XYZ-Analyse - Variationskoeffizient - Vorbereitung der Daten für die Vorhersage.
Wir müssen uns mit der Berechnung von Werten wie Varianz, Standardabweichung und natürlich dem Variationskoeffizienten befassen. Es ist der Berechnung des letzteren besondere Aufmerksamkeit zu widmen. Es ist sehr wichtig, dass jeder Neuling, der gerade erst anfängt, mit ihm zu arbeiten tabelleneditor, könnte schnell die relative Streuungsgrenze von Werten berechnen.
Was ist der Variationskoeffizient und wofür ist er?
Es erscheint mir daher sinnvoll, eine kleine theoretische Exkursion zu machen und die Natur des Variationskoeffizienten zu verstehen. Dieser Indikator ist erforderlich, um den Datenbereich im Verhältnis zum Durchschnittswert wiederzugeben. Mit anderen Worten zeigt es das Verhältnis der Standardabweichung zum Mittelwert. Es ist üblich, den Variationskoeffizienten in Prozent zu messen und damit die Homogenität der Zeitreihen anzuzeigen.
Der Variationskoeffizient wird zu einem unverzichtbaren Werkzeug, wenn Sie eine Prognose mit Daten aus einer bestimmten Stichprobe erstellen müssen. Dieser Indikator hebt die Hauptreihe von Werten hervor, die für die nachfolgende Vorhersage am nützlichsten sind, und löscht die Stichprobe der unwesentlichen Faktoren. Wenn Sie also sehen, dass der Wert des Koeffizienten 0% beträgt, geben Sie mit Sicherheit an, dass die Reihe homogen ist, was bedeutet, dass alle darin enthaltenen Werte gleich sind. Wenn der Variationskoeffizient einen Wert über der 33% -Marke annimmt, deutet dies darauf hin, dass es sich um eine heterogene Reihe handelt, bei der sich die einzelnen Werte erheblich von der durchschnittlichen Abtastrate unterscheiden.
Wie finde ich die Standardabweichung?
Da wir zur Berechnung des Variationsindex in Excel die Standardabweichung verwenden müssen, ist es angebracht, herauszufinden, wie wir diesen Parameter berechnen.
Aus dem Schulalgebra-Kurs wissen wir, dass die Standardabweichung die aus der Varianz extrahierte Quadratwurzel ist, dh dieser Indikator bestimmt den Grad der Abweichung eines bestimmten Indikators der Gesamtstichprobe von seinem Durchschnittswert. Damit können wir das absolute Maß der Schwingung des untersuchten Merkmals messen und es klar interpretieren.
Berechnen Sie den Koeffizienten in Excel
Leider enthält Excel keine Standardformel, mit der der Variationsindex automatisch berechnet werden kann. Dies bedeutet jedoch nicht, dass Sie Berechnungen in Ihrem Kopf durchführen müssen. Das Fehlen einer Vorlage in der Formelleiste beeinträchtigt in keiner Weise die Funktionen von Excel. Sie können das Programm also auf einfache Weise zwingen, die erforderliche Berechnung durchzuführen, indem Sie den entsprechenden Befehl manuell eingeben.

Um den Variationsindex in Excel zu berechnen, muss der Mathematikkurs der Schule abgerufen und die Standardabweichung durch den Mittelwert der Stichprobe dividiert werden. In der Praxis lautet die Formel also wie folgt: STANDOWCLONE (angegebener Datenbereich) / AVERAGE (angegebener Datenbereich). Sie müssen diese Formel darin eingeben excel-Zellein dem Sie die Berechnung erhalten möchten, die Sie benötigen.
Vergessen Sie nicht, dass die Zelle mit der Formel das entsprechende Format festlegen muss, da der Koeffizient in Prozent angegeben wird. Sie können dies wie folgt tun:
- Öffnen Sie die Registerkarte Startseite.
- Suchen Sie darin die Kategorie „Format of cells“ und wählen Sie den erforderlichen Parameter aus.
Alternativ können Sie das Prozentformat einer Zelle festlegen, indem Sie auf klicken rechte taste Maus auf die aktivierte Zelltabelle. In der erschienen kontextmenüÄhnlich wie beim obigen Algorithmus müssen Sie die Kategorie „Zellenformat“ auswählen und den erforderlichen Wert festlegen.

Wählen Sie "Prozent" und geben Sie bei Bedarf die Anzahl der Nachkommastellen an.
Vielleicht scheint jemand den obigen Algorithmus schwierig. Tatsächlich ist die Berechnung des Koeffizienten so einfach wie die Addition zweier natürlicher Zahlen. Sobald Sie diese Aufgabe in Excel abgeschlossen haben, kehren Sie nie mehr zu den langwierigen, komplexen Entscheidungen im Notizbuch zurück.
Können Sie den Grad der Datenstreuung noch nicht qualitativ vergleichen? Sampling verloren? Dann machen Sie sich gleich an die Arbeit und setzen Sie das oben beschriebene theoretische Material in die Praxis um! Lassen Sie die statistische Analyse und Entwicklung der Prognose nicht mehr zu Ängsten und Negativitäten führen. Sparen Sie Zeit und Energie mit
Aus diesem Artikel lernen Sie:
- ;
- Wie macht man XYZ-Analyse in Excel;
- Anwendung XYZ-Analyse bei der Datenvorbereitung für die Prognose.
So berechnen Sie den Variationskoeffizienten in Excel
Dies ist ein Indikator, der die Variation der Werte relativ zum Mittelwert (das Verhältnis der Standardabweichung zum Mittelwert) widerspiegelt. Der Variationskoeffizient wird in Prozent gemessen und spiegelt die Homogenität der Zeitreihen wider.
Der Variationskoeffizient ist ein ausgezeichneter Indikator, der Ihnen bei der Vorbereitung der Daten für die Prognose hilft. Der Variationskoeffizient ist ein Indikator, der Ihnen hilft, die Zeilen zu identifizieren, auf die Sie achten sollten, bevor Sie die Prognose berechnen und Daten aus Zufallsfaktoren löschen.
Wenn der Koeffizient 0% ist, ist die Reihe absolut gleichmäßig, d.h. Alle Werte sind gleich.
Wenn der Variationskoeffizient mehr als 33% beträgt, wird die Reihe nach der klassischen Theorie als ungleichmäßig angesehen, d.h. große Streuung der Daten relativ zum Mittelwert.
Zum Beispiel:
|
Einheitliche Reihe |
||||
|
Heterogene Reihe |
So berechnen Sie den Variationskoeffizienten in Excel
Variationskoeffizient = Verhältnis von Standardabweichung zu Mittelwert
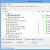
In Excel der Variationskoeffizient kann nach folgender Formel berechnet werden:
- STANDOCLONPA (J6: M6) - Formel zur Berechnung der Standardabweichung in Excel für den analysierten Zeitraum;
- (SUMME (J6: M6) / ZÄHLER (J6: M6; "\u003e 0")) - der Durchschnitt für den analysierten Zeitraum;
Geben Sie die Formel in die Zelle ein, wir erhalten die Berechnung des Variationskoeffizienten

Wir dehnen die Formel auf das gesamte Datenfeld aus.
Wie mache ich eine XYZ-Analyse?
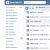
Nun segmentieren wir unsere Variationskoeffizienten und ordnen jedem der 3 Buchstaben X Y und Z zu
- X - für Reihen mit einem Variationskoeffizienten von 0% bis 10%
- Y - für Serien mit einem Variationskoeffizienten von 10% bis 25%
- Z - für Reihen mit einem Variationskoeffizienten von 25% und mehr
Geben Sie in die Excel-Zelle die Formel ein
IF (N3<=0,1;"X";ЕСЛИ(N3<=0,25;"Y";"Z"))

Anwendung der XYZ-Analyse bei der Datenaufbereitung für die Prognose
Wenn Sie beim Vorbereiten von Daten für eine Prognose mit einer großen Datenmenge arbeiten, ist ein Indikator erforderlich, der angibt, auf welche Zeitreihen Sie zuerst achten sollten. Als Indikator können Sie den "Variationskoeffizienten" oder die XYZ-Analyse verwenden.
Wenn der Variationskoeffizient größer als 10 - 25% ist oder für die Y- und Z-ReiheAnschließend untersuchen wir die Daten (z. B. Warenverkäufe nach Monaten im Kontext der Verkaufsrichtungen) und ermitteln die Faktoren, die die Abweichung beeinflussten.
Fügen Sie der XYZ-Spaltenanalyse einen Filter hinzu und analysieren Sie die Zeilen.
Zuerst filtern wir die Zeilen mit einem Variationskoeffizienten von mehr als 25% oder Z

Wir untersuchen Serien mit großen Abweichungen der tatsächlichen Daten der letzten 4-5 Monate. Ermitteln Sie die Ursachen für Ausfälle oder einen starken Umsatzanstieg. Daten für die Prognose vorbereiten. Wir bereinigen die Daten vom Einfluss zufälliger Faktoren oder korrigieren das Defizit.
Wenn die Serie eine große Heterogenität aufweist, ist es sinnvoll, die Zeitreihen zu gruppieren. Zum Beispiel
- Uneinheitliche Umsätze pro Monat summieren sich zu Umsätzen pro Quartal.
- Wöchentliche Verkäufe summieren sich zu monatlichen Verkäufen,
- Umsatz nach Produktgruppen aufrollen ...
Machen Sie eine Prognose für eine homogene Gruppe einer höheren Ebene und verteilen Sie sie dann proportional zur Logik innerhalb der Gruppe.
Wählen Sie dann die Zeilen mit dem Variationskoeffizienten Y aus

In ähnlicher Weise durchsuchen wir jede Zeile. Wenn Sie ein ungewöhnliches Verhalten der Serie feststellen, ermitteln Sie die Ursachen und löschen Sie die Daten, falls erforderlich.
Wir empfehlen, eine Liste von Faktoren zu erstellen (z. B. Werbeaktionen für Verkaufsförderung, Warenmangel, Sonderkunden ...) und für jeden der Faktoren einen Indikator zu bestimmen, den wir subtrahieren oder zu den Daten für die Prognose hinzufügen.
Sobald die Daten von Faktoren gelöscht sind, die sich in der zukunft nicht wiederholen und für die prognose vorbereitet sind, berechnen wir die umsatzprognose.




Anweisung
Verwenden Sie die folgende Formel, um den Variationskoeffizienten zu ermitteln:
V = σ / Хср, wobei
σ - mittlere quadratische Abweichung
Хср - arithmetischer Durchschnitt der Variationsreihe.
Es ist zu beachten, dass der Variationskoeffizient in der Praxis nicht nur zur vergleichenden Bewertung von Variationen verwendet wird, sondern auch zur Charakterisierung der Homogenität der Population. Wenn dieser Indikator 0,333 oder 33,3% nicht überschreitet, wird die Variation des Merkmals als schwach und bei mehr als 0,333 als stark angesehen. Im Falle einer starken Abweichung wird das untersuchte statistische Aggregat als nicht einheitlich angesehen, und der Durchschnittswert ist nicht typisch, daher kann er nicht als verallgemeinerter Indikator für dieses Aggregat verwendet werden. Die Untergrenze des Variationskoeffizienten ist Null, die Obergrenze existiert nicht. Mit zunehmender Variation des Merkmals steigt jedoch auch sein Wert.
Bei der Berechnung des Variationskoeffizienten müssen Sie die Standardabweichung verwenden. Es ist definiert als die Quadratwurzel der Varianz, die sich wiederum wie folgt ergibt: D = Σ (X-Xsr) ^ 2 / N. Varianz ist also das mittlere Quadrat der Abweichung vom arithmetischen Mittelwert. Die Standardabweichung bestimmt, inwieweit bestimmte Indikatoren der Reihe von ihrem Durchschnittswert abweichen. Es ist ein absolutes Maß für die Variabilität der Merkmale und wird daher klar interpretiert.
Betrachten Sie das Beispiel zur Berechnung des Variationskoeffizienten. Der Rohstoffverbrauch pro Produktionseinheit der ersten Technologie beträgt Xsr = 10 kg mit einer durchschnittlichen Standardabweichung von σ1 = 4 gemäß der zweiten Technologie - Xsr = 6 kg mit σ2 = 3. Beim Vergleich der Standardabweichung können wir die falsche Schlussfolgerung ziehen dass die Schwankungen beim Verbrauch von Rohstoffen bei der ersten Technologie stärker sind als bei der zweiten. Die Variationskoeffizienten V1 = 0,4 oder 40% und V2 = 0,5 oder 50% lassen den gegenteiligen Schluss zu.
Relativ indikatoren sollen die Intensität der Änderungen charakterisieren, die in der gemessenen Größe stattfinden. Um sie zu finden, müssen die absoluten Werte mindestens an zwei Messpunkten bekannt sein - zum Beispiel an zwei Punkten der Zeitskala. Daher relativ indikatoren werden in Bezug auf das Absolute als zweitrangig angesehen, aber ohne sie ist es schwierig, das Gesamtbild der Änderungen zu beurteilen, die mit dem gemessenen Parameter auftreten.
Anweisung
Teilen Sie einen absoluten Indikator durch einen anderen, um den Wert eines relativen Indikators zu erhalten, der die aufgetretenen Änderungen der absoluten Indikatoren kennzeichnet. Der absolute Wert sollte in den Zähler eingegeben werden, der aktuell (oder "vergleichbar") ist, und der Nenner sollte ein absoluter Indikator sein, mit dem der aktuelle Wert verglichen wird - er wird als "Basis" oder "Vergleichsbasis" bezeichnet. Das Ergebnis der Division (dh der relative Indikator) gibt an, wie oft der aktuelle absolute Indikator größer als die Basislinie ist oder wie viele Einheiten des aktuellen Werts auf jede Einheit der Basislinie fallen.
Wenn die verglichenen absoluten Werte die gleichen Maßeinheiten haben (z. B. die Anzahl der erzeugten Haubitzen), wird die relative Zahl, die sich aus den Berechnungen ergibt, normalerweise als Prozentsatz, ppm, Promillille oder in Koeffizienten ausgedrückt. In den Koeffizienten wird der relative Indikator für den Fall ausgedrückt, dass der absolute Basisindikator gleich eins ist. Wenn eine Einheit durch Hundert ersetzt wird, wird der relative Indikator als Prozentsatz ausgedrückt, wenn mit einer Million, in ppm und wenn mit zehn Millionen, in Prod-Million. Beim Vergleich zweier Größen mit unterschiedlichen Maßeinheiten (z. B. Haubitzen und Bevölkerung eines Landes) wird der resultierende relative Indikator in benannten Werten (z. B. Haubitzen pro Kopf) ausgedrückt.
In der Statistik ist es häufig erforderlich, bei der Analyse eines Phänomens oder eines Prozesses nicht nur Informationen über die Durchschnittswerte der untersuchten Parameter zu berücksichtigen, sondern auch Informationen über die Durchschnittswerte der untersuchten Parameter streuung oder Variation der Werte einzelner Einheiten Dies ist ein wichtiges Merkmal der untersuchten Bevölkerung.
Aktienkurse, Angebots- und Nachfragemengen, Zinssätze in verschiedenen Zeiträumen und an verschiedenen Orten unterliegen den größten Schwankungen.
Die wichtigsten Variationsindikatoren sind der Bereich, die Varianz, die Standardabweichung und der Variationskoeffizient.
Variationsbreite ist die Differenz zwischen den Maximal- und Minimalwerten des Merkmals: R = Xmax - Xmin. Der Nachteil dieses Indikators besteht darin, dass er nur die Variationsgrenzen des Merkmals schätzt und seine Variabilität innerhalb dieser Grenzen nicht widerspiegelt.
Dispersion ohne diesen Nachteil. Es wird berechnet als das durchschnittliche Quadrat der Abweichungen der charakteristischen Werte von ihrem Durchschnittswert:
Vereinfachte Methode zur Berechnung der Varianz unter Verwendung der folgenden Formeln (einfach und gewichtet):
Beispiele für die Anwendung dieser Formeln sind in Aufgabe 1 und 2 aufgeführt.
Ein gängiger Indikator in der Praxis ist standardabweichung :
Die Standardabweichung wird als Quadratwurzel der Varianz definiert und hat die gleiche Dimension wie das zu untersuchende Merkmal.
Die betrachteten Indikatoren erlauben es, den absoluten Wert der Variation zu erhalten, d.h. werte es in Einheiten des untersuchten Merkmals aus. Im Gegensatz zu ihnen, variationskoeffizient misst die relative Variabilität im Verhältnis zum Durchschnittsniveau, was in vielen Fällen vorzuziehen ist.
Die Formel zur Berechnung des Variationskoeffizienten.
Beispiele zur Problemlösung zum Thema "Indikatoren für Variationen in der Statistik"
Aufgabe 1 . Bei der Untersuchung des Einflusses der Werbung auf die Höhe des durchschnittlichen monatlichen Beitrags in den Banken der Region wurden 2 Banken befragt. Die folgenden Ergebnisse wurden erhalten:
Definieren:
1) für jede Bank: a) die durchschnittliche Höhe der Einzahlung für den Monat; b) die Varianz des Beitrags;
2) die durchschnittliche monatliche Einzahlung für zwei Banken zusammen;
3) Die Varianz der Einzahlung für 2 Banken, abhängig von der Werbung;
4) Varianz der Einlage für 2 Banken, abhängig von allen Faktoren, außer Werbung;
5) Gesamtvarianz unter Verwendung der Additionsregel;
6) Bestimmungskoeffizient;
7) Korrelationsverhältnis.
Lösung
1) Erstellen Sie einen Tisch für die Bank mit Werbung . Um die durchschnittliche Höhe der Einzahlung für den Monat zu bestimmen, finden wir die Mitte der Intervalle. In diesem Fall ist der Wert des offenen Intervalls (das erste) herkömmlicherweise gleich dem Intervall dazwischen (das zweite).
Die durchschnittliche Größe des Beitrags ergibt sich aus der Formel des gewichteten arithmetischen Durchschnitts:
29 000/50 = 580 Rubel.
Die Varianz des Beitrags ergibt sich aus der Formel:
23 400/50 = 468
Ähnliche Aktionen werden produzieren für Bank ohne Werbung :
2) Ermitteln Sie die durchschnittliche Höhe der Einlage für beide Banken zusammen. Xav = (580 × 50 + 542,8 × 50) / 100 = 561,4 Rubel.
3) Die Varianz der Einlage für zwei Banken ergibt sich je nach Werbung aus der Formel: σ 2 = pq (die Formel für die Streuung eines alternativen Merkmals). Hier ist p = 0,5 der Anteil werbeabhängiger Faktoren; q = 1–0,5, dann σ 2 = 0,5 × 0,5 = 0,25.
4) Da der Anteil der übrigen Faktoren 0,5 beträgt, beträgt die Varianz der Einlage für die beiden Banken in Abhängigkeit von allen Faktoren außer Werbung ebenfalls 0,25.
5) Wir definieren die Gesamtvarianz mit der Additionsregel.
= (468*50+636,16*50)/100=552,08
= [(580-561,4)250+(542,8-561,4)250] / 100= 34 596/ 100=345,96
σ 2 = σ 2 Fakt + σ 2 OT = 552,08 + 345,96 = 898,04
6) Der Bestimmungskoeffizient η 2 = σ 2 Fakt / σ 2 = 345,96 / 898,04 = 0,39 = 39% - die Höhe des Beitrags um 39% hängt von der Werbung ab.
7) Das empirische Korrelationsverhältnis ist η = √η 2 = √0,39 = 0,62 - der Zusammenhang ist ziemlich eng.
Aufgabe 2 . Es gibt eine Gruppierung von Unternehmen nach dem Wert marktfähiger Produkte:
Bestimmen Sie: 1) die Varianz des Wertes von Handelsprodukten; 2) Standardabweichung; 3) Variationskoeffizient.
Lösung
1) Entsprechend der vorliegenden Bedingung Intervallintervallverteilung. Es muss diskret ausgedrückt werden, dh die Mitte des Intervalls (x ") finden. In Gruppen von geschlossenen Intervallen finden wir die Mitte eines einfachen arithmetischen Durchschnitts. In Gruppen mit einer oberen Schranke als Differenz zwischen dieser oberen Schranke und der halben Größe des nächsten Intervalls (200- (400) -200): 2 = 100).
In Gruppen mit einer Untergrenze - die Summe dieser Untergrenze und der halben Größe des vorherigen Intervalls (800+ (800-600): 2 = 900).
Die Berechnung des Durchschnittswertes von Waren erfolgt nach der Formel:
Xsr = k × ((Σ ((x "-a): k) × f): Σf) + a. Hier ist a = 500 die Größe der Variante bei der höchsten Frequenz, k = 600-400 = 200 ist die Größe des Intervalls bei der höchsten Frequenz Das Ergebnis wird in die Tabelle gestellt:
Der Durchschnittswert marktfähiger Produkte für den Untersuchungszeitraum beträgt also im Allgemeinen Xsr = (-5: 37) × 200 + 500 = 472,97 Tausend Rubel.
2) Wir finden die Dispersion unter Verwendung der folgenden Formel:
σ 2 = (33/37) * 2002- (472,97-500) 2 = 35 675,67-730,62 = 34 945,05
3) Standardabweichung: σ = ± √σ 2 = ± √34 945,05 ≈ ± 186,94 Tausend Rubel.
4) Variationskoeffizient: V = (σ / Хср) * 100 = (186,94 / 472,97) * 100 = 39,52%
Von allen Variationsindikatoren wird die Standardabweichung am häufigsten für andere Arten statistischer Analysen verwendet. Die Standardabweichung gibt jedoch eine absolute Schätzung des Maßes für die Streuung der Werte an. Um zu verstehen, wie groß sie im Verhältnis zu den Werten selbst ist, ist ein relativer Indikator erforderlich. Dieser Indikator heißt variationskoeffizient.
Die Formel für den Variationskoeffizienten:
Dieser Indikator wird in Prozent gemessen (wenn mit 100% multipliziert).
In der Statistik wird davon ausgegangen, wenn der Variationskoeffizient
bei weniger als 10% wird der Grad der Datenstreuung als unbedeutend angesehen.
von 10% bis 20% - Durchschnitt,
mehr als 20% und weniger als oder gleich 33% - signifikant
der Wert des Variationskoeffizienten 33% nicht überschreitet, gilt das Aggregat als homogen,
wenn mehr als 33%, dann - ungleichmäßig.
Die für eine homogene Population berechneten Durchschnittswerte sind signifikant, d.h. charakterisiere diese Menge wirklich, für eine heterogene Menge - nicht signifikant, charakterisiere die Menge nicht wegen der signifikanten Variation der charakteristischen Werte im Aggregat.
Nehmen Sie das Beispiel der Berechnung der durchschnittlichen linearen Abweichung.

Und ein Erinnerungsplan

Aus diesen Daten berechnen wir: den Durchschnittswert, den Variationsbereich, die durchschnittliche lineare Abweichung, die Varianz und die Standardabweichung.
Der Mittelwert ist das übliche arithmetische Mittel.
Variationsbreite - der Unterschied zwischen dem Maximum und dem Minimum:
Die durchschnittliche lineare Abweichung wird nach folgender Formel berechnet:
Die Dispersion berechnet sich nach der Formel:
Standardabweichung - die Quadratwurzel der Varianz:

Die Berechnung ist in der Tafel zusammengefasst.

Die Variation des Indikators spiegelt die Variabilität des Prozesses oder Phänomens wider. Sein Grad kann mit mehreren Indikatoren gemessen werden.
Variationsbreite - die Differenz zwischen dem Maximum und dem Minimum. Reflektiert den Bereich möglicher Werte.
Mittlere lineare Abweichung - gibt den Durchschnitt der absoluten (in Modulen) Abweichungen aller Werte der analysierten Grundgesamtheit von ihrem Durchschnittswert wieder.
Dispersion - das durchschnittliche Quadrat der Abweichungen.
Standardabweichung - die Wurzel der Varianz (mittlere quadratische Abweichungen).
Variationskoeffizient - der universellste Indikator, der den Grad der Streuung der Werte unabhängig von ihrer Skala und Maßeinheit widerspiegelt. Der Variationskoeffizient wird in Prozent gemessen und kann verwendet werden, um Variationen verschiedener Prozesse und Phänomene zu vergleichen.
Daher gibt es in der statistischen Analyse ein System von Indikatoren, die die Homogenität von Phänomenen und die Stabilität von Prozessen widerspiegeln. Oft haben die Variationsindikatoren keine eigenständige Bedeutung und werden für die weitere Datenanalyse verwendet. Eine Ausnahme bildet der Variationskoeffizient, der die Datenhomogenität kennzeichnet und ein wertvolles statistisches Merkmal darstellt.