Strukturen in Assemblersprache. Programmstruktur in Assemblersprache Datenformat und Anweisungsstruktur in Assemblersprache
Thema 1.4 Assembler-Mnemonik. Befehlsstruktur und Formate. Arten der Adressierung. Mikroprozessor-Befehlssatz
Planen:
1 Assemblersprache. Grundlegendes Konzept
2 Symbole der Assemblersprache
3 Arten von Assembler-Anweisungen
4 Montagerichtlinien
5 Prozessor-Befehlssatz
1 IchAssemblersprache. Grundlegendes Konzept
Assemblerspracheist eine symbolische Darstellung der Maschinensprache. Alle Prozesse in der Maschine auf der untersten Hardwareebene werden nur durch Befehle (Anweisungen) der Maschinensprache gesteuert. Daraus wird deutlich, dass trotz des gebräuchlichen Namens die Assemblersprache für jeden Computertyp unterschiedlich ist.
Ein Programm in Assemblersprache ist eine Sammlung von Speicherblöcken, die aufgerufen werden Speichersegmente. Ein Programm kann aus einem oder mehreren dieser Blocksegmente bestehen. Jedes Segment enthält eine Sammlung von Sprachsätzen, von denen jeder eine separate Programmcodezeile belegt.
Es gibt vier Arten von Assembly-Anweisungen:
1) Befehle oder Anweisungen die symbolische Analoga von Maschinenbefehlen sind. Während des Übersetzungsprozesses werden Assembleranweisungen in die entsprechenden Befehle des Mikroprozessor-Befehlssatzes umgewandelt;
2) Makros -die auf bestimmte Weise formalisierten Sätze des Programmtextes werden während der Sendung durch andere Sätze ersetzt;
3) Richtlinien,Dies sind Anweisungen an den Assembler-Übersetzer, um einige Aktionen auszuführen. Direktiven haben keine Entsprechungen in der Maschinendarstellung;
4) Kommentarzeilen , die beliebige Zeichen enthält, einschließlich Buchstaben des russischen Alphabets. Kommentare werden vom Übersetzer ignoriert.
Aufbau des Montageprogramms. Assembler-Syntax.
Die Sätze, aus denen ein Programm besteht, können ein syntaktisches Konstrukt sein, das einem Befehl, Makro, einer Anweisung oder einem Kommentar entspricht. Damit der Assembler-Übersetzer sie erkennt, müssen sie nach bestimmten syntaktischen Regeln gebildet werden. Verwenden Sie dazu am besten eine formale Beschreibung der Syntax der Sprache, wie die Grammatikregeln. Die gebräuchlichsten Arten, eine Programmiersprache wie diese zu beschreiben - Syntaxdiagramme Und erweiterte Formen von Backus-Naur. Bequemer für den praktischen Gebrauch Syntaxdiagramme. Beispielsweise kann die Syntax von Anweisungen in Assemblersprache anhand der in den folgenden Abbildungen 10, 11, 12 gezeigten Syntaxdiagramme beschrieben werden.
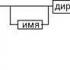
Abbildung 10 – Assembly-Satzformat

Abbildung 11 – Format der Direktiven
Abbildung 12 – Format von Befehlen und Makros
Auf diesen Zeichnungen:
Markenname- Identifikator, dessen Wert die Adresse des ersten Bytes des Satzes des Quellcodes des Programms ist, den er bezeichnet;
Name -eine Kennung, die diese Direktive von anderen gleichnamigen Direktiven unterscheidet. Durch die Verarbeitung einer bestimmten Direktive durch den Assembler können diesem Namen bestimmte Eigenschaften zugeordnet werden;
Betriebscode (COP) und Direktive - dies sind mnemonische Symbole für die entsprechende Maschinenanweisung, Makroanweisung oder Compiler-Anweisung;
Operanden -Teile eines Befehls, Makros oder einer Assembler-Direktive, die Objekte bezeichnen, an denen Aktionen ausgeführt werden. Assembler-Operanden werden durch Ausdrücke mit numerischen und Textkonstanten, Variablenlabels und Bezeichnern mit Operatorzeichen und einigen reservierten Wörtern beschrieben.
Syntaxdiagramme helfen Suchen und durchlaufen Sie dann den Pfad von der Eingabe des Diagramms (links) zu seiner Ausgabe (rechts). Wenn ein solcher Pfad existiert, dann ist der Satz oder die Konstruktion syntaktisch korrekt. Wenn es keinen solchen Pfad gibt, akzeptiert der Compiler diese Konstruktion nicht.
2 Symbole der Assemblersprache
Erlaubte Zeichen beim Schreiben des Textes von Programmen sind:
1) alle lateinischen Buchstaben: A-Z,a-z. In diesem Fall werden Groß- und Kleinbuchstaben als gleichwertig betrachtet;
2) Zahlen von 0 Vor 9 ;
3) Zeichen ? , @ , $ , _ , & ;
4) Trennzeichen , . () < > { } + / * % ! " " ? = # ^ .
Assemblersätze werden gebildet aus Token, die syntaktisch untrennbare Folgen gültiger Sprachzeichen sind, die für den Übersetzer sinnvoll sind.
Token sind:
1) Identifikatoren - Sequenzen gültiger Zeichen, die zur Bezeichnung von Programmobjekten wie Opcodes, Variablennamen und Labelnamen verwendet werden. Die Regel für das Schreiben von Bezeichnern lautet wie folgt: Ein Bezeichner kann aus einem oder mehreren Zeichen bestehen;
2) Zeichenketten - in einfache oder doppelte Anführungszeichen eingeschlossene Zeichenfolgen;
3) ganze Zahlen in einem der folgenden Zahlensysteme : binär, dezimal, hexadezimal. Die Identifizierung von Zahlen beim Schreiben in Assemblerprogrammen erfolgt nach bestimmten Regeln:
4) Dezimalzahlen benötigen keine zusätzlichen Zeichen zu ihrer Kennzeichnung, zB 25 oder 139. Zur Kennzeichnung im Quellcode des Programms binäre Zahlen Es ist notwendig, nach dem Schreiben der in ihrer Zusammensetzung enthaltenen Nullen und Einsen das lateinische „ B“, zum Beispiel 10010101 B.
5) Hexadezimalzahlen haben mehr Konventionen in ihrer Notation:
Erstens bestehen sie aus Zahlen. 0...9 , Klein- und Großbuchstaben des lateinischen Alphabets ein,B, C,D,e,F oder EIN,B,C,D,E,F.
Zweitens kann der Übersetzer Schwierigkeiten haben, Hexadezimalzahlen zu erkennen, da sie sowohl aus den Ziffern 0 ... 9 bestehen können (z. B. 190845) als auch mit einem Buchstaben des lateinischen Alphabets beginnen (z. B. ef15). Um dem Übersetzer zu „erklären“, dass es sich bei dem angegebenen Lexem nicht um eine Dezimalzahl oder einen Bezeichner handelt, muss der Programmierer die Hexadezimalzahl extra zuordnen. Schreiben Sie dazu am Ende der Folge von Hexadezimalziffern, aus denen die Hexadezimalzahl besteht, den lateinischen Buchstaben „ h". Dies ist eine Voraussetzung. Wenn eine Hexadezimalzahl mit einem Buchstaben beginnt, wird ihr eine führende Null vorangestellt: 0 ef15 h.
Fast jeder Satz enthält eine Beschreibung des Objekts, an dem oder mit dessen Hilfe eine Aktion ausgeführt wird. Diese Objekte werden aufgerufen Operanden. Sie können wie folgt definiert werden: Operanden- Dies sind Objekte (einige Werte, Register oder Speicherzellen), die von Anweisungen oder Anweisungen beeinflusst werden, oder dies sind Objekte, die die Aktion von Anweisungen oder Anweisungen definieren oder verfeinern.
Folgende Klassifizierung der Operanden ist möglich:
konstante oder unmittelbare Operanden;
Adressoperanden;
verschobene Operanden;
Adresszähler;
Registeroperand;
Basis- und Indexoperanden;
Strukturoperanden;
Aufzeichnungen.
Operanden sind elementare Komponenten, die einen Teil des Maschinenbefehls bilden und die Objekte bezeichnen, an denen die Operation ausgeführt wird. In einem allgemeineren Fall können Operanden als Komponenten in komplexeren Formationen genannt werden Ausdrücke.
Ausdrücke sind Kombinationen von Operanden und Operatoren als Ganzes betrachtet. Das Ergebnis der Ausdrucksauswertung kann die Adresse einer Speicherzelle oder ein konstanter (absoluter) Wert sein.
3 Arten von Assembler-Anweisungen
Lassen Sie uns die möglichen Typen auflisten Assembler-Aussagen und syntaktische Regeln zur Bildung von Assembler-Ausdrücken:
Rechenzeichen;
Schichtoperatoren;
Vergleichsoperatoren;
logische Operatoren;
Indexoperator;
geben Sie den Override-Operator ein;
Segment-Neudefinitionsoperator;
Benennungsoperator für Strukturtypen;
Operator zum Erhalten der Segmentkomponente der Adresse des Ausdrucks;
Ausdrucks-Offset-Get-Operator.
1 Montagerichtlinien
Assembler-Direktiven sind:
1) Segmentierungsrichtlinien. Im Laufe der vorherigen Diskussion haben wir alle Grundregeln für das Schreiben von Anweisungen und Operanden in einem Programm in Assemblersprache herausgefunden. Offen bleibt die Frage, wie die Befehlsfolge richtig formatiert werden muss, damit der Übersetzer sie verarbeiten und der Mikroprozessor sie ausführen kann.
Bei der Betrachtung der Architektur des Mikroprozessors haben wir gelernt, dass er sechs Segmentregister hat, durch die er gleichzeitig arbeiten kann:
mit einem Codesegment;
mit einem Stapelsegment;
mit einem Datensegment;
mit drei zusätzlichen Datensegmenten.
Physikalisch gesehen ist ein Segment ein Speicherbereich, der von Befehlen und (oder) Daten belegt ist, deren Adressen relativ zum Wert im entsprechenden Segmentregister berechnet werden. Die syntaktische Beschreibung eines Segments in Assembler ist die in Abbildung 13 gezeigte Konstruktion:

Abbildung 13 – Syntaktische Beschreibung des Segments in Assembler
Es ist wichtig zu beachten, dass die Funktionalität eines Segments etwas breiter ist als das einfache Aufteilen des Programms in Code-, Daten- und Stack-Blöcke. Segmentierung ist Teil eines allgemeineren Mechanismus im Zusammenhang mit Konzept der modularen Programmierung. Es beinhaltet die Vereinheitlichung des Entwurfs von Objektmodulen, die vom Compiler erstellt wurden, einschließlich derjenigen aus verschiedenen Programmiersprachen. Dadurch können Sie Programme kombinieren, die in verschiedenen Sprachen geschrieben sind. Für die Implementierung verschiedener Optionen für eine solche Union sind die Operanden in der SEGMENT-Direktive vorgesehen.
2) Steueranweisungen für die Auflistung. Kotierungskontrollanweisungen werden in folgende Gruppen unterteilt:
allgemeine Richtlinien zur Börsenkontrolle;
Ausgabeanweisungen zum Einfügen von Dateilisten;
Ausgabeanweisungen für bedingte Montageblöcke;
Ausgabeanweisungen zur Auflistung von Makros;
Anweisungen zum Anzeigen von Informationen über Querverweise in der Auflistung;
Anweisungen zum Ändern des Listenformats.
2 Prozessor-Befehlssatz
Der Befehlssatz des Prozessors ist in Abbildung 14 dargestellt.
Betrachten Sie die Hauptgruppen von Befehlen.

Abbildung 14 – Klassifizierung von Montageanleitungen
Befehle sind:
1 Datenübertragungsbefehle. Diese Befehle nehmen einen sehr wichtigen Platz im Befehlssatz jedes Prozessors ein. Sie erfüllen die folgenden wesentlichen Funktionen:
Speichern der Inhalte der internen Register des Prozessors im Speicher;
Kopieren von Inhalten von einem Speicherbereich in einen anderen;
Schreiben auf E/A-Geräte und Lesen von E/A-Geräten.
Bei einigen Prozessoren werden alle diese Funktionen durch einen einzigen Befehl ausgeführt BEWEGUNG (für Byte-Übertragungen - MOVB ) aber mit unterschiedlichen Methoden zur Adressierung von Operanden.
In anderen Prozessoren neben der Anweisung BEWEGUNG Es gibt mehrere weitere Befehle, um die aufgeführten Funktionen auszuführen. Zu den Datenübertragungsbefehlen gehören auch Informationsaustauschbefehle (ihre Bezeichnung basiert auf dem Wort Austausch ). Es kann möglich sein, einen Informationsaustausch zwischen internen Registern, zwischen zwei Hälften eines Registers ( TAUSCHEN ) oder zwischen einem Register und einer Speicherstelle.
2 Arithmetische Befehle. Arithmetische Befehle behandeln Operandencodes als numerische Binär- oder BCD-Codes. Diese Befehle können in fünf Hauptgruppen unterteilt werden:
Befehle für Operationen mit einem Fixpunkt (Addition, Subtraktion, Multiplikation, Division);
Gleitkommabefehle (Addition, Subtraktion, Multiplikation, Division);
Bereinigungsbefehle;
Inkrement- und Dekrementbefehle;
Vergleichsbefehl.
3 Festkommabefehle arbeiten mit Codes in Prozessorregistern oder im Speicher, wie sie es mit normalen Binärcodes tun würden. Gleitkomma-(Punkt-)Anweisungen verwenden ein Zahlendarstellungsformat mit einem Exponenten und einer Mantisse (normalerweise belegen diese Zahlen zwei aufeinanderfolgende Speicherstellen). In modernen leistungsfähigen Prozessoren ist der Gleitkomma-Befehlssatz nicht nur auf vier arithmetische Operationen beschränkt, sondern enthält auch viele andere komplexere Anweisungen, beispielsweise die Berechnung trigonometrischer Funktionen, logarithmischer Funktionen und komplexer Funktionen, die für die Ton- und Bildverarbeitung erforderlich sind.
4 Clear-Befehle dienen dazu, einen Nullcode in ein Register oder eine Speicherzelle zu schreiben. Diese Befehle können durch Null-Code-Übertragungsanweisungen ersetzt werden, aber spezielle Löschanweisungen sind normalerweise schneller als Übertragungsanweisungen.
5 Befehle zum Erhöhen (Erhöhen um eins) und Verringern
(Ermäßigungen um eins) sind auch sehr bequem. Sie könnten im Prinzip durch Add-One- oder Subtract-One-Befehle ersetzt werden, aber Inkrement und Dekrement sind schneller als Addieren und Subtrahieren. Diese Anweisungen erfordern einen Eingabeoperanden, der auch ein Ausgabeoperand ist.
6 Der Vergleichsbefehl dient zum Vergleichen zweier Eingangsoperanden. Tatsächlich berechnet er die Differenz dieser beiden Operanden, bildet aber nicht den Ausgangsoperanden, sondern ändert nur die Bits im Prozessorstatusregister basierend auf dem Ergebnis dieser Subtraktion. Der Befehl, der dem Vergleichsbefehl folgt (normalerweise ein Sprungbefehl), analysiert die Bits im Statusregister des Prozessors und führt Aktionen basierend auf ihren Werten aus. Einige Prozessoren stellen Anweisungen zum Kettenvergleich zweier Sequenzen von Operanden im Speicher bereit.
7 Logikbefehle. Logikbefehle führen logische (bitweise) Operationen an Operanden durch, d. h. sie betrachten die Operandencodes nicht als einzelne Zahl, sondern als einen Satz einzelner Bits. Darin unterscheiden sie sich von arithmetischen Befehlen. Logikbefehle führen die folgenden grundlegenden Operationen aus:
logisches UND, logisches ODER, Modulo-2-Addition (XOR);
logische, arithmetische und zyklische Verschiebungen;
Prüfen von Bits und Operanden;
Setzen und Löschen von Bits (Flags) des Prozessorstatusregisters ( PSW).
Logikbefehle ermöglichen die bitweise Berechnung grundlegender Logikfunktionen aus zwei Eingangsoperanden. Zusätzlich wird die UND-Operation verwendet, um das Löschen der angegebenen Bits zu erzwingen (als einer der Operanden verwendet dies den Maskencode, in dem die Bits, die gelöscht werden müssen, auf Null gesetzt werden). Die ODER-Operation wird verwendet, um das Setzen der angegebenen Bits zu erzwingen (als einer der Operanden wird der Maskencode verwendet, bei dem die Bits, die auf eins gesetzt werden müssen, gleich eins sind). Die XOR-Operation wird verwendet, um die gegebenen Bits zu invertieren (als einer der Operanden wird der Maskencode verwendet, in dem die zu invertierenden Bits auf Eins gesetzt werden). Befehle benötigen zwei Eingangsoperanden und bilden einen Ausgangsoperanden.
8 Mit den Shift-Befehlen können Sie den Operandencode bitweise nach rechts (zu den niedrigeren Bits) oder nach links (zu den höheren Bits) verschieben. Die Art der Verschiebung (logisch, arithmetisch oder zyklisch) bestimmt, was der neue Wert des höchstwertigen Bits (bei Rechtsverschiebung) oder des niederwertigsten Bits (bei Linksverschiebung) sein wird, und bestimmt auch, ob der alte Wert der höchstwertige ist Bit wird irgendwo gespeichert (bei Verschiebung nach links) oder niedrigstwertiges Bit (bei Verschiebung nach rechts). Rotationsverschiebungen ermöglichen es Ihnen, die Bits des Operandencodes kreisförmig zu verschieben (im Uhrzeigersinn bei einer Verschiebung nach rechts oder gegen den Uhrzeigersinn bei einer Verschiebung nach links). In diesem Fall kann der Schaltring das Carry-Flag enthalten oder nicht. Das Carry-Flag-Bit (falls verwendet) wird auf das höchstwertige Bit für die Linksrotation und das niedrigstwertige Bit für die Rechtsrotation gesetzt. Dementsprechend wird der Wert des Carry-Flag-Bits bei einer zyklischen Linksverschiebung auf das niedrigstwertige Bit und bei einer zyklischen Rechtsverschiebung auf das höchstwertige Bit umgeschrieben.
9 Sprungbefehle. Sprungbefehle dienen dazu, alle Arten von Schleifen, Verzweigungen, Unterprogrammaufrufen usw. zu organisieren, dh sie unterbrechen den sequentiellen Ablauf des Programms. Diese Befehle schreiben einen neuen Wert in das Befehlszählerregister und bewirken dadurch, dass der Prozessor nicht zum nächsten Befehl in der Reihenfolge springt, sondern zu jedem anderen Befehl im Programmspeicher. Einige Sprungbefehle ermöglichen es Ihnen, zu dem Punkt zurückzukehren, von dem aus der Sprung ausgeführt wurde, während andere dies nicht tun. Wenn eine Rückgabe erfolgt, werden die aktuellen Prozessorparameter auf dem Stack gespeichert. Wenn keine Rückgabe erfolgt, werden die aktuellen Prozessorparameter nicht gespeichert.
Sprungbefehle ohne Backtracking werden in zwei Gruppen eingeteilt:
Befehle für unbedingte Sprünge;
bedingte Sprunganweisungen.
Diese Befehle verwenden die Wörter Branch (Zweig) und Jump (Sprung).
Unbedingte Sprungbefehle bewirken in jedem Fall einen Sprung zu einer neuen Adresse. Sie können einen Sprung zum angegebenen Offset-Wert (vorwärts oder rückwärts) oder zur angegebenen Speicheradresse bewirken. Als Eingangsoperand wird der Offsetwert bzw. neuer Adresswert angegeben.
Bedingte Sprungbefehle bewirken nicht immer einen Sprung, sondern nur dann, wenn die angegebenen Bedingungen erfüllt sind. Solche Bedingungen sind normalerweise die Werte der Flags im Prozessorstatusregister ( PSW ). Das heißt, die Übergangsbedingung ist das Ergebnis der vorherigen Operation, die die Werte der Flags ändert. Insgesamt kann es 4 bis 16 solcher Sprungbedingungen geben Einige Beispiele für bedingte Sprungbefehle:
springe wenn gleich Null;
springe, wenn nicht Null;
springen, wenn es einen Überlauf gibt;
springen, wenn kein Überlauf vorhanden ist;
springen, wenn größer als Null;
Sprung, wenn kleiner oder gleich Null.
Wenn die Übergangsbedingung erfüllt ist, wird ein neuer Wert in das Befehlszählerregister geladen. Wenn die Sprungbedingung nicht erfüllt ist, wird der Befehlszähler einfach erhöht, und der Prozessor wählt den nächsten Befehl in Folge aus und führt ihn aus.
Speziell zur Prüfung von Verzweigungsbedingungen wird ein Vergleichsbefehl (CMP) verwendet, der einem bedingten Sprungbefehl (oder auch mehreren bedingten Sprungbefehlen) vorangestellt ist. Aber Flags können durch jeden anderen Befehl gesetzt werden, wie zum Beispiel einen Datenübertragungsbefehl, jeden arithmetischen oder logischen Befehl. Beachten Sie, dass die Sprungbefehle selbst die Flags nicht ändern, was Ihnen nur erlaubt, mehrere Sprungbefehle hintereinander zu setzen.
Unter den Sprungbefehlen mit Return nehmen Unterbrechungsbefehle eine Sonderstellung ein. Diese Befehle benötigen als Eingangsoperanden eine Interrupt-Nummer (Vektoradresse).
Ausgabe:
Die Assemblersprache ist eine symbolische Darstellung der Maschinensprache. Die Assemblersprache für jeden Computertyp ist unterschiedlich. Ein Assemblersprachenprogramm ist eine Sammlung von Speicherblöcken, die als Speichersegmente bezeichnet werden. Jedes Segment enthält eine Sammlung von Sprachsätzen, von denen jeder eine separate Programmcodezeile belegt. Es gibt vier Arten von Assembly-Anweisungen: Befehle oder Anweisungen, Makros, Direktiven, Kommentarzeilen.
Gültige Zeichen beim Schreiben des Textes von Programmen sind alle lateinischen Buchstaben: A-Z,a-z. In diesem Fall werden Groß- und Kleinbuchstaben als gleichwertig betrachtet; Zahlen aus 0 Vor 9 ; Zeichen ? , @ , $ , _ , & ; Trennzeichen , . () < > { } + / * % ! " " ? = # ^ .
Es gelten die folgenden Arten von Assembler-Anweisungen und Syntaxregeln für die Bildung von Assembler-Ausdrücken. arithmetische Operatoren, Verschiebungsoperatoren, Vergleichsoperatoren, logische Operatoren, Indexoperatoren, Typneudefinitionsoperatoren, Segmentneudefinitionsoperatoren, Strukturtypbenennungsoperatoren, Operatoren zum Erhalten von Ausdrucksadressensegmentkomponenten, Operatoren zum Erhalten von Ausdrucksoffsets.
Das Befehlssystem ist in 8 Hauptgruppen unterteilt.
Testfragen:
1 Was ist Assemblersprache?
2 Welche Symbole können verwendet werden, um Befehle in Assembler zu schreiben?
3 Was sind Etiketten und wozu dienen sie?
4 Erklären Sie den Aufbau einer Montageanleitung.
5 Nennen Sie 4 Arten von Assembler-Anweisungen.
1. PC-Architektur……………………………………………………………………5
1.1. Register.
1.1.1 Allzweckregister.
1.1.2. Segmentregister
1.1.3 Flaggenregister
1.2. Organisation des Gedächtnisses.
1.3. Daten Präsentation.
1.3.1 Datentypen
1.3.2 Zeichen- und Zeichenkettendarstellung
2. Erklärungen zum Vollversammlungsprogramm ……………………………………
Befehle in Assemblersprache
2.2. Adressierungsmodi und Maschinenbefehlsformate
3. Pseudo-Operatoren ………………………………………………………….
3.1 Datendefinitionsrichtlinien
3.2 Aufbau des Montageprogramms
3.2.1 Programmsegmente. Direktive annehmen
3.2.3 Vereinfachte Segmentierungsrichtlinie
4. Assemblieren und Linken des Programms ………………………….
5. Datenübertragungsbefehle…………………………………………….
5.1 Allgemeine Befehle
5.2 Stack-Befehle
5.3 E/A-Befehle
5.4 Adressweiterleitungsbefehle
5.5 Flag-Transfer-Befehle
6. Rechenbefehle ……………………………………………….
6.1 Arithmetische Operationen mit binären ganzen Zahlen
6.1.1 Addition und Subtraktion
6.1.2 Befehle zum Inkrementieren und Dekrementieren des Empfängers um eins
6.2 Multiplikation und Division
6.3 Vorzeichenwechsel
7. Logische Operationen ………………………………………………….
8. Schichten und zyklische Schichten …………………………………………
9. Stringoperationen …………………………………………………….
10. Logik und Organisation von Programmen ………………………………………
10.1 Bedingungslose Sprünge
10.2 Bedingte Sprünge
10.4 Prozeduren in Assemblersprache
10.5 Interrupts INT
10.6 Systemsoftware
10.6.1.1 Lesen der Tastatur.
10.6.1.2 Anzeigen von Zeichen auf dem Bildschirm
10.6.1.3 Beenden von Programmen.
10.6.2.1 Anzeigemodi auswählen
11. Festplattenspeicher ………………………………………………………………..
11.2 Dateizuordnungstabelle
11.3 Festplatten-E/A
11.3.1 Schreiben einer Datei auf die Festplatte
11.3.1.1 ASCIIZ-Daten
11.3.1.2 Aktenzeichen
11.3.1.3 Erstellen einer Festplattendatei
11.3.2 Lesen einer Diskettendatei
Einführung
Die Assemblersprache ist eine symbolische Darstellung der Maschinensprache. Alle Prozesse in einem Personal Computer (PC) auf der niedrigsten Hardwareebene werden nur durch Maschinensprachbefehle (Anweisungen) gesteuert. Ohne Assembler-Kenntnisse ist es unmöglich, hardwarebezogene Probleme (oder sogar hardwarebezogene Probleme, wie z. B. die Verbesserung der Geschwindigkeit eines Programms) wirklich zu lösen.
Assembler ist eine bequeme Form von Befehlen direkt für PC-Komponenten und erfordert Kenntnisse über die Eigenschaften und Fähigkeiten der integrierten Schaltung, die diese Komponenten enthält, nämlich des PC-Mikroprozessors. Somit steht die Assemblersprache in direktem Zusammenhang mit der internen Organisation des PCs. Und es ist kein Zufall, dass fast alle Compiler von Hochsprachen den Zugriff auf die Assembler-Programmierebene unterstützen.
Ein Element der Vorbereitung eines professionellen Programmierers ist notwendigerweise das Studium von Assembler. Dies liegt daran, dass die Programmierung in Assemblersprache Kenntnisse der PC-Architektur erfordert, die es Ihnen ermöglichen, effizientere Programme in anderen Sprachen zu erstellen und diese mit Programmen in Assemblersprache zu kombinieren.
Das Handbuch befasst sich mit der Programmierung in Assemblersprache für Computer, die auf Intel-Mikroprozessoren basieren.
Dieses Tutorial richtet sich an alle, die sich für die Architektur des Prozessors und die Grundlagen der Programmierung in Assembler interessieren, in erster Linie an die Entwickler des Softwareprodukts.
PC-Architektur.
Computerarchitektur ist eine abstrakte Darstellung eines Computers, die seine Struktur, Schaltkreise und logische Organisation widerspiegelt.
Alle modernen Computer haben einige gemeinsame und individuelle architektonische Eigenschaften. Individuelle Eigenschaften sind nur einem bestimmten Computermodell eigen.
Das Konzept der Computerarchitektur umfasst:
Blockdiagramm eines Computers;
Mittel und Methoden für den Zugriff auf die Elemente des Blockdiagramms eines Computers;
Satz und Verfügbarkeit von Registern;
Organisation und Methoden der Adressierung;
Präsentationsverfahren und Format von Computerdaten;
eine Reihe von Computermaschinenanweisungen;
Maschinenbefehlsformate;
Unterbrechungsbehandlung.
Die Hauptelemente der Computerhardware: Systemeinheit, Tastatur, Anzeigegeräte, Laufwerke, Druckgeräte (Drucker) und verschiedene Kommunikationsmittel. Die Systemeinheit besteht aus der Systemplatine, dem Netzteil und Erweiterungssteckplätzen für zusätzliche Platinen. Das Motherboard enthält den Mikroprozessor, den Nur-Lese-Speicher (ROM), den Direktzugriffsspeicher (RAM) und den Coprozessor.
Register.
Innerhalb des Mikroprozessors sind Informationen in einer Gruppe von 32 Registern (16 Benutzer, 16 System) enthalten, die dem Programmierer mehr oder weniger zur Verfügung stehen. Da sich das Handbuch der Programmierung des Mikroprozessors 8088-i486 widmet, ist es am logischsten, dieses Thema mit der Erörterung der internen Register des Mikroprozessors zu beginnen, die dem Benutzer zur Verfügung stehen.
Benutzerregister werden vom Programmierer zum Schreiben von Programmen verwendet. Zu diesen Registern gehören:
acht 32-Bit-Register (Allzweckregister) EAX/AX/AH/AL, EBX/BX/BH/BL, ECX/CX/CH/CL, EDX/DX/DLH/DL, EBP/BP, ESI/SI, EDI/DI, ESP/SP;
sechs 16-Bit-Segmentregister: CS, DS, SS, ES, FS, GS;
Status- und Steuerregister: EFLAGS/FLAGS-Flag-Register und EIP/IP-Befehlszeigerregister.
Teile eines 32-Bit-Registers werden durch einen Schrägstrich dargestellt. Das Präfix E (Extended) kennzeichnet die Verwendung eines 32-Bit-Registers. Um mit Bytes zu arbeiten, werden Register mit den Präfixen L (low) und H (high) verwendet, z. B. AL, CH - die Low- und High-Bytes der 16-Bit-Teile der Register bezeichnen.
Allgemeine Register.
EAX/AX/AH/AL(Akkumulatorregister) - Batterie. Wird bei Multiplikation und Division, bei E/A-Operationen und bei einigen Operationen mit Zeichenfolgen verwendet.
EBX/BX/BH/BL - Basisregister(Basisregister), wird häufig verwendet, wenn Daten im Speicher adressiert werden.
ECX/CX/CH/CL - Schalter(Zählregister), dient als Zähler für die Anzahl der Schleifenwiederholungen.
EDX/DX/DH/DL - Datenregister(Datenregister), das zum Speichern von Zwischendaten verwendet wird. Einige Befehle erfordern es.
Alle Register dieser Gruppe erlauben den Zugriff auf ihre "unteren" Teile. Nur die unteren 16- und 8-Bit-Teile dieser Register können für die Selbstadressierung verwendet werden. Die oberen 16 Bit dieser Register stehen nicht als eigenständige Objekte zur Verfügung.
Zur Unterstützung von Zeichenfolgenverarbeitungsbefehlen, die eine sequentielle Verarbeitung von Zeichenfolgen von Elementen mit einer Länge von 32, 16 oder 8 Bit ermöglichen, werden die folgenden verwendet:
ESI/SI (Quellindexregister) - Index Quelle. Enthält die Adresse des aktuellen Quellelements.
EDI/DI (Distanzregister) - Index Empfänger(Empfänger). Enthält die aktuelle Adresse im Zielstring.
Die Architektur des Mikroprozessors auf Hard- und Softwareebene unterstützt die Datenstruktur – den Stack. Um mit dem Stack zu arbeiten, gibt es spezielle Befehle und spezielle Register. Es ist zu beachten, dass der Stack zu kleineren Adressen hin gefüllt wird.
ESP/SP (Stapelzeigerregister) - registrieren Zeiger Stapel. Enthält einen Zeiger auf den Stapelanfang im aktuellen Stapelsegment.
EBP/BP (Basiszeigerregister) – Stapelbasiszeigerregister. Entwickelt, um den wahlfreien Zugriff auf Daten innerhalb des Stacks zu organisieren.
1.1.2. Segmentregister
Das Mikroprozessor-Softwaremodell hat sechs Segmentregister: CS, SS, DS, ES, GS, FS. Ihre Existenz ist auf die Besonderheiten der Organisation und Verwendung von RAM durch Intel-Mikroprozessoren zurückzuführen. Die Mikroprozessor-Hardware unterstützt die strukturelle Organisation des Programms bestehend aus Segmente. Segmentregister werden verwendet, um anzuzeigen, welche Segmente aktuell verfügbar sind. Der Mikroprozessor unterstützt die folgenden Arten von Segmenten:
Codesegment. Enthält Programmbefehle Um auf dieses Segment zuzugreifen, verwenden Sie das CS-Register (Code Segment Register) - Segmentcoderegister. Es enthält die Adresse des Maschinenbefehlssegments, auf das der Mikroprozessor Zugriff hat.
Datensegment. Enthält die vom Programm verarbeiteten Daten. Um auf dieses Segment zuzugreifen, wird das DS-Register (Datensegmentregister) verwendet - Segmentdatenregister, das die Adresse des Datensegments des aktuellen Programms speichert.
Stack-Segment. Dieses Segment ist ein Speicherbereich, der Stapel genannt wird. Der Mikroprozessor organisiert den Stack nach dem Prinzip – der Erste „kam“, der Erste „ging“. Um auf den Stack zuzugreifen, wird das SS-Register (Stack Segment Register) verwendet - Stapelsegmentregister A enthält die Adresse des Stapelsegments.
Zusätzliches Datensegment. Die zu verarbeitenden Daten können sich in drei weiteren Datensegmenten befinden. Standardmäßig wird davon ausgegangen, dass sich die Daten im Datensegment befinden. Bei Verwendung zusätzlicher Datensegmente müssen deren Adressen explizit durch spezielle Segment-Redefinition-Präfixe im Befehl angegeben werden. Adressen zusätzlicher Datensegmente müssen in den Registern ES, GS, FS (Extension Data Segment Registers) enthalten sein.
Steuer- und Statusregister
Der Mikroprozessor enthält mehrere Register, die Informationen über den Zustand sowohl des Mikroprozessors selbst als auch des Programms enthalten, dessen Anweisungen gerade in die Pipeline geladen werden. Das:
EIP/IP-Befehlszeigerregister;
EFLAGS/FLAGS-Flag-Register.
Mithilfe dieser Register können Sie Informationen über die Ergebnisse der Befehlsausführung erhalten und den Zustand des Mikroprozessors selbst beeinflussen.
EIP/IP (Befehlszeigerregister) - Zeiger Befehle. Das EIP/IP-Register ist 32 oder 16 Bit breit und enthält den Offset des nächsten auszuführenden Befehls relativ zu den Inhalten des CS-Segmentregisters im aktuellen Befehlssegment. Dieses Register ist nicht direkt zugänglich, wird aber durch Sprungbefehle verändert.
EFLAGS/FLAGS (Flaggenregister) - registrieren Flaggen. Bittiefe 32/16 Bit. Einzelne Bits dieses Registers haben einen bestimmten funktionalen Zweck und werden Flags genannt. Ein Flag ist ein Bit, das auf 1 ("Flag ist gesetzt") gesetzt ist, wenn eine Bedingung wahr ist, und andernfalls auf 0 ("Flag ist gelöscht"). Der untere Teil dieses Registers ist vollständig analog zum FLAGS-Register für den i8086.
1.1.3 Flaggenregister
Das Flag-Register ist 32 Bit groß und trägt den Namen EFLAGS (Bild 1). Einzelne Bits des Registers haben einen bestimmten funktionalen Zweck und werden Flags genannt. Jedem von ihnen ist ein bestimmter Name zugeordnet (ZF, CF usw.). Die unteren 16 Bits von EFLAGS stellen das 16-Bit-FLAGS-Register dar, das verwendet wird, wenn Programme ausgeführt werden, die für die i086- und i286-Mikroprozessoren geschrieben wurden.
Abb.1 Flaggenregister
Einige Flags werden Bedingungsflags genannt; Sie ändern sich automatisch, wenn Befehle ausgeführt werden, und legen bestimmte Eigenschaften ihres Ergebnisses fest (z. B. ob es gleich Null ist). Andere Flags werden Zustandsflags genannt; sie verändern sich vom Programm und beeinflussen das weitere Verhalten des Prozessors (zB blockieren sie Interrupts).
Bedingungsflags:
CF (Carry-Flag) - Flagge tragen. Sie nimmt den Wert 1 an, wenn bei der Addition ganzer Zahlen eine Übertragseinheit auftauchte, die nicht in das Bitraster „passte“, oder wenn bei der Subtraktion vorzeichenloser Zahlen die erste kleiner war als die zweite. Bei den Shift-Befehlen wird das Off-Grid-Bit in die CF eingetragen. CF behebt auch die Merkmale der Multiplikationsanweisung.
OF (Überlauf-Flag) Überlauf-Flag. Es wird auf 1 gesetzt, wenn beim Addieren oder Subtrahieren ganzer Zahlen mit Vorzeichen das Ergebnis modulo über dem zulässigen Wert erhalten wurde (die Mantisse ist übergelaufen und in das Vorzeichenbit "geklettert").
ZF (Nullfahne) Null-Flag. Auf 1 gesetzt, wenn das Ergebnis des Befehls 0 ist.
SF (SIGN-Flag) - Flagge Schild. Auf 1 setzen, wenn die Operation mit vorzeichenbehafteten Zahlen zu einem negativen Ergebnis führt.
PF (Paritätsflag) - Flagge Parität. Es ist gleich 1, wenn das Ergebnis des nächsten Befehls eine gerade Anzahl binärer Einsen enthält. Sie wird in der Regel nur bei I/O-Operationen berücksichtigt.
AF (Auxiliary Carry Flag) - zusätzliches Carry-Flag. Behebt die Funktionen zum Ausführen von Operationen mit Binär-Dezimal-Zahlen.
Statusflags:
DF (Richtungsflagge) Richtungsfahne. Legt die Richtung des Scannens von Zeilen in String-Befehlen fest: Mit DF=0 werden Zeilen "vorwärts" (von Anfang bis Ende) gescannt, mit DF=1 - in die entgegengesetzte Richtung.
IOPL (Eingabe-/Ausgabeberechtigungsebene) - E/A-Berechtigungsstufe. Wird im geschützten Modus des Mikroprozessors verwendet, um den Zugriff auf E / A-Befehle zu steuern, abhängig von der Berechtigung der Aufgabe.
NT (verschachtelte Aufgabe) Task-Verschachtelungsflag. Wird im geschützten Modus des Mikroprozessors verwendet, um die Tatsache aufzuzeichnen, dass eine Aufgabe in einer anderen verschachtelt ist.
Systemflag:
IF (INTERrupt-Flag) - Interrupt-Flag. Bei IF=0 reagiert der Prozessor nicht mehr auf ankommende Interrupts, bei IF=1 wird die Blockierung von Interrupts aufgehoben.
TF (Trap-Flag) Trace-Flag. Bei TF = 1 macht der Prozessor nach Ausführung jeder Anweisung einen Interrupt (mit der Nummer 1), der beim Debuggen eines Programms verwendet werden kann, um es zu verfolgen.
RF (Wiederaufnahme-Flag) Flagge wieder aufnehmen. Wird verwendet, wenn Interrupts von den Debug-Registern verarbeitet werden.
VM (virtueller 8086-Modus) - virtuelles 8086-Flag. 1 – der Prozessor arbeitet im virtuellen 8086-Modus 0 – der Prozessor arbeitet im realen oder geschützten Modus.
AC (Alignment check) - Ausrichtungskontrollflag. Entwickelt, um die Ausrichtungssteuerung beim Zugriff auf den Speicher zu ermöglichen.
Organisation des Gedächtnisses.
Der physische Speicher, auf den der Mikroprozessor Zugriff hat, wird aufgerufen Arbeitsgedächtnis ( oder Speicher mit wahlfreiem Zugriff RAM). RAM ist eine Kette von Bytes, die ihre eigene eindeutige Adresse (ihre Nummer) haben, genannt körperlich. Der physische Adressbereich liegt zwischen 0 und 4 GB. Der Speicherverwaltungsmechanismus ist vollständig hardwarebasiert.
Der Mikroprozessor unterstützt mehrere Modelle der RAM-Nutzung in der Hardware:
segmentiertes Modell. Bei diesem Modell wird der Programmspeicher in zusammenhängende Speicherbereiche (Segmente) unterteilt, und das Programm selbst kann nur auf Daten zugreifen, die sich in diesen Segmenten befinden;
Seitenmodell. In diesem Fall wird RAM als eine Gruppe von Blöcken mit einer festen Größe von 4 KB betrachtet. Die Hauptanwendung dieses Modells bezieht sich auf die Organisation des virtuellen Speichers, der es Programmen ermöglicht, mehr Speicherplatz als die Menge an physischem Speicher zu verwenden. Bei einem Pentium-Mikroprozessor kann die Größe des möglichen virtuellen Speichers bis zu 4 TB betragen.
Die Verwendung und Implementierung dieser Modelle hängt von der Betriebsart des Mikroprozessors ab:
Real-Adress-Modus (Real-Modus). Der Modus ähnelt dem Betrieb des i8086-Prozessors. Erforderlich für den Betrieb von Programmen, die für frühe Prozessormodelle entwickelt wurden.
Sicherheitsmodus. Im geschützten Modus wird es möglich, Informationsverarbeitung, Speicherschutz unter Verwendung eines vierstufigen Berechtigungsmechanismus und dessen Paging im Multitasking zu verarbeiten.
Virtueller 8086-Modus. In diesem Modus wird es möglich, mehrere Programme für i8086 auszuführen. In diesem Fall können Real-Modus-Programme funktionieren.
Die Segmentierung ist ein Adressierungsmechanismus, der die Existenz mehrerer unabhängiger Adressräume sicherstellt. Ein Segment ist ein unabhängiger, hardwareunterstützter Speicherblock.
Jedes Programm kann im Allgemeinen aus beliebig vielen Segmenten bestehen, hat aber direkten Zugriff auf die drei Hauptsegmente: Code, Daten und Stack – und auf ein bis drei zusätzliche Datensegmente. Das Betriebssystem platziert Programmsegmente im RAM an bestimmten physikalischen Adressen und platziert dann die Werte dieser Adressen in den entsprechenden Registern. Innerhalb eines Segments greift das Programm auf Adressen relativ zum Anfang des Segments linear zu, d. h. beginnend bei Adresse 0 und endend bei einer Adresse gleich der Größe des Segments. Relative Adresse bzw Voreingenommenheit, die der Mikroprozessor verwendet, um auf Daten innerhalb eines Segments zuzugreifen, aufgerufen Wirksam.
Bildung einer physikalischen Adresse im Realmodus
Im Real-Modus reicht der physikalische Adressbereich von 0 bis 1 MB. Die maximale Segmentgröße beträgt 64 KB. Bei Bezugnahme auf eine bestimmte physikalische Adresse RAM wird durch die Adresse des Segmentanfangs und den Offset innerhalb des Segments bestimmt. Die Segmentstartadresse wird dem entsprechenden Segmentregister entnommen. In diesem Fall enthält das Segmentregister nur die oberen 16 Bit der physikalischen Adresse des Segmentanfangs. Die fehlenden unteren vier Bits der 20-Bit-Adresse erhält man, indem man den Wert des Segmentregisters um 4 Bits nach links verschiebt. Die Verschiebungsoperation wird in Hardware durchgeführt. Der resultierende 20-Bit-Wert ist die tatsächliche physikalische Adresse, die dem Anfang des Segments entspricht. Also physische Adresse wird als ein "Segment:Offset"-Paar angegeben, wobei "Segment" die ersten 16 Bits der Startadresse des Speichersegments sind, zu dem die Zelle gehört, und "Offset" die 16-Bit-Adresse dieser Zelle ist, gezählt ab Anfang dieses Speichersegments (Wert 16*Segment + Offset ergibt die absolute Adresse der Zelle). Wenn beispielsweise der Wert 1234h im CS-Register gespeichert ist, dann definiert das Adresspaar 1234h:507h eine absolute Adresse gleich 16*1234h+507h = 12340h+507h = 12847h. Ein solches Paar wird in Form eines Doppelworts und (wie bei Zahlen) in einer "umgekehrten" Form geschrieben: Das erste Wort enthält den Offset und das zweite - das Segment, in dem jedes dieser Wörter wiederum dargestellt wird "umgekehrte" Form. Das Paar 1234h:5678h würde beispielsweise so geschrieben:| 78 | 56| 34 | 12|.
Dieser Mechanismus zur Bildung einer physikalischen Adresse ermöglicht es Ihnen, die Software verschiebbar zu machen, dh unabhängig von bestimmten Download-Adressen im Arbeitsspeicher.
Die Programmierung auf der Ebene von Maschinenbefehlen ist die Mindestebene, auf der eine Programmierung möglich ist. Das System der Maschinenbefehle muss ausreichen, um die erforderlichen Aktionen auszuführen, indem Anweisungen an die Computerhardware ausgegeben werden.
Jeder Maschinenbefehl besteht aus zwei Teilen:
- OP-Saal – bestimmen, „was zu tun ist“;
- Operand - Definieren von Verarbeitungsobjekten, „was damit zu tun ist“.
Die in Assemblersprache geschriebene Maschinenanweisung des Mikroprozessors ist eine einzelne Zeile mit der folgenden syntaktischen Form:
Label-Befehl/Anweisung Operand(en) ;Kommentare
In diesem Fall ist ein Pflichtfeld in einer Zeile ein Befehl oder eine Direktive.
Label, Befehl/Anweisung und Operanden (falls vorhanden) werden durch mindestens ein Leerzeichen oder Tabulatorzeichen getrennt.
Wenn ein Befehl oder eine Anweisung in der nächsten Zeile fortgesetzt werden muss, wird der umgekehrte Schrägstrich verwendet: \.
Standardmäßig unterscheidet die Assemblersprache nicht zwischen Groß- und Kleinbuchstaben in Befehlen oder Anweisungen.
Beispielzeilen Code:
Zähldatenbank 1 ;Name, Direktive, ein Operand
verschieben eax,0 ;Befehl, zwei Operanden
cbw ; Befehl
Stichworte
Etikette in Assemblersprache kann die folgenden Symbole enthalten:
- alle Buchstaben des lateinischen Alphabets;
- Zahlen von 0 bis 9;
- Sonderzeichen: _, @, $, ?.
Ein Punkt kann als erstes Zeichen eines Labels verwendet werden, aber einige Compiler raten von diesem Zeichen ab. Reservierte Assemblersprachennamen (Direktiven, Operatoren, Befehlsnamen) können nicht als Labels verwendet werden.
Das erste Zeichen im Label muss ein Buchstabe oder Sonderzeichen sein (keine Zahl). Die maximale Etikettenlänge beträgt 31 Zeichen. Alle Labels, die in eine Zeile geschrieben werden, die keine Assembler-Direktive enthält, müssen mit einem Doppelpunkt enden: .
Mannschaften
Befehl teilt dem Übersetzer mit, welche Aktion der Mikroprozessor ausführen soll. In einem Datensegment definiert ein Befehl (oder eine Direktive) ein Feld, einen Arbeitsbereich oder eine Konstante. In einem Codesegment definiert eine Anweisung eine Aktion, wie z. B. eine Bewegung (mov) oder eine Addition (add).
Richtlinien
Der Assembler verfügt über eine Reihe von Operatoren, mit denen Sie den Prozess des Assemblierens und Generierens eines Listings steuern können. Diese Operatoren werden aufgerufen Richtlinien . Sie wirken nur beim Zusammenstellen des Programms und erzeugen im Gegensatz zu Anweisungen keine Maschinencodes.
Operanden
Operand
– ein Objekt, auf dem ein Maschinenbefehl oder ein Programmiersprachenoperator ausgeführt wird.
Eine Anweisung kann einen oder zwei Operanden oder überhaupt keine Operanden haben. Die Anzahl der Operanden wird implizit durch den Befehlscode angegeben.
Beispiele:
- Keine Operanden ret ;Return
- Ein Operand inc ecx ;Erhöhe ecx
- Zwei Operanden addieren eax,12 ;Addiere 12 zu eax
Label, Befehl (Direktive) und Operand müssen nicht an einer bestimmten Position im String beginnen. Es wird jedoch empfohlen, sie für eine bessere Lesbarkeit des Programms in eine Spalte zu schreiben.
Operanden können sein
- Identifikatoren;
- in einfache oder doppelte Anführungszeichen eingeschlossene Zeichenfolgen;
- Ganzzahlen im Binär-, Oktal-, Dezimal- oder Hexadezimalformat.
Identifikatoren
Identifikatoren – Sequenzen gültiger Zeichen, die zur Bezeichnung von Programmobjekten wie Operationscodes, Variablennamen und Bezeichnungsnamen verwendet werden.
Regeln zum Schreiben von Bezeichnern.
- Die Kennung kann aus einem oder mehreren Zeichen bestehen.
- Als Zeichen können Sie Buchstaben des lateinischen Alphabets, Zahlen und einige Sonderzeichen verwenden: _, ?, $, @.
- Ein Bezeichner darf nicht mit einer Ziffer beginnen.
- Die ID kann bis zu 255 Zeichen lang sein.
- Der Übersetzer akzeptiert die ersten 32 Zeichen des Bezeichners und ignoriert den Rest.
Bemerkungen
Kommentare werden durch ein Zeichen von der ausführbaren Zeile getrennt; . In diesem Fall ist alles, was nach dem Semikolon und bis zum Zeilenende geschrieben wird, ein Kommentar. Die Verwendung von Kommentaren in einem Programm verbessert dessen Übersichtlichkeit, insbesondere wenn der Zweck einer Reihe von Anweisungen unklar ist. Der Kommentar kann alle druckbaren Zeichen einschließlich Leerzeichen enthalten. Der Kommentar kann sich über die gesamte Zeile erstrecken oder dem Befehl in derselben Zeile folgen.
Aufbau des Montageprogramms
Ein in Assemblersprache geschriebenes Programm kann aus mehreren Teilen bestehen, genannt Module . Jedes Modul kann ein oder mehrere Daten-, Stapel- und Codesegmente definieren. Jedes vollständige Assemblersprachenprogramm muss ein Haupt- oder Hauptmodul enthalten, von dem aus seine Ausführung beginnt. Ein Modul kann Code-, Daten- und Stapelsegmente enthalten, die mit den entsprechenden Direktiven deklariert sind. Bevor Sie Segmente deklarieren, müssen Sie das Speichermodell mit der Direktive .MODEL angeben.
Ein Beispiel für ein „nichts tun“-Programm in Assemblersprache:
686P
.MODEL WOHNUNG, STDCALL
.DATEN
.CODE
ANFANG:
RET
ENDE START
Dieses Programm enthält nur einen Mikroprozessorbefehl. Dieser Befehl ist RET . Es sorgt für die korrekte Beendigung des Programms. Im Allgemeinen wird dieser Befehl verwendet, um eine Prozedur zu beenden.
Der Rest des Programms bezieht sich auf den Betrieb des Übersetzers.
.686P - Befehle für den geschützten Modus von Pentium 6 (Pentium II) sind zulässig. Diese Direktive wählt den unterstützten Assembler-Befehlssatz durch Angabe des Prozessormodells aus. Der Buchstabe P am Ende der Direktive teilt dem Übersetzer mit, dass der Prozessor im geschützten Modus läuft.
.MODEL FLAT, stdcall ist ein flaches Speichermodell. Dieses Speichermodell wird im Windows-Betriebssystem verwendet. Standardanruf
.DATA ist ein Programmsegment, das Daten enthält.
.CODE ist ein Programmblock, der Code enthält.
START ist ein Label. In Assembler spielen Labels eine große Rolle, was man von modernen Hochsprachen nicht behaupten kann.
END START - das Ende des Programms und eine Nachricht an den Übersetzer, dass das Programm ab dem Label START gestartet werden muss.
Jedes Modul muss eine END-Direktive enthalten, die das Ende des Quellcodes des Programms markiert. Alle Zeilen, die der END-Direktive folgen, werden ignoriert. Das Weglassen der END-Direktive erzeugt einen Fehler.
Die Bezeichnung nach der END-Direktive teilt dem Compiler den Namen des Hauptmoduls mit, von dem aus die Programmausführung beginnt. Wenn das Programm ein Modul enthält, kann das Label nach der END-Direktive weggelassen werden.
Befehle können nach Zweck unterschieden werden (Beispiele für mnemonische Opcodes von Befehlen eines PC-Assemblers wie IBM PC sind in Klammern angegeben):
l выполнения арифметических операций (ADD и ADC - сложения и сложения с переносом, SUB и SBB - вычитания и вычитания с заемом, MUL и IMUL - умножения без знака и со знаком, DIV и IDIV - деления без знака и со знаком, CMP - сравнения usw.);
l Ausführung logischer Operationen (OR, AND, NOT, XOR, TEST usw.);
l Datenübertragung (MOV - senden, XCHG - austauschen, IN - in den Mikroprozessor eingeben, OUT - vom Mikroprozessor abziehen usw.);
l Steuerungsübergabe (Programmverzweigungen: JMP - unbedingte Verzweigung, CALL - Prozeduraufruf, RET - Rückkehr von der Prozedur, J* - bedingte Verzweigung, LOOP - Schleifensteuerung usw.);
l Verarbeitung von Zeichenfolgen (MOVS - Übertragungen, CMPS - Vergleiche, LODS - Downloads, SCAS - Scans. Diese Befehle werden normalerweise mit einem Präfix (Wiederholungsmodifikator) REP verwendet;
l Programm-Interrupts (INT - Software-Interrupts, INTO - bedingte Interrupts bei Überlauf, IRET - Rückkehr vom Interrupt);
l Mikroprozessorsteuerung (ST* und CL* - Flags setzen und löschen, HLT - Stopp, WAIT - Standby, NOP - Leerlauf usw.).
Eine vollständige Liste der Assembler-Befehle befindet sich in Arbeit.
Datenübertragungsbefehle
l MOV dst, src - Datenübertragung (move - verschieben von src nach dst).
Überträgt: ein Byte (wenn src und dst im Byte-Format sind) oder ein Wort (wenn src und dst im Wort-Format sind) zwischen Registern oder zwischen Register und Speicher und schreibt einen sofortigen Wert in ein Register oder einen Speicher.
Die Operanden dst und src müssen dasselbe Format haben - Byte oder Wort.
Src kann vom Typ sein: r (Register) – Register, m (Speicher) – Speicher, i (Impedanz) – sofortiger Wert. Dst kann vom Typ r, m sein. Operanden können nicht in einem Befehl verwendet werden: rsegm zusammen mit i; zwei Operanden vom Typ m und zwei Operanden vom Typ rsegm). Operand i kann auch ein einfacher Ausdruck sein:
Bewegung AX, (152 + 101B) / 15
Die Ausdrucksauswertung wird nur während der Übersetzung durchgeführt. Flags ändern sich nicht.
l PUSH src - legt ein Wort auf den Stack (push - durchsetzen; von src auf den Stack schieben). Schiebt den Inhalt von src an die Spitze des Stapels – jedes 16-Bit-Register (einschließlich Segment) oder zwei Speicherstellen, die ein 16-Bit-Wort enthalten. Die Flags ändern sich nicht;
l POP dst - Extrahieren eines Wortes aus dem Stack (pop - pop; Zähle vom Stack in dst). Entfernt ein Wort von der Spitze des Stacks und platziert es in dst – einem beliebigen 16-Bit-Register (einschließlich Segment) oder zwei Speicherstellen. Flags ändern sich nicht.
Kursarbeit
Thema "Systemprogrammierung"
Thema Nummer 4: "Problemlösung für Verfahren"
Option 2
EAST SIBIRIAN STATE UNIVERSITY
TECHNOLOGIE UND MANAGEMENT
____________________________________________________________________
TECHNOLOGISCHE HOCHSCHULE
DIE AUFGABE
für Hausarbeiten
| Disziplin: |
| Thema: Problemlösung für Verfahren |
| Künstler: Glawinskaja Arina Alexandrowna |
| Leitung: Sesegma Viktorovna Dambaeva |
| Kurze Zusammenfassung der Arbeit: das Studium von Subroutinen in Assemblersprache, |
| Problemlösung mit Subroutinen |
| 1. Theoretischer Teil: Grundlegende Informationen zur Assemblersprache (set |
| Befehle usw.), Organisation von Unterprogrammen, Möglichkeiten der Parameterübergabe |
| in Unterprogrammen |
| 2. Praktischer Teil: Entwickeln Sie zwei Subroutinen, von denen eine einen beliebigen Buchstaben in Großbuchstaben (einschließlich russischer Buchstaben) und die andere den Buchstaben in Kleinbuchstaben konvertiert. |
| wandelt jeden gegebenen Buchstaben in Großbuchstaben um, und der andere wandelt den Buchstaben in Kleinbuchstaben um. |
| wandelt einen Buchstaben in Kleinbuchstaben um. |
| Projektzeitpläne gemäß Zeitplan: |
| 1. Theoretischer Teil - 30 % bis Woche 7. |
| 2. Praktischer Teil - 70 % nach 11 Wochen. |
| 3. Schutz - 100 % nach 14 Wochen. |
| Gestaltungsanforderungen: |
| 1. Die Abrechnung und Begründung des Kursvorhabens sind einzureichen |
| elektronische und gedruckte Kopien. |
| 2. Der Umfang des Berichts muss mindestens 20 maschinengeschriebene Seiten ohne Anhänge betragen. |
| 3. RPP wird gemäß GOST 7.32-91 erstellt und vom Leiter unterzeichnet. |
Arbeitsleiter __________________
Darsteller __________________
Datum der Ausstellung " 26 " September 2017 G.
Einführung. 2
1.1 Grundlegende Informationen zur Assemblersprache. 3
1.1.1 Befehlssatz. 4
1.2 Organisation von Subroutinen in Assemblersprache. 4
1.3 Methoden zum Übergeben von Parametern in Unterprogrammen. 6
1.3.1 Übergabe von Parametern durch Register.. 6
1.3.2 Übergabe von Parametern durch den Stack. 7
2 PRAKTISCHER ABSCHNITT 9
2.1 Problemstellung. neun
2.2 Beschreibung der Problemlösung. neun
2.3 Testen des Programms.. 7
Fazit. 8
Referenzen.. 9
Einführung
Es ist allgemein bekannt, dass das Programmieren in Assemblersprache schwierig ist. Wie Sie wissen, gibt es mittlerweile viele verschiedene Sprachen hohes Level, wodurch Sie viel weniger Aufwand beim Schreiben von Programmen aufwenden können. Natürlich stellt sich die Frage, wann ein Programmierer beim Schreiben von Programmen Assembler verwenden muss. Derzeit gibt es zwei Bereiche, in denen die Verwendung von Assemblersprache gerechtfertigt und oft notwendig ist.
Erstens sind dies die sogenannten maschinenabhängigen Systemprogramme, sie steuern normalerweise verschiedene Computergeräte (solche Programme werden Treiber genannt). Diese Systemprogramme verwenden spezielle Maschinenbefehle, die normalerweise nicht verwendet werden müssen (oder, wie sie sagen, angewandt) Programme. Diese Befehle sind in einer Hochsprache nicht oder nur sehr schwer zu spezifizieren.
Das zweite Einsatzgebiet von Assembler betrifft die Optimierung der Programmausführung. Sehr oft produzieren Übersetzungsprogramme (Compiler) aus Hochsprachen ein sehr ineffizientes Maschinensprachenprogramm. Dies gilt normalerweise für Programme mit Rechencharakter, bei denen ein sehr kleiner (etwa 3–5 %) Abschnitt des Programms (die Hauptschleife) die meiste Zeit ausgeführt wird. Um dieses Problem zu lösen, können sogenannte mehrsprachige Programmiersysteme eingesetzt werden, die es ermöglichen, Teile des Programms in verschiedenen Sprachen zu schreiben. Üblicherweise wird der Hauptteil des Programms in einer höheren Programmiersprache (Fortran, Pascal, C etc.) und die zeitkritischen Programmteile in Assembler geschrieben. In diesem Fall kann sich die Geschwindigkeit des gesamten Programms erheblich erhöhen. Dies ist oft die einzige Möglichkeit, ein Programm dazu zu bringen, in angemessener Zeit Ergebnisse zu erzielen.
Ziel dieser Kursarbeit ist es, praktische Fähigkeiten in der Programmierung in Assemblersprache zu erwerben.
Arbeitsaufgaben:
1. Grundlegende Informationen über die Sprache Assembler lernen (Struktur und Komponenten des Programms in Assembler, Befehlsformat, Organisation von Unterprogrammen usw.);
2. die Arten von Bitoperationen, das Format und die Logik der Assembler-Logikbefehle zu studieren;
3. Lösen Sie ein individuelles Problem für die Verwendung von Unterprogrammen in Assembler;
4. Formulieren Sie ein Fazit über die geleistete Arbeit.
1 THEORETISCHER ABSCHNITT
Grundlagen der Assemblersprache
Assembler ist eine Low-Level-Programmiersprache, die ein Format zum Schreiben von Maschinenanweisungen darstellt, das für die menschliche Wahrnehmung geeignet ist.
Befehle der Assemblersprache entsprechen eins zu eins Prozessorbefehlen und stellen tatsächlich eine bequeme symbolische Form der Notation (mnemonischer Code) von Befehlen und ihren Argumenten dar. Die Assemblersprache bietet auch grundlegende Programmierabstraktionen: das Verknüpfen von Programmteilen und Daten durch Labels mit symbolischen Namen und Direktiven.
Assembler-Direktiven ermöglichen es Ihnen, Datenblöcke (explizit beschrieben oder aus einer Datei gelesen) in das Programm einzufügen; ein bestimmtes Fragment eine bestimmte Anzahl von Malen wiederholen; kompilieren Sie das Fragment gemäß der Bedingung; Stellen Sie die Fragmentausführungsadresse ein, ändern Sie die Labelwerte während der Kompilierung; Verwenden Sie Makrodefinitionen mit Parametern usw.
Vorteile und Nachteile
Die minimale Menge an redundantem Code (die Verwendung von weniger Befehlen und Speicherzugriffen). Als Folge - höhere Geschwindigkeit und kleinere Programmgröße;
große Mengen an Code, viele zusätzliche kleine Aufgaben;
Schlechte Lesbarkeit des Codes, Schwierigkeiten beim Support (Debuggen, Hinzufügen von Funktionen);
· die Schwierigkeit, Programmierparadigmen und andere etwas komplexe Konventionen zu implementieren, die Komplexität gemeinsamer Entwicklung;
Weniger verfügbare Bibliotheken, ihre geringe Kompatibilität;
· direkter Zugriff auf Hardware: Input-Output-Ports, spezielle Prozessorregister;
maximales "fitting" für die gewünschte Plattform (Verwendung spezieller Anweisungen, technische Eigenschaften des "Eisens");
· Nicht-Portierbarkeit auf andere Plattformen (mit Ausnahme von binärkompatiblen).
Zusätzlich zu den Anweisungen kann das Programm Direktiven enthalten: Befehle, die nicht direkt in Maschinenanweisungen übersetzt werden, aber den Betrieb des Compilers steuern. Ihr Satz und ihre Syntax variieren erheblich und hängen nicht von der Hardwareplattform ab, sondern vom verwendeten Compiler (wodurch Dialekte von Sprachen innerhalb derselben Architekturfamilie entstehen). Als eine Reihe von Richtlinien können wir unterscheiden:
Definition von Daten (Konstanten und Variablen);
Verwaltung der Organisation des Programms im Speicher und der Parameter der Ausgabedatei;
Einstellen des Compilermodus;
· alle Arten von Abstraktionen (d. h. Elemente von Hochsprachen) – vom Entwurf von Prozeduren und Funktionen (um die Implementierung des prozeduralen Programmierparadigmas zu vereinfachen) bis hin zu bedingten Strukturen und Schleifen (für das strukturelle Programmierparadigma);
Makros.
Befehlssatz
Typische Anweisungen in Assemblersprache sind:
Datenübertragungsbefehle (mov usw.)
Arithmetische Befehle (add, sub, imul usw.)
Logische und bitweise Operationen (or, and, xor, shr usw.)
Befehle zur Verwaltung der Programmausführung (jmp, loop, ret usw.)
Anrufunterbrechungsbefehle (manchmal auch als Steuerbefehle bezeichnet): int
I/O-Befehle an Ports (in, out)
Mikrocontroller und Mikrocomputer sind auch durch Befehle gekennzeichnet, die Prüfungen und Übergänge nach Bedingung durchführen, zum Beispiel:
· jne – springe, wenn nicht gleich;
· jge-Sprung, wenn größer als oder gleich.