Excelの線形依存 Excelの回帰の主な課題:モデルを構築する例
以前の注意事項では、分析の分析はしばしば別々の数変数、例えば、相互資金の歩留まり、Webページをロードする時間、または非アルコール飲料消費量の歩留まりとなりました。 現在および以下の注意事項では、1つ以上の他の数値変数の値に応じて数値変数値の予測方法を調べます。
この材料は例によって例示される。 衣料品店での売上高を予測する。25年間のヒマワリの割引衣料品店は常に拡大しました。 しかし、今、当社は新しい出口の選択に対する体系的なアプローチを持っていません。 会社が新しい店を開く予定の場所は、主観的な考慮事項に基づいて決定されます。 選択基準は有利なリース条件または理想的なロケーションマネージャです。 あなたが特別プロジェクトと計画の部門の長であると想像してください。 あなたは新しい店舗を開くための戦略的計画を立てるように指示されました。 この計画には、新しく開かれた店舗の年間売上高の予測を含める必要があります。 あなたは、取引地域が直接収益の量に関連していると信じており、あなたは意思決定プロセスにおいてこの事実を考慮に入れたいと思います。 新しい店舗の規模に基づいて年間売上高を予測できる統計モデルを開発する方法
ルールとして、変数値を予測するために使用されます 回帰分析。 その目的は、依存変数の値、または応答の値を少なくとも1つ、独立した、または説明的な変数の値で予測できる統計モデルを開発することです。 このノートでは、単純な線形回帰 - 依存変数の値を予測できる統計的方法を検討します。 y。 独立変数の値によって バツ。。 後続の注意事項では、独立変数の値を予測するように設計された、複数回帰モデルについて説明します。 y。 いくつかの従属変数の値によって x 1、x 2、...、x k).
フォーマットまたは例のフォーマットでメモをダウンロードしてください
回帰モデルの種類
どこ ρ 1 - 自己相関係数。 もし ρ 1 \u003d 0(自己相関なし)、 d ←2; もし ρ 1 ←1(陽性自己相関)、 d ≈0; もし ρ 1 \u003d -1(負の自己相関)、 d ≈ 4.
実際には、Durbin-Watsonの基準の使用は比較に基づいています d 重要な理論値で d L. そして dU. 所定の数の観察者について n、独立した変数の数モデル k (簡単なので 線形回帰 k \u003d 1)および有意性αのレベル。 もし d< d L 、ランダム偏差の独立性に関する仮説は拒絶されている(したがって、陽性自己相関が存在する)。 もし D\u003e D U.、仮説は拒否されない(つまり、自己相関はありません)。 もし d L.< D < d U 決定を下すのに十分な根拠はありません。 計算値の場合 d 2を超えると、 d L. そして dU. 係数そのものを比較してください d、式(4 - d).
Durbina-Watson統計をExcelで計算するために、図1の底面テーブルに変える。 four four 結論残差。 式(10)内の分子は、関数\u003d集計可能(Array1; Array2)、およびDeNominator \u003d Summalk(Array)を用いて計算される(図16)。

図。 16. Durbin-Watsonの統計を計算するための式
私たちの例で d \u003d 0.883。 主な質問は次のとおりです - ダービンワトソン統計の意味は何が肯定的な自己相関の存在を結論づけるのに十分小さいと見なされるべきですか? Dの値をクリティカル値と相関させる必要があります( d L.そして DU.観察数によって異なります n 有意率αのレベル(図17)。

図。 17. Durbin-Watson統計の重要な値(表フラグメント)
したがって、店舗の販売のタスクでは、家に商品を配達する店舗には、独立した変数が1つあります( k \u003d 1)、15の観察( n \u003d 15)および有意差のレベルα\u003d 0.05。 したがって、 d L.\u003d 1.08 I. d u \u003d 1.36。 ins d = 0,883 < d L.\u003d 1.08では、残基間に正の自己相関があり、最小二乗法を適用することができない。
勾配と相関係数について仮説を確認してください
上記の回帰は予測専用で使用されていました。 回帰係数と変数の値の予測を決定する y。 与えられた変数値の場合 バツ。 最小二乗法を用いた。 また、推定値と混合相関係数の平均二乗誤差を検討した。 残基の分析が最小二乗法の適用性の条件が違反されないことを確認し、単純な線形回帰のモデルが適切であることを確認し、それは変数間に線形依存性があると主張することができる。一般的な人口で。
応用t 傾斜のための手法。β1ゼロの一般的な組み合わせの傾きが等しいかどうかを検証することで、変数間の統計的に意味のある関係があるかどうかを判断することが可能であるかどうか バツ。 そして y。。 この仮説が偏向した場合、変数間の間に主張することができます バツ。 そして y。 線形依存があります。 ゼロおよび代替の仮説は以下のように処方される.H 0:β1\u003d 0(線形依存性なし)、H1:β1≧0(線形依存性がある)。 a-priory t- ステーションは、チルト推定の平均二乗誤差に分割された一般母集団の傾斜の傾斜の違いとの差に等しい。
(11) t = (b 1 – β 1 ) / S B. 1
どこ b 1
- 選択データによる直接回帰の勾配β1は直接一般骨材の仮想斜面である。 ![]() 、そしてテスト統計 t それは持っています tの配分 n - 2。 自由度。
、そしてテスト統計 t それは持っています tの配分 n - 2。 自由度。
店舗のサイズとα\u003d 0.05の年間販売数量の間に統計的に重要な関係があるかどうかを確認してください。 t使用時の他のパラメータとともに印刷が表示されます パッケージ分析 (オプション 回帰)。 分析パッケージの分析の結果を完全に図4に示す。 図4において、図4のT統計に属する断片。 18。
図。 18.応用結果 t
店舗数以来 n \u003d 14(図3参照)、臨界値 t- 有意差のレベルの統計α\u003d 0.05は式によって見つけることができる。 t L. \u003d学生。(0.025; 12)\u003d -2,1788、ここで0.025は有意水準の半分、12 \u003d n – 2; u \u003d学生。教授(0.975; 12)\u003d + 2,1788。
ins t-station \u003d 10.64\u003e u \u003d 2,1788(図19)、ゼロ仮説 h 0 逸脱します。 一方、 r- ノート h \u003d 10,6411、式\u003d 1ステージ(D3; 12;真理)、ほぼゼロ、その仮説 h 0 また拒否されました。 事実 r- アイデアはほぼゼロに等しいので、店舗のサイズと年間販売数量の間に実際の線形依存性がなかった場合は、線形回帰を使用して検出することはほとんど不可能です。 その結果、店頭における年間平均販売数量とそのサイズとの間に統計的に有意な線形依存がある。

図。 19.有意水準の傾きについての仮説を確認し、0.05、および12自由度
応用f 傾斜のための手法。単純な線形回帰の勾配に関する仮説をチェックするための代替的なアプローチは使用することです f- クリテリア。 それを思い出します f2つの分散間の関係を検証するために基準を使用します(詳細については、参照)。 ランダムエラーの尺度によってスロープに関する仮説をチェックするときは、誤差分散(エラーの二乗の合計を自由度で割ったもの)です。 f- 基準は回帰(すなわち値)のために分散比を使用する SSR独立変数の数で割った k)、分散エラーへ( MSE \u003d S y バツ。 2 ).
a-priory f-Stationは、回帰(MSR)が誤差分散(MSE)に分割された偏差の平均二乗に等しい。 f = MSR/ MSEどこ MSR \u003d。SSR / k、MSE \u003d。SSE./(n- K - 1)、K - 回帰モデル内の独立変数の数。 テスト統計情報 f それは持っています fの配分 k そして n - K - 1 自由度。
与えられた有意性αで、決定的規則は以下のように策定される。 F\u003e F u、ゼロ仮説は逸脱します。 そうでなければ、それは逸脱しません。 分散解析の要約テーブルの形で装飾された結果を図4に示す。 20。

図。 仮説を検査するための分散テーブルに関する 統計的有意性 不況係数
同様に t- 手法 f使用時にテーブルにグリテリアが表示されます パッケージ分析 (オプション 回帰)。 完全性能結果 パッケージ分析 図1に示す。 4、断片に関連する f- スタティックスティックス - 21。

図。 21.応用結果 fエクセル分析パッケージを用いて得られた基準
F統計は113.23、そして r- ゼロに近い結び(セル 意義f)。 有意率αのレベルが0.05の場合、臨界値を決定する f1と12の自由度の分布は式を使用することができます f \u003d F. PREFES(1-0.05; 1; 12)\u003d 4,7472(図22)。 ins f = 113,23 > f \u003d 4,7472、そして r- 0に近いノート< 0,05, нулевая гипотеза h 0 逸脱する、 店舗の大きさは年間売上高と密接に関係しています。

図。 22. 0.05に等しい、一般的な人口の傾きについての仮説を確認すると、1と12の自由度があります。
β1の傾きを含む信頼区間。 変数間の線形関係の存在について仮説をテストするために、β1の傾きを含む信頼区間を構築することができ、β1\u003d 0の仮想値がこの間隔に属することを確認することができる。 β1の傾きを含む信頼区間の中心は選択的な傾きです b 1 、その罫線 - 値 b 1±t N. –2 S B. 1
図5に示すように、No。 18、 b 1 = +1,670, n = 14, S B. 1 = 0,157. t 12 \u003d学生。教授(0.975; 12)\u003d 2,1788。 したがって、 b 1±t N. –2 S B. 1 \u003d + 1,670±2,1788 * 0.157 \u003d + 1,670±0.342、または+ 1,328≦β1≦+ 2,012。 したがって、0.95の確率を有する一般集団の勾配は、+ 1.328から+ 2.012の範囲である(すなわち、1,268,000米ドルから2,012,000)。 これらの量はゼロより大きいので、年間販売数量と店舗領域の間に統計的に大きな線形依存性があります。 信頼区間がゼロに含まれている場合、変数間の依存性はありません。 さらに、信頼区間は、1,000平方メートルの店舗領域のあらゆる増加を意味する。 足は、1,328,000から2,012,000ドルの価値の平均売上高の増加につながります。
usingt 相関係数のための基準。 相関係数を導入した r、2つの数値変数間の関係の尺度を表す。 これにより、2つの変数の間に統計的にあるかどうかをインストールできます。 重要な通信。 両方の変数の一般設定とシンボルρとの間の相関係数を示す。 ゼロと代替の仮説は次のように策定されます。 h 0:ρ\u003d 0(相関なし)、 H 1。:ρ≠0(相関がある)。 相関の存在を確認する

どこ r = + 、 もし b 1 > 0, r = – 、 もし b 1 < 0. Тестовая статистика t それは持っています tの配分 n - 2。 自由度。
ネットワークのタスクにはSunflowersが格納されています r 2。 \u003d 0.904、そして b 1。- + 1,670(図4参照)。 ins b 1。 \u003e 0、年間売上高と店舗のサイズの相関係数が等しい r \u003d +≒0.904 \u003d + 0.951。 これらの変数間に相関がないと主張するゼロ仮説を確認してください。 t-統計:

有意性のレベルでα\u003d 0.05ゼロ仮説は拒否されるべきである t \u003d 10.64\u003e 2,1788。 したがって、年間売上高と店舗のサイズの間に統計的に重要な接続があると主張することができます。
一般的な人口の傾きに関連する結論を議論するとき、仮説をテストするための信頼区間と基準は交換可能な道具です。 しかしながら、選択的統計分布の種類以来、相関係数を含む信頼区間の計算はより複雑である。 r 真の相関係数によって異なります。
数学的期待と個々の値の予測の評価
このセクションでは、応答の数学的期待を評価するための方法について説明します y。 と個々の値の予測 y。 変数の指定値で バツ。.
機密の間隔を構築する。実施例2(上記の節を参照のこと 最小二乗法) 回帰方程式 変数の値を予測できます y。 バツ。。 場所を選ぶという仕事で 貿易ポイント 4000平方メートルショップでの年間平均売上高。 足は7644万ドルに等しくなりました。しかし、一般的な人口の数学的期待の評価は時点です。 一般的な人口の数学的期待を評価するために、機密期間の概念が提案されました。 同様に、あなたは概念を入力することができます 数学的対応期待のための信頼区間 与えられた変数値で バツ。:
どこ  , =
b 0
+
b 1
x i。 - 予測値変数 y。 にとって バツ。 = x i。, yx。 - ラジアントエラー、 n - サンプルサイズ、 バツ。 私。 - 変数の指定値 バツ。, µ
y。| バツ。 =
バツ。 私。 - 数学的待機変数 y。 にとって h = x i。、ssx \u003d。
, =
b 0
+
b 1
x i。 - 予測値変数 y。 にとって バツ。 = x i。, yx。 - ラジアントエラー、 n - サンプルサイズ、 バツ。 私。 - 変数の指定値 バツ。, µ
y。| バツ。 =
バツ。 私。 - 数学的待機変数 y。 にとって h = x i。、ssx \u003d。 
式(13)の分析は、信頼区間の幅がいくつかの要因に依存することを示している。 与えられた意味では、標準誤差を使用して測定された回帰線の周囲の振動の振幅を大きくすると、間隔の幅の上昇が増します。 一方、予想通り、試料の大きさの増加は間隔の狭窄を伴う。 なお、間隔の幅は値によって異なります バツ。 私。。 変数の値の場合 y。 大きさのために予測される バツ。平均値に近い 信頼区間は、平均から離れた値に対する応答を予測するときよりもすでに利用可能です。
店舗の場所を選択することで、全店舗の平均年間売上高の95%の信頼区間を建設したいとします。その面積は4000平方メートルです。 足:

その結果、その地域が4,000平方メートルのすべての店舗の年間平均売上高。 95%の確率で、6.971から8317百万ドルの範囲内にあります。
予測値の信頼区間を計算します。特定の可変値を持つ数学的応答の信頼区間に加えて バツ。予測値の信頼区間を知ることがしばしば必要です。 そのような信頼区間を計算するための式が式(13)と非常に似ているという事実にもかかわらず、この間隔は予測値を含み、パラメータの推定値は含まれていない。 予測応答の間隔 y。 バツ。 = Xi. 特定の可変値を持つ バツ。 私。 式:

交通率のための場所を選択すると、店内の予測された年間売上高のための95%信頼区間を構築したいとします。その面積は4000平方メートルです。 足:

その結果、店舗の年間売上高は4000平方メートルです。 95%の確率は5.433から98億4百万ドルの範囲であります。私たちが見ると、予測される応答値の信頼区間はその数学的期待の信頼区間よりもはるかに広いです。 これは、個々の値を予測する際の変動性が数学的期待を評価するときよりもはるかに大きいという事実によって説明されます。
回帰に関連した水中石と倫理的問題
回帰分析に関連する困難性:
- 最小二乗法の適用性の条件を無視する。
- 最小二乗法の適用条件の誤差評価
- 最小二乗法の適用性の条件に違反した代替方法の誤った選択。
- 研究の主題に関する深い知識なしに回帰分析の適用
- 説明変数への変化の範囲を超えた回帰の外挿。
- 統計的依存性と因果関係の間の混乱
広範囲のスプレッドシートと ソフトウェア 統計的計算のために、回帰分析の適用を妨げる計算上の問題を解消しました。 しかし、これは、回帰分析が十分な資格と知識を持っていないユーザーの適用を始めたという事実をもたらしました。 他のメソッドが最小の正方形の方法の適用可能性の概念がわからない場合は、代替方法についてどのように知っていて、自分の実行の確認方法がわからないのですか。
研究者は、剪断、傾向、および混合相関の係数の計算を数字の粉砕によって運ばないでください。 彼はより深い知識が必要です。 これを説明して、教科書から取られた古典的な例が説明しています。 アンズキーは、図4に示されている4つのデータセットすべてが示されたことを示した。 図23の回帰パラメータ(図24)を有する。

図。 23.人工データの4つのセット

図。 4つの人工データセットの回帰分析 援助で作られました パッケージ分析(画像をクリックして画像を拡大)
したがって、回帰分析の観点からは、これらすべてのデータセットは完全に同一です。 分析が完成した場合、私たちはたくさん失うだろう 有用な情報。 これは、これらのデータセット用に構築された、散布図(図25)および残差グラフ(図26)によって証明される。

図。 4データセットの散布図
残基の散乱とスケジュールの図は、これらのデータが互いに異なることを示しています。 直線に沿って分配された唯一の設定は、SET Aによって計算された残余のスケジュールのセットです。パターンはありません。 これは、セットB、B、Gについては言えません.SET B上に構築された散布スケジュールは、発音の2次モデルを示しています。 この結論は放物線形状を有する残基のスケジュールによって確認される。 散布図と残差スケジュールは、データ・セットに排出量を含むことを示しています。 この状況では、データセットから排出を排除して分析を繰り返す必要があります。 観測から排出量を検出し除外することを可能にする方法は、影響の分析と呼ばれます。 放出を除いた後、モデルの再評価の結果は完全に異なる場合があります。 セットからのデータに従って構築された散布図は、経験的モデルが別々の応答で大きく依存する異常な状況を示しています( ×8。 = 19, y。 8 \u003d 12.5)。 そのような回帰モデルは特に注意深く計算されなければならない。 したがって、散乱スケジュールと残差スケジュールは回帰分析に非常に必要なツールであり、不可欠な部分であるべきです。 それらがなければ、回帰分析は信頼に値しません。

図。 4組のデータのための残留スケジュール
回帰分析の水中石を回避する方法:
- 変数間の可能な関係の分析 バツ。 そして y。 散布図の構成から常に始めます。
- 回帰分析の結果を解釈する前に、その適用性の条件を確認してください。
- 残基の依存性のグラフを独立変数から構築します。 これにより、経験的モデルが観察の結果を満たし、分散分散を検出する方法を決定します。
- 通常の誤差分布の仮定を検証するには、ヒストグラム、「トランクと葉」を使用します。通常の分布のブロック図とチャートを使用します。
- 最小二乗法の適用性状が実行されない場合は、代替方法(例えば、二次回帰モデルまたは複数回帰モデル)を使用する。
- 最小二乗法の適用性条件が実行される場合、回帰係数の統計的有意性に関する仮説をテストし、数学的期待値と予測応答値を含む信頼区間を構築することが必要である。
- 独立変数の変化範囲外の従属変数の値を予測しないでください。
- 統計的な依存関係は必ずしも原因ではないことに注意してください。 変数間の相関関係は、それらの間の因果関係を意味するものではないことを忘れないでください。
概要。構造的スキーム(図27)に示されるように、単純な線形回帰モデル、その適用性の条件およびこれらの条件をチェックするための方法を説明する。 考慮された t回帰傾向の統計的有意性を検証するための基準。 従属変数の値を予測するには、回帰モデルが使用されました。 店舗地域からの年間販売数量の依存性を調べる取引先の場所の選択に関連する例を調べた。 受信した情報はあなたが店のためのより正確な場所を選び、その年間売上を予測することを可能にします。 以下の注意事項は回帰分析について議論し続け、複数回回帰のモデルも考慮されます。

図。 27.構造方式の注意事項
BOOK Levin et al。マネージャの統計。 - M。:Williams、2004。 792-872。
従属変数がカテゴリカーである場合は、ロジスティック回帰を適用する必要があります。
回帰分析は、最も求められた統計的研究方法の1つです。 これにより、従属変数に対する独立した値の影響度を確立することが可能です。 機能的に マイクロソフトエクセル。 そのような種類の分析を実行するためのツールがあります。 彼らが自分自身を表すこと、そしてそれらの使い方を分析しましょう。
分析パッケージを接続する
ただし、回帰分析を実行できる機能を使用するには、まず、分析パッケージをアクティブにする必要があります。 その場合のみ、この手順に必要なツールがExileテープに表示されます。
- 「ファイル」タブに移動します。
- 「パラメータ」セクションに進みます。
- Excel Parametersウィンドウが開きます。 サブセクション「付加構造」に進みます。
- 開閉ウィンドウの下部には、別の位置にある場合は、「コントロール」ブロックのスイッチを「Excelアドイン」位置に並べ替えます。 「GOボタン」をクリックしてください。
- Excelの上部構造にアクセス可能なウィンドウを開きました。 「分析パッケージ」項目についてチェックを立てる。 「OK」ボタンをクリックしてください。

さて、「データ」タブに移動すると、「分析」ツールバー「データ解析」ボタンの新規ボタンが表示されます。

回帰分析の種類
回帰にはいくつかの種類があります。
- パラボリック
- パワー;
- 対数
- 指数関数
- 気持ちいい。
- 双曲線
- 線形回帰
Exceleの最後のタイプの回帰分析の実装についてもっと話します。
Excelプログラムにおける線形回帰
以下に、一例として、路上の平均1日の空気温度が平均的なテーブルを提示し、適切な労働日の店舗バイヤーの数が示されている。 回帰分析の助けを借りて、気温の形の気象条件が商業機関の出席にどのように影響するかどうかを調べましょう。
線形種の退行方程式は以下の通りである.Y \u003d A0 + A1X1 + ... + AKK。 この式において、yは変数を意味し、私たちが探検しようとしている要因の影響を意味します。 私たちの場合、これは買い手の数です。 xの値は、変数に影響を与える様々な要因です。 パラメータAは係数回帰である。 つまり、特定の要因の重要性を判断するのです。 インデックスkは、これらの要因の総数を表す。


分析結果の分析
回帰分析の結果は、設定に示されている場所の表の形で表示されます。

主な指標の1つはR字形です。 モデルの品質を示します。 私たちの場合には この係数 0.705または約70.5%に等しい。 これは許容可能なレベルの品質です。 依存依存は0.5未満が悪い。
別の重要な指標は、「Y交差点」ラインと「係数」列との交差点のセル内に配置されている。 それはどのような値がyになるでしょう、そして私たちの場合では、これはバイヤーの数です。他のすべての要因はゼロに等しいです。 このテーブルはこの表の58.04です。
カウント「変数x1」および「係数」の交点における値は、XからのYの依存性レベルを示しています。私たちの場合、それは温度上のストアのクライアント数の依存度です。 1.31の係数は影響力のかなり高い指標と見なされます。
あなたが見ることができるように、助けて マイクロソフトプログラム Excelは回帰分析のテーブルを作るのは非常に簡単です。 しかし、出口で得られたデータを処理し、その本質を理解するために、準備人だけが可能になります。
私たちはあなたが問題を解決するのを助けることができることをうれしく思います。
問題の本質を詳細に演奏しながら、コメントに質問してください。 私たちの専門家はできるだけ早く答えようとします。
この記事はあなたを助けますか?
線形回帰法により、直接回線、最も適切な順序蒸気(x、y)を記述することができます。 線形方程式として知られている直線の方程式を以下に示します。
④ - 与えられた値xの期待値
xは独立変数です。
a - 直線のY軸を切り取る
b - 直線を傾ける。
次の図では、この概念はグラフィカルに表されます。
上の図は、式ν\u003d 2 + 0.5xで説明されている行を示しています。 軸の軸上のセグメントは軸の軸の交点です。 私たちの場合、a \u003d 2の勾配、b、l線の長さへの持ち上がり線の比は0.5です。 正の斜面は、線が左から右に上昇することを意味します。 B \u003d 0の場合、水平線は、従属変数と独立変数の間に接続がないことを意味します。 つまり、値xの変化はyの値には影響しません。
頻繁に混乱してŷとy。 この式に従って、グラフは6つの順序の点と線の対を示しま\u200b\u200bす。
この図では、順序付けされたペアX \u003d 2、Y \u003d 4に対応する点を示している。 h \u003d 2は√です。 次の式を使用してこれを確認できます。
○\u003d 2 + 0.5x \u003d 2 + 0.5(2)\u003d 3。
値uは実際の点で、値はyを使ってyの期待値です。 線形方程式 与えられた値xで。
次のステップは、順序付けられた蒸気のセットに対応する最大方程式を決定することであり、最小二乗法による式の形式が決定された前の記事でこれについて説明した。
Excelを使用して線形回帰を決定します
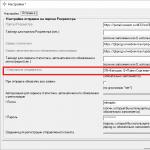
Excelに埋め込まれた回帰分析ツールを使用するには、アドインを有効にする必要があります。 分析パッケージ。 タブをクリックして見つけることができます ファイル - \u003eパラメータ(2007以降)、ダイアログボックスに表示されるダイアログボックスに パラメーターエクセルタブに行きます 上部構造フィールドで コントロール選ぶ 上部構造エクセルそしてクリックします go表示されるウィンドウで、私たちは反対のティックを置きます 分析パッケージzhmem。 OK。
タブに データグループで 分析新しいボタンが表示されます データ解析。
アドインの作業を実証するために、私たちは前の記事からのデータを使っています。 列Aとクリーンシートの入ったお風呂で、この例のデータを入力してください。
タブに行きます データ、グループで 分析クリック データ解析。表示されるウィンドウで データ解析 選ぶ 回帰図に示すように、[OK]をクリックします。
ウィンドウに必要な回帰パラメータをインストールします 回帰写真のように:
クリック OK。得られた結果を下図を示します。
これらの結果は、前の記事で独立したコンピューティングによって受け取ったものに対応しています。
回帰分析は、1つまたは複数の独立した変数からのパラメータの依存性を示す統計的研究方法です。 特に大量のデータがあった場合、アプリケーションは複雑な時代に使用するのが困難でした。 今日、Excelで回帰を築く方法を学ぶ、あなたは文字通り数分で複雑な統計タスクを解決することができます。 以下を表しています 具体的な例 経済学の分野から。
回帰の種類
このコンセプト自体は1886年に数学フランシス・ガルトに導入されました。 回帰が起こります:
- 線形;
- パラボリック
- パワー;
- 指数関数
- 双曲線
- 気持ちいい。
- 対数
実施例1。
チームのメンバーの数の数の依存性を6産業企業の平均給与から決定するという課題を考えてみましょう。
仕事。 6つの企業では、月平均賃金と自分の要求を辞めた従業員の数を分析しました。 表形式で:
6企業の平均給与から圧倒された労働者の量の依存性を判断するという課題は、回帰モデルは式y \u003d A0 + A1×1 + ... + akxkの形式を有する。ここで、XI - 影響変数AI回帰係数、AKは要因数です。
このタスクでは、yは声をかけた従業員、そして影響因子 - XがXで示される人の指標です。
「Excel」テーブルプロセッサの機能を使用する
Excelの回帰分析は、組み込み関数の既存の表データへのアプリケーションが先行する必要があります。 しかし、これらの目的のためには、非常に有用な上部構造「分析パッケージ」を使用することをお勧めします。 それを有効にするには、次のようにします。
- [ファイル]タブから[パラメータ]セクションに移動します。
- 開くウィンドウで、「超構造」文字列を選択します。
- 行「管理」の右側にある「GOボタン」をクリックしてください。
- 「分析パッケージ」という名前の横にあるチェックを入れ、[OK]をクリックしてアクションを確認します。
すべてが正しく行われたら、ワークステーション「Excel」の上にある「データ」タブの右側に、目的のボタンが表示されます。
Excelの線形回帰
現在、計算計算の実装に必要なすべての仮想ツールがある場合は、私たちのタスクを解決するために進むことができます。 このため:
- 「データ分析」ボタンをクリックしてください。
- 開くウィンドウで、「回帰」ボタンをクリックしてください。
- 表示されるタブでは、Y(廃止された従業員数)とXの値の範囲を入力します(廃棄物)。
- 「OK」ボタンを押して操作を確認してください。
その結果、プログラムは自動的に回帰分析データを持つ新しいテーブルプロセッサのシートを記入します。 注意! Excelは、この目的のためにあなたが好む場所を独立して尋ねる能力を持っています。 たとえば、値がYとX、さらには同じシートである場合があります。 新しい本そのようなデータを保存するために特別に設計されています。
R字形の回帰結果の解析
に Excelデータ 考慮された例の処理中に得られた例は、以下のとおりです。
まず第一に、あなたはR四角形の値に注意を払うべきです。 判定係数です。 に この例 R標準\u003d 0.755(75.5%)、すなわち、計算されたモデルのパラメータは、検討中のパラメータ間の関係を75.5%で説明する。 決定係数の値が高いほど、選択されたモデルは特定のタスクに適していると考えられる。 0.8を超えるR四方の値を実際の状況を正しく説明すると考えられています。 R字形TKRの場合、線形方程式の自由メンバーの無意味の仮説は拒絶される。
「Excel」ツールを使用して、自由メンバーの検討中の問題において、T \u003d 169,20903、およびP \u003d 2.89E-12、すなわち、我々は自由のわからないという正しい仮説がゼロの確率を有する。メンバーは拒否されます。 未知のT \u003d 5,79405、およびP \u003d 0.001158の係数の場合。 言い換えれば、係数の無意味の正しい仮説が未知で拒絶される可能性は0.12%である。
したがって、結果として生じる線形回帰の方程式は十分にあると主張することができる。
株式のパッケージを購入することの実現可能性に関するタスク
Excelの複数回帰は、全「データ解析」ツールを使用して実行されます。 特定の適用タスクを検討してください。
管理会社「NNN」は、MMM JSCで20%の株式を購入することの実現可能性を決定する必要があります。 パッケージ(SP)のコストは7000万ドルです。 専門家「NNN」同様のトランザクションに関するデータを収集しました。 そのようなパラメータでのステークのコストを評価することを決定しました。
- 買掛金(VK)
- 年間売上高の量(VO)
- 債権(VD);
- 固定資産のコスト(SOF)。
さらに、賃金企業(V3 P)の何千ドルの和解が使用されています。
テーブルプロセッサの解決策ツール
まず最初に、ソースデータのテーブルを作成する必要があります。 次の形式です。
- 「データ分析」ウィンドウを呼び出します。
- 「回帰」のセクションを選択してください。
- 「入力間隔y」ウィンドウでは、列Gからの従属変数の値の範囲が導入されています。
- 「Interval X」ウィンドウの右側にある赤い矢印を持つアイコンをクリックして、からのすべての値の範囲を割り当てます。 列B、C、D、F。
項目「新しい作業リスト」をクリックし、「OK」をクリックしてください。
このタスクの分析を受け取る。
結果と結論の研究
上記の丸みを帯びたデータから、テーブルプロセッサExcelのシート、回帰式のシートから「集める」
SP \u003d 0.103 * SOF + 0.541 * VO - 0.031 * VK + 0.405 * VD + 0.691 * VZP - 265,844。
より身近な数学的形式では、次のように書くことができます。
y \u003d 0.103 * X1 + 0,541 * X2 - 0.031 * X3 + 0,405 * X4 + 0,691 * X5 - 265,844
MMM JSCのデータを表:
それらを回帰式に代入すると、6472万ドルの姿を受け取ります。 これは、7000万ドルのコストが十分に過大評価されているため、MMM JSCの株式を購入しないでください。
ご覧のとおり、「Excel」テーブルプロセッサと回帰式の使用は、完全に具体的な取引の実現可能性に関して合理的な決定を採用することを可能にしました。
今、あなたはどの回帰があるか知っています。 上記のExcelの例は、経済学の分野からの実用的な仕事を解決するのに役立ちます。
MS Excelパッケージは、線形回帰方程式の構造を非常に迅速に作動させることを可能にします。 得られた結果をどのように解釈するかを理解することが重要です。 回帰モデルを構築するには、Service \\ Data Analysis \\ Regressionを選択する必要があります(Excel 2007このモードはデータ/データ解析単位/回帰にあります)。 その後、結果を分析ユニットにコピーします。

私の意見では、学生として、経済学は私が私の大学の壁に知り合いになることができたすべてのものから最も適用されている科学の1つです。 これを使用すると、実際には、企業全体で適用されたタスクを解決できます。 これらのソリューションの効果的な効果的な問題は、3番目の質問です。 一番下の線は、ほとんどの知識が理論のままであるということですが、経済学や回帰分析は依然として特別な注意を払って勉強する価値があります。
回帰を説明しますか?
MS Excel関数を検討する前に、あなたがこれらのタスクを解決できるようにする前に、本質的に回帰分析を意味するというあなたの指であなたに説明したいと思います。 だからあなたが試験を受けることはあなたが試験を受けることが簡単になり、最も重要なことに、それは主題を研究するのが興味深いです。
数学の関数の概念に精通していることを願っていましょう。 関数は2つの変数の関係です。 1つの変数を変更するときは、もう一方のものが起こります。 xを変更し、それぞれyを変更します。 機能はさまざまな法律を説明しています。 機能を知ることで、xの任意の値を代用してyを見てもらえます。
回帰は、非体系的かつカオス的なプロセスで一目で一目で特定の機能の助けを借りて説明しようとする試みであるため、非常に重要です。 それで、例えば、あなたはロシアのドルと失業の関係を特定することができます。
このパターンが検出された場合は、計算中に受信した機能に従って、ルーブルに関連してN-OHMドル率での失業レベルとなる予測を行うことができます。
この関係は相関と呼ばれます。 回帰分析は相関係数の計算を含み、それは検討中の変数(ドルコースとジョブ数)間の関係の厳しさを説明する。
この係数は正と負にすることができます。 その値は-1から1の範囲にあります。したがって、私たちは高い否定的または正の相関を観察することができます。 それが肯定的であれば、ドルの増加は続き、新しい仕事の出現が続きます。 それが否定的であれば、コースを増やすための仕事の減少があるでしょう。
回帰はいくつかの種です。 それは線形、放物線状、電力、指数関数などです。 どの回帰が私たちの場合に特に満たされるかに応じてモデルの選択をします。このモデルは私たちの相関にできるだけ近くになります。 タスクの例としてこれを考慮し、MS Excelで解決してください。
MS Excelの線形回帰
線形回帰の問題を解決するには、「データ分析」機能が必要になります。 それはあなたに含まれないかもしれないのでそれを有効にする必要があります。
- 「ファイル」ボタンをクリックしてください。
- 項目「パラメータ」を選択してください。
- 左側の「超構造」の最後のタブをクリックしてください。
- 下から碑文「管理」と「GO」ボタンが表示されます。 クリックして;
- 「分析パッケージ」にチェックを入れてください。
- 「OK」をクリックしてください。

タスクの例
バッチ分析機能が有効になります。 以下のタスクを使用します。 企業内のPEの数と雇用された労働者数について数年間データのサンプルがあります。 これら2つの変数間の関係を特定する必要があります。 説明変数Xがあります - これは労働者の数であり、説明可能な変数 - yは緊急事態の数です。 送信元データを2列に配布します。
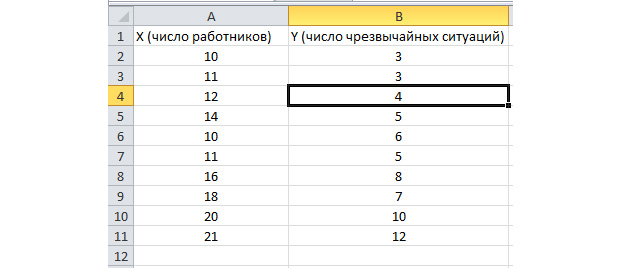
「データ」タブに行き、「データ分析」を選択しましょう。
表示されるリストで、「回帰」を選択してください。 入力間隔YとXでは、対応する値を選択します。
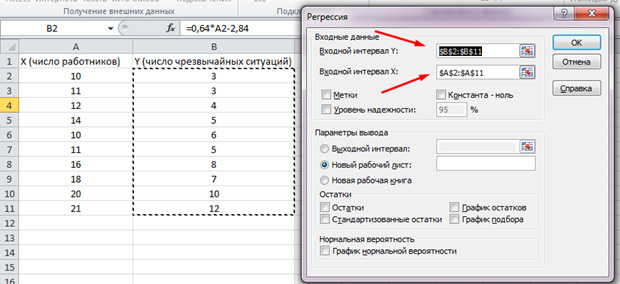
「OK」をクリックしてください。 解析が生成され、新しいシートでは結果がわかります。
私たちにとって最も重要な値は下図のマークされています。
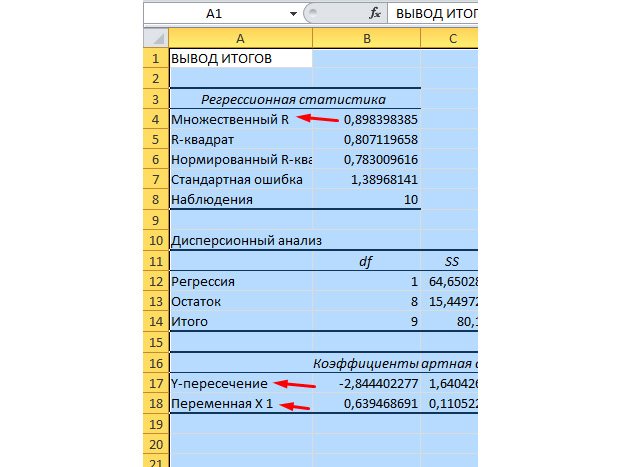
複数のRは判定係数である。 複雑な計算式があり、相関係数を信頼する方法を示します。 したがって、この値が多いほど、信頼できるほど、私たちのモデルは全体として強くなります。
y交差点と交差点X1は私たちの回帰の係数です。 既に述べたように、回帰は関数であり、彼女は特定の係数を持っています。 したがって、私たちの関数は次のように見えます:y \u003d 0.64 * x-2.84。
私たちにそれを与えるのは何ですか? これは私達に予測をする機会を与えます。 私たちは企業上で25の労働者を雇いたいと思うとします、そして、私たちは緊急事態の数がどのようになるかをおおよそ想像する必要があります。 この価値を当社の機能に置き換え、結果Y \u003d 0.64 * 25 - 2.84を取得します。 約13 ppが発生します。
それがどのように機能するか見てみましょう。 下の図面を見てください。 関係する従業員の事実上の値では、事実値が置き換えられます。 本物の娯楽をどのように重要であるかを見てください。

「挿入」タブをクリックしてポイント図を選択して、IPSとICS領域を選択して相関フィールドを構築することもできます。

ポイントは角に移動しますが、一般に、ラインが真ん中にあるかのように動きます。 また、MS Excelの[レイアウト]タブをクリックしてトレンドライン項目を選択することで、この行を追加することもできます。
表示された行に沿って2回クリックし、以前に述べられたものを見てください。 相関フィールドのように見える方法に応じて、回帰の種類を変更できます。
おそらく、ポイントがパラボラを描画し、直接回線ではなく、別のタイプの回帰を選択するのに適しているようです。
結論
この記事があなたに回帰分析が必要なのか、そしてそれが必要なものについての理解を深めることを願っていました。 これすべてが大きな適用価値があります。
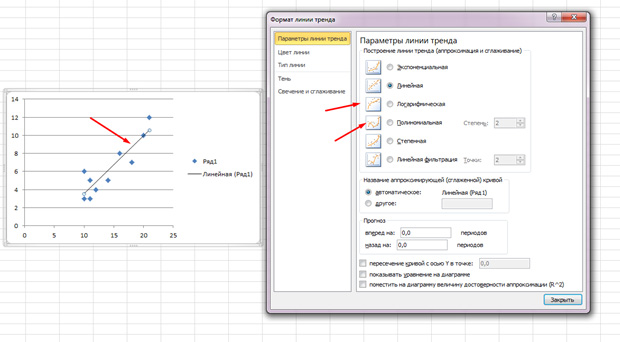
に エクセル 線形回帰スケジュール(そしてCMとしての非線形回帰の主要な種類でさえも)を構築するためのさらに高速でより便利な方法があります。 これは次のようにすることができます。
1)データで列を割り当てます バツ。 そして y。 (彼らはこの順序で見つけるべきです!);
2)呼び出します マスターチャート そしてグループで選ぶ タイプ – p そしてすぐにプレスします 準備ができて;
3)ダイアグラムから選択をドロップすることなく、表示される最初の項目項目を選択します ダイアグラムあなたはアイテムを選ぶべきです トレンドラインを追加してください;
4)ダイアログの表示ダイアログボックスで トレンドライン タブに タイプ選ぶ 線形;
5)タブに パラメータースイッチを有効にすることができます チャートの方程式を示すこれにより、係数(4.5)が計算される線形回帰式(4.4)を見ることができます。
6)同じタブで、スイッチを有効にすることができます ダイアグラム上の近似精度の値(R ^ 2)を配置する(R ^ 2)。 この大きさは相関係数(4.3)の二乗であり、計算式に実験的依存性をどの程度うまく表すかを示しています。 もし r 2は単位に近い、理論回帰方程式は実験的な依存を表しています(理論は実験とよく一致しています)、そして r 2ゼロに近い、その後 この方程式 実験的依存性を説明するのには適していない(理論は実験と一致していません)。
説明された動作の実行の結果として、回帰スケジュールおよびその方程式を有する図が得られるであろう。
§4.3。 主種 非線形回帰
パラボラおよび多項式の回帰
パラボリック 大きさの依存 y。 マグニチュードから h 依存関係は二次関数(2次パラボラ)と呼ばれます。
この式は求められます 放物線回帰の方程式 上に h。 パラメーター だが, b, から 呼び出す 放物線退行係数の係数。 放物線回帰係数の計算は常に面倒なので、計算にコンピュータを使用することをお勧めします。
パラボラ回帰の式(4.8)は、多項式と呼ばれるより一般的な回帰の特別なケースです。 多項式 大きさの依存 y。 マグニチュードから h Polynomialによって表現された依存関係と呼ばれます n注文:
数字の数 a i。 (私。=0,1,…, n) 多項式回帰係数の係数.
消費電流
力 大きさの依存 y。 マグニチュードから h フォームの依存関係が呼び出されます。
この式は求められます 消費電流の方程式 上に h。 パラメーター だが そして b 呼び出す 消費電流の係数.
ln \u003d ln。 a.+bln。 バツ。. (4.11)
この式は、LNの対数座標軸を持つ平面上の直接を表します。 バツ。 そしてln。 したがって、電力回帰の適用性の基準は、経験データLNの対数のポイントが要求されていることです。 x i。 そしてln。 私。 それらは線に最も近い(4.11)。
指標回帰
indic indic(または又は 指数関数)大きさの依存 y。 マグニチュードから h フォームの依存関係が呼び出されます。
(または)。 (4.12)
この式は求められます 式は示します (または又は 指数関数) 退職 上に h。 パラメーター だが (または又は k) 私。 b 呼び出す 係数を示す (または又は 指数関数) 回帰.
電力回帰式の両方の部分が事例である場合、式は次に
ln \u003d。 バツ ・ln。 a.+ ln。 b (またはln \u003d k・X。+ ln。 b). (4.13)
この式は、別の値からの単一のLN値の対数の線形依存性を表しています。 バツ。。 したがって、消費電流の適用性の基準は、同じ大きさの経験的データの点が要求されていることです。 x i。 そして他のLNの大きさの対数 私。 彼らは直接(4.13)に最も近いです。
対数回帰
対数大きさの依存 y。 マグニチュードから h フォームの依存関係が呼び出されます。
=a.+bln。 バツ。. (4.14)
この式は求められます 対数回帰の方程式 上に h。 パラメーター だが そして b 呼び出す 対数回帰係数.
双曲線回帰
双曲線 大きさの依存 y。 マグニチュードから h フォームの依存関係が呼び出されます。
この式は求められます 双曲線回帰の方程式 上に h。 パラメーター だが そして b 呼び出す 双曲線回帰の係数 そして最小の正方形の方法によって決定されます。 この方法を使用すると、式があります。
式(4.16-4.17)の合計はインデックスによって行われます 私。 観察数から観察数まで n.
残念ながら、 エクセル 双曲線回帰の係数を計算する機能はありません。 測定値が逆比例に関連していることが知られていない場合、電力回帰式を求めるための双曲線回帰式の代わりに推奨される。 エクセル その場所の手順があります。 測定値の間に双曲線依存性が想定されている場合、その回帰係数は式(4.16-4.17)に従って補助計算テーブルと合計操作を使用して計算する必要があります。