Html statische und dynamische Seiten im Detail. Beachtung. Vorbereitung auf die Arbeit
Ist es nicht wunderbar, eine Website mit eigenen Händen erstellen und pflegen zu können, ohne jemanden um Hilfe zu bitten? Dadurch können Sie nicht nur Geld sparen (schließlich kosten Webentwicklungsdienste viel), sondern auch viele Probleme selbstständig lösen: Erstellen einer persönlichen Webseite, einer Unternehmenswebsite, eines Online-Shops, Umsetzung interessanter Projekte - das ist kein vollständige Liste dessen, was eine Person tun kann, Web-Entwicklungstechnologien zu besitzen.
Nach der Lektüre dieses Buches erfahren Sie, was eine moderne Website ist, wie ihr Konzept aufgebaut ist, was Hosting und ein Domainname sind, wie sich eine statische von einer dynamischen Website unterscheidet, wie Website-Inhalte gebildet werden, warum sie sein müssen optimiert, und viel Freund. Sie lernen selbstständig Webseiten mit der HTML Hypertext Markup Language zu programmieren und lernen Softwareprodukte, die speziell für Webentwickler entwickelt wurden, im Detail kennen, um mit minimalem Zeit- und Arbeitsaufwand automatisch eine vollwertige Website zu erstellen .
Ein einfacher, zugänglicher Präsentationsstil sowie eine Vielzahl an illustrativen Illustrationen und praktischen Beispielen machen das Studium dieses Buches zu einem spannenden Prozess, der die Fähigkeit haben wird, schnell eine attraktive moderne Webressource zu erstellen und alle durchzuführen die notwendigen Schritte zur Pflege, Wartung und Optimierung.
Buch:
Das Konzept der statischen und dynamischen Webseite
Zuvor haben wir kurz darüber gesprochen, was statische und dynamische Webseiten ausmacht. In diesem Abschnitt werden wir dieses Thema genauer betrachten.
Der Name einer statischen Seite spricht für sich: Auf einer solchen Seite werden statische, konstante und unveränderliche Informationen präsentiert. Vielmehr können Sie es ändern, dafür müssen Sie jedoch die entsprechenden Anpassungen am Programmcode der Seite vornehmen.
Normalerweise liegt eine statische Seitendatei im HTML-Format vor. Ein Webentwickler schreibt HTML-Code, um den Inhalt der Site zu bilden, weist der Datei einen Namen zu, lädt die Seite dann auf den Webserver hoch und stellt sie Internetbenutzern zur Verfügung. Auf einer Unternehmenswebsite kann eine statische Seite beispielsweise Informationen über die Geschichte des Unternehmens, die Hauptrichtungen seiner Aktivitäten usw. enthalten. Beachten Sie, dass Sie Ihre ersten Erfahrungen im Bereich der Webentwicklung mit der Erstellung eines statischen Webs beginnen sollten Seiten. Wir werden mehr darüber im Kapitel über die Grundlagen der Webprogrammierung mit HTML sprechen.
HINWEIS
Die Adresse einer in HTML geschriebenen Seite endet mit den Zeichen nach einem Punkt.
Der grundlegende Unterschied zwischen einer dynamischen und einer statischen Webseite besteht darin, dass ihr Inhalt nicht dauerhaft ist, sondern sich ändern kann. Es wird je nach Wunsch des Benutzers gebildet, bzw. aufgrund von Anfragen, die von Besuchern erstellt und an den Webserver gesendet werden. Wie bereits erwähnt, ist das typischste Beispiel für eine dynamische Webseite eine Seite mit Suchergebnissen, die von einer Suchmaschine (zB www.google.ru) basierend auf einer von einem Benutzer gesendeten Suchanfrage zurückgegeben werden. Ein weiteres typisches Beispiel für die Nutzung von Webseiten sind Online-Shops: Ein Besucher gibt über die Optionen an, für welches Produkt und mit welchen Eigenschaften er sich interessiert, sendet eine Anfrage (dies geschieht normalerweise über die entsprechende Schaltfläche - usw.) und danach ein paar Sekunden erhält auf dem Bildschirm eine Liste von Produkten, die die angegebenen Kriterien erfüllen. Darüber hinaus werden dynamische Seiten auf anderen Websites häufig für eine Vielzahl von Zwecken und Richtungen verwendet.
Dynamische Seiten können auch mit der HTML-Sprache erstellt werden, aber dafür ist eine andere Sprache, PHP, besser geeignet (hauptsächlich aufgrund ihrer breiteren Funktionalität). Dementsprechend wird das Auslagerungsdateiformat nicht mehr HTML, sondern PHP sein, und seine Internetadresse endet mit den Zeichen nach einem Punkt.
Wir setzen den Veröffentlichungszyklus zu statischen Sites basierend auf unserem Cloud-Speicher fort (siehe vorherige Veröffentlichungen und). Heute werden wir die Fragen ihrer Feinabstimmung und Optimierung ausführlich besprechen.
Das Hauptkriterium für die hervorragende Arbeit der Seite aus Nutzersicht ist natürlich die Downloadgeschwindigkeit der Komponenten. Wenn die Seite aus irgendeinem Grund zu lange zum Laden braucht, führt dies unweigerlich zum Verlust von wartemüden Besuchern. Um eine Website schnell und bequem zu gestalten, müssen Sie einige Optimierungsarbeiten durchführen.
Wir haben bereits über die Verbindung zu unserem Cloud-CDN-Speicher von Akamai geschrieben. CDN speichert alle statischen Inhalte (Bilder, Textdateien, JS, CSS usw.) auf weltweit verstreuten Caching-Servern (siehe Karte).Beim Zugriff auf eine Webseite oder deren Ressourcen wird die Anfrage durch den dem Client geografisch nächstgelegenen Caching-Server verarbeitet. Die Verwendung eines CDN trägt dazu bei, die Ladegeschwindigkeit der Website sowohl für stationäre als auch für mobile Geräte zu erhöhen.
Standardmäßig werden alle Daten 24 Stunden lang im CDN zwischengespeichert. Vor kurzem wurde dem Repository ein neues Feature hinzugefügt, mit dem Sie den CDN-Cache jederzeit löschen können:

Gehen Sie dazu einfach auf die in der Abbildung gezeigte Registerkarte und geben Sie in das Formular die Adressen der Seiten ein, deren Cache Sie löschen möchten. Der Cache wird nicht sofort gelöscht, sondern ca. 15 Minuten nach Absenden des Formulars.
Jede Webseite enthält viele verschiedene Elemente: Bilder, Skripte, Stildateien und so weiter. Der Benutzer, der die Seite zum ersten Mal besucht, erhält alle diese Elemente durch eine Reihe von HTTP-Anfragen. Um das erneute Hochladen einer großen Anzahl von Dateien zu vermeiden, wird Caching verwendet.Das im HTTP-Protokoll verwendete Caching-Modell basiert auf den sogenannten Validatoren – speziellen Headern, die vom Client verwendet werden, um sicherzustellen, dass das zwischengespeicherte Dokument noch aktuell ist. Dank Validatoren kann der Client den Status des Dokuments überprüfen, ohne die gesamte zwischengespeicherte Kopie an den Server zu senden. Der Server wiederum sendet in seiner Antwort nur dann ein Dokument, wenn der empfangene Validator das Vorhandensein einer veralteten Kopie im Cache des Clients anzeigt.
Validatoren werden in Stärken und Schwächen eingeteilt. Starke Validatoren wurden in HTTP / 1.1 eingeführt. Sie werden so benannt, weil sie sich jedes Mal ändern, wenn sich die Datei ändert. Dazu zählen die sogenannten ETags (Entity-Tags). ETag ist eine Kennung für den Inhalt eines Dokuments; es ändert sich, wenn sich mindestens ein Bit im Dokument ändert. Als Kennung kann beispielsweise die MD5-Summe des Inhalts des Dokuments verwendet werden. Wenn ein Client ein Dokument vom Server anfordert, wird der ETag-Wert in der Antwort übertragen, zum Beispiel:
HTTP / 1.1 200 OK Server: Selectel_Storage / 1.0 Akzeptanzbereiche: Bytes Zuletzt geändert: Mo, 18.08.2014 12:25:38 GMT X-Zeitstempel: 1408364738.80296 Inhaltstyp: Bild / jpeg Inhaltslänge: 458073 Zugriffskontrolle -Allow-Origin: * Access-Control-Expose-Headers: Last-Modified, ETag, X-Timestamp ETag: "ebef3343a7b152ea7302eef75bea46c3" Datum: Mi, 20 Aug 2014 11:52:48 GMT
Wenn das gleiche Dokument erneut angefordert wird, wird der gespeicherte Validator-Wert im If-None-Match-Header übergeben:
GET / HTTP / 1.1 Host: example.org If-None-Match: "ebef3343a7b152ea7302eef75bea46c3"
Wenn das Dokument nicht geändert wurde, gibt der Server in der Antwort nur Header und 304 Not Modified-Code zurück. Andernfalls gibt der Server den Code 200 zurück und überträgt die neue Version des Dokuments sowie den neuen ETag-Wert dafür.
In unserem Repository und ETag wird sofort nach dem Hochladen der Datei generiert. Es ist ein MD5-Hash des Inhalts. Ändert sich der Inhalt, dann ändert sich auch das ETag.
Schwache Validatoren sind Validatoren, die sich nicht unbedingt jedes Mal ändern, wenn eine Datei geändert wird.
Ein Beispiel für einen schwachen Validator ist der Last-Modified-Header. Der Wert dieses Headers ist das Datum, an dem die Datei zuletzt geändert wurde. Es wird automatisch in unserem Repository installiert. Wenn Sie bei der Anfrage im If-Modified-Since-Header ein Datum angeben, das nicht früher als das aktuell im Last-Modified-Header enthaltene Datum ist, lautet die Antwort ebenfalls 304 Not Modified.
Starke Validatoren können in jedem Kontext verwendet werden. Schwache Validatoren werden in einem Kontext verwendet, der nicht vom genauen Inhalt der Datei abhängt.
Beispielsweise können beide Arten von Validatoren in bedingten GET-Anforderungen verwendet werden (If Modified Since oder If None Match). Beim Hochladen von Dateien in Teilen können jedoch nur starke Validatoren verwendet werden - sonst erhält der Client die Datei in inkonsistenter Form.
Der Cache-Control-Header mit der max-age-Direktive wird verwendet, um das Alter im Browser-Cache für eine Kopie einer Datei festzulegen, deren Original sich im Speicher befindet. Dank dieses Headers können Sie die Ladegeschwindigkeit der Site erheblich erhöhen - wenn die Datei zwischengespeichert ist, zeigt der Browser sofort den Inhalt aus dem Cache an, ohne eine einzige Anfrage an die Site zu senden.Die Speicherzeit der Datei im Cache wird in Sekunden angegeben:
Cache-Kontrolle: max-age = 7200
Im gezeigten Beispiel sind es 7200 Sekunden (2 Stunden). Normalerweise werden CSS-, JS- und Bilddateien auf diese Weise zwischengespeichert. Es ist wünschenswert, sie für immer zwischenzuspeichern und Links zu ihnen in HTML zu ändern, wenn sich der Inhalt ändert. RFC 2616 empfiehlt die Caching-Zeit für solche Dateien von nicht mehr als 1 Jahr:
Cache-Kontrolle: max-age = 31536000
Wenn Sie möchten, dass eine bestimmte Datei nicht zwischengespeichert, sondern immer "frisch" bereitgestellt wird, wird der Cache-Control-Header auf den folgenden Wert gesetzt:
Cache-Kontrolle: kein Cache
Es gibt an, dass das Element überhaupt nicht zwischengespeichert werden soll und dass der Client es jedes Mal anfordern soll, wenn auf das Repository zugegriffen wird (die Downloadzeit der Datei verlängert sich in diesem Fall, da der Dateikörper heruntergeladen werden muss).
Eine andere Möglichkeit, die Datei immer auf den neuesten Stand zu bringen, besteht darin, dem Dateinamen eine Inhaltsprüfsumme hinzuzufügen.
Ändert sich der Inhalt der Datei um mindestens ein Bit, dann ändert sich auch die Prüfsumme. Wenn keine Änderungen vorgenommen wurden, verwendet der Browser die Datei aus dem Cache. Wenn Sie die Datei ändern, ändert sich der Link darauf und die neue Version wird geladen.
Sie können die Prüfsumme sowohl mit den Standarddienstprogrammen md5sum oder sha1sum als auch mit speziellen Dienstprogrammen abrufen.
Sie können Links zu Dateien auch einen beliebigen Satz von Zeichen hinzufügen – beispielsweise einen Zeitstempel (http://example.com/script.js?timestamp_here) – und die Links bei jeder Bereitstellung der Site aktualisieren. Bei dieser Methode gibt es jedoch keine Garantie dafür, dass der Browser keine unnötigen Anfragen stellt: Auch zu Dateien, deren Inhalt sich nicht geändert hat, führt ein anderer Link (der Caching-Schlüssel ist der gesamte Link mit Abfrageparametern) und Sie muss sie erneut herunterladen.
Für HTML-Seiten ist es vorzuziehen, den Cache-Control-Header auf no-cache zu setzen. Wenn auf der Seite dringend etwas geändert werden muss und der Client diese Seite bereits zwischengespeichert hat (moderne Browser tun dies standardmäßig), dann sieht der Client die Änderungen möglicherweise überhaupt nicht.
Dies ist besonders wichtig bei der Verwendung von CDNs: Das CDN von Akamai speichert Dateien ohne entsprechende Header standardmäßig 24 Stunden lang im Cache. Sie können natürlich den Cache leeren (siehe oben), müssen aber nach dem Absenden der entsprechenden Anfrage noch mindestens 15 Minuten warten. Das Setzen des No-Cache-Wertes hilft, mögliche Probleme zu vermeiden - die Seite wird immer aktuell geladen. Browser verwenden in diesem Fall immer noch If-None-Match (oder If-Modified-Since)-Header und eine Seite, die nicht geändert wurde, wird nicht erneut geladen.
In einigen Fällen ist es besser, die Caching-Zeit für HTML-Seiten basierend auf der Häufigkeit der Änderungen festzulegen. Wenn beispielsweise die Seite mit Neuigkeiten auf der Website stündlich aktualisiert wird, kann das maximale Alter auf 3600 (1 Stunde) eingestellt werden.
Der Wert des Cache-Control-Headers (sowie anderer HTTP-Header) in unserem Shop kann über das Webinterface eingestellt werden:

Über das Webinterface werden Headerwerte nur für den Container als Ganzes gesetzt. Header-Werte für einzelne Dateien können nur über die API oder über Drittanbieter-Clients gesetzt werden.
Der Expires-Header kann anstelle von Cache-Control verwendet werden. Sein Wert gibt das Datum im RFC 1123-Datumsformat an, nach dem die Datei nicht mehr gültig ist (zum Beispiel: Di, 31 Jan 2012 15:02:53 GMT). Bis zu diesem Datum stellt der Browser keine Anfragen an die Site, sondern erhält die Datei aus dem Cache. Nach diesem Datum wird die Datei erneut heruntergeladen.
Mit Hilfe der Komprimierung können Sie das Laden der Site erheblich beschleunigen. Seit HTTP / 1.1 melden Clients unterstützte Komprimierungsmethoden im Accept-Encoding-Header:Akzeptieren-Kodierung: gzip, deflate
In der Serverantwort werden im Content-Encoding-Header Informationen über das verwendete Komprimierungsverfahren übermittelt:
Inhaltskodierung: gzip
Eine der beliebtesten und am häufigsten verwendeten Methoden ist heute natürlich gzip. Mit seiner Hilfe können Sie die Downloadzeit erheblich verkürzen. Gzip funktioniert besonders gut mit Textdateien: HTML, CSS, JS. Dank der Komprimierung wird die Größe von Textdateien (und dementsprechend das Volumen des übertragenen Datenverkehrs) durchschnittlich um das 5- bis 10-fache reduziert. Dadurch kann die Seitenladegeschwindigkeit deutlich erhöht werden, was besonders für mobile Clients mit langsamen Verbindungen wichtig ist.
Es macht keinen Sinn, gzip für Grafikdateien zu verwenden: Die Komprimierung hilft nicht, ihre Größe signifikant zu reduzieren, sondern oft sogar zu erhöhen.
Akamai CDN verwendet standardmäßig gzip für die meisten Textdateien.
Minimierung bedeutet, unnötige / optionale Zeichen aus einer Datei zu entfernen, um ihre Größe zu reduzieren und die Downloadzeit zu verkürzen. Dadurch wird die Dateigröße im Durchschnitt um das 1,5- bis 3-fache reduziert. Heutzutage ist die Praxis weit verbreitet, nicht nur JS und CSS, sondern auch andere Dateitypen (HTML, Grafikdateien usw.) zu minimieren.Zur Verkleinerung werden spezielle Werkzeuge verwendet, insbesondere:
Mit Hilfe der Minification können Sie nicht nur unbedeutende Leerzeichen und Zeilenumbrüche entfernen (in CSS und JS optional), sondern auch komplexere Operationen durchführen. Zum Beispiel in JS eine Funktion wie diese:
Funktion summ (first_param, second_param) (return (first_param + second_param);)
Sie können es in die Funktion s (a, b) (return (a + b)) umwandeln und dann überall im Code s anstelle von summ verwenden, während die Logik seiner Arbeit vollständig erhalten bleibt. Wie das JavaScript-Minifizierungsverfahren funktioniert, können Sie unter http://lisperator.net/uglifyjs/ im Abschnitt Open Demo sehen.
Hier kann die Verkettung helfen – das Kombinieren mehrerer Dateien desselben Typs (wie JS oder CSS) zu einer. Es ermöglicht Ihnen, die Anzahl der Anfragen zu reduzieren und dadurch die Ladegeschwindigkeit von Seiten zu erhöhen.
Die Verkettung kann auch verwendet werden, um das Laden von Bildern zu beschleunigen. Dies kann auf zwei Arten erfolgen: durch Einbetten von Daten in URLs und durch Verwenden von Sprites.
Die Dateninjektion erfolgt über einen speziellen URL-Typ - Daten: URI. URI (Universal Resource Identifator) kann sowohl im src-Attribut des img-Tags als auch in der URL des Hintergrundbilds in CSS verwendet werden.
Es gibt Online-Tools zum Konvertieren von Bildern in Daten: URIs (siehe zum Beispiel und).
Ein Sprite ist eine Sammlung von Bildern, die zu einem Bild kombiniert werden. Zur Erstellung von Sites werden verschiedene Softwaretools verwendet. Mit CSS können Sie auf den gewünschten Abschnitt eines großen Bildes verweisen und es an der richtigen Stelle auf der Site platzieren.
Sprites können dabei helfen, die Ladegeschwindigkeit zu erhöhen, aber es sollte beachtet werden, dass es oft schwierig ist, mit ihnen zu arbeiten. Um auch nur eine kleine Änderung am Sprite vorzunehmen, müssen Sie begleitende Änderungen am CSS vornehmen.
In modernen Tools zum Erstellen von JS-Projekten (
Wenn Sie Tag für Tag daran arbeiten, den Inhalt Ihrer Website mit interessanten Inhalten zu aktualisieren, denken Sie wahrscheinlich, dass täglich Hunderte neuer Websites erstellt und täglich Hunderte neuer Dokumente hinzugefügt werden. Wie werden all diese neuen Seiten-Arrays erstellt und wie werden sie so schnell aktualisiert? All dies ist nicht so kompliziert, wie es auf den ersten Blick scheint, da es das Konzept dynamischer Webseiten verwendet.
In diesem Artikel führen wir Sie durch die Schritte zum Erstellen eines Mechanismus zum Veröffentlichen von Pressemitteilungen auf Websites. Unsere Site verbindet in einer Datenbank gespeicherte Pressemitteilungen on-the-fly mit Webseiten mit Vorlagen. Es ist nicht unsere Absicht, den Lesern die Grundlagen der Website-Entwicklungstools vorzustellen, da viele Bücher und Artikel darüber geschrieben wurden. Dieser Artikel richtet sich hauptsächlich an Benutzer, die bereits Erfahrung mit der Erstellung von Webseiten und einfachen Sites haben. Unser Hauptziel ist es, Ihnen zu zeigen, wie Sie mit der Entwicklung Ihrer ersten dynamischen Website beginnen können. Zum Verständnis des Artikels ist es wünschenswert, über Grundkenntnisse der Architekturen von Informationssystemen, der Hypertext Markup Language (HTML) und der Programmiersprache Perl zu verfügen. Wir werden drei leistungsstarke Open-Source-Technologien verwenden, um diese Site zu erstellen: Apache, MySQL und Perl / DBI.
Was ist eine statische Website?
Bevor Sie sich mit der Entwicklung dynamischer Websites befassen, ist es wichtig zu verstehen, was eine statische Website und die statischen Webseiten sind, aus denen sie besteht. Statische Webseiten werden manuell erstellt, dann gespeichert und auf die Site hochgeladen. Immer wenn der Inhalt einer solchen Seite geändert werden muss, ändert der Benutzer ihn auf seinem Arbeitscomputer, normalerweise mit einem HTML-Editor, speichert ihn und lädt ihn dann erneut auf die Website hoch. Wenn Sie sich ein Portal wie CNN.com oder BBC.co.uk genau ansehen, könnten Sie denken, dass diese Unternehmen eine Armee von Layout-Designern einstellen, um den Inhalt ihrer Websites zu aktualisieren. Tatsächlich gibt es einen besseren Weg - das Konzept einer dynamischen Website zu verwenden.
Was ist eine dynamische Website?
Jede angezeigte Seite dynamischer Websites basiert auf einer Vorlagenseite, in die ständig wechselnde Inhalte eingefügt werden, die in der Regel in einer Datenbank gespeichert sind. Wenn ein Benutzer eine Seite anfordert, werden die relevanten Informationen aus der Datenbank abgerufen, in die Vorlage eingefügt, um eine neue Webseite zu bilden, und vom Webserver an den Browser des Benutzers gesendet, der sie wie erwartet wiedergibt. Neben Inhalten kann auch die Website-Navigation dynamisch erstellt werden. Wenn Sie also den Inhalt Ihrer Site aktualisieren müssen, fügen Sie einfach Text für die neue Seite hinzu, der dann mit einem bestimmten Mechanismus in die Datenbank eingefügt wird. Daher scheint sich die Website selbst zu aktualisieren.
Aufbau einer dynamischen Website
Das erste, was Sie zum Erstellen einer dynamischen Site benötigen, ist ein Webserver wie Apache.
Der Webserver kann verwendet werden, um eine E-Commerce-Site, einen Nachrichtenserver, eine Suchmaschine, ein Fernunterrichtssystem und sogar alle diese Bereiche zu bedienen. Die Wahl eines Webservers hängt von der Art der Aktivität ab, die die Person oder Organisation im Internet durchführen möchte.
Nur wenige der strategischen Entscheidungen, die Sie im Geschäftsleben treffen, sind so wichtig wie die Wahl einer Plattform für Ihren Webserver. Die Serverleistung ist ein äußerst wichtiger Faktor bei der Bestimmung der Zuverlässigkeit einer Site, ihrer Reaktionsfähigkeit auf Client-Anfragen und des Aufwands, der unternommen werden muss, um sie am Laufen zu halten. Mit den richtigen Komponenten und dem hochwertigen Design kann eine Website Kunden und Partnern eine neue, bequemere Möglichkeit bieten, mit Ihrem Unternehmen zu interagieren. Eine Überlastung des Webservers kann dazu führen, dass der Datenbankserver oder eine andere Ressource für Clients nicht mehr verfügbar ist.
Große Unternehmen verließen sich bis vor kurzem auf Microsoft Internet Information Server, Netscape FastTrack, IBM WebSphere und Apache wurde hauptsächlich von kleinen Unternehmen verwendet. Jetzt hat sich die Situation jedoch etwas geändert und Apache beginnt, die Leistung einiger großer Internetprojekte, insbesondere Yahoo, zu unterstützen.
Die Vollversion des Artikels finden Sie auf unserer CD-ROM.
Apache bietet eine Fülle von Optionen, um Ihren Webserver an die Bedürfnisse von Privatpersonen und Unternehmen anzupassen. Die Einstellung erfolgt über die in den Konfigurationsdateien enthaltenen Anweisungen. Apache ermöglicht Ihnen das Erstellen virtueller Websites und fungiert auch als Proxy-Server. Wenn Sie nur einer begrenzten Anzahl von Personen Zugriff auf die Inhalte des Servers gewähren möchten, kann der Webserver so konfiguriert werden, dass der Server beim Zugriff auf die angegebenen Verzeichnisse die Login-Namen und Passwörter in seiner eigenen oder in einer der Datenbanken prüft damit verbunden.
Als nächstes müssen Sie entscheiden, wie Sie den Inhalt (Inhalt) speichern möchten, der auf der Webseite angezeigt wird. In diesem Artikel zeigen wir anhand eines konkreten Beispiels, wie Sie eine Datenbank in MySQL DBMS erstellen, die es uns ermöglicht, Webinhalte in Tabellen mit Feldern und Datensätzen mit Daten aufzuteilen. Ein Feld ist eine diskrete Dateneinheit in einer Tabelle. Beispielsweise können wir eine tbl_news_items-Tabelle mit den Feldern col_title, col_date, col_fullstory, col_author erstellen. MySQL ist aufgrund seiner einfachen Handhabung und Verwaltung, der kostenlosen Verteilung für verschiedene Plattformen, einschließlich Linux und Windows, und der schnell wachsenden Popularität eine ausgezeichnete Wahl für die Erstellung einer solchen Datenbank.
Danach erstellen wir dynamische HTML-Vorlagenseiten. Um Anwendungen für die Interaktion mit der Datenbank und den Vorlagen zu entwickeln, verwenden wir die Sprache Perl.
Tatsächlich müssen wir drei Perl-Programme oder Skripte erstellen: eines zeigt Links zu allen verfügbaren Pressemitteilungen an (pr-list-dbi.pl), das andere - der Inhalt der ausgewählten Pressemitteilung (pr-content-dbi. pl) und die dritte ermöglicht es uns, der Datenbank (pr-add-dbi.pl) eine neue Pressemitteilung hinzuzufügen. Die Layoutarbeit kann Ihrem bevorzugten HTML-Editor zugewiesen werden, zum Beispiel Allaire HomeSite (http://www.allaire.com/). Denken Sie daran, dass Sie beim Erstellen einer Vorlage leere Bereiche lassen müssen, in denen dynamische Füllungen (natürlich mit variabler Länge) eingefügt werden.
Nachdem Sie ein allgemeines Design für Ihre Pressemitteilungen entwickelt haben, fügen Sie einfach spezifische Schlagworte in die leeren Felder oben ein (siehe unten für mehr dazu). Sobald der Benutzer eine Pressemitteilung anfordert, parst der Webserver den Perl-Code und ersetzt die Schlüsselwörter in den Vorlagen durch Inhalte aus der Datenbank, also durch eine bestimmte Pressemitteilung.
Als letztes müssen Sie Ihre Vorlagen in bestimmten Verzeichnissen auf den Webserver hochladen. Sie können den CuteFTP FTP-Client (http://www.cuteftp.com/) verwenden, aber wir bevorzugen den FAR-Datei-Wrapper. Zwei wichtige Dinge sind zu beachten: Erstens müssen Vorlagendateien Namen enthalten, die auf .pl enden, und zweitens müssen sie ausführbar sein (auf UNIX-Systemen chmod 0755 template_name.pl). Das ist alles!
Hinzufügen von Funktionen
Es ist nicht schwierig, dem Veröffentlichungsmechanismus für Pressemitteilungen Funktionen hinzuzufügen. Sie können die Links zu den in der Datenbank verfügbaren Pressemitteilungen nach Datum oder Titel sortieren und nach Jahr gruppieren. Oder Sie möchten beispielsweise gelegentlich eine Pressemitteilung auf Ihrer Webseite anzeigen, um Besuchern von Zeit zu Zeit Informationen bereitzustellen, unabhängig davon, wann sie tatsächlich veröffentlicht wurden. Die wahrscheinlich wichtigste und nützlichste Funktionalität wird jedoch das Hinzufügen eines HTML-Formulars zur Eingabe des Inhalts der Pressemitteilung und die Entwicklung eines CGI-Programms in Perl sein, um dieses Formular zu verarbeiten und dann das Dokument in die Datenbank zu stellen. Denken Sie daran, dass CGI (Common Gateway Interface) ein Protokoll, ein Mechanismus oder eine formale Vereinbarung zwischen einem Webserver und einem einzelnen Programm ist. Der Server kodiert Eingabedaten, wie beispielsweise HTML-Formulare, und das CGI-Programm dekodiert sie und erzeugt einen Ausgabestrom. Die Protokollspezifikation sagt nichts über eine bestimmte Programmiersprache aus. Daher können Programme, die diesem Protokoll entsprechen, in fast jeder Sprache geschrieben werden - in C, C++, Visual Basic, Delphi, Tcl, Python oder, wie in unserem Fall, in Perl.
Fassen wir einige der Ergebnisse zusammen. Hoffentlich hilft Ihnen dieser Artikel dabei, die Vorteile des Konzepts dynamischer Webseiten gegenüber statischen zu verstehen. Die Anwendung dieses Konzepts reduziert die manuelle Arbeit, trägt zur Verteilung der Server-Arbeitslast bei und fügt Ihrer Site schnell Inhalte hinzu. Die Kombination von Apache, MySQL und Perl wird eine praktisch kostenlose, einfach zu verwendende, flexibel zu installierende und zu konfigurierende plattformübergreifende und skalierbare Entwicklungsumgebung bieten. Hier werden wir nicht auf die Besonderheiten ihrer Installation eingehen, da erstens einfach nicht genügend Platz für diesen Artikel zur Verfügung steht und zweitens jedes dieser Tools mit einer sehr detaillierten Dokumentation geliefert wird.
Erstellen einer Datenbank im MySQL DBMS
Entwicklung von Datenbankmodellen
Der erste und wichtigste Schritt beim Erstellen einer Datenbank ist die Entwicklung ihres Modells. Also lasst uns anfangen.
Schritt 1
Wir müssen die Datenbank irgendwie benennen. Nennen wir es db_website.
Schritt 2
Es ist notwendig zu bestimmen, was genau die Datenbanktabellen enthalten werden. Die Datenbank kann Hunderte von Tabellen enthalten. Zunächst benötigen wir nur einen Tisch, um unsere Pressemitteilungen zu speichern. Nennen wir es tbl_news_items.
Schritt 3
Es ist notwendig, die Felder zu definieren, die unsere Tabelle enthalten wird. Diese Felder repräsentieren alle Elemente der Pressemitteilung. Unser Beispiel verwendet fünf Felder: col_id (numerische ID der Pressemitteilung), col_title (Titel), col_date (Veröffentlichungsdatum), col_fullstory (Inhalt), col_author (Autorenname). Das Feld col_id enthält eine eindeutige Kennung, mit der der Benutzer den Inhalt einer bestimmten Pressemitteilung abfragen kann.
Datenbankerstellung
Jetzt müssen wir eine Verbindung zum MySQL DBMS herstellen und unsere Datenbank erstellen. Im Folgenden zeigen wir Ihnen, wie Sie dies von der Befehlszeile aus tun. Es gibt jedoch viele Managementsysteme oder DBMS-Manager, die es Ihnen ermöglichen, es über eine benutzerfreundliche grafische Oberfläche zu verwalten.
Vor allem sollten Sie unbedingt die Grundlagen der Structured Query Language (SQL) kennen. Das MySQL DBMS wird mit einer vollständigen Beschreibung der unterstützten SQL-Spezifikation ausgeliefert. Diese Sprache ist leicht zu verstehen, weil ihre Operatoren und ihre Konstruktionen leicht zu verstehen und zu merken sind. Um zu funktionieren, benötigen Sie Anweisungen zum Erstellen (CREATE oder INSERT), Auswählen (SELECT) und Löschen (DROP oder DELETE) sowie zum Ändern (UPDATE, MODIFY). In konkreten Beispielen werden wir nur einige davon verwenden.
Um das Einrichten von Benutzerkonten und das Zuweisen der erforderlichen Zugriffsrechte zu überspringen, nehmen wir an, dass Sie das Administratorkonto (root) verwenden.
Schritt 1
Öffnen Sie ein Terminalfenster (wenn Sie die X Window GUI für Linux oder Windows 9x / NT / 2000 verwenden) und stellen Sie eine Verbindung zum MySQL DBMS her, indem Sie mysql in der Befehlszeile eingeben. Als Antwort sollten Sie nach mysql>-Befehlen gefragt werden.
Schritt 2
Lassen Sie uns unsere Datenbank erstellen, indem wir Folgendes eingeben:
DATENBANK ERSTELLEN db_website;
Denken Sie daran, nach jedem Befehl (;) einzugeben. Es ist sehr wichtig, weil es ein Signal an MySQL sendet, um die Befehlseingabe zu beenden.
Verwenden Sie db_website;
Schritt 4
Erstellen wir eine Tabelle tbl_news_items, in der wir die Art der Daten definieren, die in ihren Feldern gespeichert werden. Eintreten:
1.CREATE TABLE tbl_news_items (2.col_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, 3.col_title VARCHAR (100), 4.col_author VARCHAR (100), 5.col_body TEXT, 6.col_date DATE 7.);
Schritt 5
Nachdem wir nun eine Tabelle für unsere Daten erstellt haben, müssen wir sie mit einigen Beispieldaten füllen. Beachten Sie, dass wir im folgenden Befehl das Feld col_id nicht definieren, da es beim Hinzufügen neuer Daten automatisch ausgefüllt wird. Beachten Sie auch, dass die Syntax für Datum ist<год/месяц/день>... Geben Sie an der Eingabeaufforderung mysql> den folgenden Befehl ein.
8. INSERT INTO tbl_news_items (col_title, _ col_author, col_body, col_date) 9. WERTE (10. 'Meine erste Pressemitteilung', 11. 'Ihr Name', 12. 'Diese Pressemitteilung wird in der MySQL-Datenbank gespeichert', 13 . „15.04.2001“ 14.);
Geben Sie einige weitere ähnliche Abfragen zum Einfügen ein. Geben Sie an der Eingabeaufforderung mysql> Folgendes ein, um anzuzeigen, was in der Datenbank gespeichert ist:
SELECT * FROM tbl_news_items;
Erstellen dynamischer Webseiten in Perl
Vorbereitung auf die Arbeit
Um Perl-Programme auszuführen, benötigen Sie die Perl-Interpreter-Version 5.005 oder 5.6 der Perl Standard- oder ActiveState-Perl-Distributionen für UNIX oder Win32. Wenn Sie Anwendungen entwickeln, die unter Win32 funktionieren, ist das Paket von ActiveState etwas bequemer zu verwenden, außerdem enthält es ein PPM-Dienstprogramm zum Installieren zusätzlicher Module.
Um das Zusammenspiel unserer Perl-Programme mit dem MySQL-DBMS zu organisieren, ist es notwendig, dass das Perl-Paket das DBI-Modul enthält. Da das Modul im Grunde nichts alleine macht, sondern alle Operationen für die Interaktion mit Datenbanken auf den entsprechenden Treiber verlagert, ist es erforderlich, die DBD-Mysql-Bibliothek (ein Treiber für die MySQL-Datenbank für das DBI-Modul) zu installieren. Tim Bunce, der Autor und Entwickler des Moduls, sagte: „DBI ist eine API für den Zugriff auf Datenbanken aus Perl-Programmen. Die DBI-API-Spezifikation definiert eine Reihe von Funktionen, Variablen und Regeln, die für eine transparente Schnittstelle mit Datenbanken verwendet werden.
Das Konzept der Datenbanktreiber ist sehr praktisch, da Sie in Ihrer Perl-Anwendung Standard-DBI-Aufrufe verwenden, die dann Module an den entsprechenden Treiber weiterleiten, der wiederum direkt mit der Datenbank interagiert, ohne dass Sie die technischen Funktionen studieren müssen jedes einzelnen DBMS. So gibt es die Treiber DBD :: Sybase, DBD :: Oracle, DBD :: Informix usw. ( Reis. 1 , ).
Gehen wir ein wenig über den Rahmen des Artikels hinaus. Nehmen wir an, das DBI-Paket enthält keinen Treiber für ein bestimmtes DBMS. In diesem Fall kommt die DBD-ODBC-Brücke zur Rettung. Es reicht aus, eine neue Datenquelle (Data Source Name) für den ODBC-Treiber (Open DataBase Connectivity) zu erstellen, in der Sie den Typ dieses DBMS, die Host-Adresse, zu der Sie die Verbindung herstellen möchten, den Datenbanknamen auswählen müssen und Berechtigungsdaten, d. h. Benutzername und Passwort ( Reis. 3). Interagieren Sie dann mithilfe des DBI-Moduls mit der Datenbank. Außerdem ist das Modul Win32 :: ODBC (Win32-ODBC) normalerweise in der Standarddistribution von ActiveState Perl enthalten. Die Arbeit damit unterscheidet sich geringfügig von der Arbeit mit DBI, ist aber im Allgemeinen sehr ähnlich. Der einzige Unterschied besteht darin, dass Win32 :: ODBC ein reines Win32-Modul ist und es Ihnen ermöglicht, effizienter mit nativen ODBC-Funktionen zu arbeiten als DBD :: ODBC.
Zwischen ODBC und DBI lässt sich eine Parallele ziehen. DBI entspricht dem ODBC-Administrator (Datenbanktreiber-Manager). Jeder DBD-Treiber entspricht in seinen Funktionen einem ODBC-Treiber. Das einzige, was verwirrend sein kann, ist die Tatsache, dass es, wie oben erwähnt, einen DBD :: ODBC-Treiber gibt. Sie können jedoch nur eine DBI-Verbindung mit ODBC-Treibern herstellen.
Um DBI und DBD-Mysql mit dem PPM-Dienstprogramm in Win32 zu installieren, geben Sie Folgendes ein:
Ppm installieren DBI
Bitte beachten Sie, dass Ihr Computer zu diesem Zeitpunkt mit dem Internet verbunden sein muss. Wenn Sie das entsprechende Modul auf Ihrer lokalen Festplatte haben, verwenden Sie die Hilfeinformationen, indem Sie den folgenden Befehl eingeben:
Ppm-Hilfe bei der Installation
Für UNIX-Benutzer ist die Installation des DBI-Moduls ähnlich wie die Installation anderer Perl-Module:
Tar –zxvf DBI-1.06.tar.gz cd DBI-1.06 / perl Makefile.PL make make test make install
Sie können auch die CPAN-Shell verwenden. Wenn die UNIX-Version des ActiveState-Pakets auf Ihrem Computer installiert ist, können Sie auch mit dem PPM-Installationsdienstprogramm arbeiten. Manchmal kommt es vor, dass die CPAN- und PPM-Shells nicht funktionieren, wenn eine Firewall oder Firewall im Unternehmensnetzwerk installiert ist, mit dem Ihr Computer verbunden ist. In diesem Fall helfen Ihnen nur die Module mit manuell geladenem Quellcode. Um sie zu installieren und eine Verbindung zu Perl oder Apache herzustellen, benötigen Sie einen Perl-Interpreter, einen C / C ++- oder GCC / PGCC-Compiler und einige der make build-Dienstprogramme (von einem der UNIX-Klone bereitgestellt, sowie Microsoft Visual C ++), nmake oder dmake. Daher ist das Verfahren zum Installieren von Modulen etwas kompliziert. Fast jeder von ihnen wird mit einer "Build"-Dokumentation geliefert, die Ihnen den Einstieg erleichtern sollte.
Anzeigen einer Artikelliste
Da Sie nun über eine funktionierende Datenbank für Pressemitteilungen verfügen, können Sie diese ganz einfach mit einer Webseite verbinden. Beginnen wir damit, eine einfache Seite zu erstellen, die eine Liste aller verfügbaren Pressemitteilungen anzeigt. Beachten Sie, dass der Apache-Webserver standardmäßig "denkt", dass sich alle Ihre Dokumente in seinem htdocs-Verzeichnis und ausführbare Dateien in seiner cgi-bin befinden sollten. Daher ist es notwendig, alle Dateien mit der Erweiterung .pl im Verzeichnis cgi-bin abzulegen. Die generierten HTML-Vorlagendateien müssen wiederum im tpl-Verzeichnis abgelegt werden. Die Verzeichnishierarchie sieht wie folgt aus:
/ (Root einer beliebigen Festplatte) / local / local / usr / local / usr / bin / local / usr / cgi-bin / local / usr / htdocs / local / usr / tpl
Für DOS-/Windows-Systeme könnte der Pfad zu cgi-bin so aussehen:
C: \ local \ usr \ cgi-bin
Schritt 1
Erstellen Sie mit Ihrem bevorzugten Texteditor die Datei pr-list-tpl.htm:
15. 16.
17.Diese Datei soll eine Liste aller verfügbaren Pressemitteilungen anzeigen.
Schritt 2
Erstellen Sie eine Datei pr-list-block-tpl.htm, die jeden Block mit der gefundenen Pressemitteilung als Tabelle anzeigt:
23.
| @[E-Mail geschützt] |
| @[E-Mail geschützt], _ @[E-Mail geschützt] |
Schritt 3
Erstellen Sie eine Datei pr-content-tpl.htm, die den Inhalt der Pressemitteilung anzeigt:
27. 28.
29.@[E-Mail geschützt]
33.| @[E-Mail geschützt] |
|---|
| Autor: @[E-Mail geschützt] Datum: @ [E-Mail geschützt] |
| @[E-Mail geschützt] |
Schritt 4
Erstellen Sie ein Perl-Skript pr-list-dbi.pl, das Daten aus der Datenbank db_website liest und mithilfe von HTML-Vorlagendateien eine Liste von Pressemitteilungen anzeigt (den Text dieses Skripts finden Sie auf unserer CD).
Lassen Sie uns nun das Code-Listing durchgehen und sehen, wie das Pressemitteilungen-Listing-Programm funktioniert.
Die Zeilen 1-9 sind wie ein Initialisierungsblock, in dem alle globalen Variablen und Konstanten deklariert sind:
41. #! / Local / usr / bin / perl 42.43. use DBI; 44. $ dbh = DBI-> connect (‘dbi: mysql: db_website’, ’root’, ’’); 45. $ path = "/local/usr/tpl"; 46. $ TPL_LIST = "$ Pfad / pr-list-tpl.htm"; 47. $ TPL_LIST_BLOCK = "$ path / pr-list-block-tpl.htm"; 48. 49. print "Inhaltstyp: Text / HTML \ n \ n";
Zuerst teilen wir dem Apache-Webserver einen Pfad mit, der angibt, wo sich der Perl-Interpreter befindet, der ausgeführt wird, wenn das Skript angefordert wird, es auf Fehler überprüft und dann ausführt. Als nächstes deklarieren wir das DBI-Modul (DataBase Interface), dessen Methoden im Programm verwendet werden, um mit der Datenbank zu interagieren (Zeile 3). Wir stellen dann eine Verbindung zu unserer Datenbank db_website (4) her und geben root (Administrator) als Login-Benutzernamen und einen leeren String (Standard) als Passwort an. Geben Sie in der Variablen $ path den Pfad an, in dem sich die HTML-Vorlagendateien befinden (5). In den Variablen $ TPL_LIST bzw. $ TPL_LIST_BLOCK geben wir deren Namen an (6, 7). Dann teilen wir dem Webserver mit, dass alle ausgehenden Daten im MIME-Text / HTML-Format dargestellt werden müssen, um den HTML-Stream an den Browser des Benutzers auszugeben (9).
Die Zeilen 11-22 stellen den Hauptteil des Programms dar:
50.51. öffnen (L, "$ TPL_LIST"); 52. während ($ line1 =
Öffnen Sie die Vorlagendatei pr-list-tpl.htm (11) und durchsuchen Sie sie in einer Schleife (12-20) und schreiben Sie jede gelesene Zeile in die Variable $ line. Während jeder Iteration prüfen wir, ob das Schlüsselwort @ in dieser Zeile vorhanden ist. [E-Mail geschützt](14-19), was bedeutet, dass Sie an dieser Stelle einen Block mit einer Pressemitteilung einfügen müssen. Sobald es gefunden wurde, rufen wir die Prozeduren read_db() und ins_data() auf.
Die Zeilen 26-39 sind der Hauptteil der Routine read_db(), die den Inhalt der Tabelle tbl_news_items liest, in der unsere Pressemitteilungen gespeichert sind:
64.65.66. sub read_db (67. $ c = 0; 68. my ($ sql) = "SELECT * FROM tbl_news_items"; 69. $ rs = $ dbh-> Prepare ($ sql); 70. $ rs -> ausführen; 71. while (my $ ref = $ rs-> fetchrow_hashref ()) (72. $ id [$ c] = "$ ref -> ('col_id')"; 73. $ title [$ c] = " $ ref -> ('col_title')"; 74. $ author [$ c] = "$ ref -> ('col_author')"; 75. $ date [$ c] = "$ ref -> (' col_date ' ) "; 76. $ c ++; 77.) 78. $ rs-> beenden (); 79.)
Wir initialisieren den Zähler $ c = 0, stellen eine Abfrage zusammen, um alle Daten aus der Tabelle (28) auszuwählen, führen die Abfrage aus (29, 30) und holen die Daten in das Recordset (Recordset) $ rs. Dann extrahieren wir in einer Schleife (31-37) Daten aus dem Recordset mit der Methode fetshrow_hashref und geben einen Verweis auf das assoziative Array% ref (31) zurück, das die Namen und Werte der Felder des aktuellen Datensatzes enthält. Die extrahierten Daten (32-35) schreiben wir entsprechend ihrem Typ in die üblichen Arrays @id, @title, @author und @date. Wir schließen den Datensatz (38).
Die Zeilen 41-53 sind der Hauptteil der Prozedur ins_data(), die das Einfügen von aus der Datenbank extrahierten Daten in den ausgehenden Datenstrom implementiert; Zeilen 55-63 - der Rumpf der Prozedur pr_block(), die in einer Schleife von der Prozedur ins_data() aufgerufen wird:
80. 81. sub ins_data (82. $ toread = "pr-read-dbi.pl"; 83. for ($ i = 0; $ i<$c; $i++) { 84. $line = &pr_block; 85. 86. $line =~ s/\@NUMBER\@/$id[$i]/; 87. $line =~ s/\@TITLE\@/$title[$i]/; 88. $line =~ s/\@AUTHOR\@/$author[$i]/; 89. $line =~ s/\@DATE\@/$date[$i]/; 90. $line =~ s/\@READ\@/$toread/; 91. print "$line"; 92. } 93. } 94. 95. sub pr_block { 96. my($block) = ‘’; 97. open (B, "$TPL_LIST_BLOCK"); 98. while ($line=) (99. $ Block = $ Block. $ Linie; 100.) 101. schließen (B); 102. zurück ($-Block); 103.)
Nachdem wir also den Maximalwert des Zählers $ c als Ergebnis der Prozedur read_db() erhalten haben, führen wir in der Schleife (43-52) die Prozedur pr_block() aus, die den Inhalt des pr-list-blocks liest. tpl.htm HTML-Template und schreibt es in die Variable $ block (59), die dann in der Variable $ line (44) der Prozedur ins_data() zurückgegeben (62) wird. Weiter im gleichen Zyklus ersetzen wir (46-50) die Schlüsselwörter @, die im ausgehenden $-Zeilenstrom gefunden wurden [E-Mail geschützt], @[E-Mail geschützt], @[E-Mail geschützt], @[E-Mail geschützt], @[E-Mail geschützt] auf die Werte der Arrays @id, @title, @author, @date und der Variablen $ toread entsprechend dieser Schleifeniteration ($ i).
Anzeige des Textes der Pressemitteilung
Nachdem wir eine Liste aller in der Datenbank verfügbaren Pressemitteilungen ( Reis. 4), müssen Sie dem Benutzer die Möglichkeit geben, den Text einer von ihnen anzuzeigen (das entsprechende Skript finden Sie auch auf unserer CD).
Das neue Skript pr-read-dbi.pl wird sich geringfügig von dem bereits erstellten pr-list-dbi.pl unterscheiden.
Diese Auflistung ist zu 98% der Auflistung 1 ähnlich, jedoch mit einigen geringfügigen Unterschieden:
- verbundene CGI-Bibliothek zum Lesen des Parameters id (9) aus dem Abfragestring (zum Beispiel http: //localhost/cgi-bin/pr-content-dbi.pl? id = 1);
- nur ein HTML-Template wird verwendet (pr-content-tpl.htm);
- die Datenbankabfrage wird durch eine bedingte SQL-WHERE-Klausel ergänzt, um alle Daten auszuwählen, die einer bestimmten Pressemitteilung durch die Kennung col_id entsprechen;
- das Feld col_body mit dem Text der ausgewählten Pressemitteilung wird ebenfalls aus der Datenbank gelesen.
Erstellen einer neuen Pressemitteilung
Wir werden die Funktionalität unseres Systems erweitern, indem wir die Möglichkeit hinzufügen, neue Pressemitteilungen zu erstellen, ohne direkt mit der Datenbank arbeiten zu müssen, um die Tabelle tbl_news_items mit neuen Informationen aufzufüllen.
Das neue Perl-Programm (das sich wie die beiden vorherigen auf der CD befindet) wird sich also von den vorherigen vor allem dadurch unterscheiden, dass es nicht dazu gedacht ist, Daten anzuzeigen, sondern sie der Datenbank hinzuzufügen. Daher müssen wir den für die Interaktion mit der Datenbank zuständigen Teil leicht ändern, indem wir die SQL INSERT-Abfrage und die entsprechenden Anweisungen des DBI-Moduls verwenden.
Die Zeilen 12-18 sind der Hauptteil des Hauptprogramms:
12. if ($ cmd ne "add") (13. & show_form; 14.) else (15. $ dbh = DBI-> connect ('dbi: mysql: db_website', _ 'root', ''); 16 . & add_pr; 17.dbh-> trennen; 18.)
Hier prüfen wir, ob das Team eingetroffen ist, um die Pressemitteilung in die Datenbank aufzunehmen. Sobald es ankommt, bauen wir eine Verbindung zur Datenbank auf (15), führen das Unterprogramm app_pr() aus (16) und beenden die Verbindung (17). Gab es keinen Befehl, dann zeigen wir einfach das Ausfüllformular (13) für die Pressemitteilungsdaten an - die Prozedur show_form().
Die Zeilen 20-36 sind der Hauptteil der pr_add()-Routine zum Hinzufügen von Pressemitteilungen:
19. 20. sub add_pr (21. $ title = $ q-> param ("pr_title"); 22. $ author = $ q-> param ("pr_author"); 23. $ body = $ q-> param ( "pr_body"); 24. $ body = ~ s / \ r \ n /
/ g; 25.26.my ($ sql) = "INSERT INTO tbl_news_items (col_title, col_author, col_body, col_date) VALUES (\ '$ title \', \ '$ author \', \ '$ body \', CURDATE ()) "; 27. $rs = $dbh-> do ($sql); 28.29.if ( [E-Mail geschützt]) (30. $ rc = $ dbh-> Rollback; 31.) else (32. $ rc = $ dbh-> commit; 33.) 34. 35. print "Speicherort: / cgi-bin / pr-list-dbi .pl \ n \ n "; 36.)
Zunächst verarbeiten wir die Daten des Formulars (22-25), verfassen eine SQL-Abfrage (27) und führen diese mit der DBI-Methode $ dbh-> do () aus (27) . Da hier der Vorgang zum Einfügen von Daten in die Datenbank durchgeführt wird, müssen Sie im Fehlerfall auf die Möglichkeit achten, den Vorgang abzubrechen. Dazu haben wir den Transaktionsrückgängig- und Rollback-Code in den vorherigen Zustand (30-34) eingefügt. Wenn $ dbh-> do() fehlschlägt, machen Sie die vorgenommenen Änderungen rückgängig (31). Wenn der Fehler nicht aufgetreten ist, bestätigen wir die vorgenommenen Änderungen (33). Gehen Sie dann nach all den Aktionen einfach auf die Seite mit einer Liste aller Pressemitteilungen (36).
Die Zeilen 37-55 sind der Rumpf des Formularausgabeverfahrens zur Eingabe von Informationen über die neue Pressemitteilung (es wird das HTML-Template verwendet, dessen Name in der Variablen $ TPL_INSERT, pr-add-tpl.htm, angegeben ist):
37. 38. sub show_form (39. print "Content-type: text / html \ n \ n"; 40. 41. open (L, "$ TPL_INSERT"); 42. while ($ line =
Systemüberladung
Da Sie eine dynamische Website entwickeln, kann die Informationsmenge darauf sehr schnell anwachsen. Darüber hinaus steigt mit der Popularität Ihrer Ressource auch die Anzahl ihrer Besucher, was zu Serverüberlastungen, d. h. zu einer Verringerung der Systemleistung, führen kann. Bevor Sie nach Möglichkeiten suchen, die Leistung der Hardware zu erhöhen und die Konfiguration eines neuen Systems zu finden, können Sie versuchen, eine der möglichen Ursachen für einen übermäßigen RAM-Verbrauch zu beseitigen. Das gleiche Perl kann der Schuldige sein. Tatsache ist, dass der Webserver jedes Mal, wenn Sie auf ein bestimmtes Perl-Skript zugreifen, den Interpreter in den Arbeitsspeicher lädt (er nimmt 500-1000 KB auf der Festplatte in Anspruch) und dieser das Programm von Anfang bis Ende auf der Suche nach Syntaxfehlern analysiert ... Danach liest er es erneut, initialisiert Variablen und Funktionen, liest die Eingabedaten (Parameter), verarbeitet und gibt die Ergebnisse zurück. Können Sie sich vorstellen, was passiert, wenn Pressemitteilungen gleichzeitig Hunderte von Besuchern Ihrer Website anzeigen möchten?
Um diesen Prozess zu beschleunigen, wurden spezielle Lösungen entwickelt, die zusätzliche Module für den Apache-Webserver sind - mod_fastcgi und mod_perl.
Das FastCGI-Modul (mod_fastcgi) geht von einem umfangreichen Einsatz von Datenaustauschwerkzeugen zwischen laufenden Prozessen (Tasks) des Betriebssystems aus. Zu Beginn seiner Arbeit aktiviert der Webserver das CGI-Programm und lässt das Programm und mehrere Kopien davon im Hintergrund laufen. Alle Anfragen an das Programm werden einfach auf die bereits aktiven Kopien übertragen, was den Server von der zusätzlichen Last entlastet, die mit der erneuten Aktivierung des Prozesses verbunden ist.
Das Modul mod_perl ermöglicht es Ihnen, Perl im gleichen Adressraum wie der Apache-Webserver selbst in den Arbeitsspeicher zu laden und Perl im Speicher zu belassen, bis dieser beendet wird, wodurch verhindert wird, dass die nächste Kopie des Interpreters beim Zugriff auf das CGI-Programm geladen wird. Dieses Modul wird häufiger als FastCGI verwendet, da es keine Programmänderungen erfordert.
ComputerPresse 6 "2001
Die Oberfläche zur Verwaltung statischer Seiten besteht aus einem integralen Block, auf dem sich verschiedene Elemente befinden (Abbildung 5.1).
Tatsächlich zeigt diese Seite eine Tabelle mit den Spalten "Titel" und "Seitenadresse" an.
Oben befindet sich ein Eingabefeld, in dem Sie angeben können, wie viele statische Seiten in der Paginierung angezeigt werden sollen.
Auch verfügbar 3 Massenoperationen auf statischen Seiten - Löschen, Veröffentlichen, Aufheben der Veröffentlichung.
Hinzufügen einer neuen Seite
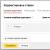
Um eine neue Seite hinzuzufügen, klicken Sie auf den Reiter „Statische Seite hinzufügen“ (Abbildung 5.2).
Danach werden Sie auf eine Seite mit einem Formular weitergeleitet, das Sie ausfüllen müssen. (Abbildung 5.3).

Abb. 5.3
Beachtung: das Titelfeld und der Hauptteil der Seite selbst sind erforderlich.
Üerschrift- Der Name der neuen Seite wird angezeigt. Titeldaten sind der Inhalt des Title-Tags, das in der Titelleiste des Browserfensters angezeigt wird.
Alt. Name- Hier müssen Sie einen Link zu dieser Seite angeben. Beachtung: Der Link muss lateinisch sein und darf keine Sonderzeichen und Leerzeichen enthalten.
Beschreibung- Wird verwendet, um eine kurze Beschreibung der Seite zu erstellen, die von Suchmaschinen zur Indexierung verwendet wird.
Stichworte- Schlüsselwörter für das Schlüsselwort-Meta-Tag.
- Veröffentlichen - Wenn dieses Flag ausgewählt ist, wird diese Seite nicht auf der Site angezeigt.
- Verwendung von HTML-Tags zulassen - Wenn dieses Flag ausgewählt ist, können Sie im Hauptteil der Seite zusätzlich zu BB-Codes HTML-Tags verwenden.
- Automatische Formatierung deaktivieren - Wenn dieses Flag ausgewählt ist, werden die automatische Textformatierung, der Zeilenumbruch usw. deaktiviert.
Die Vorlage muss sich im Verzeichnis / templates / (template_name) / static / befinden und muss die Erweiterung .tpl haben