Cの文字列。 序章。 文字列の操作。 文字列クラス。 クラスコンストラクター。 割り当て()、追加()、挿入()、置換()、消去()、検索()、rfind()、比較()、c_str()関数。 の例
文字列。 I / Oライン。 フォーマットされたI / O。 標準のC関数を使用して文字列を処理します。メモリを操作します。
1.1。 文字列の宣言と初期化。
文字列は、空の文字 '\ 0'で終わる文字の配列です。 文字列は、たとえば、通常の文字配列として宣言されます
char s1; // 9文字の長さの文字列
char * s2; //文字列へのポインタ
s1とs2の違いは、s1が名前付き定数であり、s2が変数であるということです。
文字列定数は、一重引用符で囲まれた文字とは対照的に、二重引用符で囲まれます。 例えば、
「これは文字列です。」
文字列定数の長さは、標準で509文字を超えることはできません。 ただし、多くの実装では、より長い文字列が許可されます。
文字列を初期化するときは、配列の次元を指定しないことをお勧めします。コンパイラは、文字列の長さを計算して文字列に追加することでこれを行います。 例えば、
char s1 = "これは文字列です。";
Cプログラミング言語では、文字列を操作するために、 たくさんのプロトタイプがstdlib.hおよびstring.hヘッダーファイルに記述されている関数。 これらの関数の操作については、次の段落で説明します。
1.2。 I / Oライン。
コンソールから文字列を入力するには、関数を使用します
char * get(char * str);
これは文字列をstrに書き込み、入力された文字列のアドレスを返します。 この関数は、「\ n」またはEOF(ファイルの終わり)文字に遭遇すると入力を停止します。 改行文字はコピーされません。 読み取り行の最後にゼロバイトが配置されます。 成功すると、関数は読み取り文字列へのポインタを返し、失敗するとNULLを返します。
コンソールに行を出力するには、標準機能を使用します
int puts(const char * s);
これは、成功した場合は負でない数を返し、失敗した場合はEOFを返します。
getおよびputs関数のプロトタイプは、stdio.hヘッダーファイルに記述されています。
#含む
printf( "入力文字列:");
1.3。 フォーマットされたI / O。
コンソールからのフォーマットされたデータ入力には、関数を使用します
int scanf(const char * format、...);
これは、成功した場合は読み取られたデータのユニット数を返し、そうでない場合はEOFを返します。 formatパラメータは、入力フォーマットの仕様を含むフォーマットされた文字列を指している必要があります。 フォーマット文字列に続く引数の数とタイプは、フォーマット文字列で指定された入力フォーマットの数とタイプと一致する必要があります。 この条件が満たされない場合、関数の結果は予測できません。
スペース、フォーマット文字列の文字「\ t」または「\ n」は、入力ストリーム内の1つ以上の空の文字を表します。これには、スペース、 '\ t'、 '\ n'、 '\ v'、 '\の文字が含まれます。 f '。 scanf関数は、入力ストリームの空白文字をスキップします。
フォーマット文字列のリテラル文字は、%文字を除いて、入力ストリームに表示されるのとまったく同じ文字を必要とします。 そのような文字がない場合、scanfは入力を停止します。 scanf関数は、リテラル文字をスキップします。
一般に、入力形式の仕様は次のとおりです。
%[*] [width] [modifiers] type
'*'文字は、この仕様で定義されたフィールドに入力するときにスキップすることを示します。
-「width」は、この仕様に従って入力される最大文字数を定義します。
タイプは次の値を取ることができます。
c-文字配列、
s-文字列、文字列は空白文字で区切られ、
d-10秒/秒の符号付き整数、
iは符号付き整数であり、記数法は最初の2桁に依存します。
u-10 s / sでの符号なし整数、
o-8秒/秒の符号なし整数、
x、X-16秒/秒の符号なし整数、
e、E、f、g、G-浮動小数点数、
pはポインタへのポインタであり、
nは整数へのポインタであり、
[...]-スキャンされた文字の配列。たとえば、。
後者の場合、角括弧で囲まれた文字のみが入力ストリームから入力されます。 角かっこ内の最初の文字が「^」の場合、配列にない文字のみが入力されます。 配列内の文字の範囲は、「-」記号を使用して指定されます。 文字を入力するときは、文字列の先頭の空白と終了のヌルバイトも入力されます。
修飾子は次の値を取ることができます。
h-短整数、
l、L-長整数または浮動小数点、
整数または浮動小数点数にのみ使用されます。
次の例は、scanf関数の使用例を示しています。 フォーマット指定子の前には、浮動小数点入力から始まるスペースがあることに注意してください。
#含む
printf( "整数を入力してください:");
scanf( "%d"、&n);
printf( "ダブルを入力:");
scanf( "%lf"、&d);
printf( "文字を入力:");
scanf( "%c"、&c);
printf( "文字列を入力してください:");
scanf( "%s"、&s);
このプログラムでは、浮動小数点数が初期化されることに注意してください。 これは、浮動小数点数の操作をサポートするライブラリをコンパイラに含めるために行われます。 そうしないと、浮動小数点数を入力するときに実行時にエラーが発生します。
コンソールへのフォーマットされた出力には、関数を使用します
int printf(const char * format、...);
これは、成功した場合はデータ出力のユニット数を返し、そうでない場合はEOFを返します。 formatパラメータは、出力フォーマットの仕様を含むフォーマットされた文字列です。 フォーマット文字列に続く引数の数とタイプは、フォーマット文字列で指定された出力フォーマット仕様の数とタイプと一致する必要があります。 一般に、出力形式の仕様は次のとおりです。
%[フラグ] [幅] [。精度] [修飾子]タイプ
-「フラグ」は、出力形式を指定するさまざまな記号です。
-「width」は、この仕様に従って表示される最小文字数を定義します。
-'。precision'は、表示される最大文字数を定義します。
-「修飾子」は引数のタイプを指定します。
-「type」は引数のタイプを定義します。
符号付き整数は、次の形式で出力されます。
%[-] [+ | スペース] [幅] [l] d
---左に配置、デフォルトでは-右に配置。
+-記号「+」が表示されます。負の数の場合、記号「-」が常に表示されることに注意してください。
「スペース」-スペースは文字の位置に表示されます。
d-データ型int。
符号なし整数の出力には、次の出力形式が使用されます。
%[-] [#] [幅] [l]
#-8 c / sの数値の場合は最初の0が表示され、16 c / sの数値の場合は最初の0xまたは0Xが表示されます。
l-長いデータ型の修飾子。
u-10c / sの整数、
o-8秒/秒の整数、
x、Xは16秒/秒の整数です。
浮動小数点数の場合、次の出力形式が使用されます。
%[-] [+ | スペース] [幅] [。精度]
「精度」は、f、e、E形式の場合は小数点以下の桁数、g、G形式の場合は有効桁数を示します。数値は四捨五入されます。 デフォルトは10進数の6桁です。
f-固定小数点数、
e-指数形式の数値。指数は文字「e」で示されます。
E-指数形式の数値。指数は文字「E」で示されます。
g-fまたはg形式の最短、
GはfまたはGフォーマットの中で最も短いものです。
printf( "n =%d \ n f =%f \ n e =%e \ n E =%E \ n f =%。2f"、-123、12.34、12.34、12.34、12.34);
//出力:n = 123 f = 12.340000 e = 1.234000e + 001 E = 1.234000E + 001 f = 12.34
1.4。 文字列のフォーマット。
文字列をフォーマットするためのscanf関数とprintf関数にはバリエーションがあり、それぞれsscanfとsprintfと呼ばれます。
int sscanf(const char * str、const char * format、...);
formatパラメーターで指定されたフォーマット文字列に従って、strパラメーターで指定された文字列からデータを読み取ります。 成功した場合は読み取られたデータの量を返し、失敗した場合はEOFを返します。 例えば、
#含む
char str = "a 101.2文字列入力なし";
sscanf(str、 "%c%d%lf%s"、&c、&n、&d、s);
printf( "%c \ n"、c); //印刷:
printf( "%d \ n"、n); //印刷:10
printf( "%f \ n"、d); //印刷:1.200000
printf( "%s \ n"、s); //出力:文字列
int sprintf(char * buffer、const char * format、...);
formatパラメーターで指定された形式に従って文字列をフォーマットし、その結果を文字配列バッファーに書き込みます。 この関数は、終了ヌルバイトを除いて、文字配列バッファに書き込まれた文字数を返します。 例えば、
#含む
char str = "c =%c、n =%d、d =%f、s =%s";
char s = "これは文字列です。";
sprintf(buffer、str、c、n、d、s);
printf( "%s \ n"、バッファ); //出力:c = c、n = 10、d = 1.200000、s =これは文字列です
1.5。 文字列を数値データに変換します。
文字列を数値データに変換するための関数のプロトタイプは、プログラムにインクルードする必要があるstdlib.hヘッダーファイルに記載されています。
文字列を整数に変換するには、関数を使用します
int atoi(const char * str);
char * str =“ -123”;
n = atoi(str); // n = -123
文字列を長整数に変換するには、関数を使用します
long int atol(const char * str);
これは、成功した場合、文字列strが変換された整数を返し、0が失敗した場合、たとえば、
char * str =“ -123”;
n = atol(str); // n = -123
文字列をdoubleに変換するには、関数を使用します
double atof(const char * str);
これは、成功した場合、文字列strが変換されたdouble型の浮動小数点数を返し、0が失敗した場合、たとえば、
char * str =“ -123.321”;
n = atof(str); // n = -123.321
次の関数は、atoi、atol、atofと同じアクションを実行しますが、より高度な機能を提供します。
long int strtol(const char * str、char ** endptr、int base);
文字列strをlongintに変換し、それを返します。 この関数のパラメーターには、次の意味があります。
基数が0の場合、変換はstrの最初の2文字に依存します。
最初の文字が1から9までの数字である場合、その数字は10秒/秒で表されていると見なされます。
最初の文字が数字の0で、2番目の文字が1から7までの数字である場合、その数字は8 c / sで表されると想定されます。
最初の文字が0で、2番目の文字が「X」または「x」の場合、数値は16 c / sで表されると見なされます。
基数が2から36までの数値の場合、この値は基数の基数と見なされ、この基数の外側の文字は変換を停止します。 ベース11から36は、数字を表すために文字「A」から「Z」または「a」から「z」を使用します。
endptr引数は、strtol関数によって設定されます。 この値には、strの変換を停止した文字へのポインターが含まれています。 成功した場合、strtol関数は変換された数値を返し、失敗した場合は0を返します。たとえば、
n = strtol(“ 12a”、&p、0);
printf(“ n =%ld、%stop =%c、n、* p); // n = 12、stop = a
n = strtol(“ 012b”、&p、0);
printf(“ n =%ld、%stop =%c、n、* p); // n = 10、stop = b
n = strtol(“ 0x12z”、&p、0);
printf(“ n =%ld、%stop =%c、n、* p); // n = 18、stop = z
n = strtol(“ 01117”、&p、0);
printf(“ n =%ld、%stop =%c、n、* p); // n = 7、停止= 7
unsigned long int strtol(const char * str、char ** endptr、int base);
strtolと同様に機能しますが、数値の文字表現をunsigned longintに変換します。
double strtod(const char * str、char ** endptr);
数値の文字表現をdoubleに変換します。
この段落にリストされているすべての関数は、問題の数値の形式に適合しない最初の文字に遭遇すると、作業を停止します。
さらに、数値の文字値が対応するデータ型の有効な値の範囲を超える場合、関数atof、strtol、strtoul、strtodはerrno変数の値をERANGEに設定します。 errno変数とERANGE定数は、math.hヘッダーファイルで定義されています。 atof関数とstrtod関数はHUGE_VAL値を返し、strtol関数はLONG_MAXまたはLONG_MIN値を返し、strtoul関数はULONG_MAX値を返します。
非標準関数itoa、ltoa、utoa、ecvt、fcvt、およびgcvtを使用して、数値データを文字列に変換できます。 ただし、これらの目的には標準のsprintf関数を使用することをお勧めします。
1.6。 文字列を操作するための標準関数。
このセクションでは、文字列を操作するための関数について説明します。そのプロトタイプは、ヘッダーファイルstring.hに記述されています。
1.文字列の比較。 strcmp関数とstrncmp関数は、文字列を比較するために使用されます。
int strcmp(const char * str1、const char * str2);
字句的にstr1、str2を比較し、str1がそれぞれstr2より小さい、等しい、または大きい場合は–1、0、または1を返します。
int strncmp(const char * str1、const char * str2、size_t n);
辞書式順序で、str1とstr2の最初の文字を最大n個比較します。 この関数は、文字列str1の最初のn文字が、文字列str2の最初のn文字よりも小さい、等しい、または大きい場合、それぞれ-1、0、または1を返します。
//文字列比較の例
#含む
#含む
char str1 = "aa bb";
char str2 = "aa aa";
char str3 = "aa bb cc";
printf( "%d \ n"、strcmp(str1、str3)); //出力:-1
printf( "%d \ n"、strcmp(str1、str1)); //出力:-0
printf( "%d \ n"、strcmp(str1、str2)); //印刷:1
printf( "%d \ n"、strncmp(str1、str3、5)); //出力:0
2.行をコピーします。 strcpy関数とstrncpy関数は、文字列をコピーするために使用されます。
char * strcpy(char * str1、const char * str2);
文字列str2を文字列str1にコピーします。 終了ヌルバイトを含む文字列str2全体がコピーされます。 この関数は、str1へのポインタを返します。 線が重なっている場合、結果は予測できません。
char * strncpy(char * str1、const char * str2、size_t n);
n文字を文字列str2から文字列str1にコピーします。 文字列str2に含まれる文字がn文字未満の場合、文字列str2をn文字に拡張するために、最後のnullバイトが必要な回数だけコピーされます。 この関数は、文字列str1へのポインタを返します。
char str2 = "文字列をコピーします。";
strcpy(str1、str2);
printf(str1); //出力:文字列をコピーします。
4.文字列の連結。 strcat関数とstrncat関数は、文字列を1つの文字列に連結するために使用されます。
char * strcat(char * str1、const char * str2);
文字列str2を文字列str1に追加し、文字列str1の終了ヌルバイトを消去します。 この関数は、文字列str1へのポインタを返します。
char * strncat(char * str1、const char * str2、size_t n);
文字列str2から文字列str1にn文字を追加し、文字列str1の終了ヌルバイトを消去します。 この関数は、文字列str1へのポインタを返します。 文字列str2の長さがn未満の場合、文字列str2に含まれる文字のみが追加されます。 文字列を連結した後、常にゼロバイトがstr1に追加されます。 この関数は、文字列str1へのポインタを返します。
#含む
#含む
char str1 = "文字列";
char str2 = "カテネーション";
char str3 = "はいいいえ";
strcat(str1、str2);
printf( "%s \ n"、str1); //出力:文字列の連結
strncat(str1、str3、3);
printf( "%s \ n"、str1); //出力:文字列の連結はい
5.文字列内の文字を検索します。 strchr、strrchr、strspn、strcspn、およびstrpbrk関数は、文字列内の文字を検索するために使用されます。
char * strchr(const char * str、int c);
文字列strのcパラメータで指定された文字の最初の出現を検索します。 成功すると、関数は最初に見つかった文字へのポインタを返し、失敗するとNULLを返します。
char * strrchr(const char * str、int c);
文字列strのcパラメータで指定された文字の最後の出現を検索します。 成功した場合、関数は最後に見つかった文字へのポインタを返し、失敗した場合はNULLを返します。
#含む
#含む
char str = "文字検索";
printf( "%s \ n"、strchr(str、 "r")); //出力:r検索
printf( "%s \ n"、strrchr(str、 "r")); //印刷:rch
size_t strspn(const char * str1、const char * str2);
文字列str2にない文字列str1の最初の文字のインデックスを返します。
size_t strcspn(const char * str1、const char * str2);
文字列str2に入る文字列str1の最初の文字のインデックスを返します。
char str = "123 abc";
printf( "n =%d \ n"、strspn(str、 "321"); //出力:n = 3
printf( "n =%d \ n"、strcspn(str、 "cba"); //出力:n = 4
char * strpbrk(const char * str1、const char * str2);
文字列str2の文字の1つと等しい文字列str1の最初の文字を検索します。 成功すると、関数はこの文字へのポインタを返し、失敗するとNULLを返します。
char str = "123 abc";
printf( "%s \ n"、strpbrk(str、 "bca")); //印刷:abc
6.文字列の比較。 strstr関数は、文字列を比較するために使用されます。
char * strstr(const char * str1、const char * str2);
文字列str1で最初に出現する文字列str2(末尾のヌルバイトなし)を検索します。 成功すると、関数は見つかったサブ文字列へのポインタを返し、失敗するとNULLを返します。 str1ポインターが長さゼロのストリングを指している場合、関数はstr1ポインターを返します。
char str = "123 abc 456;
printf( "%s \ n"、strstr(str、 "abc"); // print:abc 456
7.文字列をトークンに解析します。 strtok関数は、文字列をトークンに解析するために使用されます。
char * strtok(char * str1、const char * str2);
文字列str1の次のトークン(単語)へのポインタを返します。トークンは文字列str2の文字で区切られます。 語彙素が終了すると、関数はNULLを返します。 strtok関数の最初の呼び出しでは、str1パラメーターはトークンに解析される文字列を指している必要があり、その後の呼び出しでは、このパラメーターをNULLに設定する必要があります。 トークンを見つけた後、strtok関数は、セパレータの代わりにこのトークンの後にゼロバイトを書き込みます。
#含む
#含む
char str = "12 34 ab cd";
p = strtok(str、 "");
printf( "%s \ n"、p); //値を列に出力します:12 34 ab cd
p = strtok(NULL、 "");
8.文字列の長さを決定します。 strlen関数は、文字列の長さを決定するために使用されます。
size_t strlen(const char * str);
最後のヌルバイトを除いた文字列の長さを返します。 例えば、
char str = "123";
printf( "len =%d \ n"、strlen(str)); //出力:len = 3
1.7。 メモリを操作するための関数。
ヘッダーファイルstring.hには、メモリブロックを操作するための関数も記述されています。これは、文字列を操作するための対応する関数に似ています。
void * memchr(const void * str、int c、size_t n);
strのnバイトでcパラメーターによって指定された文字の最初の出現を検索します。
int memcmp(const void * str1、const void * str2、size_t n);
str1とstr2の最初のnバイトを比較します。
void * memcpy(const void * str1、const void * str2、size_t n);
最初のnバイトを文字列str1から文字列str2にコピーします。
void * memmove(const void * str1、const void * str2、size_t n);
最初のnバイトを文字列str1から文字列str2にコピーし、重複する文字列が正しく処理されるようにします。
void * memset(const void * str、int c、size_t n);
cパラメーターで指定された文字をstrの最初のnバイトにコピーします。
このサイトでAdBlockを一時停止してください。
したがって、Cの文字列。 他の多くのプログラミング言語で行われているように、それらに個別のデータ型はありません。 Cでは、文字列は文字の配列です。 行の終わりを示すために、このレッスンの最後の部分で説明した「\ 0」文字が使用されます。 画面には一切表示されないので、見ることはできません。
文字列の作成と初期化
文字列は文字の配列であるため、文字列の宣言と初期化は1次元配列の場合と同じです。
次のコードは、文字列を初期化するさまざまな方法を示しています。
リスト1。
Char str; char str1 =( "Y"、 "o"、 "n"、 "g"、 "C"、 "o"、 "d"、 "e"、 "r"、 "\ 0"); char str2 = "こんにちは!"; char str3 = "こんにちは!";
図1文字列の宣言と初期化
最初の行では、10文字の配列を宣言しています。 なぜなら、それはまったく文字列ではありません。 単なる文字セットである限り、ヌル文字\ 0はありません。
二行目。 最も簡単な方法額の初期化。 各文字を個別に宣言します。 ここで重要なのは、ヌル文字\ 0を追加することを忘れないことです。
3行目は、2行目に類似しています。 写真に注意してください。 なぜなら 右側の文字列の文字数は配列の要素よりも少なく、残りの要素は\ 0で埋められます。
4行目。 ご覧のとおり、ここではサイズは指定されていません。 プログラムはそれを自動的に計算し、必要な長さの文字の配列を作成します。 これにより、ヌル文字\ 0が最後に挿入されます。
文字列の出力方法
作成した行を画面に表示する本格的なプログラムに上記のコードを追加してみましょう。
リスト2。
#含む

図2画面に文字列を表示するさまざまな方法
ご覧のとおり、画面に文字列を表示する基本的な方法はいくつかあります。
- %s指定子でprintf関数を使用する
- puts関数を使用する
- fputs関数を使用して、2番目のパラメーターとしてstdoutを指定します。
putsおよびfputs関数に関する唯一の注意点。 puts関数は出力を次の行にラップしますが、fputs関数はラップしないことに注意してください。
ご覧のとおり、結論は非常に単純です。
入力文字列
文字列の入力は、出力よりも少し複雑です。 最も簡単な方法は次のとおりです。
リスト3。
#含む
get関数はプログラムを一時停止し、キーボードから入力された文字列を読み取り、それを文字配列に配置します。その名前はパラメーターとして関数に渡されます。
get関数の完了は、Enterキーに対応し、ヌル文字として文字列に書き込まれる文字になります。
危険に気づきましたか? そうでない場合、コンパイラはそれについて親切に警告します。 重要なのは、gets関数は、ユーザーがEnterキーを押したときにのみ終了するということです。 これは、この場合、20文字を超える文字が入力された場合に、配列を超えることができるという事実に満ちています。
ちなみに、バッファオーバーフローエラーは、以前は最も一般的なタイプの脆弱性と見なされていました。 それらは今日でも発見されていますが、プログラムをハッキングするためにそれらを使用することははるかに困難になっています。
だから私たちは何を持っていますか。 限られたサイズの配列に文字列を書き込むというタスクがあります。 つまり、ユーザーが入力する文字数をなんらかの方法で制御する必要があります。 ここで、fgets関数が役に立ちます。
リスト4。
#含む
fgets関数は、入力として3つの引数を取ります。文字列を書き込む変数、書き込む文字列のサイズ、および文字列に書き込むデータを取得するストリームの名前(この場合はstdin)です。 レッスン3ですでにご存知のように、stdinは標準入力であり、通常はキーボードに関連付けられています。 データがstdinストリームから取得される必要はまったくありません。将来的には、この関数を使用してファイルからデータを読み取る予定です。
このプログラムの実行中に10文字より長い文字列を入力すると、最初から9文字だけで改行が配列に書き込まれ、fgetsは文字列を必要な長さに「カット」します。
fgetsは10文字ではなく、9文字を読み取ることに注意してください。 覚えているように、文字列では、最後の文字はnull文字用に予約されています。
それをチェックしよう。 最後のリストからプログラムを始めましょう。 そして、行1234567890を入力します。 画面に文字列123456789が表示されます。

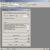
図3fgets関数がどのように機能するかの例
問題が発生します。 10番目のキャラクターはどこに行きましたか? そして答えます。 それはどこにも行きませんでした、それは入力ストリームに残っています。 次のプログラムを実行します。
リスト5。
#含む
これが彼女の仕事の結果です。

図4空でないstdinバッファー
何が起こったのか説明させてください。 fgets関数と呼びました。 彼女は入力ストリームを開き、私たちがデータを入力するのを待ちました。 キーボードから1234567890と入力しました\ n(\ n Enterキーを押すことを意味します)。 これはstdin入力ストリームに送られました。 fgets関数は、予想どおり、入力ストリームから最初の9文字123456789を取得し、それらにnull文字\ 0を追加して、文字列strに書き込みました。 入力ストリームにはまだ0 \ nが残っています。
次に、h変数を宣言します。 その値を画面に表示します。 次に、scanf関数を呼び出します。 これは私たちが何かを入力できると期待される場所ですが、 0 \ nが入力ストリームでハングし、scanf関数がこれを入力として認識し、0がh変数に書き込まれます。 次に、それを画面に表示します。
もちろん、これは私たちが期待する動作とは異なります。 この問題に対処するには、ユーザーが入力した行を入力バッファーから読み取った後、入力バッファーをクリアする必要があります。 これには、特殊関数fflushが使用されます。 パラメータは1つだけです。つまり、クリーンアップするストリームです。
最後の例を修正して、予測どおりに機能するようにします。
リスト6。
#含む
これで、プログラムは期待どおりに機能します。

図4フラッシュによるstdinバッファのフラッシュ
要約すると、2つの事実に注意することができます。 初め。 現時点ではgets関数を使用するのは安全ではないため、どこでもfgets関数を使用することをお勧めします。
2番。 fgets関数を使用している場合は、入力バッファーをフラッシュすることを忘れないでください。
これで、文字列の入力に関する会話は終わりです。 進む。
n»信頼できるSEOエージェンシーインドは中小企業の収益を増やすことができます
80%のユーザーが購入前にGoogleやその他の検索エンジンで検索し、検索エンジンを通じて生成された50%以上の問い合わせが変換されます。 これらの2つの統計は、検索エンジン最適化の重要性を証明しています。 明確なポイントを示すそのような統計や事実はたくさんあります。小規模、中規模、または大規模のビジネスには、専門的なSEOサービスが必要です。 中小企業や新興企業はしばしば予算の問題に直面します。 彼らは、インドの信頼できるSEO代理店の助けを借りて、予算内で最高のSEOサービスを取得し、収益を増やすことができます。
検索は消費者の心に大きな影響を与えます。 Search Engine Land、Moz、SEO Journal、Digital Marketers India、Hubspotなどのさまざまな認定Webサイトで主要な検索エンジン最適化の専門家が共有するさまざまな統計によると。 SEOはリードの大部分を獲得します。 また、オーガニック検索結果からのリードは、コンバージョン率が高くなります。 これらの統計と消費者行動は、最高のSEOサービスが贅沢ではなく、あらゆるビジネスにとって必要であることを明確に示しています。
競争を回避し、ビジネスの成長を促進するには、各組織が検索エンジン最適化サービスを使用する必要があります。 大手ブランドは、トップSEO企業またはSEOスペシャリストが提供するエキスパートSEOサービスに十分な資金を投資できますが、中小企業の所有者は、予算が少ないためにこのサービスの品質に妥協することがよくあります。 中小企業や新興企業が、プロのSEOサービスで作成できる機会を残したり、良い結果をもたらさない安価なSEOサービスを使用したりすることになるのは難しい事実です。
中小企業の経営者や新興企業は、限られた予算の中でもプロのSEOサービスを利用できます。 最善の解決策は、インドを拠点とする信頼できるSEO会社を見つけることです。 インドには、デジタルマーケティングエージェンシーと協力して業界最高のサービスを提供している多くのSEO専門家がいます。 彼らはあなたの予算内であなたに必要なSEOサービスを提供することができます。 賃金は、より低い料金でより良いサービスを得るために、SEOエージェンシーインドと交渉することができます。 ただし、専門知識には自己負担がかかるため、料金が安く、より多くのサービスを提供することを約束する安価なSEOサービスに騙されないでください。 あなたはあなたのビジネスのために会社と契約する前にポートフォリオを見るか、適切な質問をしなければなりません。
インドのSEO専門家は、検索エンジン最適化のベストプラクティスに精通しています。 また、Ash VyasなどのインドのSEOスペシャリストは、定められた予算内でビジネスに最適な検索エンジン最適化戦略を作成することを専門としています。 SEOの専門家は明確な計画を作成し、期待される結果を共有します。 このようにあなたはあなたの投資と収益をよく知ることができます。 これは、より良いビジネス上の意思決定を行うのに役立ちます。
できるだけ早く最高のSEOサービスを提供するインドの信頼できるSEO会社を見つけて契約することをお勧めします。 また、少額の予算と限られた活動から始めて、Webページのインデックスを作成し、検索エンジンでキーワードを増やすこともできます。 最高のSEOサービスに投資するのに何千ドルもかかる完璧な時間や日を待たないでください。 早期に開始することで、マーケティングアプローチに積極的に取り組むことができれば、より迅速な結果を得ることができます。 インドを拠点とする信頼できるSEO企業は、現在および将来の計画を定義して、良い結果を生み出すのに役立ちます。 より多くのインデックス付きページがランキングを上げ、継続的なプロのSEOプラクティスで作られたあなたのビジネスの信頼できるブランドは、問い合わせ、ビジネス、そして収益を倍増させます。 中小企業は、プロのSEOサービスへの2桁の投資から始めることができます。 インドには、低予算でありながら、指向性のある検索エンジン最適化サービスの結果であるSEOエージェンシーがたくさんあります。
亡命者からの調査
-
CraigWew
12.04.2018п»ї不動産および一般販売における顧客との信頼関係を確立することの重要性
お客様との信頼関係を築くことの重要性。
顧客との関係を確立することは獲得されなければならず、販売プロセスの非常に不可欠な部分としてアプローチされなければなりません。
顧客とあなた自身が実際に1対1で関係するようにするためには、2つのことが必要です。
まず、あなたは気づいてそこにいる必要があります! 次に、このプロセス中に発生する2つの異なる段階があることを理解する必要があります。
A-そこにいる-それはどういう意味ですか?
oほとんどの人は、話しているときに他の人の話を実際に聞きません。 一般的に、彼らは次の答えや声明を作成するのに忙しく、実際に聞くことができなかったでしょう。
oこれがあなたのように聞こえる場合、そこにいるということは黙って聞いてください!
B-最初の段階または初期段階は何ですか?
o通常、顧客の心の中で、彼らが対処したい人として自分自身を確立するのにほんの数分しかありません。
o疑問がある場合は、最初に質問をして、それを引き出し、自分自身について話すのが最善です。
oプロとして出演することも常に安全です。私はストイックやドライという意味ではありませんが、彼らが何をしているのかを知っていて、話したり、その部分を見たりする人です。
C-その他の段階
o時間が経つにつれて、彼らが持つ会話や質問を通して、あなたは自分の能力を確立するかどうかのどちらかになります。
o彼らはおそらくしばらくの間あなたを測定していることに注意してください。 良いニュースは、ある時点で、あなたが信頼関係を確立することに成功した場合、彼らはリラックスし、あなたは家を見つけるか売ることに集中することができるということです。
他に何が私が信頼関係を築くのを助けることができますか?
oさまざまな性格タイプを理解しようとし、次に適切な質問をして話します。
o良好な関係がある場合(顧客と同じ波長になります)、販売は基本的に終了します。今では、適切な家を見つけるか、リストペーパーに記入するだけです。
さまざまな性格はどうですか
oこれは精神医学に関する本ではないので、今のところ2つの主要なタイプを理解してください。
o内向的および外向的な人々がいます。
oあなたはタイプを知っています。 それぞれの分類に当てはまるあなたが知っている3人について考えてみてください。
ボディーランゲージとスピーチパターンはどうですか?
o話す速度が速い、または遅い場合は、発話パターンを模倣してみてください。
o彼らが大声でまたは小声で話す場合は、同じことをします。 彼らは前傾していますか、それとも後ろ傾していますか?
o言うまでもなく、このテーマについて書かれた本はたくさんあります。 これは重要な要素であることに注意してください。特に、会議室や誰かの家で40万ドルの取引について話し合っている場合はなおさらです。
信頼関係を築くことは、学び、向上させることができるスキルです。
o私たちは皆、私たちに何かを売ってくれたセールスマンを経験しましたが、それでも私たちが売られているような気がしませんでした。 その理由は、彼または彼女が、あなたが彼らを信頼した場所にあなたを快適に感じさせたからです。
どうすれば信頼関係を築くことができますか?
o目と耳を使って、質問をします。 説明する
o目を使用します。
o彼らのドレス-彼らの車-彼らの個人的な所有物を見てください、そして私は本当に彼らを見て、それが彼らについてあなたに何を伝えているかを解読することを意味します。
o耳を使用します。
o彼らの言うことに耳を傾け、質問をして、彼らの本当のモチベーションの根底に到達しましょう!
さて、このすべての会話の間に、あなたが彼らと共通していることに気付くであろう1つか2つのことがおそらくあるでしょう。 (家族、地理的地域、釣りなど)共通点に出くわしたら、親しみがあることを伝えてから、少し時間を取って話し合います。
目標は何ですか?
o彼らがあなたを彼らの一人として受け入れると、あなたはチームとして一緒に仕事をしているので、販売で本当に素晴らしい経験をすることができます。あなたはもはや顧問の立場にあるセールスマンではありません。 ..。。
o顧客は、あなたが自分の世界に入ることを許可するか、許可しないかのどちらかであることを忘れないでください。 これを理解し、彼/彼女に共感するために本当に一生懸命働くならば、あなたは信頼の地位を得ることができます。 ほとんどの場合、これが途中で起こったとき、あなたは実際に彼らがリラックスするのを見るでしょう(ボディーランゲージ)。
oこれを説明するために、スピーチをしたことがありますが、最終的に聴衆とつながると、彼らは承認をうなずきます。 これらはすべて些細なことのように見えるかもしれませんが、そうではありません。
最後に、顧客の信頼を得ることができれば、製品やサービスの販売ははるかに簡単になり、関係者全員にとってその体験はうっとりするものになります。
Win / Winが最良の状況であることを常に忘れないでください。
ハブラ、こんにちは!
少し前まで、私はコンピュータサイエンス大学の教師の1人が関与したというかなり興味深い事件を経験しました。
Linuxプログラミングについての会話は、この男がシステムプログラミングの複雑さは実際には非常に誇張されていると主張するところまでゆっくりと移動しました。 C言語は、実際にはLinuxカーネル(彼の言葉で)のように、一致するほど単純です。
紳士用のC開発ツール(gcc、vim、make、valgrind、gdb)のセットを備えたLinuxラップトップを持っていました。 そのとき私たちがどのような目標を設定したかはもう覚えていませんが、数分後、対戦相手はこのラップトップの後ろにいることに気づき、問題を完全に解決する準備ができました。
そして、文字通り最初の行で、彼は...行にメモリを割り当てるときに重大な間違いを犯しました。
Char * str =(char *)malloc(sizeof(char)* strlen(buffer));
bufferは、キーボードからのデータが書き込まれたスタック変数です。
「ここで何かおかしいのではないか」と尋ねる人は間違いなくいると思います。
私を信じてください、それはできます。
そして、正確には-カットを読んでください。
ちょっとした理論-一種のFaceBez。
わかっている場合は、次のヘッダーまでスクロールします。Cの文字列は文字の配列であり、友好的な方法で常に「\ 0」(行末文字)で終わる必要があります。 スタック(静的)上の文字列は、次のように宣言されます。
Char str [n] =(0);
nは文字配列のサイズで、文字列の長さと同じです。
代入(0)-文字列を「無効にする」(オプションで、文字列なしで宣言できます)。 結果は、memset(str、0、sizeof(str))およびbzero(str、sizeof(str))関数の場合と同じです。 初期化されていない変数のガベージを防ぐために使用されます。
また、スタックでは、次の行をすぐに初期化できます。
Char buf = "デフォルトのバッファテキスト\ n";
さらに、文字列をポインタとして宣言し、ヒープ上のメモリをその文字列に割り当てることができます。
Char * str = malloc(サイズ);
size-文字列に割り当てるバイト数。 このような文字列は動的と呼ばれます(必要なサイズが動的に計算され、割り当てられたメモリサイズはrealloc()関数を使用していつでも増やすことができるため)。
スタック変数の場合、配列のサイズを決定するために表記nを使用しました。ヒープ上の変数の場合、表記サイズを使用しました。 そして、これは、スタック上の宣言とヒープ上のメモリ割り当てを伴う宣言の違いの真の本質を完全に反映しています。これは、要素の数について話すときにnが通常使用されるためです。 そしてサイズは全然違う話です...
Valgrindは私たちを助けます
前回の記事でも触れました。 Valgrind(、2-小さなハウツー)-非常に 便利なプログラムこれは、プログラマーがメモリリークとコンテキストエラーを追跡するのに役立ちます。これらは、文字列を操作するときに最も頻繁に発生するものです。私が言及したプログラムに似たものを実装する小さなリストを見て、valgrindを実行してみましょう:
#含む
そして、実際には、プログラムの結果:
$ gcc main.c $ ./a.out->こんにちは、Habr!
これまでのところ珍しいことはありません。 それでは、このプログラムをvalgrindで実行しましょう!
$ valgrind --tool = memcheck ./a.out == 3892 == Memcheck、メモリエラー検出器== 3892 == Copyright(C)2002-2015、およびGNU GPL "d、by Julian Seward etal。== 3892 == Valgrind-3.12.0とLibVEXを使用します;著作権情報のために-hで再実行します== 3892 ==コマンド:./ a.out == 3892 == == 3892 ==サイズ2の無効な書き込み== 3892 = = at 0x4005B4:main(in /home/indever/prg/C/public/a.out)== 3892 ==アドレス0x520004cは、サイズ13のブロック内の12バイトalloc "d == 3892 == at 0x4C2DB9D:malloc (vg_replace_malloc.c:299)== 3892 == by 0x400597:main(in /home/indever/prg/C/public/a.out)== 3892 == == 3892 ==サイズ1の無効な読み取り== 3892 == at 0x4C30BC4:strlen(vg_replace_strmem.c:454)== 3892 == by 0x4E89AD0:vfprintf(in /usr/lib64/libc-2.24.so)== 3892 == by 0x4E90718:printf(in / usr / lib64 / libc-2.24.so)== 3892 == by 0x4005CF:main(in /home/indever/prg/C/public/a.out)== 3892 ==アドレス0x520004dはサイズ13のブロックの後の0バイトですalloc "d == 3892 == at 0x4C2DB9D:malloc(vg_replace_malloc.c:299)== 3892 == by 0x400597:main(in / home / indever / prg / C / public / a.out)== 3892 ==->こんにちは、Habr! == 3892 == == 3892 == HEAPの概要:== 3892 ==終了時に使用中:0ブロックで0バイト== 3892 ==合計ヒープ使用量:2割り当て、2解放、1,037バイト割り当て== 3892 = = == 3892 ==すべてのヒープブロックが解放されました-リークは発生しません== 3892 == == 3892 ==検出および抑制されたエラーのカウントについては、次のコマンドで再実行してください:-v == 3892 ==エラーの概要:3つのエラー2つのコンテキスト(抑制:0から0)
== 3892 ==すべてのヒープブロックが解放されました-リークは発生しません-リークはありません。これは朗報です。 しかし、目を少し低くする価値があります(ただし、これは要約にすぎず、基本的な情報は少し他の場所にあります)。
== 3892 ==エラーの概要:2つのコンテキストからの3つのエラー(抑制:0から0)
3つの間違い。 2つのコンテキストで。 そのような単純なプログラムで。 どのように!?
とても簡単です。 全体の「トリック」は、strlen関数が行末文字「\ 0」を考慮しないことです。 入力行(#define HELLO_STRING "Hello、Habr!\ N \ 0")で明示的に指定しても、無視されます。
プログラム実行の結果の少し上、行 ->こんにちは、Habr!私たちの貴重なvalgrindが気に入らなかったものと場所に関する詳細なレポートがあります。 私はこれらの線を自分で見て結論を出すことを提案します。
実際、プログラムの正しいバージョンは次のようになります。
#含む
valgrindを実行してみましょう:
$ valgrind --tool = memcheck ./a.out->こんにちは、Habr! == 3435 == == 3435 == HEAPの概要:== 3435 ==終了時に使用中:0ブロックで0バイト== 3435 ==合計ヒープ使用量:2割り当て、2解放、1,038バイト割り当て== 3435 = = == 3435 ==すべてのヒープブロックが解放されました-リークは発生しません== 3435 == == 3435 ==検出および抑制されたエラーのカウントについては、次のコマンドで再実行してください:-v == 3435 ==エラーの概要:0エラー0コンテキスト(抑制:0から0)
罰金。 エラーはありません。割り当てられたメモリの+1バイトが問題の解決に役立ちました。
興味深いことに、ほとんどの場合、最初のプログラムと2番目のプログラムはどちらも同じように機能しますが、終了文字が収まらない行に割り当てられたメモリが空でない場合、printf()関数はそのようなlineは、この行の後にすべてのガベージも出力します。すべては、行末文字がprintf()パスに表示されるまで表示されます。
ただし、(strlen(str)+ 1)はそのようなソリューションです。 私たちは2つの問題に直面しています:
- また、たとえばs(n)printf(..)を使用して形成された文字列にメモリを割り当てる必要がある場合はどうでしょうか。 引数はサポートしていません。
- 外観。 変数宣言行はひどいように見えます。 何人かの人はまた、まるで彼らがプラスの下で書いているかのように、mallocに(char *)をねじ込むことができます。 文字列を定期的に処理する必要があるプログラムでは、より洗練されたソリューションを見つけるのが理にかなっています。
snprintf()
int snprintf(char * str、size_t size、const char * format、...);--function --sprintfの拡張。文字列をフォーマットし、最初の引数として渡されたポインターに書き込みます。 strがsizeより多くのバイトを書き込まないという点で、sprintf()とは異なります。この関数には興味深い機能が1つあります。それは、生成された文字列のサイズをとにかく返します(行末文字を除く)。 文字列が空の場合、0が返されます。
strlenの使用に関して説明した問題の1つは、sprintf()およびsnprintf()関数に関連しています。 strに何かを書く必要があるとしましょう。 最後の文字列には、他の変数の値が含まれています。 エントリは次のようになります。
Char * str = / *ここにメモリを割り当てます* /; sprintf(str、 "Hello、%s \ n"、 "Habr!");
疑問が生じます:文字列strに割り当てるメモリの量をどのように決定するのですか?
Char * str = malloc(sizeof(char)*(strlen(str、 "Hello、%s \ n"、 "Habr!")+ 1)); - うまくいかないだろう。 strlen()関数のプロトタイプは次のようになります。
#含む
const char * sは、sに渡される文字列が可変数の引数を持つフォーマット文字列である可能性があることを意味するものではありません。
これは、前述のsnprintf()関数の便利なプロパティが役立つ場所です。 次のプログラムのコードを見てみましょう。
#含む
valgrindでプログラムを実行します。
$ valgrind --tool = memcheck ./a.out->こんにちは、Habr! == 4132 == == 4132 == HEAPの概要:== 4132 ==終了時に使用中:0ブロックで0バイト== 4132 ==合計ヒープ使用量:2割り当て、2解放、1,041バイト割り当て== 4132 = = == 4132 ==すべてのヒープブロックが解放されました-リークは発生しません== 4132 == == 4132 ==検出および抑制されたエラーのカウントについては、次のコマンドで再実行してください:-v == 4132 ==エラーの概要:0エラー0コンテキスト(抑制:0から0)$
罰金。 引数をサポートしています。 snprintf()関数の2番目の引数としてゼロを渡すため、nullポインターで書き込むとSeagfaultが発生することはありません。 ただし、これにもかかわらず、関数は文字列に必要なサイズを返します。
しかし一方で、変数を追加する必要があり、
Size_t required_mem = snprintf(NULL、0、 "Hello、%s!\ N"、 "Habr")+ sizeof( "\ 0");
strlen()よりもさらに悪く見えます。
一般に、+ sizeof( "\ 0")は、フォーマット文字列の最後に "\ 0"を明示的に指定することで削除できます(size_t required_mem = snprintf(NULL、0、 "Hello、%s!\ N \0
"、" Habr ");)ですが、これが常に可能であるとは限りません(ライン処理メカニズムによっては、追加のバイトを割り当てることができます)。
何かをする必要があります。 少し考えて、今が古代人の知恵に訴える時が来たと思いました。 最初の引数としてnullポインターを使用し、2番目の引数としてnullを使用してsnprintf()を呼び出すマクロ関数について説明します。 そして、行の終わりを忘れないでください!
#define strsize(args ...)snprintf(NULL、0、args)+ sizeof( "\ 0")
はい、それは誰かにとってニュースかもしれませんが、Cのマクロは可変数の引数をサポートし、楕円はプリプロセッサにマクロ関数の指定された引数(この場合はargs)がいくつかの実際の引数に対応することを伝えます。
実際にソリューションを確認してみましょう。
#含む
valgrundで実行:
$ valgrind --tool = memcheck ./a.out->こんにちは、Habr! == 6432 == == 6432 == HEAPの概要:== 6432 ==終了時に使用中:0ブロックで0バイト== 6432 ==合計ヒープ使用量:2割り当て、2解放、1,041バイト割り当て== 6432 = = == 6432 ==すべてのヒープブロックが解放されました-リークは発生しません== 6432 == == 6432 ==検出および抑制されたエラーのカウントについては、次のコマンドで再実行してください:-v == 6432 ==エラーの概要:0エラー0コンテキスト(抑制:0から0)
はい、間違いはありません。 すべてが正しいです。 そしてvalgrindは満足しており、プログラマーはついに眠りにつくことができます。
しかし、最後に、私は別のことを言います。 任意の文字列にメモリを割り当てる必要がある場合(引数がある場合でも)、すでに 完全に機能するターンキーソリューション.
それはasprintf関数についてです:
#define _GNU_SOURCE / * feature_test_macros(7)を参照* / #include
最初の引数として、文字列(** strp)へのポインタを取り、逆参照されたポインタにメモリを割り当てます。
asprintf()プログラムは次のようになります。
#含む
そして、実際には、valgrindでは:
$ valgrind --tool = memcheck ./a.out->こんにちは、Habr! == 6674 == == 6674 == HEAPの概要:== 6674 ==終了時に使用中:0ブロックで0バイト== 6674 ==合計ヒープ使用量:3割り当て、3解放、1,138バイト割り当て== 6674 = = == 6674 ==すべてのヒープブロックが解放されました-リークは発生しません== 6674 == == 6674 ==検出および抑制されたエラーのカウントについては、次のコマンドで再実行してください:-v == 6674 ==エラーの概要:0エラー0コンテキスト(抑制:0から0)
すべて問題ありませんが、ご覧のとおり、より多くのメモリが割り当てられ、2つではなく3つの割り当てがあります。弱い組み込みシステムでは、この機能は望ましくありません。
さらに、コンソールでman asprintfと書くと、次のようになります。
準拠これらの関数はGNU拡張機能であり、CまたはPOSIXではありません。 * BSDでも利用できます。 FreeBSD実装は、エラー時にstrpをNULLに設定します。
このことから、この機能はGNUソースでのみ利用可能であることが明らかです。
結論
結論として、Cで文字列を操作することは、多くのニュアンスを持つ非常に複雑なトピックであると言いたいです。 たとえば、「安全な」コードを書くには 動的割り当てメモリの場合でも、malloc()の代わりにcalloc()関数を使用することをお勧めします-callocは割り当てられたメモリをゼロで詰まらせます。 または、メモリを割り当てた後、memset()関数を使用します。 そうしないと、割り当てられたメモリ領域に元々存在していたガベージが、デバッグ中、および場合によっては文字列を操作しているときに質問を引き起こす可能性があります。私の要求に応じて、文字列にメモリを割り当てる問題を解決した私の仲間のCプログラマー(ほとんどは初心者)の半数以上が、最終的にコンテキストエラーにつながるような方法でそれを行いました。 あるケースでは、メモリリークが発生した場合でも(まあ、人は解放するのを忘れていました(str)、そうはなりません)。 実際、これはあなたが今読んだこの作品を作成するように私に促しました。
この記事がお役に立てば幸いです。 なぜ私はこれらすべてを交渉したのですか?単純な言語はありません。 どこにでも独自の微妙さがあります。 そして、あなたが知っている言語の微妙さが多ければ多いほど、あなたのコードはより良くなります。
この記事を読んだ後、あなたのコードは少し良くなると思います:)
頑張って、Habr!
文字列の宣言
C文字列は、文字の1次元配列であり、その最後の要素はnullで終了する文字列(nullで終了する文字列)です。
C言語で文字列型の変数を宣言することは3つの方法で可能であり、そのうちの2つは宣言中に文字列を初期化します。
最初の方法:
文字配列宣言(末尾のnull用のスペースを追加することを忘れないでください):
Char s;
2番目の方法:
文字列変数に初期値を割り当てます(この場合、コンパイラは文字列自体の長さを計算できます)。
Char s = "文字列の初期化の例";
代入記号の右側に文字列定数が書き込まれます。 行の終わりにゼロ( '\ 0')が自動的に追加されます。 文字列定数はスタティックメモリクラスに配置されます。
3番目の方法:
配列が使用されていることを暗黙的に示します。 割り当て記号の左側には、記号へのポインターがあります。
Char * s = "2番目の初期化オプション";
s変数は、文字列定数が配置されているRAM内の場所へのポインタになります。 この形式の表記法には潜在的な誤りがあります。つまり、文字へのポインタは文字列と呼ばれることがよくあります。 以下のエントリは、文字列を配置するスペースがないため、文字へのポインタにすぎません。
Char * s;
標準の入力デバイス(キーボード)から文字列を入力する
文字列を操作するための一連の関数があります。 標準入力デバイス(キーボード)からの入力には、標準入出力モジュールのライブラリ関数が最もよく使用されます。 scanfと 取得.
関数を使用して文字列を入力するには scanf、形式を使用します « % NS» 、および文字列識別子の前にアドレス記号が使用されていないことに注意してください « & » 、1次元配列はすでにその先頭へのポインタで表されているため、次のようになります。
Scanf( "%s"、s);
関数 取得 ()改行文字に達するまで文字を読み取ります。 この関数は、改行文字までのすべての文字を受け入れますが、それは含まれません。 末尾のゼロ( '\ 0')が行の終わりに追加されます。 関数 取得 ()キーボードから読み取られた文字のシーケンスをstring型のパラメーターに入れ、この文字列へのポインター(操作が成功した場合)またはNULL(エラーの場合)を返します。 以下の例では、操作が正常に完了すると、2つの同じ行が画面に表示されます。
#含む
ちなみに、gets関数は、sscanf関数を目的の形式にさらに変換する目的で、または入力データの予備分析のために、キーボードから任意のデータを文字列として入力するためによく使用されることに注意してください。
#含む
標準出力への出力ライン(モニタ画面)
2つの機能を使用して文字列を標準出力に出力できます(モニター画面) printfと プット..。 printf関数では、「%s」がフォーマットとして渡されます。 この関数を使用すると、文字列に加えて、他のタイプのデータをすぐに出力できるという利点があります。 機能機能 プット行の出力後、次の行への遷移が自動的に発生するという事実にあります。
文字列を操作するための関数
文字列ライブラリは、C言語で文字列を変換するために提供されています。 各機能には、独自の記録形式(プロトタイプ)があります。
この記事では、最もよく使用される関数について説明します。 - 読んだ
文字列を操作するプログラム(リスト)の例