PostgreSQL: inštalácia, konfigurácia, údržba.
PostgreSQL priamo z krabice nemožno použiť na použitie s 1C. Čo je potrebné, je upravená verzia z 1C, ktorá mení PostgreSQL na blokátor a musíte pochopiť, že zámky budú použité na celý stôl naraz. Ak potrebujete zámky na úrovni záznamov, zapnite režim kontrolovaných zámkov v 1C a zapíšte ich do konfigurácie pomocou držadiel. Záver: musíte stiahnuť špeciálnu distribúciu z lokality 1C alebo prevziať ITS disk.
inštalácia
Samotná inštalácia nespôsobuje žiadne zvláštne problémy, musíte venovať pozornosť správnej inicializácii databázy, menovite nastavenie lokality, potom ju môžete zmeniť iba inicializáciou znova. Napríklad základňa 1C s ukrajinskými regionálnymi nastaveniami v DBMS s inštalovaným ruským miestom sa nezavedie. Áno, problémy s triedením nie sú potrebné. Preto robíme init podľa požadovaného jazyka.
Pre ruský jazyk
initdb - locale = en_RU.UTF-8 - lc-collate = en_RU.UTF-8 - lc-ctype = en_RU.UTF-8 - kódovanie = UTF8 -D / db / postgresql
Pre ukrajinský jazyk
initdb - locale = uk_UA.UTF-8 - lc-collate = uk_UA.UTF-8 - lc-ctype = uk_UA.UTF-8 - kódovanie = UTF8 -D / db / postgresql
kde / db / postgresql je váš dátový adresár PostgreSQL. Kódovanie je samozrejme UTF-8.
Podrobná možnosť obnovenia klastra
1. Musí sa vydávať plné práva na priečinok, v ktorom sme nainštalovali program PostgreSQL, zvyčajne C: \\ Program Files \\ PostgreSQL
2. Z práva spravovať správcu cmd. Ak sa to stane vo win7, potom spustite od administrátora.
3. Vytvorte priečinok, na ktorom bude klastr uložený. Napríklad d: \\ postgredata.
md d: \\ postgredata
4. Inicializáciu klastra vykonáme ručne, pričom špecifikujeme cestu, kde sa bude nachádzať.
"C: \\ Program Files \\ PostgreSQL \\ 9.1.2-1.1C \\ bin \\ initdb.exe" -D d: \\ postgredata - locale = Russian_Russia - kódovanie = UTF8 -U postgres
5. Odstráňte službu PostgreSQL, ktorá bola nainštalovaná počas inštalácie.
sc odstrániť pgsql-9.1.2-1.1C-x64
Kde pgsql-9.1.2-1.1C-x64 je názov služby. Ak nepoznáte presne toto meno, môžete si prezrieť vlastnosti služby "PostgreSQL Database Server ..." (Štart - Ovládací panel - Nástroje pre správu - Služby)
6. Vytvárame novú službu v našom klastri
"C: \\ Program Files \\ PostgreSQL \\ 9.1.2-1.1C \\ bin \\ pg_ctl" zaregistrovať -N pgsql -U postgresql -P heslo -D d: / postgredata
7. Teraz ideme do služby. Štart - Ovládací panel - Správa - Služby a spustite službu.
Chyba databázy DBMS: Chyba: nové kódovanie (UTF8) nie je kompatibilné s databázou šablón (WIN1251).
TIP: Používajte rovnaké kódovanie ako v databáze šablón alebo použite template0 ako šablónu.
Pri inštalácii DBMS (WIN1251) pre server a klienta ste vybrali nesprávne miestne nastavenie, musíte v konfigurácii zmeniť na UTF-8 alebo opätovne nainštalovať DBMS s nasledujúcimi parametrami:
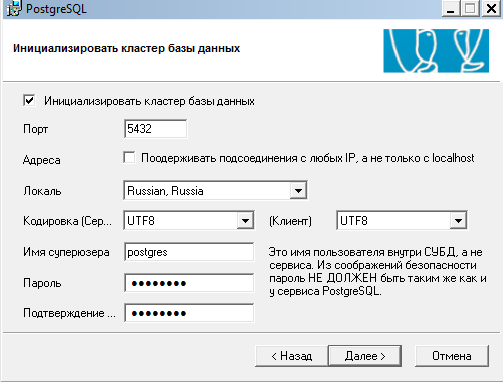
pozorpri inštalácii NEZVOLENE nastavenia OS operačného systému, vyberte zo zoznamu Russian, Russia
PostgreSQL nastavenie
Je potrebné pamätať na odporúčanie 1C nepoužívať PLNÝ VONKAJŠÍ PRIPOJENIE v žiadostiach o konštrukciu a nahradiť ju napríklad kombináciou niekoľkých ľavých spojení. Existuje tiež známy problém so stratou výkonu v dopytoch, kde sa používa spojenie s virtuálnou tabuľkou.
Nakonfigurujte konfiguráciu úpravou súboru postgresql.conf.
Najdôležitejšie parametre
effective_cache_size = 0,5 kapacity RAM
fsync = vypnúť vypnúť reset na disk po každom prenose (Upozornenie! Používajte iba pri použití spoľahlivého UPS, hrozí riziko straty dát, ak dôjde k neočakávanému vypnutiu)
synchronous_commit = vypnúť vypnutie synchronizovaného záznamu (riziká sú rovnaké ako pri fsync)
wal_buffers = 0,25 kapacity RAM
Po nastavení nezabudnite reštartovať službu:
služba postgresql restart
Nastavenie siete
Pre pripojenie klientov 1C na server z vonkajšej strany a prevádzkovanie databázového servera na bráne firewall musia byť otvorené nasledujúce porty:
Serverový agent (ragent) & tcp: 1540 Hlavný manažér klastrov (rmngr) & tcp: 1541 Rozsah sieťových portov pre dynamické rozdelenie pracovných tokov & tcp: 1560 & 1591, tcp: 5432 & Postgresql. Vytvorte pravidlo prostredníctvom štandardného rozhrania alebo pomocou príkazu:
netsh advfirewall firewall pridať pravidlo name = "1Cv8-Server" dir = v akcii = povoliť protokol = TCP localport = 1540,1541,5432,1560-1590 enable = yes profil = ľubovoľný remoteip = ANY interfacetype = LAN
Teraz z iného počítača začneme tichým spôsobom klient 1C: Enterprise, pridajte existujúcu databázu newdb. Nezabudnite na licenciu, ochranu softvéru a hardvéru.
zálohovanie
Vytvorte príkaz výpisu databázy
su postgres -c "pg_dump -U postgres -Fc -Z9 -f base1.sql base1"
Obnova zo skládky
su postgres-c "pg_restore -U postgres -c -d base1 -v base1.sql"
Pravidelná údržba
su postgres -c "/ usr / bin / vacuumdb --dbname = $ i --analyzovať - úplne"
Zobraziť aktivitu služby PostgreSQL
Niekedy je užitočné zistiť, čo server robí teraz. Tento návrh pomôže:
sledovať-n 1 "ps auxww | grep ^ postgres"
PostgreSQL je objektovo-relačný databázový systém, ktorý má vlastnosti tradičnej komerčnej databázy s rozšíreniami, ktoré budú k dispozícii pre ďalšiu generáciu DBMS (databázové systémy).
inštalácia
Ak chcete nainštalovať PostgreSQL, spustite nasledujúci príkaz v termináli:
Sudo apt-get nainštalovať postgresql
Bezprostredne po inštalácii môžete prispôsobiť server PostgreSQL podľa svojich potrieb, hoci štandardné nastavenie je celkom životaschopné.
nastavenie
Predvolene sú blokované pripojenia cez protokol TCP / IP. PostgreSQL podporuje viacero autentifikačných metód. Metóda overovania IDENT používané pre postgres a miestni používatelia ešte nenakonfigurovali niečo iné. Pozrite sa, či použijete akúkoľvek alternatívu, ako je Kerberos.
Ďalšia diskusia predpokladá, že budete povoliť pripojenie TCP / IP a používať autentifikáciu klienta na základe MD5. Konfiguračné súbory PostgreSQL sú uložené v adresári / etc / postgresql /
Konfigurácia autentifikácie ident Pridajte položky do súboru /etc/postgresql/8.4/main/pg_ident.conf. Súbor obsahuje podrobné poznámky, ktoré vás sprevádzajú.
Ak chcete povoliť pripojenie cez protokol TCP / IP, upravte súbor /etc/postgresql/8.4/main/postgresql.conf. Nájdite riadok
#listen_addresses = "localhost"
a nahraďte ho:
Listen_addresses = "localhost"
Ak chcete povoliť pripojenie iných počítačov k vášmu PostgreSQL serveru, nahraďte "localhost" IP adresou vášho servera alebo alternatívne 0,0.0.0 na pripojenie všetkých rozhraní.
Môžete tiež upraviť akékoľvek ďalšie parametre, ak viete, čo robíte! Ďalšie podrobnosti nájdete v komentároch súborov možností alebo v dokumentácii programu PostgreSQL.
Keďže sa môžeme pripojiť k nášmu serveru PostgreSQL, ďalším krokom je nastavenie hesla pre používateľa. postgres, Spustite nasledujúci príkaz v termináli na pripojenie k štandardnej databáze šablón PostgreSQL:
Sudo-u postgres psql template1
Tento príkaz sa pripojí k šablóne databázy PostgreSQL 1 ako používateľ postgres. Po pripojení k serveru PostgreSQL sa budete nachádzať v konzole SQL. V konzole môžete spustiť nasledujúci príkaz SQL psql nastaviť heslo používateľa postgres:
ALTER USER posiela šifrované heslo "your_password";
Po nastavení hesla zmeňte súbor /etc/postgresql/8.4/main/pg_hba.conf, aby ste použili autentifikáciu MD5 pre používateľa postgres:
Lokálne všetky postgres md5
Nakoniec budete musieť reštartovať službu PostgreSQL, aby ste mohli použiť nové nastavenia. Z terminálu vykonajte nasledujúce kroky na reštartovanie PostgreSQL:
Sudo /etc/init.d/postgresql-8.4 restart
Toto nastavenie je neúplné. Ďalšie možnosti nájdete v Príručke administrátora služby PostgreSQL.
Niečo o konfigurácii PostgreSQL
* Existuje alternatíva k MSSQL?
* PostgreSQL - brzda alebo vynikajúce DBMS?
* Ako spraviť PostgreSQL v plnej rýchlosti?
Tento článok nepredstihuje úplné vysvetlenie všetkých konfiguračných funkcií PostgreSQL av porovnávacích testoch nezahŕňajú všetky režimy databázy. Záujemcovia odporúčajú študovať knihu na odkaz
vstup
Pracoval som s PostgreSQL a považujem za vynikajúce DBMS. Mám multi-gigabajtú pracovnú databázu (nie 1C), ktorá spracováva obrovské dátové súbory okamžite. PostgreSQL vynikajúco využíva indexy, dobre sa vyrovná paralelným pracovným zaťaženiam, funkcia uložených procedúr je až do značiek, existujú dobré administratívne nástroje a vylepšené výkony mimo škatuľky a komunita vytvorila užitočné nástroje, Ale bol som prekvapený, keď zistil, že mnohí administrátori 1C majú názor o PostgreSQL, ktorý nie je až par, že je pomalý a sotva prevyšuje súborovú verziu databázy a iba MSSQL môže ušetriť deň.
Po preskúmaní otázky som našiel veľa článkov postgreSQL inštalácia Kroky pre figuríny, a to ako v systéme Linux aj pod Windows. Ale drvivá väčšina článkov opisuje inštaláciu predtým, ako bola "zriadená - vytvoríme základňu" a vôbec sa nedotýkajte otázky konfigurácie. V zostávajúcej konfigurácii sa spomína iba na úrovni "predpísať takéto hodnoty", prakticky bez vysvetlenia prečo.
A ak je prístup založený na "jednom tlačidle" použiteľný pre MSSQL a vo všeobecnosti pre mnohé produkty pod Windows, bohužiaľ sa to netýka PostgreSQL. Predvolené nastavenie výrazne obmedzuje používanie pamäte tak, aby bolo možné ho nainštalovať aj na kalkulačku a nezasahovalo do práce so zvyškom softvéru. PostgreSQL musí byť nutne konfigurovaný pre konkrétny systém a až potom sa bude môcť ukázať príležitosti. V závažných prípadoch môžete vyladiť nastavenia PostgreSQL, databázy a súborový systém ale je to skôr Linuxový systém, kde je viac možností konfigurovať všetko a všetko.
Treba pripomenúť, že PostgreSQL od vývojárov DBMS, kompilovaných len z patched zdrojového kódu, nie je vhodný pre 1C. Pripravené kompatibilné zostavy ponúkajú 1C (prostredníctvom diskov ITS a kancelárie pre tých, ktorí majú predplatné na podporu) a EterSoft
Testovanie bolo vykonané v prostredí systému Windows, ale všetky odporúčania na prispôsobenie nie sú špecifické pre platformu a sú použiteľné pre ľubovoľný operačný systém.
Testovanie a porovnanie
Pri testovaní som nenastavil úlohu vykonať testy vo všetkých režimoch a scenároch práce, iba hrubú kontrolu úspešnej konfigurácie.
Na testovanie som použil nasledujúcu konfiguráciu:
Hostiteľský počítač: Win7, Core i5-760 2.8MHz, 4 jadrá, 12GB RAM, VMWare 10
Virtuálne: Win7 x64, 2 jadrá, 4 GB RAM, samostatné fyzické pevný disk na prispôsobenie databázy (nie SSD)
MSSQL Express 2014
PostgreSQL EtherSoft 9.2.1
1C 8.3.5 1383
Použili sme databázu s dT-vykládkou 780 MB.
Po obnovení databázy:
veľkosť súboru 1CD vo verzii súboru - 10 GB,
veľkosť databázy PostgreSQL je 8 GB
veľkosť databázy MSSQL - 6,7 GB.
Pri skúške som použil žiadosť o výber vzorky zmlúv zmluvných strán (21 k) so vzorkou ďalších podrobností z rôznych registrov a pre každú zmluvu bola skutočne vytvorená samostatná vzorka z registrov. Vzal som konfiguráciu, ktorá bola k dispozícii - výrazne upravená na základe účtovníctva 3.0.
Pri testovaní som niekoľkokrát vykonal dotaz s jedným a dvoma klientmi, až kým nebudú získané stabilné výsledky. Ignoroval som prvé spustenie.
Testovanie jedným klientom:
Odber vzoriek na hostiteľovi z verzie súboru so základňou na jednotke SSD - 31s
Vzor z verzie súboru v virtuálny stroj (s pevný disk) - 46c
Odber vzoriek z databázy MSSQL - prvý priechod - 25 alebo 9 s (zrejme závisí od relevantnosti vyrovnávacej pamäte DBMS) (spotreba pamäte procesu DBMS bola približne 1,3 GB)
Odber vzoriek z PostgreSQL s predvolenými nastaveniami - 43s (spotreba pamäte nepresiahla 80 MB na pripojenie)
Príklad optimalizovanej PostgreSQL - 21s (spotreba pamäte bola 120 MB na pripojenie)
Testovanie dvoma klientmi:
Ukážka na hostiteľovi z verzie súboru so základňou na jednotke SSD - 34c
Odber vzoriek z verzie súboru vo virtuálnom stroji (z pevného disku) - 56 c
Odber vzoriek z databázy MSSQL - o 50 alebo 20 s (zrejme v závislosti od relevantnosti vyrovnávacej pamäte DBMS)
Odber vzoriek z PostgreSQL s predvolenými nastaveniami je 60 sekúnd
Odber vzoriek z optimalizovaného PostgreSQL - 40s
Poznámky k testovaniu:
- Po pridaní tretieho jadra začali varianty PostgreSQL a MSSQL pracovať v teste "dva klienti" prakticky s výkonom testu "one client", t. J. úspešne paralelizované. To, čo im bránilo paralelizovať prácu na dvoch jadrách, zostáva pre mňa záhadou.
- MSSQL zachytáva veľa pamäte naraz, PostgreSQL požadoval výrazne menej vo všetkých režimoch, a hneď po dokončení dotazu takmer všetko bolo prepustené.
- MSSQL funguje ako jediný proces. PostgreSQL beží na samostatnom procese pripojenia + servisných procesov. To umožňuje aj 32-bitovú verziu efektívne využívať pamäť pri spracovaní požiadaviek od niekoľkých klientov.
- Zvýšenie pamäte pre systém PostgreSQL v nastaveniach na základe nasledujúcich hodnôt neviedlo k výraznému zvýšeniu výkonu.
- Prvé testy vo všetkých prípadoch trvali dlhšie ako v následných meraniach, nekonkrétne merali, ale subjektívne MSSQL začal rýchlejšie.
Konfigurácia PostgreSQL
Existuje výborná kniha o konfigurovaní a optimalizácii PostgreSQL v ruštine: pre každého staviteľa slonov je zmysluplné označiť tento odkaz. Kniha opisuje množstvo techník na optimalizáciu DBMS, vytvárajúcich tolerantné a distribuované systémy. Ale teraz sa pozrieme na to, čo je užitočné pre všetkých - konfiguráciu využitia pamäte. PostgreSQL nepoužíva viac pamäte, ako sú povolené nastaveniami, a so štandardnými nastaveniami PostgreSQL používa minimálnu pamäť. V tomto prípade nie je potrebné špecifikovať viac pamäte ako je k dispozícii na použitie - systém začne používať pagingový súbor so všetkými nasledujúcimi smutnými dôsledkami pre výkonnosť servera. Séria tipov o konfigurácia PostgreSQL sú uvedené na disku ITS.
V oknách konfiguračné súbory PostgreSQL je umiestnený v inštalačnom adresári v adresári Data:
- postgresql.conf - hlavný súbor s nastaveniami DBMS
- pg_hba.conf súbor s nastaveniami prístupu pre klientov. Najmä tu môžete určiť, ktorí používatelia, z ktorých adresy IP sa môžete pripojiť k určitým databázam a či je potrebné skontrolovať používateľské heslo a ak áno, akou metódou.
- pg_ident.conf - súbor s konverziou názvov používateľov zo systému na interný (je nepravdepodobné, že to bude potrebovať väčšina používateľov)
Textové súbory môžete upravovať poznámkový blok. Riadky začínajúce na # sú považované za pripomienky a ignorované.
Parametre týkajúce sa množstva pamäte môžu byť doplnené o prípony kB, MB, GB - kilobajty, megabajty, gigabajty, napríklad 128 MB. Parametre popisujúce časové intervaly môžu byť doplnené o prípony ms, s, min, h, d - milisekundy, sekundy, minúty, hodiny, dni, napríklad 5min
Ak ste zabudli heslo na postregresiu - na tom nezáleží, môžete napísať pg_hba.conf riadok:
Hostite všetky dôverné 127.0.0.1/32
A pripojiť každý užívateľ (napríklad, postgres) do DBMS na lokálnom počítači na 127.0.0.1 bez kontroly hesla.
optimalizácia využitie pamäte
Nastavenia pamäte sú umiestnené v priečinku postgresql.conf
Optimálne hodnoty parametrov závisia od množstva voľných rAM, veľkosť základne a jednotlivé prvky databázy (tabuľky a indexy), zložitosť dotazov (v zásade stojí za to spoliehať sa na to, že otázky budú dosť zložité - viacnásobné pripojenia v dotazoch sú typickým scenárom) a počet súčasne aktívnych klientov. Mimochodom, PostgreSQL ukladá tabuľky a indexy databáz v samostatných súboroch (<каталог установки PG>\\ data \\ base \\<идентификатор БД>\\) a veľkosť objektov môže byť odhadnutá. Môžete tiež použiť dodávaný nástroj pgAdmin na pripojenie k databáze, otvoriť "Schémy" - "verejné" a generovať štatistický výkaz pre prvok "Tabuľky".
Ďalej uvádzam približné hodnoty, pomocou ktorých je možné začať s nastavením. po počiatočné nastavenie Odporúča sa riadiť server v prevádzkových režimoch a monitorovať spotrebu pamäte. V závislosti od získaných výsledkov budete možno musieť upraviť hodnoty parametrov.
Pri nastavovaní servera na testovanie som sa spoliehal na nasledujúce výpočty:
Len 4 GB RAM. Spotrebitelia - Windows, 1C server, PostgreSQL a cache disku. Vychádzal som z toho, že pre DBMS môžete prideliť až 2,5 GB RAM
Hodnoty je možné špecifikovať s príponami kB, MB a GB (hodnoty v kilobajtoch, megabajtoch alebo gigabajtoch). Po zmene hodnôt musíte reštartovať službu PostgreSQL.
shared_buffers - Server shared buffer
Veľkosť vyrovnávacej pamäte pre čítanie a zápis PostgreSQL, ktorá je spoločná pre všetky pripojenia. Ak údaje nie sú v cache, čítajú sa z disku (operačný systém môže byť uložený do vyrovnávacej pamäte)
Ak množstvo vyrovnávacej pamäte nestačí na ukladanie často používaných prevádzkových údajov, potom sa budú neustále písať a čítať z vyrovnávacej pamäte OS alebo z disku, čo negatívne ovplyvní výkon.
Ale to nie je všetka pamäť potrebná pre prácu, nemali by ste určiť príliš veľa hodnoty, inak nebude existovať žiadna pamäť pre skutočné vykonanie požiadaviek zákazníkov (a tým väčšia spotreba pamäte), a pre OS a iné aplikácie, napríklad proces servera 1C. Server sa tiež spolieha na vyrovnávaciu pamäť systému OS a snaží sa udržať vo vyrovnávacej pamäti, čo je s najväčšou pravdepodobnosťou systémom uložené do vyrovnávacej pamäte.
Používa sa v teste
shared_buffers = 512MB
work_mem - pamäť na triedenie, zhromažďovanie údajov atď.
Je priradená pre každú požiadavku, možno viackrát pre komplexné dopyty. Ak nie je dostatok pamäte, PostgreSQL použije dočasné súbory. Ak je hodnota príliš veľká, môže dôjsť k prekročeniu pamäte RAM a OS začne používať stránkovací súbor so zodpovedajúcim poklesom výkonu.
V výpočtoch sa odporúča, aby sa zobralo množstvo dostupnej pamäte mínus shared_buffers, a rozdeliť podľa počtu súčasne vykonaných dopytov. V prípade zložitých dopytov by mal byť deliteľ zvýšený, t.j. znížiť výsledok. Pre daný prípad, založený na 5 aktívnych používateľoch (2.5Gb-0.5GB (shared_buffers)) / 5 = 400MB. Ak DBMS považuje dopyty za dosť zložité, alebo ďalších používateľov, bude potrebné znížiť hodnotu.
Pre jednoduché dopyty sú dostatočne malé hodnoty - až niekoľko megabajtov, ale pre komplexné dopyty (a to je typický scenár pre 1C), bude potrebné viac. Odporúčanie - pre pamäť 1-4 GB môžete použiť hodnoty 32-128Mb. V použitom teste
work_mem = 128 MB
maintenance_work_mem - pamäť pre príkazy na zhromažďovanie odpadu, štatistiky, vytváranie indexov.
Odporúča sa nastaviť hodnotu na 50-75% veľkosti najväčšej tabuľky alebo indexu, ale aby bola dostatočná pamäť pre systém a aplikácie. Odporúča sa, aby hodnoty boli väčšie ako work_mem. V použitom teste
maintenance_work_mem = 192MB
temp_buffers Buffer pre dočasné objekty, hlavne pre dočasné tabuľky.
Môžete nastaviť poradie 16 MB. V použitom teste
temp_buffers = 32 MB
effective_cache_size - približný objem diskovej vyrovnávacej pamäte súborového systému.
Optimalizátor použije túto hodnotu pri vytváraní plánu dopytu na odhad pravdepodobnosti nájdenia údajov v cache (s rýchlym náhodným prístupom) alebo na pomalom disku. V systéme Windows je možné zobraziť aktuálnu veľkosť pamäte priradenej k vyrovnávacej pamäti v správcovi úloh.
Autovacuum - "zber odpadu"
PostgreSQL ako typický zástupca "verzií" DBMS (na rozdiel od blokovania) nezávisle blokuje pri zmene údajov v tabuľke a pri čítaní transakcií pri čítaní (v prípade 1C samotný server 1C to robí). Namiesto toho sa vytvorí kópia upraveného záznamu, ktorý sa stáva viditeľným pre následné transakcie, zatiaľ čo aktívne pokračujú v zobrazovaní údajov, ktoré sú relevantné na začiatku ich transakcie. V dôsledku toho sa tabuľky zhromažďujú zastaralé údaje - predchádzajúce verzie upravených záznamov. Aby mohol DBMS využívať uvoľnený priestor, je potrebné vykonať "zbierku odpadkov" - aby ste určili, ktoré záznamy sa už nepoužívajú. To sa dá urobiť explicitne pomocou príkazu SQL. VACUUM, alebo počkajte, kým tabuľka nebude spracovaná automatickým zberačom odpadu - AUTOVACUUM, Tesne pred určitou verziou bola zbierka odpadov spojená so zhromažďovaním štatistík (plánovač používa údaje o počte záznamov v tabuľkách a distribúcii hodnôt indexovaných polí na vytvorenie optimálneho plánu dopytu). Na jednej strane je potrebné zhromažďovať odpadky tak, aby tabuľky nerastúvali a efektívne využívali miesto na disku. Na druhej strane náhle spustený zber odpadu spôsobuje ďalšie zaťaženie na disku a tabuľkách, čo vedie k zvýšeniu času vykonávania dopytu. Podobný efekt vytvára automatické zhromažďovanie štatistických údajov (samozrejme, že ho môže spustiť príkaz ANALÝZA alebo spoločne so zberom odpadu ANALÝZA VÁKUA). A hoci od verzie po verziu PostgreSQL zlepšuje tieto mechanizmy na minimalizáciu negatívneho vplyvu na výkon (napríklad v starších verziách zbierka odpadkov úplne zablokoval prístup k tabuľke od verzie 9.0, VACUUM zrýchlené), je tu niečo nakonfigurovať.
Autovacuum môžete úplne vypnúť nastavením:
autovacuum = vypnuté
Autovacuum tiež vyžaduje parameter track_counts =, inak to nebude fungovať.
V predvolenom nastavení sú obe možnosti povolené. Autovakum nemôže byť úplne vyradený - dokonca aj pri autovacuum = niekedy (po veľkom počte transakcií) začne autovakum.
poznámka: VACUUM zvyčajne neznižuje veľkosť súboru tabuľky, označuje iba voľné, opakovane použiteľné oblasti. Ak potrebujete fyzicky uvoľniť viac miesta a minimalizovať priestor na disku, potrebujete príkaz VAKUUM FULL, Táto možnosť blokuje prístup k tabuľke v čase spustenia a zvyčajne sa nevyžaduje, aby ju používala. Ďalšie informácie o používaní príkazu VACUUM nájdete v dokumentácii (v angličtine).
Ak Autovacuum nie je úplne zakázaný, môžete nastaviť jeho účinok na vykonanie dopytu pomocou nasledujúcich parametrov:
autovacuum_max_workers - Maximálny počet paralelne bežiacich procesov čistenia.
autovacuum_naptime je minimálny interval, ktorý autovacuum nespustí. Predvolená hodnota je 1 minúta. Môžete zvýšiť, potom s častými zmenami v analýze údajov bude vykonávaná menej často.
autovacuum_vacuum_threshold, - počet zmenených alebo odstránených položiek v tabuľke potrebných na spustenie procesu zhromažďovania odpadu VACUUM alebo zber štatistických údajov ANALÝZA, Predvolená hodnota je 50.
autovacuum_vacuum_scale_factor , autovacuum_analyze_scale_factor - koeficient veľkosti tabuľky v záznamoch pridaných do autovacuum_vacuum_threshold a autovacuum_analyze_threshold resp. Predvolené hodnoty sú 0,2 (tj 20% z počtu položiek) a 0,1 (10%).
Zvážte príklad s tabuľkou pre 10 000 položiek. Potom, keď sa po 50 + 10000 * 0,1 = 1050 zmenených alebo odstránených záznamov predvolené nastavenia, zbierajú štatistiky ANALÝZA, a po 2050 zmenách - zber odpadu VACUUM.
Ak zvýšíte prahovú hodnotu a hodnotu faktora scale_factor, procesy údržby sa budú vykonávať menej často, ale malé tabuľky môžu výrazne rásť. Ak databáza pozostáva hlavne z malých tabuliek, celkové zvýšenie obsadeného miesta na disku môže byť významné, a preto je možné tieto hodnoty zvýšiť, ale s mysľou.
Preto môže byť zmysluplné zvýšiť interval autovacuum_naptime a trochu zvýšiť prahovú hodnotu a faktor_zmeny. V načítaných základoch môže byť alternatívou k výraznému zvýšeniu faktora scale_factor (hodnota 1 umožní tabuľkám "bobtnať" dvakrát) a zapísať do plánovača denné vykonávanie ANALÝZA VÁKUA v období minimálneho zaťaženia databázy.
default_statistics_target - priradí množstvo štatistických údajov získaných príkazom ANALÝZA, Predvolená hodnota je 100. Väčšie hodnoty zvyšujú dobu vykonania príkazu ANALYZE, ale umožňujú plánovačovi zostaviť efektívnejšie plány spúšťania dopytu. Existujú odporúčania na zvýšenie na 300.
Môže riadiť výkon AUTOVACUUM, takže je odolnejší, ale menej zaťažovací systém.
vacuum_cost_page_hit - veľkosť "pokuty" pre spracovanie bloku umiestneného v zdieľaných_bufferech. Je spojený s potrebou zablokovať prístup k vyrovnávacej pamäti. Predvolená hodnota je 1
vacuum_cost_page_miss - veľkosť "jemnej" pre spracovanie bloku na disku. Súvisí s uzamknutím vyrovnávacej pamäte, vyhľadávaním údajov v vyrovnávacej pamäti, čítaním údajov z disku. Predvolená hodnota je 10
vacuum_cost_page_dirty - Veľkosť "pokuty" na úpravu bloku. Súvisí s potrebou obnoviť upravené údaje na disk. Predvolená hodnota je 20
vacuum_cost_limit - maximálna veľkosť "jemných častí", po ktorých môže byť proces montáže "zmrznutý" na čas vacuum_cost_delay. Predvolená hodnota je 200
vacuum_cost_delay - čas "zmrazenia" procesu zberu odpadu s cieľom dosiahnuť hodnotu vacuum_cost_limit. Predvolená hodnota je 0 ms
autovacuum_vacuum_cost_delay - čas na "zmrazenie" procesu zberu odpadu pre autovakus. Predvolená hodnota je 20 ms. Ak je nastavená hodnota -1, použije sa hodnota vacuum_cost_delay.
autovacuum_vacuum_cost_limit - Maximálna veľkosť "pokuty" pre autovacuum. Predvolená hodnota je -1 - použije sa hodnota vacuum_cost_limit
Hlásené použitie vacuum_cost_page_hit = 6, vacuum_cost_limit = 100, autovacuum_vacuum_cost_delay = 200ms znižuje účinok AUTOVACUUM o až 80%, ale trojnásobne znižuje jeho čas vykonania.
Nastavenie písania na disk
Po dokončení transakcie PostgreSQL začne písať dáta do špeciálneho protokolu transakcií WAL (zápis pred zápisom) a potom do databázy po zapísaní údajov denníka na disk. Predvolený mechanizmus je fsynckeď PostgreSQL násilne prepláca dáta (log) z diskovej medzipamäte disku na disk a až po úspešnom písaní (log) je klient informovaný o úspešnom dokončení transakcie. Použitie denníka transakcií vám umožňuje dokončiť transakciu alebo obnoviť databázu, ak dôjde k chybe počas zápisu údajov.
V načítaných systémoch s veľkými objemami zápisu môže mať zmysel preniesť protokol transakcií na samostatný fyzický disk (ale nie na iný oddiel toho istého disku!). Ak to chcete urobiť, zastavte databázu DBMS, presuňte adresár pg_xlog na iné miesto a vytvorte symbolické prepojenie na starom mieste, napríklad pomocou pomôcky pre spojenie. Rovnaké prepojenia môžu vytvoriť Far Manager (Alt-F6). Zároveň sa musíte uistiť, že nová stránka má prístupové práva pre používateľa, z ktorého je spustený PostgreSQL (zvyčajne postgres).
Pri veľkom počte operácií na úpravu údajov môže byť potrebné zvýšiť hodnotu kontrolných bodov, ktoré regulujú množstvo údajov, ktoré možno očakávať, že sa budú prenášať z denníka do samotnej databázy. Predvolená hodnota je 3. Súčasne je potrebné vziať do úvahy, že medzera pridelená vzorcom (checkpoint_segments * 2 + 1) * 16 MB je priradená pre denník, ktorý s hodnotou 32 už bude vyžadovať viac ako 1 GB voľného miesta na disku.
PostgreSQL obnoví údaje z vyrovnávacej pamäte súborov OS na disk po každom dokončení transakcie písania. Na jednej strane to zaručuje, že údaje na disku sú vždy aktuálne, na druhej strane s veľkým počtom transakcií, poklesom výkonnosti. Zakázať úplne fsync je to možné, čo naznačuje
fsync = vypnuté
full_page_writes = vypnuté
Vykonajte to iba vtedy, ak ste 100% dôveryhodným vybavením a UPS (zdroj neprerušiteľného napájania). V opačnom prípade v prípade zlyhania systému hrozí riziko poškodenia databázy. A v každom prípade riadiaca jednotka RAID s batériou na napájanie pamäte nezaznamenaných údajov tiež neublíži.
Určitou alternatívou môže byť použitie parametra
synchronous_commit = vypnuté
V takomto prípade môže po úspešnej reakcii na dokončenie transakcie trvať nejaký čas, kým sa bezpečne zapíše disk. V prípade náhleho vypnutia sa databáza nezhasne, ale údaje o posledných transakciách sa môžu stratiť.
Ak fsync vôbec neaktivujete, môžete v parametri určiť metódu synchronizácie. Článok z disku ITS odkazuje na nástroj pg_test_fsync, ale nebol v mojom PostgreSQL. Podľa 1C, v ich prípade v systéme Windows, metóda open_datasync (zrejme sa táto metóda používa štandardne).
Ak existuje veľa malých písomných transakcií (v prípade 1C môže to byť masívna aktualizácia adresára mimo transakcie), môže pomôcť kombinácia parametrov commit_delay (čas oneskorenia ukončenia transakcie v mikrosekundách, predvolená hodnota 0) a commit_siblings (predvolená hodnota 5). Keď sú povolené možnosti, dokončenie transakcie môže byť oneskorené počas doby spánku commit_, ak sú v súčasnosti vykonávané aspoň transakcie transakcie commit_siblings transakcie. V tomto prípade bude výsledok všetkých dokončených transakcií zaznamenaný spolu, aby sa optimalizovalo písanie na disk.
Ďalšie parametre ovplyvňujúce výkonnosť
wal_buffers - množstvo pamäte v zdieľaných_obsahoch na uchovávanie protokolov transakcií. Odporúčanie - s 1 až 4 GB dostupnej pamäte použite hodnoty 256 kB-1 MB. Dokumentácia tvrdí, že hodnota "-1" sa automaticky zhoduje s hodnotou v závislosti od hodnoty shared_buffers.
random_page_cost - "Náklady" náhodného čítania, ktoré sa používajú pri vyhľadávaní údajov indexom. Predvolená hodnota je 4,0. Jednotka má čas na postupný prístup k údajom. Pri rýchlych diskových poliach, najmä SSD, je zmysluplné znížiť hodnotu, v tomto prípade PostgreSQL použije indexy aktívnejšie.
V knihe na linke sú niektoré ďalšie parametre, ktoré je možné nakonfigurovať. Tiež dôrazne odporúčame prečítať dokumentáciu programu PostgreSQL na účely konkrétnych parametrov.
Parametre zo sekcie QUERY TUNING, najmä pokiaľ ide o zákaz plánovača pomocou špecifických metód vyhľadávania, sa odporúčajú meniť len vtedy, ak máte plné pochopenie toho, čo robíte. Je veľmi jednoduché optimalizovať jeden typ dopytu a zbaliť výkon všetkých ostatných. Účinnosť zmeny väčšiny parametrov v tejto časti závisí od údajov v databáze, požiadaviek na tieto údaje (to znamená na verzii použitého 1C vrátane) a verzie DBMS.
záver
PostgreSQL je výkonný systém správy databáz v pravých rukách, ale vyžaduje si dôkladnú konfiguráciu. Môže sa použiť spolu s 1C a získať slušnú rýchlosť a jeho voľný bude veľmi príjemný bonus.
Kritika a dodatky k tomuto článku sú vítané.
Užitočné odkazy
http://postgresql.leopard.in.ua/ - knižná stránka " Práca s ladením a škálovaním služby PostgreSQL ", čo je najkomplexnejší a najrozumnejší sprievodca podľa môjho názoru o konfigurácii a správe PostgreSQL
http://etersoft.ru/products/postgre - tu si môžete stiahnuť aplikáciu PostgreSQL kompatibilnú s 1C pod Windows a rôzne distribúcie a verzie Linuxu. Pre tých, ktorí nemajú predplatné ITS alebo vyžadujú verziu pod verzia Linuxktorý nie je prezentovaný na v8.1cc.
http://www.postgresql.org/docs/9.2/static/ - oficiálna dokumentácia PostgreSQL (v angličtine)
Články z disku ITS pre konfiguráciu PostgreSQL
Článok histórie úprav
- 01/29/2015 - zverejnená pôvodná verzia
- 01/31/2015 - článok je doplnený o časť o AUTOVACUUM, bol pridaný odkaz na pôvodnú dokumentáciu.
V budúcnosti mám v úmysle otestovať prácu DBMS v spôsobe pridávania a modifikácie údajov.
- cvičenie
Chcel som vytvoriť úžasnú a komplexnú príručku Getting Start bez vody, ale vrátane základných buniek pre začiatočníkov, ktorí používajú systém PostgreSQL v systéme Linux.
PostgreSQL je objektovo-relačný databázový systém riadenia (ORDBMS) založený na POSTGRES, verzia 4.2, vyvinutá na University of California v Berkeley Department of Computer Science.
PostgreSQL je otvoreným zdrojovým pôvodcom pôvodného kódu Berkeley. Podporuje väčšinu štandardov SQL a ponúka mnoho pokročilých funkcií:
- Komplikované dopyty
- Spravovanie konkurenčného prístupu s viacerými verziami
- dátových typov
- funkcie
- prevádzkovatelia
- súhrnné funkcie
- index metód
- procedurálnych jazykov
Montáž a inštalácia
Rovnako ako všetci fanúšikov PostgreSQL, budeme samozrejme budovať a neťahovávať hotové balíky (napríklad nie sú žiadne repozitáre Debianu najnovšiu verziu). Tu je veľa verzií, samozrejme najlepšie sťahovanie je najnovšie. V čase zápisu tohto príspevku je verzia 9.2.2Wget http://ftp.postgresql.org/pub/source/v9.2.2/postgresql-9.2.2.tar.gz tar xzf postgresql-9.2.2.tar.gz
Teraz máme zdrojový adresár tejto vynikajúcej databázy.
V predvolenom nastavení sú databázové súbory nainštalované v adresári / usr / local / pgsql, ale tento adresár sa dá zmeniť zadaním
Prefix = / path / to / pgsql
pred príkazom / configure
Pred budovaním môžete zadať kompilátor C ++
Export CC = gcc
PostgeSQL môže použiť knižnicu readline, ak ju nemáte a nechcete ju nainštalovať, stačí zadať túto možnosť
Without-readline
Dúfam, že každý má autotools? Potom postúpte do zostavy:
Cd postgresql-9.2.2 ./configure - bez čítania sudo urobte inštaláciu čistou
Všetci páni! Blahoželáme!
nastavenie
Musíme určiť ukladanie dát v našich databázach (klastroch) a spustiť ich.Existuje jedna výstraha - vlastník adresára údajov a používateľ, ktorý môže spustiť databázu, by nemal byť root. To sa deje pre bezpečnosť systému. Preto vytvoríme špeciálneho používateľa.
sudo useradd postgres -p postgres -U-m
A ďalšie je všetko jasné
Sudo chown -R pošta: postgres / usr / local / pgsql
Dôležitý proces. Musíme inicializovať skupinu melónov. Mali by sme to urobiť v mene používateľa postgres.
Initdb -D / usr / local / pgsql / dáta
Teraz je potrebné pridať spustenie programu PostgreSQL na automatické spustenie. Na to je pripravený skript a nachádza sa v postgresql-9.2.2 / contrib / start-scripts / linux
Tento súbor môžete otvoriť a venovať pozornosť nasledujúcim premenným:
- prefix - toto je miesto, kde sme nainštalovali PostgreSQL a nastavili sme ho v. / configure
- PGDATA - tam je miesto, kde je uložený databázový klastr a kde by náš prístupový používateľ mal mať prístup
- PGUSER - je to ten istý používateľ, v mene ktorého bude všetko fungovať
Sudo cp ./postgresql-9.2.2/contrib/start-scripts/linux/etc/init.d/postgres sudo update-rc.d postgres default
Reštartujte systém a skontrolujte, či funguje náš skript.
Predstavujeme
/ usr / local / pgsql / bin / psql -U postgres
A ak okno pracuje s databázou, konfigurácia bola úspešná! Blahoželáme!
Databáza sa štandardne vytvára pod názvom postgres
Teraz je dôležité hovoriť o metódach autorizácie.
Súbor /usr/local/pgsql/data/pg_hba.conf má na to potrebné nastavenia
# TYPE DATABASE UŽÍVATEĽ ADRESA metóda lokálne všetky všetky dôvery hostiteľ všetky všetky 127.0.0.1/32 dôverovať hostiteľ všetci všetci :: 1/128 trust
Prvý riadok zodpovedá za miestne pripojenie, druhý za pripojenie cez protokol IPv4 a tretí protokol IPv6.
Posledný parameter je len spôsob autorizácie. Jeho a zvážiť (iba základné)
- dôvera - prístup k databáze môže získať kohokoľvek pod akýmkoľvek menom, ktorý má s ňou spojenie.
- zamietnuť - bezpodmienečne odmietnuť! Toto je vhodné na filtrovanie určitých adries IP
- heslo - vyžaduje povinné zadanie hesla. Nie je vhodný pre lokálnych používateľov, len pre používateľov vytvorených príkazom CREATE USER
- ident - umožňuje iba používateľovi zaregistrovanému v súbore /usr/local/pgsql/data/pg_ident.conf vytvoriť spojenie s databázou.