Microsoft SQLServerデータベースの復元。 データベースの回復
DBMSの主な要件の1つは、外部メモリのデータストレージの信頼性です。 ストレージの信頼性とは、ハードウェアまたはソフトウェアに障害が発生した後、DBMSがデータベースの最後の一貫した状態を復元できる必要があるという事実を指します。 通常、ハードウェア障害には2つのタイプが考えられます。コンピュータの突然の停止(たとえば、緊急電源オフ)として解釈できるいわゆるソフト障害と、メディア上の情報の損失を特徴とするハード障害です。 。 外部メモリ。 ソフトウェア障害の例としては、DBMSのクラッシュ(ソフトウェアエラーまたは何らかのハードウェア障害による)またはユーザープログラムのクラッシュがあり、一部のトランザクションが不完全なままになります。 最初の状況は、特殊な種類のソフトハードウェア障害と考えることができます。 後者が発生した場合、1つのトランザクションのみの結果を排除する必要があります。
いずれにせよ、データベースを復元するには、いくつかの追加情報が必要です。 つまり、データベース内のデータストレージの信頼性を維持するには、冗長なデータストレージが必要であり、リカバリに使用されるデータの一部を特に確実に保存する必要があります。 このような冗長な情報を維持するための最も一般的な方法は、データベースの変更のログを保持することです。
ログはデータベースの特別な部分であり、DBMSユーザーは利用できず、細心の注意を払って維持されます(ログの2つのコピーが異なる場所にある場合もあります)。 物理ディスク)、データベースの主要部分のすべての変更のレコードを受け取ります。 ロギングするとき、それらは「プリエンプティブ」書き込みの戦略に従います。これは、変更されたオブジェクトがの外部メモリに入る前に、データベースオブジェクトの変更のレコードがログの外部メモリに入る必要があるという事実から成ります。データベースの主要部分。 この状態がDBMSで正しく観察されれば、ログの助けを借りて、障害後にデータベースを復元する際のすべての問題を解決できることが知られています。
ソフトクラッシュ中、データベースの主要部分の外部メモリには、クラッシュ時までに終了していないトランザクションによって変更されたオブジェクトが含まれている場合があり、トランザクションによって変更されたオブジェクトがクラッシュ時までに正常に完了していない場合があります。クラッシュしますが、外部メモリに書き込まれていません。 ソフト障害後のリカバリプロセスの目標は、データベースの主要部分の外部メモリの状態です。これは、完了したすべてのトランザクションの変更が外部メモリにコミットされたときに発生し、未完了の痕跡は含まれません。トランザクション。 これを実現するために、未完了のトランザクションが最初にロールバックされ、次に完了したトランザクションの操作が再生され、その結果は外部メモリに表示されません。 ハード障害後にデータベースを復元するには、データベースのログとアーカイブコピーを使用します。 アーカイブコピーは、ログがいっぱいになるまでのデータベースの完全なコピーです。 ハード障害後の通常のデータベースリカバリでは、ログが失われないようにする必要があります。 次に、データベースの復元は、アーカイブコピーに基づいて、障害が発生するまでに終了したすべてのトランザクションの作業をログに再現するという事実に基づいています。
信頼性の観点からロギングには特別な要件がありますが、原則として失われる可能性もあります。 次に、データベースを復元する唯一の方法は、バックアップコピーに戻ることです。 もちろん、この場合、データベースの最後の一貫した状態を取得することはできませんが、何もないよりはましです。
ログがいっぱいになったときにデータベースをアーカイブする最も簡単な方法。 いわゆる「イエローゾーン」がジャーナルに導入され、そこに到達すると、新しいトランザクションの形成が一時的にブロックされます。 すべてのトランザクションが終了し、データベースが一貫性のある状態になったら、それをアーカイブしてから、ログへの入力を再開できます。
ログがいっぱいになるよりも少ない頻度でデータベースをバックアップできます。 ログがいっぱいになり、開始したすべてのトランザクションが終了したら、ログ自体をアーカイブできます。 このようなアーカイブログは、基本的にデータベースのアーカイブコピーを再作成するためにのみ必要であるため、アーカイブ中にログ情報を大幅に圧縮できます。
バックアップからデータを復元する方法を学ぶ必要があります。 ハードウェア障害が発生した場合、または別のサーバーに既存のデータベースの完全に同一のコピーを作成する必要がある場合は、復元が必要になることがあります。
Simple Recovery Modelを使用してデータベースを復元する場合は、最新の完全バックアップのみを復元する必要があることを忘れないでください。 フルリカバリモデルまたはバルクリカバリモデルを使用している場合は、フルバックアップ、最後の差分バックアップ、およびトランザクションログのすべてのコピーを復元する必要があります。 回復プロセスを詳しく見てみましょう。
フルバックアップからのデータベースの復元。
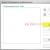
リカバリモデルに関係なく、最初のステップは常に最新の完全バックアップを復元することです。 Enterprise Managerでデータベースを復元するには、データベースを強調表示してダブルクリックします 右クリックマウスを選択して選択します コンテキストメニュー「すべてのタスク>データベースの復元」をクリックすると、図Aに示すダイアログボックスが開きます。
図A。
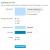
[データベースの復元]ダイアログボックスでは、最近のすべてを表示できます バックアップ年代順に。 そこで、復元するデータベースを選択することもできます。 図Bに示す[オプション]タブでは、次のオプションを選択できます。
- 各バックアップを復元した後、テープを取り出します
- 各バックアップの復元を開始する前にプロンプトを表示します(各バックアップの復元を開始する前に追加の警告を表示します)
- 既存のデータベースを強制的に復元します。このオプションは、T-SQLでの移動と同等です。
図B。

ウィンドウの下部には、バックアップが復元された後のデータベースの状態を判別できる3つのスイッチがあります。
- データベースを運用可能にしておきます。 追加のトランザクションログは復元できません。
- この値を選択すると、バックアップがロードされた後、復元プロセスが開始され、保留中のすべてのトランザクションがロールバックされます。 トランザクションログの追加のコピーをダウンロードすることはできなくなります。 ユーザーはデータベースを正常に操作できるようになります。
- データベースを動作不能のままにしますが、追加のトランザクションログを復元できます。
- コピーがダウンロードされた後、データベースは一時的に利用できなくなります。 追加のコピーをダウンロードしてから、復元プロセスを開始する必要があります。
- データベースを読み取り専用のままにして、追加のトランザクションログを復元できるようにします。
- データベースは読み取り専用になります。 追加のトランザクションログバックアップをダウンロードできます。 このオプションは、スタンバイサーバー(スタンバイサーバー)を作成するために使用されます
データベースとトランザクションログの復元は、[OK]をクリックするのと同じくらい簡単です。
T-SQLを使用したデータベースの復元。
データベースのリカバリは、EnterpriseManagerよりも多くのオプションを提供するT-SQLを使用して実行することもできます。 使用構文 T-SQLコマンド次:
データベースの復元( データベース名 | @
database_name_var }
[ から< backup_device > [ ,
...n ] ]
[と
[RESTRICTED_USER]
[ [ ,
]ファイル =
{ ファイル番号 | @
ファイル番号 } ]
[ [ ,
]パスワード =
{ パスワード | @
password_variable } ]
[ [ ,
]メディアネーム =
{ media_name | @
media_name_variable } ]
[ [ ,
]メディアパスワード =
{ mediapassword | @
mediapassword_variable } ]
[ [ ,
]動く "
logic_file_name"
に "
operation_system_file_name"
]
[ ,
...n ]
[ [ ,
] KEEP_REPLICATION]
[ [ ,
](NORECOVERY | RECOVERY | STANDBY =
undo_file_name } ]
[ [ ,
](NOREWIND | REWIND)]
[ [ ,
](NOUNLOAD | UNLOAD)]
[ [ ,
]交換]
[ [ ,
]再起動]
[ [ ,
]統計[ =
パーセンテージ ] ]
各オプションの詳細については、SQL Server 2000 BooksOnlineの説明を参照してください。
図Cは、バックアップデバイスからの完全バックアップからのPubsデータベースの復元を示しています。
図C。

差分コピーからのデータベースの復元。
フルリカバリモデルまたはバルクリカバリモデルを使用している場合は、最初にフルバックアップを復元し、次に最後の差分バックアップとすべてのトランザクションログを復元する必要があります。 差分コピーを使用してデータベースの復元を実行するには、Enterprise Managerでデータベースを選択し、マウスの右ボタンでデータベースをダブルクリックして、コンテキストメニューから[すべてのタスク]> [データベースの復元]を選択し、完全コピーと差分コピーの復元を選択します。データベースの[OK]をクリックします。 (図D)
図D

差分コピーを使用して復元を実行するRestoreコマンドの構文を図Eに示します。
図E。

トランザクションログの復元。
トランザクションログの復元を開始する前に、データベースの完全で最新の差分コピーを復元する必要があります。 その後、トランザクションログを適切な順序で復元できます。 Enterprise Managerを使用している場合は、データベースを選択し、マウスの右ボタンでダブルクリックして、コンテキストメニューから[すべてのタスク]> [データベースの復元]を選択し、必要なすべてのコピーを選択し、必要に応じてポイントを選択する必要があります。時間復元オプション(特定の時点に復元)(図F)。
図F。

トランザクションログを復元するためのRestoreコマンドの構文を図Gに示します。
図G。

まとめましょう。 バックアップデータベースの回復は、データベース管理者の主要で最も重要なタスクの1つです。 いつでも、データベースを復元する能力を確認する必要があります SQLサーバー災害復旧計画に従って2000年。 災害復旧計画がない場合は、計画を立てることをお勧めします。 何かが起こってデータが失われた場合、あなたにとっての次の損失はあなたの仕事の損失かもしれません。
今日のレッスン: MySQL。(MySQLは無料のデータベース管理システムです)。 データベースの復元は非常に簡単ですが、このためにはデータベースのバックアップコピーが必要です。 データベースに問題があったとき、サイトにアクセスできず、すべての記事が消えました。 Wordprerssデータベースを復元する方法を緊急に決定する必要がありました。
この状況は、私がレッスン59を書いていた数日前に私に起こりました。 ほんの数分後、Yandex-Metricaから自分のサイトが利用できないというSMSを受け取りました。 以前にこのような問題が発生したことがある場合は、すべてを動作状態に戻す方法を知っています。そうでない場合は、読み進めてください。
WordPressデータベースを復元する方法(方法1)
インターネットでは、主にデータベースのバックアップ方法を書いていますが、書いている人はほとんどいません。 WordPressデータベースを復元する方法 。 必ずしも データベースあなたの過失により問題が発生する可能性があります。 他の理由でもデータベースでエラーが発生する可能性があります。
ブログにプラグインなどがまだインストールされていない場合は、ブログがないままになるリスクがあります。 あなたが長い間、そして一度だけブログを書いていると想像してみてください、そしてそれはそれです! アンバ! このプラグインはそれが起こらないようにします。 それはあなたのブログデータベースを永久に保持します 自動モードそしてあなたの参加なしで。
インターネット上にはデータベースの復旧に関する情報がたくさんありますが、時にはそのようなナンセンスを書いているので、人々も感謝しています。 記事の著者はこれとそれを正しく行う方法についてアドバイスを与えますが、彼自身は彼が何について書いているのかさえ理解していません。 皆さん、ビジネスに取り掛かる時が来ました🙂
ブログを以前の状態に復元するには、データベースを新しくバックアップする必要があります。 ベースファイルを解凍し、解凍したファイルをWindowsのメモ帳で開きます。 ファイルの内容をにコピーします。 PhpMyAdminでホスティングのコントロールパネルに移動します。
復元するデータベースの名前をクリックします。
次に、をクリックする必要があります 「SQL"をクリックし、データベースファイルからコピーしたものをボックスに貼り付けます。 CTRL " + "V"。を押してから" わかった ".

データベースのリカバリが完了するのを待っています。 成功メッセージが表示されます。

これで、ブログが完全に復元されました。
WordPressデータベースをすばやく復元する方法(方法2)
したがって、これ以上の紹介はありません。 ホスティングコントロールパネル(cPanel)に移動します。 リンクを探す " MySQL" また " PhpMyAdmin ».

次に、データベース管理パネル、つまりPhpMyAdminにログインする必要があります。 押す " 入って»

PhpMyAdminに移動します。 左側で、復元するデータベースをクリックします。 私の場合、これはdvpressベースです。

データベースを選択すると、そのデータベース内のすべてのテーブルが表示されます。 リカバリ中にエラーが発生しないようにするには、このデータベースを完全に削除する必要があります。 一番下まで行って見つけます すべて選択/すべて選択解除 "。 クリック " すべて選択 」、すべてのデータベーステーブルにチェックボックスがあります。 右のボックスで選択 消去"、次に確認してください" はい"。データベースからすべてのテーブルを完全に削除する必要があります。

ここでのタスクは、バックアップからこのデータベースを復元することです。 上をクリックしてください 輸入"、ボタンをクリックしてください" ファイルを選択 "。 コンピュータ上のデータベースバックアップを見つけて、[ 開ける"。 下部にあるPhpMyAdminで、[ わかった"。 操作は成功する必要があります。これは、「 SQLクエリ正常に完了しました ».
先週投稿したもので、興味をそそられたようですが、残念ながら「練習」が入っていませんでした。 はい、データを保存する方法を説明していますが、例はありません。
当初は同じ作者による別の翻訳をしたかったのですが、考えてから「自分で」投稿することにしました。 私がそうするように促した理由は、投稿の最後のメモで説明します。
SQLServerでのデータベースの復元
前の記事で述べたように、クラスター化インデックスまたはヒープページが破損した場合、これらのページに含まれるデータは失われ、それらを復元する唯一のオプションはデータベースを直接復元することです。SQL Serverには、データベースを回復するための多くのオプションが用意されています。 まず、これはデータベース全体の復元です。データベースのサイズと速度によっては、かなりの時間がかかる場合があります。 ハードドライブ)。 次に、個々のファイルグループ、またはデータベースが複数のファイルグループ(またはそれぞれファイル)で構成されている場合はファイルを復元します。 この場合、残りの部分に影響を与えることなく、データベースの損傷した部分のみを復元することができます。 これらの2種類のデータベース回復は非常に頻繁に使用されるため、これ以上説明しません。
第3に、SQL Server 2005では、個々のデータベースページを復元する機能が導入されました。この場合、指定されたページのみがバックアップから復元されます。 このような回復は、DBCC CHECKDBが、大量のファイルに「横たわっている」巨大なテーブルでいくつかの破損したページを見つけた場合に特に関係があります。 ファイル全体が復元されるわけではなく、テーブル全体が復元されるわけではなく、数ページしか復元されないため、ダウンタイムを大幅に削減できます。
要件と制限
リカバリモデルとトランザクションログバックアップの可用性
覚えておくべき最も重要なことは、単一のページを復元するには、データベースが完全な(完全な)回復モデル、または一括ログ記録された回復モデルを使用する必要があるということです。 データベースが単純な(単純な)リカバリモデルである場合、これ以上読むことはできません。2番目の要件は、完全バックアップとトランザクションログバックアップが壊れないログチェーンを形成する必要があることです。 BACKUP LOG WITH TRUNCATE_ONLY(NO_LOG)コマンドを実行したことがない場合は、 シンプルなモデル復元してトランザクションログを削減すると、ページが破損していない最後の完全バックアップ以降のすべてのトランザクションログバックアップ(この最も完全なバックアップを含む)があります。ログチェーンについて心配する必要はありません。
バルクログリカバリモデルでは、理論的には、上記の条件が満たされ、復元されるページが最小限のログ操作によって変更されていない限り、個々のページリカバリは正常に機能するはずです。
SQLServerのエディション
ページの回復はSQLServerのどのエディションでも可能ですが、EnterpriseEditionおよびDeveloperEditionの場合、破損したページをオンラインで回復することができます。 リカバリ中にデータベースにアクセスできます(さらに、これらのページ自体が「影響を受けていない」場合は、現在復元されているページが属するテーブルにもアクセスできます。そうでない場合、要求は失敗します)。 Enterprise Editionの「下」のエディションの場合、ページのリカバリはオフラインで実行され、リカバリ期間中はデータベースが使用できなくなります。破損したページタイプ
インデックスページまたはデータが破損した場合、EnterpriseEditionでオンラインで回復できます。重要なシステムテーブルに属するページは復元できますが、復元すると、どのエディションのSQLServerでもデータベースにアクセスできなくなります。
「ロケーションカード」は「個別に」復元することはできません。 GAM、SGAM、PFS、ML、DIFFページが破損している場合は、データベース全体を復元する必要があります。 唯一の例外はIAMページです。 これらは「配置マップ」を参照していますが、データベース全体ではなく1つのテーブルのみを記述しており、それらを回復することができます。
データベースブートページ(1番目のデータベースファイルの9ページ)とファイルヘッダーページ(各ファイルの0ページ)は「個別に」復元できません。これらが破損している場合は、データベース全体を復元する必要があります。
実際、回復
さて、ついに、私たちは理論から実践へと移ります。まず、トレーニングには、破損したデータベースが必要です。
データベースの移植
実験には、SQLServerに付属のAdventureWorksデータベースを使用します。 インストールしていない場合は、をダウンロードできます。 私はそれを完全な回復モデルに変換します:ALTER DATABASE AdventureWorks SET RECOVERY FULLまだエラーがないことを確認してください:
DBCC CHECKDB( "AdventureWorks")WITH NO_INFOMSGS、ALL_ERRORMSGS、DATA_PURITYを使用して、完全バックアップを作成します。
データベースAdventureWorksをディスクにバックアップ= "D:\ tmp \ aw_backups \ aw_full_ok1.bak"
このデータベースでは、クラッシュテーブルを作成します。
CREATE TABLEクラッシュ(txt varchar(1000))SQL Serverが、SQL Server自体が書き込んだデータではなく、突然その中に何が発生するかを確認するために、varchar型フィールドを台無しにします。
あなたが何かを台無しにする前に、あなたはそれを何かで満たす必要があります。 作成したテーブルの左側のデータをハンマーで叩きます。
DECLARE @i INT SET @i = 1 WHILE @ iにNOCOUNTを設定します<100000
BEGIN
INSERT INTO crash
SELECT REPLICATE("a", 1000)
SET @i = @i + 1
END
SET NOCOUNT OFF
Теперь делаю резервную копию журнала транзакций:
バックアップログAdventureWorksTO DISK = "D:\ tmp \ aw_backups \ aw_log_ok1.trn"
次に、データを少し変更しましょう。 
これで、すべての準備が整いました。 データベースを切断し、FAR "om(またはより便利な方)を使用してmdfファイルを開き、その中の文字列" zzzzzzz "を探し、いくつかの" z "を任意の文字に置き換えます。 
データベースが破損したので、接続します。 そして、はい、前回の記事で、データベースをデタッチ/アタッチするべきではないと明確に述べられていたことを覚えています。 しかし、私たちの場合、それは絶対に「安全」です-「疑わしい」データベースは落ちません。
間違いを探す
したがって、破損したデータベースは正常にサービスに戻りました。 整合性チェックをもう一度実行してみましょう。DBCC CHECKDB( "AdventureWorks")WITH NO_INFOMSGS、ALL_ERRORMSGS、DATA_PURITY結果は、期待どおりです( 破損したページの数を忘れないでください!):
メッセージ8928、レベル16、状態1、行1
オブジェクトID1883153754、インデックスID 0、パーティションID 72057594054246400、割り当てユニットID 72057594061651968(タイプ行内データ):ページ(1:20455)を処理できませんでした。 詳細については、他のエラーを参照してください。
メッセージ8939、レベル16、状態98、行1
テーブルエラー:オブジェクトID 1883153754、インデックスID 0、パーティションID 72057594054246400、割り当てユニットID 72057594061651968(行内データのタイプ)、ページ(1:20455)。 テスト(IS_OFF(BUF_IOERR、pBUF-> bstat))が失敗しました。 値は29493257と-4です。
CHECKDBは、テーブル「crash」(オブジェクトID 1883153754)で0個の割り当てエラーと2個の整合性エラーを検出しました。
CHECKDBは、データベース「AdventureWorks」で0個の割り当てエラーと2個の整合性エラーを検出しました。
repair_allow_data_lossは、DBCC CHECKDB(AdventureWorks)によって検出されたエラーの最小修復レベルです。
V この場合ヒープ自体のデータが破損しているため(インデックスID = 0)、SQLServerはこのデータを回復できません。
現在、3つのオプションがあります。
- データ損失を受け入れ、DBCC CHECKDB( "AdventureWorks"、REPAIR_ALLOW_DATA_LOSS)を実行します
- トランザクションログのアクティブな部分のバックアップを作成し、データベース全体を復元します-結果としてデータが失われることはありませんが、時間がかかります
- トランザクションログのアクティブな部分のバックアップを作成し、破損したページを1つだけ復元します(!)
破損したページの復元
まず、トランザクションログの最後のフラグメントのバックアップを作成する必要があります(テールバックアップ)。 同時に、Enterprise Editionを使用している場合、NORECOVERYパラメーターを追加することはできません。これにより、データベースは「復元中」の状態になります。これは、このエディションがオンライン・ページのリカバリーをサポートしているためです。 さらに、トランザクションログのバックアップを定期的に実行している場合は、ログチェーンを壊さないように、EnterpriseEditionでCOPY_ONLYバックアップを作成できます。オフラインリカバリのパスをたどって実行します。
バックアップログAdventureWorksTO DISK = "D:\ tmp \ aw_backups \ aw_log_fail3.trn" WITH NORECOVERY

これで、破損したページを修復できます。 まず、完全バックアップ(aw_full_ok1.bak)を使用します。
データベースの復元AdventureWorksPAGE = "1:20455" FROM DISK = "D:\ tmp \ aw_backups \ aw_full_ok1.bak" WITH NORECOVERY
その結果、次のようになります。
トランザクションログのバックアップをロールする必要があるため、NORECOVERYオプションを使用する必要があることに注意してください。
ログを復元AdventureWorksFROM DISK = "D:\ tmp \ aw_backups \ aw_log_ok1.trn" WITH NORECOVERY and
ログを復元AdventureWorksFROM DISK = "D:\ tmp \ aw_backups \ aw_log_fail3.trn" WITH RECOVERY 
すべてがうまくいったようです。DBCCCHECKDBを実行して... 
回復は成功しました。
データベース全体を完全バックアップから復元するのではなく、破損したページのみを復元するため、ダウンタイムが短縮されることに注意してください(バックアップ全体を復元した場合、バックアップは8.5秒で復元されますが、 大きいサイズ DB-時間の差が大きくなります)。 オンライン復元を使用するSQLServer Enterprise Editionの幸運なものは、ログバックアップからの復元にかかる時間を節約し、オフライン復元の場合、残念ながら、ログは完全に処理されます。
また、SQL Server 2005、2008、2008 R2では、単一ページの復元はT-SQLの助けを借りてのみ可能であり、DenaliにはGUIを介してこれを行う機能があることも追加する価値があります。
そして、すべて同じDBCC CHECKDBの場合はどうなりますか?
念のため、REPAIR_ALLOW_DATA_LOSSオプションを指定してDBCCCHECKDBを実行した場合にSQLServerがどのように動作するかを確認することにしました。 それでも同じエラー:
まず、データベースをSINGLE_USERモードにします。
ALTER DATABASE AdventureWorks SET SINGLE_USER次に、リカバリを開始します。
DBCC CHECKDB( "AdventureWorks"、REPAIR_ALLOW_DATA_LOSS)WITH NO_INFOMSGS、ALL_ERRORMSGS、DATA_PURITY結果:
修復:ページ(1:20455)は、オブジェクトID 1883153754、インデックスID 0、パーティションID 72057594054246400、割り当てユニットID 72057594061651968(行内データのタイプ)から割り当て解除されました。
はい、SQLServerは「破損した」ページを削除しました。 データベースをMULTI_USERモードに転送して、すべてのユーザーが利用できるようにし、不足しているものを確認します。

SQL Serverのページサイズが8KBであり、ユーザーデータに使用できるものが少し少ないことを考えると、すべてが自然であり、テーブルは7レコード(最初は99999でした)で「重みを失いました」。 このテーブルにはクラスター化インデックスがないため、データは任意の順序で保存できます。 どのデータが失われるかさえわかりませんでした。
では、なぜ、結局のところ、翻訳ではないのでしょうか。
それで、なぜそれはまだ翻訳ではなく、「に基づく」投稿なのですか。 事実、パブリックドメインには、GailShawによる「PageRestore」という記事はありません。 SQL Server MVP Deep Dives vol.2にはそのようなセクションがあり、かなりの金額で販売されています(もちろん、インターネットで簡単に見つけることができます)。翻訳を公開するかどうかはわかりません。ええと...正しいか何か。一般的に、私は記事を読み、要点を書き留めてから、自分で文章を書き、その過程で修復の実験を行いました。 この経験が誰かに役立つことを願っています。
そして、紳士淑女の皆さん、この実験を繰り返すことにした場合は、細心の注意を払ってください(たとえば、本番サーバーのメインデータベースで実験しないことを心から願っています)。 私はあなたの行動に対して責任を負わないことに注意してください。
先週投稿したもので、興味をそそられたようですが、残念ながら「練習」が入っていませんでした。 はい、データを保存する方法を説明していますが、例はありません。
当初は同じ作者による別の翻訳をしたかったのですが、考えてから「自分で」投稿することにしました。 私がそうするように促した理由は、投稿の最後のメモで説明します。
SQLServerでのデータベースの復元
前の記事で述べたように、クラスター化インデックスまたはヒープページが破損した場合、これらのページに含まれるデータは失われ、それらを復元する唯一のオプションはデータベースを直接復元することです。SQL Serverには、データベースを回復するための多くのオプションが用意されています。 まず、これはデータベース全体の復元です。これにはかなりの時間がかかる場合があります(データベースのサイズとハードドライブの速度によって異なります)。 次に、個々のファイルグループ、またはデータベースが複数のファイルグループ(またはそれぞれファイル)で構成されている場合はファイルを復元します。 この場合、残りの部分に影響を与えることなく、データベースの損傷した部分のみを復元することができます。 これらの2種類のデータベース回復は非常に頻繁に使用されるため、これ以上説明しません。
第3に、SQL Server 2005では、個々のデータベースページを復元する機能が導入されました。この場合、指定されたページのみがバックアップから復元されます。 このような回復は、DBCC CHECKDBが、大量のファイルに「横たわっている」巨大なテーブルでいくつかの破損したページを見つけた場合に特に関係があります。 ファイル全体が復元されるわけではなく、テーブル全体が復元されるわけではなく、数ページしか復元されないため、ダウンタイムを大幅に削減できます。
要件と制限
リカバリモデルとトランザクションログバックアップの可用性
覚えておくべき最も重要なことは、単一のページを復元するには、データベースが完全な(完全な)回復モデル、または一括ログ記録された回復モデルを使用する必要があるということです。 データベースが単純な(単純な)リカバリモデルである場合、これ以上読むことはできません。2番目の要件は、完全バックアップとトランザクションログバックアップが壊れないログチェーンを形成する必要があることです。 BACKUP LOG WITH TRUNCATE_ONLY(NO_LOG)コマンドを実行せず、トランザクションログを縮小するために単純なリカバリモデルに切り替えた場合、ページが破損していない最後の完全バックアップ以降のすべてのトランザクションログバックアップがあります(これを含む最も完全なバックアップ)-ログのチェーンについて心配する必要はありません。
バルクログリカバリモデルでは、理論的には、上記の条件が満たされ、復元されるページが最小限のログ操作によって変更されていない限り、個々のページリカバリは正常に機能するはずです。
SQLServerのエディション
ページの回復はSQLServerのどのエディションでも可能ですが、EnterpriseEditionおよびDeveloperEditionの場合、破損したページをオンラインで回復することができます。 リカバリ中にデータベースにアクセスできます(さらに、これらのページ自体が「影響を受けていない」場合は、現在復元されているページが属するテーブルにもアクセスできます。そうでない場合、要求は失敗します)。 Enterprise Editionの「下」のエディションの場合、ページのリカバリはオフラインで実行され、リカバリ期間中はデータベースが使用できなくなります。破損したページタイプ
インデックスページまたはデータが破損した場合、EnterpriseEditionでオンラインで回復できます。重要なシステムテーブルに属するページは復元できますが、復元すると、どのエディションのSQLServerでもデータベースにアクセスできなくなります。
「ロケーションカード」は「個別に」復元することはできません。 GAM、SGAM、PFS、ML、DIFFページが破損している場合は、データベース全体を復元する必要があります。 唯一の例外はIAMページです。 これらは「配置マップ」を参照していますが、データベース全体ではなく1つのテーブルのみを記述しており、それらを回復することができます。
データベースブートページ(1番目のデータベースファイルの9ページ)とファイルヘッダーページ(各ファイルの0ページ)は「個別に」復元できません。これらが破損している場合は、データベース全体を復元する必要があります。
実際、回復
さて、ついに、私たちは理論から実践へと移ります。まず、トレーニングには、破損したデータベースが必要です。
データベースの移植
実験には、SQLServerに付属のAdventureWorksデータベースを使用します。 インストールしていない場合は、をダウンロードできます。 私はそれを完全な回復モデルに変換します:ALTER DATABASE AdventureWorks SET RECOVERY FULLまだエラーがないことを確認してください:
DBCC CHECKDB( "AdventureWorks")WITH NO_INFOMSGS、ALL_ERRORMSGS、DATA_PURITYを使用して、完全バックアップを作成します。
データベースAdventureWorksをディスクにバックアップ= "D:\ tmp \ aw_backups \ aw_full_ok1.bak"
このデータベースでは、クラッシュテーブルを作成します。
CREATE TABLEクラッシュ(txt varchar(1000))SQL Serverが、SQL Server自体が書き込んだデータではなく、突然その中に何が発生するかを確認するために、varchar型フィールドを台無しにします。
あなたが何かを台無しにする前に、あなたはそれを何かで満たす必要があります。 作成したテーブルの左側のデータをハンマーで叩きます。
DECLARE @i INT SET @i = 1 WHILE @ iにNOCOUNTを設定します<100000
BEGIN
INSERT INTO crash
SELECT REPLICATE("a", 1000)
SET @i = @i + 1
END
SET NOCOUNT OFF
Теперь делаю резервную копию журнала транзакций:
バックアップログAdventureWorksTO DISK = "D:\ tmp \ aw_backups \ aw_log_ok1.trn"
次に、データを少し変更しましょう。
これで、すべての準備が整いました。 データベースを切断し、FAR "om(またはより便利な方)を使用してmdfファイルを開き、その中の文字列" zzzzzzz "を探し、いくつかの" z "を任意の文字に置き換えます。
データベースが破損したので、接続します。 そして、はい、前回の記事で、データベースをデタッチ/アタッチするべきではないと明確に述べられていたことを覚えています。 しかし、私たちの場合、それは絶対に「安全」です-「疑わしい」データベースは落ちません。
間違いを探す
したがって、破損したデータベースは正常にサービスに戻りました。 整合性チェックをもう一度実行してみましょう。DBCC CHECKDB( "AdventureWorks")WITH NO_INFOMSGS、ALL_ERRORMSGS、DATA_PURITY結果は、期待どおりです( 破損したページの数を忘れないでください!):
メッセージ8928、レベル16、状態1、行1
オブジェクトID1883153754、インデックスID 0、パーティションID 72057594054246400、割り当てユニットID 72057594061651968(タイプ行内データ):ページ(1:20455)を処理できませんでした。 詳細については、他のエラーを参照してください。
メッセージ8939、レベル16、状態98、行1
テーブルエラー:オブジェクトID 1883153754、インデックスID 0、パーティションID 72057594054246400、割り当てユニットID 72057594061651968(行内データのタイプ)、ページ(1:20455)。 テスト(IS_OFF(BUF_IOERR、pBUF-> bstat))が失敗しました。 値は29493257と-4です。
CHECKDBは、テーブル「crash」(オブジェクトID 1883153754)で0個の割り当てエラーと2個の整合性エラーを検出しました。
CHECKDBは、データベース「AdventureWorks」で0個の割り当てエラーと2個の整合性エラーを検出しました。
repair_allow_data_lossは、DBCC CHECKDB(AdventureWorks)によって検出されたエラーの最小修復レベルです。
この場合、ヒープ自体のデータが破損しているため(インデックスID = 0)、SQLServerはこのデータを回復できません。
現在、3つのオプションがあります。
- データ損失を受け入れ、DBCC CHECKDB( "AdventureWorks"、REPAIR_ALLOW_DATA_LOSS)を実行します
- トランザクションログのアクティブな部分のバックアップを作成し、データベース全体を復元します-結果としてデータが失われることはありませんが、時間がかかります
- トランザクションログのアクティブな部分のバックアップを作成し、破損したページを1つだけ復元します(!)
破損したページの復元
まず、トランザクションログの最後のフラグメントのバックアップを作成する必要があります(テールバックアップ)。 同時に、Enterprise Editionを使用している場合、NORECOVERYパラメーターを追加することはできません。これにより、データベースは「復元中」の状態になります。これは、このエディションがオンライン・ページのリカバリーをサポートしているためです。 さらに、トランザクションログのバックアップを定期的に実行している場合は、ログチェーンを壊さないように、EnterpriseEditionでCOPY_ONLYバックアップを作成できます。オフラインリカバリのパスをたどって実行します。
バックアップログAdventureWorksTO DISK = "D:\ tmp \ aw_backups \ aw_log_fail3.trn" WITH NORECOVERY
これで、破損したページを修復できます。 まず、完全バックアップ(aw_full_ok1.bak)を使用します。
データベースの復元AdventureWorksPAGE = "1:20455" FROM DISK = "D:\ tmp \ aw_backups \ aw_full_ok1.bak" WITH NORECOVERY
その結果、次のようになります。
トランザクションログのバックアップをロールする必要があるため、NORECOVERYオプションを使用する必要があることに注意してください。
ログを復元AdventureWorksFROM DISK = "D:\ tmp \ aw_backups \ aw_log_ok1.trn" WITH NORECOVERY and
ログを復元AdventureWorksFROM DISK = "D:\ tmp \ aw_backups \ aw_log_fail3.trn" WITH RECOVERY
すべてがうまくいったようです。DBCCCHECKDBを実行して...
回復は成功しました。
データベース全体を完全バックアップから復元するのではなく、破損したページのみを復元するため、ダウンタイムが短縮されることに注意してください(バックアップ全体を復元した場合、バックアップは8.5秒で復元されますが、データベースサイズが大きくなります) 、より多くの時差があります)。 オンライン復元を使用するSQLServer Enterprise Editionの幸運なものは、ログバックアップからの復元にかかる時間を節約し、オフライン復元の場合、残念ながら、ログは完全に処理されます。
また、SQL Server 2005、2008、2008 R2では、単一ページの復元はT-SQLの助けを借りてのみ可能であり、DenaliにはGUIを介してこれを行う機能があることも追加する価値があります。
そして、すべて同じDBCC CHECKDBの場合はどうなりますか?
念のため、REPAIR_ALLOW_DATA_LOSSオプションを指定してDBCCCHECKDBを実行した場合にSQLServerがどのように動作するかを確認することにしました。 それでも同じエラー:まず、データベースをSINGLE_USERモードにします。
ALTER DATABASE AdventureWorks SET SINGLE_USER次に、リカバリを開始します。
DBCC CHECKDB( "AdventureWorks"、REPAIR_ALLOW_DATA_LOSS)WITH NO_INFOMSGS、ALL_ERRORMSGS、DATA_PURITY結果:
修復:ページ(1:20455)は、オブジェクトID 1883153754、インデックスID 0、パーティションID 72057594054246400、割り当てユニットID 72057594061651968(行内データのタイプ)から割り当て解除されました。
はい、SQLServerは「破損した」ページを削除しました。 データベースをMULTI_USERモードに転送して、すべてのユーザーが利用できるようにし、不足しているものを確認します。
SQL Serverのページサイズが8KBであり、ユーザーデータに使用できるものが少し少ないことを考えると、すべてが自然であり、テーブルは7レコード(最初は99999でした)で「重みを失いました」。 このテーブルにはクラスター化インデックスがないため、データは任意の順序で保存できます。 どのデータが失われるかさえわかりませんでした。
では、なぜ、結局のところ、翻訳ではないのでしょうか。
それで、なぜそれはまだ翻訳ではなく、「に基づく」投稿なのですか。 事実、パブリックドメインには、GailShawによる「PageRestore」という記事はありません。 SQL Server MVP Deep Dives vol.2にはそのようなセクションがあり、かなりの金額で販売されています(もちろん、インターネットで簡単に見つけることができます)。翻訳を公開するかどうかはわかりません。ええと...正しいか何か。一般的に、私は記事を読み、要点を書き留めてから、自分で文章を書き、その過程で修復の実験を行いました。 この経験が誰かに役立つことを願っています。
そして、紳士淑女の皆さん、この実験を繰り返すことにした場合は、細心の注意を払ってください(たとえば、本番サーバーのメインデータベースで実験しないことを心から願っています)。 私はあなたの行動に対して責任を負わないことに注意してください。