Befehle in Assemblersprache. Grundlegende Befehle der Assemblersprache Kurze Beschreibung der Assemblersprachen
Damit die Maschine menschliche Befehle auf Hardwareebene ausführen kann, ist es notwendig, eine bestimmte Abfolge von Aktionen in der Sprache der „Nullen und Einsen“ festzulegen. Assembler wird in dieser Angelegenheit ein Assistent. Dies ist ein Dienstprogramm, das mit der Übersetzung von Befehlen in Maschinensprache arbeitet. Das Schreiben eines Programms ist jedoch ein sehr zeitaufwändiger und komplexer Prozess. Diese Sprache ist nicht dazu gedacht, einfache und einfache Aktionen zu erstellen. Im Moment können Sie mit jeder verwendeten Programmiersprache (Assembler funktioniert gut) spezielle effiziente Aufgaben schreiben, die den Betrieb der Hardware stark beeinflussen. Der Hauptzweck besteht darin, Mikroanweisungen und kleine Codes zu erstellen. Diese Sprache bietet mehr Funktionen als beispielsweise Pascal oder C.
Kurze Beschreibung der Assemblersprachen
Alle Programmiersprachen sind in Ebenen unterteilt: niedrig und hoch. Jedes der syntaktischen Systeme der „Familie“ von Assembler unterscheidet sich dadurch, dass es einige der Vorteile der gängigsten und modernsten Sprachen auf einmal vereint. Sie sind auch dadurch mit anderen verwandt, dass Sie das Computersystem voll nutzen können.
Ein besonderes Merkmal des Compilers ist seine Benutzerfreundlichkeit. Darin unterscheidet es sich von denen, die nur mit hohen Pegeln arbeiten. Berücksichtigt man eine solche Programmiersprache, arbeitet Assembler doppelt so schnell und besser. Um ein leichtes Programm darin zu schreiben, wird es nicht zu viel Zeit in Anspruch nehmen.
Kurz über die Struktur der Sprache
Wenn wir allgemein über die Arbeit und Struktur der Funktionsweise der Sprache sprechen, können wir mit Sicherheit sagen, dass ihre Befehle vollständig mit den Befehlen des Prozessors übereinstimmen. Das heißt, der Assembler verwendet mnemonische Codes, die für eine Person am bequemsten zu schreiben sind.
Im Gegensatz zu anderen Programmiersprachen verwendet Assembler bestimmte Labels anstelle von Adressen, um Speicherzellen zu schreiben. Sie werden mit dem Code-Ausführungsprozess in die sogenannten Direktiven übersetzt. Dies sind relative Adressen, die den Betrieb des Prozessors nicht beeinflussen (sie werden nicht in Maschinensprache übersetzt), aber für die Erkennung durch die Programmierumgebung selbst erforderlich sind.
Jede Prozessorlinie hat ihre eigene In dieser Situation ist jeder Prozess korrekt, einschließlich des übersetzten.
Die Assemblersprache hat mehrere Syntaxen, die in diesem Artikel besprochen werden.

Sprachprofis
Die wichtigste und bequemste Anpassung der Assemblersprache wird sein, dass sie verwendet werden kann, um jedes Programm für den Prozessor zu schreiben, der sehr kompakt sein wird. Wenn der Code sehr groß ist, werden einige Prozesse in den Arbeitsspeicher umgeleitet. Gleichzeitig arbeiten sie alle ziemlich schnell und fehlerfrei, es sei denn, sie werden natürlich von einem qualifizierten Programmierer gesteuert.
Treiber, Betriebssysteme, BIOS, Compiler, Interpreter usw. sind alle Programme in Assemblersprache.
Wenn Sie einen Disassembler verwenden, der von Maschine zu Maschine übersetzt, können Sie leicht verstehen, wie diese oder jene Systemaufgabe funktioniert, auch wenn es keine Erklärungen dafür gibt. Dies ist jedoch nur möglich, wenn die Programme leicht sind. Leider ist es ziemlich schwierig, nicht-triviale Codes zu verstehen.
Nachteile der Sprache
Leider ist es für Programmieranfänger (und oft Profis) schwierig, die Sprache zu verstehen. Der Monteur benötigt eine detaillierte Beschreibung der erforderlichen Anweisung. Aufgrund der Tatsache, dass Sie Maschinenanweisungen verwenden müssen, steigt die Wahrscheinlichkeit fehlerhafter Aktionen und die Komplexität der Ausführung.
Um auch nur das einfachste Programm zu schreiben, muss der Programmierer qualifiziert und sein Wissensstand hoch genug sein. Der durchschnittliche Spezialist schreibt leider oft schlechte Codes.
Wenn die Plattform, für die das Programm erstellt wird, aktualisiert wird, müssen alle Befehle manuell neu geschrieben werden - dies wird von der Sprache selbst verlangt. Der Assembler unterstützt nicht die Funktion der automatischen Regulierung des Zustands von Prozessen und des Austauschs von Elementen.

Sprachbefehle
Wie oben erwähnt, hat jeder Prozessor seinen eigenen Befehlssatz. Die einfachsten Elemente, die von jedem Typ erkannt werden, sind die folgenden Codes:

Direktiven verwenden
Das Programmieren von Mikrocontrollern in der Sprache (Assembler erlaubt dies und funktioniert hervorragend) der untersten Ebene endet in den meisten Fällen erfolgreich. Verwenden Sie am besten Prozessoren mit begrenzten Ressourcen. Für die 32-Bit-Technologie passt diese Sprache perfekt. Sie können Anweisungen oft in Codes sehen. Was ist das? Und wofür wird es verwendet?
Zunächst muss betont werden, dass Direktiven nicht in Maschinensprache übersetzt werden. Sie bestimmen, wie der Compiler arbeitet. Im Gegensatz zu Befehlen unterscheiden sich diese Parameter mit unterschiedlichen Funktionen nicht aufgrund unterschiedlicher Prozessoren, sondern aufgrund eines unterschiedlichen Übersetzers. Zu den wichtigsten Richtlinien gehören:

Herkunft des Namens
Wie heißt die Sprache - "Assembler"? Die Rede ist von einem Übersetzer und einem Compiler, die die Daten verschlüsseln. Aus dem Englischen bedeutet Assembler nichts anderes als ein Assembler. Das Programm wurde nicht von Hand kompiliert, es wurde ein automatischer Aufbau verwendet. Darüber hinaus haben Benutzer und Spezialisten im Moment bereits den Unterschied zwischen den Begriffen gelöscht. Assembler wird oft als Programmiersprache bezeichnet, obwohl es nur ein Dienstprogramm ist.
Aufgrund der allgemein akzeptierten Sammelbezeichnung haben einige Leute die irrige Annahme, dass es eine einzige Low-Level-Sprache (oder Standardnormen dafür) gibt. Damit der Programmierer versteht, um was für eine Struktur es sich handelt, muss geklärt werden, für welche Plattform diese oder jene Assemblersprache verwendet wird.

Makro-Tools
Assemblersprachen, die relativ neu sind, verfügen über Makrofunktionen. Sie erleichtern sowohl das Schreiben als auch das Ausführen eines Programms. Aufgrund ihrer Anwesenheit führt der Übersetzer den geschriebenen Code um ein Vielfaches schneller aus. Beim Erstellen einer bedingten Auswahl können Sie einen riesigen Befehlsblock schreiben, aber es ist einfacher, Makros zu verwenden. Sie ermöglichen es Ihnen, schnell zwischen Aktionen zu wechseln, falls eine Bedingung erfüllt oder nicht erfüllt ist.
Bei der Verwendung von Makrosprachendirektiven erhält der Programmierer Assembler-Makros. Manchmal kann es weit verbreitet sein, und manchmal ist seine Funktionalität auf einen einzigen Befehl reduziert. Ihre Anwesenheit im Code erleichtert die Arbeit damit, macht ihn verständlicher und visueller. Sie sollten jedoch immer noch vorsichtig sein - in einigen Fällen verschlechtern Makros im Gegenteil die Situation.
Thema 2.5 Grundlagen der Prozessorprogrammierung
Mit zunehmender Länge des Programms wird es schwieriger, sich die Codes für verschiedene Operationen zu merken. Mnemotechniken bieten dabei eine gewisse Hilfe.
Die symbolische Befehlscodierungssprache wird aufgerufen Monteur.
Assemblersprache ist eine Sprache, in der jede Anweisung genau einem Maschinenbefehl entspricht.
Montage wird das Konvertieren eines Programms aus der Assemblersprache genannt, dh das Erstellen eines Programms in Maschinensprache durch Ersetzen symbolischer Namen von Operationen durch Maschinencodes und symbolischer Adressen durch absolute oder relative Zahlen sowie das Einschließen von Bibliotheksprogrammen und das Generieren von Folgen symbolischer Anweisungen durch Spezifizieren spezifischer Parameter in Mikrobefehlen. Dieses Programm wird normalerweise im ROM abgelegt oder von einem externen Medium in den RAM eingegeben.
Die Assemblersprache hat mehrere Merkmale, die sie von Hochsprachen unterscheiden:
1. Dies ist eine Eins-zu-Eins-Entsprechung zwischen Anweisungen in Assemblersprache und Maschinenbefehlen.
2. Der Assembler-Programmierer hat Zugriff auf alle Objekte und Befehle, die auf der Zielmaschine vorhanden sind.
Ein Verständnis der Grundlagen der Programmierung in maschinennahen Sprachen ist hilfreich für:
Besseres Verständnis der PC-Architektur und bessere Nutzung von Computern;
Rationellere Strukturen von Algorithmen für Programme zur Lösung angewandter Probleme zu entwickeln;
Die Möglichkeit, ausführbare Programme mit den Erweiterungen .exe und .com, die aus beliebigen Hochsprachen kompiliert wurden, bei Verlust der Quellprogramme anzuzeigen und zu korrigieren (indem diese Programme in den DEBUG-Programmdebugger aufgerufen und ihre Anzeige in Assemblersprache dekompiliert werden );
Kompilieren von Programmen zur Lösung der kritischsten Aufgaben (ein in einer maschinenorientierten Sprache kompiliertes Programm ist normalerweise effizienter - kürzer und um 30-60 Prozent schneller als Programme, die durch Übersetzung aus Hochsprachen erhalten werden)
Zur Implementierung von im Hauptprogramm enthaltenen Prozeduren als separate Fragmente für den Fall, dass diese weder in der verwendeten Hochsprache noch mit OS-Dienstprozeduren implementiert werden können.
Ein Programm in Assemblersprache kann nur auf Computern derselben Familie ausgeführt werden, während ein in einer Hochsprache geschriebenes Programm potenziell auf verschiedenen Computern ausgeführt werden kann.
Das Alphabet der Assemblersprache besteht aus ASCII-Zeichen.
Zahlen sind nur ganze Zahlen. Unterscheiden:
Binärzahlen, die mit dem Buchstaben B enden;
Dezimalzahlen, die mit D enden;
Hexadezimalzahlen, die mit dem Buchstaben N enden.
RAM, Register, Datendarstellung
Für eine bestimmte Reihe von MPs wird eine eigene Programmiersprache verwendet - die Assemblersprache.
Die Assemblersprache nimmt eine Zwischenstellung zwischen Maschinencodes und Hochsprachen ein. Das Programmieren in dieser Sprache ist einfacher. Ein Programm in Assemblersprache nutzt die Fähigkeiten einer bestimmten Maschine (genauer gesagt MP) rationeller als ein Programm in einer Hochsprache (was für einen Programmierer einfacher ist als für einen Assembler). Wir betrachten die Grundprinzipien der Programmierung in maschinennahen Sprachen am Beispiel der Assemblersprache für MP KR580VM80. Zum Programmieren in der Sprache wird eine allgemeine Technik verwendet. Spezifische Techniken zum Aufzeichnen von Programmen beziehen sich auf die Architektur und Befehlssystemmerkmale des Ziel-MP.
Softwaremodell eines Mikroprozessorsystems basierend auf MP KR580VM80
Das Programmmodell des MPS gemäß Bild 1
MP Ports Speicher
| S | Z | AC | P | C |
Bild 1
Aus Sicht des Programmierers hat der KR580VM80 MP die folgenden programmzugänglichen Register.
ABER– 8-Bit-Akkuregister. Es ist das Hauptregister von MP. Jede in der ALU durchgeführte Operation beinhaltet das Plazieren eines der zu verarbeitenden Operanden in den Akkumulator. Das Ergebnis der Operation in der ALU wird normalerweise auch in A gespeichert.
B, C, D, E, H, L– 8-Bit-Universalregister (RON). MP interner Speicher. Entwickelt, um die verarbeiteten Informationen sowie die Ergebnisse der Operation zu speichern. Bei der Verarbeitung von 16-Bit-Wörtern aus Registern werden Paare BC, DE, HL gebildet, und das Doppelregister wird als erster Buchstabe bezeichnet - B, D, H. Im Registerpaar ist das erste Register das höchste. Die H-, L-Register, die sowohl zum Speichern von Daten als auch zum Speichern von 16-Bit-Adressen von RAM-Zellen verwendet werden, haben eine besondere Eigenschaft.
FL– Flag-Register (Feature-Register) Ein 8-Bit-Register, das fünf Features des Ergebnisses der Durchführung arithmetischer und logischer Operationen im MP speichert. FL-Format laut Bild
Bit C (CY - Übertrag) - Übertrag, auf 1 gesetzt, wenn bei der Durchführung arithmetischer Operationen ein Übertrag von der höheren Ordnung des Bytes vorhanden war.
Bit P (Parität) - Parität, wird auf 1 gesetzt, wenn die Anzahl der Einheiten in den Bits des Ergebnisses gerade ist.
Das AC-Bit ist ein zusätzlicher Übertrag, der dazu bestimmt ist, den Übertragswert aus der unteren Tetrade des Ergebnisses zu speichern.
Bit Z (Null) – auf 1 gesetzt, wenn das Ergebnis der Operation 0 ist.
Das S-Bit (Vorzeichen) wird auf 1 gesetzt, wenn das Ergebnis negativ ist, und auf 0, wenn das Ergebnis positiv ist.
SP-- der Stapelzeiger, ein 16-Bit-Register, dient zum Speichern der Adresse des Speicherplatzes, an dem das zuletzt in den Stapel eingegebene Byte geschrieben wurde.
RS– Programmzähler (Programmzähler), 16-Bit-Register, zum Speichern der Adresse der nächsten ausführbaren Anweisung. Der Inhalt des Programmzählers wird automatisch um 1 erhöht, sobald das nächste Befehlsbyte geholt wird.
Im anfänglichen Speicherbereich der Adresse 0000H - 07FF befinden sich ein Steuerprogramm und Demoprogramme. Dies ist der ROM-Bereich.
0800 - 0AFF - Adressbereich zur Aufnahme der Studiengänge. (RAM).
0В00 - 0ВВ0 - Adressbereich für die Datenaufzeichnung. (RAM).
0BB0 ist die Startadresse des Stapels. (RAM).
Stack ist ein speziell organisierter RAM-Bereich, der zum vorübergehenden Speichern von Daten oder Adressen bestimmt ist. Die letzte Zahl, die auf den Stapel geschoben wird, ist die erste Zahl, die vom Stapel abgehoben wird. Der Stapelzeiger speichert die Adresse der letzten Stapelstelle, wo Informationen gespeichert sind. Beim Aufruf eines Unterprogramms wird die Rücksprungadresse zum Hauptprogramm automatisch auf dem Stack abgelegt. In der Regel werden zu Beginn jedes Unterprogramms die Inhalte aller an seiner Ausführung beteiligten Register auf dem Stack abgelegt und am Ende des Unterprogramms vom Stack wiederhergestellt.
Datenformat und Befehlsstruktur der Assemblersprache
Der Speicher MP KR580VM80 ist ein Array aus 8-Bit-Wörtern, die Bytes genannt werden.Jedes Byte hat seine eigene 16-Bit-Adresse, die seine Position in der Folge vonSpeicherzellen bestimmt. Der MP kann 65536 Byte Speicher adressieren, der sowohl ROM als auch RAM enthalten kann.
Datei Format
Daten werden im Speicher als 8-Bit-Wörter gespeichert:
D7 D6 D5 D4 D3 D2 D1 D0
Das niedrigstwertige Bit ist Bit 0, das höchstwertige Bit ist Bit 7.
Der Befehl ist durch das Format gekennzeichnet, d. h. die Anzahl der ihm zugeordneten Bits, die byteweise in bestimmte Funktionsfelder unterteilt sind.
Befehlsformat
MP KR580VM80-Befehle haben ein, zwei oder drei Byte Format. Multibyte-Anweisungen müssen in benachbarten PLs platziert werden. Das Format des Befehls hängt von den Besonderheiten der ausgeführten Operation ab.
Das erste Byte des Befehls enthält den in mnemonischer Form geschriebenen Opcode.
Es definiert das Format des Befehls und die Aktionen, die von dem MP an den Daten während seiner Ausführung durchgeführt werden müssen, sowie das Adressierungsverfahren und kann auch Informationen über den Speicherort der Daten enthalten.
Das zweite und dritte Byte können zu bearbeitende Daten oder Adressen enthalten, die den Ort der Daten angeben. Die Daten, an denen Operationen durchgeführt werden, werden Operanden genannt.
Single-Byte-Befehlsformat gemäß Abbildung 2
Figur 4
In Anweisungen in Assemblersprache hat der Opcode eine abgekürzte Schreibweise englischer Wörter - eine mnemonische Notation. Mnemonik (aus dem Griechischen mnemonisch – die Kunst des Auswendiglernens) erleichtert es, sich Befehle gemäß ihrem funktionalen Zweck zu merken.
Vor der Ausführung wird das Quellprogramm mit einem Übersetzungsprogramm, Assembler genannt, in die Sprache der Codekombinationen – Maschinensprache – übersetzt, in dieser Form im Speicher des MP abgelegt und dann bei der Ausführung des Befehls verwendet.
Adressierungsmethoden
Alle Operandencodes (Ein- und Ausgang) müssen irgendwo stehen. Sie können sich in den internen Registern des MP befinden (die bequemste und schnellste Option). Sie können sich im Systemspeicher befinden (die häufigste Option). Schließlich können sie sich in E / A-Geräten befinden (der seltenste Fall). Die Position der Operanden wird durch den Befehlscode bestimmt. Es gibt verschiedene Verfahren, durch die der Befehlscode bestimmen kann, woher der Eingangsoperand genommen und wo der Ausgangsoperand abgelegt werden soll. Diese Methoden werden als Adressierungsmethoden bezeichnet.
Für MP KR580VM80 gibt es folgende Adressierungsmethoden:
Sofortig;
Registrieren;
indirekt;
Stapel.
Sofortig Die Adressierung geht davon aus, dass sich der Operand (Eingabe) unmittelbar nach dem Befehlscode im Speicher befindet. Der Operand ist normalerweise eine Konstante, die irgendwo gesendet, zu etwas hinzugefügt werden muss usw. Daten sind im zweiten oder zweiten und dritten Byte der Anweisung enthalten, wobei das niedrige Datenbyte im zweiten Befehlsbyte und das hohe Datenbyte enthalten sind im dritten Befehlsbyte.
Gerade Die (auch als absolute) Adressierung geht davon aus, dass sich der Operand (Eingabe oder Ausgabe) im Speicher an der Adresse befindet, deren Code sich innerhalb des Programms unmittelbar nach dem Befehlscode befindet. Wird in Drei-Byte-Befehlen verwendet.
Registrieren Die Adressierung setzt voraus, dass der Operand (Eingang oder Ausgang) im internen MP-Register steht. Wird in Einzelbyte-Befehlen verwendet
Indirekt Die (implizite) Adressierung geht davon aus, dass das interne Register des MP nicht der Operand selbst ist, sondern seine Adresse im Speicher.
Stapel Die Adressierung setzt voraus, dass der Befehl keine Adresse enthält. Adressierung von Speicherzellen durch den Inhalt des 16-Bit-SP-Registers (Stapelzeiger).
Befehlssystem
Das MP-Befehlssystem ist eine vollständige Liste elementarer Aktionen, die der MP ausführen kann. Der von diesen Befehlen gesteuerte MP führt einfache Aktionen aus, wie z. B. elementare arithmetische und logische Operationen, Datenübertragung, Vergleich zweier Werte usw. Die Anzahl der Befehle des MP KR580VM80 beträgt 78 (einschließlich Modifikationen 244).
Es gibt folgende Befehlsgruppen:
Datenübertragung;
Arithmetik;
Rätsel;
Sprungbefehle;
Befehle für Input-Output, Steuerung und Arbeit mit dem Stack.
Symbole und Abkürzungen, die zur Beschreibung von Befehlen und zum Schreiben von Programmen verwendet werden
| Symbol | Die Ermäßigung |
| ADDR | 16-Bit-Adresse |
| DATEN | 8-Bit-Daten |
| DATEN 16 | 16-Bit-Daten |
| HAFEN | 8-Bit-E/A-Adresse (E/A-Geräte) |
| Byte 2 | Zweites Befehlsbyte |
| Byte 3 | Drittes Befehlsbyte |
| R, R1, R2 | Eines der Register: A, B, C, D, E, H, L |
| RP | Eines der Registerpaare: B - stellt ein Flugzeugpaar ein; D - setzt ein Paar DE; H - gibt ein Paar HL an |
| RH | Erstes Register des Paares |
| RL | Zweites Register des Paares |
| Λ | Boolesche Multiplikation |
| v | Boolesche Addition |
| Modulo-Zwei-Addition | |
| m | Speicherzelle, deren Adresse den Inhalt des HL-Registerpaares angibt, also M = (HL) |
1. PC-Architektur……………………………………………………………………5
1.1. Register.
1.1.1 Allzweckregister.
1.1.2. Segmentregister
1.1.3 Flaggenregister
1.2. Organisation des Gedächtnisses.
1.3. Daten Präsentation.
1.3.1 Datentypen
1.3.2 Zeichen- und Zeichenkettendarstellung
2. Erklärungen zum Vollversammlungsprogramm ……………………………………
Befehle in Assemblersprache
2.2. Adressierungsmodi und Maschinenbefehlsformate
3. Pseudo-Operatoren ………………………………………………………….
3.1 Datendefinitionsrichtlinien
3.2 Aufbau des Montageprogramms
3.2.1 Programmsegmente. Direktive annehmen
3.2.3 Vereinfachte Segmentierungsrichtlinie
4. Assemblieren und Linken des Programms ………………………….
5. Datenübertragungsbefehle…………………………………………….
5.1 Allgemeine Befehle
5.2 Stack-Befehle
5.3 E/A-Befehle
5.4 Adressweiterleitungsbefehle
5.5 Flag-Transfer-Befehle
6. Rechenbefehle ……………………………………………….
6.1 Arithmetische Operationen mit binären ganzen Zahlen
6.1.1 Addition und Subtraktion
6.1.2 Befehle zum Inkrementieren und Dekrementieren des Empfängers um eins
6.2 Multiplikation und Division
6.3 Vorzeichenwechsel
7. Logische Operationen ………………………………………………….
8. Schichten und zyklische Schichten …………………………………………
9. Stringoperationen …………………………………………………….
10. Logik und Organisation von Programmen ………………………………………
10.1 Bedingungslose Sprünge
10.2 Bedingte Sprünge
10.4 Prozeduren in Assemblersprache
10.5 Interrupts INT
10.6 Systemsoftware
10.6.1.1 Lesen der Tastatur.
10.6.1.2 Anzeigen von Zeichen auf dem Bildschirm
10.6.1.3 Beenden von Programmen.
10.6.2.1 Anzeigemodi auswählen
11. Festplattenspeicher ………………………………………………………………..
11.2 Dateizuordnungstabelle
11.3 Festplatten-E/A
11.3.1 Schreiben einer Datei auf die Festplatte
11.3.1.1 ASCIIZ-Daten
11.3.1.2 Aktenzeichen
11.3.1.3 Erstellen einer Festplattendatei
11.3.2 Lesen einer Diskettendatei
Einführung
Die Assemblersprache ist eine symbolische Darstellung der Maschinensprache. Alle Prozesse in einem Personal Computer (PC) auf der niedrigsten Hardwareebene werden nur durch Maschinensprachbefehle (Anweisungen) gesteuert. Ohne Assembler-Kenntnisse ist es unmöglich, hardwarebezogene Probleme (oder sogar hardwarebezogene Probleme, wie z. B. die Verbesserung der Geschwindigkeit eines Programms) wirklich zu lösen.
Assembler ist eine bequeme Form von Befehlen direkt für PC-Komponenten und erfordert Kenntnisse über die Eigenschaften und Fähigkeiten der integrierten Schaltung, die diese Komponenten enthält, nämlich des PC-Mikroprozessors. Somit steht die Assemblersprache in direktem Zusammenhang mit der internen Organisation des PCs. Und es ist kein Zufall, dass fast alle Compiler von Hochsprachen den Zugriff auf die Assembler-Programmierebene unterstützen.
Ein Element der Vorbereitung eines professionellen Programmierers ist notwendigerweise das Studium von Assembler. Dies liegt daran, dass die Programmierung in Assemblersprache Kenntnisse der PC-Architektur erfordert, die es Ihnen ermöglichen, effizientere Programme in anderen Sprachen zu erstellen und diese mit Programmen in Assemblersprache zu kombinieren.
Das Handbuch befasst sich mit der Programmierung in Assemblersprache für Computer, die auf Intel-Mikroprozessoren basieren.
Dieses Tutorial richtet sich an alle, die sich für die Architektur des Prozessors und die Grundlagen der Programmierung in Assembler interessieren, in erster Linie an die Entwickler des Softwareprodukts.
PC-Architektur.
Computerarchitektur ist eine abstrakte Darstellung eines Computers, die seine Struktur, Schaltkreise und logische Organisation widerspiegelt.
Alle modernen Computer haben einige gemeinsame und individuelle architektonische Eigenschaften. Individuelle Eigenschaften sind nur einem bestimmten Computermodell eigen.
Das Konzept der Computerarchitektur umfasst:
Blockdiagramm eines Computers;
Mittel und Methoden für den Zugriff auf die Elemente des Blockdiagramms eines Computers;
Satz und Verfügbarkeit von Registern;
Organisation und Methoden der Adressierung;
Präsentationsverfahren und Format von Computerdaten;
eine Reihe von Computermaschinenanweisungen;
Maschinenbefehlsformate;
Unterbrechungsbehandlung.
Die Hauptelemente der Computerhardware: Systemeinheit, Tastatur, Anzeigegeräte, Laufwerke, Druckgeräte (Drucker) und verschiedene Kommunikationsmittel. Die Systemeinheit besteht aus der Systemplatine, dem Netzteil und Erweiterungssteckplätzen für zusätzliche Platinen. Das Motherboard enthält den Mikroprozessor, den Nur-Lese-Speicher (ROM), den Direktzugriffsspeicher (RAM) und den Coprozessor.
Register.
Innerhalb des Mikroprozessors sind Informationen in einer Gruppe von 32 Registern (16 Benutzer, 16 System) enthalten, die dem Programmierer mehr oder weniger zur Verfügung stehen. Da sich das Handbuch der Programmierung des Mikroprozessors 8088-i486 widmet, ist es am logischsten, dieses Thema mit der Erörterung der internen Register des Mikroprozessors zu beginnen, die dem Benutzer zur Verfügung stehen.
Benutzerregister werden vom Programmierer zum Schreiben von Programmen verwendet. Zu diesen Registern gehören:
acht 32-Bit-Register (Allzweckregister) EAX/AX/AH/AL, EBX/BX/BH/BL, ECX/CX/CH/CL, EDX/DX/DLH/DL, EBP/BP, ESI/SI, EDI/DI, ESP/SP;
sechs 16-Bit-Segmentregister: CS, DS, SS, ES, FS, GS;
Status- und Steuerregister: EFLAGS/FLAGS-Flag-Register und EIP/IP-Befehlszeigerregister.
Teile eines 32-Bit-Registers werden durch einen Schrägstrich dargestellt. Das Präfix E (Extended) kennzeichnet die Verwendung eines 32-Bit-Registers. Um mit Bytes zu arbeiten, werden Register mit den Präfixen L (low) und H (high) verwendet, z. B. AL, CH - die Low- und High-Bytes der 16-Bit-Teile der Register bezeichnen.
Allgemeine Register.
EAX/AX/AH/AL(Akkumulatorregister) - Batterie. Wird bei Multiplikation und Division, bei E/A-Operationen und bei einigen Operationen mit Zeichenfolgen verwendet.
EBX/BX/BH/BL - Basisregister(Basisregister), wird häufig verwendet, wenn Daten im Speicher adressiert werden.
ECX/CX/CH/CL - Schalter(Zählregister), dient als Zähler für die Anzahl der Schleifenwiederholungen.
EDX/DX/DH/DL - Datenregister(Datenregister), das zum Speichern von Zwischendaten verwendet wird. Einige Befehle erfordern es.
Alle Register dieser Gruppe erlauben den Zugriff auf ihre "unteren" Teile. Nur die unteren 16- und 8-Bit-Teile dieser Register können für die Selbstadressierung verwendet werden. Die oberen 16 Bit dieser Register stehen nicht als eigenständige Objekte zur Verfügung.
Zur Unterstützung von Zeichenfolgenverarbeitungsbefehlen, die eine sequentielle Verarbeitung von Zeichenfolgen von Elementen mit einer Länge von 32, 16 oder 8 Bit ermöglichen, werden die folgenden verwendet:
ESI/SI (Quellindexregister) - Index Quelle. Enthält die Adresse des aktuellen Quellelements.
EDI/DI (Distanzregister) - Index Empfänger(Empfänger). Enthält die aktuelle Adresse im Zielstring.
In der Architektur des Mikroprozessors wird eine Datenstruktur, ein Stack, auf Hardware- und Softwareebene unterstützt. Um mit dem Stack zu arbeiten, gibt es spezielle Befehle und spezielle Register. Es ist zu beachten, dass der Stack zu kleineren Adressen hin gefüllt wird.
ESP/SP (Stapelzeigerregister) - registrieren Zeiger Stapel. Enthält einen Zeiger auf den Stapelanfang im aktuellen Stapelsegment.
EBP/BP (Basiszeigerregister) – Stapelbasiszeigerregister. Entwickelt, um den wahlfreien Zugriff auf Daten innerhalb des Stacks zu organisieren.
1.1.2. Segmentregister
Das Mikroprozessor-Softwaremodell hat sechs Segmentregister: CS, SS, DS, ES, GS, FS. Ihre Existenz ist auf die Besonderheiten der Organisation und Verwendung von RAM durch Intel-Mikroprozessoren zurückzuführen. Die Mikroprozessor-Hardware unterstützt die strukturelle Organisation des Programms bestehend aus Segmente. Segmentregister werden verwendet, um anzuzeigen, welche Segmente aktuell verfügbar sind. Der Mikroprozessor unterstützt die folgenden Arten von Segmenten:
Codesegment. Enthält Programmbefehle Um auf dieses Segment zuzugreifen, verwenden Sie das CS-Register (Code Segment Register) - Segmentcoderegister. Es enthält die Adresse des Maschinenbefehlssegments, auf das der Mikroprozessor Zugriff hat.
Datensegment. Enthält die vom Programm verarbeiteten Daten. Um auf dieses Segment zuzugreifen, wird das DS-Register (Datensegmentregister) verwendet - Segmentdatenregister, das die Adresse des Datensegments des aktuellen Programms speichert.
Stack-Segment. Dieses Segment ist ein Speicherbereich, der Stapel genannt wird. Der Mikroprozessor organisiert den Stack nach dem Prinzip – der Erste „kam“, der Erste „ging“. Um auf den Stack zuzugreifen, wird das SS-Register (Stack Segment Register) verwendet - Stapelsegmentregister A enthält die Adresse des Stapelsegments.
Zusätzliches Datensegment. Die zu verarbeitenden Daten können sich in drei weiteren Datensegmenten befinden. Standardmäßig wird davon ausgegangen, dass sich die Daten im Datensegment befinden. Bei Verwendung zusätzlicher Datensegmente müssen deren Adressen explizit durch spezielle Segment-Redefinition-Präfixe im Befehl angegeben werden. Adressen zusätzlicher Datensegmente müssen in den Registern ES, GS, FS (Extension Data Segment Registers) enthalten sein.
Steuer- und Statusregister
Der Mikroprozessor enthält mehrere Register, die Informationen über den Zustand sowohl des Mikroprozessors selbst als auch des Programms enthalten, dessen Anweisungen gerade in die Pipeline geladen werden. Das:
EIP/IP-Befehlszeigerregister;
EFLAGS/FLAGS-Flag-Register.
Mithilfe dieser Register können Sie Informationen über die Ergebnisse der Befehlsausführung erhalten und den Zustand des Mikroprozessors selbst beeinflussen.
EIP/IP (Befehlszeigerregister) - Zeiger Befehle. Das EIP/IP-Register ist 32 oder 16 Bit breit und enthält den Offset des nächsten auszuführenden Befehls relativ zu den Inhalten des CS-Segmentregisters im aktuellen Befehlssegment. Dieses Register ist nicht direkt zugänglich, wird aber durch Sprungbefehle verändert.
EFLAGS/FLAGS (Flaggenregister) - registrieren Flaggen. Bittiefe 32/16 Bit. Einzelne Bits dieses Registers haben einen bestimmten funktionalen Zweck und werden Flags genannt. Ein Flag ist ein Bit, das auf 1 ("Flag ist gesetzt") gesetzt ist, wenn eine Bedingung wahr ist, und andernfalls auf 0 ("Flag ist gelöscht"). Der untere Teil dieses Registers ist vollständig analog zum FLAGS-Register für den i8086.
1.1.3 Flaggenregister
Das Flag-Register ist 32 Bit groß und trägt den Namen EFLAGS (Bild 1). Einzelne Bits des Registers haben einen bestimmten funktionalen Zweck und werden Flags genannt. Jedem von ihnen ist ein bestimmter Name zugeordnet (ZF, CF usw.). Die unteren 16 Bits von EFLAGS stellen das 16-Bit-FLAGS-Register dar, das verwendet wird, wenn Programme ausgeführt werden, die für die i086- und i286-Mikroprozessoren geschrieben wurden.
Abb.1 Flaggenregister
Einige Flags werden Bedingungsflags genannt; Sie ändern sich automatisch, wenn Befehle ausgeführt werden, und legen bestimmte Eigenschaften ihres Ergebnisses fest (z. B. ob es gleich Null ist). Andere Flags werden Zustandsflags genannt; sie verändern sich vom Programm und beeinflussen das weitere Verhalten des Prozessors (zB blockieren sie Interrupts).
Bedingungsflags:
CF (Carry-Flag) - Flagge tragen. Sie nimmt den Wert 1 an, wenn beim Addieren ganzer Zahlen eine Übertragseinheit auftaucht, die nicht in das Bitraster „passt“, oder wenn beim Subtrahieren von Zahlen ohne Vorzeichen die erste kleiner ist als die zweite. Bei den Shift-Befehlen wird das Off-Grid-Bit in die CF eingetragen. CF behebt auch die Merkmale der Multiplikationsanweisung.
OF (Überlauf-Flag) Überlauf-Flag. Es wird auf 1 gesetzt, wenn beim Addieren oder Subtrahieren ganzer Zahlen mit Vorzeichen das Ergebnis modulo über dem zulässigen Wert erhalten wurde (die Mantisse ist übergelaufen und in das Vorzeichenbit "geklettert").
ZF (Nullfahne) Null-Flag. Auf 1 gesetzt, wenn das Ergebnis des Befehls 0 ist.
SF (SIGN-Flag) - Flagge Schild. Auf 1 setzen, wenn die Operation mit vorzeichenbehafteten Zahlen zu einem negativen Ergebnis führt.
PF (Paritätsflag) - Flagge Parität. Es ist gleich 1, wenn das Ergebnis des nächsten Befehls eine gerade Anzahl binärer Einsen enthält. Sie wird in der Regel nur bei I/O-Operationen berücksichtigt.
AF (Auxiliary Carry Flag) - zusätzliches Carry-Flag. Behebt die Funktionen zum Ausführen von Operationen mit Binär-Dezimal-Zahlen.
Statusflags:
DF (Richtungsflagge) Richtungsfahne. Legt die Richtung des Scannens von Zeilen in String-Befehlen fest: Mit DF=0 werden Zeilen "vorwärts" (von Anfang bis Ende) gescannt, mit DF=1 - in die entgegengesetzte Richtung.
IOPL (Eingabe-/Ausgabeberechtigungsebene) - E/A-Berechtigungsstufe. Wird im geschützten Modus des Mikroprozessors verwendet, um den Zugriff auf E / A-Befehle zu steuern, abhängig von der Berechtigung der Aufgabe.
NT (verschachtelte Aufgabe) Task-Verschachtelungsflag. Wird im geschützten Modus des Mikroprozessors verwendet, um die Tatsache aufzuzeichnen, dass eine Aufgabe in einer anderen verschachtelt ist.
Systemflag:
IF (INTERrupt-Flag) - Interrupt-Flag. Bei IF=0 reagiert der Prozessor nicht mehr auf ankommende Interrupts, bei IF=1 wird die Blockierung von Interrupts aufgehoben.
TF (Trap-Flag) Trace-Flag. Bei TF = 1 macht der Prozessor nach Ausführung jeder Anweisung einen Interrupt (mit der Nummer 1), der beim Debuggen eines Programms verwendet werden kann, um es zu verfolgen.
RF (Wiederaufnahme-Flag) Flagge wieder aufnehmen. Wird verwendet, wenn Interrupts von den Debug-Registern verarbeitet werden.
VM (virtueller 8086-Modus) - virtuelles 8086-Flag. 1 – der Prozessor arbeitet im virtuellen 8086-Modus 0 – der Prozessor arbeitet im realen oder geschützten Modus.
AC (Alignment check) - Ausrichtungskontrollflag. Entwickelt, um die Ausrichtungssteuerung beim Zugriff auf den Speicher zu ermöglichen.
Organisation des Gedächtnisses.
Der physische Speicher, auf den der Mikroprozessor Zugriff hat, wird aufgerufen Arbeitsgedächtnis ( oder Speicher mit wahlfreiem Zugriff RAM). RAM ist eine Kette von Bytes, die ihre eigene eindeutige Adresse (ihre Nummer) haben, genannt körperlich. Der physische Adressbereich liegt zwischen 0 und 4 GB. Der Speicherverwaltungsmechanismus ist vollständig hardwarebasiert.
Der Mikroprozessor unterstützt mehrere Modelle der RAM-Nutzung in der Hardware:
segmentiertes Modell. Bei diesem Modell wird der Programmspeicher in zusammenhängende Speicherbereiche (Segmente) unterteilt, und das Programm selbst kann nur auf Daten zugreifen, die sich in diesen Segmenten befinden;
Seitenmodell. In diesem Fall wird RAM als eine Gruppe von Blöcken mit einer festen Größe von 4 KB betrachtet. Die Hauptanwendung dieses Modells bezieht sich auf die Organisation des virtuellen Speichers, der es Programmen ermöglicht, mehr Speicherplatz als die Menge an physischem Speicher zu verwenden. Bei einem Pentium-Mikroprozessor kann die Größe des möglichen virtuellen Speichers bis zu 4 TB betragen.
Die Verwendung und Implementierung dieser Modelle hängt von der Betriebsart des Mikroprozessors ab:
Real-Adress-Modus (Real-Modus). Der Modus ähnelt dem Betrieb des i8086-Prozessors. Erforderlich für den Betrieb von Programmen, die für frühe Prozessormodelle entwickelt wurden.
Sicherheitsmodus. Im geschützten Modus wird es möglich, Informationsverarbeitung, Speicherschutz unter Verwendung eines vierstufigen Berechtigungsmechanismus und dessen Paging im Multitasking zu verarbeiten.
Virtueller 8086-Modus. In diesem Modus wird es möglich, mehrere Programme für i8086 auszuführen. In diesem Fall können Real-Modus-Programme funktionieren.
Die Segmentierung ist ein Adressierungsmechanismus, der die Existenz mehrerer unabhängiger Adressräume sicherstellt. Ein Segment ist ein unabhängiger, hardwareunterstützter Speicherblock.
Jedes Programm kann im Allgemeinen aus beliebig vielen Segmenten bestehen, hat aber direkten Zugriff auf die drei Hauptsegmente: Code, Daten und Stack – und auf ein bis drei zusätzliche Datensegmente. Das Betriebssystem legt Programmsegmente im RAM an bestimmten physikalischen Adressen ab und legt dann die Werte dieser Adressen in den entsprechenden Registern ab. Innerhalb eines Segments greift das Programm auf Adressen relativ zum Anfang des Segments linear zu, d. h. beginnend bei Adresse 0 und endend bei einer Adresse gleich der Größe des Segments. Relative Adresse bzw Voreingenommenheit, die der Mikroprozessor verwendet, um auf Daten innerhalb eines Segments zuzugreifen, aufgerufen Wirksam.
Bildung einer physikalischen Adresse im Realmodus
Im Real-Modus reicht der physikalische Adressbereich von 0 bis 1 MB. Die maximale Segmentgröße beträgt 64 KB. Bei Bezugnahme auf eine bestimmte physikalische Adresse RAM wird durch die Adresse des Segmentanfangs und den Offset innerhalb des Segments bestimmt. Die Segmentstartadresse wird dem entsprechenden Segmentregister entnommen. In diesem Fall enthält das Segmentregister nur die oberen 16 Bit der physikalischen Adresse des Segmentanfangs. Die fehlenden unteren vier Bits der 20-Bit-Adresse erhält man, indem man den Wert des Segmentregisters um 4 Bits nach links verschiebt. Die Verschiebungsoperation wird in Hardware durchgeführt. Der resultierende 20-Bit-Wert ist die tatsächliche physikalische Adresse, die dem Anfang des Segments entspricht. Also physische Adresse wird als ein "Segment:Offset"-Paar angegeben, wobei "Segment" die ersten 16 Bits der Startadresse des Speichersegments sind, zu dem die Zelle gehört, und "Offset" die 16-Bit-Adresse dieser Zelle ist, gezählt ab Anfang dieses Speichersegments (Wert 16*Segment + Offset ergibt die absolute Adresse der Zelle). Wenn beispielsweise der Wert 1234h im CS-Register gespeichert ist, dann definiert das Adresspaar 1234h:507h eine absolute Adresse gleich 16*1234h+507h = 12340h+507h = 12847h. Ein solches Paar wird in Form eines Doppelworts und (wie bei Zahlen) in einer "umgekehrten" Form geschrieben: Das erste Wort enthält den Offset und das zweite - das Segment, in dem jedes dieser Wörter wiederum dargestellt wird "umgekehrte" Form. Das Paar 1234h:5678h würde beispielsweise so geschrieben:| 78 | 56| 34 | 12|.
Dieser Mechanismus zur Bildung einer physikalischen Adresse ermöglicht es Ihnen, die Software verschiebbar zu machen, dh unabhängig von bestimmten Download-Adressen im RAM.
Allgemeine Informationen zur Assemblersprache
Die symbolische Assemblersprache ermöglicht es, die Mängel der Maschinensprachenprogrammierung weitgehend zu beseitigen.
Sein Hauptvorteil besteht darin, dass in der Assemblersprache alle Programmelemente in symbolischer Form dargestellt werden. Die Umwandlung symbolischer Befehlsnamen in ihre Binärcodes wird einem speziellen Programm - Assembler - zugewiesen, das den Programmierer von mühsamer Arbeit befreit und die unvermeidlichen Fehler beseitigt.
Symbolische Namen, die beim Programmieren in Assemblersprache eingeführt werden, spiegeln in der Regel die Semantik des Programms und die Abkürzung von Befehlen wider - ihre Hauptfunktion. Zum Beispiel: PARAM - Parameter, TABLE - Tabelle, MASK - Maske, ADD - Addition, SUB - Subtraktion usw. n. Der Programmierer kann sich solche Namen leicht merken.
Für die Programmierung in Assemblersprache sind komplexere Werkzeuge erforderlich als für die Programmierung in Maschinensprache: Sie benötigen Computersysteme auf der Basis von Mikrocomputern oder PCs mit einer Reihe von Peripheriegeräten (alphanumerische Tastatur, Zeichenanzeige, Diskettenlaufwerk und Druckgerät). sowie residente oder systemübergreifende Programmierung für die benötigten Mikroprozessortypen. Mit der Assemblersprache können Sie effektiv viel komplexere Programme schreiben und debuggen als mit der Maschinensprache (bis zu 1 - 4 KB).
Assemblersprachen sind maschinenorientiert, also abhängig von der Maschinensprache und Struktur des entsprechenden Mikroprozessors, da sie jeder Mikroprozessoranweisung einen bestimmten symbolischen Namen zuweisen.
Assemblersprachen sorgen im Vergleich zu Maschinensprachen für eine deutliche Steigerung der Produktivität von Programmierern und behalten gleichzeitig die Möglichkeit, alle per Software zugänglichen Hardware-Ressourcen des Mikroprozessors zu nutzen. Dadurch können erfahrene Programmierer Programme schreiben, die in kürzerer Zeit ablaufen und weniger Speicherplatz beanspruchen als Programme, die in einer Hochsprache geschrieben sind.
In dieser Hinsicht sind fast alle Steuerprogramme (Treiber) für E/A-Geräte in Assemblersprache geschrieben, obwohl eine ziemlich große Auswahl an Hochsprachen vorhanden ist.
Unter Verwendung der Assemblersprache kann der Programmierer die folgenden Parameter einstellen:
Mnemonik (symbolischer Name) jedes Befehls der Maschinensprache des Mikroprozessors;
Standardformat für Zeilen eines in Assembler beschriebenen Programms;
ein Format zum Spezifizieren verschiedener Adressierungsmethoden und Befehlsoptionen;
Format zur Angabe von Zeichenkonstanten und Konstanten vom Typ Integer in verschiedenen Zahlensystemen;
Pseudobefehle, die den Assemblierungsprozess (Übersetzung) des Programms steuern.
In der Assemblersprache wird das Programm Zeile für Zeile geschrieben, d. h. jeder Anweisung wird eine Zeile zugeordnet.
Für Mikrocomputer, die auf der Basis der gängigsten Mikroprozessortypen aufgebaut sind, kann es mehrere Varianten der Assemblersprache geben, aber man hat normalerweise eine praktische Verbreitung - dies ist die sogenannte Standard-Assemblersprache
Die Programmierung auf der Ebene von Maschinenbefehlen ist die Mindestebene, auf der eine Programmierung möglich ist. Das System der Maschinenbefehle muss ausreichen, um die erforderlichen Aktionen auszuführen, indem Anweisungen an die Computerhardware ausgegeben werden.
Jeder Maschinenbefehl besteht aus zwei Teilen:
Betrieb - Bestimmen, "was zu tun ist";
· Operand – Definieren von Verarbeitungsobjekten, „was damit zu tun ist“.
Die in Assemblersprache geschriebene Maschinenanweisung des Mikroprozessors ist eine einzelne Zeile mit der folgenden syntaktischen Form:
Label Befehl/Direktive Operand(en) ;Kommentare
In diesem Fall ist ein Pflichtfeld in einer Zeile ein Befehl oder eine Direktive.
Label, Befehl/Anweisung und Operanden (falls vorhanden) werden durch mindestens ein Leerzeichen oder Tabulatorzeichen getrennt.
Wenn ein Befehl oder eine Anweisung in der nächsten Zeile fortgesetzt werden muss, wird der umgekehrte Schrägstrich verwendet: \.
Standardmäßig unterscheidet die Assemblersprache nicht zwischen Groß- und Kleinbuchstaben in Befehlen oder Anweisungen.
Direkte Adressierung Hinweis: Die effektive Adresse wird direkt durch das Maschinenbefehls-Offsetfeld bestimmt, das 8, 16 oder 32 Bit groß sein kann.
bewege eax, summe ; eax = Summe
Der Assembler ersetzt sum durch die entsprechende Adresse, die im Datensegment gespeichert ist (standardmäßig adressiert durch das Register ds) und legt den unter der Adresse sum gespeicherten Wert in das Register eax.
indirekte Adressierung hat wiederum folgende Typen:
Indirekte Grundadressierung (Register);
Indirekte Basis-(Register-)Adressierung mit Offset;
· indirekte Indexadressierung;
· indirekte Basisindexadressierung.
Indirekte Grundadressierung (Register). Bei dieser Adressierung kann sich die effektive Adresse des Operanden in jedem der Mehrzweckregister befinden, mit Ausnahme von sp / esp und bp / ebp (dies sind spezielle Register für die Arbeit mit einem Stapelsegment). Syntaktisch wird dieser Adressierungsmodus in einer Anweisung ausgedrückt, indem der Registername in eckige Klammern gesetzt wird.
verschieben eax, ; eax = *esi; *esi-Wert an der Adresse esi
Anweisungsstruktur in Assemblersprache Das Programmieren auf der Ebene von Maschinenanweisungen ist die Mindestebene, auf der Computerprogrammierung möglich ist. Das System der Maschinenanweisungen sollte ausreichen, um die erforderlichen Aktionen durch Ausgabe von Anweisungen an die Maschinenhardware umzusetzen. Jeder Maschinenbefehl besteht aus zwei Teilen: einem Operationsteil, der definiert, „was zu tun ist“, und einem Operanden, der Verarbeitungsobjekte definiert, das heißt, „was zu tun ist“. Die in Assemblersprache geschriebene Maschinenanweisung des Mikroprozessors ist eine einzelne Zeile mit der folgenden Form: Label-Anweisung/Direktive Operand(en); Kommentare Label, Befehl/Anweisung und Operand werden durch mindestens ein Leerzeichen oder Tabulatorzeichen getrennt. Die Anweisungsoperanden werden durch Kommas getrennt.
 Struktur eines Assemblersprachbefehls Ein Assemblersprachbefehl teilt dem Compiler mit, welche Aktion der Mikroprozessor ausführen soll. Assembler-Direktiven sind im Programmtext angegebene Parameter, die den Assembler-Prozess oder die Eigenschaften der Ausgabedatei beeinflussen. Der Operand gibt den Anfangswert der Daten (im Datensegment) oder der Elemente an, auf die der Befehl einwirken soll (im Codesegment). Eine Anweisung kann einen oder zwei Operanden oder keine Operanden haben. Die Anzahl der Operanden wird implizit durch den Befehlscode angegeben. Wenn der Befehl oder die Anweisung in der nächsten Zeile fortgesetzt werden muss, wird der umgekehrte Schrägstrich verwendet: "" . Standardmäßig unterscheidet der Assembler in Befehlen und Direktiven nicht zwischen Groß- und Kleinschreibung. Beispiele für Anweisungen und Befehle Count db 1 ; Name, Direktive, ein Operand mov eax, 0 ; Befehl, zwei Operanden
Struktur eines Assemblersprachbefehls Ein Assemblersprachbefehl teilt dem Compiler mit, welche Aktion der Mikroprozessor ausführen soll. Assembler-Direktiven sind im Programmtext angegebene Parameter, die den Assembler-Prozess oder die Eigenschaften der Ausgabedatei beeinflussen. Der Operand gibt den Anfangswert der Daten (im Datensegment) oder der Elemente an, auf die der Befehl einwirken soll (im Codesegment). Eine Anweisung kann einen oder zwei Operanden oder keine Operanden haben. Die Anzahl der Operanden wird implizit durch den Befehlscode angegeben. Wenn der Befehl oder die Anweisung in der nächsten Zeile fortgesetzt werden muss, wird der umgekehrte Schrägstrich verwendet: "" . Standardmäßig unterscheidet der Assembler in Befehlen und Direktiven nicht zwischen Groß- und Kleinschreibung. Beispiele für Anweisungen und Befehle Count db 1 ; Name, Direktive, ein Operand mov eax, 0 ; Befehl, zwei Operanden
 Bezeichner sind Folgen gültiger Zeichen, die zur Bezeichnung von Variablennamen und Bezeichnungsnamen verwendet werden. Die Kennung kann aus einem oder mehreren der folgenden Zeichen bestehen: alle Buchstaben des lateinischen Alphabets; Zahlen von 0 bis 9; Sonderzeichen: _, @, $, ? . Als erstes Zeichen des Labels kann ein Punkt verwendet werden. Reservierte Assemblernamen (Direktiven, Operatoren, Befehlsnamen) können nicht als Bezeichner verwendet werden. Das erste Zeichen der Kennung muss ein Buchstabe oder ein Sonderzeichen sein. Die maximale Bezeichnerlänge beträgt 255 Zeichen, aber der Übersetzer akzeptiert die ersten 32 Zeichen und ignoriert den Rest. Alle Labels, die in eine Zeile geschrieben werden, die keine Assembler-Direktive enthält, müssen mit einem Doppelpunkt ":" enden. Label, Befehl (Direktive) und Operand müssen nicht an einer bestimmten Position im String beginnen. Es wird empfohlen, sie für eine bessere Lesbarkeit des Programms in eine Spalte zu schreiben.
Bezeichner sind Folgen gültiger Zeichen, die zur Bezeichnung von Variablennamen und Bezeichnungsnamen verwendet werden. Die Kennung kann aus einem oder mehreren der folgenden Zeichen bestehen: alle Buchstaben des lateinischen Alphabets; Zahlen von 0 bis 9; Sonderzeichen: _, @, $, ? . Als erstes Zeichen des Labels kann ein Punkt verwendet werden. Reservierte Assemblernamen (Direktiven, Operatoren, Befehlsnamen) können nicht als Bezeichner verwendet werden. Das erste Zeichen der Kennung muss ein Buchstabe oder ein Sonderzeichen sein. Die maximale Bezeichnerlänge beträgt 255 Zeichen, aber der Übersetzer akzeptiert die ersten 32 Zeichen und ignoriert den Rest. Alle Labels, die in eine Zeile geschrieben werden, die keine Assembler-Direktive enthält, müssen mit einem Doppelpunkt ":" enden. Label, Befehl (Direktive) und Operand müssen nicht an einer bestimmten Position im String beginnen. Es wird empfohlen, sie für eine bessere Lesbarkeit des Programms in eine Spalte zu schreiben.
 Labels Alle Labels, die in eine Zeile geschrieben werden, die keine Assembler-Direktive enthält, müssen mit einem Doppelpunkt ":" enden. Label, Befehl (Direktive) und Operand müssen nicht an einer bestimmten Position im String beginnen. Es wird empfohlen, sie für eine bessere Lesbarkeit des Programms in eine Spalte zu schreiben.
Labels Alle Labels, die in eine Zeile geschrieben werden, die keine Assembler-Direktive enthält, müssen mit einem Doppelpunkt ":" enden. Label, Befehl (Direktive) und Operand müssen nicht an einer bestimmten Position im String beginnen. Es wird empfohlen, sie für eine bessere Lesbarkeit des Programms in eine Spalte zu schreiben.
 Kommentare Die Verwendung von Kommentaren in einem Programm verbessert dessen Übersichtlichkeit, insbesondere wenn der Zweck einer Reihe von Anweisungen unklar ist. Kommentare beginnen in jeder Zeile eines Quellmoduls mit einem Semikolon (;). Alle Zeichen rechts von "; ' am Ende der Zeile stehen Kommentare. Der Kommentar kann alle druckbaren Zeichen enthalten, einschließlich „Leerzeichen“. Der Kommentar kann sich über die gesamte Zeile erstrecken oder dem Befehl in derselben Zeile folgen.
Kommentare Die Verwendung von Kommentaren in einem Programm verbessert dessen Übersichtlichkeit, insbesondere wenn der Zweck einer Reihe von Anweisungen unklar ist. Kommentare beginnen in jeder Zeile eines Quellmoduls mit einem Semikolon (;). Alle Zeichen rechts von "; ' am Ende der Zeile stehen Kommentare. Der Kommentar kann alle druckbaren Zeichen enthalten, einschließlich „Leerzeichen“. Der Kommentar kann sich über die gesamte Zeile erstrecken oder dem Befehl in derselben Zeile folgen.
 Struktur eines Assemblersprachenprogramms Ein Assemblersprachenprogramm kann aus mehreren Teilen bestehen, die Module genannt werden, von denen jeder ein oder mehrere Daten-, Stack- und Codesegmente definieren kann. Jedes vollständige Assemblersprachenprogramm muss ein Haupt- oder Hauptmodul enthalten, von dem aus seine Ausführung beginnt. Ein Modul kann Programm-, Daten- und Stapelsegmente enthalten, die mit den entsprechenden Direktiven deklariert sind.
Struktur eines Assemblersprachenprogramms Ein Assemblersprachenprogramm kann aus mehreren Teilen bestehen, die Module genannt werden, von denen jeder ein oder mehrere Daten-, Stack- und Codesegmente definieren kann. Jedes vollständige Assemblersprachenprogramm muss ein Haupt- oder Hauptmodul enthalten, von dem aus seine Ausführung beginnt. Ein Modul kann Programm-, Daten- und Stapelsegmente enthalten, die mit den entsprechenden Direktiven deklariert sind.
 Speichermodelle Bevor Sie Segmente deklarieren, müssen Sie das Speichermodell mit einer Direktive angeben. Modifizierer MODEL Speichermodell, Aufrufkonvention, Betriebssystemtyp, Stapelparameter Grundlegende Speichermodelle in Assemblersprache: Speichermodell Codeadressierung Datenadressierung Betriebssystem Code- und Datenverschachtelung TINY NEAR MS-DOS Gültig SMALL NEAR MS-DOS, Windows Nein MEDIUM FAR NEAR NEAR MS-DOS, Windows Nein COMPACT NEAR FAR MS-DOS, Windows Nein LARGE FAR MS-DOS, Windows Nein HUGE FAR MS-DOS, Windows Nein NEAR Windows 2000, Windows XP, Windows Valid FLAT NEAR NT,
Speichermodelle Bevor Sie Segmente deklarieren, müssen Sie das Speichermodell mit einer Direktive angeben. Modifizierer MODEL Speichermodell, Aufrufkonvention, Betriebssystemtyp, Stapelparameter Grundlegende Speichermodelle in Assemblersprache: Speichermodell Codeadressierung Datenadressierung Betriebssystem Code- und Datenverschachtelung TINY NEAR MS-DOS Gültig SMALL NEAR MS-DOS, Windows Nein MEDIUM FAR NEAR NEAR MS-DOS, Windows Nein COMPACT NEAR FAR MS-DOS, Windows Nein LARGE FAR MS-DOS, Windows Nein HUGE FAR MS-DOS, Windows Nein NEAR Windows 2000, Windows XP, Windows Valid FLAT NEAR NT,
 Speichermodelle Das winzige Modell funktioniert nur in 16-Bit-MS-DOS-Anwendungen. In diesem Modell befinden sich alle Daten und Codes in einem physischen Segment. Die Größe der Programmdatei überschreitet in diesem Fall 64 KB nicht. Das kleine Modell unterstützt ein Codesegment und ein Datensegment. Daten und Code werden bei Verwendung dieses Modells als near (near) adressiert. Das mittlere Modell unterstützt mehrere Codesegmente und ein Datensegment, wobei alle Links in den Codesegmenten standardmäßig als weit entfernt und Links im Datensegment als nah (near) gelten. Das kompakte Modell unterstützt mehrere Datensegmente, die die Ferndatenadressierung (far) verwenden, und ein Codesegment, das die Nahdatenadressierung (near) verwendet. Das große Modell unterstützt mehrere Codesegmente und mehrere Datensegmente. Standardmäßig werden alle Code- und Datenreferenzen weit berücksichtigt. Das riesige Modell entspricht fast dem großen Speichermodell.
Speichermodelle Das winzige Modell funktioniert nur in 16-Bit-MS-DOS-Anwendungen. In diesem Modell befinden sich alle Daten und Codes in einem physischen Segment. Die Größe der Programmdatei überschreitet in diesem Fall 64 KB nicht. Das kleine Modell unterstützt ein Codesegment und ein Datensegment. Daten und Code werden bei Verwendung dieses Modells als near (near) adressiert. Das mittlere Modell unterstützt mehrere Codesegmente und ein Datensegment, wobei alle Links in den Codesegmenten standardmäßig als weit entfernt und Links im Datensegment als nah (near) gelten. Das kompakte Modell unterstützt mehrere Datensegmente, die die Ferndatenadressierung (far) verwenden, und ein Codesegment, das die Nahdatenadressierung (near) verwendet. Das große Modell unterstützt mehrere Codesegmente und mehrere Datensegmente. Standardmäßig werden alle Code- und Datenreferenzen weit berücksichtigt. Das riesige Modell entspricht fast dem großen Speichermodell.
 Speichermodelle Das flache Modell geht von einer nicht segmentierten Programmkonfiguration aus und wird nur auf 32-Bit-Betriebssystemen verwendet. Dieses Modell ähnelt dem winzigen Modell darin, dass sich die Daten und der Code im selben 32-Bit-Segment befinden. Entwicklung eines Programms für das flache Modell vor der Richtlinie. model flat sollte eine der Anweisungen platzieren: . 386, . 486, . 586 bzw. 686. Die Wahl der Prozessorauswahldirektive bestimmt den Satz verfügbarer Befehle beim Schreiben von Programmen. Der Buchstabe p nach der Prozessorauswahlanweisung bedeutet Protected Mode of Operation. Die Daten- und Codeadressierung ist nahe, wobei alle Adressen und Zeiger 32-Bit sind.
Speichermodelle Das flache Modell geht von einer nicht segmentierten Programmkonfiguration aus und wird nur auf 32-Bit-Betriebssystemen verwendet. Dieses Modell ähnelt dem winzigen Modell darin, dass sich die Daten und der Code im selben 32-Bit-Segment befinden. Entwicklung eines Programms für das flache Modell vor der Richtlinie. model flat sollte eine der Anweisungen platzieren: . 386, . 486, . 586 bzw. 686. Die Wahl der Prozessorauswahldirektive bestimmt den Satz verfügbarer Befehle beim Schreiben von Programmen. Der Buchstabe p nach der Prozessorauswahlanweisung bedeutet Protected Mode of Operation. Die Daten- und Codeadressierung ist nahe, wobei alle Adressen und Zeiger 32-Bit sind.
 Gedächtnismodelle. MODEL Modifikator memory_model, calling_convention, OS_type, stack_parameter Der Modifikatorparameter wird verwendet, um Segmenttypen zu definieren und kann die folgenden Werte annehmen: use 16 (Segmente des ausgewählten Modells werden als 16-Bit verwendet) use 32 (Segmente des ausgewählten Modells werden verwendet als 32-Bit). Der Parameter "calling_convention" wird verwendet, um festzulegen, wie Parameter übergeben werden, wenn eine Prozedur aus anderen Sprachen, einschließlich Hochsprachen (C++, Pascal), aufgerufen wird. Der Parameter kann folgende Werte annehmen: C, BASIC, FORTRAN, PASCAL, SYSCALL, STDCALL.
Gedächtnismodelle. MODEL Modifikator memory_model, calling_convention, OS_type, stack_parameter Der Modifikatorparameter wird verwendet, um Segmenttypen zu definieren und kann die folgenden Werte annehmen: use 16 (Segmente des ausgewählten Modells werden als 16-Bit verwendet) use 32 (Segmente des ausgewählten Modells werden verwendet als 32-Bit). Der Parameter "calling_convention" wird verwendet, um festzulegen, wie Parameter übergeben werden, wenn eine Prozedur aus anderen Sprachen, einschließlich Hochsprachen (C++, Pascal), aufgerufen wird. Der Parameter kann folgende Werte annehmen: C, BASIC, FORTRAN, PASCAL, SYSCALL, STDCALL.
 Gedächtnismodelle. Modifizierer MODEL memory_model, calling_convention, OS_type, stack_parameter Der OS_type-Parameter ist standardmäßig OS_DOS und derzeit der einzige unterstützte Wert für diesen Parameter. Der Parameter stack_param ist gesetzt auf: NEARSTACK (SS-Register ist gleich DS, Daten- und Stack-Regionen befinden sich im selben physikalischen Segment) FARSTACK (SS-Register ist nicht gleich DS, Daten- und Stack-Regionen befinden sich in unterschiedlichen physikalischen Segmenten). Der Standardwert ist NEARSTACK.
Gedächtnismodelle. Modifizierer MODEL memory_model, calling_convention, OS_type, stack_parameter Der OS_type-Parameter ist standardmäßig OS_DOS und derzeit der einzige unterstützte Wert für diesen Parameter. Der Parameter stack_param ist gesetzt auf: NEARSTACK (SS-Register ist gleich DS, Daten- und Stack-Regionen befinden sich im selben physikalischen Segment) FARSTACK (SS-Register ist nicht gleich DS, Daten- und Stack-Regionen befinden sich in unterschiedlichen physikalischen Segmenten). Der Standardwert ist NEARSTACK.
 Ein Beispiel für ein „Nichtstun“-Programm. 686 P. MODELL WOHNUNG, STDCALL. DATEN. CODE START: RET END START RET - Mikroprozessorbefehl. Es sorgt für die korrekte Beendigung des Programms. Der Rest des Programms bezieht sich auf den Betrieb des Übersetzers. . 686 P - Pentium 6 (Pentium II) geschützte Modusbefehle sind erlaubt. Diese Direktive wählt den unterstützten Assembler-Befehlssatz durch Angabe des Prozessormodells aus. . MODEL FLAT, stdcall - flaches Speichermodell. Dieses Speichermodell wird im Windows-Betriebssystem verwendet. stdcall ist die zu verwendende Prozeduraufrufkonvention.
Ein Beispiel für ein „Nichtstun“-Programm. 686 P. MODELL WOHNUNG, STDCALL. DATEN. CODE START: RET END START RET - Mikroprozessorbefehl. Es sorgt für die korrekte Beendigung des Programms. Der Rest des Programms bezieht sich auf den Betrieb des Übersetzers. . 686 P - Pentium 6 (Pentium II) geschützte Modusbefehle sind erlaubt. Diese Direktive wählt den unterstützten Assembler-Befehlssatz durch Angabe des Prozessormodells aus. . MODEL FLAT, stdcall - flaches Speichermodell. Dieses Speichermodell wird im Windows-Betriebssystem verwendet. stdcall ist die zu verwendende Prozeduraufrufkonvention.
 Ein Beispiel für ein „Nichtstun“-Programm. 686 P. MODELL WOHNUNG, STDCALL. DATEN. CODE START: RET ENDE START . DATA - Programmsegment, das Daten enthält. Dieses Programm verwendet den Stack nicht, also segmentieren. STAPEL fehlt. . CODE - ein Segment des Programms, das den Code enthält. START - Etikett. END START - das Ende des Programms und eine Nachricht an den Compiler, dass das Programm ab dem Label START gestartet werden muss. Jedes Programm muss eine END-Direktive enthalten, die das Ende des Quellcodes des Programms markiert. Alle Zeilen, die auf die END-Direktive folgen, werden ignoriert.Das Label nach der END-Direktive teilt dem Compiler den Namen des Hauptmoduls mit, von dem aus die Programmausführung beginnt. Wenn das Programm ein Modul enthält, kann das Label nach der END-Direktive weggelassen werden.
Ein Beispiel für ein „Nichtstun“-Programm. 686 P. MODELL WOHNUNG, STDCALL. DATEN. CODE START: RET ENDE START . DATA - Programmsegment, das Daten enthält. Dieses Programm verwendet den Stack nicht, also segmentieren. STAPEL fehlt. . CODE - ein Segment des Programms, das den Code enthält. START - Etikett. END START - das Ende des Programms und eine Nachricht an den Compiler, dass das Programm ab dem Label START gestartet werden muss. Jedes Programm muss eine END-Direktive enthalten, die das Ende des Quellcodes des Programms markiert. Alle Zeilen, die auf die END-Direktive folgen, werden ignoriert.Das Label nach der END-Direktive teilt dem Compiler den Namen des Hauptmoduls mit, von dem aus die Programmausführung beginnt. Wenn das Programm ein Modul enthält, kann das Label nach der END-Direktive weggelassen werden.
 Assembler-Übersetzer Ein Übersetzer ist ein Programm oder eine Hardware, die ein Programm, das in einer der Programmiersprachen präsentiert wird, in ein Programm in der Zielsprache, Objektcode genannt, umwandelt. Zusätzlich zur Unterstützung von Mnemoniken für Maschinenbefehle hat jeder Compiler seinen eigenen Satz von Direktiven und Makros, die oft mit nichts anderem kompatibel sind. Die Haupttypen von Assembler-Übersetzern sind: MASM (Microsoft Assembler), TASM (Borland Turbo Assembler), FASM (Flat Assembler) – ein frei verteilter Multi-Pass-Assembler, geschrieben von Tomasz Gryshtar (Polnisch), NASM (Netwide Assembler) – a Der kostenlose Assembler für die Intel-x-Architektur 86 wurde von Simon Tatham mit Julian Hall erstellt und wird derzeit von einem kleinen Entwicklerteam bei Source entwickelt. Schmiede. Netz.
Assembler-Übersetzer Ein Übersetzer ist ein Programm oder eine Hardware, die ein Programm, das in einer der Programmiersprachen präsentiert wird, in ein Programm in der Zielsprache, Objektcode genannt, umwandelt. Zusätzlich zur Unterstützung von Mnemoniken für Maschinenbefehle hat jeder Compiler seinen eigenen Satz von Direktiven und Makros, die oft mit nichts anderem kompatibel sind. Die Haupttypen von Assembler-Übersetzern sind: MASM (Microsoft Assembler), TASM (Borland Turbo Assembler), FASM (Flat Assembler) – ein frei verteilter Multi-Pass-Assembler, geschrieben von Tomasz Gryshtar (Polnisch), NASM (Netwide Assembler) – a Der kostenlose Assembler für die Intel-x-Architektur 86 wurde von Simon Tatham mit Julian Hall erstellt und wird derzeit von einem kleinen Entwicklerteam bei Source entwickelt. Schmiede. Netz.
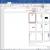
Src="https://present5.com/presentation/-29367016_63610977/image-15.jpg" alt="(!LANG:Programmübersetzung in Microsoft Visual Studio 2005 1) Erstellen Sie ein Projekt, indem Sie Datei->Neu->Projekt auswählen Menü Und"> Трансляция программы в Microsoft Visual Studio 2005 1) Создать проект, выбрав меню File->New->Project и указав имя проекта (hello. prj) и тип проекта: Win 32 Project. В дополнительных опциях мастера проекта указать “Empty Project”.!}
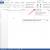
Src="https://present5.com/presentation/-29367016_63610977/image-16.jpg" alt="(!LANG:Programmübersetzung in Microsoft Visual Studio 2005 2) Im Projektbaum (Ansicht->Solution Explorer) hinzufügen"> Трансляция программы в Microsoft Visual Studio 2005 2) В дереве проекта (View->Solution Explorer) добавить файл, в котором будет содержаться текст программы: Source. Files->Add->New. Item.!}
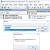
 Übersetzung des Programms in Microsoft Visual Studio 2005 3) Wählen Sie den Dateityp Code C++, aber geben Sie den Namen mit der Erweiterung an. asm:
Übersetzung des Programms in Microsoft Visual Studio 2005 3) Wählen Sie den Dateityp Code C++, aber geben Sie den Namen mit der Erweiterung an. asm:

 Übersetzung des Programms in Microsoft Visual Studio 2005 5) Compiler-Optionen setzen. Wählen Sie auf der rechten Schaltfläche im Projektdateimenü Custom Build Rules…
Übersetzung des Programms in Microsoft Visual Studio 2005 5) Compiler-Optionen setzen. Wählen Sie auf der rechten Schaltfläche im Projektdateimenü Custom Build Rules…
 Übersetzung des Programms in Microsoft Visual Studio 2005 und wählen Sie im angezeigten Fenster Microsoft Macro Assembler.
Übersetzung des Programms in Microsoft Visual Studio 2005 und wählen Sie im angezeigten Fenster Microsoft Macro Assembler.
 Übersetzung des Programms in Microsoft Visual Studio 2005 Überprüfen Sie mit der rechten Maustaste in der Datei hallo. asm des Projektbaums aus dem Menü Eigenschaften und wählen Sie Allgemein->Tool: Microsoft Macro Assembler.
Übersetzung des Programms in Microsoft Visual Studio 2005 Überprüfen Sie mit der rechten Maustaste in der Datei hallo. asm des Projektbaums aus dem Menü Eigenschaften und wählen Sie Allgemein->Tool: Microsoft Macro Assembler.
Src="https://present5.com/presentation/-29367016_63610977/image-22.jpg" alt="(!LANG:Programmübersetzung in Microsoft Visual Studio 2005 6) Kompilieren Sie die Datei, indem Sie Build->Build hello.prj auswählen ."> Трансляция программы в Microsoft Visual Studio 2005 6) Откомпилировать файл, выбрав Build->Build hello. prj. 7) Запустить программу, нажав F 5 или выбрав меню Debug->Start Debugging.!}
 Programmierung im Betriebssystem Windows Die Programmierung im Betriebssystem Windows basiert auf der Verwendung von API-Funktionen (Application Program Interface, d. h. Software-Anwendungsschnittstelle). Ihre Zahl erreicht 2000. Das Programm für Windows besteht größtenteils aus solchen Aufrufen. Alle Interaktionen mit externen Geräten und Ressourcen des Betriebssystems erfolgen in der Regel über solche Funktionen. Das Windows-Betriebssystem verwendet ein flaches Speichermodell. Die Adresse jeder Speicherstelle wird durch den Inhalt eines 32-Bit-Registers bestimmt. Es gibt 3 Arten von Programmstrukturen für Windows: Dialog (das Hauptfenster ist ein Dialog), Konsolen- oder fensterlose Struktur, klassische Struktur (Fenster, Rahmen).
Programmierung im Betriebssystem Windows Die Programmierung im Betriebssystem Windows basiert auf der Verwendung von API-Funktionen (Application Program Interface, d. h. Software-Anwendungsschnittstelle). Ihre Zahl erreicht 2000. Das Programm für Windows besteht größtenteils aus solchen Aufrufen. Alle Interaktionen mit externen Geräten und Ressourcen des Betriebssystems erfolgen in der Regel über solche Funktionen. Das Windows-Betriebssystem verwendet ein flaches Speichermodell. Die Adresse jeder Speicherstelle wird durch den Inhalt eines 32-Bit-Registers bestimmt. Es gibt 3 Arten von Programmstrukturen für Windows: Dialog (das Hauptfenster ist ein Dialog), Konsolen- oder fensterlose Struktur, klassische Struktur (Fenster, Rahmen).
 Aufrufen von Windows-API-Funktionen In der Hilfedatei wird jede API-Funktion als Typ Funktionsname (FA 1, FA 2, FA 3) dargestellt Typ – Typ des Rückgabewerts; FAX – Liste der formalen Argumente in ihrer Reihenfolge, zum Beispiel int Nachricht. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Diese Funktion zeigt ein Fenster mit einer Nachricht und einer oder mehreren Exit-Schaltflächen an. Bedeutung der Parameter: h. Wnd - Handle auf das Fenster, in dem das Nachrichtenfenster erscheinen wird, lp. Text - der Text, der im Fenster erscheint, lp. Beschriftung - Text im Fenstertitel, u. Typ - Fenstertyp, insbesondere können Sie die Anzahl der Exit-Schaltflächen angeben.
Aufrufen von Windows-API-Funktionen In der Hilfedatei wird jede API-Funktion als Typ Funktionsname (FA 1, FA 2, FA 3) dargestellt Typ – Typ des Rückgabewerts; FAX – Liste der formalen Argumente in ihrer Reihenfolge, zum Beispiel int Nachricht. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Diese Funktion zeigt ein Fenster mit einer Nachricht und einer oder mehreren Exit-Schaltflächen an. Bedeutung der Parameter: h. Wnd - Handle auf das Fenster, in dem das Nachrichtenfenster erscheinen wird, lp. Text - der Text, der im Fenster erscheint, lp. Beschriftung - Text im Fenstertitel, u. Typ - Fenstertyp, insbesondere können Sie die Anzahl der Exit-Schaltflächen angeben.
 Aufrufen von Windows-API-Funktionen int Message. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Fast alle API-Funktionsparameter sind tatsächlich 32-Bit-Ganzzahlen: HWND ist eine 32-Bit-Ganzzahl, LPCTSTR ist ein 32-Bit-String-Zeiger, UINT ist eine 32-Bit-Ganzzahl. Das Suffix "A" wird häufig an den Namen von Funktionen angehängt, um zu neueren Versionen von Funktionen zu springen.
Aufrufen von Windows-API-Funktionen int Message. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Fast alle API-Funktionsparameter sind tatsächlich 32-Bit-Ganzzahlen: HWND ist eine 32-Bit-Ganzzahl, LPCTSTR ist ein 32-Bit-String-Zeiger, UINT ist eine 32-Bit-Ganzzahl. Das Suffix "A" wird häufig an den Namen von Funktionen angehängt, um zu neueren Versionen von Funktionen zu springen.
 Aufrufen von Windows-API-Funktionen int Message. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Wenn Sie MASM verwenden, müssen Sie am Ende des Namens @N N hinzufügen – die Anzahl der Bytes, die die übergebenen Argumente auf dem Stapel belegen. Für Win 32-API-Funktionen kann diese Zahl als die Anzahl der Argumente n mal 4 (Bytes in jedem Argument) definiert werden: N=4*n. Um eine Funktion aufzurufen, wird die CALL-Anweisung des Assemblers verwendet. In diesem Fall werden der Funktion alle Argumente über den Stack übergeben (PUSH-Befehl). Übergaberichtung des Arguments: LINKS NACH RECHTS – UNTEN NACH OBEN. Das Argument u wird zuerst auf den Stack geschoben. Art. Der Aufruf der angegebenen Funktion sieht folgendermaßen aus: CALL Message. Kasten. [E-Mail geschützt]
Aufrufen von Windows-API-Funktionen int Message. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Wenn Sie MASM verwenden, müssen Sie am Ende des Namens @N N hinzufügen – die Anzahl der Bytes, die die übergebenen Argumente auf dem Stapel belegen. Für Win 32-API-Funktionen kann diese Zahl als die Anzahl der Argumente n mal 4 (Bytes in jedem Argument) definiert werden: N=4*n. Um eine Funktion aufzurufen, wird die CALL-Anweisung des Assemblers verwendet. In diesem Fall werden der Funktion alle Argumente über den Stack übergeben (PUSH-Befehl). Übergaberichtung des Arguments: LINKS NACH RECHTS – UNTEN NACH OBEN. Das Argument u wird zuerst auf den Stack geschoben. Art. Der Aufruf der angegebenen Funktion sieht folgendermaßen aus: CALL Message. Kasten. [E-Mail geschützt]
 Aufrufen von Windows-API-Funktionen int Message. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Das Ergebnis der Ausführung einer API-Funktion ist normalerweise eine Ganzzahl, die im EAX-Register zurückgegeben wird. Die OFFSET-Direktive ist ein "Segment-Offset" oder, in Hochsprache ausgedrückt, ein "Zeiger" auf den Beginn einer Zeichenkette. Die Direktive EQU definiert wie #define in C eine Konstante. Die Direktive EXTERN teilt dem Compiler mit, dass eine Funktion oder ein Bezeichner außerhalb des Moduls liegt.
Aufrufen von Windows-API-Funktionen int Message. Box (HWND h. Wnd, LPCTSTR lp. Text, LPCTSTR lp. Caption, UINT u. Type); Das Ergebnis der Ausführung einer API-Funktion ist normalerweise eine Ganzzahl, die im EAX-Register zurückgegeben wird. Die OFFSET-Direktive ist ein "Segment-Offset" oder, in Hochsprache ausgedrückt, ein "Zeiger" auf den Beginn einer Zeichenkette. Die Direktive EQU definiert wie #define in C eine Konstante. Die Direktive EXTERN teilt dem Compiler mit, dass eine Funktion oder ein Bezeichner außerhalb des Moduls liegt.
 Ein Beispiel für das Programm "Hallo alle zusammen!" . 686 P. MODELL WOHNUNG, STDCALL. STACK 4096. DATA MB_OK EQU 0 STR 1 DB "Mein erstes Programm", 0 STR 2 DB "Hallo zusammen!", 0 HW DD ? EXTERNE Nachricht. Kasten. [E-Mail geschützt]: IN DER NÄHE VON. CODE START: PUSH MB_OK PUSH OFFSET STR 1 PUSH OFFSET STR 2 PUSH HW CALL Nachricht. Kasten. [E-Mail geschützt] ZURÜCK ENDE START
Ein Beispiel für das Programm "Hallo alle zusammen!" . 686 P. MODELL WOHNUNG, STDCALL. STACK 4096. DATA MB_OK EQU 0 STR 1 DB "Mein erstes Programm", 0 STR 2 DB "Hallo zusammen!", 0 HW DD ? EXTERNE Nachricht. Kasten. [E-Mail geschützt]: IN DER NÄHE VON. CODE START: PUSH MB_OK PUSH OFFSET STR 1 PUSH OFFSET STR 2 PUSH HW CALL Nachricht. Kasten. [E-Mail geschützt] ZURÜCK ENDE START
 Die INVOKE-Direktive Der MASM-Sprachübersetzer ermöglicht es auch, den Funktionsaufruf mit einem Makrotool zu vereinfachen - der INVOKE-Direktive: INVOKE-Funktion, Parameter1, Parameter2, ... Es besteht keine Notwendigkeit, @16 zum Funktionsaufruf hinzuzufügen; die Parameter werden genau in der Reihenfolge geschrieben, in der sie in der Funktionsbeschreibung angegeben sind. Übersetzer-Makros schieben Parameter auf den Stack. Um die INVOKE-Direktive verwenden zu können, benötigen Sie eine Beschreibung des Funktionsprototyps mit der PROTO-Direktive in der Form: Nachricht. Kasten. A PROTO: DWORD, : DWORD
Die INVOKE-Direktive Der MASM-Sprachübersetzer ermöglicht es auch, den Funktionsaufruf mit einem Makrotool zu vereinfachen - der INVOKE-Direktive: INVOKE-Funktion, Parameter1, Parameter2, ... Es besteht keine Notwendigkeit, @16 zum Funktionsaufruf hinzuzufügen; die Parameter werden genau in der Reihenfolge geschrieben, in der sie in der Funktionsbeschreibung angegeben sind. Übersetzer-Makros schieben Parameter auf den Stack. Um die INVOKE-Direktive verwenden zu können, benötigen Sie eine Beschreibung des Funktionsprototyps mit der PROTO-Direktive in der Form: Nachricht. Kasten. A PROTO: DWORD, : DWORD