Lineare Abhängigkeit in Excel. Die Hauptaufgaben der Regression in Excel: ein Beispiel für den Aufbau eines Modells
In früheren Anmerkungen wurde die Analyse der Analyse häufig zu einer separaten Zahlenvariablen, z. B. der Ausbeute an Investmentfonds, der Zeit des Ladens einer Webseite oder des Volumens des alkoholfreien Getränkungsverbrauchs. In den vorliegenden und folgenden Hinweisen werden wir die Vorhersagemethoden der numerischen Variablenwerte in Abhängigkeit von den Werten einer oder mehrerer anderen numerischen Variablen ansehen.
Das Material wird durch ein Beispiel durch ein Beispiel dargestellt. Prognoseverkäufe im Bekleidungsgeschäft.Sunflowers Discounted Bekleidungsgeschäft für 25 Jahre ist ständig erweitert. Nun hat das Unternehmen jedoch keinen systematischen Ansatz zur Auswahl neuer Auslässe. Ein Ort, an dem das Unternehmen einen neuen Laden eröffnen wird, ermittelt anhand von subjektiven Überlegungen. Die Auswahlkriterien sind günstige Leasingbedingungen oder den idealen Standortmanager. Stellen Sie sich vor, Sie sind der Leiter der Abteilung für spezielle Projekte und Planung. Sie wurden angewiesen, einen strategischen Plan für die Eröffnung neuer Filialen zu entwickeln. Dieser Plan sollte die Prognose des Jahresumsatzes in neu eröffneten Geschäften enthalten. Sie glauben, dass der Handelsbereich direkt mit dem Umsatzvolumen zusammenhängt, und Sie möchten diese Tatsache im Entscheidungsprozess berücksichtigen. Wie entwickeln Sie ein statistisches Modell, mit dem Sie den jährlichen Umsatz basierend auf der Größe eines neuen Ladens vorhersagen können?
Um die variablen Werte vorherzusagen, wird in der Regel verwendet regressionsanalyse. Sein Ziel ist es, ein statistisches Modell zu entwickeln, mit dem Sie die Werte der abhängigen Variablen oder der Antwort, durch Werte von mindestens einer unabhängigen, unabhängigen oder erläuternden Variablen vorhersagen können. In dieser Hinweis berücksichtigen wir eine einfache lineare Regression - eine statistische Methode, mit der Sie die Werte der abhängigen Variablen vorherzusagen können Y. durch die Werte einer unabhängigen Variablen X.. In anschließenden Notizen wird ein mehrfacher Regressionsmodell beschrieben, das die Werte einer unabhängigen Variablen vorhersagen soll. Y. durch die Werte mehrerer abhängiger Variablen ( X 1, x 2, ..., x k).
Notiz im Format oder in Format herunterladen
Arten von Regressionsmodellen
wo ρ 1 - der Autokorrelationskoeffizient; wenn ein ρ 1 \u003d 0 (keine Autokorrelation), D. ≈ 2; wenn ein ρ 1 ≈ 1 (positive Autokorrelation), D. ≈ 0; wenn ein ρ 1 \u003d -1 (negative Autokorrelation), D. ≈ 4.
In der Praxis basiert die Verwendung von Durbin-Watson-Kriterien auf dem Vergleich D. mit kritischen theoretischen Werten d L. und du. Für eine gegebene Anzahl von Beobachtungen n.Anzahl unabhängiger Variablenmodelle k. (Für einfach lineare Regression k. \u003d 1) und der Signifikanzniveau α. Wenn ein D.< d L Die Hypothese über die Unabhängigkeit zufälliger Abweichungen wird abgelehnt (daher ist positive Autokorrelation vorhanden); wenn ein D\u003e d uDie Hypothese wird nicht abgelehnt (das heißt, es gibt keine Autokorrelation); wenn ein d L.< D < d U Es gibt keine ausreichende Gründe für eine Entscheidung. Bei berechneter Wert D. damals 2 überschreiten d L. und du. Verglichen nicht der Koeffizient selbst D.und Ausdruck (4 - D.).
Um die Statistik von Durbina-Watson in Excel zu berechnen, wenden wir uns in die untere Tabelle in FIG. vierzehn Fazit Rückstand. Der Numerator in der Expression (10) wird unter Verwendung der Funktion \u003d zusammenfassbar (Array1; Array2) und der Nenner \u003d Abrechnungszeichen (Anordnung) berechnet (Abb. 16).

Feige. 16. Formeln zur Berechnung der Statistiken von Durbin-Watson
In unserem Beispiel D. \u003d 0.883. Die Hauptfrage lautet wie folgt - was die Bedeutung von Durbin-Watson Statistiken ist, sollte als klein genug angesehen werden, um die Existenz einer positiven Autokorrelation abzuschließen? Es ist notwendig, den Wert von d mit kritischen Werten zu korrelieren ( d L.und Du.) Abhängig von der Anzahl der Beobachtungen n. und das Maß an Bedeutung α (Fig. 17).

Feige. 17. Kritische Werte von Durbin-Watson-Statistiken (Tischfragment)
In der Umsatzaufgabe im Laden, der Waren zum Haus liefert, gibt es daher eine unabhängige Variable ( k. \u003d 1), 15 Beobachtungen ( n. \u003d 15) und der Maß an Bedeutung α \u003d 0,05. Daher, d L.\u003d 1.08 I. d. U. \u003d 1,36. Soweit D. = 0,883 < d L.\u003d 1.08, es gibt eine positive Autokorrelation zwischen den Rückständen, das kleinste Quadrate-Verfahren kann nicht angewendet werden.
Überprüfen Sie Hypothesen um den Neigung und den Korrelationskoeffizienten
Die obere Regression wurde ausschließlich zur Prognose verwendet. Um die Regressionskoeffizienten und Vorhersage des Werts der Variablen zu bestimmen Y. Für einen bestimmten variablen Wert X. Die kleinste Quadratmethode wurde verwendet. Darüber hinaus betrachteten wir den mittleren quadratischen Fehler der Schätzung und den gemischten Korrelationskoeffizienten. Wenn die Analyse der Rückstände bestätigt, dass die Bedingungen für die Anwendbarkeit der Mindestquadrate-Methode nicht verletzt werden, und das Modell der einfachen linearen Regression ist angemessen, auf der Grundlage von selektiven Daten kann argumentiert werden, dass eine lineare Abhängigkeit zwischen Variablen besteht in der allgemeinen Bevölkerung.
Anwendungt. -Kriterien zur Neigung.Überprüfen, ob die Neigung der allgemeinen Kombination von β 1 Null gleich ist, ob es möglich ist, festzustellen, ob die statistisch sinnvolle Beziehung zwischen Variablen besteht X. und Y.. Wenn diese Hypothese ablenkt, kann es argumentiert werden, dass zwischen Variablen X. und Y. Es gibt eine lineare Abhängigkeit. Null- und alternative Hypothesen werden wie folgt formuliert: H 0: β 1 \u003d 0 (keine lineare Abhängigkeit), H1: β 1 ≠ 0 (es gibt eine lineare Abhängigkeit). A-PREIORE. t.-Station ist gleich dem Unterschied zwischen der selektiven Neigung und dem hypothetischen Wert der Neigung der allgemeinen Bevölkerung, die in den mittleren quadratischen Fehler der Neigungsschätzung unterteilt ist:
(11) t. = (b. 1 – β 1 ) / S B. 1
wo b. 1
- die Neigung der direkten Regression gemäß selektiven Daten, β1 ist eine hypothetische Neigung des direkten allgemeinen Aggregats, ![]() und Teststatistiken t. Es hat t.-Distribution von S. n - 2. Freiheitsgrade.
und Teststatistiken t. Es hat t.-Distribution von S. n - 2. Freiheitsgrade.
Prüfen Sie, ob zwischen der Größe des Ladens und dem jährlichen Verkaufsvolumen bei α \u003d 0,05 eine statistisch signifikante Beziehung besteht. t.-Kriterien wird zusammen mit anderen Parametern angezeigt, wenn sie verwendet werden Paketanalyse (Möglichkeit Regression.). Vollständig Die Ergebnisse der Analyse des Analysepakets sind in Fig. 4 gezeigt. In Fig. 4 gehört ein Fragment, das zu T-Statistiken gehört - in FIG. achtzehn.
Feige. 18. Erträge der Anwendung t.
Seit der Anzahl der Geschäfte n. \u003d 14 (siehe Abb.3), kritischer Wert t.- Die Statistiken auf der Ebene der Bedeutung α \u003d 0,05 sind von der Formel zu finden: t l. \u003d Student. Produzieren (0,025; 12) \u003d -2,1788, wobei 0,025 die Hälfte des Wertes der Bedeutung ist, und 12 \u003d n. – 2; tu. \u003d Student. Prof (0.975; 12) \u003d +2,1788.
Soweit t.-Station \u003d 10.64\u003e tu. \u003d 2,1788 (Abb. 19), Nullhypothese H 0. abweicht. Andererseits, r.-Notion für. H. \u003d 10 6411, berechnet von der Formel \u003d 1-Stufe.sp (D3; 12; Wahrheit), ungefähr Null, also die Hypothese H 0. wieder abgelehnt Die Tatsache, dass r.- Eine Idee ist fast gleich Null, es bedeutet, dass es, wenn es keine echte lineare Abhängigkeit zwischen der Größe der Filialen und dem jährlichen Verkaufsvolumen gab, fast unmöglich wäre, sie mit linearer Regression zu erkennen. Folglich gibt es eine statistisch signifikante lineare Abhängigkeit zwischen dem durchschnittlichen jährlichen Verkaufsvolumen in den Filialen und deren Größe.

Feige. 19. Überprüfen der Hypothese über die Neigung der allgemeinen Bevölkerung auf der Signifikanzniveau, gleich 0,05 und 12 Grad Freiheit
AnwendungF. -Kriterien zur Neigung.Ein alternativer Ansatz zur Überprüfung der Hypothesen um die Steigung einer einfachen linearen Regression ist zu verwenden F.-Kriterien. Erinnere dich daran F.-Kriterien dient zur Überprüfung der Beziehung zwischen zwei Dispersionen (für weitere Details, siehe). Bei der Überprüfung der Hypothese um die Steigung durch ein Maß für zufällige Fehler ist die Fehlerdispersion (die Summe der Fehlquadrate, die durch die Anzahl der Freiheitsgrade geteilt ist), so F.-Kriterien verwendet das Dispersionsverhältnis aufgrund von Regression (d. H. Werte SSR.geteilt durch die Anzahl der unabhängigen Variablen k.), zu Dispersionsfehlern ( MSE \u003d S y X. 2 ).
A-PREIORE. F.-Station ist gleich dem durchschnittlichen Quadrat der Abweichungen, die durch Regression (MSR) verursacht werden, die in Fehlerdispersion (MSE) unterteilt sind: F. = MSR./ MSE.wo Msr \u003d.SSR. / k., MSE \u003d.Sens/(n.- k - 1), k - Die Anzahl der unabhängigen Variablen im Regressionsmodell. Teststatistik. F. Es hat F.-Distribution von S. k. und n. - K - 1 Freiheitsgrade.
Bei einem bestimmten Signifikanzniveau α wird die entscheidende Regel wie folgt formuliert: wenn F\u003e F. U., Nullhypothese weicht ab; Andernfalls weicht es nicht ab. Die in Form einer zusammenfassenden Tabelle der Dispersionsanalyse dekorierten Ergebnisse sind in Fig. 4 gezeigt. zwanzig.

Feige. 20. Dispersionstabelle zum Testen von Hypothese über statistische Signifikanz Rezessionskoeffizient
Ähnlich t.-Kriterien. F.-Kriterien wird in der Tabelle angezeigt, wenn Sie verwendet werden Paketanalyse (Möglichkeit Regression.). Vollständige Leistungsergebnisse. Paketanalyse In FIG. 4, Fragment im Zusammenhang mit F.-Statistik - in FIG. 21.

Feige. 21. Die Ergebnisse der Anwendung F.-Kriterien mit dem Excel-Analysepaket erhalten
F-Statistik sind 113,23 und r.-NOTION in der Nähe von Null (Zelle BedeutungF.). Wenn der Signifikanzniveau α 0,05 beträgt, bestimmen Sie den kritischen Wert F.Die Verteilung mit einem und 12 Grad der Freiheit kann die Formel verwenden Fu. \u003d F. produzieren (1-0,05; 1; 12) \u003d 4,7472 (Abb. 22). Soweit F. = 113,23 > Fu. \u003d 4,7472 und r.-Notion in der Nähe von 0< 0,05, нулевая гипотеза H 0. weicht ab, d. H. Die Größe des Ladens ist eng mit dem Jahresumsatz verbunden.

Feige. 22. Überprüfung der Hypothese über die Neigung der allgemeinen Bevölkerung auf einem Maß an Bedeutung, gleich 0,05, mit einem und 12 Grad Freiheit
Das Vertrauensintervall, das die Neigung von β 1 enthält. Um die Hypothese über das Vorhandensein einer linearen Beziehung zwischen Variablen zu testen, kann ein Vertrauensintervall, das die Neigung von β 1 enthält, aufgebaut und sicherstellen, dass der hypothetische Wert von β 1 \u003d 0 zu diesem Intervall gehört. Der Zentrum des Konfidenzintervalls, der die Steigung von β 1 enthält, ist der selektive Hang b. 1 und seine Grenzen - Werte b 1 ±t N. –2 S B. 1
Wie in FIG. achtzehn, b. 1 = +1,670, n. = 14, S B. 1 = 0,157. t. 12 \u003d Student. Prof (0.975; 12) \u003d 2.1788. Daher, b 1 ±t N. –2 S B. 1 \u003d +1,670 ± 2,1788 * 0,157 \u003d +1,670 ± 0,342 oder + 1,328 ≤ β 1 ≤ +2,012. Somit liegt die Steigung der allgemeinen Bevölkerung mit einer Wahrscheinlichkeit von 0,95 im Bereich von +1.328 bis +2.012 (d. H. Ab 1.268.000 bis 2.012.000 $). Da diese Mengen größer als Null sind, gibt es eine statistisch signifikante lineare Abhängigkeit zwischen dem jährlichen Verkaufsvolumen und dem Speicherbereich. Wenn das Vertrauensintervall Null enthielt, würde es keine Abhängigkeit zwischen den Variablen geben. Darüber hinaus bedeutet das Konfidenzintervall, dass jede Erhöhung des Geschäftsbereichs von 1.000 Quadratmetern ist. Füße führen zu einer Erhöhung des durchschnittlichen Umsatzes um den Wert von 1.328.000 bis 2.012.000 US-Dollar.
Verwendett. -Kriterien für den Korrelationskoeffizienten. Der Korrelationskoeffizient wurde eingeführt r.und ein Maß für die Beziehung zwischen zwei numerischen Variablen darstellen. Damit können Sie installieren, ob es statistisch zwischen zwei Variablen gibt signifikante Kommunikation. Bezeichnen den Korrelationskoeffizienten zwischen den allgemeinen Einstellungen beider Variablen mit dem Symbol ρ. Null- und alternative Hypothesen werden wie folgt formuliert: H 0.: ρ \u003d 0 (keine Korrelation), H 1.: ρ ≠ 0 (Es gibt eine Korrelation). Überprüfen der Existenz der Korrelation:

wo r. = + , wenn ein b. 1 > 0, r. = – , wenn ein b. 1 < 0. Тестовая статистика t. Es hat t.-Distribution von S. n - 2. Freiheitsgrade.
In der Aufgabe des Netzwerks speichert Sonnenblumen r 2. \u003d 0.904 und b 1.- +1.670 (siehe Abb. 4). Soweit b 1. \u003e 0, der Korrelationskoeffizient zwischen dem Jahresumsatz und der Größe des Ladens ist gleich r. \u003d + √0.904 \u003d +0,951. Überprüfen Sie die Nullhypothese, die argumentiert, dass zwischen diesen Variablen keine Korrelation zwischen diesen Variablen verwendet t.-Statistiken:

Auf der Ebene der Bedeutung sollte α \u003d 0,05 Nullhypothese zurückgewiesen werden, weil t. \u003d 10.64\u003e 2.1788. So kann argumentiert werden, dass zwischen dem Umsatzvolumen und der Größe des Ladens eine statistisch signifikante Verbindung besteht.
Bei der Erörterung der Schlussfolgerungen der Neigung der allgemeinen Bevölkerung sind Vertrauensintervalle und Kriterien zum Testen von Hypothesen austauschbare Werkzeuge. Die Berechnung des Konfidenzintervalls, der den Korrelationskoeffizienten enthält, ist jedoch komplexer, da die Art der selektiven Statistikverteilung r. Hängt vom wahren Korrelationskoeffizienten ab.
Bewertung der mathematischen Erwartung und Vorhersage der einzelnen Werte
Dieser Abschnitt diskutiert die Methoden zur Bewertung der mathematischen Erwartung der Antwort Y. und Vorhersagen der einzelnen Werte Y. Bei den angegebenen Werten der Variablen X..
Ein vertrauliches Intervall aufbauen.In Beispiel 2 (siehe oben Am wenigsten quadratische Methode.) regressionsgleichung. durfte den Wert der Variablen vorherzusagen Y. X.. In der Aufgabe, einen Platz für zu wählen handelspunkt. Der durchschnittliche jährliche Umsatz in einem 4000 Quadratmeter großen Laden. Die Füße betrug 7,644 Millionen US-Dollar. Diese Bewertung der mathematischen Erwartung der allgemeinen Bevölkerung ist jedoch ein Punkt. Um die mathematische Erwartung der allgemeinen Bevölkerung zu beurteilen, wurde das Konzept eines vertraulichen Intervalls vorgeschlagen. In ähnlicher Weise können Sie das Konzept eingeben vertrauensintervall für die Erwartung der mathematischen Antwort mit einem bestimmten variablen Wert X.:
wo  , =
b. 0
+
b. 1
X I. - vorhergesagte Wertvariable Y. zum X. = X I., S yx. - Radantenfehler, n. - Abtastvolumen. X. ICH. - der angegebene Wert der Variablen X., µ
Y.| X. =
X. ICH. - Mathematische Wartevariable Y. zum H. = X I., Ssx \u003d.
, =
b. 0
+
b. 1
X I. - vorhergesagte Wertvariable Y. zum X. = X I., S yx. - Radantenfehler, n. - Abtastvolumen. X. ICH. - der angegebene Wert der Variablen X., µ
Y.| X. =
X. ICH. - Mathematische Wartevariable Y. zum H. = X I., Ssx \u003d. 
Die Analyse der Formel (13) zeigt, dass die Breite des Konfidenzintervalls von mehreren Faktoren abhängt. Bei einem bestimmten Maß an Bedeutung führt das Erhöhen der Amplitude von Schwingungen um die Regressionslinie, die unter Verwendung des Standardfehlers gemessen wird, zu einer Erhöhung der Breite des Intervalls. Andererseits wird, wie erwartet, eine Erhöhung der Größe der Probe mit einer Verengung des Intervalls begleitet. Darüber hinaus variiert die Breite des Intervalls in Abhängigkeit von den Werten X. ICH.. Wenn der Wert der Variablen Y. voraussichtlich für die Größenordnung X.In der Nähe des Durchschnittswerts Das Konfidenzintervall ist bereits verfügbar als bei der Vorhersage der Antwort für Werte, die weit abschnittsweise sind.
Angenommen, durch die Wahl eines Ortes für den Laden möchten wir ein 95% Konfidenzintervall für den durchschnittlichen Jahresumsatz in allen Filialen aufbauen, deren Bereich 4000 m² ist. Fuß:

Daher der durchschnittliche Jahresumsatz in allen Filialen, deren Bereich 4000 Quadratmeter beträgt. Fuß mit einer Wahrscheinlichkeit von 95% liegt im Bereich von 6,971 bis 8,317 Mio. USD.
Berechnen des Konfidenzintervalls für den vorhergesagten Wert.Zusätzlich zum Vertrauensintervall für die mathematische Antwort mit einem bestimmten variablen Wert X.Es ist oft notwendig, das Konfidenzintervall für den vorhergesagten Wert zu kennen. Trotz der Tatsache, dass die Formel zur Berechnung eines solchen Konfidenzintervalls der Formel (13) sehr ähnlich ist, enthält dieses Intervall einen vorhergesagten Wert und keine Schätzung des Parameters. Intervall für die vorhergesagte Antwort Y. X. = Xi Mit einem bestimmten variablen Wert X. ICH. Bestimmt durch die Formel:

Angenommen,, dass wir, um einen Ort für einen Verkehrsort auszuwählen, wir möchten ein 95% -Konfidenzintervall für den vorhergesagten jährlichen Umsatz im Laden aufbauen, deren Bereich 4000 m² ist. Fuß:

Daher, vorausgesagte jährliche Verkäufe im Laden, dessen Bereich 4000 m² ist. M. Fuß, mit einer Wahrscheinlichkeit von 95% liegt im Bereich von 5,433 bis 9,854 Mio. USD. Wie wir sehen, ist das Vertrauensintervall für den vorhergesagten Antwortwert viel breiter als das Konfidenzintervall für seine mathematische Erwartung. Dies wird dadurch erläutert, dass die Variabilität bei der Vorhersage der einzelnen Werte viel größer ist als bei der Bewertung der mathematischen Erwartung.
Unterwassersteine \u200b\u200bund ethische Probleme, die mit der Regression verbunden sind
Schwierigkeiten, die mit der Regressionsanalyse verbunden sind:
- Ignorieren der Anwendungsbedingungen der Methode von mindestens Quadraten.
- Fehlerbewertung der Anwendungsbedingungen der Methode der kleinsten Quadrate.
- Falsche Auswahl alternativer Methoden zur Verletzung der Anwendungsbedingungen der Methode der kleinsten Quadrate.
- Anwendung der Regressionsanalyse ohne tiefes Wissen über das Thema der Studie.
- Extrapolation der Regression über den Bereich der Änderungen der Erläuterungsvariablen hinaus.
- Verwirrung zwischen statistischen und kausalen Abhängigkeiten.
Weit verbreitete Tabellenkalkulationen und software Für statistische Berechnungen beseitigte rechnerische Probleme, die die Anwendung der Regressionsanalyse verhinderten. Dies führte jedoch dazu, dass die Regressionsanalyse anfing, Benutzer anzuwenden, die keine ausreichenden Qualifikationen und Kenntnisse haben. Wie wissen Benutzer über alternative Methoden, wenn viele von ihnen nicht das geringste Konzept der Anwendungsbedingungen der Methode kleinster Quadrate haben und nicht wissen, wie sie ihre Ausführung überprüfen soll?
Der Forscher sollte nicht durch das Schleifen der Zahlen (Berechnung der Scherung, Neigung und dem gemischten Korrelationskoeffizienten nicht mitgetragen werden. Er braucht tieferes Wissen. Wir zeigen dies durch ein klassisches Beispiel aus Lehrbüchern. Ansky zeigte, dass alle vier Datensätze in FIG. 23 haben die gleichen Regressionsparameter (Abb. 24).

Feige. 23. Vier künstlicher Datensatz

Feige. 24. Regressionsanalyse von vier künstlichen Datensätzen; Mit Hilfe gemacht Paketanalyse(Klicken Sie auf das Bild, um das Bild zu vergrößern)
Aus Sicht der Regressionsanalyse sind alle diese Datensätze vollständig identisch. Wenn die Analyse auf diesem Ende war, würden wir viel verlieren nützliche Informationen. Dies wird durch die Streugsdiagramme (Abb. 25) und Restdiagramme (Abb. 26), die für diese Datensätze gebaut sind, belegt.

Feige. 25. Scatter-Diagramme für vier Datensätze
Diagramme der Streuung und Zeitpläne von Rückständen zeigen an, dass sich diese Daten voneinander unterscheiden. Das einzige Satz, der entlang der geraden Linie verteilt ist, ist ein Satz von A. Der Zeitplan von Rückständen, die von Set A berechnet werden, hat kein Muster. Dies kann nicht über die Sätze B, B und G gesagt werden. Der Streuplan, der auf einem Set B gebaut wurde, zeigt ein ausgesprochen quadratisches Modell. Diese Schlussfolgerung wird durch den Zeitplan der Rückstände mit einer parabolischen Form bestätigt. Das Streudiagramm und der Restzeitplan zeigen, dass die in enthaltenen Daten Emissionen enthalten. In dieser Situation ist es notwendig, die Emission aus einem Datensatz auszuschließen und die Analyse wiederholen zu können. Die Methode, die es ermöglicht, Emissionen von Beobachtungen zu erkennen und auszuschließen, wird als Analyse des Einflusses bezeichnet. Nach dem Ausschluss der Emission kann das Ergebnis der Wiederbewertung des Modells völlig anders sein. Das nach Daten aus einem Satz errichtete Streudiagramm zeigt eine ungewöhnliche Situation, in der das empirische Modell wesentlich von einer separaten Antwort abhängt ( X 8. = 19, Y. 8 \u003d 12.5). Solche Regressionsmodelle müssen besonders sorgfältig berechnet werden. Streuungs- und Rückstandspläne sind also ein äußerst notwendiges Instrument für die Regressionsanalyse und sollte ein integraler Bestandteil sein. Ohne sie verdient die Regressionsanalyse nicht das Vertrauen.

Feige. 26. Rückstände für vier Datensätze
So vermeiden Sie Unterwassersteine \u200b\u200bmit Regressionsanalyse:
- Analyse der möglichen Beziehung zwischen Variablen X. und Y. Beginnen Sie immer mit dem Bau des Streuungsdiagramms.
- Bevor Sie die Ergebnisse der Regressionsanalyse interpretieren, überprüfen Sie die Bedingungen ihrer Anwendbarkeit.
- Bauen Sie ein Diagramm der Abhängigkeit der Rückstände von einer unabhängigen Variablen auf. Dies bestimmt, wie das empirische Modell die Ergebnisse der Beobachtung erfüllt und die Dispersionsdispersion erfasst.
- Um die Annahme der normalen Fehlerverteilung zu überprüfen, verwenden Sie Histogramme, Diagramme "Kofferraum- und Blätter", Blockdiagramme und Diagramme der Normalverteilung.
- Wenn die Anwendbarkeitsbedingungen der Methode der kleinsten Quadrate nicht durchgeführt werden, verwenden Sie alternative Verfahren (z. B. ein quadratisches oder mehrere Regressionsmodell).
- Wenn die Anwendbarkeitsbedingungen der Methode der kleinsten Quadrate durchgeführt werden, ist es erforderlich, die Hypothese über die statistische Signifikanz der Regressionskoeffizienten zu testen und Vertrauensintervalle zu erstellen, die die mathematische Erwartung und den vorhergesagten Antwortwert enthalten.
- Vermeiden Sie das Vorhersagen der Werte der abhängigen Variablen außerhalb des Änderungsbereichs in einer unabhängigen Variablen.
- Denken Sie daran, dass statistische Abhängigkeiten nicht immer kausal sind. Denken Sie daran, dass die Korrelation zwischen Variablen keine kausalen Abhängigkeit zwischen ihnen bedeutet.
Zusammenfassung.Wie auf dem Strukturschema (Abb. 27) gezeigt, beschreibt ein Hinweis ein einfaches lineares Regressionsmodell, Bedingungen seiner Anwendbarkeit und Methoden zur Überprüfung dieser Bedingungen. Berücksichtigt t.-Kriterien, um die statistische Signifikanz der Neigung der Regression zu überprüfen. Um die Werte der abhängigen Variablen vorherzusagen, wurde ein Regressionsmodell verwendet. Das in Verbindung mit der Wahl des Ortes für den Handelspunkt, der die Abhängigkeit des jährlichen Umsatzvolumens aus dem Ladenbereich untersucht, wird untersucht. Mit den erhaltenen Informationen können Sie einen genaueren Ort für den Laden auswählen und seinen Jahresumsatz vorhersagen. Die folgenden Hinweise werden weiterhin die Regressionsanalyse diskutieren, und die Modelle der mehrfachen Regression werden ebenfalls berücksichtigt.

Feige. 27. Structural Scheme Hinweise
Die Materialien des Buches Levin et al. Statistiken für Manager. - M.: Williams, 2004. - mit. 792-872.
Wenn die abhängige Variable kategorisch ist, ist es erforderlich, eine logistische Regression anzuwenden.
Die Regressionsanalyse ist eine der gefragtesten Methoden der statistischen Forschung. Damit ist es möglich, den Einflussgrad unabhängiger Werte auf die abhängige Variable festzulegen. In der Funktionalität. Microsoft Excel. Es gibt Werkzeuge, die eine solche Art von Analyse durchführen konzipieren. Lassen Sie uns analysieren, dass sie sich selbst repräsentieren und wie man sie benutzt.
Anschließen eines Analysesäulens
Um jedoch eine Funktion zu verwenden, mit der Sie eine Regressionsanalyse durchführen können, müssen Sie zunächst das Analysepaket aktivieren. Nur dann erscheint die für dieses Verfahren erforderlichen Werkzeuge auf dem Exilband.
- Wechseln Sie in die Registerkarte "Datei".
- Gehen Sie zum Abschnitt "Parameter".
- Das Fenster Excel-Parameter wird geöffnet. Gehen Sie zu Unterabschnitt "HinzufügenStruktur".
- Am unteren Rand des Öffnungsfensters ordnen wir den Schalter in der Position "Control" an die Position "Excel Add-In" an, wenn sie sich in einer anderen Position befindet. Klicken Sie auf die Schaltfläche "GO".
- Geöffnetes Fenster, das auf Excel-Superstruktur zugänglich ist. Wir legen ein Tick auf das Element "Analysepaket". Klicken Sie auf die Schaltfläche "OK".

Wenn wir jetzt auf die Registerkarte "Daten" ziehen, sehen wir eine neue Schaltfläche in der Symbolleiste "Analyse", "Data Analysis" -Taste.

Arten der Regressionsanalyse
Es gibt verschiedene Arten von Regressionen:
- parabolisch;
- leistung;
- logarithmisch;
- exponentiell;
- indikativ;
- hyperbolisch;
- lineare Regression.
Wir werden mehr über die Umsetzung der letzten Art der Regressionsanalyse in Excele mehr sprechen.
Lineare Regression im Excel-Programm
Nachfolgend wird als Beispiel ein Tisch dargestellt, in dem die durchschnittliche tägliche Lufttemperatur auf der Straße und die Anzahl der Ladenkäufer für den entsprechenden Arbeitstag angegeben ist. Lassen Sie uns mit der Hilfe der Regressionsanalyse herausfinden, genau wie die Wetterbedingungen in Form von Lufttemperatur die Anwesenheit des Handelseinstituts beeinträchtigen können.
Die allgemeine Gleichung der Regression der linearen Spezies ist wie folgt: y \u003d A0 + A1x1 + ... + AKK. In dieser Formel bedeutet Y eine Variable, den Einfluss der Faktoren, auf die wir versuchen, zu erkunden. In unserem Fall ist dies die Anzahl der Käufer. Der Wert von x ist verschiedene Faktoren, die die Variable betreffen. Parameter A sind die Regression von Koeffizienten. Das heißt, sie bestimmen die Wichtigkeit eines bestimmten Faktors. Der Index K bezeichnet die Gesamtzahl dieser Faktoren.


Analyse der Ergebnisse der Analyse
Die Ergebnisse der Regressionsanalyse werden in Form einer Tabelle an dem in den Einstellungen angegebenen Ort angezeigt.

Einer der Hauptindikatoren ist R-Square. Es zeigt die Qualität des Modells an. In unserem Fall diesen Koeffizienten gleich 0,705 oder etwa 70,5%. Dies ist ein akzeptables Qualitätsniveau. Abhängigkeit von weniger als 0,5 ist schlecht.
Ein weiterer wichtiger Indikator befindet sich in der Zelle an der Kreuzung der Zeile "Y-Kreuzung" und der Spalte "Koeffizienten". Es zeigt an, welcher Wert in Y sein wird, und in unserem Fall ist dies die Anzahl der Käufer, wobei alle anderen Faktoren Null gleich sind. Diese Tabelle ist in dieser Tabelle 58.04.
Der Wert an der Kreuzung der Graf "Variable X1" und "Koeffizienten" zeigt den Abhängigkeit von Y von X. In unserem Fall ist es der Abhängigkeit der Anzahl der Kunden des Lagers auf der Temperatur. Der Koeffizient von 1,31 gilt als ziemlich hoher Indikator für den Einfluss.
Wie Sie sehen, mit der Hilfe microsoft-Programme Excel ist ziemlich einfach, um eine Tabelle der Regressionsanalyse herzustellen. Um jedoch mit den an der Austritt erzielten Daten zu arbeiten und ihre Essenz zu verstehen, kann nur eine vorbereitete Person in der Lage sein.
Wir freuen uns, dass Sie Ihnen helfen könnten, das Problem zu lösen.
Fragen Sie Ihre Frage in den Kommentaren, während Sie die Essenz des Problems im Detail spielen. Unsere Spezialisten werden versuchen, so schnell wie möglich zu antworten.
Wird dieser Artikel Ihnen helfen?
Mit der linearen Regressionsmethode können wir die direkte Linie beschreiben, die angemessenste Anzahl von bestellten Dampf (x, y). Die Gleichung für eine gerade Linie, die als lineare Gleichung bekannt ist, ist unten dargestellt:
ŷ - der erwartete Wert des angegebenen Werts x,
x ist eine unabhängige Variable,
a - Schneiden Sie die Y-Achse für eine gerade Linie an,
b - Neigung gerade Linie.
In der folgenden Abbildung ist dieses Konzept grafisch dargestellt:
Die obige Abbildung zeigt die von der Gleichung ŷ \u003d 2 + 0,5x beschriebene Linie. Das Segment an der Achse der Achse ist der Schnittpunkt der Achse der Achse; In unserem Fall beträgt A \u003d 2. Die Steigung der Linie B, das Verhältnis der Hebeleitung bis zur Länge der Linie ist 0,5. Eine positive Hang bedeutet, dass die Linie von links nach rechts erhebt. Wenn B \u003d 0, die horizontale Linie, was bedeutet, dass es keine Verbindung zwischen den abhängigen und unabhängigen Variablen gibt. Mit anderen Worten, die Änderung des Wertes x wirkt sich nicht auf den Wert von y aus.
Häufig verwirrt ŷ und y. Die Grafik zeigt 6 angeordnete Punktpaare und eine Zeile gemäß dieser Gleichung.
In dieser Figur zeigt einen Punkt, der einem angeordneten Paar X \u003d 2 und Y \u003d 4 entspricht, beachten Sie, dass der erwartete Wert von y in Übereinstimmung mit der Zeile, wenn h. \u003d 2 ist ŷ. Wir können dies mit der folgenden Gleichung bestätigen:
ŷ \u003d 2 + 0,5х \u003d 2 +0,5 (2) \u003d 3.
Wert u ist der tatsächliche Punkt, und der Wert ŷ ist der erwartete Wert von y lineargleichung Mit einem bestimmten Wert x.
Der nächste Schritt besteht darin, die lineare Gleichung zu bestimmen, das Maximum, das dem Satz von bestelltem Dampf entspricht, wir haben im vorherigen Artikel darüber gesprochen, wo die Form der Gleichung gemäß der Methode der kleinsten Quadrate bestimmt wurde.
Verwenden von Excel, um die lineare Regression zu bestimmen
Um das Regressionsanalyse-Tool für eingebettet in Excel zu verwenden, müssen Sie das Add-In aktivieren Analysepaket.. Sie können es finden, indem Sie auf die Registerkarte klicken Datei -\u003e Parameter(2007+), im Dialogfeld, das Dialogfeld angezeigt wird ParameterAufhebenauf die Registerkarte gehen ÜberstrukturenAuf dem Feld Steuerungwählen ÜberbauAufhebenund klicken GehenIn dem Fenster, das erscheint, legten wir ein Zecker gegenüber Analysepaket.zhmem. OK.
Auf der Registerkarte Datenin einer Gruppe Analyseeine neue Schaltfläche wird angezeigt Datenanalyse.
Um die Arbeit des Add-Ins zu demonstrieren, verwenden wir die Daten aus dem vorherigen Artikel, in denen der Typ und das Mädchen einen Tisch im Badezimmer teilen sollen. Geben Sie die Daten unseres Beispiels mit einem Bad in Säulen A und in einem sauberen Blatt ein.
Auf die Registerkarte gehen Daten,in einer Gruppe Analyseklicken Datenanalyse.In dem angezeigten Fenster Datenanalyse Wählen Regression., wie in der Abbildung gezeigt, und klicken Sie auf OK.
Installieren Sie die erforderlichen Regressionsparameter im Fenster Regression., wie es auf dem Bild dargestellt wird:
Klicken OK.Abbildung unten zeigt die erzielten Ergebnisse:
Diese Ergebnisse entsprechen denen, die wir von unabhängigem Rechnen im vorherigen Artikel erhalten haben.
Die Regressionsanalyse ist eine statistische Forschungsmethode, die die Abhängigkeit eines Parameters von einem oder mehreren unabhängigen Variablen zeigt. Der Antrag war schwierig, es in einer Compuscript-Ära zu verwenden, insbesondere wenn es um große Datenmengen ging. Heute lernen Sie, wie Sie in Excel in der Regression aufbauen können, können Sie komplexe statistische Aufgaben in einigen Minuten buchstäblich lösen. Unten sind dargestellt spezifische Beispiele aus dem Bereich der Wirtschaft.
Arten von Regression.
Dieses Konzept selbst wurde 1886 in die Mathematik Francis Galton eingeführt. Regression passiert:
- linear;
- parabolisch;
- leistung;
- exponentiell;
- hyperbolisch;
- indikativ;
- logarithmisch.
Beispiel 1.
Betrachten Sie die Aufgabe, die Abhängigkeit der Anzahl derjenigen zu bestimmen, die die Mitglieder des Teams aus dem durchschnittlichen Gehalt in 6 Industrieunternehmen gelöscht haben.
Eine Aufgabe. In den sechs Unternehmen analysierte der durchschnittliche monatliche Lohn und die Anzahl der Mitarbeiter, die auf eigene Anfrage aufhörten. In tabellarischer Form haben wir:
Für die Aufgabe, die Abhängigkeit von der Menge der Arbeiter zu bestimmen, die von dem durchschnittlichen Gehalt in 6 Unternehmen überwältigt wurde, hat das Regressionsmodell die Form der Gleichung y \u003d A0 + A1 × 1 + ... + AKXK, wobei XI-Beeinflussungsvariablen, AI - Regressionskoeffizienten, AK ist die Anzahl der Faktoren.
Für diese Aufgabe ist Y ein Indikator für diejenigen, die mit den Mitarbeitern gestritten sind, und der Beeinflussungsfaktor - das Gehalt, das x von X bezeichnet wird.
Verwenden der Funktionen des Tabellenprozessors "Excel"
Die Regressionsanalyse in Excel sollte der Anwendung an die vorhandenen Tabellendaten der eingebauten Funktionen vorausgehen. Für diese Zwecke ist es jedoch besser, ein sehr nützliches Superstruktur "Analysepaket" zu verwenden. Um es zu aktivieren, brauchen Sie:
- gehen Sie auf der Registerkarte Datei in den Abschnitt "Parameter".
- wählen Sie in dem öffnenden Fenster die Zeichenfolge "Superstructure" aus.
- klicken Sie unten auf die Schaltfläche "GO-Button" rechts neben der Zeile "Management";
- legen Sie neben dem Namen "Analysis Paket" ein an und bestätigen Sie Ihre Aktionen, indem Sie auf OK klicken.
Wenn alles korrekt gemacht wird, auf der rechten Seite der Registerkarte "Daten", über der Workstation "Excel", erscheint die gewünschte Taste.
Lineare Regression in Excel
Wenn Sie jetzt alle erforderlichen virtuellen Instrumente für die Umsetzung von ökonometrischen Berechnungen haben, können wir unsere Aufgabe lösen. Dafür:
- klicken Sie auf die Schaltfläche "Datenanalyse".
- klicken Sie in dem öffnenden Fenster auf die Schaltfläche "Regression".
- auf der darauf erscheinenden Registerkarte geben wir den Wertbereich für y (die Anzahl der aboolierten Angestellten) und für X (ihre Gehälter) ein.
- bestätigen Sie Ihre Aktionen, indem Sie die Taste "OK" drücken.
Infolgedessen füllt das Programm automatisch ein neues Blatt des Tabellenprozessors mit Regressionsanalysedaten aus. Beachten Sie! Excel hat die Fähigkeit, den Ort, den Sie für diesen Zweck bevorzugen, unabhängig voneinander zu fragen. Es kann beispielsweise das gleiche Blatt sein, in dem die Werte Y und X sind, oder sogar ein neues BuchSpeziell für das Speichern solcher Daten entwickelt.
Analyse der Regressionsergebnisse für R-Quadrat
IM Excel-Daten Die während der Verarbeitung des betrachteten Beispiels erhaltenen Beispiele sind:
Zunächst sollten Sie auf den Wert des R-Quadrats achten. Es ist der Bestimmungskoeffizient. IM dieses Beispiel R-Square \u003d 0,755 (75,5%), d. H. Die berechneten Parameter des Modells erklären die Beziehung zwischen den in Betracht gezogenen Parametern um 75,5%. Je höher der Wert des Bestimmungskoeffizienten, das ausgewählte Modell wird für eine bestimmte Aufgabe angemessen angesehen. Es wird angenommen, dass es die tatsächliche Situation korrekt beschreibt, wobei der Wert des R-Quadrats über 0,8 liegt. Wenn R-Quadrat TKR, dann wird die Hypothese der Belegschaft eines freien Mitglieds der linearen Gleichung abgelehnt.
Bei dem in Betracht gezogenen Problem, das für ein freies Mitglied unter Verwendung der "Excel" -Weroben verwendet wurde, wurde erhalten, dass t \u003d 169.20903 und p \u003d 2,89e-12, dh wir haben eine Nullwahrscheinlichkeit, dass die korrekte Hypothese der Unnachgiebigkeit eines freien Mitglied wird abgelehnt. Für den Koeffizienten an einem unbekannten T \u003d 5,79405 und p \u003d 0,001158. Mit anderen Worten, die Wahrscheinlichkeit, dass die korrekte Hypothese der Bedeutungszwecke des Koeffizienten auf ein Unbekanntes abgelehnt wird, beträgt 0,12%.
So kann argumentiert werden, dass die resultierende Gleichung der linearen Regression angemessen ist.
Aufgabe zur Durchführbarkeit des Kaufs eines Aktienpakets
Mehrere Regression in Excel wird mit dem gesamten "Datenanalyse-Tool" ausgeführt. Betrachten Sie eine bestimmte angewandte Aufgabe.
Die Verwaltungsgesellschaft "NNN" sollte sich für die Durchführbarkeit des Kaufs eines Anteils von 20% an MMM JSC entscheiden. Die Kosten des Pakets (SP) beträgt 70 Millionen US-Dollar. Spezialisten "NNN" erhoben Daten zu ähnlichen Transaktionen. Es wurde beschlossen, die Kosten eines Anteils an solchen Parametern in Millionen amerikanischer Dollars zu beurteilen, als:
- verbindlichkeiten (VK);
- volumen des Jahresumsatzes (VO);
- forderungen (VD);
- die Kosten des Anlagevermögens (SOUN).
Darüber hinaus wird die Abrechnung des Lohnunternehmens (v3 p) in Tausenden von US-Dollar verwendet.
Lösungswerkzeuge für einen Tabellenprozessor-Excel
Zunächst müssen Sie eine Tabelle mit Quelldaten erstellen. Es hat das folgende Formular:
- rufen Sie das Fenster "Datenanalyse" an.
- wählen Sie den Abschnitt "Regression" aus.
- im Fenster "Input Intervall Y" werden ein Bereich von Werten von abhängigen Variablen aus der Spalte G eingeführt;
- klicken Sie auf das Symbol mit einem roten Pfeil rechts neben dem Fenster "Innect Intervall X" und geben Sie den Bereich aller Werte aus säulen B, c, D, f.
Der Artikel "Neue Arbeitsliste" und klicken Sie auf "OK".
Analyse für diese Aufgabe erhalten.
Studie der Ergebnisse und der Schlussfolgerungen
"Sammeln Sie von den oben genannten abgerundeten Daten auf einem Blatt eines Tabellenprozessors Excel, der Regressionsgleichung:
SP \u003d 0,103 * SOF + 0.541 * VO - 0,031 * VK + 0,405 * VD + 0,691 * VZP - 265.844.
In einer vertrauter mathematischer Form kann es geschrieben werden als:
y \u003d 0,103 * x1 + 0,541 * x2 - 0.031 * x3 + 0,405 * x4 + 0,691 * x5 - 265,844
Daten für MMM JSC sind in der Tabelle dargestellt:
Sie ersetzen sie in die Regressionsgleichung, erhalten sie einen Wert von 64,72 Millionen US-Dollar. Dies bedeutet, dass die Anteile von MMM JSC nicht erworben werden sollten, da ihre Kosten von 70 Millionen US-Dollar ausreichend überschätzt werden.
Wie wir sehen, ließ die Verwendung des "Excel" -Antabellenprozessors und der Regressionsgleichungen es ermöglichen, eine angemessene Entscheidung über die Durchführbarkeit einer völlig spezifischen Transaktion anzunehmen.
Jetzt wissen Sie, welche Regression ist. Die oben diskutierten Excel-Beispiele helfen Ihnen, praktische Aufgaben aus dem Bereich der Ökonometrie zu lösen.
Das MS Excel-Paket ermöglicht den Bau einer linearen Regressionsgleichung der meisten der Arbeit sehr schnell. Es ist wichtig zu verstehen, wie Sie die erzielten Ergebnisse interpretieren können. Um ein Regressionsmodell aufzubauen, müssen Sie Service \\ Data-Analyse \\ Regression auswählen (in Excel 2007 Dieser Modus befindet sich in der Daten- / Datenanalyseeinheit / Regression). Dann werden die Ergebnisse in die Analyseeinheit kopiert.

Meiner Meinung nach ist Econometric als Student eine der angelegten Wissenschaften von allem, was ich in den Mauern meiner Universität kennengelernt habe. Damit ist es in der Tat, Sie können angewandte Aufgaben im gesamten Unternehmen lösen. Wie effektiv diese Lösungen sind - die dritte Frage. Die unterste Linie ist, dass der größte Teil des Wissens Theorie bleiben wird, aber Ökonometrie und Regressionsanalyse lohnt sich immer noch, mit besonderer Aufmerksamkeit zu studieren.
Was erklärt die Regression?
Bevor wir mit MS Excel-Funktionen fortfahren, so dass Sie diese Aufgaben lösen können, möchte ich Ihnen auf Ihren Fingern erklären, dass im Wesentlichen die Regressionsanalyse impliziert. Es ist also einfacher für Sie, die Prüfung zu ergreifen, und vor allem ist es interessanter, das Thema zu studieren.
Hoffen wir, dass Sie mit dem Konzept einer Funktion der Mathematik vertraut sind. Die Funktion ist die Beziehung von zwei Variablen. Wenn Sie eine Variable ändern, geschieht etwas auf der anderen Seite. Ändern Sie X, Änderungen y. Funktionen beschreiben verschiedene Gesetze. Wir können eine Funktion kennen, wir können beliebige Werte von X ersetzen und ansehen, wie y.
Es ist von großer Bedeutung, da Regression ein Versuch ist, mit Hilfe einer bestimmten Funktion auf den ersten Blick auf unsystematische und chaotische Prozesse zu erklären. So können Sie beispielsweise die Beziehung des Dollars und der Arbeitslosigkeit in Russland identifizieren.
Wenn dieses Muster erkannt wird, werden wir gemäß der Funktion, die wir während der Berechnungen erhalten haben, eine Prognose erstellen, die auf der N-Ohm-Dollarrate in Bezug auf den Rubel das Niveau der Arbeitslosigkeit sein wird.
Diese Beziehung wird als Korrelation bezeichnet. Die Regressionsanalyse beinhaltet die Berechnung des Korrelationskoeffizienten, der die Dichtheit der Beziehung zwischen den unter Berücksichtigung der Variablen (Dollarkurs und der Anzahl der Jobs) erklärt.
Dieser Koeffizient kann positiv und negativ sein. Seine Werte liegen im Bereich von -1 bis 1. Dementsprechend können wir eine hohe negative oder positive Korrelation beobachten. Wenn es positiv ist, folgt der Anstieg des Dollars und der Entstehung neuer Arbeitsplätze. Wenn es negativ ist, wird es einen Rückgang der Arbeitsplätze, um den Kurs zu steigern.
Regression ist mehrere Arten. Es kann linear, parabolisch, macht, exponentiell usw. sein Wir treffen die Wahl des Modells, je nachdem, welche Regression das speziell auf unseren Fall erfüllt, welches Modell so nahe wie möglich an unserem Korrelation ist. Betrachten Sie dies im Beispiel der Aufgabe und lösen Sie es in MS Excel.
Lineare Regression in MS Excel
Um lineare Regressionsprobleme zu lösen, benötigen Sie eine Funktion "Datenanalyse". Es kann nicht mit Ihnen enthalten sein, damit Sie es aktivieren müssen.
- Klicken Sie auf die Schaltfläche "Datei".
- Wählen Sie den Artikel "Parameter" aus.
- Klicken Sie auf die vorletzte Registerkarte des "Superstructure" auf der linken Seite.
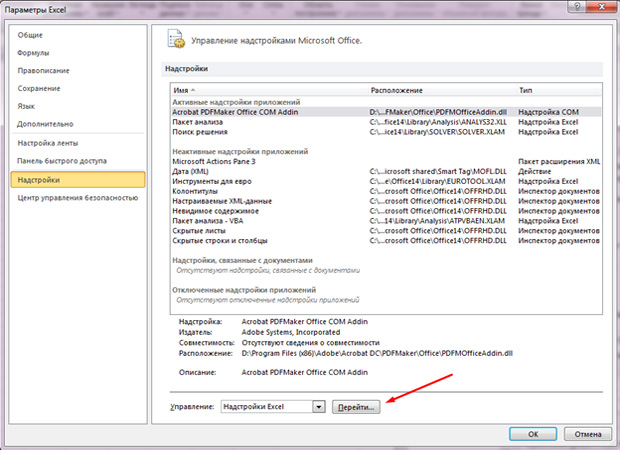
- Von unten sehen Sie die Inschrift "Management" und "GO" -Taste. Klick es an;
- Zecke ein Tick auf das "Analysepaket";
- OK klicken".

Beispiel für die Aufgabe
Die Batch-Analyse-Funktion ist aktiviert. Lassen Sie die folgende Aufgabe. Wir haben ein Beispiel für mehrere Jahre über die Anzahl der PE im Unternehmen und die Anzahl der Beschäftigten. Wir müssen die Beziehung zwischen diesen beiden Variablen erkennen. Es gibt eine erläuternde Variable X - Dies ist die Anzahl der Arbeiter und die erläuternde Variable - y ist die Anzahl der Notfälle. Ich verteile die Quelldaten in zwei Säulen.
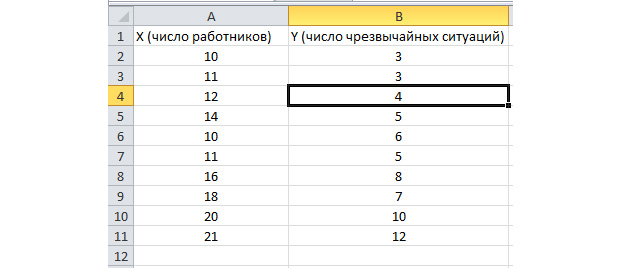
Gehen wir auf die Registerkarte "Daten" und wählen Sie "Datenanalyse".
Wählen Sie in der angegebenen Liste "Regression" aus. Wählen Sie in den Eingangsintervallen Y und X die entsprechenden Werte aus.
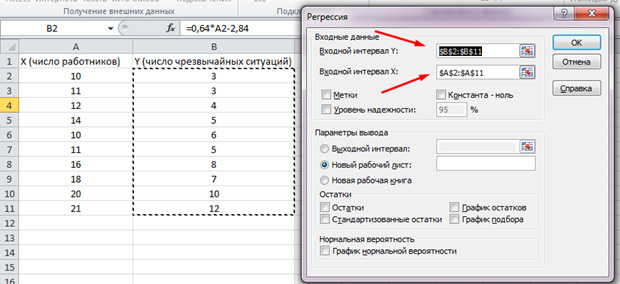
OK klicken". Die Analyse wird hergestellt, und in einem neuen Blatt sehen wir die Ergebnisse.
Die wichtigsten Werte für uns sind in der folgenden Abbildung markiert.
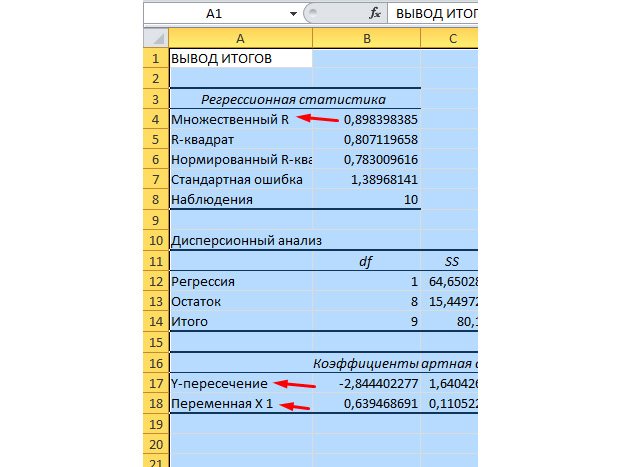
Mehrere R ist der Bestimmungskoeffizient. Es verfügt über eine komplexe Berechnungsformel und zeigt, wie er unseren Korrelationskoeffizienten vertrauen kann. Denin mehr, desto mehr dieser Wert, desto mehr Vertrauen, desto stärker ist unser Modell als Ganzes.
Y-Kreuzung und Kreuzung X1 sind die Koeffizienten unserer Regression. Wie bereits erwähnt, ist Regression eine Funktion, und sie hat bestimmte Koeffizienten. Somit wird unsere Funktion ansehen: y \u003d 0,64 * x-2.84.
Was gibt uns das? Dies gibt uns die Möglichkeit, eine Prognose zu erstellen. Angenommen, wir möchten 25 Arbeiter auf dem Unternehmen einstellen, und wir müssen uns annähernd vorstellen, wie die Anzahl der Notfälle sein wird. Wir ersetzen diesen Wert auf unsere Funktion und wir erhalten das Ergebnis y \u003d 0,64 * 25 - 2.84. Etwa 13 PP werden wir auftreten.
Mal sehen, wie es funktioniert. Schauen Sie sich die untenstehende Zeichnung an. In den tatsächlichen Werten der beteiligten Mitarbeiter werden die sachlichen Werte ersetzt. Sehen, wie nah an echten Akteuren an Bedeutung ist.

Sie können das Korrelationsfeld auch aufbauen, indem Sie den IPVENTION- und ICS-Bereich auswählen, indem Sie auf die Registerkarte "Einfügen" klicken und ein Punktdiagramm auswählen.

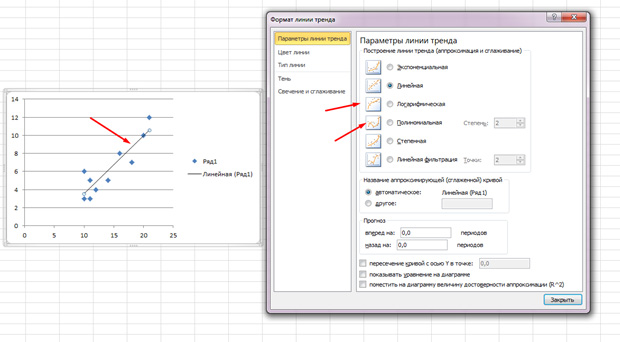
Die Punkte gehen in die Ecke, steigen aber im Allgemeinen auf, als ob die Linie in der Mitte liegt. Sie können diese Zeile auch hinzufügen, indem Sie in MS Excel auf die Registerkarte "Layout" klicken und die Trendzeilenelemente auswählen
Klicken Sie zweimal auf der angegebenen Linie, die erscheint, und sehen Sie, was zuvor angegeben wurde. Sie können die Art der Regression ändern, je nachdem, wie Ihr Korrelationsfeld aussieht.
Vielleicht scheint es Ihnen, dass die Punkte einen Parabola ziehen, und keine direkte Linie und Sie angemessen, um eine andere Art von Regression zu wählen.
Fazit
Hoffen wir, dass dieser Artikel Ihnen ein größeres Verständnis dafür hat, welche Regressionsanalyse ist und für das, was es benötigt wird. All dies hat einen großen Anwendungswert.
IM Aufheben Es gibt noch eine schnellere und bequemere Möglichkeit, einen linearen Regressionsplan (und sogar die Haupttypen der nichtlinearen Regressionen, als cm. Nächstes) aufzubauen. Dies kann wie folgt durchgeführt werden:
1) Zuordnen von Spalten mit Daten X. und Y. (Sie sollten sich in dieser Reihenfolge befinden!);
2) Anruf Master-Chart und wählen Sie in einer Gruppe Eine Art – Pagle Und sofort drücken Bereit;
3) Wenn Sie die Auswahl aus dem Diagramm aus dem Diagramm ablegen, wählen Sie den ersten Elementelement aus, das angezeigt wird Diagrammin dem Sie den Artikel auswählen sollten Trendlinie hinzufügen;
4) Im Dialogfeld, das Dialogfeld angezeigt wird Trendlinie Auf der Registerkarte Eine Artwählen Linear;
5) Auf der Registerkarte Parametersie können den Switch aktivieren Zeigen Sie die Gleichung auf dem DiagrammDies ermöglicht es, die lineare Regressionsgleichung (4.4) zu sehen, in der die Koeffizienten (4.5) berechnet werden.
6) In derselben Registerkarte können Sie den Schalter aktivieren Platzieren Sie den Wert der Genauigkeit der Annäherung (R ^ 2) im Diagramm (R ^ 2). Diese Größe ist das Quadrat des Korrelationskoeffizienten (4.3) und es zeigt, wie gut die berechnete Gleichung experimentelle Abhängigkeit beschreibt. Wenn ein R. 2 sind nahe an der Einheit, dann beschreibt die theoretische Regressionsgleichung eine gut experimentelle Abhängigkeit (die Theorie ist mit dem Experiment gut vereinbart) und wenn R. 2 in der Nähe von Null, dann diese Gleichung. Nicht geeignet für die Beschreibung experimenteller Abhängigkeiten (die Theorie ist nicht mit dem Experiment überein).
Infolge der Ausführung der beschriebenen Aktionen wird ein Diagramm mit Regressionszeitplan und seiner Gleichung erhalten.
§4.3. Hauptarten nichtlineare Regression.
Parabol- und Polynomregression.
Parabolisch Die Abhängigkeit der Größe Y. von der Größenordnung H. Die Abhängigkeit wird als quadratische Funktion bezeichnet (2. Ordnung Parabola):
Diese Gleichung wird aufgerufen die Gleichung der parabolischen Regression y auf der H.. Parameter aber, b., von namens koeffizienten der parabolischen Regression. Die Berechnung der parabolischen Regressionskoeffizienten ist immer umständlich, daher wird empfohlen, einen Computer für Berechnungen zu verwenden.
Gleichung (4.8) der parabolischen Regression ist ein Sonderfall einer allgemeineren Regression, das als Polynom genannt wird. Polynom Die Abhängigkeit der Größe Y. von der Größenordnung H. wird als Abhängigkeit genannt, ausgedrückt durch Polynom n.Auftrag:
wo Zahlen ein I. (iCH.=0,1,…, n.) Namens koeffizienten der Polynomregression.
Stromregression.
Leistung Die Abhängigkeit der Größe Y. von der Größenordnung H. Die Abhängigkeit des Formulars wird aufgerufen:
Diese Gleichung wird aufgerufen gleichung der Stromregression y auf der H.. Parameter aber und b. namens koeffizienten der Stromregression.
ln \u003d ln. eIN.+b ·ln. x.. (4.11)
Diese Gleichung beschreibt die direkte in der Ebene mit den logarithmischen Koordinatenachsen von LN x. und ln. Daher ist das Kriterium für die Anwendbarkeit der Stromregression die Anforderung, dass die Punkte von Logarithmen der empirischen Daten ln x I. und ln. iCH. Sie waren der Linie am nächsten (4.11).
Indikative Regression.
Indikativ(oder exponentiell) Die Abhängigkeit der Größe Y. von der Größenordnung H. Die Abhängigkeit des Formulars wird aufgerufen:
(oder ). (4.12)
Diese Gleichung wird aufgerufen die Gleichung ist indikativ (oder exponentiell) regression Y. auf der H.. Parameter aber (oder k.) ICH. b. namens bekämpfungskoeffizienten (oder exponentiell) regression..
Wenn beide Teile der Stromregressionsgleichung prologiert werden, wird die Gleichung sein
ln \u003d. x ·ln. eIN.+ Ln. b. (oder ln \u003d k · X.+ Ln. b.). (4.13)
Diese Gleichung beschreibt die lineare Abhängigkeit des Logarithmus eines einzelnen LN-Werts von einem anderen Wert. x.. Daher ist das Kriterium für die Anwendbarkeit der Stromregression die Anforderung, dass die Punkte der empirischen Daten derselben Größes x I. Und die Logarithmen einer anderen LN-Größenordnung iCH. Sie waren direkterseitig (4.13) am nächsten.
Logarithmische Regression.
Logarithmischdie Abhängigkeit der Größe Y. von der Größenordnung H. Die Abhängigkeit des Formulars wird aufgerufen:
=eIN.+b ·ln. x.. (4.14)
Diese Gleichung wird aufgerufen die Gleichung der logarithmischen Regression y auf der H.. Parameter aber und b. namens koeffizienten logarithmischer Regression.
Hyperbolische Regression.
Hyperbolisch Die Abhängigkeit der Größe Y. von der Größenordnung H. Die Abhängigkeit des Formulars wird aufgerufen:
Diese Gleichung wird aufgerufen die Gleichung der hyperbolischen Regression y auf der H.. Parameter aber und b. namens die Koeffizienten der hyperbolischen Regression und werden durch das Verfahren kleinster Quadrate bestimmt. Die Verwendung dieser Methode führt zu Formeln:
In den Formeln (4.16-4.17) erfolgt die Summation durch Index iCH. von einem bis zur Anzahl der Beobachtungen n..
Leider in. Aufheben Es gibt keine Funktionen, die die Koeffizienten der hyperbolischen Regression berechnen. In Fällen, in denen nicht bekannt ist, dass die Messwerte mit inversen Proportionalität verbunden sind, wird er anstelle der hyperbolischen Regressionsgleichung empfohlen, um die Stromregressionsgleichung zu suchen, also in Aufheben Es gibt ein Verfahren für seinen Standort. Wenn eine hyperbolische Abhängigkeit zwischen den Messwerten angenommen wird, müssen seine Regressionskoeffizienten unter Verwendung der Hilfsberechnungstabellen und Summationsvorgänge gemäß den Formeln (4.16-4.17) berechnet werden.