アセンブリ言語の構造。 アセンブリ言語プログラムの構造データ形式とアセンブリ言語の命令構造
トピック1.4アセンブラのニーモニック。 コマンドの構造と形式。 アドレス指定のタイプ。 マイクロプロセッサ命令セット
プラン:
1アセンブリ言語。 基本概念
2 アセンブリ言語記号
3種類のアセンブラステートメント
4アセンブリディレクティブ
5プロセッサ命令セット
1私アセンブリ言語。 基本概念
アセンブリ言語機械語の象徴的な表現です。 最下位のハードウェアレベルのマシン内のすべてのプロセスは、機械語のコマンド(命令)によってのみ駆動されます。 このことから、一般名にもかかわらず、コンピュータの種類ごとにアセンブリ言語が異なることは明らかです。
アセンブリ言語プログラムは、と呼ばれるメモリのブロックのコレクションです。 メモリセグメント。プログラムは、これらのブロックセグメントの1つまたは複数で構成されている場合があります。 各セグメントには言語文のコレクションが含まれており、各セグメントはプログラムコードの個別の行を占めています。
アセンブリステートメントには、次の4つのタイプがあります。
1) コマンドまたは指示 これは、マシンコマンドの象徴的な類似物です。 変換プロセス中に、アセンブリ命令はマイクロプロセッサ命令セットの対応するコマンドに変換されます。
2) マクロ-特定の方法で形式化された番組のテキストの文は、放送中に他の文に置き換えられます。
3) 指令、これは、いくつかのアクションを実行するためのアセンブラートランスレーターへの指示です。 ディレクティブには、マシン表現に対応するものはありません。
4) コメント行 、ロシア語のアルファベットの文字を含む任意の文字を含みます。 コメントは翻訳者によって無視されます。
アセンブリプログラムの構造。 アセンブラ構文。
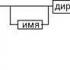
プログラムを構成する文は、コマンド、マクロ、ディレクティブ、またはコメントに対応する構文構造にすることができます。 アセンブラトランスレータがそれらを認識するためには、特定の構文規則に従ってそれらを形成する必要があります。 これを行うには、文法の規則のように、言語の構文の正式な説明を使用するのが最善です。 このようなプログラミング言語を説明する最も一般的な方法 -構文図と バッカス・ナウアの拡張形式。実用に便利 シンタックスダイアグラム。たとえば、アセンブリ言語ステートメントの構文は、次の図10、11、12に示す構文図を使用して記述できます。
図10-アセンブリ文の形式

図11-ディレクティブの形式
図12-コマンドとマクロの形式
これらの図面について:
ラベル名-識別子。その値は、プログラムのソースコードの文の最初のバイトのアドレスであり、それが示します。
名前 -このディレクティブを同じ名前の他のディレクティブと区別する識別子。 アセンブラによる特定のディレクティブの処理の結果として、特定の特性をこの名前に割り当てることができます。
オペコード(COP)とディレクティブ- これらは、対応するマシン命令、マクロ命令、またはコンパイラ指令のニーモニックシンボルです。
オペランド-コマンド、マクロ、またはアセンブラーディレクティブの一部であり、アクションが実行されるオブジェクトを示します。 アセンブラオペランドは、数値定数とテキスト定数、変数ラベル、および演算子記号といくつかの予約語を使用した識別子を使用した式で記述されます。
シンタックスダイアグラムは ダイアグラムの入力(左)から出力(右)へのパスを見つけてトラバースします。 そのようなパスが存在する場合、文または構文は構文的に正しいです。 そのようなパスがない場合、コンパイラはこの構造を受け入れません。
2アセンブリ言語記号
プログラムのテキストを書き込むときに許可される文字は次のとおりです。
1) すべてのラテン文字: A-Z,a-z。 この場合、大文字と小文字は同等と見なされます。
2)からの数字 0 前 9 ;
3)標識 ? , @ , $ , _ , & ;
4)セパレーター , . () < > { } + / * % ! " " ? = # ^ .
アセンブラ文はから形成されます トークン、これは、翻訳者にとって意味のある、構文的に分離できない有効な言語文字のシーケンスです。
トークンそれは:
1)識別子 - オペコード、変数名、ラベル名などのプログラムオブジェクトを指定するために使用される有効な文字のシーケンス。 識別子を書き込むための規則は次のとおりです。識別子は1つ以上の文字で構成されている場合があります。
2) 文字列 - 一重引用符または二重引用符で囲まれた文字シーケンス。
3)次の数値システムのいずれかの整数 : 2進数、10進数、16進数。 アセンブラプログラムで番号を書き込むときの番号の識別は、特定の規則に従って実行されます。
4)10進数は、識別のために追加の記号(たとえば、25または139)を必要としません。プログラムのソースコードでの識別のため 2進数構成に含まれる0と1を書き込んだ後、ラテン語を「 b」、たとえば10010101 b.
5) 16進数には、表記法にさらに多くの規則があります。
まず、それらは数字で構成されています。 0...9 、ラテンアルファベットの小文字と大文字 a,b, c,d,e,fまた A,B,C,D,E,F.
第2に、16進数は、0〜9の数字(たとえば、190845)で構成され、ラテンアルファベットの文字(たとえば、 ef15)。 与えられた語彙素が10進数でも識別子でもないことを翻訳者に「説明」するために、プログラマーは16進数を特別に割り当てる必要があります。 これを行うには、16進数を構成する16進数のシーケンスの最後に、ラテン文字「 h"。 これは前提条件です。 16進数が文字で始まる場合、先頭にゼロが付きます。 0 ef15 h。
ほとんどすべての文には、何らかのアクションが実行されるオブジェクトの説明が含まれています。 これらのオブジェクトはと呼ばれます オペランド。 これらは次のように定義できます。 オペランド-これらは、命令またはディレクティブの影響を受けるオブジェクト(一部の値、レジスタ、またはメモリセル)であるか、命令またはディレクティブのアクションを定義または改良するオブジェクトです。
次のオペランドの分類を実行できます。
定数または即時オペランド。
アドレスオペランド;
オペランドを移動しました。
アドレスカウンター;
レジスタオペランド;
ベースオペランドとインデックスオペランド。
構造オペランド;
記録。
オペランドは、機械命令の一部を形成する基本コンポーネントであり、操作が実行されるオブジェクトを示します。 より一般的なケースでは、オペランドは、と呼ばれるより複雑なフォーメーションのコンポーネントとして含めることができます。 式.
式 全体として考えられるオペランドと演算子の組み合わせです。 式の評価の結果は、メモリセルのアドレスまたは定数(絶対)値になります。
3種類のアセンブラステートメント
可能なタイプをリストしましょう アセンブラステートメントアセンブラ式を形成するための構文規則:
算術演算子;
シフト演算子;
比較演算子;
論理演算子;
インデックス演算子;
タイプオーバーライド演算子。
セグメント再定義演算子。
構造タイプの命名演算子。
式のアドレスのセグメントコンポーネントを取得するための演算子。
式オフセットget演算子。
1 アセンブリディレクティブ
アセンブラディレクティブは次のとおりです。
1)セグメンテーションディレクティブ。 前の議論の過程で、アセンブリ言語プログラムで命令とオペランドを書くためのすべての基本的な規則を見つけました。 翻訳者がコマンドを処理し、マイクロプロセッサがコマンドを実行できるように、コマンドのシーケンスを適切にフォーマットする方法の問題は未解決のままです。
マイクロプロセッサのアーキテクチャを検討すると、6つのセグメントレジスタがあり、それを介して同時に動作できることがわかりました。
1つのコードセグメントで;
1つのスタックセグメントで。
1つのデータセグメントで。
3つの追加データセグメントがあります。
物理的には、セグメントは、対応するセグメントレジスタの値を基準にしてアドレスが計算されるコマンドおよび(または)データによって占有されるメモリ領域です。 アセンブラのセグメントの構文上の説明は、図13に示す構造です。

図13-アセンブラのセグメントの構文の説明
セグメントの機能は、プログラムをコード、データ、およびスタックのブロックに単純に分割するよりもいくらか広いことに注意することが重要です。 セグメンテーションは、に関連するより一般的なメカニズムの一部です。 モジュラープログラミングの概念。これには、さまざまなプログラミング言語のオブジェクトモジュールを含む、コンパイラによって作成されたオブジェクトモジュールの設計の統合が含まれます。 これにより、異なる言語で書かれたプログラムを組み合わせることができます。 SEGMENTディレクティブのオペランドが意図されているのは、このようなユニオンのさまざまなオプションを実装するためです。
2)制御ディレクティブの一覧表示。 リスト制御ディレクティブは、次のグループに分けられます。
一般的なリスト制御ディレクティブ。
ファイルリストをインクルードするための出力ディレクティブ。
条件付きアセンブリブロックの出力ディレクティブ。
マクロのリストへの出力ディレクティブ。
リスト内の相互参照に関する情報を表示するためのディレクティブ。
リスト形式の変更ディレクティブ。
2 プロセッサ命令セット
プロセッサの命令セットを図14に示します。
コマンドの主なグループについて考えてみましょう。

図14-組み立て手順の分類
コマンドは次のとおりです。
1データ転送コマンド。 これらの命令は、プロセッサの命令セットの中で非常に重要な位置を占めています。 これらは、次の重要な機能を実行します。
プロセッサの内部レジスタの内容をメモリに保存します。
あるメモリ領域から別のメモリ領域にコンテンツをコピーする。
I / Oデバイスへの書き込みとI / Oデバイスからの読み取り。
一部のプロセッサでは、これらすべての機能が単一の命令によって実行されます MOV (バイト転送の場合- MOVB ) ただし、オペランドのアドレス指定方法は異なります。
命令以外の他のプロセッサでは MOV リストされた機能を実行するためのコマンドがさらにいくつかあります。 データ転送コマンドには、情報交換コマンドも含まれます(それらの指定は単語に基づいています交換 )。 1つのレジスタの2つの半分の間で、内部レジスタ間で情報の交換を提供することが可能かもしれません(スワップ )またはレジスタとメモリ位置の間。
2算術コマンド。 算術命令は、オペランドコードを数値の2進数またはBCDコードとして扱います。 これらのコマンドは、5つの主要なグループに分けることができます。
固定点を使用した演算(加算、減算、乗算、除算)のコマンド。
浮動小数点命令(加算、減算、乗算、除算);
クリーンアップコマンド。
インクリメントおよびデクリメントコマンド。
比較コマンド。
3固定小数点命令は、通常のバイナリコードの場合と同様に、プロセッサレジスタまたはメモリ内のコードを操作します。 浮動小数点(point)命令は、指数と仮数を使用した数値表現形式を使用します(通常、これらの数値は2つの連続したメモリ位置を占めます)。 最新の強力なプロセッサでは、浮動小数点命令セットは4つの算術演算だけでなく、三角関数、対数関数、音声および画像処理に必要な複雑な関数の計算など、他の多くのより複雑な命令も含まれています。
4クリアコマンドは、レジスタまたはメモリセルにゼロコードを書き込むように設計されています。 これらのコマンドはゼロコード転送命令に置き換えることができますが、特別なクリア命令は通常、転送命令よりも高速です。
5インクリメント(1ずつインクリメント)およびデクリメントコマンド
(1つ減らす)も非常に便利です。 原則として、加算1または減算1の命令に置き換えることができますが、インクリメントとデクリメントは加算と減算よりも高速です。 これらの命令には、出力オペランドでもある1つの入力オペランドが必要です。
6比較命令は、2つの入力オペランドを比較するためのものです。 実際、これら2つのオペランドの差を計算しますが、出力オペランドを形成せず、この減算の結果に基づいてプロセッサステータスレジスタのビットを変更するだけです。 比較命令に続く命令(通常はジャンプ命令)は、プロセッサのステータスレジスタのビットを解析し、それらの値に基づいてアクションを実行します。 一部のプロセッサは、メモリ内の2つのオペランドシーケンスをチェーン比較するための命令を提供します。
7ロジックコマンド。 論理命令は、オペランドに対して論理(ビット単位)演算を実行します。つまり、オペランドコードを単一の数値ではなく、個々のビットのセットと見なします。 この点で、それらは算術コマンドとは異なります。 ロジックコマンドは、次の基本的な操作を実行します。
論理積、論理OR、モジュロ2加算(XOR);
論理的、算術的、循環的シフト。
ビットとオペランドのチェック。
プロセッサステータスレジスタのビット(フラグ)の設定とクリア( PSW)。
論理命令により、2つの入力オペランドから基本的な論理関数をビットごとに計算できます。 さらに、AND演算を使用して、指定されたビットを強制的にクリアします(オペランドの1つとして、クリアが必要なビットがゼロに設定されているマスクコードを使用します)。 OR演算は、指定されたビットの設定を強制するために使用されます(オペランドの1つとして、1への設定が必要なビットが1に等しいマスクコードが使用されます)。 XOR演算は、指定されたビットを反転するために使用されます(オペランドの1つとして、反転されるビットが1に設定されるマスクコードが使用されます)。 命令には2つの入力オペランドが必要で、1つの出力オペランドを形成します。
8シフトコマンドを使用すると、オペランドコードをビットごとに右(下位ビットに向かって)または左(上位ビットに向かって)にシフトできます。 シフトのタイプ(論理、算術、または循環)は、最上位ビット(右にシフトする場合)または最下位ビット(左にシフトする場合)の新しい値を決定し、最上位ビットの古い値を決定します。ビットはどこかに(左にシフトした場合)または最下位ビット(右にシフトした場合)に格納されます。 ロータリーシフトを使用すると、オペランドコードのビットを円でシフトできます(右にシフトする場合は時計回り、左にシフトする場合は反時計回り)。 この場合、シフトリングにはキャリーフラグが含まれる場合と含まれない場合があります。 キャリーフラグビット(使用されている場合)は、左回転の場合は最上位ビットに、右回転の場合は最下位ビットに設定されます。 したがって、キャリーフラグビットの値は、左サイクリックシフトでは最下位ビットに、右サイクリックシフトでは最上位ビットに書き換えられます。
9ジャンプコマンド。 ジャンプコマンドは、あらゆる種類のループ、分岐、サブルーチン呼び出しなどを整理するように設計されています。つまり、プログラムのシーケンシャルフローを中断します。 これらの命令は新しい値を命令カウンタレジスタに書き込み、それによってプロセッサを順番に次の命令ではなく、プログラムメモリ内の他の命令にジャンプさせます。 一部のジャンプコマンドでは、ジャンプが行われたポイントに戻ることができますが、そうでないものもあります。 リターンが提供された場合、現在のプロセッサパラメータがスタックに格納されます。 戻り値が提供されない場合、現在のプロセッサー・パラメーターは保存されません。
バックトラックなしのジャンプコマンドは、次の2つのグループに分けられます。
無条件ジャンプのコマンド。
条件付きジャンプ命令。
これらのコマンドは単語を使用しますブランチ(ブランチ)とジャンプ(ジャンプ)。
無条件のジャンプ命令は、何があっても新しいアドレスへのジャンプを引き起こします。 指定されたオフセット値(順方向または逆方向)または指定されたメモリアドレスにジャンプする可能性があります。 オフセット値または新しいアドレス値が入力オペランドとして指定されます。
条件付きジャンプコマンドは、必ずしもジャンプを引き起こすとは限りませんが、指定された条件が満たされた場合にのみ発生します。 このような条件は通常、プロセッサステータスレジスタのフラグの値です( PSW )。 つまり、遷移条件は、フラグの値を変更する前の操作の結果です。 合計で、このようなジャンプ条件は4〜16個あります。条件付きジャンプコマンドの例:
ゼロに等しい場合はジャンプします。
ゼロ以外の場合はジャンプします。
オーバーフローがある場合はジャンプします。
オーバーフローがない場合はジャンプします。
ゼロより大きい場合はジャンプします。
ゼロ以下の場合はジャンプします。
遷移条件が満たされると、新しい値が命令カウンタレジスタにロードされます。 ジャンプ条件が満たされない場合、命令カウンタは単純にインクリメントし、プロセッサは次の命令を順番に選択して実行します。
特に分岐条件をチェックするために、条件付きジャンプ命令(またはいくつかの条件付きジャンプ命令)の前にある比較命令(CMP)が使用されます。 ただし、フラグは、データ転送コマンド、算術コマンド、論理コマンドなど、他のコマンドで設定できます。 ジャンプコマンド自体はフラグを変更しないことに注意してください。これにより、複数のジャンプコマンドを次々に配置できます。
割り込みコマンドは、リターン付きのジャンプコマンドの中で特別な位置を占めます。 これらの命令には、入力オペランドとして割り込み番号(ベクトルアドレス)が必要です。
出力:
アセンブリ言語は、機械語の象徴的な表現です。 コンピュータの種類ごとにアセンブリ言語は異なります。 アセンブリ言語プログラムは、メモリセグメントと呼ばれるメモリブロックのコレクションです。 各セグメントには言語文のコレクションが含まれており、各セグメントはプログラムコードの個別の行を占めています。 アセンブリステートメントには、コマンドまたは命令、マクロ、ディレクティブ、コメント行の4つのタイプがあります。
プログラムのテキストを書くときに有効な文字はすべてラテン文字です。 A-Z,a-z。 この場合、大文字と小文字は同等と見なされます。 からの数字 0 前 9 ; サイン ? , @ , $ , _ , & ; セパレーター , . () < > { } + / * % ! " " ? = # ^ .
次のタイプのアセンブラステートメントと、アセンブラ式を形成するための構文規則が適用されます。 算術演算子、シフト演算子、比較演算子、論理演算子、インデックス演算子、型再定義演算子、セグメント再定義演算子、構造型命名演算子、式アドレスセグメントコンポーネント取得演算子、式オフセット取得演算子。
コマンドシステムは8つの主要なグループに分けられます。
テストの質問:
1 アセンブリ言語とは何ですか?
2 アセンブラでコマンドを書き込むために使用できるシンボルは何ですか?
3 ラベルとは何ですか?その目的は何ですか?
4 組み立て説明書の構造を説明してください。
5 4種類のアセンブラステートメントをリストします。
1.PCアーキテクチャ…………………………………………………………………5
1.1。 レジスター。
1.1.1汎用レジスタ。
1.1.2。 セグメントレジスタ
1.1.3フラグレジスタ
1.2。 記憶の組織。
1.3。 データ表現。
1.3.1データ型
1.3.2文字と文字列の表現
2.アセンブリプログラムステートメント……………………………………
アセンブリ言語コマンド
2.2。 アドレッシングモードと機械命令フォーマット
3.擬微分作用素…………………………………………………………。
3.1データ定義ディレクティブ
3.2アセンブリプログラムの構造
3.2.1プログラムセグメント。 ディレクティブを想定
3.2.3簡略化されたセグメンテーションディレクティブ
4.プログラムの組み立てとリンク…………………………。
5.データ転送コマンド……………………………………………。
5.1一般的なコマンド
5.2スタックコマンド
5.3 I / Oコマンド
5.4アドレス転送コマンド
5.5フラグ転送コマンド
6.算術コマンド………………………………………………。
6.12進整数の算術演算
6.1.1加算と減算
6.1.2レシーバーを1つインクリメントおよびデクリメントするコマンド
6.2乗算と除算
6.3サインの変更
7.論理演算…………………………………………………。
8.シフトとサイクリックシフト…………………………………………
9.文字列操作……………………………………………………。
10.プログラムの論理と構成………………………………………
10.1無条件ジャンプ
10.2条件付きジャンプ
10.4アセンブリ言語での手順
10.5割り込みINT
10.6システムソフトウェア
10.6.1.1キーボードの読み取り。
10.6.1.2画面に文字を表示する
10.6.1.3プログラムの終了。
10.6.2.1表示モードの選択
11.ディスクメモリ……………………………………………………………..
11.2ファイルアロケーションテーブル
11.3ディスクI / O
11.3.1ディスクへのファイルの書き込み
11.3.1.1ASCIIZデータ
11.3.1.2ファイル番号
11.3.1.3ディスクファイルの作成
11.3.2ディスクファイルの読み取り
序章
アセンブリ言語は、機械語の象徴的な表現です。 最下位のハードウェアレベルのパーソナルコンピュータ(PC)のすべてのプロセスは、機械語コマンド(命令)によってのみ駆動されます。 アセンブラの知識がなければ、ハードウェア関連の問題(さらには、プログラムの速度の向上などのハードウェア関連の問題)を実際に解決することは不可能です。
アセンブラは、PCコンポーネントに直接使用できる便利なコマンド形式であり、これらのコンポーネントを含む集積回路、つまりPCマイクロプロセッサのプロパティと機能に関する知識が必要です。 したがって、アセンブリ言語はPCの内部構成に直接関係しています。 そして、高級言語のほとんどすべてのコンパイラがアセンブラプログラミングレベルへのアクセスをサポートしているのは偶然ではありません。
プロのプログラマーの準備の要素は、必然的にアセンブラーの研究です。 これは、アセンブリ言語プログラミングにはPCアーキテクチャの知識が必要であるためです。これにより、他の言語でより効率的なプログラムを作成し、それらをアセンブリ言語プログラムと組み合わせることができます。
このマニュアルでは、Intelマイクロプロセッサをベースにしたコンピュータのアセンブリ言語でのプログラミングについて説明しています。
このチュートリアルは、プロセッサのアーキテクチャとアセンブリ言語でのプログラミングの基本に関心のあるすべての人を対象としています。まず、ソフトウェア製品の開発者を対象としています。
PCアーキテクチャ。
コンピュータアーキテクチャは、その構造、回路、および論理的な構成を反映したコンピュータの抽象的な表現です。
最近のすべてのコンピューターには、いくつかの共通の個別のアーキテクチャー特性があります。 個々のプロパティは、特定のコンピューターモデルにのみ固有です。
コンピュータアーキテクチャの概念は次のとおりです。
コンピュータのブロック図。
コンピュータのブロック図の要素にアクセスするための手段と方法。
レジスタの設定と可用性。
組織と対処方法。
コンピュータデータの表示方法とフォーマット。
コンピュータマシンの命令のセット。
機械命令フォーマット;
割り込み処理。
コンピュータハードウェアの主な要素:システムユニット、キーボード、ディスプレイデバイス、ディスクドライブ、印刷デバイス(プリンタ)、およびさまざまな通信手段。 システムユニットは、システムボード、電源装置、および追加ボード用の拡張スロットで構成されています。 マザーボードには、マイクロプロセッサ、読み取り専用メモリ(ROM)、ランダムアクセスメモリ(RAM)、およびコプロセッサが含まれています。
レジスター。
マイクロプロセッサの内部では、情報は32個のレジスタ(16ユーザー、16システム)のグループに含まれており、プログラマーが多かれ少なかれ使用できます。 マニュアルは8088-i486マイクロプロセッサのプログラミングに専念しているため、ユーザーが利用できるマイクロプロセッサの内部レジスタについて説明することからこのトピックを開始するのが最も論理的です。
ユーザーレジスタは、プログラマがプログラムを作成するために使用します。 これらのレジスタには次のものが含まれます。
8つの32ビットレジスタ(汎用レジスタ)EAX / AX / AH / AL、EBX / BX / BH / BL、ECX / CX / CH / CL、EDX / DX / DLH / DL、EBP / BP、ESI / SI、 EDI / DI、ESP / SP;
6つの16ビットセグメントレジスタ:CS、DS、SS、ES、FS、GS。
ステータスおよび制御レジスタ:EFLAGS / FLAGSフラグレジスタ、およびEIP / IPコマンドポインタレジスタ。
1つの32ビットレジスタの一部はスラッシュで示されています。 プレフィックスE(拡張)は、32ビットレジスタの使用を示します。 バイトを処理するために、接頭辞L(低)およびH(高)を持つレジスタが使用されます。たとえば、AL、CH-レジスタの16ビット部分の下位バイトと上位バイトを示します。
一般的なレジスタ。
EAX / AX / AH / AL(アキュムレータレジスタ)- バッテリー。 乗算と除算、I / O操作、および文字列の一部の操作で使用されます。
EBX / BX / BH / BL- ベースレジスタ(ベースレジスタ)。メモリ内のデータをアドレス指定するときによく使用されます。
ECX / CX / CH / CL- カウンター(カウントレジスタ)、ループ繰り返し回数のカウンタとして使用されます。
EDX / DX / DH / DL- データレジスタ(データレジスタ)、中間データを格納するために使用されます。 一部のコマンドはそれを必要とします。
このグループのすべてのレジスタを使用すると、それらの「下位」部分にアクセスできます。 セルフアドレッシングに使用できるのは、これらのレジスタの下位16ビットおよび8ビット部分のみです。 これらのレジスタの上位16ビットは、独立したオブジェクトとして使用できません。
32、16、または8ビットの長さの要素の文字列の順次処理を可能にする文字列処理コマンドをサポートするために、以下が使用されます。
ESI / SI(ソースインデックスレジスタ)- 索引 ソース。 現在のソース要素のアドレスが含まれます。
EDI / DI(距離インデックスレジスタ)- 索引 レシーバー(受信者)。 宛先文字列に現在のアドレスが含まれます。
マイクロプロセッサのアーキテクチャでは、データ構造であるスタックがハードウェアおよびソフトウェアレベルでサポートされています。 スタックを操作するために、特別なコマンドと特別なレジスタがあります。 スタックは小さいアドレスに向かっていっぱいになることに注意してください。
ESP / SP(スタックポインタレジスタ)- 登録 ポインタ スタック。 現在のスタックセグメントのスタックの最上位へのポインタが含まれます。
EBP / BP(ベースポインタレジスタ)– スタックベースポインタレジスタ。 スタック内のデータへのランダムアクセスを整理するように設計されています。
1.1.2。 セグメントレジスタ
マイクロプロセッサソフトウェアモデルには6つあります セグメントレジスタ: CS、SS、DS、ES、GS、FS。 それらの存在は、IntelマイクロプロセッサによるRAMの構成と使用の詳細によるものです。 マイクロプロセッサハードウェアは、以下で構成されるプログラムの構造的編成をサポートします。 セグメント。セグメントレジスタは、現在使用可能なセグメントを示すために使用されます。 マイクロプロセッサは、次のタイプのセグメントをサポートしています。
コードセグメント。プログラムコマンドが含まれていますこのセグメントにアクセスするには、CSレジスタ(コードセグメントレジスタ)を使用します- セグメントコードレジスタ。 これには、マイクロプロセッサがアクセスできる機械命令セグメントのアドレスが含まれています。
データセグメント。プログラムによって処理されたデータが含まれます。 このセグメントにアクセスするには、DSレジスタ(データセグメントレジスタ)を使用します- セグメントデータレジスタ、現在のプログラムのデータセグメントのアドレスを格納します。
スタックセグメント。このセグメントは、スタックと呼ばれるメモリの領域です。 マイクロプロセッサは、最初の「来た」、最初の「左」という原則に従ってスタックを編成します。 スタックにアクセスするには、SSレジスタ(スタックセグメントレジスタ)を使用します- スタックセグメントレジスタスタックセグメントのアドレスを含むA。
追加のデータセグメント。処理されるデータは、3つの追加データセグメントに含めることができます。 デフォルトでは、データはデータセグメントにあると見なされます。 追加のデータセグメントを使用する場合は、コマンドで特別なセグメント再定義プレフィックスを使用して、それらのアドレスを明示的に指定する必要があります。 追加のデータセグメントのアドレスは、レジスタES、GS、FS(extenSIonデータセグメントレジスタ)に含まれている必要があります。
制御およびステータスレジスタ
マイクロプロセッサには、マイクロプロセッサ自体と、現在パイプラインに命令がロードされているプログラムの両方の状態に関する情報を含むいくつかのレジスタが含まれています。 これ:
EIP / IPコマンドポインタレジスタ。
EFLAGS / FLAGSフラグレジスタ。
これらのレジスタを使用すると、コマンド実行の結果に関する情報を取得し、マイクロプロセッサ自体の状態に影響を与えることができます。
EIP / IP(命令ポインタレジスタ)- ポインタ コマンド。 EIP / IPレジスタは32ビットまたは16ビット幅で、現在の命令セグメントのCSセグメントレジスタの内容に対して実行される次の命令のオフセットが含まれています。 このレジスタには直接アクセスできませんが、ジャンプ命令によって変更されます。
EFLAGS / FLAGS(フラグレジスタ)- 登録 フラグ。 ビット深度32/16ビット。 このレジスタの個々のビットには特定の機能目的があり、フラグと呼ばれます。 フラグは、ある条件が真の場合は1(「フラグが設定されている」)に設定され、そうでない場合は0(「フラグがクリアされている」)に設定されるビットです。 このレジスタの下部は、i8086のFLAGSレジスタに完全に類似しています。
1.1.3フラグレジスタ
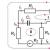
フラグレジスタは32ビットで、EFLAGSという名前が付いています(図1)。 レジスタの個々のビットには特定の機能目的があり、フラグと呼ばれます。 それぞれに特定の名前(ZF、CFなど)が割り当てられます。 EFLAGSの下位16ビットは、i086およびi286マイクロプロセッサ用に記述されたプログラムを実行するときに使用される16ビットFLAGSレジスタを表します。
図1フラグの登録
一部のフラグは条件フラグと呼ばれます。 コマンドが実行されると自動的に変更され、結果の特定のプロパティ(たとえば、ゼロに等しいかどうか)が修正されます。 他のフラグは状態フラグと呼ばれます。 それらはプログラムから変更され、プロセッサのさらなる動作に影響を与えます(たとえば、割り込みをブロックします)。
条件フラグ:
CF(キャリーフラグ)- キャリーフラグ。 整数を加算するときにビットグリッドに「適合」しないキャリーユニットが表示された場合、または符号なしの数値を減算したときに最初の値が2番目よりも小さかった場合は、値1を取ります。 シフトコマンドでは、オフグリッドのビットがCFに入力されます。 CFは、乗算命令の機能も修正します。
OF(オーバーフローフラグ) オーバーフローフラグ。 符号付きの整数を加算または減算するときに、モジュロが許容値を超えた結果が得られた場合(仮数がオーバーフローし、符号ビットに「登った」場合)、1に設定されます。
ZF(ゼロフラグ) ゼロフラグ。 コマンドの結果が0の場合は、1に設定します。
SF(SIgnフラグ)- 国旗 サイン。 符号付き数値の演算で否定的な結果が得られる場合は、1に設定します。
PF(パリティフラグ)- 国旗 パリティ。 次のコマンドの結果に偶数のバイナリが含まれている場合は、1になります。 これは通常、I / O操作中にのみ考慮されます。
AF(補助キャリーフラグ)- 追加のキャリーフラグ。 2進化10進数で演算を実行する機能を修正しました。
ステータスフラグ:
DF(方向フラグ) 方向フラグ。 文字列コマンドで線をスキャンする方向を設定します。DF= 0の場合、線は「前方」(最初から最後まで)にスキャンされ、DF = 1の場合は反対方向にスキャンされます。
IOPL(入出力特権レベル)- I / O特権レベル。タスクの特権に応じて、I / Oコマンドへのアクセスを制御するためにマイクロプロセッサの保護モードで使用されます。
NT(ネストされたタスク) タスクネストフラグ。マイクロプロセッサの保護モードで使用され、あるタスクが別のタスク内にネストされているという事実を記録します。
システムフラグ:
IF(割り込みフラグ)- 割り込みフラグ。 IF = 0の場合、プロセッサはそれに入る割り込みへの応答を停止します。IF= 1の場合、割り込みのブロックは削除されます。
TF(トラップフラグ) トレースフラグ。 TF = 1の場合、各命令を実行した後、プロセッサは割り込み(番号1)を作成します。これは、プログラムをデバッグしてトレースするときに使用できます。
RF(再開フラグ) 再開フラグ。 デバッグレジスタからの割り込みを処理するときに使用されます。
VM(仮想8086モード)- 仮想8086フラグ。 1-プロセッサは仮想8086モードで動作します。0-プロセッサは実モードまたは保護モードで動作します。
AC(アライメントチェック)- アラインメント制御フラグ。メモリにアクセスするときにアライメント制御を有効にするように設計されています。
記憶の組織。
マイクロプロセッサがアクセスできる物理メモリは、 ワーキングメモリ(またはランダムアクセスメモリ 羊)。 RAMは、独自のアドレス(その番号)を持つバイトのチェーンであり、 物理的。物理アドレスの範囲は0〜4GBです。 メモリ管理メカニズムは完全にハードウェアベースです。
マイクロプロセッサは、ハードウェアでのRAM使用のいくつかのモデルをサポートしています。
セグメント化されたモデル。 このモデルでは、プログラムメモリは連続したメモリ領域(セグメント)に分割され、プログラム自体はこれらのセグメントにあるデータにのみアクセスできます。
ページモデル。 この場合、RAMは4KBの固定サイズのブロックのセットと見なされます。 このモデルの主な用途は、仮想メモリの編成に関連しています。これにより、プログラムは物理メモリの量よりも多くのメモリスペースを使用できます。 Pentiumマイクロプロセッサの場合、可能な仮想メモリのサイズは最大4TBです。
これらのモデルの使用と実装は、マイクロプロセッサの動作モードによって異なります。
リアルアドレスモード(リアルモード)。このモードは、i8086プロセッサの動作に似ています。 初期のプロセッサモデル用に設計されたプログラムの操作に必要です。
保護モード。プロテクトモードでは、4レベルの特権メカニズムとそのページングを使用して、マルチタスク情報処理、メモリ保護が可能になります。
仮想8086モード。このモードでは、i8086用に複数のプログラムを実行することが可能になります。 この場合、リアルモードプログラムが機能します。
セグメンテーションは、いくつかの独立したアドレス空間の存在を保証するアドレス指定メカニズムです。 セグメントは、ハードウェアでサポートされている独立したメモリブロックです。
一般的な場合、各プログラムは任意の数のセグメントで構成できますが、コード、データ、スタックの3つの主要なプログラムと、1つから3つの追加のデータセグメントに直接アクセスできます。 オペレーティングシステムは、プログラムセグメントを特定の物理アドレスのRAMに配置し、これらのアドレスの値を対応するレジスタに配置します。 セグメント内では、プログラムはセグメントの開始に関連するアドレスに直線的にアクセスします。つまり、アドレス0で開始し、セグメントのサイズに等しいアドレスで終了します。 相対アドレスまたは バイアス、マイクロプロセッサがセグメント内のデータにアクセスするために使用するものは、 効率的。
リアルモードでの物理アドレスの形成
リアルモードでは、物理アドレスの範囲は0〜1MBです。 最大セグメントサイズは64KBです。 特定のことを指すとき 実在住所 RAMは、セグメントの先頭のアドレスとセグメント内のオフセットによって決定されます。 セグメント開始アドレスは、対応するセグメントレジスタから取得されます。 この場合、セグメントレジスタには、セグメントの先頭の物理アドレスの上位16ビットのみが含まれます。 20ビットアドレスの欠落している下位4ビットは、セグメントレジスタの値を4ビット左にシフトすることによって取得されます。 シフト操作はハードウェアで実行されます。 結果の20ビット値は、セグメントの先頭に対応する実際の物理アドレスです。 つまり、 住所は「segment:offset」ペアとして指定されます。ここで、「segment」はセルが属するメモリセグメントの開始アドレスの最初の16ビットであり、「offset」はこのセルの16ビットアドレスです。このメモリセグメントの先頭(値16 * segment + offsetはセルの絶対アドレスを示します)。 たとえば、値1234hがCSレジスタに格納されている場合、アドレスペア1234h:507hは、16 * 1234h + 507h = 12340h + 507h = 12847hに等しい絶対アドレスを定義します。 このようなペアは、ダブルワードの形式で記述され、(数値に関しては)「反転」形式で記述されます。最初のワードにはオフセットが含まれ、2番目のセグメントにはこれらの各ワードが順番に表されます。 「反転」形式。 たとえば、ペア1234h:5678hは次のように記述されます。| 78 | 56 | 34 | 12 |。
物理アドレスを形成するこのメカニズムにより、ソフトウェアを再配置可能にすることができます。つまり、RAM内の特定のダウンロードアドレスに依存することはありません。
機械命令のレベルでのプログラミングは、プログラミングが可能な最小レベルです。 機械命令のシステムは、コンピュータハードウェアに命令を発行することによって必要なアクションを実装するのに十分でなければなりません。
各機械命令は2つの部分で構成されています。
- 手術室-「何をすべきか」を決定する。
- オペランド-処理オブジェクトの定義、「何をするか」。
アセンブリ言語で記述されたマイクロプロセッサの機械命令は、次の構文形式の1行です。
ラベルコマンド/ディレクティブ オペランド;コメント
この場合、行の必須フィールドはコマンドまたはディレクティブです。
ラベル、コマンド/ディレクティブ、およびオペランド(存在する場合)は、少なくとも1つのスペースまたはタブ文字で区切られます。
コマンドまたはディレクティブを次の行に続ける必要がある場合は、バックスラッシュ文字を使用します:\。
デフォルトでは、アセンブリ言語はコマンドまたはディレクティブの大文字と小文字を区別しません。
コードの例:
Countdb 1 ;名前、ディレクティブ、1つのオペランド
mov eax、0 ;コマンド、2つのオペランド
cbw; 指示
タグ
ラベル アセンブリ言語では、次の記号を含めることができます。
- ラテンアルファベットのすべての文字。
- 0から9までの数字。
- 特殊文字:_、@、$、?。
ラベルの最初の文字としてドットを使用できますが、一部のコンパイラーはこの文字を推奨していません。 予約済みのアセンブリ言語名(ディレクティブ、演算子、コマンド名)をラベルとして使用することはできません。
ラベルの最初の文字は、文字または特殊文字(数字ではない)である必要があります。 ラベルの最大長は31文字です。 アセンブラディレクティブを含まない行に書き込まれるすべてのラベルは、コロンで終了する必要があります。
チーム
指示 マイクロプロセッサが実行する必要のあるアクションを翻訳者に通知します。 データセグメントでは、コマンド(またはディレクティブ)がフィールド、ワークスペース、または定数を定義します。 コードセグメントでは、命令は移動(mov)や追加(add)などのアクションを定義します。
ディレクティブ
アセンブラには、リストのアセンブルと生成のプロセスを制御できる多数の演算子があります。 これらの演算子はと呼ばれます ディレクティブ 。 これらはプログラムを組み立てる過程でのみ機能し、命令とは異なり、マシンコードを生成しません。
オペランド
オペランド
–マシンコマンドまたはプログラミング言語演算子が実行されるオブジェクト。
命令には、1つまたは2つのオペランドがある場合と、オペランドがまったくない場合があります。 オペランドの数は、命令コードによって暗黙的に指定されます。
例:
- オペランドなしret; Return
- 1つのオペランドincecx;インクリメントecx
- 2つのオペランドがeax、12を追加します; eaxに12を追加します
ラベル、コマンド(ディレクティブ)、およびオペランドは、文字列内の特定の位置から開始する必要はありません。 ただし、プログラムを読みやすくするために、列に書き込むことをお勧めします。
オペランドは
- 識別子;
- 一重引用符または二重引用符で囲まれた文字列。
- 2進数、8進数、10進数、または16進数の整数。
識別子
識別子 –操作コード、変数名、ラベル名などのプログラムオブジェクトを指定するために使用される有効な文字のシーケンス。
識別子を書くための規則。
- 識別子は1つ以上の文字にすることができます。
- 文字として、ラテンアルファベットの文字、数字、およびいくつかの特殊文字(_、?、$、@)を使用できます。
- 識別子を数字で始めることはできません。
- IDの長さは最大255文字です。
- トランスレータは、識別子の最初の32文字を受け入れ、残りを無視します。
コメントコメント
コメントは、実行可能行から文字で区切られます。 。 この場合、セミコロン文字の後から行末までに書かれているものはすべてコメントです。 プログラムでコメントを使用すると、特に一連の命令の目的が不明確な場合に、その明確さが向上します。 コメントには、スペースを含む任意の印刷可能な文字を含めることができます。 コメントは1行全体にまたがることも、同じ行のコマンドに従うこともできます。
アセンブリプログラムの構造
アセンブリ言語で書かれたプログラムは、次のようないくつかの部分で構成されている場合があります。 モジュール 。 各モジュールは、1つ以上のデータ、スタック、およびコードセグメントを定義できます。 完全なアセンブリ言語プログラムには、実行を開始する1つのメインモジュールまたはメインモジュールが含まれている必要があります。 モジュールには、適切なディレクティブで宣言されたコード、データ、およびスタックセグメントが含まれる場合があります。 セグメントを宣言する前に、.MODELディレクティブを使用してメモリモデルを指定する必要があります。
アセンブリ言語での「何もしない」プログラムの例:
686P
.MODEL FLAT、STDCALL
。データ
。コード
始める:
RET
終了開始
このプログラムには、マイクロプロセッサ命令が1つだけ含まれています。 このコマンドはRETです。 これにより、プログラムが正しく終了します。 通常、このコマンドはプロシージャを終了するために使用されます。
プログラムの残りの部分は、翻訳者の操作に関連しています。
.686P-Pentium 6(Pentium II)プロテクトモードコマンドが許可されます。 このディレクティブは、プロセッサモデルを指定することにより、サポートされているアセンブラ命令セットを選択します。 ディレクティブの最後にある文字Pは、プロセッサがプロテクトモードで実行されていることをトランスレータに通知します。
.MODEL FLAT、stdcallはフラットメモリモデルです。 このメモリモデルは、Windowsオペレーティングシステムで使用されます。 stdcall
.DATAは、データを含むプログラムセグメントです。
.CODEは、コードを含むプログラムブロックです。
STARTはラベルです。 アセンブラでは、ラベルが大きな役割を果たしますが、これは現代の高級言語では言えません。
END START-プログラムの終了と、プログラムをSTARTというラベルから開始する必要があるという翻訳者へのメッセージ。
各モジュールには、プログラムのソースコードの終わりを示すENDディレクティブが含まれている必要があります。 ENDディレクティブに続くすべての行は無視されます。 ENDディレクティブを省略すると、エラーが発生します。
ENDディレクティブの後のラベルは、プログラムの実行を開始するメインモジュールの名前をコンパイラに通知します。 プログラムにモジュールが1つ含まれている場合は、ENDディレクティブの後のラベルを省略できます。
目的によって、コマンドを区別することができます(IBM PCなどのPCアセンブラーのコマンドのニーモニックオペコードの例は括弧内に示されています)。
l算術演算を実行します(ADDとADC-キャリーで加算と加算、SUBとSBB-ローンで減算と減算、MULとIMUL-符号なしと符号付きの乗算、DIVとIDIV-符号なしと符号付きの除算、CMP-比較など) ;
l論理演算(OR、AND、NOT、XOR、TESTなど)を実行します。
lデータ転送(MOV-送信、XCHG-交換、IN-マイクロプロセッサへの入力、OUT-マイクロプロセッサからの撤退など)。
l制御の転送(プログラム分岐:JMP-無条件分岐、CALL-プロシージャ呼び出し、RET-プロシージャからの戻り、J *-条件分岐、LOOP-ループ制御など)。
l文字列の処理(MOVS-転送、CMPS-比較、LODS-ダウンロード、SCAS-スキャン。これらのコマンドは通常、プレフィックス(繰り返し修飾子)REPとともに使用されます。
lプログラム割り込み(INT-ソフトウェア割り込み、INTO-オーバーフロー時の条件付き割り込み、IRET-割り込みからの復帰);
lマイクロプロセッサ制御(ST *およびCL *-フラグの設定とクリア、HLT-停止、WAIT-スタンバイ、NOP-アイドルなど)。
アセンブラコマンドの完全なリストは、作品にあります。
データ転送コマンド
l MOV dst、src-データ転送(move-srcからdstに移動)。
転送:レジスタ間またはレジスタとメモリ間で1バイト(srcとdstがバイト形式の場合)または1ワード(srcとdstがワード形式の場合)で、レジスタまたはメモリに即値を書き込みます。
オペランドdstとsrcは、同じ形式(バイトまたはワード)である必要があります。
Srcのタイプは次のとおりです。r(レジスタ)-レジスタ、m(メモリ)-メモリ、i(インピーダンス)-即値。 Dstは、タイプr、mにすることができます。 オペランドを1つのコマンドで使用することはできません。rsegmとi。 タイプmの2つのオペランドとタイプrsegmの2つのオペランド)。 オペランドiも単純な式にすることができます。
mov AX、(152 + 101B)/ 15
式の評価は、翻訳中にのみ実行されます。 フラグは変更されません。
l PUSH src-単語をスタックに置く(プッシュ - 押し通します; srcからスタックにプッシュします)。 srcの内容をスタックの最上位(16ビットレジスタ(セグメントを含む)または16ビットワードを含む2つのメモリ位置)にプッシュします。 フラグは変更されません。
l POP dst-スタックから単語を抽出します(pop-pop; dstのスタックからカウントします)。 スタックの最上位からワードを削除し、それをdst(任意の16ビットレジスタ(セグメントを含む)または2つのメモリ位置)に配置します。 フラグは変更されません。
コースワーク
件名「システムプログラミング」
トピック4:「手順の問題を解決する」
オプション2
イーストシベリア州立大学
テクノロジーと管理
____________________________________________________________________
技術専門学校
タスク
タームペーパー用
| 規律: |
| トピック:手順の問題解決 |
| アーティスト:Glavinskaya Arina Alexandrovna |
| ヘッド:Sesegma Viktorovna Dambaeva |
| 作業の簡単な要約:アセンブリ言語でのサブルーチンの研究、 |
| サブルーチンを使用した問題解決 |
| 1.理論的部分:アセンブリ言語に関する基本情報(セット |
| コマンドなど)、サブプログラムの編成、パラメータの受け渡し方法 |
| サブルーチン内 |
| 2.実用的な部分:2つのサブルーチンを開発します。1つは任意の文字を大文字に変換し(ロシア語の文字を含む)、もう1つは文字を小文字に変換します。 |
| 任意の文字を大文字に変換し、もう一方は文字を小文字に変換します。 |
| 文字を小文字に変換します。 |
| スケジュールに従ってプロジェクトのタイムライン: |
| 1.理論的部分-7週目までに30%。 |
| 2.実用的な部分-11週間で70%。 |
| 3.保護-14週間までに100%。 |
| 設計要件: |
| 1.コースプロジェクトの決済と説明文は、に提出する必要があります |
| 電子コピーとハードコピー。 |
| 2.レポートのボリュームは、付録を除いて、少なくとも20ページのタイプライターである必要があります。 |
| 3.RPPはGOST7.32-91に従って作成され、ヘッドによって署名されます。 |
作業責任者__________________
出演者__________________
発行日 " 26 " 9月 2017 G。
序章。 2
1.1アセンブリ言語に関する基本情報。 3
1.1.1コマンドセット。 4
1.2アセンブリ言語でのサブルーチンの編成。 4
1.3サブルーチンでパラメータを渡すためのメソッド。 6
1.3.1レジスタを介したパラメータの受け渡し..6
1.3.2スタックを介したパラメータの受け渡し。 7
2実践セクション..9
2.1問題の説明。 九
2.2問題解決の説明。 九
2.3プログラムのテスト..7
結論。 8
参考文献..9
序章
アセンブリ言語でのプログラミングが難しいことはよく知られています。 ご存知のように、今では多くの異なる言語があります 上級、これにより、プログラムを作成する際の労力を大幅に削減できます。 当然、プログラマーがプログラムを作成するときにアセンブラーを使用する必要がある場合に問題が発生します。 現在、アセンブリ言語の使用が正当化され、多くの場合必要となる2つの領域があります。
まず、これらはいわゆるマシン依存のシステムプログラムであり、通常、さまざまなコンピュータデバイスを制御します(このようなプログラムはドライバと呼ばれます)。 これらのシステムプログラムは、通常の方法で使用する必要のない特別な機械命令を使用します(または、彼らが言うように、 適用)プログラム。 これらのコマンドは、高級言語で指定することは不可能または非常に困難です。
アセンブラーのアプリケーションの2番目の領域は、プログラム実行の最適化に関連しています。 非常に多くの場合、高級言語の翻訳プログラム(コンパイラ)は非常に非効率的な機械語プログラムを生成します。 これは通常、プログラムの非常に小さな(約3〜5%)セクション(メインループ)がほとんどの時間実行される計算的な性質のプログラムに適用されます。 この問題を解決するために、いわゆる多言語プログラミングシステムを使用することができます。これにより、プログラムの一部をさまざまな言語で作成できます。 通常、プログラムの主要部分は高級プログラミング言語(Fortran、Pascal、Cなど)で記述され、プログラムのタイムクリティカルセクションはアセンブラーで記述されます。 この場合、プログラム全体の速度が大幅に向上する可能性があります。 これは多くの場合、プログラムに妥当な時間で結果を生成させる唯一の方法です。
このコースワークの目的は、アセンブリ言語でのプログラミングの実践的なスキルを習得することです。
作業タスク:
1.アセンブラー言語に関する基本情報(アセンブラーのプログラムの構造とコンポーネント、コマンドの形式、サブルーチンの構成など)を学習する。
2.ビット演算のタイプ、アセンブラロジックコマンドのフォーマットとロジックを調べるため。
3.アセンブラーでのサブルーチンの使用に関する個々の問題を解決します。
4 ..行われた作業について結論を出します。
1理論セクション
アセンブリ言語の基本
アセンブラは、人間の知覚に便利な機械命令を書くためのフォーマットである低水準プログラミング言語です。
アセンブリ言語コマンドは、プロセッサコマンドに1対1で対応し、実際、コマンドとその引数の便利な記号形式(ニーモニックコード)を表します。 アセンブリ言語は、基本的なプログラミングの抽象化も提供します。つまり、プログラムの一部とデータを、記号名とディレクティブを使用したラベルを介してリンクします。
アセンブリディレクティブを使用すると、データのブロック(明示的に記述されているかファイルから読み取られる)をプログラムに含めることができます。 特定のフラグメントを指定された回数繰り返します。 条件に従ってフラグメントをコンパイルします。 フラグメント実行アドレスを設定し、コンパイル中にラベル値を変更します; パラメータなどでマクロ定義を使用します。
長所と短所
冗長コードの最小量(より少ないコマンドとメモリアクセスの使用)。 結果として、速度が速くなり、プログラムサイズが小さくなります。
大量のコード、多数の追加の小さなタスク。
コードの可読性の低さ、サポートの難しさ(デバッグ、機能の追加)。
・プログラミングパラダイムやその他のやや複雑な規則の実装の難しさ、共同開発の複雑さ。
利用可能なライブラリが少なく、互換性が低い。
・ハードウェアへの直接アクセス:入出力ポート、特別なプロセッサレジスタ。
目的のプラットフォームの最大「フィッティング」(特別な指示の使用、「アイアン」の技術的特徴)。
・他のプラットフォームへの非移植性(バイナリ互換プラットフォームを除く)。
命令に加えて、プログラムにはディレクティブが含まれている場合があります。これは、マシン命令に直接変換されないが、コンパイラの動作を制御するコマンドです。 それらのセットと構文は大幅に異なり、ハードウェアプラットフォームではなく、使用されるコンパイラに依存します(同じアーキテクチャファミリ内の言語の方言を生み出します)。 ディレクティブのセットとして、次のものを区別できます。
データの定義(定数と変数);
メモリ内のプログラムの編成と出力ファイルのパラメータの管理。
コンパイラモードの設定。
・あらゆる種類の抽象化(つまり、高級言語の要素)-プロシージャと関数の設計(手続き型プログラミングパラダイムの実装を簡素化するため)から条件付き構造とループ(構造プログラミングパラダイム用)まで。
マクロ。
コマンドセット
一般的なアセンブリ言語の説明は次のとおりです。
データ転送コマンド(movなど)
算術コマンド(add、sub、imulなど)
論理演算およびビット演算(または、および、xor、shrなど)
プログラムの実行を管理するためのコマンド(jmp、loop、retなど)
割り込み呼び出しコマンド(制御コマンドと呼ばれることもあります):int
ポートへのI / Oコマンド(入力、出力)
マイクロコントローラーとマイクロコンピューターは、条件ごとにチェックと遷移を実行するコマンドによっても特徴付けられます。次に例を示します。
・jne-等しくない場合はジャンプします。
・jge-以上の場合はジャンプします。