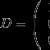フォン・ノイマン原理とは何ですか? ジョン・フォン・ノイマンの原則。 コンピュータの世代 現代のコンピューターの分類
フォン・ノイマン原則 (フォン・ノイマン・アーキテクチャ)
コンピュータアーキテクチャ
1946 年、D. フォン ノイマン、G. ゴールドスタイン、A. バークスは共同論文で、コンピューターの構築と操作に関する新しい原理を概説しました。 その後、最初の 2 世代のコンピューターがこれらの原理に基づいて製造されました。 ノイマンの原則は今日でも有効ですが、後の世代ではいくつかの変更がありました。
実際、ノイマンは他の多くの科学者の科学的発展と発見を要約し、それらに基づいて根本的に新しいものを定式化することに成功しました。
フォン・ノイマンの原理
コンピューターでの 2 進数システムの使用。 10 進数システムに対する利点は、デバイスを非常に単純に作成できることと、2 進数システムでの算術演算および論理演算も非常に簡単に実行できることです。
コンピュータソフトウェア制御。 コンピュータの動作は、一連のコマンドからなるプログラムによって制御されます。 コマンドは次々と順番に実行されます。 プログラムが保存されたマシンの作成は、今日私たちがプログラミングと呼ぶものの始まりでした。
コンピュータのメモリは、データの保存だけでなくプログラムの保存にも使用されます。。 この場合、プログラム コマンドとデータは両方とも 2 進数システムでエンコードされます。 録音方法は同じです。 したがって、特定の状況では、コマンドに対してデータに対してと同じアクションを実行できます。
コンピュータのメモリセルには連続した番号が付けられたアドレスがあります。 いつでも、アドレスによって任意のメモリ セルにアクセスできます。 この原理により、プログラミングで変数を使用できる可能性が開かれました。
プログラム実行中の条件ジャンプの可能性。 コマンドは順番に実行されるという事実にもかかわらず、プログラムはコードの任意のセクションにジャンプする機能を実装できます。
これらの原則の最も重要な結果は、プログラムがもはやマシンの永続的な部分 (たとえば、計算機など) ではなくなったことです。 簡単にプログラムを変更できるようになりました。 しかし、もちろん設備は変わっておらず、非常にシンプルです。
比較すると、ENIAC コンピュータ (プログラムが保存されていない) のプログラムは、パネル上の特別なジャンパによって決定されていました。 マシンを再プログラムする (ジャンパを別の設定にする) には 1 日以上かかる場合があります。 また、最新のコンピュータ用のプログラムを作成するには何年もかかりますが、ハード ドライブに数分インストールするだけで、何百万ものコンピュータで動作します。
フォン・ノイマンマシンはどのように動作するのでしょうか?
ノイマン型マシンは、記憶装置 (メモリ) - メモリ、算術論理演算装置 - ALU、制御装置 - CU、および入出力デバイスで構成されます。
プログラムとデータは、入力装置から算術論理演算装置を介してメモリに入力されます。 すべてのプログラムコマンドは隣接するメモリセルに書き込まれ、処理対象のデータを任意のセルに含めることができます。 どのプログラムでも、最後のコマンドはシャットダウン コマンドでなければなりません。
コマンドは、(特定のハードウェア上で可能な操作の中から) どのような操作を実行すべきかの指示と、指定された操作を実行するデータが保存されているメモリ セルのアドレス、およびセルのアドレスで構成されます。結果を書き込む場所 (メモリに保存する必要がある場合)。
算術論理演算装置は、指定されたデータに対して命令によって指定された演算を実行します。
算術論理演算ユニットからの結果はメモリまたは出力デバイスに出力されます。 メモリと出力デバイスの基本的な違いは、メモリにはデータがコンピュータによる処理に便利な形式で保存され、データが出力デバイス (プリンタ、モニタなど) に便利な方法で送信されることです。人のために。
コントロールユニットはコンピュータのすべての部分を制御します。 他のデバイスは制御デバイスから「何をすべきか」という信号を受け取り、制御ユニットは他のデバイスからその状態に関する情報を受け取ります。
制御デバイスには、「プログラム カウンタ」と呼ばれる特別なレジスタ (セル) が含まれています。 プログラムとデータをメモリにロードした後、プログラムの最初の命令のアドレスがプログラム カウンタに書き込まれます。 コントロールユニットは、プログラムカウンタにあるアドレスを持つメモリセルの内容をメモリから読み取り、それを特別なデバイスである「コマンドレジスタ」に置きます。 制御ユニットはコマンドの動作を決定し、コマンドでアドレスが指定されているデータをメモリ内で「マーク」し、コマンドの実行を制御します。 この演算は、ALU またはコンピューター ハードウェアによって実行されます。
コマンドを実行すると、プログラム カウンタが 1 つ変化し、プログラムの次のコマンドを指します。 現在のコマンドの次ではないが、指定されたコマンドから特定のアドレス数だけ離れたコマンドを実行する必要がある場合、特別なジャンプ コマンドには制御を移す必要があるセルのアドレスが含まれます。 。
フォン・ノイマンの原理[編集 | ソーステキストを編集]
記憶均一性の原理
コマンドとデータは同じメモリに保存され、外部からはメモリ内で区別できません。 それらは使用方法によってのみ認識できます。 つまり、メモリセル内の同じ値は、アクセス方法にのみ応じて、データ、コマンド、およびアドレスとして使用できます。 これにより、数値に対するのと同じ操作をコマンドに対しても実行できるようになり、さまざまな可能性が広がります。 したがって、コマンドのアドレス部分を周期的に変更することにより、データ配列の連続する要素にアクセスすることができます。 この手法はコマンド変更と呼ばれますが、最新のプログラミングの観点からはお勧めできません。 さらに有用なのは、あるプログラムからの命令が別のプログラムの実行の結果として得られる場合、同質性原理の別の結果です。 この可能性は翻訳、つまりプログラムテキストを高級言語から特定のコンピュータの言語に翻訳することの根底にあります。
ターゲティングの原則
構造的には、メイン メモリは番号が付けられたセルで構成されており、プロセッサはいつでも任意のセルを使用できます。 コマンドやデータのバイナリコードはワードと呼ばれる情報の単位に分割されてメモリセルに格納されており、アクセスするには対応するセルの番号、つまりアドレスが使用されます。
プログラム制御原理
問題を解決するためにアルゴリズムによって提供されるすべての計算は、一連の制御ワード、つまりコマンドで構成されるプログラムの形式で提示する必要があります。 各コマンドは、コンピューターによって実装される一連の操作の中から何らかの操作を規定します。 プログラム コマンドはコンピュータの連続したメモリ セルに格納され、自然な順序、つまりプログラム内の位置の順序で実行されます。 必要に応じて、特別なコマンドを使用して、このシーケンスを変更できます。 プログラム コマンドの実行順序を変更する決定は、以前の計算結果の分析に基づいて、または無条件に行われます。
バイナリコーディングの原理
この原則に従って、データとコマンドの両方のすべての情報は 2 進数の 0 と 1 でエンコードされます。各種類の情報は 2 進数のシーケンスで表され、独自の形式を持ちます。 特定の意味を持つフォーマット内のビットのシーケンスはフィールドと呼ばれます。 数値情報には通常、符号フィールドと有効数字フィールドがあります。 コマンドフォーマットでは、オペレーションコードフィールドとアドレスフィールドの 2 つのフィールドを区別できます。
もう 1 つの真に革新的なアイデアは、その重要性を過大評価することが困難ですが、ノイマンによって提案された「ストアド プログラム」原理です。 当初、プログラムは特別なパッチパネルにジャンパを取り付けて設定されました。 これは非常に労働集約的な作業でした。たとえば、ENIAC マシンのプログラムを変更するには数日かかりました (一方、計算自体は数分しか続かず、ランプが故障しました)。 ノイマンは、プログラムが処理する数値と同じメモリに一連の 0 と 1 として保存できることに最初に気づきました。 プログラムとデータの間に根本的な違いがないため、コンピュータは計算結果に応じて自らプログラムを作成することが可能になりました。
フォン・ノイマンは、コンピューターの論理構造の基本原理を提唱しただけでなく、コンピューターの最初の 2 世代の間に再現されたその構造も提案しました。 Neumann 氏によると、主なブロックは、制御ユニット (CU) と算術論理演算ユニット (ALU) (通常は中央プロセッサに結合される)、メモリ、外部メモリ、入出力デバイスです。 このようなコンピュータの設計図を図に示します。 外部メモリは、コンピュータにとって便利な形式でデータが入力されるが、人間が直接認識することはできないという点で、入出力装置とは異なることに留意すべきである。 したがって、磁気ディスクドライブは外部メモリを指し、キーボードは入力装置、ディスプレイと印刷装置は出力装置です。

米。 1. ノイマンの原理に基づいて構築されたコンピュータ アーキテクチャ。 矢印付きの実線は情報の流れの方向を示し、点線はプロセッサから他のコンピュータ ノードへの制御信号を示します。
最新のコンピュータの制御デバイスと算術論理ユニットは、メモリや外部デバイスからの情報のコンバータであるプロセッサという 1 つのユニットに結合されています (これには、メモリからの命令の取得、エンコードとデコード、算術演算を含むさまざまな実行が含まれます) 、運用、コンピュータノードの運用の調整)。 プロセッサの機能については、以下でさらに詳しく説明します。
メモリ(記憶装置)には情報(データ)やプログラムが保存されています。 最新のコンピュータのストレージ デバイスは「多層」になっており、ランダム アクセス メモリ (RAM) が含まれており、コンピュータが特定の時点で直接動作している情報 (実行可能プログラム、それに必要なデータの一部、その他の情報) が保存されます。制御プログラム)、および外部記憶装置 (ESD) ) RAM よりもはるかに大きな容量。 ただし、アクセスは大幅に遅くなります (また、保存された情報の 1 バイトあたりのコストも大幅に低くなります)。 メモリ デバイスの分類は RAM と VRAM だけで終わるわけではありません。特定の機能は、SRAM (スーパー ランダム アクセス メモリ)、ROM (読み取り専用メモリ)、およびその他のコンピュータ メモリのサブタイプの両方によって実行されます。
説明したスキームに従って構築されたコンピュータでは、命令がメモリから順次読み取られて実行されます。 次のメモリセルの番号(アドレス)。 次のプログラムコマンドがどのコマンドから抽出されるかは、特別なデバイス、つまりコントロールユニット内のコマンドカウンターによって示されます。 その存在もまた、当該建築の特徴の一つである。
フォン ノイマンによって開発されたコンピューティング デバイスのアーキテクチャの基礎は、文献で「フォン ノイマン アーキテクチャ」という名前が付けられるほど基本的なものであることが判明しました。 今日のコンピューターの大部分はノイマン型マシンです。 唯一の例外は、プログラム カウンターがなく、変数の古典的な概念が実装されていない、古典的なモデルとのその他の重要な基本的な違いがある、並列コンピューティング用の特定の種類のシステムです (ストリーミング コンピューターやリダクション コンピューターなど)。
どうやら、情報処理が計算ではなく論理的な結論に基づいて行われる第5世代マシンのアイデアの開発の結果、ノイマン型アーキテクチャからの大幅な逸脱が発生するようです
 .
.
基本的な四則演算を実行できる最初の加算機は、有名なフランスの科学者であり哲学者であるブレーズ パスカルの加算機でした。 その主な要素は歯車であり、その発明自体がコンピュータ技術の歴史において重要な出来事となりました。 コンピューター技術の分野における進化は不均一で、発作的に行われていることに注意したいと思います。力が蓄積された期間は開発のブレークスルーに置き換えられ、その後は安定期が始まり、その間に達成された結果は実際に使用され、また、次の段階で使用されます。同時に次の飛躍のための知識と力が蓄積されます。 それぞれの革命の後、進化のプロセスは新たなより高いレベルに到達します。
1671 年、ドイツの哲学者で数学者のグスタフ ライプニッツも、特別なデザインの歯車であるライプニッツ歯車をベースにした加算機を作成しました。 ライプニッツの加算マシンは、彼の前任者の加算マシンと同様に、4 つの基本的な算術演算を実行しました。 この時代は終わり、人類はほぼ 1 世紀半にわたって、コンピューター テクノロジーの次の進化に向けて力と知識を蓄積してきました。 18世紀から19世紀は、数学や天文学をはじめとするさまざまな科学が急速に発展した時代でした。 多くの場合、時間と労力を要する計算を必要とするタスクが含まれていました。
コンピューティングの歴史におけるもう一人の有名な人物は、イギリスの数学者チャールズ・バベッジです。 1823 年、バベッジは多項式を計算する機械の開発を開始しましたが、さらに興味深いことに、この機械は計算を直接行うことに加えて、結果を生成することになっていました。結果を写真プリント用のネガ版に印刷することになっていました。 この機械は蒸気エンジンを動力源とすることが計画されていました。 技術的な問題により、バベッジはプロジェクトを完了できませんでした。 ここで初めて、何らかの外部(周辺)デバイスを使用して計算結果を出力するというアイデアが生まれました。 それにも関わらず、別の科学者であるシャイツが 1853 年にバベッジによって考案された機械を実装したことに注意してください (計画よりもさらに小型であることが判明しました)。 バベッジはおそらく、新しいアイデアを何か物質的なものに変換するよりも、新しいアイデアを探す創造的なプロセスを好みました。 1834 年に、彼は「分析」と呼んだ別の機械の動作原理を概説しました。 技術的な問題により、彼は再び自分のアイデアを完全に実現することができなくなりました。 バベッジはこのマシンを実験段階まで持ち込むことしかできませんでした。 しかし、科学と技術の進歩の原動力となるのはアイデアです。 Charles Babbage の次のマシンは、次のアイデアを具体化したものでした。
生産工程管理。 機械が織機の動作を制御し、特殊な紙テープの穴の組み合わせによって、出来上がる生地の模様が変わります。 このテープは、パンチカードやパンチテープとしてよく知られている情報媒体の前身となりました。
プログラマビリティ。 この機械も穴のあいた特殊な紙テープによって制御されていました。 穴の順序によって、コマンドとそのコマンドによって処理されるデータが決まります。 その機械には演算装置と記憶装置が搭載されていた。 このマシンのコマンドには、中間結果に応じて計算の流れを変更する条件付きジャンプ コマンドも含まれていました。
このマシンの開発には、世界初のプログラマーとされるエイダ・オーガスタ・ラブレス伯爵夫人が参加しました。
チャールズ・バベッジのアイデアは、他の科学者によって開発され、使用されました。 そこで、20 世紀初頭の 1890 年に、アメリカ人のハーマン ホレリスは、データ テーブルを操作するマシン (最初の Excel?) を開発しました。 この機械はパンチカード上のプログラムによって制御されていました。 1890 年の米国国勢調査で使用されました。 1896 年、ホレリスは IBM の前身となる会社を設立しました。 バベッジの死により、20 世紀の 30 年代までのコンピューティング テクノロジーの進化に新たな区切りが訪れました。 その後、人類の発展はコンピューターなしでは考えられなくなりました。
1938 年に、開発の中心は一時的にアメリカからドイツに移り、そこで Konrad Zuse は、前任者とは異なり、10 進数ではなく 2 進数で動作するマシンを作成しました。 このマシンもまだ機械式でしたが、その間違いなく利点は、データをバイナリ コードで処理するというアイデアを実装したことでした。 研究を続けながら、Zuse は 1941 年にリレーをベースにした演算装置である電気機械機械を作成しました。 マシンは浮動小数点演算を実行できます。
海外では、アメリカでもこの時期に同様の電気機械機械を作成する作業が進められていました。 1944 年、ハワード エイケンは Mark-1 と呼ばれるマシンを設計しました。 彼女は、ズーゼのマシンと同様に、リレーに取り組みました。 しかし、このマシンは明らかにバベッジの作品の影響下で作成されたため、10 進数形式のデータで動作しました。
当然のことながら、機械部品の割合が高いため、これらの機械は運命にありました。
4 世代のコンピューター
20 世紀の 30 年代の終わりまでに、複雑なコンピューティング プロセスの自動化の必要性が大幅に高まりました。 これは、航空機製造、核物理学などの産業の急速な発展によって促進されました。 1945 年から現在に至るまで、コンピューター テクノロジーは 4 世代にわたって発展してきました。
初代
第一世代 (1945 ~ 1954 年) - 真空管コンピューター。 これらは先史時代、コンピューター技術の出現の時代です。 第一世代のマシンのほとんどは実験装置であり、特定の理論原理をテストするために構築されました。 これらのコンピューター恐竜の重量と大きさは、しばしば独立した建物を必要とするため、長い間伝説になっていました。
1943 年初め、米国のハワード エイトケン、J. モークリー、P. エッカートが率いる専門家グループは、電磁リレーではなく真空管に基づいたコンピューターの設計を開始しました。 このマシンは ENIAC (Electronic Numeral Integrator And Computer) と呼ばれ、Mark-1 よりも 1,000 倍高速に動作しました。 ENIACには1万8千本の真空管が含まれており、面積は9×15メートル、重さは30トン、消費電力は150キロワットでした。 ENIAC には重大な欠点もありました。パッチ パネルを使用して制御され、メモリがなく、プログラムを設定するにはワイヤを正しい方法で接続するのに数時間、場合によっては数日かかりました。 すべての欠点の中で最悪だったのは、コンピューターの信頼性が恐ろしく低いことでした。1 日の稼働中に約 12 本の真空管が故障したためです。
プログラムの設定プロセスを簡素化するために、モークリーとエッカートは、メモリにプログラムを保存できる新しいマシンの設計を開始しました。 1945 年に、有名な数学者ジョン フォン ノイマンがこの作業に関与し、このマシンに関する報告書を作成しました。 このレポートで、フォン ノイマンは、ユニバーサル コンピューティング デバイスの機能の一般原則を明確かつ単純に定式化しました。 コンピューター。 これは真空管で構築された最初の実用的なマシンであり、1946 年 2 月 15 日に正式に稼働しました。 彼らはこの機械を使って、フォン・ノイマンが用意した原爆計画に関連したいくつかの問題を解決しようとしました。 その後、アバディーン試験場に輸送され、1955 年まで運用されました。
ENIAC は、第 1 世代コンピュータの最初の代表者となりました。 いずれの分類も条件付きですが、ほとんどの専門家は、マシンが構築される要素ベースに基づいて世代を区別する必要があることに同意しました。 したがって、初代は真空管機であると思われます。
第一世代テクノロジーの開発におけるアメリカの数学者フォン・ノイマンの多大な役割に注目する必要があります。 ENIAC の長所と短所を理解し、その後の開発に向けた推奨事項を作成する必要がありました。 フォン・ノイマンと同僚の G. ゴールドシュタインおよび A. バークスによる報告書 (1946 年 6 月) は、コンピューターの構造の要件を明確に定式化しました。 この報告書の規定の多くはフォン・ノイマン原則と呼ばれていました。
国産コンピュータの最初のプロジェクトは S.A. によって提案されました。 レベデフ、B.I. 1948年のラメーエフ 1949 年から 1951 年にかけて。 S.A.のプロジェクトによると レベデフ、MESM(小型電子計算機)を製作。 この機械のプロトタイプの最初の試験打ち上げは 1950 年 11 月に行われ、この機械は 1951 年に運用開始されました。 MESM は 3 アドレスのコマンド システムを備えたバイナリ システムで動作し、計算プログラムは動作可能な記憶装置に格納されました。 並列ワードプロセッサを備えた Lebedev のマシンは、根本的に新しいソリューションでした。 これは世界で最初のコンピューターの 1 つであり、プログラムが格納されたヨーロッパ大陸初のコンピューターでした。
第 1 世代コンピュータには、S.A. の主導で開発された BESM-1 (大型電子計算機) も含まれています。 レベデヴァは 1952 年に完成し、5,000 個のランプが含まれており、10 時間故障することなく動作しました。 パフォーマンスは 1 秒あたり 10,000 オペレーションに達しました (付録 1)。
ほぼ同時に、Yu.Ya のリーダーシップの下、Strela コンピューター (付録 2) が設計されました。 バジレフスキー、1953年。 それは生産に投入されました。 その後、Ural - 1 コンピューター (付録 3) が登場しました。これは、B.I. の指導の下で開発され、生産された一連のウラル マシンの始まりとなりました。 ラメーバ。 1958年 第一世代コンピュータ M-20 (最大 20,000 操作/秒の速度) が量産されました。
第一世代のコンピューターの速度は、1 秒あたり数万回の演算でした。 内部メモリとしてフェライト コアが使用され、ALU と制御ユニットは電子管上に構築されました。 コンピュータの速度は、より遅いコンポーネントである内部メモリによって決定され、これにより全体的な影響が減少しました。
第一世代のコンピューターは算術演算を実行することを目的としていました。 これらを分析タスクに適用しようとしたところ、効果がないことが判明しました。
プログラミング言語自体はまだ存在しておらず、プログラマーは機械語命令またはアセンブラを使用してアルゴリズムをコーディングしていました。 これにより、プログラミングプロセスが複雑になり、遅れが生じました。
50 年代の終わりまでに、プログラミング ツールは根本的な変化を遂げていました。汎用言語と標準プログラムのライブラリを使用したプログラミングの自動化への移行が行われました。 世界共通言語の使用は翻訳者の出現につながりました。
プログラムはタスクごとに実行されました。 オペレーターはタスクの進行状況を監視し、終了に達したら次のタスクを開始する必要がありました。
第2世代
第 2 世代のコンピュータ (1955 ~ 1964 年) では、真空管の代わりにトランジスタが使用され、現代のハードドライブの遠い祖先である磁気コアと磁気ドラムがメモリデバイスとして使用され始めました。 これらすべてにより、コンピュータのサイズとコストを大幅に削減することが可能になり、コンピュータは初めて販売用に製造され始めました。
しかし、この時代の主な成果はプログラムの分野に属します。 第 2 世代のコンピューターでは、現在オペレーティング システムと呼ばれるものが初めて登場しました。 同時に、最初の高級言語であるFortran、Algol、Cobolが開発されました。 これら 2 つの重要な改善により、コンピューター プログラムの作成がはるかに簡単かつ迅速になりました。 プログラミングは科学でありながら、工芸品の機能を獲得します。
これに伴い、コンピュータの応用範囲も拡大した。 今や、コンピューティング技術へのアクセスを当てにできるのは科学者だけではなくなりました。 コンピュータは計画や管理に使用され、一部の大企業では会計のコンピュータ化さえ行われ、この流行を 20 年先取りしていました。
半導体は第 2 世代の要素基盤となりました。 間違いなく、トランジスタは 20 世紀で最も印象的な奇跡の 1 つであると考えられます。
トランジスタの発見に関する特許は 1948 年にアメリカ人の D. バーディーンと W. ブラッテンに発行され、8 年後、彼らは理論家の V. ショックレーとともにノーベル賞受賞者になりました。 非常に最初のトランジスタ素子のスイッチング速度は、真空管素子のスイッチング速度の数百倍であり、信頼性と効率も高いことが判明しました。 初めて、フェライト コアと磁性薄膜上のメモリが広く使用され始め、誘導素子 (パラメータ) がテストされました。
大陸間ロケットに搭載された最初の搭載コンピューターであるアトラスは、1955 年に米国で運用開始されました。 このマシンは 2 万個のトランジスタとダイオードを使用し、消費電力は 4 キロワットでした。1961 年には、バローズの地上ベースのストレッチ コンピューターがアトラス ロケットの宇宙飛行を制御し、IBM のマシンが宇宙飛行士ゴードン クーパーの飛行を制御しました。 このコンピューターは、1964 年に月へ向かうレンジャー型無人宇宙船や、火星へ向かうマリナー宇宙船の飛行を制御しました。 ソ連のコンピューターも同様の機能を実行していました。
1956 年、IBM はエアクッション上の浮遊磁気ヘッドを開発しました。 彼らの発明により、新しいタイプのメモリ、つまりディスク記憶装置の作成が可能になり、その後の数十年間のコンピュータ技術の発展でその重要性が十分に認識されました。 最初のディスク記憶装置は、IBM-305 および RAMAC マシンに登場しました (付録 4)。 後者は、12,000 rpm の速度で回転する 50 枚の磁気コーティングされた金属ディスクからなるパッケージを備えていました。 ディスクの表面には、データを記録するための 100 トラックがあり、各トラックには 10,000 文字が含まれていました。
トランジスタを搭載した最初の量産メインフレーム コンピュータは 1958 年に米国、ドイツ、日本で同時に発売されました。
最初のミニコンピューターが登場します (たとえば、PDP-8 (付録 5))。
ソ連では、最初のランプのない機械「セトゥーン」、「ラズダン」、「ラズダン-2」が 1959 年から 1961 年にかけて製造されました。 60 年代にソ連の設計者は約 30 モデルのトランジスタ コンピュータを開発し、そのほとんどが量産され始めました。 その中で最も強力なミンスク-32 は 1 秒あたり 65,000 回の操作を実行しました。 「ウラル」、「ミンスク」、BESMの車両ファミリー全体が登場しました。
第 2 世代コンピューターの記録保持者は BESM-6 (付録 6) で、その速度は 1 秒あたり約 100 万回で、世界で最も生産性の高いコンピューターの 1 つです。 このコンピュータのアーキテクチャと多くの技術的ソリューションは非常に進歩的で時代を先取りしており、ほぼ私たちの時代まで問題なく使用されてきました。
特に、ウクライナ・ソビエト社会主義共和国科学アカデミーのサイバネティクス研究所における工学計算の自動化については、学者V.M. の指導の下で行われました。 グルシコフは MIR (1966 年) および MIR-2 (1969 年) コンピューターを開発しました。 MIR-2 マシンの重要な特徴は、情報を視覚的に制御するためのテレビ画面と、画面上でデータを直接修正できるライト ペンの使用でした。
約10万個のスイッチング素子を含むこのようなシステムの構築は、ランプ技術に基づいてはまったく不可能です。 したがって、第 2 世代は、第 1 世代の機能の多くを取り入れて誕生しました。 しかし、60 年代半ばまでに、トランジスタ生産分野のブームは最大に達し、市場は飽和状態になりました。 実際のところ、電子機器の組み立ては非常に労働集約的で時間のかかるプロセスであり、機械化や自動化には適していませんでした。 したがって、要素間の従来の接続を排除することで回路の複雑さの増大に対応する新しいテクノロジーへの移行の条件は熟しています。
三代目
最後に、コンピュータの第 3 世代 (1965 ~ 1974 年) では、単一の半導体結晶上に作られたデバイス全体と数十、数百のトランジスタのユニットである集積回路 (現在マイクロ回路と呼ばれるもの) が初めて使用され始めました。 同時に半導体メモリも登場し、今でもパソコンの中でRAMとして一日中使われています。 第 3 世代コンピューターの基本基盤となった集積回路の発明における優先権は、この発見を互いに独立して行ったアメリカの科学者 D. キルビーと R. ノイスにあります。 集積回路の大量生産は 1962 年に始まり、1964 年には個別素子から集積素子への移行が急速に始まりました。 前述の ENIAK は 9 × 15 メートルの大きさで、1971 年には 1.5 平方センチメートルの板の上に組み立てられていた可能性があります。 エレクトロニクスからマイクロエレクトロニクスへの変革が始まりました。
この数年間で、コンピュータの生産は産業規模になりました。 リーダーとなった IBM は、コンピューター ファミリを初めて導入しました。これは、最小のものから小さなクローゼットのサイズまで、相互に完全に互換性のある一連のコンピューターです (当時、IBM はこれより小さいものは開発していませんでした)。最も強力で高価なモデルまで。 当時最も普及していたのは IBM の System/360 ファミリで、これに基づいて ES シリーズのコンピュータがソ連で開発されました。 1973 年に ES シリーズの最初のコンピューター モデルがリリースされ、1975 年以降、モデル ES-1012、ES-1032、ES-1033、ES-1022 が登場し、その後、より強力な ES-1060 が登場しました。
第 3 世代の一部として、ユニークなマシン「ILLIAK-4」が米国で製造されました。オリジナルのバージョンでは、モノリシック集積回路で作られた 256 個のデータ処理デバイスを使用することが計画されていました。 このプロジェクトは、かなり高額な費用 (1,600 万ドル以上) のため、後に変更されました。 プロセッサの数を 64 個に減らす必要があり、また、集積度の低い集積回路に切り替える必要がありました。 このプロジェクトの短縮バージョンは 1972 年に完了し、ILLIAC-4 の公称速度は 1 秒あたり 2 億操作でした。 ほぼ 1 年間、このコンピュータは計算速度の記録を保持していました。
60 年代初頭に遡ると、最初のミニコンピューターが登場しました。これは、小規模な企業や研究室にとって手頃な価格の、小型で低電力のコンピューターです。 ミニコンピューターはパーソナル コンピューターへの第一歩を表し、そのプロトタイプは 70 年代半ばになって初めてリリースされました。 Digital Equipment のよく知られた PDP ミニコンピュータ ファミリは、ソビエト SM シリーズ マシンのプロトタイプとして機能しました。
一方、1 つの超小型回路に収まる要素と要素間の接続の数は増え続け、70 年代にはすでに集積回路に数千のトランジスタが含まれていました。 これにより、ほとんどのコンピュータ コンポーネントを 1 つの小さな部品に組み合わせることが可能になりました。インテルは 1971 年にこれを実行し、登場したばかりのデスクトップ電卓を対象とした最初のマイクロプロセッサをリリースしました。 この発明は、次の 10 年で真の革命を生み出す運命にありました。結局のところ、マイクロプロセッサは私たちのパーソナル コンピュータの心臓部であり、魂です。
しかし、それだけではありません。本当に、60 年代から 70 年代の変わり目は運命の時代でした。 1969 年に、現在インターネットと呼ばれるものの初期となる、最初の世界的なコンピューター ネットワークが誕生しました。 そして同じ 1969 年に、Unix オペレーティング システムと C プログラミング言語が同時に登場しました。これはソフトウェアの世界に大きな影響を与え、今でもその主導的地位を維持しています。
四代目
要素ベースのもう一つの変化は世代交代につながりました。 70 年代には、大規模および超大型集積回路 (LSI および VLSI) の開発が盛んに進められ、単一チップ上に数万個の素子を配置することが可能になりました。 これにより、コンピュータのサイズとコストがさらに大幅に削減されました。 ソフトウェアの操作がより使いやすくなり、ユーザー数の増加につながりました。
原理的には、この程度の要素の集積により、機能的に完全なコンピューターを単一のチップ上に作成することが可能になりました。 適切な試みがなされたが、たいていは信じられないような笑顔で迎えられた。 おそらく、このアイデアがわずか 15 年後にメインフレーム コンピューターを絶滅させる原因になると予測できたなら、こうした笑顔は少なくなったでしょう。
しかし、70 年代初頭に、Intel はマイクロプロセッサ (MP) 4004 をリリースしました。そして、それまでコンピューティングの世界には 3 つの方向 (スーパーコンピュータ、メインフレーム、ミニコンピュータ) しかなかったとしたら、今ではそこにもう 1 つの方向、つまりマイクロプロセッサが追加されました。 一般に、プロセッサは、マイクロプログラム制御の原理に基づいて情報の論理的および算術処理のために設計されたコンピュータの機能単位として理解されます。 ハードウェア実装に基づいて、プロセッサはマイクロプロセッサ (すべてのプロセッサ機能が完全に統合されている) と、低および中程度の統合を備えたプロセッサに分類できます。 これは構造的に、マイクロプロセッサがすべてのプロセッサ機能を 1 つのチップ上で実現するのに対し、他の種類のプロセッサは多数のチップを接続することでプロセッサ機能を実現するという事実で表されます。
したがって、最初のマイクロプロセッサ 4004 は、70 年代の変わり目にインテルによって作成されました。 これは 4 ビットの並列コンピューティング デバイスであり、その機能は大幅に制限されていました。 4004 は基本的な四則演算を実行でき、当初はポケット電卓でのみ使用されていました。 その後、その適用範囲はさまざまな制御システム(信号機の制御など)に拡大されました。 インテルは、マイクロプロセッサーの可能性を正しく予見し、集中的な開発を続け、最終的にそのプロジェクトの 1 つが大きな成功につながり、それがコンピューター技術の将来の発展の道筋を決定づけました。
これは 8 ビット プロセッサ 8080 (1974 年) を開発するプロジェクトでした。 このマイクロプロセッサはかなり発達したコマンド システムを備えており、数値を除算することができました。 これは、若きビル ゲイツが最初の BASIC 言語インタプリタの 1 つを作成した Altair パーソナル コンピュータの作成に使用されました。 おそらく、この瞬間から第5世代が数えられるはずです。
五代目
第 5 世代コンピューターへの移行は、人工知能の作成を目的とした新しいアーキテクチャへの移行を意味します。
第 5 世代のコンピューター アーキテクチャには 2 つの主要なブロックが含まれると考えられていました。 そのうちの 1 つはコンピュータ自体であり、ユーザーとの通信は「インテリジェント インターフェイス」と呼ばれるユニットによって実行されます。 インターフェースの役割は、自然言語または音声で書かれたテキストを理解し、そのように述べられた問題の記述を動作するプログラムに変換することです。
第 5 世代コンピュータの基本要件: 開発されたマンマシン インターフェイス (音声認識、画像認識) の作成。 知識ベースと人工知能システムを作成するためのロジックプログラミングの開発。 コンピュータ機器の製造における新技術の創造。 新しいコンピュータ アーキテクチャとコンピューティング システムの作成。
コンピュータ技術の新たな技術的能力により、解決すべき課題の範囲が広がり、人工知能を生み出す課題への移行が可能になったはずです。 人工知能の構築に必要なコンポーネントの 1 つは、科学技術のさまざまな分野の知識ベース (データベース) です。 データベースの作成と使用には、高速コンピューティング システムと大量のメモリが必要です。 汎用コンピュータは高速計算を実行できますが、通常は磁気ディスクに保存されている大量のレコードの高速比較および並べ替え操作を実行するのには適していません。 データベースを埋め、更新し、操作するプログラムを作成するために、従来の手続き型言語と比較して最大の機能を提供する特別なオブジェクト指向および論理プログラミング言語が作成されました。 これらの言語の構造には、従来のノイマン型コンピューター アーキテクチャから、人工知能を作成するタスクの要件を考慮したアーキテクチャへの移行が必要です。
スーパーコンピュータには、発売時点で最高の性能を備えたコンピュータ、いわゆる第 5 世代コンピュータが含まれます。
最初のスーパーコンピューターはすでに第 2 世代コンピューター (1955 ~ 1964 年、第 2 世代コンピューターを参照) の中に登場しており、高速計算を必要とする複雑な問題を解決するように設計されていました。 これらは、UNIVAC の LARC、IBM のストレッチ、および Control Data Corporation の CDC-6600 (CYBER ファミリ) であり、並列処理方式 (単位時間あたりに実行される操作の数を増やす)、コマンド パイプライン (1 つのコマンドの実行中に使用される) を使用していました。 2 つ目はメモリから読み取られて実行の準備が行われ、データ プロセッサのマトリックスとタスクを分散してシステム内のデータ フローを制御する特別な制御プロセッサで構成される複雑なプロセッサ構造を使用した並列処理です。 複数のマイクロプロセッサを使用して複数のプログラムを並行して実行するコンピュータは、マルチプロセッサ システムと呼ばれます。 80 年代半ばまでは、世界最大のスーパーコンピューター メーカーのリストには Sperry Univac と Burroughs が含まれていました。 1 つ目は、特にメインフレーム UNIVAC-1108 および UNIVAC-1110 で知られており、大学や政府機関で広く使用されていました。
Sperry Univac と Burroughs の合併後、統合された UNISYS は、それぞれの上位互換性を維持しながら、両方のメインフレーム ラインをサポートし続けました。 これは、以前に開発されたソフトウェアの機能を維持するという、メインフレームの開発をサポートする不変のルールを明確に示しています。
Intelはスーパーコンピュータの世界でも有名です。 分散メモリ マルチプロセッサ構造のファミリーに属する Intel の Paragon マルチプロセッサ コンピュータも同様に古典的なものになりました。
フォン・ノイマン原理
1946 年、D. フォン ノイマン、G. ゴールドスタイン、A. バークスは共同論文で、コンピューターの構築と操作に関する新しい原理を概説しました。 その後、最初の 2 世代のコンピューターがこれらの原理に基づいて製造されました。 ノイマンの原則は今日でも有効ですが、後の世代ではいくつかの変更がありました。 実際、ノイマンは他の多くの科学者の科学的発展と発見を要約し、それらに基づいて根本的に新しい原理を定式化することに成功しました。
1. 数値の表現と保存の原理。
2 進数システムは、数値の表現と保存に使用されます。 10 進数システムに対する利点は、ビットの実装が簡単で、大容量のビット メモリが非常に安価で、デバイスが非常に単純に作成でき、2 進数システムでの算術および論理演算も非常に簡単であることです。
2. コンピュータプログラム制御の原理。
コンピュータの動作は、一連のコマンドからなるプログラムによって制御されます。 コマンドは次々と順番に実行されます。 コマンドは、コンピュータのメモリに保存されているデータを処理します。
3. ストアドプログラムの原理。
コンピュータのメモリは、データの保存だけでなくプログラムの保存にも使用されます。 この場合、プログラム コマンドとデータは両方とも 2 進数システムでエンコードされます。 録音方法は同じです。 したがって、特定の状況では、コマンドに対してデータに対してと同じアクションを実行できます。
4. ダイレクトメモリアクセスの原理。
コンピュータの RAM セルには、連続した番号が付けられたアドレスがあります。 いつでも、アドレスによって任意のメモリ セルにアクセスできます。
5. 分岐と循環計算の原理。
条件付きジャンプ コマンドを使用すると、コードの任意のセクションへの遷移を実装できるため、分岐を整理してプログラムの特定のセクションを再実行することができます。
これらの原則の最も重要な結果は、プログラムがもはやマシンの永続的な部分 (たとえば、計算機など) ではなくなったことです。 簡単にプログラムを変更できるようになりました。 しかし、もちろん設備は変わっておらず、非常にシンプルです。 比較すると、ENIAC コンピュータ (プログラムが保存されていない) のプログラムは、パネル上の特別なジャンパによって決定されていました。 マシンを再プログラムする (ジャンパを別の設定にする) には 1 日以上かかる場合があります。
また、最新のコンピューターのプログラムの開発には数か月かかる場合もありますが、インストール (コンピューターへのインストール) には、大規模なプログラムであっても数分かかります。 このようなプログラムは何百万ものコンピュータにインストールされ、それぞれのコンピュータ上で何年にもわたって実行される可能性があります。
アプリケーション
付録 1

付録 2

コンピューター「ウラル」
付録 3

コンピュータ「ストレラ」
付録 4

IBM-305とRAMAC
付録 5

ミニコンピュータ PDP-8
付録 6

文学:
1) ブロイド V.L. コンピューティング システム、ネットワーク、電気通信。 大学向けの教科書。 第2版 – サンクトペテルブルク: ピーター、2004 年
2) ジマキン A.P. コンピュータアーキテクチャ。 – サンクトペテルブルク: BHV - サンクトペテルブルク、2006
3) セメネンコ V.A. 電子コンピュータ。 専門学校用教科書 - M.: 高等学校、1991 年
大部分のコンピューターの構築は、1945 年にアメリカの科学者ジョン フォン ノイマンによって定式化された次の一般原則に基づいています (図 8.5)。 これらの原則は、EDVAC マシンに対する彼の提案で初めて発表されました。 このコンピュータは、最初のストアド プログラム マシンの 1 つでした。 パンチカードや他の同様のデバイスから読み取られるのではなく、マシンのメモリに保存されたプログラムを使用します。
図 9.5 - ジョン フォン ノイマン、1945 年
1. プログラム制御原理 。 このことから、プログラムはプロセッサによって特定の順序で次々に自動的に実行される一連のコマンドで構成されていることがわかります。
プログラムは、プログラム カウンタを使用してメモリから取得されます。 このプロセッサ レジスタは、そこに格納されている次の命令のアドレスを命令長分ずつ増加させます。
また、プログラムコマンドはメモリ内に次々と配置されるため、連続的に配置されたメモリセルからコマンドチェーンが編成されます。
コマンドを実行した後、次のコマンドではなく他のメモリ セルに移動する必要がある場合は、条件付きまたは無条件のジャンプ コマンドが使用され、次のコマンドを含むメモリ セルの番号がコマンド カウンタに入力されます。 メモリからのコマンドのフェッチは、「stop」コマンドに到達して実行すると停止します。
したがって、プロセッサは人間の介入なしに自動的にプログラムを実行します。
ジョン・フォン・ノイマンによれば、コンピュータは中央演算論理装置、中央制御装置、記憶装置、情報入出力装置から構成されるべきである。 彼の意見では、コンピュータは 2 進数を処理し、(電気的ではなく) 電子的なものであるべきです。 操作を順番に実行します。
問題を解決するためにアルゴリズムによって規定されるすべての計算は、一連の制御ワード - コマンドからなるプログラムの形式で提示されなければなりません。 各コマンドには、実行される特定の操作の命令、オペランドの場所 (アドレス)、およびいくつかのサービス特性が含まれています。 オペランドは、その値がデータ変換操作に関係する変数です。 すべての変数 (入力データ、中間値、計算結果) のリスト (配列) は、プログラムのもう 1 つの不可欠な要素です。
プログラム、命令、オペランドにアクセスするには、それらのアドレスが使用されます。 アドレスは、オブジェクトを保存するためのコンピューターのメモリ セルの数です。 情報 (コマンドとデータ: 数値、テキスト、グラフィックなど) は、2 進数の 0 と 1 でエンコードされます。
したがって、コンピュータのメモリ内にあるさまざまな種類の情報は実際には区別できず、コンテキスト内でそのロジックに従ってプログラムが実行される場合にのみ、それらの情報を識別することが可能です。
2. 記憶均一性の原理 。 プログラムとデータは同じメモリに保存されます。 したがって、コンピュータは、特定のメモリ セルに格納されているもの、つまり数字、テキスト、コマンドを区別しません。 コマンドに対してもデータに対してと同じアクションを実行できます。 これにより、あらゆる可能性が広がります。 たとえば、プログラムは実行中に処理することもできるため、プログラム自体の一部の部分を取得するためのルールを設定できます (これにより、プログラム内でサイクルとサブルーチンの実行が編成されます)。 さらに、あるプログラムのコマンドを別のプログラムの実行結果として取得することもできます。 翻訳方法は、プログラム テキストを高級プログラミング言語から特定のマシンの言語に翻訳するというこの原則に基づいています。
3. ターゲティングの原則 。 構造的には、メイン メモリは番号が付け直されたセルで構成されます。 プロセッサーはいつでもどのセルも利用できます。 これは、メモリ領域に名前を付ける機能を意味し、割り当てられた名前を使用して、メモリ領域に格納されている値に後でアクセスしたり、プログラムの実行中に変更したりできるようになります。
フォン・ノイマンの原則は、さまざまな方法で実際に実装できます。 ここでは、そのうちの 2 つ、バスを備えたコンピューターとチャネル構成を紹介します。 コンピュータの動作原理を説明する前に、いくつかの定義を紹介します。
コンピュータアーキテクチャ これは、ユーザー プログラミング機能、コマンド システム、アドレス指定システム、メモリ構成などの説明を含む、何らかの一般的なレベルでの説明と呼ばれます。 アーキテクチャは、プロセッサ、RAM、外部ストレージ、周辺機器など、コンピュータの主要な論理ノードの動作原理、情報接続および相互接続を決定します。 さまざまなコンピュータの共通アーキテクチャにより、ユーザーの観点から互換性が保証されます。
コンピュータの構造 は、その機能要素とそれらの間の接続のセットです。 要素には、コンピューターの主要な論理ノードから最も単純な回路に至るまで、さまざまなデバイスを含めることができます。 コンピュータの構造はブロック図の形式でグラフィカルに表現され、これを利用してコンピュータを任意の詳細レベルで説明できます。
この用語は非常に頻繁に使用されます コンピュータの設定 これは、機能要素の性質、量、関係、および主な特性を明確に定義したコンピューティング デバイスのレイアウトとして理解されます。 用語 " コンピュータ組織» コンピュータの機能がどのように実装されるかを決定します。
チーム – プログラムの実行時にプロセッサが特定のアクションを実行するために必要な情報の集合。
チームは以下で構成されています オペコード, 実行される操作の指示といくつかの情報が含まれます。 住所フィールド, 命令オペランドの位置の指示が含まれます。
コマンドのアドレスフィールドに含まれる情報からアドレスを計算する方法を といいます。 アドレッシングモード. 特定のコンピュータに実装された一連のコマンドが、そのコンピュータのコマンド システムを形成します。
チューリングマシン
チューリングマシン(MT)- 抽象的な実行者 (抽象的なコンピューティング マシン)。 アルゴリズムの概念を形式化するために 1936 年にアラン チューリングによって提案されました。
チューリング マシンは有限状態マシンの拡張であり、チャーチ-チューリングの理論によれば、 すべての出演者の真似ができる(遷移ルールを指定することによって) 段階的な計算プロセスを何らかの方法で実装します。各計算ステップは非常に基本的です。
チューリングマシンの構造[
チューリング マシンには両方向に無制限の機能が含まれています リボン(複数の無限テープを持つチューリング マシンも可能です)、セルに分割され、 制御装置(とも呼ばれている 読み書きヘッド(GZCH))、次のいずれかに入ることができます 状態のセット。 制御デバイスの可能な状態の数は有限であり、正確に指定されます。
制御装置はテープに沿って左右に移動し、有限のアルファベットの文字をセルに読み書きすることができます。 特別に目立つ 空の入力データが書き込まれるセル (最後の番号) を除く、テープのすべてのセルを埋める記号。
制御装置は次のように動作します。 移行ルールアルゴリズムを表す、 実現可能なこのチューリングマシン。 各遷移ルールは、現在の状態と現在のセルで観察されるシンボルに応じて、このセルに新しいシンボルを書き込み、新しい状態に移動し、1 つのセルを左または右に移動するようにマシンに指示します。 一部のチューリング マシン状態は次のようにラベル付けできます。 ターミナル、そしてそれらのいずれかに行くことは作業の終了を意味し、アルゴリズムを停止します。
チューリングマシンといいます 決定的な、テーブル内の状態とリボン シンボルの各組み合わせが最大 1 つのルールに対応する場合。 命令が 2 つ以上ある「リボン シンボル - 状態」のペアがある場合、そのようなチューリング マシンと呼ばれます。 非決定的.
チューリングマシンの説明[
特定のチューリング マシンは、アルファベットのセット A、状態のセット Q、およびマシンが動作するルールのセットの要素をリストすることによって定義されます。 それらの形式は次のとおりです: q i a j →q i1 a j1 d k (ヘッドが状態 q i にあり、文字 a j が観察されたセルに書き込まれている場合、ヘッドは状態 q i1 になり、セルに j1 が書き込まれますj の代わりに、頭は動き d k を行います。これには 3 つのオプションがあります。1 つのセルを左に移動 (L)、1 つのセルを右に移動 (R)、その場に留まる (N))。 あらゆる可能な構成に対して ルールは 1 つだけです (非決定性チューリング マシンの場合は、さらに多くのルールが存在する可能性があります)。 一度停止した最終状態のみにルールはありません。 さらに、最終状態と初期状態、テープ上の初期構成、およびマシン ヘッドの位置を指定する必要があります。
チューリングマシンの例[
単項数体系で数値を乗算するための MT の例を示します。 ルール「q i a j →q i1 a j1 R/L/N」のエントリは次のように理解されます。q i はこのルールが実行される状態、a j は先頭が位置するセル内のデータ、q はこのルールが実行される状態です。 i1 は移行する状態、j1 - セルに何を書き込む必要があるか、R/L/N - 移動するコマンドです。
ジョン・フォン・ノイマンによるコンピュータアーキテクチャ
フォン・ノイマン建築- コンピュータのメモリにコマンドとデータを共同保存するよく知られた原理。 この種のコンピューティング システムは、「フォン ノイマン マシン」と呼ばれることがよくありますが、これらの概念の対応関係は必ずしも明確ではありません。 一般に、ノイマン型アーキテクチャについて話すとき、それはデータと命令を 1 つのメモリに保存する原理を意味します。
フォン・ノイマン原理
フォン・ノイマンの原理[
記憶均一性の原理
コマンドとデータは同じメモリに保存され、外部からはメモリ内で区別できません。 それらは使用方法によってのみ認識できます。 つまり、メモリセル内の同じ値は、アクセス方法にのみ応じて、データ、コマンド、およびアドレスとして使用できます。 これにより、数値に対するのと同じ操作をコマンドに対しても実行できるようになり、さまざまな可能性が広がります。 したがって、コマンドのアドレス部分を周期的に変更することにより、データ配列の連続する要素にアクセスすることができます。 この手法はコマンド変更と呼ばれますが、最新のプログラミングの観点からはお勧めできません。 さらに有用なのは、あるプログラムからの命令が別のプログラムの実行の結果として得られる場合、同質性原理の別の結果です。 この可能性は翻訳、つまりプログラムテキストを高級言語から特定のコンピュータの言語に翻訳することの根底にあります。
ターゲティングの原則
構造的には、メイン メモリは番号が付けられたセルで構成されており、プロセッサはいつでも任意のセルを使用できます。 コマンドやデータのバイナリコードはワードと呼ばれる情報の単位に分割されてメモリセルに格納されており、アクセスするには対応するセルの番号、つまりアドレスが使用されます。
プログラム制御原理
問題を解決するためにアルゴリズムによって提供されるすべての計算は、一連の制御ワード、つまりコマンドで構成されるプログラムの形式で提示する必要があります。 各コマンドは、コンピューターによって実装される一連の操作の中から何らかの操作を規定します。 プログラム コマンドはコンピュータの連続したメモリ セルに格納され、自然な順序、つまりプログラム内の位置の順序で実行されます。 必要に応じて、特別なコマンドを使用して、このシーケンスを変更できます。 プログラム コマンドの実行順序を変更する決定は、以前の計算結果の分析に基づいて、または無条件に行われます。
プロセッサの種類
マイクロプロセッサ- これは、コンピュータ プロセッサの機能を実行する 1 つ以上の大規模集積回路 (LSI) であるデバイスです。古典的なコンピューティング デバイスは、演算装置 (AU)、制御装置 (CU)、記憶装置 (SU) で構成されます。 ) および入出力デバイス (I/O) )。
プラスチック PPGA ケースに入った IntelCeleron 400 ソケット 370、上面図。
さまざまなアーキテクチャのプロセッサがあります。
CISC(eng. ComplexstructsSetComputing) は、次の一連のプロパティによって特徴付けられるプロセッサ設計概念です。
· 異なる形式と長さの多数のコマンド。
· 多数の異なるアドレス指定モードの導入。
· 複雑な命令コーディングがある。
CISC プロセッサは、長さが等しくない、より複雑な命令を処理する必要があります。 単一の CISC 命令はより高速に実行できますが、複数の CISC 命令を並行して処理するのはより困難です。
アセンブラでプログラムのデバッグを容易にするには、マイクロプロセッサ ユニットをノードで混乱させる必要があります。 パフォーマンスを向上させるには、クロック周波数と集積度を高める必要があり、これには技術の向上が必要となり、その結果、製造コストが高くなります。
CISC アーキテクチャの利点[見せる]
CISC アーキテクチャの欠点[見せる]
RISC(縮小命令セットコンピューティング)。 命令セットが削減されたプロセッサ。 コマンド体系が簡素化されています。 すべてのコマンドは、単純なエンコーディングを備えた同じ形式です。 メモリへのアクセスにはロード コマンドとライト コマンドを使用します。残りのコマンドはレジスタ - レジスタ タイプです。 CPU に入力されるコマンドはすでにフィールドに分割されているため、追加の復号化は必要ありません。
結晶の一部は、追加のコンポーネントを収容するために解放されます。 統合度は以前のアーキテクチャ バリアントよりも低いため、高いパフォーマンスを得るにはクロック速度が低くても許容されます。 このコマンドにより RAM が乱雑になることは少なくなり、CPU は安価になります。 これらのアーキテクチャにはソフトウェア互換性がありません。 RISC プログラムのデバッグはさらに困難です。 このテクノロジーは、CISC テクノロジー (スーパースカラー テクノロジーなど) と互換性のあるソフトウェアで実装できます。
RISC 命令は単純であるため、実行に必要な論理ゲートの数が少なくなり、最終的にプロセッサのコストが削減されます。 しかし、今日のほとんどのソフトウェアは、インテル CISC プロセッサー専用に作成され、コンパイルされています。 RISC アーキテクチャを使用するには、現在のプログラムを再コンパイルし、場合によっては書き直す必要があります。
クロック周波数
クロック周波数は、中央プロセッサによってコマンドが実行される速度の指標です。
タクトとは、基本的な操作を実行するのに必要な時間です。
最近では、中央プロセッサのクロック速度はそのパフォーマンスと直接的に関連付けられていました。つまり、CPU のクロック速度が高いほど、生産性が高くなります。 実際には、異なる周波数のプロセッサが同じパフォーマンスを発揮する状況があります。これは、プロセッサが 1 クロック サイクルで異なる数の命令を実行できるためです (コアの設計、バス帯域幅、キャッシュ メモリに応じて異なります)。
プロセッサのクロック速度はシステム バス周波数に比例します ( 以下を参照してください).
ビット深度
プロセッサ容量は、中央プロセッサが 1 クロック サイクルで処理できる情報の量を決定する値です。
たとえば、プロセッサが 16 ビットの場合、これは 1 クロック サイクルで 16 ビットの情報を処理できることを意味します。
プロセッサーのビット深度が高くなるほど、より多くの情報を処理できることは誰もが理解していると思います。
通常、プロセッサーの容量が大きいほど、パフォーマンスも高くなります。
現在、32 ビットおよび 64 ビットのプロセッサが使用されています。 プロセッサのサイズは、同じビット サイズでコマンドを実行する必要があることを意味するものではありません。
キャッシュメモリ
まず、キャッシュ メモリとは何ですか?という質問に答えましょう。
キャッシュ メモリは、中央プロセッサが必要とする情報 (実行可能プログラムのコードとデータ) を一時的に保存するために設計された高速コンピュータ メモリです。
キャッシュメモリにはどのようなデータが保存されますか?
最も頻繁に使用されます。
キャッシュメモリの目的は何ですか?
実際のところ、RAMのパフォーマンスはCPUのパフォーマンスに比べてはるかに低いです。 プロセッサが RAM からデータが到着するのを待っていることが判明しました。これにより、プロセッサのパフォーマンスが低下し、したがってシステム全体のパフォーマンスが低下します。 キャッシュ メモリは、プロセッサによって最も頻繁にアクセスされた実行可能プログラムのデータとコードを保存することにより、プロセッサの待ち時間を短縮します (キャッシュ メモリとコンピュータ RAM の違いは、キャッシュ メモリの速度が数十倍高いことです)。
キャッシュ メモリには、通常のメモリと同様に容量があります。 キャッシュ メモリの容量が大きいほど、より多くのデータを処理できます。
キャッシュ メモリには 3 つのレベルがあります。 キャッシュ メモリ 初め (L1)、 2番 (L2) と 三番目 (L3)。 最初の 2 つのレベルは、最新のコンピューターで最もよく使用されます。
キャッシュ メモリの 3 つのレベルすべてを詳しく見てみましょう。
ファーストキャッシュレベルは最も高速で最も高価なメモリです。
L1 キャッシュはプロセッサと同じチップ上に配置され、CPU 周波数で動作し (したがって最高のパフォーマンス)、プロセッサ コアによって直接使用されます。
1 次キャッシュの容量は小さく (コストが高いため)、キロバイト単位で測定されます (通常は 128 KB 以下)。
L2キャッシュ L1 キャッシュと同じ機能を実行する高速メモリです。 L1 と L2 の違いは、後者は速度は低いですが、容量が大きい (128 KB から 12 MB) ため、リソースを大量に消費するタスクを実行するのに非常に役立ちます。
L3キャッシュマザーボード上にあります。 L3 は L1 および L2 よりも大幅に遅いですが、RAM よりは高速です。 L3 の体積が L1 および L2 の体積より大きいことが明らかです。 レベル 3 キャッシュは、非常に強力なコンピューターに搭載されています。
コア数
最新のプロセッサ製造技術により、1 つのパッケージに複数のコアを配置することが可能になります。 複数のコアが存在すると、プロセッサのパフォーマンスが大幅に向上しますが、これは、コアの存在が意味するわけではありません。 n コアによりパフォーマンスが向上します n 一度。 さらに、マルチコア プロセッサの問題は、現在、プロセッサ内に複数のコアが存在することを考慮して作成されたプログラムが比較的少ないことです。
マルチコア プロセッサでは、まず、アプリケーションの作業をプロセッサ コア間で分散するマルチタスク機能を実装できます。 これは、個々のコアがそれぞれ独自のアプリケーションを実行することを意味します。
マザーボードの構造
マザーボードを選択する前に、少なくともその構造を表面的に検討する必要があります。 ここで、ソケットやマザーボードの他の部分の位置は特別な役割を果たしていないことに注意する価値があります。
まず注目すべきはプロセッサソケットです。 これは留め具が付いた小さな四角い凹みです。
「オーバーロック」(コンピューターのオーバークロック)という用語に精通している人は、ダブル ラジエーターの存在に注目する必要があります。 多くの場合、マザーボードには二重ヒートシンクがありません。 したがって、将来コンピューターをオーバークロックする予定がある場合は、この要素がボード上に存在することを確認することをお勧めします。
細長い PCI-Express スロットは、ビデオ カード、TV チューナー、オーディオ、およびネットワーク カード用に設計されています。 ビデオ カードは高帯域幅を必要とし、PCI-Express X16 コネクタを使用します。 その他のアダプターには、PCI-Express X1 コネクタが使用されます。
専門家の助言!帯域幅が異なる PCI スロットは、ほぼ同じように見えます。 自宅でビデオカードを取り付けるときに突然がっかりすることを避けるために、コネクタを特に注意深く見て、その下のラベルを読む価値があります。
小さいコネクタは RAM スティック用です。 通常、色は黒または青です。
ボードのチップセットは通常、ヒートシンクの下に隠れています。 この要素は、プロセッサとシステムユニットの他の部分の共同動作を担当します。
ボードの端にある小さな四角いコネクタは、ハードドライブの接続に使用されます。 反対側には、入出力デバイス (USB、マウス、キーボードなど) 用のコネクタがあります。
メーカー
多くの企業がマザーボードを製造しています。 それらの中で最高か最低かを選び出すことはほとんど不可能です。 どの企業の支払いも高品質と言えます。 たとえ無名のメーカーでも良い製品を提供していることはよくあります。
その秘密は、すべてのボードに AMD と Intel の 2 社のチップセットが搭載されていることです。 さらに、チップセット間の違いはわずかであり、高度に専門化された問題を解決する場合にのみ役割を果たします。
フォームファクタ
マザーボードの場合、サイズが重要です。 標準の ATX フォーム ファクタは、ほとんどの家庭用コンピュータに搭載されています。 サイズが大きいため、さまざまなスロットが存在するため、コンピューターの基本的な特性を向上させることができます。
より小さい mATX バージョンはあまり一般的ではありません。 改善の可能性は限られています。
mITXもあります。 このフォーム ファクターは、低価格のオフィス コンピューターに採用されています。 パフォーマンスの向上は不可能であるか、意味がありません。
多くの場合、プロセッサとボードはセットとして販売されます。 ただし、プロセッサーが以前に購入されたものである場合は、プロセッサーがボードと互換性があることを確認することが重要です。 ソケットを見れば、プロセッサとマザーボードの互換性が即座に判断できます。
チップセット
システムのすべてのコンポーネントの接続リンクはチップセットです。 チップセットは Intel と AMD の 2 社によって製造されています。 それらの間に大きな違いはありません。 少なくとも平均的なユーザーにとっては。
標準チップセットはノース ブリッジとサウス ブリッジで構成されます。 Intelの最新モデルは北部のみで構成されています。 これはお金を節約する目的で行われたものではありません。 この要因によってチップセットのパフォーマンスが低下することはありません。
DD3 RAM コントローラー、PCI-Express 3.0 など、ほとんどのコントローラーがプロセッサー内に配置されているため、最新の Intel チップセットは単一のブリッジで構成されています。
AMD 類似製品は、従来の 2 ブリッジ設計に基づいて構築されています。 例えば、900シリーズにはサウスブリッジSB950とノースブリッジ990FX(990X、970)が搭載されています。
チップセットを選択するときは、ノース ブリッジの機能から始める必要があります。 Northbridge 990FX は、CrossFire モードで 4 枚のビデオ カードの同時操作をサポートできます。 ほとんどの場合、そのような力は過剰です。 ただし、重いゲームのファンや、要求の厳しいグラフィック エディタを使用して作業する人にとっては、このチップセットが最適です。
990X のわずかに機能を簡素化したバージョンでも、同時に 2 枚のビデオ カードをサポートできますが、970 モデルは 1 枚のビデオ カードでのみ動作します。
マザーボードのレイアウト
· データ処理サブシステム。
· 電源サブシステム。
· 補助 (サービス) ブロックおよびユニット。
マザーボード データ処理サブシステムの主要コンポーネントを図に示します。 1.3.14.
1 – プロセッサソケット。 2 – フロントタイヤ; 3 – ノースブリッジ。 4 – クロックジェネレーター。 5 – メモリバス。 6 – RAM コネクタ。 7 – IDE (ATA) コネクタ。 8 – SATA コネクタ。 9 – サウスブリッジ。 10 – IEEE 1394 コネクタ。 11 – USB コネクタ。 12 – イーサネットネットワークコネクタ。 13 – オーディオコネクタ。 14 – LPC バス。 15 – スーパー I/O コントローラー。 16 – PS/2 ポート。
17 – パラレルポート。 18 – シリアルポート。 19 – フロッピー ディスク コネクタ。
20 – BIOS; 21 – PCI バス。 22 – PCI コネクタ。 23 – AGP または PCI Express コネクタ。
24 – 内部バス。 25 – AGP/PCI Express バス。 26 – VGA コネクタ
FPM (Fast Page Mode) は動的メモリの一種です。
このモジュールにより、前のサイクルで転送されたデータと同じページ上のデータに高速にアクセスできるため、その名前は動作原理に対応しています。
これらのモジュールは、ほとんどの 486 ベースのコンピュータと、1995 年頃の初期の Pentium ベースのシステムで使用されていました。

EDO (Extended Data Out) モジュールは、Pentium プロセッサを搭載したコンピュータ用の新しいタイプのメモリとして 1995 年に登場しました。
これは FPM の修正バージョンです。
前任者とは異なり、EDO は前のブロックを CPU に送信すると同時に、メモリの次のブロックのフェッチを開始します。

SDRAM (シンクロナス DRAM) は、スタンバイ モードを除いてプロセッサ周波数と同期できるほど高速に動作するランダム アクセス メモリの一種です。
マイクロ回路は 2 つのセル ブロックに分割されているため、1 つのブロックのビットにアクセスしている間に、別のブロックのビットにアクセスする準備が進行します。
最初の情報にアクセスする時間が 60 ns だった場合、それ以降のすべての間隔は 10 ns に短縮されます。
1996 年から、ほとんどの Intel チップセットがこのタイプのメモリ モジュールをサポートし始め、2001 年まで非常に普及しました。
SDRAM は 133 MHz で動作でき、これは FPM のほぼ 3 倍、EDO の 2 倍の速度です。
1999 年にリリースされた Pentium および Celeron プロセッサを搭載したほとんどのコンピュータでは、このタイプのメモリが使用されていました。

DDR (Double Data Rate) は SDRAM を発展させたものです。
このタイプのメモリ モジュールは 2001 年に初めて市場に登場しました。
DDR と SDRAM の主な違いは、クロック速度を 2 倍にして高速化するのではなく、これらのモジュールはクロック サイクルごとに 2 回データを転送することです。
現在、これがメイン メモリ規格ですが、すでに DDR2 に取って代わられ始めています。

DDR2 (Double Data Rate 2) は DDR の新しいバリアントで、理論的には 2 倍の速度になります。
DDR2 メモリは 2003 年に初めて登場し、それをサポートするチップセットは 2004 年半ばに登場しました。
このメモリは、DDR と同様に、クロック サイクルごとに 2 セットのデータを転送します。
DDR2 と DDR の主な違いは、設計の改良により、大幅に高いクロック速度で動作できることです。
しかし、変更された動作スキームにより、高いクロック周波数を実現できるようになりますが、同時にメモリを操作する際の遅延も増加します。

DDR3 SDRAM (ダブル データ レート同期ダイナミック ランダム アクセス メモリ、第 3 世代) は、コンピューティングで RAM およびビデオ メモリとして使用されるランダム アクセス メモリの一種です。
DDR2 SDRAM メモリを置き換えました。
DDR3 は、DDR2 モジュールと比較してエネルギー消費が 40% 削減されています。これは、メモリ セルの電源電圧が低い (DDR2 の 1.8 V および DDR の 2.5 V と比較して 1.5 V) ためです。
電源電圧の低減は、超小型回路の製造における 90 nm (当初は 65、50、40 nm) プロセス技術の使用と、(リーク電流の低減に役立つ) デュアルゲート トランジスタの使用によって達成されます。 。
DDR3 メモリを搭載した DIMM は、同じ DDR2 メモリ モジュールと機械的に互換性がないため (キーは別の場所にあります)、DDR2 を DDR3 スロットに取り付けることはできません (これは、一部のモジュールを他のモジュールではなく誤って取り付けることを防ぐためです。メモリの種類は電気的パラメータによって異なります)。
ランバス(リム)
RAMBUS (RIMM) は、1999 年に市場に登場したメモリの一種です。
従来の DRAM をベースとしていますが、アーキテクチャが根本的に変更されています。
RAMBUS 設計によりメモリ アクセスがよりインテリジェントになり、CPU の負荷をわずかに軽減しながらデータへの事前アクセスが可能になります。
これらのメモリ モジュールで使用される主なアイデアは、小さなパケットで非常に高いクロック速度でデータを受信することです。
たとえば、SDRAM は 100 MHz で 64 ビットの情報を転送でき、RAMBUS は 800 MHz で 16 ビットの情報を転送できます。
Intel は実装に多くの問題を抱えていたため、これらのモジュールは成功しませんでした。
RDRAM モジュールは、Sony Playstation 2 および Nintendo 64 ゲーム機に登場しました。


RAM は Random Access Memory の略で、アドレスによってアクセスされるメモリです。 順次アクセスされるアドレスは任意の値を取ることができるため、任意のアドレス (または「セル」) に独立してアクセスできます。
統計メモリは、静的スイッチから構築されたメモリです。 電力が供給されている限り情報を保存します。 通常、SRAM 回路に 1 ビットを格納するには、少なくとも 6 つのトランジスタが必要です。 SRAM は小規模システム (最大数百 KB の RAM) で使用され、アクセス速度が重要な場所 (プロセッサー内のキャッシュやマザーボード上のキャッシュなど) で使用されます。
ダイナミック メモリ (DRAM) は 70 年代初頭に誕生しました。 それは容量性要素に基づいています。 DRAM は、スイッチング トランジスタによって制御される一連のコンデンサと考えることができます。 1 ビットを保存するのに必要な「コンデンサ トランジスタ」は 1 つだけなので、DRAM は SRAM よりも容量が大きくなります (そして安価です)。
DRAM は、セルの長方形のアレイとして構成されています。 セルにアクセスするには、そのセルが配置されている行と列を選択する必要があります。 通常、これは、アドレスの上位部分が行を指し、アドレスの下位部分が行 (「列」) のセルを指すように実装されます。 歴史的には (70 年代初頭の速度が遅く、IC パケットが小さかったため)、アドレスは 2 段階で DRAM チップに供給されていました - 行アドレスと列アドレスが同じ線上にあり、最初にチップは行アドレスを受信し、次にチップが行アドレスを受信します。数ナノ秒後、列アドレスが同じラインに送信されます。チップはデータを読み取り、出力に送信します。書き込みサイクル中、データは列アドレスとともにチップによって受信されます。いくつかの制御ラインが使用されます。チップを制御する RAS (Row Address Strobe) 信号。行アドレスを送信し、チップ全体をアクティブにします。 CAS (Column Address Strobe) 信号は、実行されたアクセスが書き込みアクセスであることを示す列アドレス WE (Write Enable) を送信します。 OE (出力イネーブル)は、メモリ チップから「ホスト」(プロセッサ)にデータを転送するために使用されるバッファを開きます。
FPDRAM
クラシック DRAM への各アクセスには 2 つのアドレスの転送が必要なため、25 MHz マシンには遅すぎました。 FP (Fast Page) DRAM は、各アクセス サイクルで行アドレスを転送する必要がない従来の DRAM の一種です。 RAS ラインがアクティブである限り、行は選択されたままとなり、列アドレスのみを渡すことによってその行の個々のセルを選択できます。 したがって、メモリセルは同じままですが、ほとんどの場合、アドレス転送フェーズが 1 つだけ必要になるため、アクセス時間が短縮されます。
EDO (Extended Data Out) DRAM は FP DRAM の一種です。 FP DRAM では、データ転送期間全体を通じて列アドレスが正しい状態を維持する必要があります。 データバッファは、CAS 信号アクティビティレベル信号により、カラムアドレス送信サイクル中のみ活性化されます。 新しい列アドレスがチップ上で受信される前に、メモリ データ バスからデータを読み取る必要があります。 EDO メモリは、CAS 信号が非アクティブ状態に戻り、列アドレスが削除された後、出力バッファにデータを格納します。 データの読み取りと並行して、次の列のアドレスを送信できます。 これにより、読み取り時に部分一致を使用できるようになります。 EDO RAM メモリ セルの速度は FP DRAM と同じですが、シーケンシャル アクセスの方が高速です。 したがって、特に大規模なアクセス (グラフィックス アプリケーションなど) の場合、EDO は FP よりも高速である必要があります。
ビデオ RAM は、上記の DRAM アーキテクチャのいずれかをベースにすることができます。 以下で説明する「通常の」アクセス メカニズムに加えて、VRAM には 1 つまたは 2 つの特別なシリアル ポートがあります。 VRAM は、デュアル ポート メモリまたはトリプル ポート メモリと呼ばれることがよくあります。 シリアル ポートには、一連の内容全体を保存できるレジスタが含まれています。 1 回のアクセス サイクルでメモリ アレイの行全体からレジスタへ (またはその逆に) データを転送することが可能です。 データは任意の長さのチャンクでシリアル レジスタから読み書きすることができます。 レジスタは高速な静的セルで構成されているため、レジスタへのアクセスは非常に高速で、通常はメモリ アレイよりも数倍高速です。 ほとんどの一般的なアプリケーションでは、VRAM が画面メモリ バッファとして使用されます。 パラレル ポート (標準インターフェイス) はプロセッサによって使用され、シリアル ポートはディスプレイ上のポイントに関するデータの送信 (またはビデオ ソースからのデータの読み取り) に使用されます。
WRAM は、Matrox によって開発された独自のメモリ アーキテクチャです (他に誰がいるか思い出させてください... - Samsung?、MoSys?...)。 VRAM に似ていますが、ホストによるより高速なアクセスが可能になります。 WRAM は、Matrox の Millenium および Millenium II グラフィックス カードで使用されていました (ただし、最新の Millenium G200 では使用されていません)。
SDRAM は DRAM を完全に再設計したもので、90 年代に導入されました。「S」は同期を表します。これは、SDRAM が完全に同期した (したがって非常に高速な) インターフェイスを実装しているためです。SDRAM 内には (通常 2 つの) DRAM アレイが含まれています。各アレイには独自の独自のページ レジスタは、VRAM 上のシリアル アクセス レジスタに (少し) 似ています。SDRAM は通常の DRAM よりもはるかに賢く動作します。回路全体が外部クロック信号と同期します。各クロック ティックで、チップは送信されたコマンドを受信して実行します。コマンド ラインに沿って. コマンド ライン名は古典的な DRAM チップと同じままですが、その機能はオリジナルと似ているだけです. メモリ アレイとページ レジスタの間でデータを転送するためのコマンドと、ページ レジスタ内のデータにアクセスするためのコマンドがあります。ページ レジスタへのアクセスは非常に高速です。最新の SDRAM は 6 ~ 10 ns ごとに新しいデータ ワードを転送できます。
同期グラフィックス RAM は、グラフィックス アプリケーション用に設計された SDRAM の一種です。 ハードウェア構造はほぼ同一であるため、ほとんどの場合、SDRAM と SGRAM を変更できます (Matrox G200 カードを参照 - SD を使用するものと SG を使用するものがあります)。 違いは、ページ レジスタによって実行される機能にあります。 SG は 1 サイクルで複数の位置を書き込むことができます (これにより、非常に高速な色の塗りつぶしと画面のクリアが可能になります) が、1 ワードあたり数ビットしか書き込むことができません (ビットは、インターフェイス回路によって格納されたビット マスクによって選択されます)。 したがって、「通常の」使用では物理的に SD よりも速くありませんが、グラフィックス アプリケーションでは SG の方が高速です。 SG の追加機能は、グラフィック アクセラレータによって使用されます。 特に画面クリア機能とZバッファ機能は非常に便利だと思います。
ランバス (RDRAM)
RAMBUS (RAMBUS, Inc. の商標) は 80 年代に開発され始めたもので、新しいものではありません。現代の RAMBUS テクノロジは、古くても非常に優れたアイデアと今日のメモリ製造テクノロジを組み合わせたものです。RAMBUS は、シンプルなアイデアに基づいています。 DRAM では、チップ内に静的バッファが組み込まれ (VRAM や SGRAM と同様)、250 ~ 400 MHz で動作する特別な電子的に構成可能なインターフェイスが提供されます。このインターフェイスは、SDRAM で使用されるインターフェイスの少なくとも 2 倍高速です。ランダム アクセス時間は通常遅く、シーケンシャル アクセスは非常に、非常に、非常に高速です。250 MHz RDRAM が導入されたとき、ほとんどの DRAM は 12..25 MHz の周波数で動作していたことを思い出してください。RDRAM には特別なインターフェイスと非常に慎重な物理的配置が必要です。ほとんどの RDRAM チップは、他の DRAM とは大きく異なって見えます: パッケージの片側にすべての信号線があり (つまり同じ長さです)、もう一方の側には 4 本の電源線だけがあります。 RDRAM は、Cirrus 546x チップをベースとしたグラフィックス カードで使用されます。 間もなく、RDRAM が PC のメイン メモリとして使用されるようになるでしょう。
ハードドライブデバイス。
ハードドライブには、磁性材料(ガンマフェライト酸化物、バリウムフェライト、クロム酸化物など)でコーティングされ、スピンドル(シャフト、軸)を使用して相互に接続された一連のプレートが含まれており、ほとんどの場合金属ディスクを表します。
ディスク自体 (厚さ約 2 mm) は、アルミニウム、真鍮、セラミック、またはガラスでできています。 (写真を参照)
ディスクの両面が記録に使用されます。 プレートは4~9枚使用します。 シャフトは高速一定速度 (3600 ~ 7200 rpm) で回転します。
ディスクの回転とヘッドの急激な動きは、2 つの電気モーターを使用して実行されます。
データは、ディスクの各面に 1 つずつある書き込み/読み取りヘッドを使用して書き込みまたは読み取りされます。 ヘッドの数は、すべてのディスクの作業面の数と同じです。
情報は、ディスク上の厳密に定義された場所、つまり同心円状のトラック(トラック)に記録されます。 トラックはセクターに分割されています。 1 セクターには 512 バイトの情報が含まれます。
RAMとNMD間のデータ交換は整数(クラスタ)単位でシーケンシャルに行われます。 クラスター - 連続するセクターのチェーン (1、2、3、4、…)
特別なモーターはブラケットを使用して、読み取り/書き込みヘッドを所定のトラック上に配置します (半径方向に移動します)。
ディスクが回転すると、ヘッドは目的のセクタの上に位置します。 明らかに、すべてのヘッドが同時に移動して情報を読み取り、データ ヘッドも同時に移動して、異なるドライブ上の同一トラックから情報を読み取ります。
異なるハード ドライブ ドライブ上で同じシリアル番号を持つハード ドライブ トラックは、シリンダと呼ばれます。
読み取り/書き込みヘッドはプラッタの表面に沿って移動します。 ヘッドがディスク表面に触れずに近づくほど、許容される記録密度は高くなります。 .
ハードドライブインターフェイス。
IDE (ATA – Advanced Technology Attachment) はドライブを接続するためのパラレル インターフェイスであるため、(SATA 出力付き) PATA (Parallel ATA) に変更されました。 以前はハードドライブの接続に使用されていましたが、SATA インターフェイスに置き換えられました。 現在、光学ドライブの接続に使用されています。
SATA (シリアル ATA) – ドライブとのデータ交換用のシリアル インターフェイス。 接続には8ピンコネクタを使用します。 PATA の場合と同様、これは廃止されており、光学式ドライブの操作にのみ使用されます。 SATA 規格 (SATA150) は、150 MB/秒 (1.2 Gbit/秒) のスループットを提供しました。
SATA2(SATA300)。 SATA 2 規格により、スループットが 2 倍になり、最大 300 MB/s (2.4 Gbit/s) になり、3 GHz での動作が可能になりました。 標準 SATA と SATA 2 は相互に互換性がありますが、一部のモデルではジャンパを再配置してモードを手動で設定する必要があります。
SATA 3 ですが、仕様によれば SATA 6Gb/s と呼ぶのが正しいです。 この規格により、データ転送速度が 2 倍の 6 Gbit/s (600 MB/s) になりました。 その他の積極的な革新には、NCQ プログラム制御機能と、優先度の高いプロセスの連続データ転送用コマンドが含まれます。 このインターフェイスは 2009 年に導入されましたが、まだメーカー間であまり普及しておらず、店頭ではあまり見かけません。 この規格は、ハード ドライブに加えて、SSD (ソリッド ステート ドライブ) でも使用されます。 実際には、SATA インターフェイスの帯域幅はデータ転送速度に違いがないことに注意してください。 実際には、ディスクの書き込みおよび読み取りの速度は 100 MB/秒を超えることはありません。 パフォーマンスの向上は、コントローラーとドライブ キャッシュ間の帯域幅にのみ影響します。
SCSI (Small Computer System Interface) - データ転送速度の向上が必要なサーバーで使用される規格。
SAS (Serial Attached SCSI) は、シリアル データ伝送を使用する、SCSI 標準に代わる世代です。 SCSI と同様に、ワークステーションで使用されます。 SATAインターフェースと完全互換。
CF (コンパクト フラッシュ) – メモリ カードおよび 1.0 インチ ハード ドライブを接続するためのインターフェイス。 コンパクトフラッシュ タイプIとコンパクトフラッシュ タイプIIの2つの規格があり、違いは厚さです。
FireWire は、低速な USB 2.0 の代替インターフェイスです。 ポータブルハードドライブを接続するために使用されます。 最大 400 Mb/s の速度をサポートしますが、物理的な速度は通常のものよりも低くなります。 読み取りおよび書き込み時の最大しきい値は 40 MB/秒です。
ビデオカードの種類
最新のコンピュータ (ラップトップ) にはさまざまな種類のビデオ カードが搭載されており、グラフィック プログラムやビデオ再生などのパフォーマンスに直接影響します。
現在使用されているアダプターは 3 種類あり、組み合わせて使用できます。
ビデオカードの種類を詳しく見てみましょう。
- 統合された;
- 離散;
- ハイブリッド;
- 2 つの離散的;
- ハイブリッドSLI。
内蔵グラフィックスカード- これは安価なオプションです。 ビデオメモリとグラフィックプロセッサは搭載していません。 チップセットの助けを借りて、グラフィックスは中央プロセッサによって処理され、ビデオ メモリの代わりに RAM が使用されます。 このようなデバイス システムは、コンピュータ全般のパフォーマンス、特にグラフィック処理のパフォーマンスを大幅に低下させます。
低価格の PC またはラップトップ構成でよく使用されます。 オフィス アプリケーションで作業したり、写真やビデオを視聴したり編集したりすることはできますが、最新のゲームをプレイすることはできません。 最小システム要件を備えたレガシー オプションのみが利用可能です。
多くの時間が経過しているにもかかわらず、現代のコンピューターはすべて、アメリカの数学者ジョン フォン ノイマン (1903 ~ 1957 年) によって提案された原理に基づいて動作します。 彼はまた、コンピュータの開発と応用にも多大な貢献をしました。 彼は、コンピュータが動作する原理を最初に確立した人です。
1. バイナリコーディングの原理: コンピュータ内のすべての情報は、0 と 1 の組み合わせであるバイナリ形式で表現されます。
2. メモリ均一性の原理: プログラムとデータの両方が同じメモリに格納されるため、コンピュータは特定のメモリ セルに何が格納されているかを認識しませんが、数字、テキスト、コマンドなどはそこに配置されます。スーパーデータと同様に、コマンドでも同じアクションを実行できます。
3. メモリのアドレス指定可能性の原理: 概略的には、OP (メイン メモリ) は番号付きのセルで構成され、CPU (中央処理装置) はどのメモリ セルにもいつでもアクセスできます。 したがって、OP と CPU 間のやり取りをより便利にするために、メモリ ブロックに名前を割り当てることができます。
4. 逐次プログラム制御の原理: プログラムは、CPU によって次々と逐次実行される一連の命令で構成されます。
5. 条件分岐の原理: コマンドは 1 つずつ実行されるとは限らず、格納されているデータの値に応じてコマンドの順序を変更する条件分岐コマンドが可能です。
。 現代のコンピューターの分類。
モダンな コンピューター内蔵に分かれています マイクロプロセッサ, マイコン(パソコン)、 メインフレームコンピュータそして スーパーコンピューター- 複数のプロセッサを備えたコンピュータ複合体。
マイクロプロセス- プロセッサは次の形式で実装されます。 積分 電子 マイクロ回路。 マイクロプロセッサは、電話、テレビ、その他の家電製品、機械、デバイスに組み込むことができます。
集積回路について最新のすべてのマイクロコンピュータのプロセッサと RAM、大型コンピュータとスーパーコンピュータのすべてのブロック、およびすべてのプログラマブル デバイスが実装されています。
マイクロプロセッサの性能数個に相当する 何百万もの オペレーション現在の RAM ブロックの量は数百万バイトです。
マイコン -これらは本格的です コンピューティング 車、データ処理用のプロセッサとRAMだけでなく、入出力デバイスと情報記憶デバイスも備えています。
パソコン -これ マイコン、電子スクリーン上の表示装置、キーボードの形のデータ入出力装置、および場合によってはコンピュータ ネットワークに接続するための装置を備えています。
マイコンのアーキテクチャシステム バックボーンは、プロセッサと RAM ユニット、およびすべての入出力デバイスが接続されるインターフェイス デバイスの使用に基づいています。
トランクの使い方変更できます 化合物そして 構造 マイコン- 入出力デバイスを追加し、コンピュータの機能を強化します。
長期保存庫現代のコンピュータの情報は、磁気ディスク、光ディスク、フラッシュ メモリ ブロックなどの電子、磁気、光学メディアを使用して実行されます。
現代のコンピューターのアーキテクチャファイル、ソフトウェア パッケージ、データベース、および制御オペレーティング システムが配置される長期メモリの存在が必要です。
メインフレーム コンピュータ -コンピュータ 高い 生産性大量の外部メモリを搭載。 メインフレーム コンピュータは、コンピュータ ネットワークおよび大規模なデータ ストレージ施設のサーバーとして使用されます。
メインフレームコンピュータ組織の基礎として使用される 企業 情報 システム産業企業や政府機関へのサービス提供。
スーパーコンピュータ- これ マルチプロセッサ コンピューター複雑なアーキテクチャを備え、最高のパフォーマンスを備え、超複雑なコンピューティング問題の解決に使用されます。
スーパーコンピュータの性能に相当する 十そして 何百もの 千 何十億ものコンピューティング オペレーション毎秒。 同時に、スーパーコンピューターのプロセッサーの数はますます増加しており、コンピューターのアーキテクチャはより複雑になっています。