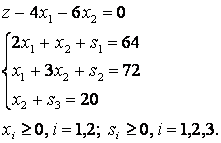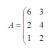Ανάλυση παλινδρόμησης σε excel αποκωδικοποίηση δεικτών. Conrad Karlberg. Ανάλυση παλινδρόμησης στο Microsoft Excel
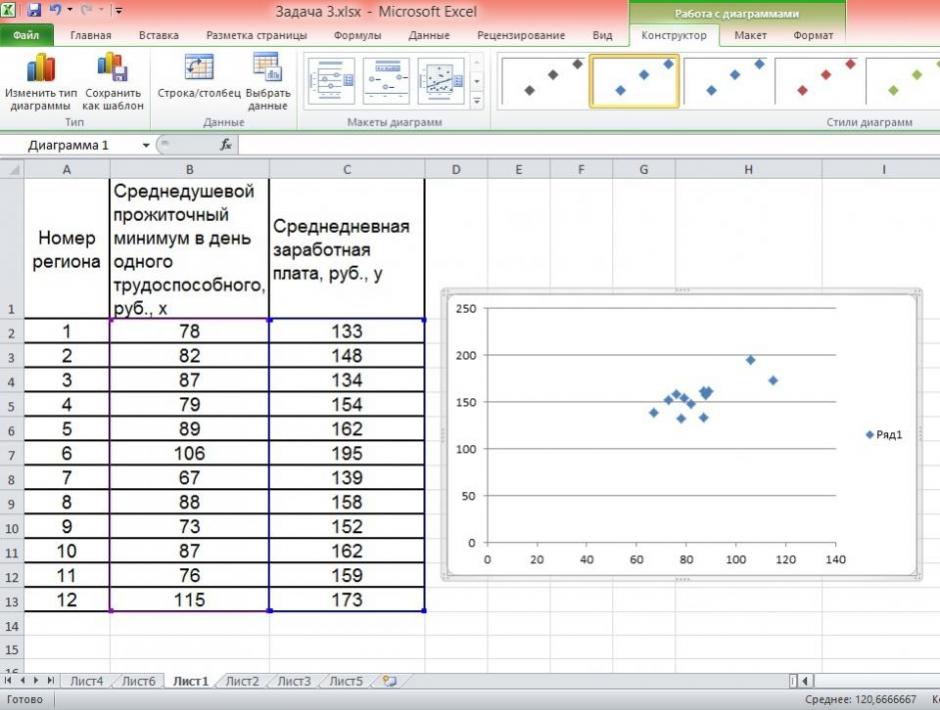
Το έδαφος της περιοχής παρέχει δεδομένα για 200Χ
| Αριθμός περιοχής | Το μέσο κατά κεφαλήν μέσον όρο μισθού ανά ημέρα ενός ατόμου με υψηλό επίπεδο σωματικής ικανότητας, ρούβλια, x | Ο μέσος ημερήσιος μισθός, ρούβλια, σε |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Ανάθεση:
1. Δημιουργήστε ένα πεδίο συσχετισμού και διατυπώστε μια υπόθεση σχετικά με τη μορφή της επικοινωνίας.
2. Υπολογίστε τις παραμέτρους της εξίσωσης γραμμικής παλινδρόμησης
4. Χρησιμοποιώντας τον μέσο (γενικό) συντελεστή ελαστικότητας, δώστε μια συγκριτική αξιολόγηση της αντοχής της σύνδεσης του παράγοντα με το αποτέλεσμα.
7. Υπολογίστε την προβλεπόμενη τιμή του αποτελέσματος εάν η προβλεπόμενη τιμή του παράγοντα αυξάνεται κατά 10% από το μέσο επίπεδο. Ορίστε ένα διάστημα εμπιστοσύνης πρόβλεψης για το επίπεδο σημαντικότητας.
Λύση:
Θα λύσουμε αυτό το πρόβλημα χρησιμοποιώντας το Excel.
1. Συγκρίνοντας τα διαθέσιμα δεδομένα x και y, για παράδειγμα, ταξινομώντας τα με αύξουσα σειρά του συντελεστή x, μπορεί κανείς να παρατηρήσει την ύπαρξη μιας άμεσης σχέσης μεταξύ των χαρακτηριστικών όταν η αύξηση του μέσου κατά κεφαλήν μισθού αυξάνει τον μέσο ημερήσιο μισθό. Με βάση αυτό, μπορεί να υποτεθεί ότι η σύνδεση μεταξύ των σημείων είναι άμεση και μπορεί να περιγραφεί από την εξίσωση της γραμμής. Το ίδιο συμπέρασμα επιβεβαιώνεται με βάση τη γραφική ανάλυση.
Για να δημιουργήσετε ένα πεδίο συσχέτισης, μπορείτε να χρησιμοποιήσετε το Excel IFR. Καταχωρίστε τα δεδομένα πηγής με την ακολουθία: πρώτα x, στη συνέχεια y.
Επιλέξτε την περιοχή κελιών που περιέχει τα δεδομένα.
Στη συνέχεια, επιλέξτε: Εισάγετε / διασκορπίστε / διασκορπίστε με δείκτες όπως φαίνεται στο σχήμα 1.

Σχήμα 1 Κατασκευή του πεδίου συσχετισμού
Η ανάλυση του πεδίου συσχέτισης δείχνει την ύπαρξη μιας σχεδόν απλής σχέσης, αφού τα σημεία βρίσκονται σχεδόν σε ευθεία γραμμή.
2. Για να υπολογίσετε τις παραμέτρους της εξίσωσης γραμμικής παλινδρόμησης
χρησιμοποιούμε την ενσωματωμένη στατιστική λειτουργία LINE.
Για να γίνει αυτό:
1) Ανοίξτε ένα υπάρχον αρχείο που περιέχει τα δεδομένα που έχουν αναλυθεί.
2) Επιλέξτε την περιοχή κενών κελιών 5 × 2 (5 σειρές, 2 στήλες) για να εμφανίσετε τα αποτελέσματα των στατιστικών παλινδρόμησης.
3) Ενεργοποίηση Οδηγός λειτουργιών: στο κύριο μενού, επιλέξτε Λειτουργία τύπων / εισόδου.
4) Στο παράθυρο Κατηγορία επιλέξτε Στατιστική, στη λειτουργία παραθύρου - LINE. Κάντε κλικ στο κουμπί Εντάξει όπως φαίνεται στο σχήμα 2,

Εικόνα 2 Το παράθυρο διαλόγου Οδηγός λειτουργιών
5) Συμπληρώστε τα επιχειρήματα των λειτουργιών:
Γνωστές τιμές του
Γνωστές τιμές x
Σταθερή - μια λογική τιμή που υποδηλώνει την παρουσία ή την απουσία ενός ελεύθερου όρου στην εξίσωση. αν Constant \u003d 1, τότε ο ελεύθερος όρος υπολογίζεται με τον συνήθη τρόπο, αν Constant \u003d 0 τότε ο ελεύθερος όρος είναι 0.
Στατιστικά στοιχεία - μια λογική τιμή που υποδεικνύει εάν θα εμφανιστούν πρόσθετες πληροφορίες σχετικά με την ανάλυση παλινδρόμησης ή όχι. Εάν η Στατιστική \u003d 1, τότε εμφανίζονται επιπρόσθετες πληροφορίες · εάν η Στατιστική \u003d 0, τότε εμφανίζονται μόνο οι εκτιμήσεις των παραμέτρων της εξίσωσης.
Κάντε κλικ στο κουμπί Εντάξει;

Εικόνα 3 Παράθυρο διαλόγου επιχειρήματα γραμμών λειτουργίας LINEIN
6) Το πρώτο στοιχείο του συνοπτικού πίνακα εμφανίζεται στο επάνω αριστερό κελί της επιλεγμένης περιοχής. Για να επεκτείνετε ολόκληρο τον πίνακα, πατήστε το πλήκτρο
Επιπλέον στατιστικά στοιχεία παλινδρόμησης θα εμφανίζονται με τη σειρά που καθορίζεται στο παρακάτω διάγραμμα:
| Συντελεστής β | Συντελεστής α |
| Τυπικό σφάλμα b | Τυπικό σφάλμα a |
| Πρότυπο σφάλμα y | |
| F στατιστικές | |
| Το άθροισμα παλινδρόμησης των τετραγώνων
|

Σχήμα 4 Το αποτέλεσμα του υπολογισμού της συνάρτησης LINE
Έχεις μια εξίσωση παλινδρόμησης:
Συμπεραίνουμε: Με την αύξηση του κατά κεφαλήν μισθού διαβίωσης κατά 1 rub. ο μέσος ημερήσιος μισθός αυξάνεται κατά μέσο όρο κατά 0,92 ρούβλια.
Αυτό σημαίνει ότι το 52% της μεταβολής των μισθών (y) εξηγείται από τη διακύμανση του συντελεστή x - το μέσο κατά κεφαλήν κόστος ζωής και το 48% - λόγω της δράσης άλλων παραγόντων που δεν περιλαμβάνονται στο μοντέλο.
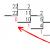
Από τον υπολογιζόμενο συντελεστή προσδιορισμού, ο συντελεστής συσχέτισης μπορεί να υπολογιστεί: ![]() .
.
Η επικοινωνία βαθμολογείται τόσο κοντά.
4. Χρησιμοποιώντας τον μέσο (ολικό) συντελεστή ελαστικότητας, προσδιορίζουμε τη δύναμη της επίδρασης του παράγοντα στο αποτέλεσμα.
Για την άμεση εξίσωση, ο μέσος (συνολικός) συντελεστής ελαστικότητας καθορίζεται από τον τύπο:

Βρίσκουμε τις μέσες τιμές επιλέγοντας την περιοχή των κυττάρων με τιμές x και επιλέγουμε Τύποι / AutoSum / Μέσος όρος, και θα κάνουμε το ίδιο με τις τιμές του y.

Εικόνα 5 Υπολογισμός των μέσων τιμών της συνάρτησης και του επιχειρήματος
Έτσι, εάν ο μέσος όρος κατά κεφαλήν κατώτατο μισθό μεταβάλλεται κατά 1% της μέσης αξίας του, ο μέσος ημερήσιος μισθός θα αλλάξει κατά μέσο όρο κατά 0,51%.
Χρησιμοποιώντας το εργαλείο ανάλυσης δεδομένων Η παλινδρόμηση μπορεί να πάρει:
- τα αποτελέσματα των στατιστικών παλινδρόμησης,
- τα αποτελέσματα της ανάλυσης της διακύμανσης,
- τα αποτελέσματα των διαστημάτων εμπιστοσύνης,
- τα υπολείμματα και τα γραφήματα της επιλογής της γραμμής παλινδρόμησης,
- υπολείμματα και κανονική πιθανότητα.
Η διαδικασία έχει ως εξής:
1) ελέγξτε την πρόσβαση στο Πακέτο ανάλυσης. Στο κύριο μενού, επιλέξτε: Αρχείο / Επιλογές / Πρόσθετα.
2) αναπτυσσόμενη λίστα Διαχείριση επιλέξτε στοιχείο Εξαρτήματα Excel και πατήστε το κουμπί Πήγαινε.
3) Στο παράθυρο Πρόσθετα ελέγξτε το κουτί Πακέτο ανάλυσηςκαι στη συνέχεια κάντε κλικ στο κουμπί Εντάξει.
Αν Πακέτο ανάλυσης όχι στη λίστα των πεδίων Διαθέσιμα πρόσθεταπατήστε το κουμπί Ανασκόπησηγια να εκτελέσετε μια αναζήτηση.
Εάν εμφανιστεί ένα μήνυμα που δηλώνει ότι το πακέτο ανάλυσης δεν είναι εγκατεστημένο στον υπολογιστή, κάντε κλικ στο κουμπί Ναιγια να το εγκαταστήσετε.
4) Στο κύριο μενού, επιλέξτε: Ανάλυση δεδομένων / δεδομένων / εργαλεία ανάλυσης / παλινδρόμησηκαι στη συνέχεια κάντε κλικ στο κουμπί Εντάξει.
5) Συμπληρώστε το παράθυρο διαλόγου για εισαγωγή δεδομένων και παραμέτρων εξόδου:
Εισαγωγικό διάστημα Y - μια περιοχή που περιέχει δεδομένα ενός αποτελεσματικού χαρακτηριστικού.
Εισαγωγικό διάστημα X - εύρος που περιέχει δεδομένα χαρακτηριστικού παράγοντα,
Ετικέτες - μια σημαία που υποδεικνύει αν η πρώτη σειρά περιέχει ονόματα στηλών ή όχι,
Σταθερό - μηδέν - μια σημαία που υποδηλώνει την παρουσία ή την απουσία ενός ελεύθερου όρου στην εξίσωση.
Περίοδος εξόδου - ορίστε ακριβώς το επάνω αριστερό κελί της μελλοντικής περιοχής.
6) Νέο φύλλο εργασίας - μπορείτε να ορίσετε ένα αυθαίρετο όνομα για το νέο φύλλο εργασίας.
Στη συνέχεια κάντε κλικ στο κουμπί Εντάξει.

Εικόνα 6 Παράθυρο διαλόγου για την εισαγωγή παραμέτρων του εργαλείου παλινδρόμησης
Τα αποτελέσματα της ανάλυσης παλινδρόμησης για τα δεδομένα εργασιών παρουσιάζονται στο Σχήμα 7.

Εικόνα 7 Αποτέλεσμα χρήσης του εργαλείου παλινδρόμησης
5. Υπολογίζουμε την ποιότητα των εξισώσεων χρησιμοποιώντας το μέσο σφάλμα προσέγγισης. Θα χρησιμοποιήσουμε τα αποτελέσματα της ανάλυσης παλινδρόμησης που παρουσιάζεται στο Σχήμα 8.

Σχήμα 8 Το αποτέλεσμα της εφαρμογής του εργαλείου παλινδρόμησης "Ισορροπία εξόδου"
Δημιουργήστε έναν νέο πίνακα όπως φαίνεται στην Εικόνα 9. Στη στήλη C, υπολογίζουμε το σχετικό σφάλμα προσέγγισης από τον τύπο:
![]()

Σχήμα 9 Υπολογισμός του μέσου σφάλματος προσέγγισης
Το μέσο σφάλμα προσέγγισης υπολογίζεται από τον τύπο:

Η ποιότητα του κατασκευασμένου μοντέλου εκτιμάται ότι είναι καλή, καθώς δεν υπερβαίνει το 8 - 10%.
6. Από τον πίνακα με στατιστικά στοιχεία παλινδρόμησης (Σχήμα 4) γράφουμε την πραγματική τιμή του Fisher F-test: ![]()
Δεδομένου ότι ![]() σε επίπεδο σημασίας 5%, μπορούμε να συμπεράνουμε ότι η εξίσωση παλινδρόμησης είναι σημαντική (η σύνδεση αποδεικνύεται).
σε επίπεδο σημασίας 5%, μπορούμε να συμπεράνουμε ότι η εξίσωση παλινδρόμησης είναι σημαντική (η σύνδεση αποδεικνύεται).
8. Υπολογίζουμε τη στατιστική σημασία των παραμέτρων παλινδρόμησης χρησιμοποιώντας στατιστικές t Student και υπολογίζοντας το διάστημα εμπιστοσύνης για κάθε έναν από τους δείκτες.
Υποβάλαμε την υπόθεση H 0 σχετικά με μια στατιστικά ασήμαντη διαφορά στους δείκτες από το μηδέν:
![]() .
.
![]() για τον αριθμό των βαθμών ελευθερίας
για τον αριθμό των βαθμών ελευθερίας
Το σχήμα 7 δείχνει τις πραγματικές τιμές των στατιστικών στοιχείων t:
Η t-δοκιμή για τον συντελεστή συσχέτισης μπορεί να υπολογιστεί με δύο τρόπους:
Εγώ τρόπος:
όπου  - τυχαίο σφάλμα του συντελεστή συσχέτισης.
- τυχαίο σφάλμα του συντελεστή συσχέτισης.
Λαμβάνουμε τα δεδομένα για τον υπολογισμό από τον πίνακα στο σχήμα 7.

ΙΙ μέθοδος:
Οι πραγματικές στατιστικές τιμές t υπερβαίνουν τις τιμές πίνακα:
Επομένως, η υπόθεση Η 0 απορρίπτεται, δηλαδή οι παράμετροι παλινδρόμησης και ο συντελεστής συσχέτισης δεν διαφέρουν τυχαία από το μηδέν, αλλά είναι στατιστικά σημαντικοί.
Το διάστημα εμπιστοσύνης για την παράμετρο a ορίζεται ως
![]()
Για την παράμετρο a, τα όρια 95% όπως φαίνεται στο σχήμα 7 ήταν:
Το διάστημα εμπιστοσύνης για τον συντελεστή παλινδρόμησης ορίζεται ως
![]()
Για τον συντελεστή παλινδρόμησης b, 95% όρια όπως φαίνεται στο Σχήμα 7 ήταν:
![]()
Μια ανάλυση των ανώτερων και κατώτερων ορίων των διαστημάτων εμπιστοσύνης οδηγεί στο συμπέρασμα ότι με την πιθανότητα ![]() οι παράμετροι α και β, που βρίσκονται εντός των υποδεικνυόμενων ορίων, δεν λαμβάνουν μηδενικές τιμές, δηλ. δεν είναι στατιστικά ασήμαντα και σημαντικά διαφορετικά από το μηδέν.
οι παράμετροι α και β, που βρίσκονται εντός των υποδεικνυόμενων ορίων, δεν λαμβάνουν μηδενικές τιμές, δηλ. δεν είναι στατιστικά ασήμαντα και σημαντικά διαφορετικά από το μηδέν.
7. Οι ληφθείσες εκτιμήσεις της εξίσωσης παλινδρόμησης καθιστούν δυνατή τη χρήση της για την πρόβλεψη. Εάν το προβλεπόμενο κόστος ζωής είναι:
Στη συνέχεια, η προβλεπόμενη αξία του κόστους ζωής θα είναι:
Το σφάλμα πρόβλεψης υπολογίζεται από τον τύπο:

όπου ![]()
Υπολογίζουμε επίσης τη διακύμανση χρησιμοποιώντας το Excel IFR. Για να γίνει αυτό:
1) Ενεργοποίηση Οδηγός λειτουργιών: στο κύριο μενού, επιλέξτε Λειτουργία τύπων / εισόδου.
3) Συμπληρώστε το εύρος που περιέχει τα αριθμητικά δεδομένα του χαρακτηριστικού συντελεστή. Πατήστε Εντάξει.

Σχήμα 10 Υπολογισμός της διακύμανσης
Έχεις την τιμή διακύμανσης ![]()
Για να υπολογίσουμε την υπολειμματική διακύμανση κατά ένα βαθμό ελευθερίας, χρησιμοποιούμε τα αποτελέσματα της ανάλυσης της διακύμανσης όπως φαίνεται στο Σχήμα 7.

Τα διαστήματα εμπιστοσύνης για την πρόβλεψη μεμονωμένων τιμών του y με πιθανότητα 0,95 καθορίζονται από την έκφραση:
![]()
Το διάστημα είναι αρκετά μεγάλο, κυρίως λόγω του μικρού όγκου παρατηρήσεων. Σε γενικές γραμμές, η εκπληκτική πρόβλεψη του μέσου μηνιαίου μισθού αποδείχθηκε αξιόπιστη.
Η κατάσταση του προβλήματος λαμβάνεται από: Εργαστήριο Οικονομετρίας: Εγχειρίδιο. επίδομα / Ι.Ι. Eliseeva, S.V. Kurysheva, Ν.Μ. Gordeenko et αϊ.; Ed. Ι.Ι. Eliseeva. - M .: Χρηματοοικονομική και Στατιστική, 2003. - 192 π.μ .: Ill.
Η ανάλυση παλινδρόμησης και συσχέτισης είναι μέθοδοι στατιστικής έρευνας. Αυτοί είναι οι πιο συνηθισμένοι τρόποι για να δείξει την εξάρτηση μιας παραμέτρου από μία ή περισσότερες ανεξάρτητες μεταβλητές.
Παρακάτω, με συγκεκριμένα πρακτικά παραδείγματα, θεωρούμε αυτές τις δύο πολύ δημοφιλείς αναλύσεις μεταξύ των οικονομολόγων. Και δώστε επίσης ένα παράδειγμα απόκτησης αποτελεσμάτων όταν τα συνδυάζετε.
Ανάλυση παλινδρόμησης στο Excel
Δείχνει την επίδραση ορισμένων τιμών (ανεξάρτητων, ανεξάρτητων) στην εξαρτημένη μεταβλητή. Για παράδειγμα, πώς ο αριθμός του οικονομικά ενεργού πληθυσμού εξαρτάται από τον αριθμό των επιχειρήσεων, το μέγεθος των μισθών και άλλες παραμέτρους. Ή: πώς επηρεάζουν το επίπεδο του ΑΕΠ οι ξένες επενδύσεις, οι τιμές ενέργειας κ.λπ.
Το αποτέλεσμα της ανάλυσης σας επιτρέπει να δώσετε προτεραιότητα. Και με βάση τους κύριους παράγοντες, να προβλέψει, να προγραμματίσει την ανάπτυξη των τομέων προτεραιότητας, να λάβει τις αποφάσεις της διαχείρισης.
Η παλινδρόμηση συμβαίνει:
- γραμμική (γ \u003d α + bx);
- παραβολική (γ \u003d α + bx + cx2);
- εκθετική (y \u003d a * exp (bx));
- νόμος εξουσίας (γ \u003d α * χ ^ β);
- υπερβολικό (γ \u003d β / χ + α);
- λογαριθμική (γ \u003d β * 1η (χ) + α).
- εκθετική (γ \u003d α * β ^ x).
Ας δούμε ένα παράδειγμα οικοδόμησης ενός μοντέλου παλινδρόμησης στο Excel και ερμηνείας των αποτελεσμάτων. Πάρτε τον γραμμικό τύπο παλινδρόμησης.
Πρόκληση. Σε 6 επιχειρήσεις αναλύθηκε ο μέσος μηνιαίος μισθός και ο αριθμός των παραιτηθέντων εργαζομένων. Είναι απαραίτητο να προσδιοριστεί η εξάρτηση του αριθμού των υπαλλήλων που εγκαταλείπουν το μέσο μισθό.
Το μοντέλο γραμμικής παλινδρόμησης έχει ως εξής:
Υ \u003d α 0 + α 1 χ 1 + ... + a k χ k.
Όπου a είναι οι συντελεστές παλινδρόμησης, οι x είναι οι μεταβλητές επηρεασμού και k είναι ο αριθμός των παραγόντων.
Στο παράδειγμά μας, το Y είναι ο δείκτης των συνταξιούχων εργαζομένων. Ο συντελεστής επηρεάζει τους μισθούς (x).
Το Excel διαθέτει ενσωματωμένες λειτουργίες που μπορούν να χρησιμοποιηθούν για τον υπολογισμό των παραμέτρων ενός μοντέλου γραμμικής παλινδρόμησης. Αλλά πιο γρήγορα αυτό θα κάνει το πρόσθετο "πακέτο ανάλυσης".
Ενεργοποιούμε ένα ισχυρό αναλυτικό εργαλείο:


Μετά την ενεργοποίηση, το πρόσθετο θα είναι διαθέσιμο στην καρτέλα "Δεδομένα".

Τώρα θα ασχοληθούμε άμεσα με την ανάλυση παλινδρόμησης.


Πρώτα απ 'όλα, δώστε προσοχή στο R-τετράγωνο και τους συντελεστές.
Το R-τετράγωνο είναι ο συντελεστής προσδιορισμού. Στο παράδειγμα μας, 0.755, ή 75.5%. Αυτό σημαίνει ότι οι υπολογιζόμενες παραμέτρους μοντέλου κατά 75,5% εξηγούν τη σχέση μεταξύ των μελετών παραμέτρων. Όσο υψηλότερος είναι ο συντελεστής προσδιορισμού, τόσο καλύτερα είναι το μοντέλο. Καλό - πάνω από 0.8. Κακό - λιγότερο από 0,5 (μια τέτοια ανάλυση δύσκολα μπορεί να θεωρηθεί λογική). Στο παράδειγμά μας, "δεν είναι κακό".
Ο συντελεστής 64.1428 δείχνει τι θα είναι το Υ εάν όλες οι μεταβλητές στο υπό εξέταση μοντέλο είναι ίσες με 0. Δηλαδή, άλλοι παράγοντες που δεν περιγράφονται στο μοντέλο επηρεάζουν επίσης την τιμή της παραμέτρου που αναλύεται.
Ο συντελεστής -0,16285 δείχνει το βάρος της μεταβλητής Χ με το Υ. Δηλαδή, ο μέσος μηνιαίος μισθός στο μοντέλο αυτό επηρεάζει τον αριθμό εκείνων που αφήνουν με βάρος -0,16285 (αυτός είναι ένας μικρός βαθμός επιρροής). Το σύμβολο "-" υποδεικνύει αρνητικό αντίκτυπο: όσο υψηλότερος είναι ο μισθός, τόσο λιγότεροι είναι εκείνοι που εγκατέλειψαν. Ποιο είναι δίκαιο.
Ανάλυση αλληλεπίδρασης Excel
Η ανάλυση συσχέτισης βοηθά να διαπιστωθεί εάν υπάρχει σχέση μεταξύ των δεικτών σε ένα ή δύο δείγματα. Για παράδειγμα, μεταξύ του χρόνου λειτουργίας του μηχανήματος και του κόστους επισκευής, η τιμή του εξοπλισμού και η διάρκεια λειτουργίας, το ύψος και το βάρος των παιδιών κ.λπ.
Εάν υπάρχει σύνδεση, η αύξηση μιας παραμέτρου συνεπάγεται αύξηση (θετική συσχέτιση) ή μείωση (αρνητική) του άλλου. Η ανάλυση της συσχέτισης βοηθά τον αναλυτή να προσδιορίσει αν η πιθανή τιμή ενός άλλου μπορεί να προβλεφθεί από την τιμή ενός δείκτη.
Ο συντελεστής συσχέτισης δηλώνεται με r. Διαφέρει από +1 έως -1. Η ταξινόμηση των σχέσεων συσχέτισης για διαφορετικές περιοχές θα είναι διαφορετική. Όταν η τιμή του συντελεστή είναι 0, δεν υπάρχει γραμμική σχέση μεταξύ των δειγμάτων.
Ας εξετάσουμε πώς να χρησιμοποιήσετε τα εργαλεία του Excel για να βρείτε τον συντελεστή συσχέτισης.
Για να βρείτε συντελεστές ζευγών, χρησιμοποιείται η λειτουργία CORREL.
Στόχος: Προσδιορίστε εάν υπάρχει σχέση μεταξύ του χρόνου λειτουργίας του τόρνου και του κόστους συντήρησης του.

Τοποθετούμε τον κέρσορα σε οποιοδήποτε στοιχείο και πατάμε το πλήκτρο fx.
- Στην κατηγορία "Στατιστικά", επιλέξτε τη λειτουργία CORREL.
- Argument "Array 1" - το πρώτο εύρος τιμών είναι ο χρόνος λειτουργίας του μηχανήματος: A2: A14.
- Το όρισμα Array 2 είναι το δεύτερο εύρος τιμών - κόστος επισκευής: B2: B14. Κάντε κλικ στο κουμπί OK.

Για να προσδιορίσετε τον τύπο της σύνδεσης, πρέπει να εξετάσετε τον απόλυτο αριθμό του συντελεστή (για κάθε τομέα δραστηριότητας υπάρχει κλίμακα).
Για την ανάλυση συσχέτισης διαφόρων παραμέτρων (περισσότερο από 2) είναι πιο βολικό να χρησιμοποιείτε την "Ανάλυση Δεδομένων" (add-in "Package Analysis"). Στη λίστα πρέπει να επιλέξετε τη συσχέτιση και να ορίσετε τον πίνακα. Αυτό είναι όλο.
Οι προκύπτοντες συντελεστές εμφανίζονται στον πίνακα συσχετισμού. Έτσι:

Ανάλυση Αντίστροφης Συσχέτισης
Στην πράξη, αυτές οι δύο τεχνικές εφαρμόζονται συχνά μαζί.
Ένα παράδειγμα:



Τώρα, τα δεδομένα της ανάλυσης παλινδρόμησης είναι επίσης ορατά.
Η ανάλυση παλινδρόμησης στο Microsoft Excel είναι ο πιο ολοκληρωμένος οδηγός για τη χρήση του MS Excel για την επίλυση των προβλημάτων της ανάλυσης παλινδρόμησης στον τομέα της επιχειρησιακής ανάλυσης. Ο Konrad Karlberg εξηγεί εύκολα τις θεωρητικές ερωτήσεις, η γνώση των οποίων θα σας βοηθήσει να αποφύγετε πολλά λάθη τόσο κατά τη διενέργεια ανάλυσης παλινδρόμησης όσο και κατά την αξιολόγηση των αποτελεσμάτων της ανάλυσης που εκτελούν άλλοι. Το σύνολο του υλικού, από απλές συσχετίσεις και δοκιμές t σε πολλαπλή ανάλυση συνδιακύμανσης, βασίζεται σε πραγματικά παραδείγματα και συνοδεύεται από λεπτομερή περιγραφή των αντίστοιχων διαδικασιών βήμα προς βήμα.
Το βιβλίο εξετάζει τα χαρακτηριστικά και τις αντιφάσεις που σχετίζονται με τις λειτουργίες του Excel για την εργασία με την παλινδρόμηση, συζητά τις συνέπειες από τη χρήση καθεμιάς από τις επιλογές και κάθε επιχείρησή του και εξηγεί πώς να εφαρμόζει αξιόπιστα τις μεθόδους παλινδρόμησης σε διάφορους τομείς, από την ιατρική έρευνα μέχρι την οικονομική ανάλυση.
Conrad Karlberg. Ανάλυση παλινδρόμησης στο Microsoft Excel. - Μ.: Διαλεκτική, 2017. - 400 σ.
Λήψη σημείωσης σε μορφή ή, παραδείγματα σε μορφή
Κεφάλαιο 1. Αξιολόγηση της μεταβλητότητας των δεδομένων
Στη διάθεση των στατιστικολόγων υπάρχουν πολλοί δείκτες μεταβλητότητας (μεταβλητότητα). Ένα από αυτά είναι το άθροισμα των τετραγωνικών αποκλίσεων των μεμονωμένων τιμών από τον μέσο όρο. Στο Excel, χρησιμοποιείται η λειτουργία QUADROTKL (). Αλλά η διασπορά χρησιμοποιείται πιο συχνά. Η διασπορά είναι ο μέσος όρος των τετραγωνικών αποκλίσεων. Η διακύμανση δεν είναι ευαίσθητη στον αριθμό των τιμών στο σύνολο δεδομένων υπό μελέτη (ενώ το άθροισμα των τετραγωνικών αποκλίσεων αυξάνεται με τον αριθμό των μετρήσεων).
Το Excel προσφέρει δύο λειτουργίες που επιστρέφουν διακύμανση: DISP.G () και DISP.V ():
- Χρησιμοποιήστε τη λειτουργία DISP.G () εάν οι τιμές που πρέπει να επεξεργαστούν αποτελούν τον πληθυσμό. Δηλαδή, οι τιμές που περιλαμβάνονται στο εύρος είναι οι μοναδικές τιμές που σας ενδιαφέρουν.
- Χρησιμοποιήστε τη λειτουργία DISP.B () εάν οι τιμές που πρέπει να επεξεργαστούν αποτελούν δείγμα από μια μεγαλύτερη συλλογή. Υποτίθεται ότι υπάρχουν πρόσθετες τιμές, η διακύμανση των οποίων μπορεί επίσης να αξιολογηθεί.
Εάν μια ποσότητα όπως ο μέσος όρος ή ο συντελεστής συσχέτισης υπολογίζεται με βάση τον πληθυσμό, τότε ονομάζεται παράμετρος. Μια παρόμοια τιμή που υπολογίζεται με βάση το δείγμα ονομάζεται στατιστική. Μετρώντας τις αποκλίσεις από τον μέσο όρο σε αυτό το σετ, θα λάβετε το άθροισμα των τετραγωνικών αποκλίσεων μικρότερης αξίας από ό, τι αν τους υπολογίζατε από οποιαδήποτε άλλη αξία. Μια παρόμοια δήλωση ισχύει και για τη διασπορά.
Όσο μεγαλύτερο είναι το μέγεθος του δείγματος, τόσο ακριβέστερη είναι η υπολογισθείσα στατιστική τιμή. Αλλά δεν υπάρχει ένα μόνο δείγμα με όγκο μικρότερο από το μέγεθος του γενικού πληθυσμού, σε σχέση με το οποίο θα μπορούσατε να είστε σίγουροι ότι η αξία των στατιστικών συμπίπτει με την αξία της παραμέτρου.
Υποθέστε ότι έχετε ένα σύνολο 100 τιμών ανάπτυξης, ο μέσος όρος των οποίων διαφέρει από το μέσο όρο του γενικού πληθυσμού, ανεξάρτητα από το πόσο μικρή είναι αυτή η διαφορά. Έχοντας υπολογίσει τη διακύμανση για το δείγμα, θα πάρετε κάποια αξία από αυτό, δηλαδή 4. Αυτή η τιμή είναι μικρότερη από οποιαδήποτε άλλη που μπορεί να ληφθεί υπολογίζοντας την απόκλιση καθεμιάς από τις 100 τιμές ανάπτυξης σε σχέση με οποιαδήποτε άλλη τιμή εκτός από τον μέσο όρο για το δείγμα, του γενικού πληθυσμού. Επομένως, η υπολογιζόμενη διακύμανση θα διαφέρει και, σε μικρότερο βαθμό, από τη διακύμανση που θα αποκτούσατε εάν κατά κάποιον τρόπο ήξερα και δεν χρησιμοποιήσατε ένα μέσο δείγματος, αλλά την παράμετρο του πληθυσμού.
Το μέσο άθροισμα των τετραγώνων που προσδιορίστηκαν για το δείγμα δίνει μια χαμηλότερη εκτίμηση της διακύμανσης του πληθυσμού. Υπολογίζεται η διακύμανση που υπολογίζεται με αυτόν τον τρόπο μεροληπτική αξιολόγηση. Αποδεικνύεται ότι για να εξαλειφθεί η προκατάληψη και να ληφθεί μια αμερόληπτη εκτίμηση, αρκεί να διαιρέσουμε το άθροισμα των τετραγωνικών αποκλίσεων όχι από nόπου n είναι το μέγεθος του δείγματος και το n - 1.
Τιμή n - 1ονομάζεται ο αριθμός (αριθμός) των βαθμών ελευθερίας. Υπάρχουν διάφοροι τρόποι υπολογισμού αυτής της τιμής, αν και όλες περιλαμβάνουν είτε την αφαίρεση ενός ορισμένου αριθμού από το μέγεθος του δείγματος είτε την καταμέτρηση του αριθμού των κατηγοριών στις οποίες εμπίπτουν οι παρατηρήσεις.
Η ουσία της διαφοράς μεταξύ των λειτουργιών DISP.G () και DISP.V () έχει ως εξής:
- Στη συνάρτηση DISP.G (), το άθροισμα των τετραγώνων διαιρείται με τον αριθμό των παρατηρήσεων και, ως εκ τούτου, αντιπροσωπεύει μια προκατειλημμένη εκτίμηση της διακύμανσης, του πραγματικού μέσου όρου.
- Στη συνάρτηση DISP.V (), το άθροισμα των τετραγώνων διαιρείται με τον αριθμό των παρατηρήσεων μείον 1, δηλ. με τον αριθμό των βαθμών ελευθερίας, που δίνει μια ακριβέστερη, αμερόληπτη εκτίμηση της διακύμανσης του πληθυσμού από τον οποίο εξήχθη αυτό το δείγμα.
Τυπική απόκλιση τυπική απόκλιση, SD) - είναι η τετραγωνική ρίζα της διακύμανσης:
Η μετατόπιση των αποκλίσεων σε ένα τετράγωνο μετατρέπει την κλίμακα μέτρησης σε μια άλλη μέτρηση, η οποία είναι το τετράγωνο του αρχικού: μέτρα έως τετραγωνικά μέτρα, δολάρια σε τετραγωνικά δολάρια, κ.λπ. Η τυπική απόκλιση είναι η τετραγωνική ρίζα της διακύμανσης και επομένως μας επιστρέφει στις αρχικές μονάδες μέτρησης. Πιο βολικό.
Συχνά θα πρέπει να υπολογίσετε την τυπική απόκλιση αφού τα δεδομένα έχουν υποβληθεί σε κάποια χειραγώγηση. Και παρόλο που σε αυτές τις περιπτώσεις τα αποτελέσματα είναι αναμφίβολα τυπικές αποκλίσεις, καλούνται συνήθως τυπικά σφάλματα. Υπάρχουν διάφορες ποικιλίες τυποποιημένων σφαλμάτων, όπως τυπικό σφάλμα μέτρησης, τυπικό σφάλμα αναλογίας, τυπικό σφάλμα του μέσου όρου.
Ας υποθέσουμε ότι έχετε συλλέξει στοιχεία ανάπτυξης για 25 τυχαία επιλεγμένα αρσενικά ενήλικα σε κάθε μία από τις 50 πολιτείες. Στη συνέχεια, υπολογίζετε το μέσο ύψος των ενηλίκων ανδρών σε κάθε κράτος. Οι ληφθείσες 50 μέσες τιμές, με τη σειρά τους, μπορούν να θεωρηθούν ως παρατηρήσεις. Βάσει αυτού, θα μπορούσατε να υπολογίσετε την τυπική απόκλιση, η οποία είναι τυπικό σφάλμα του μέσου όρου. Το Σχ. 1. σας επιτρέπει να συγκρίνετε τη διανομή 1250 αρχικών ατομικών τιμών (στοιχεία για την ανάπτυξη 25 ανδρών σε κάθε μία από τις 50 πολιτείες) με τη διανομή των μέσων τιμών των 50 κρατών. Ο τύπος για την εκτίμηση του τυπικού σφάλματος του μέσου όρου (δηλαδή της τυπικής απόκλισης των μέσων τιμών, όχι των μεμονωμένων παρατηρήσεων):
![]()
όπου είναι το τυπικό σφάλμα του μέσου όρου. s - τυπική απόκλιση των αρχικών παρατηρήσεων. n - τον αριθμό των παρατηρήσεων στο δείγμα.

Το Σχ. 1. Η μεταβολή των μέσων όρων απόστασης σε κράτος είναι σημαντικά μικρότερη από την μεταβολή των επιμέρους αποτελεσμάτων παρατήρησης.
Στα στατιστικά στοιχεία, υπάρχει συμφωνία σχετικά με τη χρήση ελληνικών και λατινικών γράμματα για να αναφερθούν στατιστικές ποσότητες. Με ελληνικά γράμματα συνηθίζεται να υποδηλώνονται οι παράμετροι του γενικού πληθυσμού, στα Λατινικά - επιλεκτικά στατιστικά στοιχεία. Επομένως, όταν πρόκειται για την τυπική απόκλιση του πληθυσμού, γράφουμε ως σ; αν λάβουμε υπόψη την τυπική απόκλιση του δείγματος, τότε χρησιμοποιούμε τις σημειώσεις. Όσον αφορά τα σύμβολα για τον καθορισμό των μέσων όρων, δεν είναι τόσο καλά συντονισμένα. Ο μέσος πληθυσμός δηλώνεται από το ελληνικό γράμμα μ. Εντούτοις, το σύμβολο Χίβ χρησιμοποιείται παραδοσιακά για να αντιπροσωπεύει τον μέσο δείγμα.
z-σκορ εκφράζει τη θέση της παρατήρησης στην κατανομή σε μονάδες τυπικής απόκλισης. Για παράδειγμα, το z \u003d 1,5 σημαίνει ότι η παρατήρηση είναι 1,5 τυπικές αποκλίσεις μακριά από τις μέσες έως τις μεγάλες τιμές. Διάρκεια z-σκορ χρησιμοποιείται για μεμονωμένες αξιολογήσεις, δηλ. για μετρήσεις που αποδίδονται σε μεμονωμένα στοιχεία δείγματος. Για τέτοιες στατιστικές (π.χ. κρατικός μέσος όρος), ο όρος z αξία:

όπου Χιι είναι η μέση τιμή του δείγματος, μ είναι η μέση τιμή του πληθυσμού, είναι το τυπικό σφάλμα του μέσου όρου του συνόλου των δειγμάτων:
![]()
όπου σ είναι το τυπικό σφάλμα του πληθυσμού (μεμονωμένες μετρήσεις), n - μέγεθος δείγματος.
Ας υποθέσουμε ότι είστε εκπαιδευτής σε μια λέσχη γκολφ. Έχετε καταφέρει να μετρήσετε το εύρος των επιπτώσεων για μεγάλο χρονικό διάστημα και γνωρίζετε ότι η μέση τιμή του είναι 205 μέτρα και η τυπική απόκλιση είναι 36 μέτρα. Σας προσφέρθηκε μια νέα λέσχη, ισχυριζόμενος ότι θα αυξήσει την απόσταση σας κατά 10 μέτρα. Ζητάτε από τους επόμενους 81 επισκέπτες του συλλόγου να πραγματοποιήσουν ένα δοκιμαστικό χτύπημα με ένα νέο σύλλογο και να καταγράψουν το εύρος του. Αποδείχθηκε ότι το μέσο εύρος του χτυπώντας ένα νέο σύλλογο είναι 215 μέτρα. Ποια είναι η πιθανότητα η διαφορά των 10 ναυπηγείων (215 - 205) να οφείλεται αποκλειστικά σε σφάλματα δειγματοληψίας; Ή με άλλο τρόπο: ποια είναι η πιθανότητα, σε μεγαλύτερη κλίμακα, μια νέα λέσχη να μην παρουσιάσει αύξηση της εμβέλειας σε σύγκριση με τον υφιστάμενο μακροπρόθεσμο μέσο όρο των 205 ναυπηγείων;
Μπορούμε να επαληθεύσουμε αυτό δημιουργώντας μια τιμή z. Τυπικό σφάλμα του μέσου όρου:
![]()
Στη συνέχεια, η τιμή z:

Πρέπει να βρούμε την πιθανότητα ότι ο μέσος όρος στο δείγμα θα είναι 2,5 σ από τον μέσο όρο του γενικού πληθυσμού. Εάν η πιθανότητα είναι μικρή, τότε οι διαφορές οφείλονται όχι τυχαία, αλλά από την ποιότητα του νέου συλλόγου. Στο Excel, δεν υπάρχει έτοιμη λειτουργία για να προσδιοριστεί η πιθανότητα μιας τιμής z. Ωστόσο, μπορείτε να χρησιμοποιήσετε τον τύπο \u003d 1-NORM.ST.RASP (τιμή z, TRUE), όπου η συνάρτηση NORM.ST.RASP () επιστρέφει την περιοχή κάτω από την κανονική καμπύλη στα αριστερά της τιμής z (Εικ. 2).

Το Σχ. 2. Η συνάρτηση NORM.ST. RASP () επιστρέφει την περιοχή κάτω από την καμπύλη στα αριστερά της τιμής z. για μεγέθυνση της εικόνας, κάντε δεξί κλικ πάνω της και επιλέξτε Ανοίξτε την εικόνα σε νέα καρτέλα
Το δεύτερο επιχείρημα της συνάρτησης NORM.ST.RASP () μπορεί να λάβει δύο τιμές: TRUE - η συνάρτηση επιστρέφει την περιοχή κάτω από την καμπύλη στα αριστερά του σημείου που καθορίζεται από το πρώτο όρισμα. FALSE - η συνάρτηση επιστρέφει το ύψος της καμπύλης στο σημείο που καθορίζεται από το πρώτο όρισμα.
Εάν η μέση τιμή (μ) και η τυπική απόκλιση (σ) του πληθυσμού δεν είναι γνωστές, χρησιμοποιείται η τιμή t (βλέπε λεπτομέρειες). Οι δομές των τιμών z και t διαφέρουν ως προς το ότι η τυπική απόκλιση s που λαμβάνεται από τα αποτελέσματα του δείγματος χρησιμοποιείται για να βρεθεί η τιμή t και όχι η γνωστή τιμή της παραμέτρου του γενικού πληθυσμού σ. Η κανονική καμπύλη έχει ένα ενιαίο σχήμα και η μορφή διανομής των τιμών t ποικίλλει ανάλογα με τον αριθμό των βαθμών ελευθερίας df (από την Eng. βαθμούς ελευθερίας) του δείγματος που αντιπροσωπεύει. Ο αριθμός βαθμών ελευθερίας δειγματοληψίας ισούται με n - 1όπου n - μέγεθος δείγματος (σχήμα 3).

Το Σχ. 3. Η μορφή των t-κατανομών που προκύπτουν σε εκείνες τις περιπτώσεις, όταν η παράμετρος σ είναι άγνωστη, διαφέρει από τη μορφή της κανονικής κατανομής
Το Excel έχει δύο λειτουργίες για τη διανομή t, που ονομάζεται επίσης διανομή μαθητών: Το STUDENT.RACP () επιστρέφει την περιοχή κάτω από την καμπύλη στα αριστερά της καθορισμένης τιμής t, και στο STUDENT.RACP.PX () - στα δεξιά.
Κεφάλαιο 2. Συσχέτιση
Η συσχέτιση είναι ένα μέτρο της σχέσης μεταξύ των στοιχείων σε ένα σύνολο ταξινομημένων ζευγών. Η συσχέτιση χαρακτηρίζεται Συντελεστές συσχέτισης Pearson- r. Ο συντελεστής μπορεί να λάβει τιμές στην περιοχή από -1,0 έως +1,0.

όπου S x και S y - τυπικές αποκλίσεις μεταβλητών Χ και Υ, S xy - συνδιακύμανση:

Σε αυτόν τον τύπο, η συνδιακύμανση χωρίζεται σε τυπικές αποκλίσεις μεταβλητών Χ και Υ, αφαιρώντας έτσι τα αποτελέσματα κλιμάκωσης που σχετίζονται με τις μονάδες από τη συνδιακύμανση. Το Excel χρησιμοποιεί τη συνάρτηση CORREL (). Στο όνομα αυτής της συνάρτησης, δεν υπάρχουν καθιερωμένα στοιχεία Γ και Β, τα οποία χρησιμοποιούνται στα ονόματα των λειτουργιών STANDOTLON (), DISP (), ή COVARIATION ()). Αν και ο συντελεστής συσχέτισης για το δείγμα παρέχει μια προκατειλημμένη εκτίμηση, ο λόγος της απόκλισης είναι διαφορετικός από ό, τι στην περίπτωση διακύμανσης ή τυπικής απόκλισης.
Ανάλογα με το μέγεθος του γενικού συντελεστή συσχέτισης (που συχνά υποδηλώνεται από την ελληνική επιστολή ρ ), ο συντελεστής συσχέτισης r δίνει μια προκατειλημμένη εκτίμηση και το φαινόμενο μεροληψίας αυξάνεται με το μειούμενο μέγεθος δείγματος. Παρόλα αυτά, δεν προσπαθούμε να διορθώσουμε αυτή την προκατάληψη με τον ίδιο τρόπο όπως, για παράδειγμα, το κάναμε αυτό κατά τον υπολογισμό της τυπικής απόκλισης, όταν αντικαταστήσαμε στον αντίστοιχο τύπο όχι τον αριθμό των παρατηρήσεων αλλά τον αριθμό των βαθμών ελευθερίας. Στην πραγματικότητα, ο αριθμός των παρατηρήσεων που χρησιμοποιούνται για τον υπολογισμό της συνδιακύμανσης δεν έχει καμία επίδραση στο μέγεθος.
Ο τυπικός συντελεστής συσχέτισης προορίζεται για χρήση με μεταβλητές που συνδέονται με γραμμική σχέση. Η παρουσία μη γραμμικότητας ή / και σφάλματα στα δεδομένα (ακραίες τιμές) οδηγεί σε εσφαλμένο υπολογισμό του συντελεστή συσχέτισης. Για τη διάγνωση προβλημάτων δεδομένων, συνιστάται η δημιουργία διαγραμμάτων διάσπασης. Αυτός είναι ο μόνος τύπος γραφήματος στο Excel στον οποίο τόσο οι οριζόντιοι όσο και οι κατακόρυφοι άξονες αντιμετωπίζονται ως άξονες αξιών. Ο γραμμικός χάρτης, μία από τις στήλες, καθορίζει τον τρόπο που ο άξονας κατηγορίας, που παραμορφώνει την εικόνα δεδομένων (Εικ. 4).

Το Σχ. 4. Οι γραμμές παλινδρόμησης φαίνονται οι ίδιες, αλλά συγκρίνουν τις εξισώσεις τους
Οι παρατηρήσεις που χρησιμοποιούνται για την κατασκευή του γραμμικού διαγράμματος βρίσκονται ισαπέχουσες κατά μήκος του οριζόντιου άξονα. Οι επιγραφές των διαιρέσεων κατά μήκος αυτού του άξονα είναι απλώς επιγραφές και όχι αριθμητικές τιμές.
Αν και η συσχέτιση συχνά σημαίνει αιτιώδη συνάφεια, δεν μπορεί να χρησιμεύσει ως απόδειξη ότι είναι. Οι στατιστικές δεν χρησιμοποιούνται για να αποδείξουν εάν μια θεωρία είναι αληθινή ή ψευδής. Για να αποκλειστούν οι ανταγωνιστικές εξηγήσεις των αποτελεσμάτων παρατήρησης, προγραμματισμένα πειράματα. Οι στατιστικές χρησιμοποιούνται για τη σύνοψη των πληροφοριών που συλλέγονται κατά τη διάρκεια τέτοιων πειραμάτων και για την ποσοτικοποίηση της πιθανότητας ότι η ληφθείσα απόφαση μπορεί να είναι εσφαλμένη, λαμβάνοντας υπόψη τη βάση στοιχείων.
Κεφάλαιο 3. Απλή παλινδρόμηση
Εάν δύο μεταβλητές αλληλοσυνδέονται, έτσι ώστε η τιμή του συντελεστή συσχέτισης υπερβαίνει, για παράδειγμα, το 0,5, τότε στην περίπτωση αυτή είναι δυνατόν να προβλεφθεί (με κάποια ακρίβεια) η άγνωστη τιμή μίας μεταβλητής από τη γνωστή τιμή του άλλου. Για να ληφθούν οι προβλεπόμενες τιμές τιμών, βάσει των δεδομένων που φαίνονται στο Σχ. 5, μπορείτε να χρησιμοποιήσετε οποιαδήποτε από τις διάφορες μεθόδους, αλλά σίγουρα δεν θα χρησιμοποιήσετε αυτό που φαίνεται στο σχ. 5. Ωστόσο, θα πρέπει να εξοικειωθείτε με αυτό, καθώς καμία άλλη μέθοδος δεν σας επιτρέπει να επιδείξετε σαφώς τη σχέση μεταξύ συσχετισμού και πρόβλεψης, όπως αυτή. Στο σχ. 5 στο εύρος B2: C12, παρουσιάζεται τυχαίο δείγμα δέκα κατοικιών και δίνονται δεδομένα σχετικά με την έκταση κάθε σπιτιού (σε τετραγωνικά πόδια) και την τιμή πώλησής του.

Το Σχ. 5. Οι προβλεπόμενες τιμές της τιμής πώλησης σχηματίζουν ευθεία γραμμή.
Βρείτε τη μέση, τυπική απόκλιση και συντελεστή συσχέτισης (περιοχή Α14: C18). Υπολογίστε τις εκτιμήσεις της z-περιοχής (E2: E12). Για παράδειγμα, το κελί Ε3 περιέχει τον τύπο: \u003d (В3- $ В $ 14) / $ В $ 15. Υπολογίστε τις z εκτιμήσεις της τιμής πρόβλεψης (F2: F12). Για παράδειγμα, το κελί F3 περιέχει τον τύπο: \u003d Ε3 * $ $ 18. Μετατρέψτε το ζ-σκορ σε τιμή σε δολάρια (H2: H12). Στο NC κύτταρο, ο τύπος είναι: \u003d F3 * $ C $ 15 + $ C $ 14.
Σημειώστε ότι η τιμή πρόβλεψης τείνει πάντοτε να μετακινείται προς το μέσο όρο του 0. Όσο πιο κοντά ο συντελεστής συσχέτισης είναι μηδέν, τόσο πιο κοντά είναι η πρόβλεψη του z-score στο μηδέν. Στο παράδειγμά μας, ο συντελεστής συσχέτισης μεταξύ της περιοχής και της τιμής πώλησης είναι 0,67 και η τιμή πρόβλεψης είναι 1,0 * 0,67, δηλ. 0,67. Αυτό αντιστοιχεί σε υπέρβαση της τιμής πάνω από τη μέση τιμή, ίση με τα δύο τρίτα της τυπικής απόκλισης. Εάν ο συντελεστής συσχέτισης ήταν 0,5, τότε η προβλεπόμενη τιμή θα ήταν 1,0 * 0,5, δηλ. 0,5. Αυτό αντιστοιχεί σε υπέρβαση της τιμής επί της μέσης τιμής, ίση με το ήμισυ της τυπικής απόκλισης. Κάθε φορά που η τιμή του συντελεστή συσχέτισης διαφέρει από την ιδανική, δηλ. μεγαλύτερη από -1,0 και μικρότερη από 1,0, η εκτίμηση της προβλεπόμενης μεταβλητής πρέπει να είναι πλησιέστερη στη μέση τιμή της από την εκτίμηση της μεταβλητής πρόβλεψης (ανεξάρτητης) ως δική της. Αυτό το φαινόμενο ονομάζεται μέση παλινδρόμηση, ή απλά παλινδρόμηση.
Το Excel έχει πολλές λειτουργίες για τον προσδιορισμό των συντελεστών της εξίσωσης μιας γραμμής παλινδρόμησης (στο Excel ονομάζεται γραμμή τάσης) y \u003dkx + β. Για να προσδιορίσετε k λειτουργεί ως λειτουργία
\u003d TILT (γνωστός_γ; γνωστός_x)
Εδώ στο Είναι η προβλεπόμενη μεταβλητή και x Είναι μια ανεξάρτητη μεταβλητή. Πρέπει να ακολουθείτε αυστηρά αυτή τη σειρά μεταβλητών. Η κλίση της γραμμής παλινδρόμησης, ο συντελεστής συσχέτισης, οι τυπικές αποκλίσεις των μεταβλητών και η συνάφεια είναι στενά συνδεδεμένες (Εικ. 6). Η συνάρτηση CUT () επιστρέφει την αποκοπή τιμής από τη γραμμή παλινδρόμησης στον κάθετο άξονα:
\u003d CUT (γνωστές_τιμές_ γνωστές_τιμές_x)

Το Σχ. 6. Η σχέση μεταξύ τυπικών αποκλίσεων μετατρέπει την συνδιακύμανση σε συντελεστή συσχέτισης και στην κλίση της γραμμής παλινδρόμησης
Λάβετε υπόψη ότι ο αριθμός των τιμών x και y που παρέχονται στα TILT () και CUT () λειτουργεί ως επιχειρήματα πρέπει να είναι ο ίδιος.
Στην ανάλυση παλινδρόμησης χρησιμοποιείται ένας άλλος σημαντικός δείκτης - R 2 (R-τετράγωνο) ή ο συντελεστής προσδιορισμού. Προσδιορίζει τη συμβολή στη γενική μεταβλητότητα δεδομένων που προκύπτει από τη σχέση μεταξύ παλινδρόμησης x και στο. Στο Excel, υπάρχει μια λειτουργία KVPIRSON () για αυτό, η οποία παίρνει ακριβώς τα ίδια επιχειρήματα με τη συνάρτηση CORREL ().
Δύο μεταβλητές με μη μηδενικό συντελεστή συσχέτισης μεταξύ τους λέγεται ότι εξηγούν τη διακύμανση ή έχουν εξηγηθείσα διακύμανση. Συνήθως, η εξήγηση που εκφράζεται εκφράζεται ως ποσοστό. Έτσι R 2 \u003d 0,81 σημαίνει ότι εξηγείται το 81% της διακύμανσης (διασποράς) των δύο μεταβλητών. Το υπόλοιπο 19% οφείλεται σε τυχαίες διακυμάνσεις.
Το Excel διαθέτει τη λειτουργία TREND, η οποία απλοποιεί τους υπολογισμούς. Λειτουργία TREND ():
- λαμβάνει τις γνωστές τιμές που παρέχετε x και γνωστές τιμές στο;
- υπολογίζει την κλίση της γραμμής παλινδρόμησης και της σταθεράς (τμήμα).
- επιστρέφει τις προβλεπόμενες τιμές στοκαθορίζεται με την εφαρμογή της εξίσωσης παλινδρόμησης σε γνωστές τιμές x (εικόνα 7).
Η συνάρτηση TREND () είναι μια συνάρτηση συστοιχιών (αν δεν έχετε συναντήσει προηγουμένως τέτοιες λειτουργίες, σας το συνιστώ).

Το Σχ. 7. Χρησιμοποιώντας τη λειτουργία TREND (), μπορείτε να επιταχύνετε και να απλοποιήσετε τους υπολογισμούς σε σύγκριση με τη χρήση ενός ζεύγους λειτουργιών TILT () και CUT ()
Για να εισαγάγετε τη συνάρτηση TREND () ως τύπο συστοιχίας στα κελιά G3: G12, επιλέξτε την περιοχή G3: G12, εισάγετε τον τύπο TREND (СЗ: С12; ВЗ: В12), πατήστε και κρατήστε πατημένα τα πλήκτρα
Η συνάρτηση TREND () έχει δύο ακόμη επιχειρήματα: new_x_valuesκαι const. Το πρώτο σας επιτρέπει να δημιουργήσετε μια πρόβλεψη για το μέλλον και το δεύτερο μπορεί να κάνει την γραμμή παλινδρόμησης να περάσει από την προέλευση (η τιμή TRUE λέει στο Excel να χρησιμοποιήσει την υπολογισμένη σταθερά, την τιμή FALSE - constant \u003d 0). Το Excel σάς επιτρέπει να σχεδιάσετε μια γραμμή παλινδρόμησης σε ένα γράφημα έτσι ώστε να περάσει από την προέλευση. Ξεκινήστε δημιουργώντας ένα διάγραμμα σκέδασης και στη συνέχεια κάντε δεξί κλικ σε έναν από τους δείκτες της σειράς δεδομένων. Στο μενού περιβάλλοντος που ανοίγει, επιλέξτε Προσθέστε γραμμή τάσεων. επιλογή Γραμμική. μετακινηθείτε προς τα κάτω, εάν χρειάζεται, ελέγξτε το κουτί Ρυθμίστε την τομή. βεβαιωθείτε ότι η τιμή που σχετίζεται με αυτό είναι ρυθμισμένη στο 0,0.
Αν έχετε τρεις μεταβλητές και θέλετε να προσδιορίσετε τη συσχέτιση μεταξύ των δύο, εξαιρουμένης της επιρροής του τρίτου, μπορείτε να χρησιμοποιήσετε ιδιωτική συσχέτιση. Ας υποθέσουμε ότι ενδιαφέρεστε για τη σχέση μεταξύ του ποσοστού των κατοίκων των πόλεων που έχουν ολοκληρώσει το κολλέγιο και του αριθμού των βιβλίων στις βιβλιοθήκες πόλεων. Συλλέξατε δεδομένα για 50 πόλεις, αλλά ... Το πρόβλημα είναι ότι και οι δύο αυτές παράμετροι μπορεί να εξαρτώνται από την ευημερία των κατοίκων μιας πόλης. Φυσικά, είναι πολύ δύσκολο να παραλάβουμε τις άλλες 50 πόλεις, που χαρακτηρίζονται από το ίδιο επίπεδο ευημερίας των κατοίκων.
Χρησιμοποιώντας στατιστικές μεθόδους για να αποκλείσετε την επίδραση του παράγοντα ευημερίας τόσο στην οικονομική στήριξη των βιβλιοθηκών όσο και στη διαθεσιμότητα της σχολικής εκπαίδευσης, θα μπορούσατε να πάρετε μια ακριβέστερη ποσοτική εκτίμηση του βαθμού εξάρτησης μεταξύ των μεταβλητών ενδιαφέροντος, δηλαδή: ο αριθμός των βιβλίων και ο αριθμός των αποφοίτων. Μια τέτοια εξαρτώμενη συσχέτιση μεταξύ δύο μεταβλητών, όταν οι τιμές των άλλων μεταβλητών είναι σταθερές, ονομάζεται μερική συσχέτιση. Ένας τρόπος για να το υπολογίσετε είναι να χρησιμοποιήσετε την εξίσωση:

Πού r CB . W - ο συντελεστής συσχέτισης μεταξύ των μεταβλητών College (College) και Books (Books) με την αποκλεισμένη επιρροή (σταθερή αξία) της μεταβλητής ευημερίας (wealth). r CB - ο συντελεστής συσχέτισης μεταξύ των μεταβλητών College and Books. r Cw - συντελεστής συσχέτισης μεταξύ των μεταβλητών του κολλεγίου και του πλούτου · r Bw - ο συντελεστής συσχέτισης μεταξύ των μεταβλητών του βιβλίου και της ευημερίας.
Από την άλλη πλευρά, η μερική συσχέτιση μπορεί να υπολογιστεί βάσει ανάλυσης υπολειμμάτων, δηλ. διαφορές μεταξύ των προβλεπόμενων τιμών και των αποτελεσμάτων των πραγματικών παρατηρήσεων που σχετίζονται με αυτές (και οι δύο μέθοδοι παρουσιάζονται στο σχήμα 8).

Το Σχ. 8. Ιδιωτικός συσχετισμός ως συσχετισμός υπολειμμάτων
Για να απλοποιήσετε τον υπολογισμό του πίνακα των συντελεστών συσχέτισης (B16: E19), χρησιμοποιήστε το πακέτο ανάλυσης Excel (μενού Δεδομένα –> Ανάλυση –> Ανάλυση δεδομένων) Από προεπιλογή, το πακέτο αυτό δεν είναι ενεργό στο Excel. Για να το εγκαταστήσετε, μεταβείτε στο μενού Αρχείο –> Παράμετροι –> Πρόσθετα. Στο κάτω μέρος του παραθύρου που ανοίγει ΠαράμετροιExcel βρείτε το πεδίο Διαχείρισηεπιλέξτε ΠρόσθεταExcelκάντε κλικ στο κουμπί Πηγαίνετε στο. Επιλέξτε το πλαίσιο δίπλα στο πρόσθετο. Πακέτο ανάλυσης. Κάντε κλικ στο κουμπί A Εξόρυξη δεδομένωνεπιλογή Συσχέτιση. Ως διάστημα εισαγωγής, καθορίστε $ B $ 2: $ D $ 13, επιλέξτε το πλαίσιο Ετικέτες στην πρώτη γραμμή, καθορίστε $ B $ 16: $ E $ 19 ως το διάστημα εξόδου.
Μια άλλη πιθανότητα είναι να προσδιοριστεί η ημι-μερική συσχέτιση. Για παράδειγμα, εξετάζετε τις επιπτώσεις του ύψους και της ηλικίας στο βάρος. Έτσι, έχετε δύο μεταβλητές πρόβλεψης - ύψος και ηλικία και ένα προβλεπόμενο μεταβλητό βάρος. Θέλετε να αποκλείσετε την επίδραση μιας μεταβλητής πρόβλεψης σε μια άλλη, αλλά όχι στην πρόβλεψη της μεταβλητής:
![]()
όπου N - ύψος (ύψος), W - βάρος (βάρος), A - ηλικία (ηλικία); ο δείκτης του ημι-προσαρμοσμένου συντελεστή συσχέτισης χρησιμοποιεί παρενθέσεις για να υποδείξει την επίδραση της μεταβλητής που εξαλείφεται και από ποια μεταβλητή. Σε αυτή την περίπτωση, ο χαρακτηρισμός W (N.A.) υποδεικνύει ότι η επίδραση της μεταβλητής ηλικίας αφαιρείται από τη μεταβλητή Ύψος, αλλά όχι από τη μεταβλητή Βάρος.
Μπορεί να φαίνεται ότι το υπό συζήτηση θέμα δεν είναι σημαντικό. Εξάλλου, το πιο σημαντικό είναι το πώς ακριβώς λειτουργεί η εξίσωση γενικής παλινδρόμησης, ενώ το πρόβλημα της σχετικής συμβολής των μεμονωμένων μεταβλητών στη συνολική διακύμανση που εξηγείται είναι δευτερεύουσας σημασίας. Ωστόσο, αυτό απέχει πολύ από την περίπτωση. Μόλις αρχίσετε να σκέφτεστε αν θα χρησιμοποιήσετε ή όχι κάποιο είδος μεταβλητής στην εξίσωση πολλαπλής παλινδρόμησης, το πρόβλημα γίνεται σημαντικό. Μπορεί να επηρεάσει την αξιολόγηση της ορθότητας της επιλογής μοντέλου για ανάλυση.
Κεφάλαιο 4. Η λειτουργία LINE ()
Η συνάρτηση LINE () επιστρέφει 10 στατιστικά στοιχεία παλινδρόμησης. Η συνάρτηση LINE () είναι μια συνάρτηση πίνακα. Για να την εισάγετε, επιλέξτε μια περιοχή που περιέχει πέντε σειρές και δύο στήλες, πληκτρολογήστε τον τύπο και πατήστε
LINE (B2: Β21, Α2: Α21, ΑΛΗΘΕΙΑ, ΑΛΗΘΕΙΑ)

Το Σχ. 9. Λειτουργία LINE (): α) επιλέξτε την περιοχή D2: E6, β) εισάγετε τον τύπο όπως φαίνεται στη γραμμή τύπων, γ) πατήστε
Η λειτουργία LINE () επιστρέφει:
- συντελεστής παλινδρόμησης (ή κλίση, κυψελίδα D2).
- (ή σταθερή, κυψελίδα Ε3).
- τυπικά σφάλματα του συντελεστή παλινδρόμησης και σταθερές (εύρος D3: E3).
- συντελεστής προσδιορισμού R2 για παλινδρόμηση (κυψελίδα D4).
- τυπικό σφάλμα εκτίμησης (κελί Ε4) ·
- Δοκιμή F για πλήρη παλινδρόμηση (κελί D5).
- ο αριθμός βαθμών ελευθερίας για το υπολειπόμενο άθροισμα τετραγώνων (κελί Ε5).
- το σύνολο παλινδρόμησης των τετραγώνων (κυψελίδα D6).
- υπολειπόμενο άθροισμα τετραγώνων (κυψελίδα Ε6).
Εξετάστε κάθε μία από αυτές τις στατιστικές και τις αλληλεπιδράσεις τους.
Τυπικό σφάλμα στην περίπτωσή μας, αυτή είναι η τυπική απόκλιση που υπολογίζεται για σφάλματα δειγματοληψίας. Δηλαδή, αυτή είναι μια κατάσταση όπου ο πληθυσμός έχει μία στατιστική και το δείγμα έχει άλλο. Διαχωρίζοντας τον συντελεστή παλινδρόμησης από το τυπικό σφάλμα, παίρνετε μια τιμή 2.092 / 0.818 \u003d 2.559. Με άλλα λόγια, ένας συντελεστής παλινδρόμησης 2.092 είναι δυο και μισό τυπικά σφάλματα μακριά από το μηδέν.
Εάν ο συντελεστής παλινδρόμησης είναι μηδέν, τότε η καλύτερη εκτίμηση της προβλεπόμενης μεταβλητής είναι η μέση τιμή του. Δυόμισι πρότυπα σφάλματα είναι μια αρκετά μεγάλη τιμή και μπορείτε να υποθέσετε με ασφάλεια ότι ο συντελεστής παλινδρόμησης για τον πληθυσμό είναι μηδενικός.
Η πιθανότητα απόκτησης ενός συντελεστή παλινδρόμησης δείγματος 2.092 μπορεί να προσδιοριστεί εάν η πραγματική του τιμή στον πληθυσμό είναι 0.0 χρησιμοποιώντας τη συνάρτηση
STUDENT.RASP.PH (t-test \u003d 2,559, αριθμός βαθμών ελευθερίας \u003d 18)
Γενικά, ο αριθμός των βαθμών ελευθερίας \u003d n - k - 1, όπου n είναι ο αριθμός των παρατηρήσεων, και k είναι ο αριθμός των μεταβλητών πρόβλεψης.
Ο τύπος αυτός επιστρέφει 0,00987 ή, σε γύρους, 1%. Μας λέει τα εξής: αν ο συντελεστής παλινδρόμησης για το γενικό πληθυσμό είναι 0%, τότε η πιθανότητα απόκτησης ενός δείγματος 20 ατόμων, για τον οποίο η υπολογιζόμενη τιμή του συντελεστή παλινδρόμησης είναι 2.092, είναι μέτρια 1%.
Το κριτήριο F (το κελί D5 στο σχήμα 9) εκτελεί τις ίδιες λειτουργίες σε σχέση με την πλήρη παλινδρόμηση ως το κριτήριο t σε σχέση με τον συντελεστή απλής ζευγαρωμένης παλινδρόμησης. Το κριτήριο F χρησιμοποιείται για να ελέγξει εάν ο συντελεστής προσδιορισμού R 2 για την παλινδρόμηση είναι αρκετά μεγάλος ώστε να απορρίψει την υπόθεση ότι στον γενικό πληθυσμό έχει τιμή 0,0, πράγμα που δείχνει την απουσία διακύμανσης που εξηγείται από τον προβλεπόμενο και την προβλεπόμενη μεταβλητή. Αν υπάρχει μόνο μία μεταβλητή πρόβλεψης, το κριτήριο F είναι ακριβώς ίσο με το τετράγωνο του κριτηρίου t.
Μέχρι στιγμής, εξετάζουμε μεταβλητές διαστήματος. Αν έχετε μεταβλητές που μπορούν να πάρουν διάφορες αξίες, όπως είναι τα απλά ονόματα, π.χ. Άνδρας και Γυναίκα ή ερπετό, αμφίβια και ψάρια, φανταστείτε τους με τη μορφή αριθμητικού κώδικα. Τέτοιες μεταβλητές ονομάζονται ονομαστικές.
Στατιστικά R 2 δίνει μια ποσοτική εκτίμηση της αναλογίας εξηγηθείσας διακύμανσης.
Τυπικό σφάλμα εκτίμησης.Στο σχ. Το Σχήμα 4.9 παρουσιάζει τις προβλεπόμενες τιμές της μεταβλητής Βάρος, που λαμβάνεται με βάση τη σύνδεσή του με τη μεταβλητή Ύψος. Η περιοχή E2: E21 περιέχει τις υπόλοιπες τιμές για τη μεταβλητή Βάρος. Πιο συγκεκριμένα, αυτά τα υπολείμματα ονομάζονται σφάλματα - συνεπώς ακολουθεί ο όρος πρότυπο σφάλμα εκτίμησης.

Το Σχ. 10. Τόσο το R 2 όσο και το τυπικό σφάλμα της εκτίμησης εκφράζουν την ακρίβεια των προβλέψεων που λαμβάνονται με την παλινδρόμηση
Όσο μικρότερο είναι το τυπικό σφάλμα της εκτίμησης, τόσο πιο ακριβής είναι η εξίσωση παλινδρόμησης και όσο πιο κοντά είναι η σύμπτωση οποιασδήποτε πρόβλεψης που λαμβάνεται χρησιμοποιώντας την εξίσωση με την πραγματική παρατήρηση που περιμένετε. Ένα τυποποιημένο σφάλμα εκτίμησης παρέχει έναν τρόπο ποσοτικοποίησης αυτών των προσδοκιών. Το βάρος του 95% των ανθρώπων με κάποια ανάπτυξη θα είναι στο εύρος:
(ανάπτυξη * 2.092 - 3.591) ± 2.092 * 21.118
F στατιστικέςΕίναι η αναλογία διακύμανσης μεταξύ ομάδων προς διακύμανση εντός της ομάδας. Αυτό το όνομα εισήχθη από τον στατιστικό George Snedecor προς τιμήν του κυρίου που ανέπτυξε την ανάλυση της διακύμανσης (ANOVA) στις αρχές του 20ού αιώνα.
Ο συντελεστής προσδιορισμού R2 εκφράζει το κλάσμα των συνολικών τετραγώνων που σχετίζονται με την παλινδρόμηση. Η τιμή (1 - R2) εκφράζει το κλάσμα του συνολικού αθροίσματος των τετραγώνων που σχετίζονται με τα υπολείμματα - σφάλματα πρόβλεψης. Η δοκιμή F μπορεί να ληφθεί χρησιμοποιώντας τη συνάρτηση LINEST (κελί F5 στο σχήμα 11), χρησιμοποιώντας το άθροισμα των τετραγώνων (εύρος G10: J11), χρησιμοποιώντας τα κλάσματα διακύμανσης (περιοχή G14: J15). Οι τύποι μπορούν να βρεθούν στο συνημμένο αρχείο Excel.

Το Σχ. 11. Ο υπολογισμός του κριτηρίου F
Όταν χρησιμοποιούνται ονομαστικές μεταβλητές, χρησιμοποιείται εικονική κωδικοποίηση (Εικ. 12). Για τιμές κωδικοποίησης, είναι σκόπιμο να χρησιμοποιηθούν οι τιμές 0 και 1. Η πιθανότητα F υπολογίζεται χρησιμοποιώντας τη συνάρτηση:
F. RAS.PX (Κ2 · I2 · I3)
Εδώ, η συνάρτηση F. RAS.PX () επιστρέφει την πιθανότητα απόκτησης του κριτηρίου F υποκείμενη στην κεντρική κατανομή F (σχήμα 13) για δύο σύνολα δεδομένων με τους βαθμούς ελευθερίας που δίδονται στα κελιά Ι2 και Ι3, η τιμή της οποίας συμπίπτει με την τιμή που δίνεται στο κυττάρου Κ2.

Το Σχ. 12. Ανάλυση παλινδρόμησης χρησιμοποιώντας εικονικές μεταβλητές

Το Σχ. 13. Κεντρική κατανομή F σε λ \u003d 0
Κεφάλαιο 5. Πολλαπλή παλινδρόμηση
Μετακινώντας από μια απλή παλινδρόμηση από μια μεταβλητή πρόβλεψης σε πολλαπλή παλινδρόμηση, προσθέτετε μία ή περισσότερες μεταβλητές πρόβλεψης. Αποθηκεύστε μεταβλητές πρόβλεψης σε παρακείμενες στήλες, όπως στήλες Α και Β για δύο προγνωστικούς παράγοντες ή Α, Β και Γ για τρεις προγνωστικούς παράγοντες. Πριν εισάγετε έναν τύπο που περιλαμβάνει τη συνάρτηση LINEST (), επιλέξτε πέντε σειρές και όσες στήλες υπάρχουν με τις μεταβλητές πρόβλεψης, συν ένα ακόμα για τη σταθερά. Στην περίπτωση παλινδρόμησης με δύο μεταβλητές πρόβλεψης, μπορεί να χρησιμοποιηθεί η ακόλουθη δομή:
Γραμμή (Α2: Α41, Β2: C41, ΑΛΗΘΕΙΑ)
Ομοίως, στην περίπτωση τριών μεταβλητών:
LINEST (A2: A61, B2: D61, TRUE)
Ας υποθέσουμε ότι θέλετε να μελετήσετε τις πιθανές επιδράσεις της ηλικίας και της διατροφής στις LDL - λιποπρωτεΐνες χαμηλής πυκνότητας, οι οποίες θεωρούνται υπεύθυνες για το σχηματισμό αθηροσκληρωτικών πλακών που προκαλούν αθηροσκλήρωση (Εικόνα 14).

Το Σχ. 14. Πολλαπλή παλινδρόμηση
Το R2 της πολλαπλής παλινδρόμησης (που αντανακλάται στο κελί F13) είναι μεγαλύτερο από το R2 κάθε απλής παλινδρόμησης (Ε4, Η4). Σε πολλαπλή παλινδρόμηση, πολλές μεταβλητές πρόβλεψης χρησιμοποιούνται ταυτόχρονα. Επιπλέον, το R 2 αυξάνεται σχεδόν πάντα.
Για κάθε απλή εξίσωση γραμμικής παλινδρόμησης με μια μεταβλητή πρόβλεψης, θα υπάρχει πάντα μια ιδανική συσχέτιση μεταξύ των προβλεπόμενων τιμών και των μεταβλητών τιμών πρόβλεψης, καθώς σε αυτή την εξίσωση οι τιμές προγνωστικών πολλαπλασιάζονται με μία σταθερά και μια διαφορετική σταθερά προστίθεται σε κάθε προϊόν. Αυτή η επίδραση δεν παραμένει σε πολλαπλή παλινδρόμηση.
Εμφάνιση των αποτελεσμάτων που επιστρέφονται από τη συνάρτηση LINEST () για πολλαπλή παλινδρόμηση (Εικ. 15). Οι συντελεστές παλινδρόμησης εμφανίζονται ως μέρος των αποτελεσμάτων που επιστρέφονται από τη συνάρτηση LINEST (). σε αντίστροφη σειρά των μεταβλητών (G - H - I αντιστοιχεί στο C - B - A).

Το Σχ. 15. Οι αποδόσεις και τα τυπικά σφάλματα εμφανίζονται με την αντίστροφη σειρά της ακολουθίας τους στο φύλλο εργασίας.
Οι αρχές και οι διαδικασίες που χρησιμοποιούνται στην ανάλυση παλινδρόμησης με μια μόνο μεταβλητή πρόβλεψης προσαρμόζονται εύκολα ώστε να λαμβάνουν υπόψη πολλαπλές μεταβλητές πρόβλεψης. Αποδεικνύεται ότι μεγάλο μέρος αυτής της προσαρμογής εξαρτάται από την εξάλειψη της επίδρασης των μεταβλητών πρόβλεψης ο ένας στον άλλο. Η τελευταία συσχετίζεται με ιδιαίτερους και ημι-μερικούς συσχετισμούς (Σχήμα 16).

Το Σχ. 16. Η πολλαπλή παλινδρόμηση μπορεί να εκφραστεί μέσω παλινδρόμησης των υπολειμμάτων (δείτε το αρχείο Excel για τους τύπους)
Στο Excel, υπάρχουν λειτουργίες που παρέχουν πληροφορίες σχετικά με τις διανομές t και F. Λειτουργίες των οποίων τα ονόματα περιλαμβάνουν μέρος του RASP, όπως τα STUDENT.RASP () και F. RASP (), παίρνουν το κριτήριο t ή F ως επιχείρημα και επιστρέφουν την πιθανότητα παρατήρησης της καθορισμένης τιμής. Οι λειτουργίες των οποίων τα ονόματα περιλαμβάνουν το τμήμα OBR, όπως το STUDENT.OBR () και το F. OBR (), λαμβάνουν την τιμή πιθανότητας ως επιχείρημα και επιστρέφουν την τιμή κριτηρίου που αντιστοιχεί στην καθορισμένη πιθανότητα.
Εφόσον αναζητούμε κρίσιμες τιμές της διανομής t που κόβουν τις άκρες των περιοχών της ουράς, περάσαμε 5% ως επιχείρημα σε μία από τις λειτουργίες STUDENT.OBR (), η οποία επιστρέφει μια τιμή που αντιστοιχεί στην πιθανότητα αυτή (Εικόνα 17, 18).

Το Σχ. 17. Δύο κατευθύνσεις t-test

Το Σχ. 18. One-way t-test
Καθορίζοντας έναν κανόνα απόφασης στην περίπτωση μιας άλφα περιοχής απλής ουράς, αυξάνετε τη στατιστική ισχύ της δοκιμής. Εάν, ξεκινώντας το πείραμα, είστε βέβαιοι ότι έχετε κάθε λόγο να περιμένετε να λάβετε έναν θετικό (ή αρνητικό) συντελεστή παλινδρόμησης, τότε θα πρέπει να εκτελέσετε ένα τεστ μονής ουράς. Σε αυτή την περίπτωση, η πιθανότητα να λάβετε τη σωστή απόφαση απορρίπτοντας την υπόθεση μηδενικού συντελεστή παλινδρόμησης στον πληθυσμό θα είναι υψηλότερη.
Οι στατιστικοί προτιμούν να χρησιμοποιούν τον όρο κατευθυντική δοκιμή αντί του όρου δοκιμή μονής ουράς και όρος μη κατευθυντική δοκιμή αντί του όρου δοκιμή διπλής ουράς. Οι όροι κατευθυντικοί και μη κατευθυντικοί είναι προτιμότεροι επειδή υπογραμμίζουν τον τύπο της υπόθεσης και όχι τη φύση των ουρών διανομής.
Μια προσέγγιση για την εκτίμηση της επίδρασης των προγνωστικών με βάση τη σύγκριση των μοντέλων.Στο σχ. Το σχήμα 19 παρουσιάζει τα αποτελέσματα μιας ανάλυσης παλινδρόμησης που ελέγχει τη συμβολή της μεταβλητής διατροφής στην εξίσωση παλινδρόμησης.

Το Σχ. 19. Σύγκριση δύο μοντέλων ελέγχοντας τις διαφορές στα αποτελέσματά τους
Τα αποτελέσματα της συνάρτησης LINEST () (περιοχή H2: K6) σχετίζονται με αυτό που αποκαλώ το πλήρες μοντέλο, στο οποίο εκτελείται η παλινδρόμηση της μεταβλητής LDL στις μεταβλητές Diet, Age και HDL. Στην περιοχή H9: J1Z, οι υπολογισμοί παρουσιάζονται χωρίς να λαμβάνεται υπόψη η μεταβλητή πρόβλεψης. Το αποκαλώ περιορισμένο μοντέλο. Στο πλήρες μοντέλο, το 49,2% της διακύμανσης της εξαρτώμενης μεταβλητής LDL εξηγείται από μεταβλητές πρόβλεψης. Στο περιορισμένο μοντέλο, μόνο το 30,8% της LDL εξηγείται από τις μεταβλητές Age και HDL. Η απώλεια του R 2 εξαιτίας του αποκλεισμού της μεταβλητής Diet από το μοντέλο είναι 0.183. Στην περιοχή G15: L17, έγιναν υπολογισμοί που δείχνουν ότι μόνο με μια πιθανότητα 0.0288 η επίδραση της μεταβλητής Διατροφής είναι τυχαία. Στο υπόλοιπο 97,1%, η δίαιτα επηρεάζει την LDL.
Κεφάλαιο 6. Υποθέσεις και προφυλάξεις σχετικά με την ανάλυση παλινδρόμησης
Ο όρος «παραδοχή» δεν ορίζεται αυστηρά και ο τρόπος χρήσης του προϋποθέτει ότι εάν η υπόθεση δεν τηρηθεί, τότε τα αποτελέσματα ολόκληρης της ανάλυσης είναι τουλάχιστον αμφισβητήσιμα ή ενδεχομένως μη έγκυρα. Στην πραγματικότητα, αυτό δεν συμβαίνει, αν και, βεβαίως, υπάρχουν περιπτώσεις όπου μια παραβίαση της υπόθεσης βασικά αλλάζει την εικόνα. Οι βασικές υποθέσεις: α) τα υπολείμματα της μεταβλητής Υ διανέμονται κανονικά σε οποιοδήποτε σημείο Χ κατά μήκος της γραμμής παλινδρόμησης. β) οι τιμές του Υ εξαρτώνται γραμμικά από τις τιμές του Χ. γ) η διασπορά των καταλοίπων είναι περίπου η ίδια σε κάθε σημείο Χ. δ) δεν υπάρχει σχέση μεταξύ των υπολειμμάτων.
Εάν οι υποθέσεις δεν διαδραματίσουν σημαντικό ρόλο, οι στατιστικολόγοι μιλούν για την ευρωστία της ανάλυσης σε σχέση με την παραβίαση της υπόθεσης. Συγκεκριμένα, όταν χρησιμοποιείτε την παλινδρόμηση για να ελέγξετε τις διαφορές μεταξύ των μέσων της ομάδας, η υπόθεση ότι οι τιμές Υ - και συνεπώς τα κατάλοιπα - κανονικά κατανεμημένες δεν παίζει σημαντικό ρόλο: οι δοκιμές είναι ισχυρές σε σχέση με την παραβίαση της υπόθεσης κανονικότητας. Είναι σημαντικό να αναλύσετε τα δεδομένα χρησιμοποιώντας γραφήματα. Για παράδειγμα, περιλαμβάνεται σε ένα πρόσθετο Ανάλυση δεδομένων μέσο Η παλινδρόμηση.
Αν τα δεδομένα δεν συμφωνούν με τις παραδοχές της γραμμικής παλινδρόμησης, έχετε στη διάθεσή σας άλλες προσεγγίσεις από τις γραμμικές. Ένα από αυτά είναι η λογιστική παλινδρόμηση (Εικ. 20). Κοντά στις άνω και κάτω οριακές τιμές της μεταβλητής πρόβλεψης, η γραμμική παλινδρόμηση οδηγεί σε μη ρεαλιστικές προβλέψεις.

Το Σχ. 20. Λογιστική παλινδρόμηση
Στο σχ. Το Σχήμα 6.8 δείχνει τα αποτελέσματα δύο μεθόδων ανάλυσης δεδομένων που στοχεύουν στη μελέτη της σχέσης μεταξύ του ετήσιου εισοδήματος και της πιθανότητας αγοράς ενός σπιτιού. Προφανώς, η πιθανότητα να πραγματοποιηθεί μια αγορά θα αυξηθεί με την αύξηση του εισοδήματος. Τα διαγράμματα διευκολύνουν τον εντοπισμό των διαφορών μεταξύ των αποτελεσμάτων που προβλέπουν την πιθανότητα αγοράς ενός σπιτιού μέσω γραμμικής παλινδρόμησης και τα αποτελέσματα που μπορεί να έχετε χρησιμοποιώντας μια διαφορετική προσέγγιση.
Στη γλώσσα των στατιστικολόγων, η απόρριψη της μηδενικής υπόθεσης, όταν στην πραγματικότητα είναι αλήθεια, ονομάζεται σφάλμα του πρώτου είδους.
Στο add-in Ανάλυση δεδομένων παρέχεται ένα βολικό εργαλείο για τη δημιουργία τυχαίων αριθμών, δίνοντας στον χρήστη τη δυνατότητα να καθορίσει την επιθυμητή μορφή διανομής (για παράδειγμα, Normal, Binomial ή Poisson), καθώς και τη μέση τιμή και την τυπική απόκλιση.
Διαφορές μεταξύ των λειτουργιών της οικογένειας STUDENT.RASP ().Ξεκινώντας με το Excel 2010, είναι διαθέσιμες τρεις διαφορετικές μορφές μιας λειτουργίας που επιστρέφουν την αναλογία της κατανομής στα αριστερά ή / και δεξιά της δεδομένης τιμής t-test. Η συνάρτηση STUDENT.DISC () επιστρέφει το κλάσμα της περιοχής κάτω από την καμπύλη διανομής στα αριστερά της τιμής κριτηρίου t που καθορίσατε. Υποθέστε ότι έχετε 36 παρατηρήσεις και συνεπώς ο αριθμός των βαθμών ελευθερίας για ανάλυση είναι 34 και η τιμή του κριτηρίου t \u003d 1,69. Σε αυτή την περίπτωση, ο τύπος
STUDENT.RASP (+1.69, 34, TRUE)
επιστρέφει μια τιμή 0,05 ή 5% (Εικ. 21). Το τρίτο επιχείρημα στη συνάρτηση STUDENT.DISC () μπορεί να είναι TRUE ή FALSE. Εάν έχει οριστεί ίση με TRUE, η συνάρτηση επιστρέφει τη σωρευτική περιοχή κάτω από την καμπύλη στα αριστερά του καθορισμένου κριτηρίου t, εκφραζόμενη ως κλάσμα. Αν είναι FALSE, η λειτουργία επιστρέφει το σχετικό ύψος της καμπύλης στο σημείο που αντιστοιχεί στο κριτήριο t. Άλλες εκδοχές της συνάρτησης STUDENT.RASP () - STUDENT.RASP.PX () και STUDENT.RASP.2X () - λαμβάνουν ως επιχειρήματα μόνο την τιμή του κριτηρίου t και τον αριθμό βαθμών ελευθερίας και δεν απαιτούν ένα τρίτο επιχείρημα.

Το Σχ. 21. Η σκοτεινότερη σκιασμένη περιοχή στην αριστερή ουρά της κατανομής αντιστοιχεί στο κλάσμα της περιοχής κάτω από την καμπύλη στα αριστερά της μεγάλης θετικής τιμής του t-test
Για να προσδιορίσετε την περιοχή στα δεξιά του κριτηρίου t, χρησιμοποιήστε έναν από τους παρακάτω τύπους:
1 - STYODENT.RASP (1, 69, 34, TRUE)
STUDENT.RASP.PH (1.69, 34)
Ολόκληρη η περιοχή κάτω από την καμπύλη πρέπει να είναι 100%, οπότε η αφαίρεση από ένα κλάσμα της περιοχής προς τα αριστερά της τιμής κριτηρίου t που επιστρέφει η συνάρτηση δίνει το κλάσμα της περιοχής που βρίσκεται στα δεξιά της τιμής κριτηρίου t. Ίσως προτιμάτε να αποκτήσετε απευθείας το κλάσμα της περιοχής που σας ενδιαφέρει χρησιμοποιώντας τη λειτουργία STUDENT.RASP.PH (), όπου PX σημαίνει τη δεξιά ουρά της διανομής (Εικ. 22).

Το Σχ. 22. Περιοχή άλφα 5% για κατευθυντική δοκιμή
Χρησιμοποιώντας τις λειτουργίες STUDENT.RACP () ή STUDENT.RACP.PH () υποδηλώνει ότι έχετε επιλέξει μια κατευθυνόμενη υπόθεση εργασίας. Μια κατευθυνόμενη υπόθεση εργασίας σε συνδυασμό με τη ρύθμιση της τιμής alpha στο 5% σημαίνει ότι βάζετε όλο το 5% στη δεξιά ουρά με διανομές. Θα πρέπει να απορρίψετε την μηδενική υπόθεση μόνο εάν η πιθανότητα του κριτηρίου t που λαμβάνετε είναι 5% ή λιγότερο. Οι κατευθυνόμενες υποθέσεις συνήθως οδηγούν σε πιο ευαίσθητες στατιστικές δοκιμές (αυτή η μεγαλύτερη ευαισθησία ονομάζεται επίσης μεγαλύτερη στατιστική ισχύς).
Σε μια μη κατευθυνόμενη δοκιμή, η τιμή alpha παραμένει στο ίδιο επίπεδο με 5%, αλλά η κατανομή θα είναι διαφορετική. Δεδομένου ότι πρέπει να επιτρέψετε δύο αποτελέσματα, η πιθανότητα ενός ψευδώς θετικού πρέπει να κατανέμεται μεταξύ των δύο ουρών της διανομής. Είναι γενικά αποδεκτό να κατανέμεται αυτή η πιθανότητα εξίσου (Εικόνα 23).

Χρησιμοποιώντας την ίδια ληφθείσα τιμή του κριτηρίου t και τον ίδιο αριθμό βαθμών ελευθερίας όπως στο προηγούμενο παράδειγμα, χρησιμοποιήστε τον τύπο
STUDENT.RASP.2X (1,69; 34)
Για κανένα ιδιαίτερο λόγο, η συνάρτηση STUDENT.RASP.2X () επιστρέφει τον κωδικό σφάλματος #NUMBER!, Εάν η αρνητική τιμή του κριτηρίου t δίνεται σε αυτό ως το πρώτο όρισμα.
Εάν τα δείγματα περιέχουν διαφορετική ποσότητα δεδομένων, χρησιμοποιήστε το t-test δύο δειγμάτων με διαφορετικές διακυμάνσεις που περιλαμβάνονται στη συσκευασία Ανάλυση δεδομένων.
Κεφάλαιο 7. Χρήση παλινδρόμησης για να ελέγξετε τις διαφορές μεταξύ των μέσων της ομάδας
Οι μεταβλητές που προηγουμένως ονομάζονταν προβλεπόμενες μεταβλητές θα ονομάζονται παραγωγικές μεταβλητές σε αυτό το κεφάλαιο και θα χρησιμοποιηθούν οι μεταβλητές παράγοντα όρος αντί των μεταβλητών πρόβλεψης.
Η απλούστερη προσέγγιση για την κωδικοποίηση μιας ονομαστικής μεταβλητής είναι εικονική κωδικοποίηση (εικ. 24).

Το Σχ. 24. Ανάλυση παλινδρόμησης βασισμένη σε ψευδο-κωδικοποίηση
Όταν χρησιμοποιείτε πλασματική κωδικοποίηση οποιουδήποτε είδους, ακολουθούνται οι ακόλουθοι κανόνες:
- Ο αριθμός των στηλών που προορίζονται για νέα δεδομένα πρέπει να είναι ίσος με τον αριθμό των επιπέδων συντελεστών μείον
- Κάθε φορέας αντιπροσωπεύει ένα επίπεδο παράγοντα.
- Τα υποκείμενα ενός από τα επίπεδα, τα οποία είναι συχνά μια ομάδα ελέγχου, λαμβάνουν τον κωδικό 0 σε όλους τους φορείς.
Ο τύπος στα κελιά F2: H6 \u003d LINEST (A2: A22, C2: D22 ;; TRUE) επιστρέφει τα στατιστικά στοιχεία παλινδρόμησης. Για λόγους σύγκρισης, στο σχ. Το Σχήμα 24 δείχνει τα αποτελέσματα μιας συμβατικής ανάλυσης της μεταβλητότητας που επέστρεψε το όργανο Μοναδική ανάλυση της διακύμανσης πρόσθετα Ανάλυση δεδομένων.
Τα αποτελέσματα κωδικοποίησης.Σε έναν άλλο τύπο κωδικοποίησης, που ονομάζεται κωδικοποίησης, ο μέσος όρος κάθε ομάδας συγκρίνεται με τον μέσο όρο των ομάδων. Αυτή η πτυχή της κωδικοποίησης των αποτελεσμάτων οφείλεται στη χρήση μιας τιμής -1 αντί του 0 ως κώδικα για μια ομάδα που λαμβάνει τον ίδιο κώδικα σε όλους τους φορείς κώδικα (Εικόνα 25).

Το Σχ. 25. Κωδικοποίηση αποτελεσμάτων
Όταν χρησιμοποιείται ψευδής κωδικοποίηση, η σταθερή τιμή που επιστρέφεται από τη συνάρτηση LINEST () συμπίπτει με τη μέση της ομάδας στην οποία αντιστοιχίζονται μηδενικοί κωδικοί σε όλους τους φορείς (συνήθως αυτή είναι μια ομάδα ελέγχου). Στην περίπτωση των αποτελεσμάτων κωδικοποίησης, η σταθερά είναι ίση με το συνολικό μέσο όρο (κύτταρο J2).
Ένα γενικό γραμμικό μοντέλο είναι ένας χρήσιμος τρόπος για να κατανοήσουμε τα συστατικά της τιμής της προκύπτουσας μεταβλητής:
Y ij \u003d μ + α j + ε ij
Η χρήση ελληνικών γράμματα αντί για λατινικά γράμματα σε αυτόν τον τύπο υπογραμμίζει το γεγονός ότι αναφέρεται στον πληθυσμό από τον οποίο εξάγονται τα δείγματα αλλά μπορεί να ξαναγραφεί σε μορφή που υποδεικνύει ότι αναφέρεται στα δείγματα που προέρχονται από τον δημοσιευμένο πληθυσμό:
Yjj \u003d Yjj + a j + ejj
Η ιδέα είναι ότι κάθε παρατήρηση Y ij μπορεί να θεωρηθεί ως το άθροισμα των ακόλουθων τριών συνιστωσών: συνολικός μέσος όρος, μ; το αποτέλεσμα επεξεργασίας j και j; η τιμή του e ij, που αντιπροσωπεύει την απόκλιση του επιμέρους ποσοτικού δείκτη Y ij από τη συνδυασμένη τιμή του συνολικού μέσου όρου και την επίδραση της j-th επεξεργασίας (Εικ. 26). Ο στόχος της εξίσωσης παλινδρόμησης είναι να ελαχιστοποιηθεί το άθροισμα τετραγωνικών υπολειμμάτων.

Το Σχ. 26. Οι παρατηρήσεις αποσυντέθηκαν σε συστατικά ενός γενικού γραμμικού μοντέλου
Ανάλυση παραγόντων.Αν μελετήσουμε τη σχέση μεταξύ μιας παραγωγικής μεταβλητής και ταυτόχρονα δύο ή περισσότερους παράγοντες, τότε σε αυτή την περίπτωση μιλάμε για τη χρήση της ανάλυσης παράγοντα. Η προσθήκη ενός ή περισσότερων παραγόντων στη μονόδρομη ανάλυση της διακύμανσης μπορεί να αυξήσει την στατιστική ισχύ. Σε μια μονόδρομη ανάλυση της διακύμανσης, η μεταβολή της πραγματικής μεταβλητής, η οποία δεν μπορεί να αποδοθεί στον παράγοντα, περιλαμβάνεται στο υπολειπόμενο μέσο τετράγωνο. Αλλά μπορεί να είναι ότι αυτή η παραλλαγή συνδέεται με έναν άλλο παράγοντα. Στη συνέχεια, αυτή η παραλλαγή μπορεί να αφαιρεθεί από το μέσο τετραγωνικό σφάλμα, η μείωση του οποίου οδηγεί σε αύξηση των τιμών του κριτηρίου F και, κατά συνέπεια, σε αύξηση της στατιστικής ισχύος του τεστ. Πρόσθετο Ανάλυση δεδομένων περιλαμβάνει ένα εργαλείο που παρέχει την ταυτόχρονη επεξεργασία δύο παραγόντων (Εικ. 27).

Το Σχ. 27. Αμφίδρομη ανάλυση της διακύμανσης με επαναλήψεις του πακέτου ανάλυσης
Η ανάλυση του εργαλείου διακύμανσης που χρησιμοποιείται σε αυτό το σχήμα είναι χρήσιμη στο ότι επιστρέφει τον μέσο όρο και τη διακύμανση της προκύπτουσας μεταβλητής, καθώς και την τιμή μετρητή για κάθε ομάδα που περιλαμβάνεται στο σχέδιο. Στο τραπέζι Ανάλυση διακύμανσης εμφανίζονται δύο παράμετροι που δεν βρίσκονται στην έξοδο της έκδοσης ενός παράγοντα της ανάλυσης της διακύμανσης. Δώστε προσοχή στις πηγές παραλλαγής. Δειγματοληψία και Στήλες στις γραμμές 27 και 28. Πηγή παραλλαγής Στήλες αναφέρεται στο πάτωμα. Πηγή παραλλαγής Δειγματοληψία αναφέρεται σε οποιαδήποτε μεταβλητή των οποίων οι τιμές καταλαμβάνουν διαφορετικές γραμμές. Στο σχ. Οι τιμές 27 για την ομάδα CourseLech1 είναι στις γραμμές 2-6, οι ομάδες CourseLech2 βρίσκονται στις γραμμές 7-11 και οι ομάδες CourseLechZ βρίσκονται στις γραμμές 12-16.
Το κύριο σημείο είναι ότι και οι δύο παράγοντες, το φύλο (στήλες υπογραφής στο κελί E28) και η θεραπεία (δείγμα υπογραφής στο κελί Ε27) περιλαμβάνονται στην ανάλυση της διακύμανσης ως πηγές μεταβολής. Οι μέσοι όροι για τους άνδρες είναι διαφορετικοί από τους μέσους όρους για τις γυναίκες και αυτό δημιουργεί μια πηγή διακύμανσης. Οι μέσοι όροι για τους τρεις τύπους θεραπείας ποικίλλουν επίσης - εδώ υπάρχει μια άλλη πηγή διακύμανσης. Υπάρχει επίσης μια τρίτη πηγή - Αλληλεπίδραση, η οποία αναφέρεται στο συνδυασμένο αποτέλεσμα των μεταβλητών Sex and Treatment.
Κεφάλαιο 8. Αναλυτική ανάλυση
Η ανάλυση Covariance ή η ANCOVA (Ανάλυση της Συσσώρευσης) μειώνει την προκατάληψη και αυξάνει την στατιστική ισχύ. Επιτρέψτε μου να σας υπενθυμίσω ότι ένας από τους τρόπους αξιολόγησης της αξιοπιστίας της εξίσωσης παλινδρόμησης είναι οι δοκιμές F:
F \u003d παλινδρόμηση MS / υπόλοιπο MS
όπου το MS (Mean Square) είναι το μέσο τετράγωνο, και οι δείκτες Regression και Residual υποδηλώνουν την παλινδρόμηση και τα υπόλοιπα στοιχεία, αντίστοιχα. Ο υπολογισμός του MS Residual εκτελείται σύμφωνα με τον τύπο:
MS υπολειπόμενο \u003d SS υπολειπόμενο / df υπολειπόμενο
όπου SS (Sum of Squares) είναι το άθροισμα των τετραγώνων, και df είναι ο αριθμός των βαθμών ελευθερίας. Όταν προσθέτετε συνδιακύμανση στην εξίσωση παλινδρόμησης, ένα κλάσμα του συνολικού αθροίσματος των τετραγώνων δεν περιλαμβάνεται στο SS ResiduaI, αλλά στην SS Regression. Αυτό οδηγεί σε μείωση του SS Residua l, και κατά συνέπεια του MS Residual. Όσο μικρότερο είναι το MS Residual, τόσο μεγαλύτερο είναι το F-test και τόσο πιο πιθανό είναι να απορρίψετε τη μηδενική υπόθεση ότι δεν υπάρχουν διαφορές μεταξύ των μέσων. Ως αποτέλεσμα, αναδιανείμετε τη μεταβλητότητα της μεταβλητής αποτελέσματος. Στην ANOVA, όταν η συνδιακύμανση δεν λαμβάνεται υπόψη, η μεταβλητότητα γίνεται λάθος. Αλλά στο ANCOVA, μέρος της μεταβλητότητας που αποδίδεται στο παρελθόν σε σφάλμα έχει ανατεθεί να μεταβληθεί και να γίνει μέρος της παλινδρόμησης SS.
Εξετάστε ένα παράδειγμα στο οποίο αναλύεται το ίδιο σύνολο δεδομένων χρησιμοποιώντας πρώτα ANOVA και στη συνέχεια χρησιμοποιώντας το ANCOVA (Εικόνα 28).

Το Σχ. 28. Η ανάλυση ANOVA δείχνει ότι τα αποτελέσματα που λαμβάνονται χρησιμοποιώντας την εξίσωση παλινδρόμησης είναι αναξιόπιστα
Η μελέτη συγκρίνει τις σχετικές επιδράσεις των σωματικών ασκήσεων που αναπτύσσουν μυϊκή δύναμη και γνωστικές ασκήσεις (επίλυση σταυρόλεξων) που ενεργοποιούν την εγκεφαλική δραστηριότητα. Τα άτομα κατανέμονται τυχαία σε δύο ομάδες, έτσι ώστε στην αρχή του πειράματος και οι δύο ομάδες να βρίσκονται στις ίδιες συνθήκες. Μετά από τρεις μήνες, μετρήθηκαν τα γνωστικά χαρακτηριστικά των υποκειμένων. Τα αποτελέσματα αυτών των μετρήσεων φαίνονται στη στήλη Β.
Στην περιοχή A2: C21, τοποθετούνται τα αρχικά δεδομένα, τα οποία μεταφέρονται στη συνάρτηση LINEST () για ανάλυση χρησιμοποιώντας κωδικοποίηση αποτελεσμάτων. Τα αποτελέσματα της συνάρτησης LINEST () δίδονται στην περιοχή Ε2: F6, όπου ο συντελεστής παλινδρόμησης που σχετίζεται με τον φορέα έκθεσης εμφανίζεται στο κελί Ε2. Στο κελί E8, η t-test \u003d 0,93 περιέχεται και στην κυψελίδα E9 δοκιμάζεται η αξιοπιστία αυτού του t-test. Η τιμή που περιέχεται στο κελί E9 δείχνει ότι η πιθανότητα να ικανοποιηθεί η διαφορά μεταξύ των μέσων ομάδας που παρατηρήθηκαν σε αυτό το πείραμα είναι 36% εάν τα μέσα ομάδας είναι ίσα στο γενικό πληθυσμό. Μόνο μερικοί αναγνωρίζουν αυτό το αποτέλεσμα ως στατιστικά σημαντικό.
Στο σχ. Το σχήμα 29 δείχνει τι συμβαίνει όταν προστίθενται στην ανάλυση οι συντεταγμένες. Σε αυτήν την περίπτωση, πρόσθεσα την ηλικία κάθε θέματος στο σύνολο δεδομένων. Ο συντελεστής προσδιορισμού R2 για την εξίσωση παλινδρόμησης στην οποία χρησιμοποιείται ομοιοπολική είναι 0.80 (κύτταρο F4). Η τιμή του R2 στην περιοχή F15: G19, στην οποία αναπαράγονται τα αποτελέσματα ANOVA που λαμβάνονται χωρίς τη χρήση μεταβλητών, είναι μόνο 0,05 (κύτταρο F17). Επομένως, η εξίσωση παλινδρόμησης, συμπεριλαμβανομένης της μεταβλητής, προβλέπει την αξία της μεταβλητής του γνωστικού δείκτη πολύ ακριβέστερα από τη χρήση μόνο του φορέα επιδράσεων. Για το ANCOVA, η πιθανότητα να ληφθεί τυχαία η τιμή του κριτηρίου F που εμφανίζεται στο κελί F5 είναι μικρότερη από 0,01%.

Το Σχ. 29. Η ANCOVA φέρνει μια εντελώς διαφορετική εικόνα
Το πακέτο MS Excel σάς επιτρέπει να κάνετε το μεγαλύτερο μέρος της εργασίας πολύ γρήγορα όταν δημιουργείτε την εξίσωση γραμμικής παλινδρόμησης. Είναι σημαντικό να κατανοήσετε τον τρόπο ερμηνείας των αποτελεσμάτων. Για να δημιουργήσετε ένα μοντέλο παλινδρόμησης, επιλέξτε το στοιχείο Εργαλεία \\ Δεδομένα ανάλυσης \\ Regression (στο Excel 2007 αυτή η λειτουργία βρίσκεται στην ενότητα Data / Data Analysis / Regression). Στη συνέχεια, αντιγράψτε τα αποτελέσματα σε ένα μπλοκ για ανάλυση.

Δείχνει την επίδραση ορισμένων τιμών (ανεξάρτητων, ανεξάρτητων) στην εξαρτημένη μεταβλητή. Για παράδειγμα, πώς ο αριθμός του οικονομικά ενεργού πληθυσμού εξαρτάται από τον αριθμό των επιχειρήσεων, το μέγεθος των μισθών και άλλες παραμέτρους. Ή: πώς επηρεάζουν το επίπεδο του ΑΕΠ οι ξένες επενδύσεις, οι τιμές ενέργειας κ.λπ.
Το αποτέλεσμα της ανάλυσης σας επιτρέπει να δώσετε προτεραιότητα. Και με βάση τους κύριους παράγοντες, να προβλέψει, να προγραμματίσει την ανάπτυξη των τομέων προτεραιότητας, να λάβει τις αποφάσεις της διαχείρισης.
Η παλινδρόμηση συμβαίνει:
Γραμμική (γ \u003d α + bx);
Παραβολική (γ \u003d α + bx + cx2);
Εκθετική (y \u003d a * exp (bx));
Νόμος εξουσίας (y \u003d a * x ^ b);
Υπερβολικό (γ \u003d β / χ + α);
· Λογαριθμική (γ \u003d b * 1n (x) + a);
Εκθετική (γ \u003d α * β ^ x).
Ας δούμε ένα παράδειγμα οικοδόμησης ενός μοντέλου παλινδρόμησης στο Excel και ερμηνείας των αποτελεσμάτων. Πάρτε τον γραμμικό τύπο παλινδρόμησης.
Πρόκληση. Σε 6 επιχειρήσεις αναλύθηκε ο μέσος μηνιαίος μισθός και ο αριθμός των παραιτηθέντων εργαζομένων. Είναι απαραίτητο να προσδιοριστεί η εξάρτηση του αριθμού των υπαλλήλων που εγκαταλείπουν το μέσο μισθό.
Το μοντέλο γραμμικής παλινδρόμησης έχει ως εξής:
Υ \u003d α 0 + α 1 χ 1 + ... + a k χ k.
Όπου a είναι οι συντελεστές παλινδρόμησης, οι x είναι οι μεταβλητές επηρεασμού και k είναι ο αριθμός των παραγόντων.
Στο παράδειγμά μας, το Y είναι ο δείκτης των συνταξιούχων εργαζομένων. Ο συντελεστής επηρεάζει τους μισθούς (x).
Το Excel διαθέτει ενσωματωμένες λειτουργίες που μπορούν να χρησιμοποιηθούν για τον υπολογισμό των παραμέτρων ενός μοντέλου γραμμικής παλινδρόμησης. Αλλά πιο γρήγορα αυτό θα κάνει το πρόσθετο "πακέτο ανάλυσης".
Ενεργοποιούμε ένα ισχυρό αναλυτικό εργαλείο:
1. Πατήστε το κουμπί "Office" και μεταβείτε στην καρτέλα "Επιλογές του Excel". "Πρόσθετα."

2. Στο κάτω μέρος, κάτω από την αναπτυσσόμενη λίστα, στο πεδίο "Διαχείριση" θα υπάρχει η ένδειξη "Πρόσθετα του Excel" (αν δεν είναι, κάντε κλικ στο πλαίσιο ελέγχου στα δεξιά και επιλέξτε). Και το κουμπί Μετάβαση σε. Πατήστε.
3. Ανοίγει μια λίστα με τα διαθέσιμα πρόσθετα. Επιλέξτε "Πακέτο ανάλυσης" και κάντε κλικ στο OK.

Μετά την ενεργοποίηση, το πρόσθετο θα είναι διαθέσιμο στην καρτέλα "Δεδομένα".

Τώρα θα ασχοληθούμε άμεσα με την ανάλυση παλινδρόμησης.
1. Ανοίξτε το μενού του εργαλείου "Ανάλυση δεδομένων". Επιλέξτε "Παλινδρόμηση".

2. Θα ανοίξει ένα μενού για την επιλογή τιμών εισόδου και παραμέτρων εξόδου (όπου θα εμφανιστεί το αποτέλεσμα). Στα πεδία για τα δεδομένα πηγής, αναφέρετε το εύρος της περιγραφόμενης παράμετρος (Y) και του παράγοντα (X) που την επηρεάζει. Τα υπόλοιπα μπορούν να μείνουν κενά.

3. Αφού κάνετε κλικ στο OK, το πρόγραμμα θα εμφανίσει τους υπολογισμούς σε ένα νέο φύλλο (μπορείτε να επιλέξετε το διάστημα που θα εμφανιστεί στο τρέχον φύλλο ή να εκχωρήσετε μια έξοδο σε ένα νέο βιβλίο).

Πρώτα απ 'όλα, δώστε προσοχή στο R-τετράγωνο και τους συντελεστές.
Το R-τετράγωνο είναι ο συντελεστής προσδιορισμού. Στο παράδειγμα μας, 0.755, ή 75.5%. Αυτό σημαίνει ότι οι υπολογιζόμενες παραμέτρους μοντέλου κατά 75,5% εξηγούν τη σχέση μεταξύ των μελετών παραμέτρων. Όσο υψηλότερος είναι ο συντελεστής προσδιορισμού, τόσο καλύτερα είναι το μοντέλο. Καλό - πάνω από 0.8. Κακό - λιγότερο από 0,5 (μια τέτοια ανάλυση δύσκολα μπορεί να θεωρηθεί λογική). Στο παράδειγμά μας, "δεν είναι κακό".
Ο συντελεστής 64.1428 δείχνει τι θα είναι το Υ εάν όλες οι μεταβλητές στο υπό εξέταση μοντέλο είναι ίσες με 0. Δηλαδή, άλλοι παράγοντες που δεν περιγράφονται στο μοντέλο επηρεάζουν επίσης την τιμή της παραμέτρου που αναλύεται.
Ο συντελεστής -0,16285 δείχνει το βάρος της μεταβλητής Χ με το Υ. Δηλαδή, ο μέσος μηνιαίος μισθός στο μοντέλο αυτό επηρεάζει τον αριθμό εκείνων που αφήνουν με βάρος -0,16285 (αυτός είναι ένας μικρός βαθμός επιρροής). Το σύμβολο "-" υποδεικνύει αρνητικό αντίκτυπο: όσο υψηλότερος είναι ο μισθός, τόσο λιγότεροι είναι εκείνοι που εγκατέλειψαν. Ποιο είναι δίκαιο.