznie doprowadził do dużego sukcesu, który z góry wyznaczył przyszłą ścieżkę rozwoju technologii komputerowej.
Był to projekt opracowania 8-bitowego procesora 8080 (1974). Ten mikroprocesor miał dość rozwinięty system poleceń i był w stanie dzielić liczby. Wykorzystano go do stworzenia komputera osobistego Altair, dla którego młody Bill Gates napisał jeden ze swoich pierwszych interpreterów języka BASIC. Prawdopodobnie od tego momentu należy liczyć piątą generację.
Piąte pokolenie
Przejście na komputery piątej generacji oznaczało przejście na nowe architektury mające na celu tworzenie sztucznej inteligencji.
Uważano, że architektura komputerów piątej generacji będzie składać się z dwóch głównych bloków. Jednym z nich jest sam komputer, w którym komunikację z użytkownikiem realizuje jednostka zwana „inteligentnym interfejsem”. Zadaniem interfejsu jest zrozumienie tekstu napisanego w języku naturalnym lub mowie i przetłumaczenie tak sformułowanego problemu na działający program.
Podstawowe wymagania dla komputerów 5. generacji: Stworzenie rozwiniętego interfejsu człowiek-maszyna (rozpoznawanie mowy, rozpoznawanie obrazu); Rozwój programowania logicznego do tworzenia baz wiedzy i systemów sztucznej inteligencji; Tworzenie nowych technologii w produkcji sprzętu komputerowego; Tworzenie nowych architektur komputerowych i systemów obliczeniowych.
Nowe możliwości techniczne techniki komputerowej powinny poszerzyć zakres zadań do rozwiązania i umożliwić przejście do zadań tworzenia sztucznej inteligencji. Jednym z elementów niezbędnych do tworzenia sztucznej inteligencji są bazy wiedzy (bazy danych) z różnych dziedzin nauki i techniki. Tworzenie i używanie baz danych wymaga szybkich systemów obliczeniowych i dużej ilości pamięci. Komputery ogólnego przeznaczenia są w stanie wykonywać obliczenia z dużą szybkością, ale nie nadają się do wykonywania szybkich operacji porównywania i sortowania dużych ilości danych, zwykle przechowywanych na dyskach magnetycznych. Do tworzenia programów wypełniających, aktualizujących i pracujących z bazami danych stworzono specjalne obiektowe i logiczne języki programowania, które zapewniają największe możliwości w porównaniu z konwencjonalnymi językami proceduralnymi. Struktura tych języków wymaga przejścia od tradycyjnej architektury komputerów von Neumanna do architektur uwzględniających wymagania zadań tworzenia sztucznej inteligencji.
Do klasy superkomputerów zalicza się komputery, które w momencie wypuszczenia na rynek posiadają maksymalną wydajność, czyli tzw. komputery 5. generacji.
Pierwsze superkomputery pojawiły się już wśród komputerów drugiej generacji (1955 - 1964, patrz: komputery drugiej generacji) i miały za zadanie rozwiązywać złożone problemy wymagające dużych szybkości obliczeń. Są to LARC firmy UNIVAC, Stretch firmy IBM oraz CDC-6600 (rodzina CYBER) firmy Control Data Corporation, wykorzystywały metody przetwarzania równoległego (zwiększające liczbę operacji wykonywanych w jednostce czasu), potokowanie poleceń (gdy podczas wykonywania jednego polecenia drugi jest odczytywany z pamięci i przygotowywany do wykonania) oraz przetwarzanie równoległe z wykorzystaniem złożonej struktury procesorowej składającej się z matrycy procesorów danych i specjalnego procesora sterującego, który rozdziela zadania i kontroluje przepływ danych w systemie. Komputery, na których równolegle uruchamia się wiele programów przy użyciu wielu mikroprocesorów, nazywane są systemami wieloprocesorowymi. Do połowy lat 80. na liście największych producentów superkomputerów na świecie znajdowały się Sperry Univac i Burroughs. Pierwsza znana jest w szczególności ze swoich komputerów mainframe UNIVAC-1108 i UNIVAC-1110, które były szeroko stosowane na uniwersytetach i organizacjach rządowych.
Po połączeniu Sperry Univac i Burroughs, połączona spółka UNISYS w dalszym ciągu obsługiwała obie linie komputerów mainframe, zachowując jednocześnie kompatybilność ze starszymi wersjami każdej z nich. Jest to wyraźne wskazanie niezmiennej zasady, która przyświecała rozwojowi komputerów mainframe – zachowania funkcjonalności wcześniej opracowanego oprogramowania.
Intel jest również znany w świecie superkomputerów. Równie klasyczne stały się komputery wieloprocesorowe Intel Paragon z rodziny struktur wieloprocesorowych z pamięcią rozproszoną.
Zasady von Neumanna
W 1946 roku D. von Neumann, G. Goldstein i A. Berks we wspólnym artykule przedstawili nowe zasady budowy i działania komputerów. Następnie w oparciu o te zasady wyprodukowano pierwsze dwie generacje komputerów. W późniejszych pokoleniach nastąpiły pewne zmiany, chociaż zasady Neumanna są nadal aktualne. W rzeczywistości Neumannowi udało się podsumować rozwój naukowy i odkrycia wielu innych naukowców i sformułować na ich podstawie zasadniczo nowe zasady:
1. Zasada przedstawiania i przechowywania liczb.
System liczb binarnych służy do przedstawiania i przechowywania liczb. Przewaga nad systemem liczb dziesiętnych polega na tym, że bit jest łatwy do wdrożenia, duża pamięć bitowa jest dość tania, urządzenia można tworzyć dość prosto, a operacje arytmetyczne i logiczne w systemie liczb binarnych są również wykonywane w dość prosty sposób.
2. Zasada sterowania programem komputerowym.
Pracą komputera steruje program składający się z zestawu poleceń. Polecenia wykonywane są sekwencyjnie, jedno po drugim. Polecenia przetwarzają dane zapisane w pamięci komputera.
3. Zasada programu zapisanego w pamięci.
Pamięć komputera służy nie tylko do przechowywania danych, ale także programów. W tym przypadku zarówno polecenia programu, jak i dane kodowane są w systemie liczb binarnych, tj. ich metoda nagrywania jest taka sama. Dlatego w niektórych sytuacjach możesz wykonywać te same czynności na poleceniach, co na danych.
4. Zasada bezpośredniego dostępu do pamięci.
Komórki RAM komputera mają adresy ponumerowane sekwencyjnie. W dowolnym momencie możesz uzyskać dostęp do dowolnej komórki pamięci po jej adresie.
5. Zasada obliczeń rozgałęzionych i cyklicznych.
Polecenia skoku warunkowego umożliwiają realizację przejścia do dowolnej sekcji kodu, zapewniając w ten sposób możliwość organizowania rozgałęzień i ponownego wykonywania określonych sekcji programu.
Najważniejszą konsekwencją tych zasad jest to, że teraz program nie jest już stałą częścią maszyny (jak na przykład kalkulator). Możliwość łatwej zmiany programu stała się możliwa. Ale sprzęt oczywiście pozostaje niezmieniony i bardzo prosty. Dla porównania program komputera ENIAC (który nie miał zapisanego programu) ustalany był specjalnymi zworkami na panelu. Przeprogramowanie maszyny może zająć więcej niż jeden dzień (inne ustawienie zworek).
I chociaż tworzenie programów na nowoczesne komputery może zająć miesiące, ich instalacja (instalacja na komputerze) zajmuje kilka minut, nawet w przypadku dużych programów. Taki program można zainstalować na milionach komputerów i działać na każdym z nich latami.
Aplikacje
Aneks 1

Załącznik 2

Komputer „Ural”
Dodatek 3

Komputer „Strela”
Dodatek 4

IBM-305 i RAMAC
Dodatek 5

minikomputer PDP-8
Załącznik 6

Literatura:
1) Broido V.L. Systemy komputerowe, sieci i telekomunikacja. Podręcznik dla uniwersytetów. wydanie 2. – Petersburg: Piotr, 2004
2) Zhmakin A.P. Architektura komputerowa. – Petersburg: BHV – Petersburg, 2006
3) Semenenko V.A. i inne Komputery elektroniczne. Podręcznik dla szkół zawodowych - M.: Szkoła Wyższa, 1991
Konstrukcja zdecydowanej większości komputerów opiera się na następujących ogólnych zasadach sformułowanych w 1945 roku przez amerykańskiego naukowca Johna von Neumanna (rysunek 8.5). Zasady te zostały po raz pierwszy opublikowane w jego propozycjach dotyczących maszyny EDVAC. Komputer ten był jedną z pierwszych maszyn z zapisanym programem, tj. z programem zapisanym w pamięci urządzenia, a nie z karty dziurkowanej lub innego podobnego urządzenia.
Rysunek 9.5 – John von Neumann, 1945
1. Zasada sterowania programowego . Wynika z tego, że program składa się ze zbioru poleceń, które procesor wykonuje automatycznie, jedna po drugiej, w określonej kolejności.
Program jest pobierany z pamięci za pomocą licznika programu. Rejestr ten procesora sekwencyjnie zwiększa adres kolejnej zapisanej w nim instrukcji o długość instrukcji.
A ponieważ polecenia programu są umieszczane w pamięci jedno po drugim, łańcuch poleceń jest w ten sposób zorganizowany z kolejno rozmieszczonych komórek pamięci.
Jeżeli po wykonaniu polecenia konieczne jest przejście nie do następnej, lecz do innej komórki pamięci, stosuje się polecenia skoku warunkowego lub bezwarunkowego, które wpisują do licznika poleceń numer komórki pamięci zawierającej kolejne polecenie. Pobieranie poleceń z pamięci zatrzymuje się po dotarciu i wykonaniu polecenia „stop”.
W ten sposób procesor wykonuje program automatycznie, bez interwencji człowieka.
Według Johna von Neumanna komputer powinien składać się z centralnej jednostki arytmetyczno-logicznej, centralnej jednostki sterującej, urządzenia przechowującego oraz urządzenia wejścia/wyjścia informacji. Jego zdaniem komputer powinien pracować z liczbami binarnymi i być elektroniczny (nie elektryczny); wykonywać operacje po kolei.
Wszystkie obliczenia wymagane przez algorytm rozwiązania problemu należy przedstawić w postaci programu składającego się z ciągu słów kontrolnych-poleceń. Każde polecenie zawiera instrukcje dotyczące konkretnej wykonywanej operacji, lokalizacji (adresów) operandów i szeregu cech usługi. Operandy to zmienne, których wartości biorą udział w operacjach transformacji danych. Lista (tablica) wszystkich zmiennych (danych wejściowych, wartości pośrednich i wyników obliczeń) to kolejny integralny element każdego programu.
Aby uzyskać dostęp do programów, instrukcji i operandów, używane są ich adresy. Adresy to numery komórek pamięci komputera przeznaczonych do przechowywania obiektów. Informacje (polecenie i dane: numeryczne, tekstowe, graficzne itp.) kodowane są cyframi binarnymi 0 i 1.
Dlatego też różnego rodzaju informacje znajdujące się w pamięci komputera są praktycznie nierozróżnialne, a ich identyfikacja możliwa jest jedynie wtedy, gdy program jest wykonywany zgodnie z jego logiką, w kontekście.
2. Zasada jednorodności pamięci . Programy i dane są przechowywane w tej samej pamięci. Dlatego komputer nie rozróżnia tego, co zapisane jest w danej komórce pamięci – liczby, tekstu czy polecenia. Na poleceniach można wykonywać te same czynności, co na danych. Otwiera to całą gamę możliwości. Przykładowo program może być przetwarzany również w trakcie jego wykonywania, co umożliwia ustalenie zasad uzyskiwania niektórych jego części w samym programie (tak zorganizowane jest w programie wykonywanie cykli i podprogramów). Ponadto polecenia z jednego programu można uzyskać w wyniku wykonania innego programu. Metody tłumaczenia opierają się na tej zasadzie - tłumaczeniu tekstu programu z języka programowania wysokiego poziomu na język konkretnej maszyny.
3. Zasada targetowania . Strukturalnie pamięć główna składa się z komórek o zmienionych numerach; Dowolna komórka jest dostępna dla procesora w dowolnym momencie. Oznacza to możliwość nazwania obszarów pamięci, aby można było później uzyskać dostęp do przechowywanych w nich wartości lub je zmienić podczas wykonywania programu przy użyciu przypisanych im nazw.
Zasady von Neumanna można zastosować w praktyce na wiele różnych sposobów. Tutaj prezentujemy dwa z nich: komputer z magistralą oraz organizację kanałów. Zanim opiszemy zasady działania komputera, wprowadzimy kilka definicji.
Architektura komputerowa nazywa się na pewnym ogólnym poziomie jego opisem, obejmującym opis możliwości programowania użytkownika, systemów dowodzenia, systemów adresowania, organizacji pamięci itp. Architektura określa zasady działania, połączenia informacyjne i wzajemne połączenia głównych węzłów logicznych komputera: procesora, pamięci RAM, pamięci zewnętrznej i urządzeń peryferyjnych. Wspólna architektura różnych komputerów zapewnia ich kompatybilność z punktu widzenia użytkownika.
Struktura komputera to zbiór jego elementów funkcjonalnych i powiązań między nimi. Elementami mogą być najróżniejsze urządzenia - od głównych węzłów logicznych komputera po najprostsze obwody. Struktura komputera jest przedstawiona graficznie w postaci schematów blokowych, za pomocą których można opisać komputer na dowolnym poziomie szczegółowości.
Termin ten jest bardzo często używany konfiguracja komputera , rozumiany jako układ urządzenia obliczeniowego z jasnym określeniem charakteru, ilości, powiązań i głównych cech jego elementów funkcjonalnych. Termin " Organizacja komputerowa» określa sposób realizacji możliwości komputera,
Zespół – zbiór informacji niezbędnych procesorowi do wykonania określonej akcji podczas wykonywania programu.
Zespół składa się z kod operacji, zawierające wskazanie operacji do wykonania i kilka pola adresowe, zawierający wskazanie lokalizacji argumentów instrukcji.
Wywołuje się metodę obliczania adresu na podstawie informacji zawartych w polu adresowym polecenia tryb adresowania. Zbiór poleceń zaimplementowanych w danym komputerze tworzy jego system dowodzenia.
Maszyna Thuringa
Maszyna Turinga (MT)- wykonawca abstrakcyjny (abstrakcyjna maszyna licząca). Zostało zaproponowane przez Alana Turinga w 1936 roku w celu sformalizowania koncepcji algorytmu.
Maszyna Turinga jest przedłużeniem maszyny o skończonych stanach i zgodnie z tezą Churcha-Turinga potrafi naśladować wszystkich wykonawców(poprzez określenie reguł przejścia), które w jakiś sposób realizują proces obliczeń krok po kroku, w którym każdy krok obliczeń jest dość elementarny.
Struktura maszyny Turinga [
Maszyna Turinga obejmuje nieograniczoną liczbę w obu kierunkach wstążka(Możliwe są maszyny Turinga, które mają kilka nieskończonych taśm), podzielone na komórki i urządzenie sterujące(nazywane również głowica czytająco-zapisująca(GZCH)), zdolny być w jednym z zbiór stanów. Liczba możliwych stanów urządzenia sterującego jest skończona i precyzyjnie określona.
Urządzenie sterujące może poruszać się po taśmie w lewo i w prawo, czytać i zapisywać w komórkach znaki jakiegoś skończonego alfabetu. Wyróżnia się wyjątkowo pusty symbol wypełniający wszystkie komórki taśmy, z wyjątkiem tych z nich (ostatnia liczba), na których zapisywane są dane wejściowe.
Urządzenie sterujące działa zgodnie z zasady przejściowe, które reprezentują algorytm, wykonalny tę maszynę Turinga. Każda reguła przejścia instruuje maszynę, w zależności od aktualnego stanu i symbolu obserwowanego w bieżącej komórce, aby zapisała nowy symbol do tej komórki, przeszła do nowego stanu i przesunęła się o jedną komórkę w lewo lub w prawo. Niektóre stany maszyny Turinga można oznaczyć jako terminal, a przejście do któregokolwiek z nich oznacza koniec pracy, zatrzymanie algorytmu.
Nazywa się maszyną Turinga deterministyczny, jeśli każda kombinacja stanu i symbolu wstążki w tabeli odpowiada co najwyżej jednej regule. Jeśli istnieje para „symbol wstążki – stan”, dla której istnieją 2 lub więcej instrukcji, taką maszynę nazywa się maszyną Turinga niedeterministyczny.
Opis maszyny Turinga
Konkretną maszynę Turinga definiuje się poprzez wyszczególnienie elementów zbioru liter alfabetu A, zbioru stanów Q oraz zbioru reguł, według których maszyna działa. Mają one postać: q i a j →q i1 a j1 d k (jeżeli głowa znajduje się w stanie q i, a w obserwowanej komórce jest wpisana litera a j, to głowa przechodzi do stanu q i1, w komórce zostaje zapisane a j1 zamiast j głowa wykonuje ruch d k, który ma trzy możliwości: jedna komórka w lewo (L), jedna komórka w prawo (R), pozostań na miejscu (N)). Do każdej możliwej konfiguracji jest dokładnie jedna reguła (dla niedeterministycznej maszyny Turinga może być więcej reguł). Nie ma żadnych zasad tylko dla stanu końcowego, w którym samochód się zatrzymuje. Dodatkowo należy określić stan końcowy i początkowy, początkową konfigurację na taśmie oraz położenie głowicy maszyny.
Przykład maszyny Turinga
Podajmy przykład MT do mnożenia liczb w systemie liczb jednoargumentowych. Wpis reguły „q i a j →q i1 a j1 R/L/N” należy rozumieć następująco: q i to stan, w jakim ta reguła jest wykonywana, a j to dane w komórce, w której znajduje się głowa, q i1 to stan, do którego należy przejść, a j1 - co należy zapisać w komórce, R/L/N - polecenie ruchu.
Architektura komputerowa autorstwa Johna von Neumanna
Architektura von Neumanna- dobrze znana zasada wspólnego przechowywania poleceń i danych w pamięci komputera. Tego rodzaju systemy obliczeniowe nazywane są często „maszynami von Neumanna”, lecz zgodność tych pojęć nie zawsze jest jednoznaczna. Ogólnie rzecz biorąc, gdy ludzie mówią o architekturze von Neumanna, mają na myśli zasadę przechowywania danych i instrukcji w jednej pamięci.
Zasady von Neumanna
Zasady von Neumanna [
Zasada jednorodności pamięci
Polecenia i dane są przechowywane w tej samej pamięci i są zewnętrznie nierozróżnialne w pamięci. Można je rozpoznać jedynie po sposobie użycia; oznacza to, że ta sama wartość w komórce pamięci może zostać użyta jako dane, jako polecenie i jako adres, w zależności tylko od sposobu dostępu do niej. Pozwala to wykonywać te same operacje na poleceniach, co na liczbach, i odpowiednio otwiera szereg możliwości. Tym samym zmieniając cyklicznie część adresową polecenia, możliwy jest dostęp do kolejnych elementów tablicy danych. Technika ta nazywana jest modyfikacją poleceń i nie jest zalecana z punktu widzenia współczesnego programowania. Bardziej użyteczna jest inna konsekwencja zasady jednorodności, gdy instrukcje z jednego programu można uzyskać w wyniku wykonania innego programu. Możliwość ta leży u podstaw tłumaczenia – tłumaczenia tekstu programu z języka wysokiego poziomu na język konkretnego komputera.
Zasada targetowania
Strukturalnie pamięć główna składa się z ponumerowanych komórek, a każda komórka jest dostępna dla procesora w dowolnym momencie. Kody binarne poleceń i danych są podzielone na jednostki informacji zwane słowami i przechowywane w komórkach pamięci, a do uzyskania dostępu do nich wykorzystywane są numery odpowiednich komórek - adresów.
Zasada sterowania programowego
Wszystkie obliczenia przewidziane przez algorytm rozwiązania problemu należy przedstawić w postaci programu składającego się z ciągu słów kontrolnych - poleceń. Każde polecenie zaleca jakąś operację z zestawu operacji realizowanych przez komputer. Polecenia programu przechowywane są w kolejnych komórkach pamięci komputera i wykonywane są w naturalnej kolejności, czyli według kolejności ich ułożenia w programie. W razie potrzeby za pomocą specjalnych poleceń można zmienić tę sekwencję. Decyzja o zmianie kolejności wykonywania poleceń programu podejmowana jest albo na podstawie analizy wyników poprzednich obliczeń, albo bezwarunkowo.
Typy procesorów
Mikroprocesor- jest to urządzenie będące jednym lub większą liczbą dużych układów scalonych (LSI) realizujących funkcje procesora komputera.Klasyczne urządzenie liczące składa się z jednostki arytmetycznej (AU), urządzenia sterującego (CU), urządzenia pamięci masowej (SU ) i urządzenie wejścia-wyjścia (I/O) ).
IntelCeleron 400 Socket 370 w plastikowej obudowie PPGA, widok z góry.
Istnieją procesory o różnych architekturach.
CISC(eng. ComplexInstructionSetComputing) to koncepcja projektu procesora charakteryzująca się następującym zestawem właściwości:
· duża liczba poleceń o różnych formatach i długościach;
· wprowadzenie dużej liczby różnych trybów adresowania;
· posiada złożone kodowanie instrukcji.
Procesor CISC musi radzić sobie z bardziej złożonymi instrukcjami o różnej długości. Pojedynczą instrukcję CISC można wykonać szybciej, ale przetwarzanie wielu instrukcji CISC równolegle jest trudniejsze.
Ułatwienie debugowania programów w asemblerze wiąże się z zaśmiecaniem jednostki mikroprocesora węzłami. Aby poprawić wydajność, należy zwiększyć częstotliwość taktowania i stopień integracji, co wymaga ulepszenia technologii, a w rezultacie droższej produkcji.
Zalety architektury CISC[pokazywać]
Wady architektury CISC[pokazywać]
RISC(Przetwarzanie ograniczonego zestawu instrukcji). Procesor ze zredukowanym zestawem instrukcji. System dowodzenia jest uproszczony. Wszystkie polecenia mają ten sam format i proste kodowanie. Dostęp do pamięci odbywa się za pomocą poleceń ładowania i zapisu, pozostałe polecenia są typu rejestr-rejestr. Polecenie wchodzące do procesora jest już podzielone na pola i nie wymaga dodatkowego deszyfrowania.
Część kryształu jest uwalniana, aby pomieścić dodatkowe składniki. Stopień integracji jest niższy niż w poprzednim wariancie architektonicznym, więc niższe częstotliwości taktowania pozwalają na uzyskanie wysokiej wydajności. Polecenie mniej zaśmieca pamięć RAM, procesor jest tańszy. Architektury te nie są kompatybilne z oprogramowaniem. Debugowanie programów RISC jest trudniejsze. Technologię tę można zaimplementować w oprogramowaniu zgodnym z technologią CISC (np. technologią superskalarną).
Ponieważ instrukcje RISC są proste, do ich wykonania potrzeba mniej bramek logicznych, co ostatecznie zmniejsza koszt procesora. Jednak większość dzisiejszego oprogramowania jest napisana i skompilowana specjalnie dla procesorów Intel CISC. Aby móc korzystać z architektury RISC, aktualne programy muszą zostać przekompilowane, a czasami przepisane.
Częstotliwość zegara
Częstotliwość zegara jest wskaźnikiem szybkości wykonywania poleceń przez centralny procesor.
Takt to czas potrzebny na wykonanie elementarnej operacji.
W niedawnej przeszłości częstotliwość taktowania procesora centralnego była bezpośrednio utożsamiana z jego wydajnością, to znaczy im wyższa częstotliwość taktowania procesora, tym jego produktywność była większa. W praktyce mamy do czynienia z sytuacją, w której procesory o różnych częstotliwościach mają tę samą wydajność, ponieważ mogą wykonać różną liczbę instrukcji w jednym cyklu zegara (w zależności od konstrukcji rdzenia, przepustowości magistrali, pamięci podręcznej).
Szybkość zegara procesora jest proporcjonalna do częstotliwości magistrali systemowej ( patrz poniżej).
Głębia bitowa
Wydajność procesora to wartość określająca ilość informacji, jaką procesor centralny jest w stanie przetworzyć w jednym cyklu zegara.
Na przykład, jeśli procesor jest 16-bitowy, oznacza to, że jest w stanie przetworzyć 16 bitów informacji w jednym cyklu zegara.
Chyba każdy rozumie, że im większa głębokość bitowa procesora, tym większą ilość informacji może on przetworzyć.
Zwykle im większa pojemność procesora, tym wyższa jest jego wydajność.
Obecnie używane są procesory 32- i 64-bitowe. Rozmiar procesora nie oznacza, że ma on obowiązek wykonywać polecenia o tej samej wielkości bitowej.
Pamięć podręczna
Na początek odpowiedzmy sobie na pytanie, czym jest pamięć podręczna?
Pamięć podręczna to szybka pamięć komputera przeznaczona do tymczasowego przechowywania informacji (kodu programów wykonywalnych i danych) potrzebnych procesorowi centralnemu.
Jakie dane są przechowywane w pamięci podręcznej?
Najczęściej używane.
Jaki jest cel pamięci podręcznej?
Faktem jest, że wydajność pamięci RAM jest znacznie niższa w porównaniu z wydajnością procesora. Okazuje się, że procesor czeka na przybycie danych z pamięci RAM – co zmniejsza wydajność procesora, a tym samym wydajność całego systemu. Pamięć podręczna zmniejsza opóźnienia procesora, przechowując dane i kod programów wykonywalnych, do których procesor miał najczęściej dostęp (różnica między pamięcią podręczną a pamięcią RAM komputera polega na tym, że prędkość pamięci podręcznej jest dziesiątki razy większa).
Pamięć podręczna, podobnie jak pamięć zwykła, ma swoją pojemność. Im większa pojemność pamięci podręcznej, tym większe wolumeny danych może ona przetwarzać.
Istnieją trzy poziomy pamięci podręcznej: pamięć podręczna Pierwszy (L1), drugi (L2) i trzeci (L3). Pierwsze dwa poziomy są najczęściej stosowane w nowoczesnych komputerach.
Przyjrzyjmy się bliżej wszystkim trzem poziomom pamięci podręcznej.
Pierwsza skrytka Level to najszybsza i najdroższa pamięć.
Pamięć podręczna L1 znajduje się na tym samym chipie, co procesor i działa z częstotliwością procesora (stąd najszybsza wydajność) i jest wykorzystywana bezpośrednio przez rdzeń procesora.
Pojemność pamięci podręcznej pierwszego poziomu jest niewielka (ze względu na jej wysoki koszt) i mierzona jest w kilobajtach (zwykle nie więcej niż 128 KB).
Pamięć podręczna L2 to szybka pamięć, która spełnia te same funkcje, co pamięć podręczna L1. Różnica między L1 i L2 polega na tym, że ten drugi ma mniejszą prędkość, ale większą pojemność (od 128 KB do 12 MB), co jest bardzo przydatne przy wykonywaniu zadań wymagających dużych zasobów.
Pamięć podręczna L3 znajduje się na płycie głównej. L3 jest znacznie wolniejszy niż L1 i L2, ale szybszy niż RAM. Oczywiste jest, że objętość L3 jest większa niż objętość L1 i L2. Pamięć podręczna poziomu 3 znajduje się w bardzo wydajnych komputerach.
Liczba rdzeni
Nowoczesne technologie produkcji procesorów umożliwiają umieszczenie więcej niż jednego rdzenia w jednej obudowie. Obecność kilku rdzeni znacznie zwiększa wydajność procesora, ale to nie znaczy, że obecność N rdzenie zapewniają zwiększoną wydajność w N raz. Ponadto problem z procesorami wielordzeniowymi polega na tym, że obecnie pisze się stosunkowo niewiele programów uwzględniających obecność kilku rdzeni w procesorze.
Procesor wielordzeniowy pozwala przede wszystkim na realizację funkcji wielozadaniowości: rozdzielania pracy aplikacji pomiędzy rdzenie procesora. Oznacza to, że każdy rdzeń obsługuje własną aplikację.
Struktura płyty głównej
Przed wyborem płyty głównej należy przynajmniej powierzchownie rozważyć jej konstrukcję. Chociaż warto tutaj zauważyć, że lokalizacja gniazd i innych części płyty głównej nie odgrywa szczególnej roli.
Pierwszą rzeczą, na którą należy zwrócić uwagę, jest gniazdo procesora. Jest to małe kwadratowe wgłębienie z zapięciem.
Dla tych, którzy znają termin „overlocking” (podkręcanie komputera), należy zwrócić uwagę na obecność podwójnego radiatora. Często płyty główne nie mają podwójnego radiatora. Dlatego dla tych, którzy zamierzają w przyszłości podkręcić swój komputer, wskazane jest zadbanie o to, aby ten element był obecny na płycie.
Wydłużone gniazda PCI-Express są przeznaczone dla kart graficznych, tunerów telewizyjnych, kart audio i sieciowych. Karty graficzne wymagają dużej przepustowości i wykorzystują złącza PCI-Express X16. W przypadku innych adapterów stosowane są złącza PCI-Express X1.
Porada eksperta!Gniazda PCI o różnych przepustowościach wyglądają prawie tak samo. Warto szczególnie uważnie przyjrzeć się złączom i przeczytać etykiety pod nimi, aby uniknąć nagłych rozczarowań w domu podczas instalacji kart graficznych.
Mniejsze złącza są przeznaczone do kości RAM. Zwykle są w kolorze czarnym lub niebieskim.
Chipset płyty głównej jest zwykle ukryty pod radiatorem. Ten element odpowiada za wspólną pracę procesora i innych części jednostki systemowej.
Małe kwadratowe złącza na krawędzi płytki służą do podłączenia dysku twardego. Z drugiej strony znajdują się złącza dla urządzeń wejściowych i wyjściowych (USB, mysz, klawiatura itp.).
Producent
Wiele firm produkuje płyty główne. Wyróżnienie najlepszych i najgorszych z nich jest prawie niemożliwe. Płatność każdej firmy można nazwać wysoką jakością. Często nawet nieznani producenci oferują dobre produkty.
Sekret polega na tym, że wszystkie płyty są wyposażone w chipsety dwóch firm: AMD i Intel. Co więcej, różnice między chipsetami są nieznaczne i odgrywają rolę tylko przy rozwiązywaniu wysoce wyspecjalizowanych problemów.
Współczynnik kształtu
W przypadku płyt głównych rozmiar ma znaczenie. W większości komputerów domowych można znaleźć standardowy format ATX. Duży rozmiar, a co za tym idzie obecność szerokiej gamy gniazd, pozwala poprawić podstawowe cechy komputera.
Mniejsza wersja mATX jest mniej popularna. Możliwości poprawy są ograniczone.
Jest też mITX. Ten współczynnik kształtu można znaleźć w budżetowych komputerach biurowych. Poprawa wydajności jest albo niemożliwa, albo nie ma sensu.
Często procesory i płyty sprzedawane są w zestawie. Jeśli jednak procesor został zakupiony wcześniej, ważne jest, aby upewnić się, że jest on kompatybilny z płytą. Patrząc na gniazdo, można natychmiast określić kompatybilność procesora i płyty głównej.
Chipset
Ogniwem łączącym wszystkie komponenty systemu jest chipset. Chipsety są produkowane przez dwie firmy: Intel i AMD. Nie ma między nimi dużej różnicy. Przynajmniej dla przeciętnego użytkownika.
Standardowe chipsety składają się z mostka północnego i południowego. Najnowsze modele Intela składają się wyłącznie z modeli północnych. Nie zrobiono tego w celu zaoszczędzenia pieniędzy. Czynnik ten w żaden sposób nie zmniejsza wydajności chipsetu.
Najnowocześniejsze chipsety Intela składają się z jednego mostu, ponieważ większość kontrolerów znajduje się teraz w procesorze, w tym kontroler DD3 RAM, PCI-Express 3.0 i kilka innych.
Analogi AMD są zbudowane w oparciu o tradycyjną konstrukcję z dwoma mostkami. Na przykład seria 900 jest wyposażona w mostek południowy SB950 i mostek północny 990FX (990X, 970).
Wybierając chipset, należy zacząć od możliwości mostka północnego. Northbridge 990FX może obsługiwać jednoczesną pracę 4 kart graficznych w trybie CrossFire. W większości przypadków taka moc jest nadmierna. Ale dla fanów ciężkich gier lub tych, którzy pracują z wymagającymi edytorami graficznymi, ten chipset będzie najbardziej odpowiedni.
Nieco uproszczona wersja 990X może nadal obsługiwać dwie karty graficzne jednocześnie, ale model 970 działa wyłącznie z jedną kartą graficzną.
Układ płyty głównej
· podsystem przetwarzania danych;
· podsystem zasilania;
· bloki i zespoły pomocnicze (usługowe).
Główne elementy podsystemu przetwarzania danych płyty głównej pokazano na ryc. 1.3.14.
1 – gniazdo procesora; 2 – opona przednia; 3 – most północny; 4 – generator zegara; 5 – szyna pamięci; 6 – złącza RAM; 7 – złącza IDE (ATA); 8 – złącza SATA; 9 – most południowy; 10 – złącza IEEE 1394; 11 – złącza USB; 12 – złącze sieci Ethernet; 13 – złącza audio; 14 – autobus LPC; 15 – Super kontroler I/O; 16 – port PS/2;
17 – port równoległy; 18 – porty szeregowe; 19 – złącze dyskietki;
20 – BIOS; 21 – magistrala PCI; 22 – złącza PCI; 23 – złącza AGP lub PCI Express;
24 – autobus wewnętrzny; 25 – magistrala AGP/PCI Express; 26 – złącze VGA
FPM (Fast Page Mode) to rodzaj pamięci dynamicznej.
Jego nazwa odpowiada zasadzie działania, gdyż moduł pozwala na szybszy dostęp do danych, które znajdują się na tej samej stronie, co dane przesłane w poprzednim cyklu.
Moduły te były używane w większości komputerów opartych na procesorze 486 i wczesnych systemach opartych na Pentium około 1995 roku.

Moduły EDO (Extended Data Out) pojawiły się w 1995 roku jako nowy typ pamięci dla komputerów z procesorami Pentium.
To jest zmodyfikowana wersja FPM.
W przeciwieństwie do swoich poprzedników, EDO rozpoczyna pobieranie następnego bloku pamięci w tym samym czasie, gdy wysyła poprzedni blok do procesora.

SDRAM (Synchronous DRAM) to rodzaj pamięci o dostępie swobodnym, która działa tak szybko, że można ją zsynchronizować z częstotliwością procesora, z wyłączeniem trybów czuwania.
Mikroukłady podzielone są na dwa bloki ogniw tak, że podczas uzyskiwania dostępu do bitu w jednym bloku trwają przygotowania do uzyskania dostępu do bitu w innym bloku.
Jeżeli czas dostępu do pierwszej informacji wynosił 60 ns, wszystkie kolejne interwały skracały się do 10 ns.
Począwszy od 1996 roku większość chipsetów Intela zaczęła obsługiwać tego typu moduły pamięci, dzięki czemu były one bardzo popularne aż do 2001 roku.
SDRAM może pracować z częstotliwością 133 MHz, czyli prawie trzy razy szybciej niż FPM i dwa razy szybciej niż EDO.
Większość komputerów z procesorami Pentium i Celeron wydanych w 1999 roku korzystała z tego typu pamięci.

DDR (Double Data Rate) było rozwinięciem pamięci SDRAM.
Ten typ modułu pamięci pojawił się po raz pierwszy na rynku w 2001 roku.
Główna różnica między DDR i SDRAM polega na tym, że zamiast podwajać prędkość zegara, aby przyspieszyć działanie, moduły te przesyłają dane dwa razy w cyklu zegara.
Teraz jest to główny standard pamięci, ale już zaczyna ustępować miejsca DDR2.

DDR2 (Double Data Rate 2) to nowszy wariant pamięci DDR, który teoretycznie powinien być dwa razy szybszy.
Pamięć DDR2 pojawiła się po raz pierwszy w 2003 roku, a obsługujące ją chipsety pojawiły się w połowie 2004 roku.
Pamięć ta, podobnie jak DDR, przesyła dwa zestawy danych na cykl zegara.
Główną różnicą między DDR2 i DDR jest możliwość pracy ze znacznie wyższymi częstotliwościami taktowania, dzięki ulepszeniom konstrukcyjnym.
Ale zmodyfikowany schemat działania, który umożliwia osiągnięcie wysokich częstotliwości zegara, jednocześnie zwiększa opóźnienia podczas pracy z pamięcią.

DDR3 SDRAM (synchroniczna dynamiczna pamięć o dostępie swobodnym o podwójnej szybkości transmisji danych, trzecia generacja) to rodzaj pamięci o dostępie swobodnym wykorzystywanej w obliczeniach jako pamięć RAM i pamięć wideo.
Zastąpiła pamięć DDR2 SDRAM.
DDR3 charakteryzuje się 40% niższym zużyciem energii w porównaniu z modułami DDR2, co wynika z niższego (1,5 V w porównaniu do 1,8 V dla DDR2 i 2,5 V dla DDR) napięcia zasilania komórek pamięci.
Obniżenie napięcia zasilania osiągane jest poprzez zastosowanie w produkcji mikroukładów technologii procesowej 90 nm (początkowo, później 65, 50, 40 nm) oraz zastosowanie tranzystorów Dual-gate (co pomaga zredukować prądy upływowe). .
Moduły DIMM z pamięcią DDR3 nie są mechanicznie kompatybilne z tymi samymi modułami pamięci DDR2 (klucz znajduje się w innym miejscu), więc DDR2 nie można zainstalować w gniazdach DDR3 (ma to na celu zapobieżenie błędnej instalacji niektórych modułów zamiast innych - rodzaje pamięci nie są takie same pod względem parametrów elektrycznych).
RAMBUS (RIMM)
RAMBUS (RIMM) to rodzaj pamięci, który pojawił się na rynku w 1999 roku.
Opiera się na tradycyjnej pamięci DRAM, ale ma radykalnie zmienioną architekturę.
Konstrukcja RAMBUS sprawia, że dostęp do pamięci jest bardziej inteligentny, umożliwiając wstępny dostęp do danych przy niewielkim odciążaniu procesora.
Główną ideą zastosowaną w tych modułach pamięci jest odbieranie danych w małych pakietach, ale z bardzo dużą szybkością zegara.
Na przykład SDRAM może przesyłać 64 bity informacji przy 100 MHz, a RAMBUS może przesyłać 16 bitów przy 800 MHz.
Moduły te nie odniosły sukcesu, ponieważ Intel miał wiele problemów z ich wdrożeniem.
Moduły RDRAM pojawiły się w konsolach do gier Sony Playstation 2 i Nintendo 64.


RAM oznacza pamięć o dostępie swobodnym – pamięć, do której można uzyskać dostęp poprzez adres. Adresy dostępne sekwencyjnie mogą przyjmować dowolną wartość, zatem dostęp do dowolnego adresu (lub „komórki”) można uzyskać niezależnie.
Pamięć statystyczna to pamięć zbudowana z przełączników statycznych. Przechowuje informacje tak długo, jak długo dostarczane jest zasilanie. Zazwyczaj do przechowywania jednego bitu w obwodzie SRAM potrzebnych jest co najmniej sześć tranzystorów. SRAM jest używany w małych systemach (do kilkuset KB RAM) i jest używany tam, gdzie szybkość dostępu jest krytyczna (np. Pamięć podręczna wewnątrz procesorów lub na płytach głównych).
Pamięć dynamiczna (DRAM) powstała na początku lat 70-tych. Opiera się na elementach pojemnościowych. Możemy myśleć o pamięci DRAM jako o szeregu kondensatorów sterowanych tranzystorami przełączającymi. Do przechowywania jednego bitu potrzebny jest tylko jeden „tranzystor kondensatorowy”, więc DRAM ma większą pojemność niż SRAM (i jest tańszy).
DRAM jest zorganizowany jako prostokątny układ komórek. Aby uzyskać dostęp do komórki, musimy wybrać wiersz i kolumnę, w której ta komórka się znajduje. Zwykle jest to realizowane w taki sposób, że wyższa część adresu wskazuje na wiersz, a dolna część adresu wskazuje na komórkę w wierszu („kolumna”). Historycznie rzecz biorąc (ze względu na małe prędkości i małe pakiety układów scalonych na początku lat 70.) adres był dostarczany do układu DRAM w dwóch fazach - adres wiersza z adresem kolumny w tych samych wierszach. Najpierw układ otrzymywał adres wiersza, a następnie po kilku nanosekundach adres kolumny jest przesyłany do tej samej linii.Chip odczytuje dane i przesyła je na wyjście.Podczas cyklu zapisu dane są odbierane przez chip wraz z adresem kolumny.Do tego wykorzystuje się kilka linii sterujących kontrolują chip.Sygnały RAS (Row Address Strobe), które przesyłają adres wiersza, a także aktywują cały chip.Sygnały CAS (Column Address Strobe), które przesyłają adres kolumny WE (Write Enable), wskazując, że wykonywany dostęp jest dostępem do zapisu OE ( Output Enable) otwiera bufory używane do przesyłania danych z układu pamięci do „hosta” (procesora).
DRAM FP
Ponieważ każdorazowy dostęp do klasycznej pamięci DRAM wymagał przesłania dwóch adresów, był on zbyt wolny dla maszyn 25 MHz. FP (Fast Page) DRAM to odmiana klasycznej pamięci DRAM, w której nie ma konieczności przesyłania adresu wiersza w każdym cyklu dostępu. Dopóki linia ZAZ jest aktywna, wiersz pozostaje zaznaczony i można wybierać poszczególne komórki z tego wiersza, przekazując jedynie adres kolumny. Tak więc, chociaż komórka pamięci pozostaje taka sama, czas dostępu jest krótszy, ponieważ w większości przypadków potrzebna jest tylko jedna faza przesyłania adresu.
EDO (Extended Data Out) DRAM jest odmianą FP DRAM. W FP DRAM adres kolumny musi pozostać poprawny przez cały okres przesyłania danych. Bufory danych są aktywowane jedynie podczas cyklu transmisji adresu kolumny, poprzez sygnał poziomu aktywności sygnału CAS. Dane muszą zostać odczytane z szyny danych pamięci, zanim nowy adres kolumny zostanie odebrany w chipie. Pamięć EDO przechowuje dane w buforach wyjściowych po powrocie sygnału CAS do stanu nieaktywnego i usunięciu adresu kolumny. Równolegle z odczytem danych można przesłać adres kolejnej kolumny. Zapewnia to możliwość korzystania z częściowego dopasowywania podczas czytania. Chociaż komórki pamięci EDO RAM mają tę samą prędkość co FP DRAM, dostęp sekwencyjny może być szybszy. Zatem EDO powinno być czymś szybszym niż FP, szczególnie w przypadku masowego dostępu (jak w aplikacjach graficznych).
Pamięć RAM wideo może być oparta na dowolnej architekturze DRAM wymienionej powyżej. Oprócz „normalnego” mechanizmu dostępu opisanego poniżej, pamięć VRAM ma jeden lub dwa specjalne porty szeregowe. Pamięć VRAM jest często określana jako pamięć dwuportowa lub potrójna. Porty szeregowe zawierają rejestry, które mogą przechowywać zawartość całej serii. Możliwe jest przeniesienie danych z całego wiersza tablicy pamięci do rejestru (lub odwrotnie) w jednym cyklu dostępu. Dane można następnie odczytać lub zapisać w rejestrze szeregowym w fragmentach o dowolnej długości. Ponieważ rejestr składa się z szybkich, statycznych komórek, dostęp do niego jest bardzo szybki, zwykle kilkukrotnie szybszy niż w przypadku tablicy pamięci. W większości typowych zastosowań pamięć VRAM wykorzystywana jest jako bufor pamięci ekranu. Port równoległy (interfejs standardowy) wykorzystywany jest przez procesor, a port szeregowy służy do przesyłania danych o punktach na wyświetlaczu (lub odczytywania danych ze źródła wideo).
WRAM to autorska architektura pamięci opracowana przez firmę Matrox i (kto jeszcze, niech pamiętam... - Samsung?, MoSys?...). Jest podobny do VRAM, ale umożliwia szybszy dostęp hosta. WRAM był używany w kartach graficznych Matrox Millenium i Millenium II (ale nie w nowoczesnym Millenium G200).
SDRAM to całkowicie przeprojektowany model DRAM, wprowadzony w latach 90. „S” oznacza synchroniczny, ponieważ SDRAM implementuje całkowicie synchroniczny (a przez to bardzo szybki) interfejs. Wewnątrz SDRAM-u znajdują się (zwykle dwie) macierze DRAM. Każda tablica ma swój własny własny rejestr stron, który przypomina (trochę) rejestr dostępu szeregowego w pamięci VRAM. SDRAM działa znacznie mądrzej niż zwykła pamięć DRAM. Cały obwód jest synchronizowany zewnętrznym sygnałem zegara. Przy każdym taktowaniu zegara chip odbiera i wykonuje przesłane polecenie wzdłuż wierszy poleceń.Nazwy wierszy poleceń pozostają takie same jak w klasycznych układach DRAM, ale ich funkcje są jedynie podobne do oryginału.Występują polecenia służące do przesyłania danych pomiędzy tablicą pamięci a rejestrami stronicowymi oraz dostępu do danych w rejestrach stronicowych. Dostęp do rejestru stron jest bardzo szybki - nowoczesne pamięci SDRAM-y mogą przesyłać nowe słowo danych co 6..10 ns.
Synchronous Graphics RAM to odmiana pamięci SDRAM przeznaczonej do zastosowań graficznych. Struktura sprzętowa jest niemal identyczna, dlatego w większości przypadków możemy podmieniać SDRAM i SGRAM (patrz karty Matrox G200 - niektóre korzystają z SD, inne z SG). Różnica polega na funkcjach wykonywanych przez rejestr stronicowy. SG może zapisywać wiele lokalizacji w jednym cyklu (pozwala to na bardzo szybkie wypełnianie kolorami i czyszczenie ekranu) i może zapisywać tylko kilka bitów na słowo (bity są wybierane przez maskę bitową przechowywaną w obwodzie interfejsu). Dlatego SG jest szybszy w aplikacjach graficznych, chociaż nie fizycznie szybszy niż SD w „normalnym” użytkowaniu. Dodatkowe funkcje SG są wykorzystywane przez akceleratory graficzne. Myślę, że w szczególności funkcje czyszczenia ekranu i bufora Z są bardzo przydatne.
RAMBUS (RDRAM)
RAMBUS (znak towarowy firmy RAMBUS, Inc.) zaczęto rozwijać w latach 80-tych, więc nie jest to nowość. Nowoczesne technologie RAMBUS łączą w sobie stare, ale bardzo dobre pomysły i dzisiejsze technologie produkcji pamięci. RAMBUS opiera się na prostej idei: bierzemy wszystko, co dobre DRAM, wbudowujemy w chip bufor statyczny (podobnie jak w VRAM i SGRAM) oraz zapewniamy specjalny, konfigurowalny elektronicznie interfejs pracujący w częstotliwości 250..400 MHz.Interfejs jest co najmniej dwukrotnie szybszy niż stosowany w SDRAM-ie, a jednocześnie czas dostępu losowego jest zwykle wolniejszy, dostęp sekwencyjny jest bardzo, bardzo, bardzo szybki. Należy pamiętać, że kiedy wprowadzono pamięci RDRAM 250 MHz, większość pamięci DRAM działała na częstotliwościach 12..25 MHz. RDRAM wymaga specjalnego interfejsu i bardzo ostrożnego fizycznego rozmieszczenia Większość układów RDRAM wygląda zupełnie inaczej niż inne pamięci DRAM: wszystkie mają wszystkie linie sygnałowe po jednej stronie obudowy (a więc mają tę samą długość) i tylko 4 linie zasilające po drugiej stronie. Pamięci RDRAM są stosowane w kartach graficznych opartych na chipach Cirrus 546x. Wkrótce zobaczymy pamięci RDRAM używane jako pamięć główna w komputerach PC.
Urządzenie z dyskiem twardym.
Dysk twardy składa się z zestawu płytek, najczęściej przedstawiających dyski metalowe, pokrytych materiałem magnetycznym - talerzem (tlenek ferrytu gamma, ferryt baru, tlenek chromu...) i połączonych ze sobą za pomocą wrzeciona (wał, oś).
Same dyski (o grubości około 2 mm) wykonane są z aluminium, mosiądzu, ceramiki lub szkła. (patrz zdjęcie)
Do nagrywania wykorzystywane są obie powierzchnie płyt. Używa się 4-9 płytek. Wał obraca się z dużą stałą prędkością (3600-7200 obr/min)
Obrót dysków i radykalny ruch głowic odbywa się za pomocą 2 silników elektrycznych.
Dane są zapisywane lub odczytywane za pomocą głowic zapisująco-odczytujących, po jednej na każdej powierzchni dysku. Liczba głowic jest równa liczbie powierzchni roboczych wszystkich dysków.
Informacje zapisywane są na dysku w ściśle określonych miejscach – koncentrycznych ścieżkach (ścieżkach). Ścieżki podzielone są na sektory. Jeden sektor zawiera 512 bajtów informacji.
Wymiana danych pomiędzy RAM i NMD odbywa się sekwencyjnie poprzez liczbę całkowitą (klaster). Klaster - łańcuchy kolejnych sektorów (1,2,3,4,…)
Specjalny silnik za pomocą wspornika ustawia głowicę odczytu/zapisu nad zadanym torem (przesuwa ją w kierunku promieniowym).
Po obróceniu dysku głowica znajduje się nad żądanym sektorem. Oczywiście wszystkie głowice poruszają się jednocześnie i odczytują informacje; głowice danych poruszają się jednocześnie i odczytują informacje z identycznych ścieżek na różnych dyskach.
Ścieżki dysku twardego o tym samym numerze seryjnym na różnych dyskach twardych nazywane są cylindrem.
Głowice odczytu i zapisu poruszają się po powierzchni talerza. Im bliżej powierzchni dysku znajduje się głowica, nie dotykając jej, tym większa jest dopuszczalna gęstość zapisu .
Interfejsy dysków twardych.
IDE (ATA – Advanced Technology załącznik) to interfejs równoległy do łączenia dysków, dlatego zmieniono go (z wyjściem SATA) na PATA (Parallel ATA). Wcześniej używany do podłączania dysków twardych, ale został wyparty przez interfejs SATA. Obecnie używany do podłączania napędów optycznych.
SATA (Serial ATA) – interfejs szeregowy do wymiany danych z dyskami. Do podłączenia służy złącze 8-pinowe. Podobnie jak w przypadku PATA, jest on przestarzały i służy wyłącznie do pracy z napędami optycznymi. Standard SATA (SATA150) zapewniał przepustowość 150 MB/s (1,2 Gbit/s).
SATA2 (SATA300). Standard SATA 2 podwoił przepustowość do 300 MB/s (2,4 Gbit/s) i umożliwia pracę z częstotliwością 3 GHz. Standardowe SATA i SATA 2 są ze sobą kompatybilne, jednak w przypadku niektórych modeli konieczne jest ręczne ustawienie trybów poprzez przestawienie zworek.
SATA 3, chociaż zgodnie ze specyfikacją można go nazwać SATA 6Gb/s. Standard ten podwoił prędkość przesyłania danych do 6 Gbit/s (600 MB/s). Inne pozytywne innowacje obejmują funkcję kontroli programu NCQ i polecenia ciągłego przesyłania danych dla procesu o wysokim priorytecie. Choć interfejs został wprowadzony w 2009 roku, nie cieszy się jeszcze szczególną popularnością wśród producentów i nieczęsto można go spotkać w sklepach. Oprócz dysków twardych standard ten jest stosowany w dyskach SSD (dyskach półprzewodnikowych). Warto zaznaczyć, że w praktyce przepustowość interfejsów SATA nie różni się szybkością przesyłania danych. W praktyce prędkość zapisu i odczytu dysków nie przekracza 100 MB/s. Zwiększenie wydajności wpływa jedynie na przepustowość pomiędzy kontrolerem a pamięcią podręczną dysku.
SCSI (Small Computer System Interface) – standard stosowany w serwerach, gdzie wymagana jest zwiększona prędkość przesyłania danych.
SAS (Serial Dołączony SCSI) to generacja, która zastąpiła standard SCSI, wykorzystując szeregową transmisję danych. Podobnie jak SCSI, jest używany w stacjach roboczych. W pełni kompatybilny z interfejsem SATA.
CF (Compact Flash) – Interfejs do podłączenia kart pamięci, a także dysków twardych 1,0 cala. Istnieją 2 standardy: Compact Flash Type I i Compact Flash Type II, różnica polega na grubości.
FireWire to alternatywny interfejs dla wolniejszego USB 2.0. Służy do podłączania przenośnych dysków twardych. Obsługuje prędkości do 400 Mb/s, ale prędkość fizyczna jest niższa niż zwykła. Podczas odczytu i zapisu maksymalny próg wynosi 40 MB/s.
Rodzaje kart graficznych
Nowoczesne komputery (laptopy) są dostępne z różnymi typami kart graficznych, które bezpośrednio wpływają na wydajność w programach graficznych, odtwarzanie wideo i tak dalej.
Obecnie w użyciu są 3 typy adapterów, które można łączyć.
Przyjrzyjmy się bliżej typom kart graficznych:
- zintegrowany;
- oddzielny;
- hybrydowy;
- dwa dyskretne;
- Hybrydowe SLI.
Zintegrowana karta graficzna- To niedroga opcja. Nie posiada pamięci wideo ani procesora graficznego. Za pomocą chipsetu grafika jest przetwarzana przez centralny procesor, zamiast pamięci wideo używana jest pamięć RAM. Taki układ urządzeń znacznie zmniejsza wydajność komputera w ogóle, a w szczególności przetwarzania grafiki.
Często używany w budżetowych konfiguracjach komputerów stacjonarnych lub laptopów. Umożliwia pracę z aplikacjami biurowymi, oglądanie i edycję zdjęć i filmów, ale nie pozwala grać w nowoczesne gry. Dostępne są tylko starsze opcje z minimalnymi wymaganiami systemowymi.
Wszystkie współczesne komputery, mimo że minęło już sporo czasu, działają na zasadach zaproponowanych przez amerykańskiego matematyka Johna von Neumanna (1903 – 1957). Wniósł także znaczący wkład w rozwój i zastosowanie komputerów. Jako pierwszy ustalił zasady działania komputera:
1. Zasada kodowania binarnego: wszystkie informacje w komputerze są prezentowane w postaci binarnej, będącej kombinacją 0 i 1.
2. Zasada jednorodności pamięci: w tej samej pamięci przechowywane są zarówno programy, jak i dane, dlatego komputer nie rozpoznaje, co jest zapisane w danej komórce pamięci, ale mogą się w niej znajdować liczby, teksty, polecenia itp. na poleceniach można wykonać te same działania, co w przypadku superdanych.
3. Zasada adresowalności pamięci: schematycznie OP (pamięć główna) składa się z ponumerowanych komórek, CPU (jednostka centralna) – każda komórka pamięci jest dostępna w dowolnym momencie. Dlatego możliwe jest przypisanie nazw blokom pamięci w celu wygodniejszej interakcji pomiędzy OP a CPU.
4. Zasada sekwencyjnego sterowania programem: program składa się ze zbioru instrukcji, które są wykonywane przez procesor sekwencyjnie, jedna po drugiej.
5. Zasada rozgałęzienia warunkowego: nie zawsze jest tak, że polecenia są wykonywane jedna po drugiej, dlatego możliwe jest posiadanie poleceń rozgałęzień warunkowych, które zmieniają sekwencyjne wykonywanie poleceń w zależności od wartości przechowywanych danych
. Klasyfikacja współczesnych komputerów.
Nowoczesny komputer są podzielone na wbudowane mikroprocesory, mikrokomputer(komputery osobiste), komputery typu mainframe I superkomputer- kompleks komputerowy z kilkoma procesorami.
Mikroprocesy- procesory zaimplementowane w formularzu całka elektroniczny mikroukłady. Mikroprocesory można wbudować w telefony, telewizory i inne urządzenia, maszyny i urządzenia.
Na układach scalonych wdrażane są procesory i pamięć RAM wszystkich współczesnych mikrokomputerów, a także wszystkie bloki dużych komputerów i superkomputerów, a także wszystkie urządzenia programowalne.
Wydajność mikroprocesora wynosi kilka miliony operacje na sekundę, a objętość nowoczesnych bloków pamięci RAM wynosi kilka milionów bajtów.
Mikrokomputer - te są pełnowartościowe przetwarzanie danych samochody, posiadający nie tylko procesor i pamięć RAM do przetwarzania danych, ale także urządzenia wejścia-wyjścia i przechowywania informacji.
Komputery osobiste - Ten mikrokomputer, posiadające urządzenia wyświetlające na ekranach elektronicznych, a także urządzenia wejścia/wyjścia danych w postaci klawiatury i ewentualnie urządzenia do podłączenia do sieci komputerowych.
Architektura mikrokomputera opiera się na wykorzystaniu szkieletu systemu - urządzenia interfejsowego, do którego podłączone są procesory i jednostki RAM, a także wszystkie urządzenia wejścia-wyjścia.
Korzystanie z bagażnika pozwala na zmianę mieszanina I Struktura mikrokomputer- dodać dodatkowe urządzenia wejścia/wyjścia i zwiększyć funkcjonalność komputerów.
Długotrwałe przechowywanie informacja we współczesnych komputerach odbywa się za pomocą nośników elektronicznych, magnetycznych i optycznych - dysków magnetycznych, dysków optycznych i bloków pamięci flash.
Architektura współczesnych komputerów wymaga obecności pamięci długotrwałej, w której znajdują się pliki, pakiety oprogramowania, bazy danych i sterujące systemy operacyjne.
Komputery typu mainframe — komputery wysoki wydajność z dużą ilością pamięci zewnętrznej. Komputery typu mainframe są wykorzystywane jako serwery sieci komputerowych i dużych obiektów do przechowywania danych.
Komputery typu mainframe wykorzystywane jako podstawa organizacji zbiorowy Informacja systemy obsługa korporacji przemysłowych i agencji rządowych.
Superkomputer- Ten wieloprocesorowy komputer o złożonej architekturze, charakteryzujące się najwyższą wydajnością i wykorzystywane do rozwiązywania bardzo złożonych problemów obliczeniowych.
Wydajność superkomputera wynosi kilkadziesiąt I setki tysiąc miliardy przetwarzanie danych operacje na sekundę. Jednocześnie liczba procesorów w superkomputerach stale rośnie, a architektura komputerów staje się coraz bardziej złożona.