Beispiele für das Lösen von Regressionen in Excel. Mathematische Methoden in der Psychologie
Die Regressionsanalyse ist eine der gefragtesten Methoden der statistischen Forschung. Es kann verwendet werden, um den Grad des Einflusses unabhängiger Variablen auf die abhängige Variable zu bestimmen. In Funktionalität Microsoft Excel Es gibt Werkzeuge für diese Art der Analyse. Werfen wir einen Blick darauf, was sie sind und wie man sie verwendet.
Um jedoch die Funktion zur Durchführung von Regressionsanalysen nutzen zu können, müssen Sie zunächst das Analysepaket aktivieren. Erst dann erscheinen die für diesen Vorgang notwendigen Werkzeuge auf der Excel-Multifunktionsleiste.


Wenn wir jetzt auf die Registerkarte gehen "Daten", auf dem Klebeband in der Werkzeugkiste "Analyse" wir werden eine neue Schaltfläche sehen - "Datenanalyse".

Arten der Regressionsanalyse
Es gibt verschiedene Arten von Regressionen:
- parabolisch;
- Machtgesetz;
- logarithmisch;
- exponentiell;
- indikativ;
- hyperbolisch;
- lineare Regression.
Bei der Ausführung des letzteren Typs Regressionsanalyse in Excel werden wir später ausführlicher sprechen.
Lineare Regression in Excel
Nachfolgend finden Sie als Beispiel eine Tabelle, die die durchschnittliche tägliche Außenlufttemperatur und die Anzahl der Ladenkäufer für den entsprechenden Arbeitstag anzeigt. Lassen Sie uns mit Hilfe der Regressionsanalyse genau herausfinden, wie sich die Wetterbedingungen in Form der Lufttemperatur auf den Besuch der Steckdose auswirken können.
Die allgemeine lineare Regressionsgleichung sieht wie folgt aus: Y = a0 + a1x1 +… + akhk. In dieser Formel Ja bedeutet eine Variable, den Einfluss von Faktoren, die wir untersuchen möchten. In unserem Fall ist dies die Anzahl der Käufer. Bedeutung x Sind verschiedene Faktoren, die die Variable beeinflussen. Optionen ein sind die Regressionskoeffizienten. Das heißt, sie bestimmen die Bedeutung dieses oder jenes Faktors. Index k bezeichnet die Gesamtzahl dieser gleichen Faktoren.


Analyse der Analyseergebnisse
Die Ergebnisse der Regressionsanalyse werden in Form einer Tabelle an der in den Einstellungen angegebenen Stelle angezeigt.

Einer der Hauptindikatoren ist R Quadrat... Es zeigt die Qualität des Modells an. In unserem Fall gegebener Koeffizient gleich 0,705 oder etwa 70,5%. Dies ist ein akzeptables Qualitätsniveau. Eine Abhängigkeit von weniger als 0,5 ist schlecht.
Ein weiterer wichtiger Indikator befindet sich in der Zelle am Schnittpunkt der Zeile. "Y-Kreuzung" und Spalte "Chancen"... Es gibt an, welchen Wert Y haben wird, und in unserem Fall ist dies die Anzahl der Käufer, wobei alle anderen Faktoren gleich Null sind. In dieser Tabelle beträgt dieser Wert 58,04.
Wert am Schnittpunkt eines Graphen "Variable X1" und "Chancen" zeigt den Grad der Abhängigkeit von Y von X. In unserem Fall ist es der Grad der Abhängigkeit der Anzahl der Filialkunden von der Temperatur. Ein Verhältnis von 1,31 gilt als relativ hoher Wirkungsindikator.
Wie Sie sehen können, verwenden Sie Microsoft-Programme Excel ist recht einfach, eine Regressionsanalysetabelle zu erstellen. Aber nur eine geschulte Person kann mit den am Ausgang erhaltenen Daten arbeiten und ihr Wesen verstehen.
Gebäude lineare Regression, kann die Schätzung seiner Parameter und deren Bedeutung mit dem Excel-Analysepaket (Regression) viel schneller durchgeführt werden. Betrachten Sie die Interpretation der im allgemeinen Fall erhaltenen Ergebnisse ( k erklärende Variablen) gemäß Beispiel 3.6.
In der Tabelle Regressionsstatistik die Werte sind angegeben:
Mehrere R - multipler Korrelationskoeffizient;
R- Quadrat- Bestimmtheitsmaß R 2 ;
Normalisiert R - Quadrat- angepasst R 2 korrigiert um die Anzahl der Freiheitsgrade;
Standart Fehler- Standardfehler der Regression S;
Beobachtungen - Anzahl der Beobachtungen n.
In der Tabelle ANOVA sind gegeben:
1. Spalte df - die Anzahl der Freiheitsgrade, gleich
für Saite Rückschritt df = k;
für Saite Restdf = n – k – 1;
für Saite Gesamtdf = n– 1.
2. Spalte SS- Summe der Quadrate der Abweichungen gleich
für Saite Rückschritt ;
für Saite Rest ;
für Saite Gesamt .
3. Spalte FRAU Abweichungen bestimmt durch die Formel FRAU = SS/df:
für Saite Rückschritt- faktorielle Varianz;
für Saite Rest- Restvarianz.
4. Spalte F - berechneter Wert F-Kriterium berechnet nach der Formel
F = FRAU(Rückschritt)/ FRAU(Rest).
5. Spalte Bedeutung F - der Wert des Signifikanzniveaus entsprechend dem berechneten F-Statistiken .
Bedeutung F= FIST ( F- Statistiken, df(Rückgang), df(Rest)).
Wenn die Bedeutung F < стандартного уровня значимости, то R 2 ist statistisch signifikant.
| Koeffizienten | Standart Fehler | t-Statistik | p-Wert | Untere 95% | Top 95 % | |
| Ja | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| x | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Diese Tabelle zeigt:
1. Chancen- Koeffizientenwerte ein, B.
2. Standardfehler–Standardfehler der Regressionskoeffizienten S a, S b.
3. T- Statistiken- berechnete Werte T -Kriterien berechnet nach der Formel:
t-Statistik = Koeffizienten / Standardfehler.
4.R-Wert (Bedeutung T) Entspricht der Signifikanzniveauwert dem berechneten T- Statistiken.
R-Wert = TDIST(T-Statistiken, df(Rest)).
Wenn R-Bedeutung< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5... Die unteren 95 % und die oberen 95 %- die untere und obere Grenze der 95 %-Konfidenzintervalle für die Koeffizienten der theoretischen linearen Regressionsgleichung.
| VERBLEIBENDE AUSZAHLUNG | ||
| Überwachung | Vorausgesagtes y | Bleibt e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
In der Tabelle VERBLEIBENDE AUSZAHLUNG angegeben:
in der Spalte Überwachung- Beobachtungsnummer;
in der Spalte Das vorhergesagte ja - berechnete Werte der abhängigen Variablen;
in der Spalte Reste e - die Differenz zwischen den beobachteten und berechneten Werten der abhängigen Variablen.
Beispiel 3.6. Es gibt Daten (konventionelle Einheiten) zu Lebensmittelkosten ja und Pro-Kopf-Einkommen x für neun Familiengruppen:
| x | |||||||||
| ja |
Lassen Sie uns anhand der Ergebnisse des Excel-Analysepakets (Regression) die Abhängigkeit der Lebensmittelkosten von der Höhe des Pro-Kopf-Einkommens analysieren.
Es ist üblich, die Ergebnisse der Regressionsanalyse in der Form zu schreiben:
![]()
wobei die Standardfehler der Regressionskoeffizienten in Klammern angegeben sind.
Regressionskoeffizienten ein = 65,92 und B= 0,107. Kommunikationsrichtung zwischen ja und x bestimmt das Vorzeichen des Regressionskoeffizienten B= 0,107, d. h. die Verbindung ist direkt und positiv. Koeffizient B= 0,107 zeigt, dass bei einem Anstieg des Pro-Kopf-Einkommens um 1 Conv. Einheiten Lebensmittelkosten steigen um 0,107 Conv. Einheiten
Schätzen wir die Signifikanz der Koeffizienten des resultierenden Modells ab. Die Bedeutung der Koeffizienten ( a, b) wird geprüft von T-Prüfung:
p-Wert ( ein) = 0,00080 < 0,01 < 0,05
p-Wert ( B) = 0,00016 < 0,01 < 0,05,
daher sind die Koeffizienten ( a, b) sind auf dem 1 %-Niveau signifikant und noch mehr auf dem 5 %-Signifikanzniveau. Somit sind die Regressionskoeffizienten signifikant und das Modell entspricht den Originaldaten.
Die Ergebnisse der Regressionsschätzung sind nicht nur mit den erhaltenen Werten der Regressionskoeffizienten kompatibel, sondern auch mit einem Teil ihrer Menge (Konfidenzintervall). Mit einer Wahrscheinlichkeit von 95 % betragen die Konfidenzintervalle für die Koeffizienten (38,16 - 93,68) für ein und (0,0728 - 0,142) für B.
Die Qualität des Modells wird durch das Bestimmtheitsmaß bewertet R 2 .
Die Größenordnung R 2 = 0,884 bedeutet, dass 88,4% der Variation (Spreizung) der Nahrungsmittelausgaben durch den Faktor des Pro-Kopf-Einkommens erklärt werden können.
Bedeutung R 2 wird geprüft von F- Test: Bedeutung F = 0,00016 < 0,01 < 0,05, следовательно, R 2 ist auf dem 1%-Niveau signifikant und noch mehr auf dem 5%-Signifikanzniveau.
Bei gepaarter linearer Regression kann der Korrelationskoeffizient definiert werden als ![]() ... Der erhaltene Wert des Korrelationskoeffizienten weist darauf hin, dass der Zusammenhang zwischen Nahrungsmittelausgaben und Pro-Kopf-Einkommen sehr eng ist.
... Der erhaltene Wert des Korrelationskoeffizienten weist darauf hin, dass der Zusammenhang zwischen Nahrungsmittelausgaben und Pro-Kopf-Einkommen sehr eng ist.
R 2 = r xy 2, wobei r xy der Korrelationskoeffizient ist.
Ein Wert von R 2 = 0,83 bedeutet beispielsweise, dass in 83% der Fälle Änderungen von x zu einer Änderung von y führen. Mit anderen Worten, die Genauigkeit der Anpassung der Regressionsgleichung ist hoch.
Sie wird berechnet, um die Qualität der Anpassung der Regressionsgleichung zu beurteilen. Für akzeptable Modelle wird angenommen, dass das Bestimmtheitsmaß größer als 50 % sein sollte. Modelle mit einem Bestimmtheitsmaß über 80 % können als recht gut angesehen werden. Der Wert des Bestimmtheitsmaßes R 2 = 1 bedeutet den funktionalen Zusammenhang zwischen den Variablen.
Im Fall von nichtlineare Regression
das Bestimmtheitsmaß wird mit diesem Rechner berechnet. Bei mehrfache Regression, der Erkennungskoeffizient kann über den Dienst Multiple Regression ermittelt werden
Im Allgemeinen wird das Bestimmtheitsmaß durch die Formel bestimmt: oder
Abweichungsadditionsregel:
,
wo ist die Gesamtsumme der Quadrate der Abweichungen;
- die Summe der Quadrate der Abweichungen aufgrund der Regression ("erklärt" oder "faktoriell");
- Restsumme der Abweichungsquadrate.
Dieser Online-Rechner berechnet Bestimmtheitsmaß und seine Bedeutung wird überprüft (Beispiellösung).
Anweisung. Geben Sie die Menge der Quelldaten an. Die resultierende Lösung wird gespeichert in Word-Datei... Außerdem wird automatisch eine Vorlage generiert, um die Lösung in Excel zu validieren.
Die lineare Regression ermöglicht es uns, die Gerade zu beschreiben, die am besten zu einer Reihe von geordneten Paaren (x, y) passt. Eine Gleichung für eine Gerade, bekannt als Lineargleichung, Nachstehend dargestellt:
ŷ ist der erwartete Wert von y für einen gegebenen Wert von x,
x ist die unabhängige Variable,
a - Segment auf der y-Achse für eine Gerade,
b - Steigung einer geraden Linie.
Die folgende Abbildung veranschaulicht dieses Konzept grafisch:
Das obige Bild zeigt die Linie, die durch die Gleichung ŷ = 2 + 0,5x beschrieben wird. Das Segment auf der y-Achse ist der Schnittpunkt der Geraden mit der y-Achse; in unserem Fall a = 2. Die Steigung der Linie, b, das Verhältnis der Steigung der Linie zur Länge der Linie, hat einen Wert von 0,5. Eine positive Steigung bedeutet, dass die Linie von links nach rechts ansteigt. Wenn b = 0, ist die Linie horizontal, dh es besteht keine Beziehung zwischen den abhängigen und unabhängigen Variablen. Mit anderen Worten, eine Änderung des x-Werts wirkt sich nicht auf den y-Wert aus.
Ŷ und y werden oft verwechselt. Der Graph zeigt 6 geordnete Punktpaare und eine Linie gemäß dieser Gleichung

Diese Abbildung zeigt den Punkt, der dem geordneten Paar x = 2 und y = 4 entspricht. Beachten Sie, dass der erwartete Wert von y gemäß der Linie bei NS= 2 ist . Dies können wir mit folgender Gleichung bestätigen:
= 2 + 0,5x = 2 +0,5 (2) = 3.
Der y-Wert ist der tatsächliche Punkt und the-value ist der erwartete y-Wert unter Verwendung einer linearen Gleichung für einen gegebenen x-Wert.
Der nächste Schritt besteht darin, die lineare Gleichung zu bestimmen, die der Menge der geordneten Paare am nächsten kommt. Wir haben darüber im vorherigen Artikel gesprochen, in dem wir die Form der Gleichung bestimmt haben.
Verwenden von Excel zum Definieren der linearen Regression
Um das in Excel integrierte Regressionsanalysetool verwenden zu können, müssen Sie das Add-In aktivieren Analysepaket... Sie finden es, indem Sie auf die Registerkarte klicken Datei -> Optionen(2007+), im angezeigten Dialogfeld OptionenExcel gehe auf die Registerkarte Add-ons. Auf dem Feld Steuerung wählen Add-onsExcel und klicke Gehen. Setzen Sie im erscheinenden Fenster ein Häkchen gegenüber Analysepaket, wir drücken OK.

Auf der Registerkarte Daten in einer Gruppe Analyse ein neuer Button wird erscheinen Datenanalyse.

Um zu demonstrieren, wie das Add-In funktioniert, verwenden wir die Daten, in denen sich ein Mann und ein Mädchen einen Tisch im Badezimmer teilen. Tragen Sie die Daten für unser Badewannenbeispiel in die Spalten A und B der leeren Tafel ein.
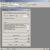
Gehe auf die Registerkarte Daten, in einer Gruppe Analyse klicken Datenanalyse. Im erscheinenden Fenster Datenanalyse wählen Rückschritt wie gezeigt und klicken Sie auf OK.

Stellen Sie die erforderlichen Regressionsparameter im Fenster ein Rückschritt, wie auf dem Bild gezeigt:

Klicken OK. Die folgende Abbildung zeigt die erhaltenen Ergebnisse:

Diese Ergebnisse stimmen mit denen überein, die wir durch unsere eigenen Berechnungen erhalten haben.
Es ist dafür bekannt, dass es in verschiedenen Tätigkeitsbereichen nützlich ist, einschließlich solcher Disziplinen wie der Ökonometrie, wo dieses Software-Dienstprogramm in seiner Arbeit verwendet wird. Grundsätzlich werden alle Aktionen von Praxis- und Laborübungen in Excel durchgeführt, was die Arbeit erheblich erleichtert und bestimmte Aktionen detailliert erklärt. So wird eines der Analysetools "Regression" verwendet, um einen Graphen für eine Reihe von Beobachtungen mit der Methode der kleinsten Quadrate auszuwählen. Lassen Sie uns überlegen, was dieses Tool des Programms ist und welchen Nutzen es für die Benutzer hat. Nachfolgend finden Sie auch eine kurze, aber leicht verständliche Anleitung zum Erstellen eines Regressionsmodells.
Hauptaufgaben und Arten der Regression
Regression ist eine Beziehung zwischen gegebenen Variablen, aufgrund derer es möglich ist, die Vorhersage des zukünftigen Verhaltens dieser Variablen zu bestimmen. Variablen sind verschiedene periodische Phänomene, einschließlich des menschlichen Verhaltens. Diese Excel-Analyse wird verwendet, um die Auswirkungen der Werte einer oder mehrerer Variablen auf eine bestimmte abhängige Variable zu analysieren. Der Umsatz in einem Geschäft wird beispielsweise von mehreren Faktoren beeinflusst, darunter Sortiment, Preise und Standort des Geschäfts. Dank der Regression in Excel können Sie den Einfluss jedes dieser Faktoren basierend auf den Ergebnissen bestehender Verkäufe bestimmen und die erhaltenen Daten dann auf die Verkaufsprognose für einen anderen Monat oder für ein anderes Geschäft in der Nähe anwenden.
Regression wird normalerweise als einfache Gleichung dargestellt, die die Beziehung und Stärke der Beziehung zwischen zwei Gruppen von Variablen aufzeigt, wobei eine Gruppe abhängig oder endogen und die andere unabhängig oder exogen ist. Bei Vorhandensein einer Gruppe von miteinander verbundenen Indikatoren wird die abhängige Variable Y basierend auf der Logik der Argumentation bestimmt, und der Rest agiert als unabhängige X-Variablen.
Die Hauptaufgaben beim Aufbau eines Regressionsmodells sind wie folgt:
- Auswahl signifikanter unabhängiger Variablen (X1, X2,…, Xk).
- Auswahl der Funktionsart.
- Konstruktion von Schätzungen für die Koeffizienten.
- Konstruktion von Konfidenzintervallen und Regressionsfunktionen.
- Überprüfung der Signifikanz der berechneten Schätzungen und der konstruierten Regressionsgleichung.
Es gibt verschiedene Arten der Regressionsanalyse:
- gepaart (1 abhängige und 1 unabhängige Variable);
- mehrere (mehrere unabhängige Variablen).
Es gibt zwei Arten von Regressionsgleichungen:
- Linear, das eine streng lineare Beziehung zwischen Variablen veranschaulicht.
- Nichtlinear - Gleichungen, die Potenzen, Brüche und trigonometrische Funktionen enthalten können.
Modellbauanleitung
Um die angegebene Konstruktion in Excel abzuschließen, müssen Sie die Anweisungen befolgen:

Verwenden Sie zur weiteren Berechnung die Funktion "Linear ()", die Y-Werte, X-Werte, Const und Statistiken vorgibt. Definieren Sie dann die Punktmenge auf der Regressionsgerade mit der Funktion "Trend" - Y-Werte, X-Werte, Neue Werte, Konst. Mittels gegebene Parameter Berechnen Sie den unbekannten Wert der Koeffizienten basierend auf den gegebenen Bedingungen des Problems.